

بسم الله الرحمن الرحیم
تعداد سوالهایی که از من در مورد تبدیل یکسری تصاویر به دیتابیسی که caffe با اون کار میکنه خیلی زیاد شده و اینجا میخوام توضیحاتی در این باره بدم و نشون بدیم چطور میشه از تصاویری که خودمون داریم یک دیتابیس به فرمت leveldb یا lmdb تهیه و بعد در Caffe استفاده کنیم .
قبل از هرچیزی ما میدونیم که اگر مجموعه تصاویری داشته باشیم الزامی نداریم که حتما اونو به فرمت lmdb یا leveldb یا حتی hdf5 در بیاریم اما دلایل خوبی وجود داره که این کارو بکنیم . ما میدونیم که میتونیم خیلی راحت با استفاده از لایه ImageDataLayerکه در بخش لایه ها توضیح کامل در موردش داد شد استفاده کنیم . کافیه پوشه هایی که تصاویر ما در اون قرار دارن رو در اون لایه مشخص کنیم و بعد لیبل ها رو هم در قالب یک فایل متنی که آدرس هر تصویر و لیبل متناظر با اون رو در خودش داره به اون لایه معرفی کنیم. این لایه یکسری عملیاتهای خاص رو هم در اختیار ما قرار میده مثل resize کردن و… که در لایه Data که مخصوص استفاده از دیتابیس های lmdb و… هست وجود نداره .
اما تبدیل محسنات خودش رو داره مهمترین اونها افزایش کارایی هست و همچنین انتقال راحت تر فایلها .
ما در Caffe یکسری نمونه مثال داریم مثل mnist یا CIFAR10 و اگر برنچ من رو استفاده کرده باشید مثال CIFAR100. این مثالها اسکریپتهایی و برنامه هایی دارن که از اون برای دانلود و تبدیل فایلها به دیتاست استفاده میشه. برنامه های مورد نظر همراه caffe کامپایل میشن و در پوشه build شما قرا ردارن. به ترتیب convert_mnist_data.exe و convert_cifar_data .exeو convert_cifar100_data.exe برنامه هایی هستن که تو زمینه تبدیل دیتاهای این دیتاست ها به فرمت lmdb یا leveldb استفاده میشن . استفاده از اونها هم خیلی راحته و کافیه ارگومانهای مورد نیاز اونها رو بهشون بدید. برای دونستن اینکه چه آرگومانهایی هم لازم دارن میتونید اونها رو در cmd بدون ارگومان اجرا کنید تا برنامه چیزهایی که نیاز داره رو نشون بده .
بعنوان مثال برای مثال mnist ما این داده ها رو داریم و به این شکل استفاده میکنیم :
زمانی که شما دیتای mnist رو دانلود میکنید ۴ تا فایل بدست میارید . دو فایل مربوط به training دو فایل هم مربوط به test set شما هست . که یکی دیتاست و دیگری لیبل مربوط به هر کدوم هست.
نحوه فراخونی هم خیلی ساده اس و میتونید بشکل زیر این کار رو انجام بدید . من هر ارگومان رو جداگونه زیر هم مینویسم تا مشخص باشه . شما موقع استفاده همه رو در یک خط بنویسید با یک اسپیس فاصله!.
- بخش اول مسیر خود فایل اجرایی ما هست .
- بخش دوم فایل حاوی تصاویر آموزشی ما هست .
- بخش سوم هم لیبل مربوط به تصاویر آموزشی ما هست .
- بخش چهارم هم نامی هست که دیتاست با اون نام ایجاد میشه.
- بخش آخر هم فرمت دیتابیس ما هست در اینجا ما lmdb رو مشخص کردیم . (میتونستیم leveldbهم بنویسیم.)
|
1 2 3 4 5 6 7 |
"buildinstallbinconvert_mnist_data.exe" Datamnisttrain-images-idx3-ubyte Datamnisttrain-labels-idx1-ubyte mnist_train_lmdb --backend=lmdb |
|
1 2 3 |
"buildinstallbinconvert_mnist_data.exe" Datamnisttrain-images-idx3-ubyte Datamnisttrain-labels-idx1-ubyte mnist_train_lmdb --backend=lmdb |
|
1 2 3 |
"buildinstallbinconvert_mnist_data.exe" Datamnistt10k-images-idx3-ubyte Datamnistt10k-labels-idx1-ubyte mnist_test_lmdb --backend=lmdb |
خب حالا اگر ما بخواییم روی تصاویر خودمون کار کنیم چیکار باید کرد؟
اینجا ما میتونیم از convert_imageset.exe استفاده کنیم که در همون پوشه build قرار داره و همراه بقیه فایلهای Caffe کامپایل میشه . شیوه کار هم مثل قبله اما من سعی میکنم با یک مثال اونو نشون بدم
فرض کنید من یک دیتاست دارم اولین کاری که میکنم اینه که دوتا پوشه ایجاد میکنم یکی برای training و دیگری برای test.
در داخل هرکدوم از این پوشه ها ما هر کلاس رو بصورت یک پوشه ایجاد میکنیم و تصاویر اون رو در اون پوشه میزاریم . مثلا فرض کنید من ۵ تا کلاس دارم . سگ گربه هواپیما کشتی و اسب ! من ۵ تا پوشه درست میکنم با همین نامها و تصاویر هر گروه رو در پوشه متناظر با خودش قرار میدم . همین کار رو هم برای test انجام میدیم و تصاویر هرکدوم رو هم درون این پوشه ها میزارم. حالا دوتا فایل متنی ایجاد میکنم . یکی بنام train_label.txt و دیگری test_label.txt که در اولی لیبل های مربوط به تصاویر training و در دومی هم لیبل های مربوط به تصاویر Test set ما قرار میگیره این فایلها رو در داخل پوشه train و test قرار میدیم.
پس من یک پوشه میسازم بنام MyDataSet و در داخل اون دوتا پوشه دیگه بنام train و test ایجاد میکنم.وارد پوشه train و test که بشیم به تعداد کلاسهایی که داریم پوشه داریم و دوتا فایل متنی هم با نامهای train_label.txt و test_label.txt در کنار این پوشه ها در داخل trainو test قرار میدم.
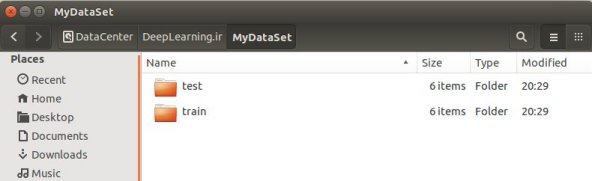
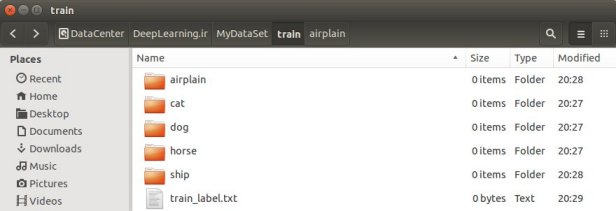
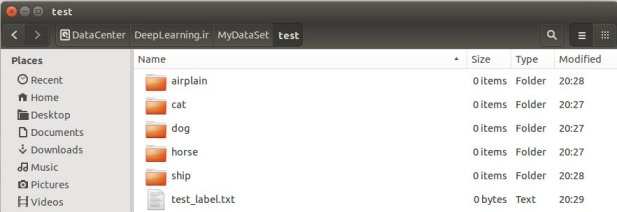
برای پر کردن فایل های لیبل ما آدرس نسبی تصاویر رو با لیبل هر کلاس در یک خط مشخص میکنیم . مثل زیر :
|
1 2 3 4 5 6 7 |
horse/lippizaner_s_001297.png 2 airplane/fighter_aircraft_s_000924.png 0 ship/container_ship_s_002089.png 1 dog/chihuahua_s_000780.png 4 cat/domestic_cat_s_001116.png 3 |
و بعد تنها کاری که الان باقی میمونه اراپه این موارد بعنوان پارامتر به برنامه convert_imageset.exe هست .
اگر این برنامه رو بدون پارامتر اجرا کنید میبینید که ما به پارامترهایی که تو مثال های mnist دیدم سروکار داریم تقریبا مثل هم هستن با کمی تفاوت .فرمت کلی اجرای دستور بصورت زیر هست :
|
1 2 3 |
/convert_imageset --resize_height=٪RESIZE_HEIGHT٪ --resize_width=٪RESIZE_WIDTH٪ --shuffle ٪TRAIN_DATA_ROOT٪ ٪TRAIN_DATA_ROOT٪/train_label.txt ٪MyDataSet٪/mydataset_train_lmdb |
اینجا ما چندتا پارامتر داریم:
- resize_height
- resize_width
- shuffle
|
1 2 3 |
convert_imageset.exe --resize_height=32 --resize_width=32 --shuffle E:/DeepLearning.ir/MyDataSet/train E:/DeepLearning.ir/MyDataSet/train/train_label.txt mydataset_train_lmdb |
خب من فرض کردم ما وارد پوشه ای شدیم که convert_imageset در داخلش هست و اونجا cmd رو اجرا کردیم و پارامترها رو دادیم . در اینصورت در کنار همین فایل convert_imageset دیتاست ما با نامی که مشخص کردیم ایجاد میشه . یک پوشه با این نام ایجاد میشه که یکسری فایل در داخلش هست . کل این پوشه دیتاست ما هست! نه فقط فایلهای داخلش.
معمولا شیوه کار به این صورته که ما یه پوشه جدید مثلا MyDataSet رو در پوشه examples کفی ایجاد میکنیم . بعد خیلی راحت وارد روت caffeمیشیم و از اونجا دستور رو مثلا به شکل زیر اجرا میکنیم . اینطوری هر فایلی سر جای خودش قرار میگیره و دردسرهای شما هم کمتر میشه .
|
1 2 3 |
/build/install/bin/convert_imageset.exe --resize_height=32 --resize_width=32 --shuffle Examples/MyDataSet/train Examples/MyDataSet/train/train.txt Examples/MyDataSet/mydataset_train_lmdb |
و همین کار رو برای test set انجام میدیم . به این شکل شما میتونید نه فقط trainو test بلکه validation و ورژن های مختلف از دیتاستتون رو ایجاد کنید و براحتی از اونها استفاده کنید.
پ.ن : تصاویری که گرفتم از اوبونتو هست چون موقع نوشتن این آموزش تو این سیستم عامل بودم برای همین نشد تصویر از ویندوز بگیرم . آموزش به فرمت ویندوز هست اما براحتی در لینوکس هم قابل استفاده اس (فقط .exe حذف میشه . forward slashهم ویندوز قبول میکنه برای همین برای نزدیکی بیشتر ویندوز و لینوکس ادرسها به فرمتی که میبینید قرار دادم.
درخواست و همینطور سوالهای زیادی داشتم که چطور خود ما لیبل ها رو درست کنیم . ما فقط یکسری پوشه از تصاویر داریم و تعداد تصاویر هم زیاده و دستی نمیشه کار کرد چیکار باید بکنیم ؟
خب نوشتن برنامه ای که لیست پوشه هایی رو بگیره و خودش عمل لیبل گذاری رو انجام بده کار سختی نیست اما به هر حال میتونید از اسکریپتهایی که من نوشتم استفاده کنید و اگر چیزی نیاز به تغییر باشه خودتون تغییر بدید .
اگه بخش ترینینگ و تست شما جدا هست میتونید خیلی ساده از این کد استفاده کنید نحوه استفاده هم سر راست و مشخص هست با کامنت همه بخشارو مشخص کردم . کد زیر رو یکبار برای تست و یکبار هم برای ترینینگ استفاده کنید (یکبار پوشه تست رو بدید و اجرا کنید و دفعه بعد پوشه ترینینگ اسم فایلها رو هم تغییر بدید. یا بهتر اینو تبدیل به تابع کنید و هربار پارامترها رو براش بفرستید اینطور راحت ترید):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# In the name of GOD # a simple script for creating labels automatically # Deeplearning.ir # Coderx7@gmail.com import os root = 'G:/hossein/data/cifar10/train/' # lets get all the sub-directories first subfolders = [name for name in os.listdir(root) if os.path.isdir(os.path.join(root,name)) ] # open a file label = open(os.path.join(root,'labels_training.txt'),'a+') # now lets enter each folder and read their images and populate our label file for class_index ,folder in enumerate(subfolders): print (folder, str(class_index)) images = [f for f in os.listdir(os.path.join(root,folder)) if f.endswith('.png')] #create a label for i, img in enumerate(images): label.write('{0}{1} {2}nr'.format(folder, img, class_index)) label.close() |
اگه بخش ترینینگ و تست رو جدا نکردید و کلا همه تصاویر با هم هستن از این استفاده کنید . اینجا خودش از تصاویری که دارید میاد ترینینگ ست و تست ست رو مشخص میکنه . پیشفرض هم ۷۰ به ۳۰ هست . میتونید این مقدار رو تغییر بدید خودتون. فکر نمیکنم توضیح خاصی نیاز باشه همه چیز مشخصه :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
from random import shuffle import os root = 'G:/hossein/data/cifar10/data_train_and_test/' # lets get all the sub-directories first subfolders = [name for name in os.listdir(root) if os.path.isdir(os.path.join(root,name)) ] #specify training/validation ratio training_ratio = 0.7 # files for training and validation(testing) labels training_label = open(os.path.join(root,'labels_train.txt'),'a+') testing_label = open(os.path.join(root,'labels_test.txt'),'a+') # now lets enter each folder and read their images and populate our label file for class_index ,folder in enumerate(subfolders): #print (folder, str(class_index)) images = [f for f in os.listdir(os.path.join(root,folder)) if f.endswith('.png')] item_count = len(images) #shuffle images shuffle(images) training_count = item_count * training_ratio test_count = item_count - training_count #create a label for i, img in enumerate(images): if i < training_count: training_label.write('{0}{1} {2}rn'.format(folder, img, class_index)) else: testing_label.write('{0}{1} {2}rn'.format(folder, img, class_index)) #print some info #print ('{0}: item #{1} processed'.format(folder, i)) training_label.close() testing_label.close() |
امیدوارم مفید بوده باشه و در پناه خداوند همیشه موفق و سربلند باشید
سید حسین حسن پور ۹ آبان ۱۳۹۵
نکات :
نکته ۱: در پوشه
datamnist در آخرین ورژن کفی یک اسکریپت برای دانلود دیتاست mnist قرار داده شده که از آون میشه برای دانلود دیتاست استفاده کرد.
نکته ای که باید بدونید این هست که اگر از این اسکریپت برای دانلود دیتاست استفاده کنید لازم هست در پوشه mnist هم از اسکریپت پاورشل مربوطه برای ایجاد دیتاست استفاده کنید چون وقتی که فایلهای mnist دانلود شدن و از حالت فشرده خارج شدند. فایلها به فرم
train-images.idx3-ubyte هستن. این فرمت در زمانی که خود شما بصورت دستی فایلهای مربوطه رو دانلود و اکسترکت کنید هم وجود داره.
اما در اسکریپتی که من نوشتم این مساله وجود نداره . بنابر این پیشنهاد من استفاده از اسکریپت هایی هست که من نوشتم تا با مشکلی مواجه نشید.
با تشکر از آقای پازوکی که یادآوری کردن این نکته رو.
نکته دوم : در زمان ایجاد لیست لیبل های ترین و تست اگر در ویندوز هستید از استفاده کنید تا به خطا نخورید. اگر در لینوکس هستید که از همون / میتونید استفاده کنید.(منظور در اسکریپت پایتونی هست که بالا برای همین کار نوشتم)
نکته سوم :لینک مربوط ورژن قدیمی برنچ ویندوز (مربوط به بیش از یکسال پیش_جهت ارجاعات آینده)
بروز رسانی اول :
تغییرات مربوط به آخرین بیلد کفی(Caffe 1.0) در آموزش بالا اعمال شد :
۱٫تغییر مسیر
BuildX64Release به
buildinstallbin
آموزش خیلی خوبی بود ….
خدا قوت
فقط یه سوالی اینکه از چه تبدیلی برلی کانورت تصویر به دیتا استفاده میشه! منظورم اینه که در این فایل .exe از چه متدی برای این تبدیل استفاده میشه ؟
خواهش میکنم
میتونید خیلی راحت کد مربوطه رو ببنید چیز خاصی نداره . تصاویر در قالب بایت ذخیره میشن و عمل ذخیره سازی هم خیلی ساده فراخونی توابع (api) مربوط به lmdb یا leveldb هست.
اگر کسی بخواد خودش هم میتونه با پایتون بعنوان مثال این کارو انجام بده .
تو فایل train_label.txt باید نام تمامی عکس ها وارد شود؟ مثلا اگه از horse ده تا عکس داریم باید تک تک اونا رو وارد کنیم؟
با تشکر
بله نام تمام تصاویر رو باید وارد کنید. در اصل از طریق این نامها تصاویر پیدا میشن و لود و بعد در دیتاست ذخیره میشن.
یادتون هم باشه shuffle رو انجام بدید.
ایا باید پسوند تمام عکسها در پوشه ها یکسان باشد؟ مثلا همه png یا jpg باشد یا مختلف؟
ترجیحا تا جایی که ممکنه سعی کنید تمام تصاویر از یک فرمت باشن اما اگر نباشن مشکل انچنانی نباید داشته باشید در اموزش.(دقت کنید عدم یکی بودن فرمت تصاویر در عملیاتهای پیش پردازش اینده مشکل ایجاد میکنه و خیلی بهتره بعد از اینکه تصاویر رو جمع کردید با استفاده از یه نرم افزار (یا اینکه خودتون کدش رو بزنید تو متلب یا پایتون و…) تصاویر رو به یه فرمت واحد در بیارید و بعد استفاده کنید. )
سلام
در هنگام تولید دیتاست lmdb به خطای system entropy not available, using fallback algorithm to generate seed instead بر میخورم. برای حل آن چه راه حلی وجود دارد؟
اون مشکلی ایجاد نمیکنه. و خطا نیست. چک کنید دیتاست ایجاد شده یا نه . اگر نشده خطا چیز دیگه ای هست.
سلام
دو تا فایل data.mdb و lock.mdb با حجم ۱mb و ۸kb ساخته.
البته a total of 0 image نیز جزو خطاها است
ممنون از راهنمایی هاتون
خواهش میکنم .
ببینید برای اینکه بشه راهنمایی کرد باید کل پیام ها رو نمایش بدید . قبلا هم عرض کردم چیزایی که تو صفحه میبنید الزاما خطا نیستن. اینکه خطا هستن یا نه وقتی مشخص میشه که شما کل پیامهایی که رو صفحه در حین عملیات مشاهده میکنید رو لطف کنید و ارائه کنید.
سلام و خسته نباشید
دیتا بیس من بزرگ هست
چطور میتونم با متلب یا … همه رو به یک فرمت دربیارم
چون دستس کار طاقت فرسایی هست.
ممنون
سلام
من متوجه نشدم منظورتون رو !
بیشتر کارهای بالا مربوط به اماده سازی تصاویر و برچسب های اونهاس.
اگه منظورتون اینه ، شما میتونید این بخش رو با متلب پیش ببرید
سلام
منظورم اینه که فرمودید سعی بشه تمام عکسها یه فرمت داشته باشند، مثلا همهjpg باشند
از تونجایی که دیتا بیس من بزرگه و البته تعداد کلاسها نیز زیاد هستند میخوام دستی فرمت رو یکسان نکنم
با متلب میشه کدشو زد؟ راهی هست
ممنون
سلام
بله به پایتون هست به متلب هم باید باشه و مشکلی نداشته باشید
کافیه یه سرچ ساده کنید
با سلام و خسته نباشید…
من فولدرهامو طبق صحبت های شما درست کردم اما خطا زیر را می دهد
the procedure entry point
??۰FlagRegistere @google@@QEAA Could not be located in the dynamic link library
سلام. خطای شما بخاطر ست نبودن dependency های شماس. کتابخونه هایی که بیلد کردید رو به path اضافه کنید که این مشکلتون برطرف بشه.
لطفا این سوال رو تو سایت پرش و پاسخ بپرسیدhttp://qa.deeplearning.ir/
با سلام
من دیتاست از تصاویر دارم که همه در یک فولدر هستند ولی دو فایل train.txt و test.txt رو با ادرس دهی کامل درست کردم ولی زمانی که می خواهم از convert_imageset.exe استفاده کنم هیچ دیتابیسی ساخته نمیشه!؟
این دستور و خروجی که اجرا می کنم هست:
D:\Software Instaltion\caffe-windows\caffe-windows\build\tools\Release>convert_imageset.exe –shuffle fei_train.txt fei_lmbd
convert_imageset.exe: Convert a set of images to the leveldb/lmdb
format used as input for Caffe.
Usage:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
The ImageNet dataset for the training demo is at
http://www.image-net.org/download-images
No modules matched: use -help
سلام دستور رو درست نمیزنید. یکبار دیگه خوب به مثالی که زدم توجه کنید و ارگومانهای مورد نیاز رو بفرستید. شما پوشه تصاویر رو بعد از دستور shuffle جا انداختید و یکسره لیبلها رو دادید .
سلام این بار این خطا رو بهم میده زمانی که دستور زیر رو میزنم
convert_imageset.exe –shuffle D:\Datasets\Accepted\FEI\All fei_train.txt fei_lmbd
I0310 14:59:15.695531 7664 convert_imageset.cpp:86] Shuffling data
I0310 14:59:16.612352 7664 common.cpp:36] System entropy source not available, using fallback algorithm to generate seed instead.
I0310 14:59:16.613373 7664 common.cpp:36] System entropy source not available, using fallback algorithm to generate seed instead.
I0310 14:59:16.614357 7664 convert_imageset.cpp:89] A total of 0 images.
F0310 14:59:16.614357 7664 db_lmdb.cpp:18] Check failed: _mkdir(source.c_str()) == 0 (-1 vs. 0) mkdir Detection failed
*** Check failure stack trace: ***
The system cannot find the path specified.
به مسیرتون گیر داده . دو نکته رو همیشه رعایت کنید.
۱٫اول چک کنید از مرحله قبل که اسکریپت رو ران کردید پوشه یا فایل جدیدی ایجاد نشده باشه اگه شده پاکش کنید.
۲٫بجای \ از / برای مسیرها استفاده کنید. مثلا
D:\DataSets\Accepted\FEI\All رو بصورت D:/DataSets/Accepted/FEI/All بدید.
ممنون از کمک شما بلاخره انجام شد یه نکته دیگر علاوه بر مواردی که دوست خوبمون آقای کلایی در مورد مسیرها گفتند اینکه نباید مسیری که دیتا بیس در آن قرار دارد حاوی کاراکتر فاصله باشد یعنی مثلا بجای
D:/Data Sets باید به صورت D:/DataSets باشد.
خواهش میکنم . من حسن پور هستم (متی کلایی پسوند اسم بنده اس 🙂 )
سلام
من هم مشکل اقای کیانی دارم و راه حل های گفته شده متاسفانه کار ساز نیس و ارور System entropy source not available رو دو بار میده . بعد فولدر دیتاست رو تو فولدر EXAMPLE ایجاد میکنه و سر سه تا عکس گیر میده که پیداش نمیکنم. در صورتی که هم تو فایل عکسا هست هم درست توی فایل تکست نوشته شده ( چند بار چک کردم). ادرس دهی هم درسته. بدون کاراکتر فاصله است و از / استفاده کردم. نمیدونم چرا برای این سه تا عکس به مشکل بر میخوره. مثل سایر عکسا درست و دقیق نوشته شده. ارور مربوطه: COULD NOT OPEN OR FIND *.JPG LABLE
که بجای ستاره اسم عکس هست و به جای لیبل هم یک عدد
مشکل از کجاست به نظر شما؟
سلام. پیام system entropy source … خطا نیست و دریافتش مشکلی ایجاد نمیکنه.
اون تصاویری که میگه مشکل داره رو حذف کنید ببینید فرایند بدرستی تا انتهای پیش میره یا خیر. اگه رفت مشکل از تصاویر شماست (یا اسمش یا خود تصویر ممکنه مشکل دار شده باشه )
هر زمان خطایی میگیرید عین خود خطا رو قید کنید و سعی کنید تو سایت پرسش و پاسخ بپرسید و گامهایی که طی کردید و دستوراتی که اجرا کردید همه رو بگید . کلی گویی کمک زیادی نمیکنه
مشکلم حل شد. دوستان توجه کنید که بعد از لیبل ها هم نباید هیچ گونه فاصله ای باشه. بر فرض مثال خط زیر را توجه کنید :
/۱/۰۰۱٫۱_Left_Down.JPG 1
بعد از ۱ که لیبل هست هیچگونه فاصله ای قرار ندید. من سهوا دستم خورده بود و بعضیاشون بعد از لیبل یک کاراکتر فاصله داشتند.
و من فکر میکردم که فقط تا قبل از لیبل مهمه
باسلام
در کدهایی که برای تبدیل دیتاست mnist به فرمت lmdb ارايه شده، در نام فایل های دانلود شده بصورت زیپ قبل از idx ها علامت منها هست وپس از extract قبل از idx علامت دات میشود که در صورتیکه این تغییر را اعمال نکنیدومستقیما دستورات بالا را کپی کنید، خطا میدهد.
با تشکر
سلام .
خیلی ممنون . به نکته خوبی اشاره کردید . درسته. من این نکته رو فراموش کردم تو متن وارد کنم.(ورژن اولیه اسکریپت دانلود نقاط رو به – تبدیل میکرد برای همین کدهای دیگه بر همین اساس کار میکنن (در برنچ من))
توضیح به متن اضافه شد.
سلام
من میخوام در داخل فایل متنی مشخصات عکسهام وارد کنم مثلا
img1 1
img2 2
مشکل من اینه که چون تعداد عکسهام زیاده نمیخوام دستی وارد کنم.البته باید رندم هم باشه. با متلب هم نتونستم
کسی میدونه چطوری باید انجام بدم؟
ممنون
سلام . من که دقیقا آموزش همین رو در پرسش و پاسخ دادم ! نباید هیچ مشکلی داشته باشید شما!
مشکل من ساخت فایل txt به صورت خودکار است.مثلا من ۳۲ تا کلاس دارم و ۳۲ پوشه .میخوام برنامه بره مسیر پوشه ها رو بخونه و به صورت تصادفی اسم عکسها رو باتوجه به پوشه ای ک قرار داره توی فایل متنی بنویسه .
سلام .
شما اصلا نیازی ندارید که اسمهای هر کلاس رو تصادفی انتخاب کنید! کافیه مسیر هر عکس با لیبلش مشخص بشه . اگه برنامه نویسی سخته براتون بصورت زیر هم برید خوبه .
شما یه پوشه میسازید مثلا با نام mydataset در داخل این پوشه ۳۲ پوشه دیگه میسازید که مربوط به کلاسهای مختلف شماست. هر کلاس هم عکسهای خودشو داره .
حالا کافیه شما مسیر پوشه mydataset رو بگیرید و سرچ کنید هرچندتا پوشه هست پیدا کنید. اسامی پوشه ها رو بریزید تو یه لیست مثلا. حالا یه loop بزنید داخل این پوشه ها، و نام تصاویر هرکدوم رو بخونید (بصورت esme_poshe_classe_morede_nazar\esme_tasvir ) و برای لیبل هم میتونید مثلا از ۰ شروع کنید برای فولدر اول و هربار یکی افزایشش بدید.
بعد فایل رو سیو کنید. تو مرحله بعد هم میتونید مثلا از atom یا sublime استفاده کنید فایل مربوط به رو باز کنید بعد از منو shuffle کنید بعدش یه مقدار رو برای ترینینگ بگیرید و یک مقدار رو برای تست . اینکارو برای بقیه انجام بدید و نهایتا فایلها رو ترکیب کنید که یک فایل واحد بشه .البته اینو هم دوست داشته باشید با برنامه نویسی میتونید انجام بدید.
(اگر هم همه تصاویر هم نام هستن. خیلی راحت با یه لوپ خودتون فایل رو بسازید . بجای اینکه نام تصاویر رو بدید (مثلا بدید img1.png 1 مسیر نسبی رو بدید . مثلا بدید class1\img1.png 1 ) اینم میتونید انجام بدید)
ممنون.اینloop زدن رو نفهمیدم یعنی چی؟
حلقه for منظور هست؟
هر پوشه ۷۰ عکس هست.
for i=1:1: 70
لوپ منظور for یا while هست. این دیگه یه مثال ساده برنامه نویسی هست . روش فکر کنیدامکان نداره یک همچین چیزی رو کسی نتونه بنویسه .
نیازی هم نیست حتما به پایتون بنویسید به هر زبانی که تسلط دارید برید کدشو بزنید
ممنون
با سلام
من میخوام داده هاو رو به فرمت lmdb ببرم اما با این ارور مواجه میشم ::
*** Check failure stack trace: ***
@ ۰x7fb26b5ea5cd google::LogMessage::Fail()
@ ۰x7fb26b5ec433 google::LogMessage::SendToLog()
@ ۰x7fb26b5ea15b google::LogMessage::Flush()
@ ۰x7fb26b5ece1e google::LogMessageFatal::~LogMessageFatal()
@ ۰x7fb26bb19468 caffe::db::LMDB::Open()
@ ۰x403aaf main
@ ۰x7fb26a55b830 __libc_start_main
@ ۰x404b59 _start
@ (nil) (unknown)
Aborted (core dumped)
نمیدونم کجاش مشکلی داره. ممنون میشم اگه راهنمایی کنید
سلام . این که نشد. شما در سایت پرسش و پاسخ متن کامل خطا رو قرار بدید و بگید چه گامهایی رو برداشتید تا بشه بهتون کمک کرد.
این دو خط چیکار میکنن؟
training_label.write(‘{0}\{1} {2}\n\r’.format(folder, img, class_index))
else:
testing_label.write(‘{0}\{1} {2}\n\r’.format(folder, img, class_index))
سلام
کار اینها ایجاد فایلهای لیبل هست که در هر سطرش مسیر یک تصویر با لیبل مورد نظرش رو قرار میدن و به سطر بعد میرن.
مسیر هم اینطور مشخص میشه بجای {۰} اسم پوشه میاد بعد یه \ و بعد هم اسم تصویر میاد و نهایتا یک اسپیش و بعدش هم که بجای {۲} لیبل مورد نظر قرار میگیره .
هر جا نمیدونید که کد چیکار میکنه میتونید از دیباگ استفاده کنید یا اینکه خیلی ساده از یه دستور print() استفاده کنید و محتویاتش رو پرینت کنید.
خیلی آموزش کامل و مفیدی بود خیلی ممنونم. ان شاالله همیشه موفق باشید.
سلام
خواهش میکنم
در پناه خداوند انشاءالله شما هم موفق و سربلند باشید
سلام
مطالبتون بسیار آموزنده هست و کاربردی.
سوال من در مورد LMDB هست. من ۸۰۰۰۰ هزار تصویر دارم که خودم تهیه کردم.
۱) در کفه نیازی نیست که فایل تکستی تهیه بشه و نام تصاویر در آنها نوشته بشه ؟ یا خود تصاویر درون فولدر کافی هست؟
۲) اگر بخواهیم ۸۰۰۰۰ تصویر ۵۰۰۰۰ برای آموزش و ۲۰۰۰۰ برای ولیدیشن و ۱۰۰۰۰ برای تست باشه چیکار باید کرد؟ فکر کنم فرمودید مدل دوم که خودش اتوماتیک ۷۰ درصد برای آموزش میزاره و ۳۰ درصد هم برای آزمون همین مورد باید باشه؟
۳) کدوم مورد استاندارد تر هست (۱) تدرست کردن دو فولدر آموزش و آزمون (۲) تهیه یک فولدر شامل تمامی تصاویر و به صورت اتوماتیک؟ البته من با مدل اول را بهتر ترجیح میدم.
۴) دقیقا بفرمایید خروجی LMDB چیست؟
۵) برای نوشتن کد آیا همین قسمت کافی هست ؟
from random import shuffle
import os
root = ‘G:/hossein/data/cifar10/data_train_and_test/’
# lets get all the sub-directories first
subfolders = [name for name in os.listdir(root) if os.path.isdir(os.path.join(root,name)) ]
#specify training/validation ratio
training_ratio = 0.7
# files for training and validation(testing) labels
training_label = open(os.path.join(root,’labels_train.txt’),’a+’)
testing_label = open(os.path.join(root,’labels_test.txt’),’a+’)
# now lets enter each folder and read their images and populate our label file
for class_index ,folder in enumerate(subfolders):
#print (folder, str(class_index))
images = [f for f in os.listdir(os.path.join(root,folder)) if f.endswith(‘.png’)]
item_count = len(images)
#shuffle images
shuffle(images)
training_count = item_count * training_ratio
test_count = item_count – training_count
#create a label
for i, img in enumerate(images):
if i < training_count:
training_label.write('{0}\{1} {2}\r\n'.format(folder, img, class_index))
else:
testing_label.write('{0}\{1} {2}\r\n'.format(folder, img, class_index))
#print some info
#print ('{0}: item #{1} processed'.format(folder, i))
training_label.close()
testing_label.close()
یا باید این قسمت ها قبل از این کد اضاف شود ؟تعریف لیبل برای دیتاستShell
۱
۲
۳
۴
۵
horse/lippizaner_s_001297.png 2
airplane/fighter_aircraft_s_000924.png 0
ship/container_ship_s_002089.png 1
dog/chihuahua_s_000780.png 4
cat/domestic_cat_s_001116.png 3
/convert_imageset –resize_height=٪RESIZE_HEIGHT٪ –resize_width=٪RESIZE_WIDTH٪ –shuffle ٪TRAIN_DATA_ROOT٪ ٪TRAIN_DATA_ROOT٪/train_label.txt ٪MyDataSet٪/mydataset_train_lmdb
convert_imageset.exe –resize_height=32 –resize_width=32 –shuffle E:/DeepLearning.ir/MyDataSet/train E:/DeepLearning.ir/MyDataSet/train/train_label.txt mydataset_train_lmdb
۱
build/x64/Release/convert_imageset.exe –resize_height=32 –resize_width=32 –shuffle Examples/MyDataSet/train Examples/MyDataSet/train/train.txt Examples/MyDataSet/mydataset_train_lmdb
سلام . نه نیازی نیست . میشه براحتی با یک زبان برنامه نویسی لیست مورد نظر رو ایجاد کرد. یک برنامه ساده هم من اینجا به پایتون نوشتم که میتونید برای کار خودتون تغییرش بدید
بهترین کار اینه که اول یک لیست از تمام تصاویر مشخص بشه. اگه ماهیت تصاویر یکی هست بله میشه از همین طریق براحتی درصدها رو مشخص کرد. اما اگه در تصاویرتون دسته های مختلفی دارید
اول سعی کنید از هر دسته این رنج رو جدا کنید بعد ترین رو جداو تست رو جدا با هم ترکیب کنید. و بعد اینکه ترکیب شد میتونید شافل کنید و در ال ام دی بی ذخیره کنید
مهم پوشه نیست مهم اون لیستی هست که میسازید . حالا اینکه چطور مدیریت میخوایید بکنید با خودتونه . من خودم ترجیم یک فولدره که همه تصاویر در اون باشه. اگه دیتاست شما دسته های مختلفی داره (فرض کنید شما دوتا کلاس دارید که میخوایید دسته بندی کنید
اما همین دوتا کلاس خودشون انواع مختلف دارن مثلا سگ و گربه دوتا کلاس هستن. اما نژاد های مختلف سگ و گربه دارید . ) خیلی بهتره برای هر کلاس یک فولدرجداگانه در نظر بگیرید. سگ جدا گربه جدا و در داخل اینها هم هر دسته فولدر خودشو داشته باشه . اینطوری دستتون خیلی بازتره و اجازه تفکیک بیشتری دارید
lmdb یه دیتابیس هست خروجی خاصی نداره.
این اسکریپت فقط برای ایجاد لیست تصاویر هست که بعدا ازش برای ایجاد دیتاست lmdb استفاده کنید. لطفا یکبار دیگه خوب اموزش رو مطالعه کنید متوجه میشید
سلام من برنامه رو اجرا کردم و دو تا فایل به نام های data.mdb و lock.mdb ساخته . حالا اینارو چه جوری استفاده کنم ؟
من میخوام از faster r-cnn استفاده کنم :
https://github.com/rbgirshick/py-faster-rcnn
حالا چه جوری دیتابیس رو استفاده کنم برای faster r-cnn ؟؟
سلام . لطفا اموزش های کفی رو مطالعه کنید.
برای استفاده از دیتاست lmdb در کفی از لایه Data استفاده میشه.
سلام
ببخشید شما بیشتر درمورد ورودی هایی صحبت کردید که به صورت تصویر هستن، اگر ورودی به صورت داده باشه چی،؟ من داده هام در متلب باز میشن چجوری اونا رو تبدیل به CSV فایل کنم؟؟
سلام .
یعنی چی به چه صورتی؟
من داده هام پسون متلب دارن ، حالا بخوام در پایتون برنامه بنویسم، همین فایل متلب رو بهش بدم اوکی هست یا اینکه باید تبدیلش کنم به csv فایل؟؟
سلام
خیلی گنگه فرمایش شما .
فایل متلب یعنی چی ؟
ببینید شما یک سری تصویر باید داشته باشید و یکسری برچسب که ما بهش میگیم label
تصاویر ممکنه بصورت معمول و عادی باشن تو یک پوشه جداگانه
بعضی موارد هم ممکنه تصاویر در قالب بایت ذخیره شده باشن بصورت باینری
که در اصل کار تفاوتی ایجاد نمیکنه فقط نحوه خوندن متفاوت میشه و در مورد حالت دوم عموما مشخصات ساختار داده ای که تصاویر در اون ذخیره شدن هم بیان میشه تا فرد بدونه چطور باید چیزی رو بخونه .
فایلهای csv عموما حاوی برچسب ها یا اطلاعات کلی تصاویر هستن که فرد میتونه یک قلم یا تعداد بیشتری قلم داده از اون برای کارش استخراج کنه.
در مورد اینکه فایل متلب رو به پایتون بدید کار میکنه یا نه بستگی به فایل داره .
ولی شما باید بتونید همین کد رو براحتی به متلب ترجمه کنید الزامی نیست که حتما همین کد رو اجرا کنید .
سلام، خسته نباشید
من ۱۲۷ تا سمپل با لیبل های مجزا دارم،که هرکدوم از این سمپل ها، یک ماتریس سطری(یک سطر و ۱۲۰۰۰۰۰۰۰ستون)هست که من میخوام هرکدوم از این ماتریس ها را به ۱۲۰ تا دسته ۱۰۰۰۰۰۰ تایی تقسیم کنم و بعد از هر دسته fft بگیره و تصویر خروجی از هر دسته رو در یک فولدر برای من ذخیره کنه،که درواقع بعد از اینکه یک مجموعه از تصاویر بدست اوردم شروع به classify کردن کنم، حالا این رو با استفاده از کراس و تنسورفلو چجوری بنویسم؟؟
خیلی لطف میکنید اگر در نوشتن این برنامه کمکم کنید.
با احترام
سلام
من الان ۱۵۲۴۰ تا ماتریس ۱ در ۱۰۰۰ دارم، حالامن میخوام که اینها رو به عنوان ورودی بدم به ۱d cnn، خوب فکر میکنم باید ابتدا داده های ترین و تست جدا بشه و بعد داده های ترین رو بدیم به مدلمون، لطف میکنید در این مورد راهنمایی بفرماییدکه چجوری این مراحل رو در پایتون انجام بدم ، خیلی به راهنمایی شما نیاز دارم اقای کلایی.
با احترام
سلام
جداسازی داده ترین از تست که مشخصه! قبلا یک نمونه کد در انتهای آموزش تبدیل بهlmdb در کفی قرار داده بودم و لینک هم خدمت شما دادم.
ببینید شما کافیه بصورت رندوم به تعدادی که نمونه برای فاز ازمایشی نیاز دارید سطر از اون ماتریس بخونید و به لیست ترینینگتون اضافه کنید این رو هم میتونید خیلی ساده با یک حلقه for در پایتون انجام بدید
برای رندوم کردن هم میتونید از روشهای مختلفی استفاده کنید میتونید هم از shuffle() در پایتون استفاده کنید و اگه دیتای شما در قالب یک لیست هست اونجا سطرها رو شافل کنید و بعد خیلی معمولی در یک حلقه for مثلا به تعداد ۱۴۰۰۰ نمونه بخونید بزارید برای ترینینگ ست و بقیه اش هرچی موند بزارید برای تست ست (که اگه به کدی که من قبلا ارجاع دادم نگاه کنید میتونید ایده بگیرید )
اگر هم از شافل استفاده نمیکنید میتونید خیلی راحت هر بار یک عدد به تصادف انتخاب کنید و سطر مربوطه (اگه قبلا انتخاب نشده باشه ) رو در ترینینگ ست بزارید و به همین صورت پیش برید
ضمنا بنده حسن پور هستم
ممنون از راهنمایی اقای حسن پور
در مورد قسمت cnn یک بعدی چی؟ یک نمونه مثال ممکنه برام بفرستید که ورودی سیگنال گرفته باشه و classify انجام داده، تو اینترنت اینقدر ۱d cnn، سرچ کردم و همشون رو بالا پایین کردم که گیج شدم، اگر لطف کنید فقط یک نمونه مثال برام در این مورد هم بفرستید ممنون میشم
سلام
شما باید conv1d رو سرچ میکردید .
به هر حال هم در صفحه توضیحات خود تنسورفلو اومده توضیحات conv1d و هم اینجا یک مثال و توضیحات بیشتر داده شده و میتونید چک کنید :
https://stackoverflow.com/questions/38114534/basic-1d-convolution-in-tensorflow
ببخشید من از نمونه برنامه ای که برای جدا کردن داده های ترین و تست گذاشتید رو متوجه نمیشم، دیتاست من به صورت ماتریس های ۱در ۱۰۰۰ هستن و ۱۵۲۴۰ تا از این ماتریس ها دارم، ممکنه لطف کنید راهنمایی بفرمایید که چجوری جدا کنم و به عنوان داده ورودی مدلم تعریف کنم؟
این یک قسمت از برنامه هست:fft_array_full، همون دیتاست من هست
# Combine the feature_arrays for all the 127 files. The resultant array will be 120*127 rows.
fft_array_full = np.append(fft_array_full, FFT_array, axis=0)
#specify training/validation ratio
training_ratio = 0.7
total_set = len(fft_array_full)
X_train = total_set * training_ratio
X_test = total_set – X_train
X_train = X_train.reshape(X_train.shape[0], 1, 1000).astype(‘float32’)
X_test = X_test.reshape(X_test.shape[0], 1, 1000).astype(‘float32’)
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
سلام خسته نباشید
تشکر از آموزش عالیتون
من دیتاست ها رو همونطور که توضیح دادین ایجاد کردم همینطور سالور و نت رو نوشتم و گذاشتم واسه تست بعد حدودا ده دقیقه بدون این که خطایی در cmd بده از کافه خارج میشه یعنی مینویسه caffe exe has stopped working و اینکه توی ویندوز ۱۰ من کامپایل کردم
ممنون از توجهتون
سلام.
لاگ رو تماما قرار بدید تا بشه نظر بهتری داد.
سلام
من یک دیتاست متشکل از ۱۰۰۰۰ تصویر گربه و سگ دارم و می خوام این دیتاست به فرمت HDF5 یا CSV تبدیل کنم,میشه بگین چطور باید این کار انجام بدم؟
سلام.
فرمت CSV که چیزی جز نام تصاویر نیست عموما بایدببینید فریم ورک مورد نظر شما ورودی رو به چه صورتی دریافت میکنه تا بعدش بتونید دیتاست رو بسازید. کار با csv هم مثل فایل ساده است و نکته خاصی نداره.
در مورد HDF5 هم میتونید اینجا رو ببینید
با سلام و خسته نباشید.
فایل convert_imageset.exe رو از کجا میشه دان کرد؟
من کارم کفه نیست و برای ترین کردن نیاز به فرمت lmdb و فایل convert_imageset.exe دارم. ممنون میشم راهنمایی کنید.
سلام
میتونید از اینجا نسخه از پیش کامپایل شده کفی رو دانلود کنید و داخل اون فایل مورد نظر رو پیدا و استفاده کنید.
ممنون ولی اون یه فایل cpp هستش. فایل exe نیست…
دقت نکردید عرض کردم از اون صفحه “نسخه از پیش کامپایل شده” رو دانلود کنید.
توضیحات پایین صفحه به فارسی و لینک دانلود هم مشخصه کاملا
حل شد آقا
خدا خیرت بده