
بسم الله الرحمن الرحیم
در این بخش ما سعی میکنیم تا یک شبکه (شبکه MNIST) را از ابتدا تا انتها ایجاد کرده و ببینیم چگونه میتوان با استفاده از Caffe این کار را انجام داد.
مواردی مثل آماده سازی داده ها توسط خود ما برای داده های جدید(یعنی چطوری یه دیتابیس از تصاویر خودمون بسازیم و…) انشاالله در یک پست دیگه توضیح میدم.
آماده سازی داده ها :
قبل از اینکه به سراغ تعریف لایه ها برویم , برای تسریع فرآیند آموزش, ما داده های خود را به فرمت lmdb تبدیل میکنیم . برای اینکار کافیست دستورات زیر را اجرا کنید :
دانلود و دریافت دیتاست MNIST در لینوکس (در ورژن ویندوز اون هم فقط پسوند عوض میشه. البته ورژن رسمی Caffe مثالها به ویندوز رو نداره اما من قبلا تبدیل کردم و میتونید از برنچ من اینجا معادلها رو بگیرید)
|
1 2 3 4 |
./data/mnist/get_mnist.sh ./examples/mnist/ create_mnist-lmdb.sh |
فایل های فوق را میتوان از سورس کد Caffe با آدرس های داده شده یافته و اجرا نمود.
تعریف Data Layer
در اینجا ما سعی میکنیم تا داده ها را از دیتابیس lmdb که در مرحله قبل آن را ایجاد کردیم بخوانیم. عمل خواندن را در لایه داده انجام به اینصورت انجام میشود:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
layer { name: “mnist” type: “Data” data_param { source: “mnist_train_lmdb” backend: LMDB batch_size: 64 scale: 0.00390625 } top: “data” top: “label” } |
در لایه بالا, اسم این لایه mnist بوده و از نوع Data میباشد. ما در بخش data_param , اطلاعات مورد نیاز این لایه را وارد میکنیم .
پارامتر :Source : این پارامتر مسیر پوشه (دایرکتوری ) حاوی داده هایی که باید خوانده شوند را مشخص میکند.
پارامتر backend : مشخص کننده نوع دیتابیسی است که ما از آن اطلاعات خود را میخوانیم
پارامتر batch_size : عددی که در این بخش مشخص میکنیم نشانگر ظرفیت دسته هاست. به این معنا که تصاویر در دسته های ۶۴ تایی پردازش میشوند.
پارامتر scale : این پارامتر هم مقادیر ورودی را به اعدادی در رنج [۰,۱) تبدیل میکند. چرا از ۰٫۰۰۳۹۰۶۲۵ استفاده کردیم ؟ این عدد از تقسیم عدد ۱ بر ۲۵۵ بدست می آید. (چون تصاویر mnist تصاویر سیاه و سفید هستند مقادیر پیکسلی آنها مقداری بین ۰ تا ۲۵۵ دارد. بنابر این با تقسیم ۱ بر ۲۵۵ عددی بدست می آید که در صورت ضرب هر مقدار در آن مقدار متناظر آن در گستره [۰,۱) بدست می آید. )
و در انتها نیز پارامتر top مشخص میکند که خروجی این لایه دو blob با نامهای data و label هستند.
تعریف لایه Convolution
حالا به تعریف لایه کانولوشن میپردازیم که بعد از لایه دیتا قرار میگیرد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
layer { name: "conv1" type: "Convolution" param { lr_mult: 1 } param { lr_mult: 2 } convolution_param { num_output: 20 kernel_size: 5 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" } } bottom: "data" top: "conv1" } |
در اینجا ما از ذکر پارامترهایی که در بخش قبل توضیح داده شدند صرفنظر میکنیم و فقط به توضیح پارامترهای جدید میپردازیم .
این لایه blob داده را از لایه داده دریافت میکند و blob conv1 را تولید میکند. این لایه ۲۰ کانال (فیلتر) تولید کرده و اندازه کرنل آن برابر با ۵ است که با stride =1 بر روی ورودی اعمال میشود.
filler ها بماکمک میکنند تا بتوانیم مقادیر وزنها و بایاس ها را بصورت تصادفی مقداردهی اولیه کنیم. برای weight filler ما از الگوریتم Xavier استفاده میکنیم که بصورت خودکار مقیاس مقداردهی اولیه را مبتنی بر تعداد نورون های ورودی و خروجی مشخص میکند. برای bias filler هم ما خیلی ساده آنرا بعنوان یک ثابت (constant) با مقدار filling پیشفرض ۰ مقداردهی اولیه میکنیم.
lr_mult ها هم تنظیمات مربوط به نرخ یادگیری (learning rate) هستند که برای پارامترهای قابل یادگیری لایه مورد استفاده قرار میگیرند. در اینجا, ما نرخ یادگیری وزن را برابر نرخ یادگیری ارائه شده توسط solver در زمان اجرا قرار میدهیم و نرخ یادگیری بایاس را هم دوبرابر آن تنظیم میکنیم . این کار معمولا باعث نرخ همگرایی بهتر میشود.
تعریف لایه Pooling
تعریف این لایه هم بصورت زیر است
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
layer { name: "pool1" type: "Pooling" pooling_param { kernel_size: 2 stride: 2 pool: MAX } bottom: "conv1" top: "pool1" } |
در اینجا میبینیم که ما عملیات max pooling را با تنظیم پارامتر pool:Max انجام خواهیم داد و اندازه کرنل هم برابر با ۲*۲ بوده که با stride =2 بر روی ورودی اعمال میشود. (با این stride هیچ اشتراکی (overlapping بین پیکسل های همسایه ناحیه های pooling وجود نخواهد داشت)/
به همین شکل , ما لایه های کانولوشن و pooling بعدی را میتوانیم طراحی کنیم .
تعریف لایه تماما متصل
این لایه هم همانند لایه های قبلی بصورت زیر تعریف میشود :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
layer { name: "ip1" type: "InnerProduct" param { lr_mult: 1 } param { lr_mult: 2 } inner_product_param { num_output: 500 weight_filler { type: "xavier" } bias_filler { type: "constant" } } bottom: "pool2" top: "ip1" } |
تعریف بالا یک لایه تماما متصل را مشخص میکند که در Caffe به لایه InnerProduct معروف است. این لایه ۵۰۰ خروجی داشته و مابقی پارامترها نیز مشابه لایه های قبلی است که توضیح انها داده شد.
تعریف لایه ReLU
یک لایه ReLU بصورت زیر تعریف میشود
|
1 2 3 4 5 6 7 8 |
layer { name: "relu1" type: "ReLU" bottom: "ip1" top: "ip1" } |
از آنجایی که ReLU یک عملیات مولفه محور است (element-wise) , بنابر این ما میتوانیم عملیات را بصورت درجا انجام داده تا در مصرف حافظه صرفه جویی کنیم . این کار با تعریف یک نام برای blob های بالایی و پایینی (همانطور که در تعریف بالا انجام شده است ) قابل انجام است. لطفا دقت کنید که شما نمیتوانید از نامهای یکسان برای blob ها در سایر لایه ها استفاده کنید و این کار مختص این لایه است.
بعد از لایه ReLU ما یک لایه تماما متصل دیگر تعریف میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
layer { name: "ip2" type: "InnerProduct" param { lr_mult: 1 } param { lr_mult: 2 } inner_product_param { num_output: 10 weight_filler { type: "xavier" } bias_filler { type: "constant" } } bottom: "ip1" top: "ip2" } |
و نهایتا لایه Loss را بصورت زیر تعریف میکنیم
|
1 2 3 4 5 6 7 8 |
layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip2" bottom: "label" } |
لایه softmax_loss هم softmax و هم multinomial logistic loss را (که نسبت به مورد اول از لحاظ زمانی و پایداری عددی (numerical stability) بهتر است) را پشتیبانی میکند. این لایه دو blob دریافت کرده که اولی پیشبینی و دومی برچسب ای است که توسط لایه داده تولید میشود است. این لایه هیچ خروجی ای تولید نمیکند . تمام کاری که انجام میدهد محاسبه مقدار تابع خطا , و گزارش آن در زمان شروع عملیات backpropagation و شروع بدست اوردن گرادیانت با توجه به ip2 میباشد.
در انتها هم معماری فوق الذکر بشکل زیر خواهد بود

نکات اضافی
در زمان تعریف مدل یک شبکه, هیچ الزامی برای خطی بودن معماری همانند شکل زیر نیست. بعبارت دیگر میتوان معماری غیرخطی (البته بدون دور) هم داشت :
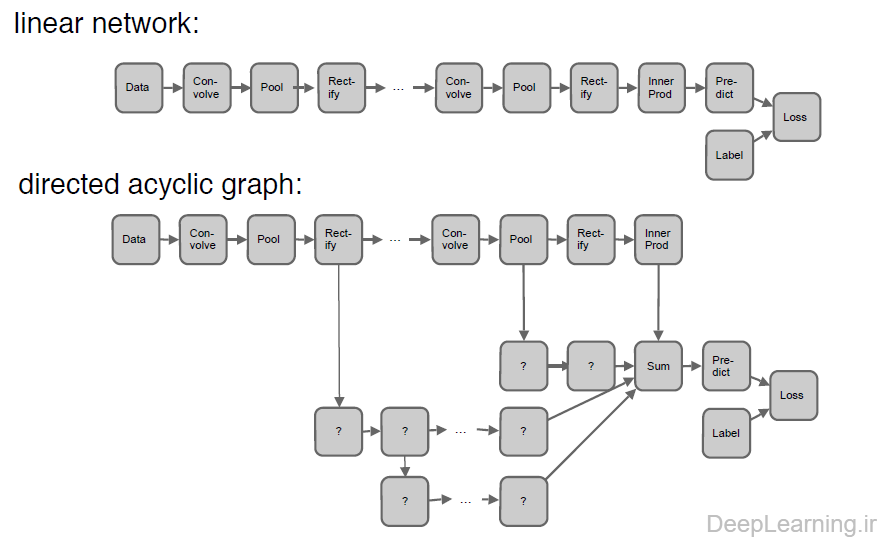
در تعاریف لایه ها میتوان با استفاده از قوانینی مشخص کرد که آیا لایه ای در زمان خاصی فعال باشد یا خیر.
بعنوان مثال, نمونه زیر را در نظر بگیرید :
|
1 2 3 4 5 6 |
layer { // ...layer definition... include: { phase: TRAIN } } |
در نمونه بالا, چیزی که مشاهده میکنید یک قانون است که حضور یک لایه در یک شبکه را بر اساس وضعیت فعلی شبکه کنترل میکند. شما میتوانید به مراجعه به CAFFE_ROOT/src/caffe/proto/caffe.proto$ اطلاعات بیشتری در باره قوانین لایه ها و طرح های مربوط به مدلها بدست بیاورید.
در مثال بالا , این لایه تنها در فاز training (آموزش) به شبکه اضافه خواهد شد. اگر ما TRAIN را با TEST عوض کنیم, این لایه تنها در فاز test مورد استفاده قرار خواهد گرفت. بصورت پیشفرض , یعنی بدون استفاده از قوانین لایه ها, یک لایه همیشه در شبکه حضور خواهد داشت و مورد استفاده قرار خواهد گرفت. بخاطر همین مسئله است که lenet_train_test.prototxt دارای ۲ لایه DATA است (که دارای batch_size های متفاوتی هستند) .یکی از آنها برای فاز training و دیگری برای فاز testing مورد استفاده قرار میگیرد. همچنین اگه به lenet_solver.prototxt نگاه کنید میبینید که یک لایه Accuracy هم وجود دارد که تنها در فاز TEST به منظور گزارش دقت مدل در هر ۱۰۰ تکرار فعال میشود .
نهایتا در زیر مدل کامل MNIST را مشاهده میکنید :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 |
name: "LeNet" layers { name: "mnist" type: DATA top: "data" top: "label" data_param { source: "examples/mnist/mnist_train_lmdb" backend: LMDB batch_size: 64 } transform_param { scale: 0.00390625 } include: { phase: TRAIN } } layers { name: "mnist" type: DATA top: "data" top: "label" data_param { source: "examples/mnist/mnist_test_lmdb" backend: LMDB batch_size: 100 } transform_param { scale: 0.00390625 } include: { phase: TEST } } layers { name: "conv1" type: CONVOLUTION bottom: "data" top: "conv1" blobs_lr: 1 blobs_lr: 2 convolution_param { num_output: 20 kernel_size: 5 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layers { name: "pool1" type: POOLING bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layers { name: "conv2" type: CONVOLUTION bottom: "pool1" top: "conv2" blobs_lr: 1 blobs_lr: 2 convolution_param { num_output: 50 kernel_size: 5 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layers { name: "pool2" type: POOLING bottom: "conv2" top: "pool2" pooling_param { pool: MAX kernel_size: 2 stride: 2 } } layers { name: "ip1" type: INNER_PRODUCT bottom: "pool2" top: "ip1" blobs_lr: 1 blobs_lr: 2 inner_product_param { num_output: 500 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layers { name: "relu1" type: RELU bottom: "ip1" top: "ip1" } layers { name: "ip2" type: INNER_PRODUCT bottom: "ip1" top: "ip2" blobs_lr: 1 blobs_lr: 2 inner_product_param { num_output: 10 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layers { name: "accuracy" type: ACCURACY bottom: "ip2" bottom: "label" top: "accuracy" include: { phase: TEST } } layers { name: "loss" type: SOFTMAX_LOSS bottom: "ip2" bottom: "label" top: "loss" } |
نکته :
الان بجای layers از layer استفاده میشه.(هرچند کد بالا هم براحتی اجرا میشه اما دیگه layers نوشته نمیشه . نوع لایه ها هم دیگه با حروف بزرگ نوشته نمیشه بصورت camel case نوشته میشه یعنی POOLING شده Pooling و CONVOLUTION شده Convolution.)
تعریف MNIST Solver
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# مسیر فایل مربوط به فاز آموزش/تست با فرمت پروتکل بافر net: "examples/mnist/lenet_train_test.prototxt" test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 # سیاست موجود برای نرخ یادگیری lr_policy: "inv" gamma: 0.0001 power: 0.75 # نتایج را در هر 100 بار تکرار نمایش بده display: 100 # بیشترین تعداد تکرار max_iter: 10000 # snapshot intermediate results snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" # در اینجا مشخص میکنیم که آیا عملیات با استفاده از سی پی یو اجرا شود یا جی پی یو. solver_mode: GPU |
test_iter مشخص میکند که چه تعداد عملیات forward pass در مرحله تست باید انجام شود. در اینجا, ما اندازه batch size فاز تست را ۱۰۰ و تعداد تکرار عملیات forward pass در فاز تست را هم ۱۰۰ قرار دادیم. تا اینطور تمام ۱۰ هزار تصویر موجود برای تست ما پوشش داده شوند. (۱۰۰*۱۰۰ =۱۰,۰۰۰ در هر تکرار یک دسته ۱۰۰ تایی از تصاویر خوانده میشود.)
test_interval هم مشخص میکند که عمل Test را در هر ۵۰۰ تکرار فاز آموزش انجام شود.
نکته خیلی مهم :
تو محاسبه test_iter بر اساس اندازه batch-size یی که در مدلتون مشخص میکنید در بخش تست خیلی دقت کنید. چون اگه ضرب این دو برابر test set شما نشه دقت غلط میگیرید یا دقت بیشتری از چیزی که هست یا کمتر از چیزی که هست.
به همین شکل حواستون به MaxIter و اندازه بچ تو فاز اموزش باشید و محاسبه شما و تست شما بر اساس هر epoch (ارائه کامل تمام نمونه های دیتاست ) باشه. مثلا اگه ۵۰ هزار عکس برای اموزش دارید و اندازه بچ شما در فاز اموزش ۱۰۰ هست. هر epoch شما برابر با ۵۰۰ تکرار هست. یعنی هر ۵۰۰ تکرار یعنی دیتاست شما کامل به شبکه ارائه شده پس میتونید testiter رو هم روی ۵۰۰ تنظیم کنید حداقل.
مثال Regression در Caffe :
برای دیدن مثال رگرشن که مثل همین مثال هست فقط یکسری فرق کوچیک داره اینجا کلیک کنید(مثلا برای deploy کردن ما تو دسته بندی از softmax استفاده میکنیم اما تو رگرشن کلا اخرین لایه ما باید لایه تماما متصل ما باشه و لایه Eucledian loss رو حذف کنیم که برای رگرشن استفاده میشه)
فایل deploy هم فایلی هست که برای تست ازش استفاده میکنیم . مثل همون فایلی هست که در اموزش ازش استفاده میکنیم با این فرق که لایه های مربوط به اموزش رو حذف میکنیم . لایه هایی مثل ورودی و لاس و … که در زمان اموزش فقط معنا دارن.
مثال Multivariate Regression
برای Multivariate Regression هم میتونید این لینک رو ببینید.(بخش Multimodal Convolutional neural networks (CNN) رو ببینید )
برای دیدن نمونه prototxt کلیک کنید
[…] بخش بعدی : مثال عملی […]
ورژن کامپایل شده Caffe در ویندوز رو میتونید از این لینک دانلود کنید : http://deeplearning.ir/آموزش-caffe-بخش-سوم-اینترفیس-ها-و-نحوه-اجرا/
سلام و وقت بخیر
امکانش هست در مورد شبکه MNIST بیشتر توضیح بفرمایید؟ یا بفرمایید که کجا می تونم در رابطه با این شبکه مطالعه کنم؟ 🙂
راستش متاسفانه تا الان فکر می کردم MNIST یک دیتاست دستخط هست
ممنونم
Mnist یک دیتاست هست. شبکه MNIST هم اشاره به LeNet5 داره که یان لیکون برای اولین بار اونو معرفی کرد (شبکه های کانولوشن رو با این شبکه معرفی کرد)
تو caffe یه ورژن از Lenet5 رو با یکسری تغییرات بعنوان مثال Mnist گذاشتن که میتونید ببینید و اجرا کنید تا بیاد دستتون طراحی شبکه و اموزش اون تو caffe مثلا چطوری انجام میشه.
تو پوشه examples یکسری فولدر هست که هرکدوم یک مثال خاص رو داره و میتونید اجرا کنید. یکی از اون مثالها مثال Mnist هست که اینجا توضیح داده.
خیلی ممنون 🙂
سلام
خدا قوت
عالی بود
ببخشید تو بخشهای قبل گفته بودیدبعد از لایه های کانولوشن لایه فعالساز(relu) قرار میگیره ولی چرا تو این شبکه اینجوری نیست؟
ممنون
سلام. این شبکه LeNet5 اصلی هست که یان لیکون تو مقاله اش ارائه کرده . تو مثال کفی هم بعنوان یه مثال کلاسیک اومده همین. اون زمان ReLU هنوز کشف نشده بود و خود لایه کانولوشن بعنوان یه nonlinearity بحساب میومد برای همینه که تو این مثال چیزی نمیبینید.
شما همین معماری رو تست کنید بعد طبق آموزشهای قبلی ما بعد هر لایه کانولوشن یه ReLU اضافه کنید . میبینید سرعت همگرایی و دقت چقدر بهتر میشه . ReLU باعث افزایش nonlinearity شبکه میشه و همینم باعث همگرایی سریعتر و دقت بهتر میشه.
سلام و خسته نباشید
تو این مثال به نظر میاد هیچ فیچری استخراج نشده.آیا درسته؟
سلام .
اینجا صرفا آموزش اولیه دادم . برای استخراج ویژگی تو خود کفی نمونه کد هست
توضیحاتتون واقعا خوب بود. ولی کاشکی یک مثال طبقه بندی تصویر رو هم ذکر میکردید. منظورم اینه که مثلا یک تصویر اعداد رو به شبکه میدادید و نتیجه رو میگرفتید
سلام
فکر میکنم اینو تو بخش پرسش و پاسخ جواب داده باشم . اونجا رو چک کنید باید جوابتون رو پیدا کنید
سلام
تمامی توضیحات شما در کفه در محیط لینوکس و پایتون هست ؟ به عنوان مثال همین پروژه عملیاتی کدهای پیاده سازی در پایتون هست و در لینوکس؟
سلام .
بله میتونید درلینوکس هم استفاده کنید فقط مسیرها رو باید بر طبق لینوکس ویرایش کنید
سلام از آموزش ها ی بسیار عالی که گذاشتید خیلی متشکرم و برای من واقعا مفید بود.
۱- من قصددارم از شبکه های CNN برای دسته بندی سنگ در اپن سی وی استفاده کنم .به نظر شما بهتره از caffe یا TensorFlow یا … استفاده کنم.چون شما در بحث آموزش یادگیری عمیق جایی گفتید که”چیزی که من پیشنهاد میکنم شما یاد بگیرید اول TensorFlow هست و بعد Torch و بعد Deeplearning4J. برای آشنایی caffe رو یادبگیرید.” می خواستم ببینم دقیقا برای مبحث CNN پیشنهادتون چی هست؟
۲- به نظرتون سخت افزار JETSON TX2 MODULE برای اینکار مناسب هست؟
۳- در مورد CIFAR و MINIST گفتید اینها دیتا بیس هستن. اما بعضی جاها از جمله مقاله ای که لینکش رو براتون می فرستم از اونها به عنوان شبکه یاد می کنه و می گه من شبکه CIFAR و MINIST رو استفاده کردم. منظور چی هست؟
لینک مقاله http://www.sciencedirect.com/science/article/pii/S0957417417303032
ببخشید سوال هام در زمینه های متفاوت بود ولی دیگه همه رو توی همین بخش پرسیدم. از اینکه با صبر و حوصله سوال های ما رو جواب میدید و ما رو راهنمایی می کنید ممنونم.
سلام
الان تنسورفلو رو یاد بگیرید تمامی نیازهای شما رو پوشش میده و در حال حاضر بهترین فریم ورک برای یادگیری عمیق هست و بیشترین مستندات و جامعه کاربری رو داره .
تورچ خیلی خوبه ولی فقط بدرد کارای تحقیقاتی میخوره و برای صنعت و… نمیتونید ازش استفاده کنید(فعلا)
کفی رو در حد اشنایی یادبگیرید ویکسری مثال اجرا کنید تا با کلیت کار آشنا بشید که در سرو کارتون با مثالی افتاد که به کفی نیاز داشت بلد باشید کار کنید و زمان از دست ندید .
CIFAR10/100 و MNIST هر دو تا دیتاست هستند.
اگر در مقاله ای که لینکش رو دادید منظور اینه از شبکه ای که بر روی دیتاست MNIST استفاده کردن بهش گفتن MNIST1 . تغییرش دادن بهش گفتن MNIST2 و الی آخر و همین کار رو با دیتاست سیفار انجام دادن
یعنی برای هر دیتاست شبکه هایی که استفاده کردن رو برای مشخص کردنشون بهشون اسم دیتاستی که روش اعمال کردن قرار دادن.