

بسم الله الرحمن الرحیم
در این پست قصد داریم در مورد معماری موبایل نت صحبت کنیم و ببینیم ایده اصلی این مقاله در چه چیزی هست. در کارگاه مطالبی مطرح شد اما بعلت ذیق وقت فرصت نشد کامل در این رابطه صحبت بشه . در این پست قصد داریم یکبار دیگه مطالب مطرح شده حول ایده اصلی رو مرور کنیم و به درک بهتری برسیم. بحث اصلی حول ایده Depth-wise separable convolution میگرده که در ادامه به اون میپردازیم.
داستان چیه؟
بحث اصلی در اینجا کاهش سربار پردازشی هست. برای کاهش سربار پردازشی روشهای مختلفی رو دیدیم که از استفاده از باتل نک ها و یا انواع مختلف فاکتوریزیشن ها (متقارن و نامتقارن) میشه نام برد.
علاوه بر اینها دوتکنیک هم بوده که باید درموردشون صحبت کنیم . یکی از اون ها ایده group convolution هست که در الکس نت مشاهده کردیم (اونجا بیشتر بحث پیاده سازی دخیل بوده) و تکنیک دیگر هم Depth-wise separable convolution هست که در مقاله موبایل نت بهش پرداخته شد.
حالا اجازه بدید این دوتا بحث رو باز کنیم . ما با بحث Depth-wise separable convolution شروع میکنیم و توضیح میدیم که چی هست و چطور باعث کاهش سربار میشه. در اخر هم ارتباطش رو با Group Convolution بیان میکنیم.
قبل از اینکه به بحث Depth-wise separable convolution بپردازیم اول اجازه بدید با هم دیگه چک کنیم یک عملیات کانولوشن معمولی چه خصوصیاتی داره. چقدر سربار پردازشی به شبکه اعمال میکنه تا اینطور بتونیم با تکنیک های بالا قیاس کنیم و بطور عینی ببینیم چه اتفاقی دقیقا رخ میده و میزان کاهش سربار چقدر هست.
مثل مثالی که در کارگاه زدیم اینجا هم سعی میکنیم همون رو باز کنیم و توضیح بدیم.
فرض میکنیم که یک توده ورودی داریم با اندازه 28x28x192 و همینطور ۳۲ کرنل ۵×۵ که در نهایت به ما ۳۲ فیچرمپ با اندازه ۲۸در۲۸ قراره ارائه کنن. بصورت زیر :
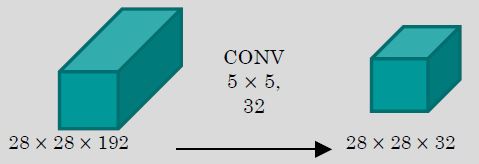
در این حالت میزان پارامترها و عملیات اعشاری بصورت زیر خواهد بود :
|
1 2 3 4 |
(5x5x192)x32x28x28 = 120,422,400 = 120MFLOPS 5x5x192x32 = 153,600 parameters |
یعنی همین یک عملیات ۱۵۳ هزار پارامتر و بیش از ۱۲۰ میلیون عملیات ضرب اعشاری رو در برخواهد داشت. در اینجا میبینیم که تعداد فیچرمپ های ورودی ،اندازه کرنل و همینطور تعداد فیچرمپ های خروجی تاثیر مستقیم بر روی نتایج حاصل دارن و اگر این اعداد بزرگ باشن سربار تا حد زیادی افزایش پیدا میکنه.
حالا در ایده depth-wise separable convolution این ایده مطرح میشه که بجای اینکه در یک عملیات کانولوشن معمولی که هر فیلتر روی تمامی فیچرمپهای ورودی اعمال میشه و بعد نتایج همه با هم ترکیب میشه و نهایتا یک خروجی ارائه میشه، ما بیاییم این یک مرحله رو به دو مرحله تبدیل کنیم. یعنی بعد از اینکه یک فیلتر روی فیچرمپی اعمال شد دیگه بلافاصله ترکیبش نکنیم. بیاییم در گام دوم توسط یک لایه کانولوشن ۱در۱ عمل ترکیب فیچرمپها با هم رو انجام بدیم .
یعنی من بیام یک فیلتر رو روی تمامی فیچرمپهای ورودی اعمال کنم اما نتایج رو ترکیب نکنم ؟ برای ترکیب بیام از یک فیلتر ۱در۱ استفاده کنم؟
جواب بله هست. اما یک نکته ای اینجا وجود داره. اگه همینطوری بخواییم پیش بریم، یعنی یک فیلتر روی تک تک فیچرمپهای ورودی اعمال بشه و بعد دوباره یک فیلتر ۱در۱ برای ترکیب استفاده بشه یک مشکلی بوجود میاد. چه مشکلی؟ بزارید بااهم حساب کنیم تا مشکل رو با هم ببینیم :
|
1 2 3 4 5 |
5x5x192x32 = 153,600 (1x1x192x32)x32 = 196,608 153,600 + 196,608 = 350,208 |
درحالت عادی هر فیلتر ما در تمامی فیچرمپهای ورودی ضرب میشد یعنی 5x5x192 و حالا وقتی n تا فیلتر داشته باشیم این عمل n بار تکرار میشه یعنی 5x5x192xn . حالا اگر n = 32 باشه میشه 5x5x192x32 . تا اینجا شده مثل حالت قبل. با این تفاوت که ما الان 32x192 فیجرمپ داریم که باهم ترکیب نکردیم. حالا اگر بخواییم از یک فیلتر ۱در۱ برای ترکیب حاصل عملیات کانولوشن مرحله قبل استفاده کنیم میشه 1x1x32x192xn که n تعداد فیلترهای ۱در۱ ما هست (همون تعداد فیچرمپ خروجی ما که باید مساوی ۳۲ باشه تا با حالت دیفالت قیاس کنیم) که میشه 1x1x32x192x32 برابر میشه با 196,608 ! که حالا اگر این تعداد پارامتر رو با پارامترهای عملیات قبل جمع کنیم میبینیم به عدد 350,208 میرسیم! یعنی تعداد پارامتر در این حالت نسبت به حالت پیشفرض افزایش پیدا کرد؟!!!
خب این اصلا خوب نیست.این که برعکس بدتر شد!؟ قرار ما بر این بود که سربار رو کاهش بدیم اما depth-wise separable که افزایش داد!
ما یک بحث دیگه ای در depth-wise separable convolution داریم که ازش بنام depth multiplier یا همون ضریب عمق یاد میکنیم. یعنی چی؟ ضریب عمق در این معماری یعنی هر فیلتر روی چند فیچرمپ ورودی خودش میتونه اعمال بشه. اگر برابر ۱ باشه یعنی هر فیچرمپ ورودی روی یک فیلتر اعمال میشه (یک فیلتر به ازای هر فیچرمپ ورودی ). اگر برابر n باشه یعنی هر فیچرمپ ورودی در n فیلتر ضرب میشه.
اجازه بدید اینو بازش کنیم. اگه ما ضریب عمق رو برابر با ۱ قرار بدیم چه اتفاقی می افته؟ یعنی هر فیلتر تنها روی یک فیچرمپ ورودی باید اعمال بشه. در اینجا اگه تعداد فیچرمپها برابر با k باشه تعداد k فیلتر هم نیاز خواهد بود. بزارید حساب کنیم باهم. هر فیلتر ۵در۵ در یک فیچرمپ اعمال بشه. یعنی ۱۹۲ تا فیلتر خواهیم داشت . پس تعداد پارامترها بصورت زیر در میاد:
|
1 2 3 |
5x5x192 = 4,800 |
حالا ما ۱۹۲ تا فیچرمپ جدید داریم که فیلتر روشون اعمال شده. حالا بیایید با ۳۲ تا فیلتر ۱در۱ این ۱۹۲ تا فیچرمپ رو با هم ترکیب کنیم. که میشه
|
1 2 3 |
(1x1x192)x32 = 6,144 |
که باز یعنی یک فیلتر ۱در۱ در تمامی ۱۹۲ فیچرمپ ورودی اعمال میشه و چون ۳۲ تا فیلتر داریم ۳۲ بار این کار تکرار میشه. حالا اگه این دو عدد رو جمع کنیم میبینیم
|
1 2 3 |
4,800 + 6,144 = 10,944 parameters |
یعنی تنها تقریبا ۱۱ هزار پارامتر داریم و این حالت رو با حالت دیفالت مقایسه بکنید! میبینید از 153,600 پارامتر رسیدیم به ۱۰ ۱۱ هزار پارامتر! و این دقیقا حالتی هست که در موبایل نت مورد استفاده قرار گرفت. یعنی در موبایل نت ما فرض ما استفاده از depth multiplier = 1 هست.
اما یک سوال آیا اینجا واقعا داره یک کار صورت میگیره ؟ یعنی اینها معادل هم هستن ؟ آیا این کاری که کردیم معادل واقعا اون چیزی هست که قبلا اتفاق می افتاد؟ بزارید مثال بزنیم
آیا
(5x5x192)32x (یعنی هر فیلتر ۵در۵ در تمام ۱۹۲ فیچرمپ اعمال بشه ، و چون ۳۲ تا از این فیلترها داریم ۳۲ بار این کار تکرار بشه )
واقعا مساوی این چیزی هست که ما اینجا صحبتش رو کردیم ؟ یعنی ما اگه بیاییم بنویسیم
5x5x192 یعنی ۱۹۲ تا فیلتر ۵در۵ (یعنی هر فیلتر دریک کانال اعمال شده)
و بعد بنویسیم
(1x1x192)32x یعنی فیلتر ۱در۱ درتمام ورودی ضرب بشه و چون ۳۲ تا از این فیلترها داریم این کار ۳۲ بار تکرار بشه .
آیا واقعا اینا یک کارو دارن انجام میدن ؟
وقتی به فرمت ضربها نگاه میکنیم . میگیم خب بنظر اینطور میاد بجای اینکه ضرب رو در اندازه فیلتر بزرگتر کنیم رفتیم روی اندازه فیلتر ۱در۱ کردیم و البته اونجا هم همه کانالهای ورودی رو لحاظ کردیم . پس فرقی نباید داشته باشن. اما واقعا اینطور نیست. واقعا اینها یک کار رو انجام نمیدن . در مورد اول هر فیلتر بطور جداگانه روی تمام کانالها اعمال میشه و اون بحث همسایگی لحاظ میشه و اگر ارتباطی وجود داشته باشه شکل میگیره . اما در حالت دوم اینطور نیست. اینجا ما ترکیب انواع مختلف فیلترها رو داریم .در حالت اول ما رپرزنتشن حاصلمون ترکیب اعمال فیلتر روی تمامی کانالها بود یعنی دید ما روی تمام توده ورودی از منظر فیلتر ما بود. اما اینجا در حالت دوم ما رپرزنتشن حاصلمون از ترکیب دیدهای مختلف روی بخشهای مختلف توده ورودی هست.
خب میشه بهبودی هم متصور بود علاوه بر این حالت ساده و پیشفرض؟ دو کار میشه انجام داد یکی اینکه در طرح موبایل نت ضریب عمق رو افزایش بدیم این فقط فیلترهای جدیدی رو معرفی میکنه (به ازای هر فیچرمپ ورودی ) اما هنوز اون بحث دید کلی روی همه فیچرمپ ها رو نداریم . راه دوم ما میتونیم با یکسری تنظیمات اصطلاحا به یک بالانس و یا توازنی در این بین برسیم یعنی سعی کنیم تا حدی خصوصیات و نکات مثبت در عملیات کانولوشن معمولی رو داشته باشیم و از طرفی بتونیم سربار رو کاهش بدیم. بعنوان مثال در همین مثال بالا با قرار دادن دید هر فیلتر برابر عددی مثل ۴ (یعنی هر فیلتر بجای کار با ۱ فیچرمپ ورودی به ۴ فیچرمپ نگاه کنه اعمال بشه و نتایج تجمیع بشه). اگه از طرح اول استفاده کنیم و ضریب عمق رو برابر ۴ قرار بدیم ما به تعداد پارامتری برابر با ۴۳,۷۷۶ میرسیم که هرچند نسبت به تعداد ۱۰,۹۴۴ ۴ برابر افزایش پیدا کرده اما هنوز نسبت به تعداد ۱۵۳,۶۰۰ حالت دیفالت ما خیلی کمتره. اگر از طرح دوم استفاده کنیم به تعداد پارامتر ۲۵۳۴۴ میرسیم و در این حالت هر فیلتر دیدی نسبت به چند فیچرمپ ورودی داره. البته حالت دوم هم چالش های خودش رو داره ولی به هر صورت میشه بعنوان یک گزینه بهش نگاه کرد. به همین شکل میشه حالت های مختلف رو از این طریق اعمال کرد و نتایج رو قیاس و بهترین حالت رو انتخاب کرد.
بحث Group Convolution هم به همین صورته با این تفاوت که در گروپ کانولوشن ایده اینه که هر کرنل تنها به تعداد از فیچرمپهای ورودی نگاه کنه و اینکه نتایج مثل حالت معمولی با هم ترکیب میشن دیگه اینطور نیست که مثل depth-wise separable convolution توسط یک لایه جداگانه ترکیب بشن.
پس بطور خلاصه حالا اگه بخواییم اصطلاحا این گپ بین دو حالت (استاندارد و depth-wise ) رو کاهش بدیم چیکار میتونیم بکنیم ؟
میشه بجای اینکه هر فیلتر به یک کانال نگاه بکنه به مجموعه ای از این کانالها نگاه کنه و بعد ادامه رو بریم اینجا هم باز دو راه پیش میاد
۱٫ تعمیم این روش به روشی که موبایل نت استفاده کرد یا بعبارت دیگه هر فیلتر بجای نگاه به یک فیچرمپ به تعداد بیشتری نگاه کنه
۲٫عدم استفاده از کانولوشن ۱در۱ در انتها و صرفا استفاده از بحث group convolution (یعنی هر کرنل رو محدود به چند کانال ورودی کنیم نه همه )
گروپ کانولوشن در الکس نت مطرح شد سال ۲۰۱۲ اولین بار و چون بحث اونجا مربوط به پیاده سازی بود، بعد از اینکه امکان پیاده سازی معماری الکس نت بصورت یکپارچه و در یک کارت گرافیک مهیا شد دیگه کسی بدنبال چک کردن ویژگی های مربتط با جداسازی عملیات کانولوشن به صورتی که صحبتش رفت تا مدتها نرفت. تا اینکه بعد از چند سال چندتا ازمحققا شروع به تست در حوزه فاکتوریزیشن کردن و این هم یکی از مباحث بود که نتیجه اش رو الان شما مشاهده میکنید.
ناگفته نماند که کماکان پیاده سازی این مساله در کفی بشدت کند و غیربهینه است . در سایر فریم ورکها هم چندان بهینه سازی نشده اما از کفی بنظر میاد بهتر باشن.
اینها بحثهایی بود که باید مطرح میشد ولی متاسفانه مطرح نشد. امیدوارم با توضیحات بالا عزیزانی که مشکل داشتن مشکلشون کامل برطرف شده باشه. انشاءالله سایر مطالب هم در ادمه سعی میشه توضیحات تکمیلی (اگر نیاز باشه) در قالب پستهای جداگانه ارائه بشه. در مطلب بعدی به بحث فاکتوریزیشن ها میپردازیم که در مقاله سوم گوگل نت بحثش مطرح شد.
اگر مشکل یا مساله ای هست لطفا در کامنت بفرمایید
سلام
ممنون از توضیحات خیلی خوبتون
بیزحمت پست بعدیتون معماری Dense-Net باشه – ممنون
سلام
البته اینجا من معماری موبایل نت رو کامل توضیح ندادم یه بحث اصلیش رو که تو ارائه ناقص عنوان شد و خوب بهش نپرداختیم(سریع رد شدیم) رو اینجا باز کردم و توضیح کامل سعی کردم بدم
تو موبایل نت دو بحث ضریب عرض و ضریب رزولوشن هم داریم که برای کاستمایز کردن شبکه ارائه شده و خوندنش در مقاله اصلا سخت نیست برای همین من دیگه اونو عنوان نکردم.
دنزنت هم چیز خاصی نداره ولی باشه سعی میکنم در اسرع وقت یه مطلب در مورد اون هم بگم ولی قبلش باید بحث فاکتوریزیشن رو باز کنم که این هم خیلی نکات مختلف داره .پس اول سعی من اینه فرصتی پیش اومد بحث فاکتوریزیشن و نکات اصلی در مقاله اینسپشن ۳ به بعد رو باز کنم بعدش بریم سراغ مابقی موارد.
ممنون
مهندس در بعضی معماری ها مثله squezeNet میبینی دو تا لایه کانالوشن گذاشته بصورت موازی البته نه تمامی لایه ها اینجوری باشه ها مثله الکس نت ، فقط بعضی لایه ها بصورت موازی هستند آیا این دلیل خاصی داره ؟ نمیشه اون دو تا لایه موازی رو ادغام کرد بشه یک لایه البته با فیلتر های جمع فیلترهای اون دوتا
سلام . کدوم ورژن؟ لینک بدید لطفا
سلام
http://dgschwend.github.io/netscope/#/preset/squeezenet
سلام اون دوتا لایه موازی که صحبت میکنید تو مقاله بهش میگن firemodule و در هر بلاک فایر ماجول داره دوتا ترنسفورمیشن اتفاق می افته
یعنی بنوعی اینا سعی کردن همون چیزی که در گوگل نت۱ انیسپشن بلاک شما دیدی اینجا بصورت ساده ترش لحاظ کنن. با اینکار لایه بعدی دوتا دید نسبت به داده قبل از خودش داره و ایده اینه که شبکه مثلا هرکدوم از این دیدها براش بهتر باشه میتونه حالا ازش بهره ببره.
در الکس نت ایده و بحث کلا یک چیز دیگه بوده اونجا بیشتر بحث پیاده سازی بوده و باز اونجا از بحث گروپ کانولوشن سعی کردن استفاده کنن. اینجا داستان اون چیزی هست که بالا گفتیم. ارائه ترنسفورمیشن های مختلف به یک لایه بالایی. قبلش هم برای کاهش سربار پردازشی از یک فیلتر ۱در۱ استفاده کردن که خوب دقت کنید میبینید ایده همون ایده سابق هست حالا محدودتر شده اینجا.
اگه اون لایه های موازی ادغام بشن (یعنی پشت سر هم باشن؟ یا اینکه نه موازی باشن ولی بجای کانکت شدن جمع بشن نتایج؟ مورد اول که بالا توضیح دادیم ایده اشون چی بوده. اگه پشت سر هم بزارن دیگه میشه یه مسیر خطی و لایه بالایی فقط یک دید رو خواهد داشت از لایه زیرین . اگه مورد دوم باشه برای تجمیع فیچرها بهتره از جمع استفاده نکنید چون باعث خراب کردن اونها میشه و نسبت به زمانی که فیچرها رو کانکت کنید بدتره.
با سلام و احترام
از پستهای خیلی خوبتون سپاس گذارم و خسته نباشید
ممکنه خواهش کنم ی پست هم راجب خروجی شبکه یادگیری عمیق منظورم راجب تحلیل اطلاعات خروجی ، لایه های خروجی و اینکه در هرلایه چه اطلاعاتی رو میشه بدست اورد بزارید
با تشکر
سلام
خواهش میکنم
در مورد سوالتون خوب متوجه نشدم یعنی چی؟ بیشتر توضیح بدید لطفا
سلام
شما پستای مختلفی از تعریف شبکه کانولوشن تا انواع شبکه و دیتاست ورودی و… گذاشتید ، اگر ممکنه یه پست هم راجب خروجی شبکه بزارید که چه جوری میشه استفاده کرد برای بحث های مختلف مثلا برای دسته بندی یا تشخیص شیء یا برای استخراج ویژگی و … چه جوری میشه از کانولوشن استفاده کرد . برای نمونه خود من اولین دفه که mnist رو ران کردم اصلا از اعداد خروجیش چیزی نفهمیدم یا تو یه مقاله دیدم به جای لایه اخر از لایه ماقبل اخر خروجی گرفته بودو…
اگر ممکنه یه پستم راجب خروجی شبکه توضیح بدید
ببخشد امیدوارم خوب منظورمو بیان کرده باشم
متوجه شدم .
باشه انشاءالله وقت کردم سعی میکنم این کارو هم بکنم .
ولی اگه سرچ کنید الان خیلی از این موارد هست. یکی از دلایلی که من الان کمتر مطلب میزارم اینه که الان الحمدالله مطالب زیاد شده و من بیشتر میتونم به کارای خودم برسم و کسی مشکلی داشته باشه خیلی راحت میتونه با سرچ مشکلش رو تا حد خیلی زیادی حل کنه.
ولی باشه چشم سعی میکنم در این زمینه هم کار کنم .
ممنونم از لطفتون من که خودم از مطالب فوق العاده سایتتون استفاده کردم و خیلی کمک کرد اگرم اشکالی داشتم از خودتون پرسیدم و شماهم همیشه با روی باز و با صبر و حوصله راهنماییم کردید که ازتون واقعا ممنونم
خواهش میکنم
کاری نکردم
در پناه خدا انشاءالله همیشه موفق و سربلند باشید
سلام وقتتون بخیر. دو تا سوال در مورد تفاوت سه مدل کانولوشنی که در بالا توضیح داده اید برام پیش اومده لطفا راهنمایی فرمایید.
۱- در جایی ازمتن بیان شده:
در ایده depth-wise separable convolution این ایده مطرح میشه که بجای اینکه در یک عملیات کانولوشن معمولی که هر فیلتر روی تمامی فیچرمپهای ورودی اعمال میشه و بعد نتایج همه با هم ترکیب میشه و نهایتا یک خروجی ارائه میشه، ما بیاییم این یک مرحله رو به دو مرحله تبدیل کنیم. یعنی بعد از اینکه یک فیلتر روی فیچرمپی اعمال شد دیگه بلافاصله ترکیبش نکنیم. بیاییم در گام دوم توسط یک لایه کانولوشن ۱در۱ عمل ترکیب فیچرمپها با هم رو انجام بدیم .لطفا توضیح فرمایید که منظور از عمل ترکیب دقیقا چه عملی است ؟!
۲- اگر درست متوجه شده باشم وقتی ضریب عمق را ۴ در نظر می گیریم در واقع در مرحله اول نیاز به ۴۸ (حاصل تقسیم ۱۹۲به ۴) فیلتر ۵ در ۵ داریم یعنی ۵*۵*۴۸=۱۲۰۰و البته چون با هم ترکیب نمی شوند عمق همان ۱۹۲ باقی می ماندو در مرحله دوم که ۳۲ فیلتر ۱ در ۱ را اعمال می کنند تعداد پارامترها برابر است با ۱*۱*۳۲*۱۹۲=۶۱۴۴. که تعداد پارامترها در آن نهایتا برابر خواهد بود با ۷۳۴۴.
در حالیکه توی متن همان حاصل قبلی را ۴ برابر کرده و حاصل را برابر با ۴۳,۷۷۶ در نظر گرفته . لطفا توضیح بفرمایید که با ضریب عمق ۴ چی شد که تعداد پارامترها ۴ برابر شد !!!!
سلام.
چیزی تقسیم بر ۴ نمیشه . این گروپ کانولوشن نیست.
ضریب عمق تعداد خروجی (مرحله اول dws) رو به ازای هر فیچرمپ ورودی مشخص میکنه. اینجا رو ببینید شاید بهتر باشه :
https://github.com/keras-team/keras/blob/master/keras/layers/convolutional.py
بخش مربوط به separable convolution رو ببینید و توضیحاتش رو بخونید.
—————————–
ممنون از پاسخگویی شما
می شه لطف کنید سوال اولم رو هم جواب بدید!!!
متشکرم
سلام.
اون ترکیب اشاره به ترکیب فیچرمپ ها در کانولوشن معمولی داره. بخش دوم اموزش شبکه های کانولوشن رو ببینید
سلام
اول ممنون از اطلاعات خوبتون یه دنیا
فقط یه چیز می خواستم بدونم این اطلاعات شبکه های جدید مثل همین موبایل نت و … رو که جدید ایجاد و طراحی میشن از کجا پیدا میشه کرد؟ برای مثال آیا سایت بخصوصی تو این زمینه هست که شبکه های جدید رو معرفی کنه و هر روز بروزبشه بگه فلان شبکه هم ایجاد شده؟
ممنونم از راهنماییتون
سلام
نه چنین سایتی نیست. تعداد مقالات خیلی زیاده و هر کسی بسته به حوزه کاری خودش یکسری موارد رو چک میکنه
بهترین کار برای باخبر شدن از جدیدترین مقالات (معماری …)چک کردن arXivهست و اکثرا همین کارو میکنن. اینجا : https://arxiv.org رو چک کنید.
سلام ابتدا تشکر بخاطر مطالبتون. من تمام مقالات شما رو خوندم … ولی این مقاله رباط مغزم را پاره کرد متاسفانه ! (شوخی)
چند تا سوال داشتم:
در ابتدای متن به این جمله بر می خوریم:
“حالا در ایده depth-wise separable convolution این ایده مطرح میشه که بجای اینکه در یک عملیات کانولوشن معمولی که هر فیلتر روی تمامی فیچرمپهای ورودی اعمال میشه و بعد نتایج همه با هم ترکیب میشه و نهایتا یک خروجی ارائه میشه، ما بیاییم این یک مرحله رو به دو مرحله تبدیل کنیم. یعنی بعد از اینکه یک فیلتر روی فیچرمپی اعمال شد دیگه بلافاصله ترکیبش نکنیم.”
–> اولین نکته : بنظر می رسه منظور دو جمله یکیه، اول شما میگید هر فیلتر روی تمامی فیچرمپ ها ورودی اعمال میشه و بعد بای هم ترکیب میشه و بار دوم هم همین مطلب گفته میشه اول اعمال میشه و بعدا ترکیب… دومین نکته : منظورتون دقیقا از ترکیب چی هست من اصلا متوجه نمی شم. ما ۳۲ فیلتر ۵*۵*۱۹۲ تایی داریم. فرض کنیم اولین فیلتر ۵*۵*۱۹۲ میاد در یک فیچرمپ ۵*۵*۱۹۲ در توده ی ورودی کانوالو میشه، نتیجش میشه یک عدد به نام x1 ، در فیچر مپ دوم نتیجش x2 و … تا فیچر مپ اخر که میشه xn . این اعداد x1 تا xn اگر با هم ترکیب بشند تصویر فیلتر شده ی اول را به ما می دهند. آیا منظورتون از ترکیب، ترکیب x1 تا xn هست؟ یعنی ما دست نگه داریم ، ترکیب نکنیم؟ تصویر فیلترشده اول را تشکیل ندیم؟
یا منظورتون از ترکیب اینه که ما فیلتر اول را در توده ورودی کانوالو می کنیم و تصویر p1 فیلتر شده را بدست میاریم. فیلتر دوم را در توده کانوالو می کنیم و تصویر p2 .. تا تصویر pk .. ما اینا را با هم ترکیب نکنیم؟ و بعد سراخر یکاری روش انجام بدیم.
خلاصه من نفهمیدم ترکیب اصلا یعنی چی؟
با توجه به نفهمیدنم در این موضوع، من این جمله آخر عبارت زیر را هم نفهمیدم!:
“درحالت عادی هر فیلتر ما در تمامی فیچرمپهای ورودی ضرب میشد یعنی ۵x5x192 و حالا وقتی n تا فیلتر داشته باشیم این عمل n بار تکرار میشه یعنی ۵x5x192xn . حالا اگر n = 32 باشه میشه ۵x5x192x32 . تا اینجا شده مثل حالت قبل. با این تفاوت که ما الان ۳۲×۱۹۲ فیجرمپ داریم که باهم ترکیب نکردیم.”
البته سوالتم زیاده؛ شاید این رو توضیح بدین بقیه ماجرا دستم بیاد
سلام
بحث اینه در صورت اول اگر شما توده ای با n فیچرمپ (یا کانال) داشته باشید و یک فیلتر رو اعمال کنید چیزی که رخ میده اینه که اون فیلتر روی تمام n فیچرمپ ورودی اعمال میشه و n فیچرمپ جدید بدست میاد. در گام بعدی اینها با هم ترکیب میشن و نهایتا میشه یک فیچرمپ خروجی.
صحبتی که اینجا میشه اینه که اون مرحله ترکیب دوم جدا سازی بشه. در این حالت در ساده ترین شکلش هر فیلتر با یک فیچرمپ ورودی ارتباط خواهد داشت. اگر n فیچرمپ ورودی باشه شما به ازای هرکدوم یک فیلتر خواهید داشتید. بعد از اینکه n فیچرمپ نتیجه شده (حاصل از اعمال هر فیلتر بر روی فیچرمپ متناظرش) در گام بعدی اینها با هم ترکیب میشن (توسط یک لایه کانولوشن یک در یک )
ضمنا فیلتر در کانولوشن ۲ بعدی اینجا مطرح هست و در اینجا فیلتر یک ماتریس با ابعاد kxk هست . اگر شما ۱۰ تا فیلتر داشته باشید ۱۰ تا ماتریس با ابعاد kxkخواهید داشت . یا به عبارت ساده تر kxkxm . توده ورودی شما هر ابعادی میتونه داشته باشه و سه بعدی هست. hxwxd .
سلام بسیار ممنون از شما. موضوع مشخص شد برام
سلام بسیار ممنون از توضیحات خوب شما، ممکن بفرمایید آیا تنها کاری که کرنل ۱در۱ اینجا انجام می دهد ترکیب فیچر مپ هاست؟ یا برای کار دیگری هم تعبیه شده است؟
متشکرم
سلام
نه در موبایل نت بطور ویژه از ۱در۱ برای ترکیب استفاده میشه
سلام
ممنون از توضیحات خوبتون
بیزحمت میشه یکم راجب تفاوت موبایل نت ۲ و ۱ بفرمایید یعنی تفاوت های اصلی .
و اینکه تعداد لایه های هرکدام چندتا هست ؟
و فیچرمپ در فارسی معادلش دقیقا چی هست؟
سلام. ان شاالله سر فرصت توضیحات تکمیلی رو میدم. فعلا این بخونید کافیه.
سلام
ببخشید من اینجاشو خوب متوجه نشدم
در حالت دوم اگر دو مرحله ایی بشه و در مرحله اول یک فیلتر به تمامی فیچرمپ ورودی اعمال بشه تعداد پارامترها برای ۳۲ فییلتر خواهیم داشت : ۳۲*۱۹۲*۵*۵ این اکی هست حالا مرحله دوم رو متوجه نمیشم مگه ما دوباره ۳۲ تا فیلتر ۱۹۲*۱*۱ نداریم ؟ تعداد پارامترهاش میشه ۳۲*۱۹۲*۱*۱ پس اون ۳۲ دیگه چیه که بهش ضرب شده ؟
خیر ببینی مهندس. عالی توضیح دادی. یه دوتا نقاشی دست نویسم میذاشتی دیگه حرف نداشت