
بسم الله الرحمن الرحیم
این بخش دوم آموزش شبکه های کانولوشن هست . تصاویر زیادی این اموزش داره خصوصا اخر و یکسری از فرمول ها رو هم مجبور شدم از word عکس بگیرم. حواستون باشه که اگه جایی چیزی باید باشه و نیست بدونید عکس لود نشده! انشاالله سرفرصت داکیومنت این هم برای دانلود قرار میدم.
لایه Convolutional
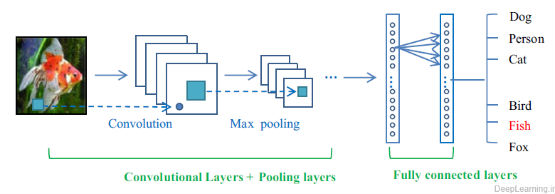
لایه کانولوشن هسته اصلی تشکیل دهنده شبکه عصبی کانولوشن است, و توده خروجی آن را میتوان بصورت یک توده سه بعدی از نورون ها تفسیر کرد. به زبان ساده تر یعنی اینکه خروجی این لایه یک توده سه بعدی است . برای درک بهتر این مسئله شبکه های عصبی معمولی را در نظر بگیرید . در شبکه های عصبی معمولی هر لایه چیزی جز لیستی(یک بعدی همانند یک مستطیل!) از نورون ها نبود که هر نورون خروجی خاص خود را تولید میکرد و نهایتا یک لیست از خروجی ها که متناظر با هر نورون بود حاصل میشد . اما در شبکه عصبی کانولوشن بجای یک لیست ساده ما با یک لیست سه بعدی (یک مکعب !) مواجه هستیم که نورونها در سه بعد آن مرتب شده اند. در نتیجه خروجی این مکعب نیز یک توده سه بعدی خواهد بود . تصاویر زیر این مفهوم و تفاوت بین این دو مفهوم را بهتر بیان میکند .
در اینجا ما در مورد جزییات اتصالات نورون ها و نحوه قرارگیری آنها در فضا و طرح اشتراک پارامتر آنها صحبت میکنیم .
خلاصه و درک شهودی مسئله :
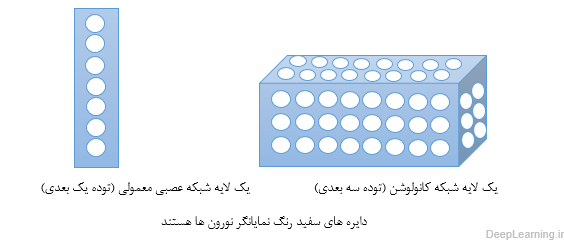
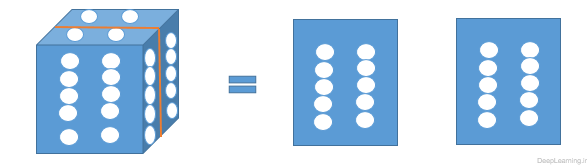
پارامترهای لایه کانولوشن شامل مجموعه ای از فیلترهای قابل یادگیری هستند. هر فیلتر از لحاظ مکانی کوچک بوده [۱] اما در امتداد عمق توده ورودی ادامه پیدا میکند. به زبان ساده تر میتوان اینطور گفت که ما با یک توده سه بعدی مواجه هستیم . این توده سه بعدی دارای یک طول و عرض و یک عمق است. اگر فرض کنیم عمق ما برابر با x باشد به این معناست که ما x برش (قاچ) از توده خواهیم داشت. بعنوان مثال اگر عمق برابر با ۱ باشد ما با یک ماتریس ساده (آرایه دوبعدی) مواجه هستیم که دارای طول و عرض است . حال اگر عمق برابر با ۲ باشد یعنی ما دارای دو ماتریس هستیم . یعنی در هر عمق در اصل یک ماتریس وجود دارد. بنابر این زمانی که ما میگوییم فیلتر مورد نظر در امتداد یا راستای عمق ادامه میابد به این معناست که این فیلتر بر روی تمامی ماتریس ها (برش های توده ورودی ) اعمال میشود.
یک توده سه بعدی با عمق برابر با ۲ که بصورت عمودی برش داده شده است .
در زمان forward pass ما هر فیلتر را در امتداد پهنا (width) و ارتفاع (height) ورودی میلغزانیم (در اصل convolve میکنیم ) با این کار ما یک نگاشت فعال سازی(Activation Map) دو بعدی برای آن فیلتر ایجاد میکنیم. همانطور که ما فیلتر را در عرض ورودی میلغزانیم (slide میدهیم) ضرب نقطه ای بین ورودی های فیلتر با ورودی را هم انجام میدهیم . بصورت شهودی, شبکه, فیلترهایی که در زمان مشاهده برخی از ویژگی های خاص در بعضی موقعیتهای مکانی در ورودی فعال میشوند را یاد میگیرد . با انباشته کردن این نگاشتهای فعال سازی (Activation Maps) برای تمامی فیلترها در راستای بُعد عمق ,توده خروجی کامل بدست می آید . هر مدخل در این توده خروجی را میتوان بعنوان خروجی یک نورون که تنها به ناحیه کوچکی در ورودی نگاه میکند در نظر گرفت که پارامترهای مشترک با بقیه نورون ها در همان نگاشت فعال سازی (Activation Map)دارد(چرا که این اعداد همه نتیجه اعمال یک فیلتر یکسان هستند ).
اتصال محلی (Local Connectivity):
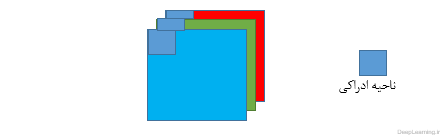
زمانی که ما با ورودی هایی با ابعاد بالا(high dimensional) مثل تصاویر مواجه هستیم[۲], همانطور که در بالا دیدیم اتصال نورون ها به تمام نورونهای قبل از خود (در توده قبلی) غیر عملی است. بنابر این بجای اینکار ما هر نورون را تنها به ناحیه کوچکی از توده ورودی متصل میکنیم .میزان وسعت این ناحیه کوچک برای اتصال یک فراپارامتر است که به آن receptive field و یا ناحیه ادراکی گفته میشود . وسعت اتصال در محور عمق همیشه مساوی با عمق توده ورودی است .توجه به این عدم تقارن در نحوه برخورد ما با ابعاد مکانی (طول و عرض تصویر و یا همان عرض و ارتفاع ) و بعد عمق حائز اهمیت است. ارتباطات در مکان محلی هستند یعنی در راستای عرض و ارتفاع تصویر هستند اما همیشه تمام عمق توده ورودی را در بر میگیرند. اجازه دهید با یک مثال توضیح بیشتری بدهیم . فرض کنید توده ورودی ما دارای اندازه ای برابر با ۳x32x32 باشد ( مثلا یک عکس رنگی (RGB) از دیتاست CIFAR-10 ). حال اگر ناحیه ادراکی (Receptive Field) اندازه ای برابر با ۵×۵ داشته باشد این به این معناست که هر نورون در لایه کانولوشن برای ناحیه ای در توده ورودی با اندازه ۵x5x3 تعداد وزنی برابر۵x5x3=75 خواهد داشت. لطفاً دقت کنید که میزان وسعت اتصال در امتداد محور عمق باید مساوی ۳ باشد چرا که عمق توده ورودی ما ۳ است ( تصویر ورودی ما دارای ۳ کانال رنگ است). پس همانطور که دقت کردید اتصالات فقط در راستای عرض و ارتفاع تصویر ورودی نیستند بلکه در محور عمق هم امتداد پیدا میکنند. و این به زبان ساده تر به این معناست که اگر تصویر رنگی ورودی خود با ۳ کانال رنگ را ۳ ماتریس که پشت سر هم قرار گرفته اند در نظر بگیریم . توضیحات بالا به این معناست که ما ناحیه ای به اندازه ۵×۵ را بر روی تمام این سه ماتریس اعمال میکنیم . تصویر زیر این مطلب را بهتر نشان میدهد.
نمایشی از ارتباط در یک توده که در راستای عرض و ارتفاع در امتداد عمق ادامه یافته است
مثال دوم را در نظر بگیرد. فرض کنید توده ورودی اندازه ای برابر با ۱۶x16x20 داشته باشد. بنابر این با استفاده از ناحیه ادراکی (Receptive field) با اندازه ۳×۳ هر نورون در لایه کانولوشن تعداد ۳x3x20 = 180 اتصال به توده ورودی خواهد داشت. توجه کنید که اتصال در فضا محلی است ( مثلا در اینجا ۳×۳ است ) اما تمام عمق را در بر گرفته است (۲۰)
 تصویر سمت چپ یک توده ورودی را نشان میدهد که با رنگ قرمز مشخص شده است ( مثلا یک عکس با اندازه ۳x32x32 از دیتا ست CIFAR-10). همینطور شما میتوانید یک توده از نورون ها را در لایه کانولوشن که به رنگ آبی نمایش داده شده است مشاهده کنید. هر نورون در لایه کانولوشن تنها به یک ناحیه محلی از لحاظ مختصات مکانی( طول و عرض) در توده ورودی متصل است اما این ارتباط در عمق بصورت کامل امتداد میابد(یعنی تمام کانال های رنگ را در بر میگیرد).توجه کنید که چندین نورون ( در این مثال ۵ نورون ) در راستای عمق وجود دارند که همگی به یک ناحیه در ورودی نگاه میکنند(توضیحات ببیشتر در ادامه داده میشود).
تصویر سمت چپ یک توده ورودی را نشان میدهد که با رنگ قرمز مشخص شده است ( مثلا یک عکس با اندازه ۳x32x32 از دیتا ست CIFAR-10). همینطور شما میتوانید یک توده از نورون ها را در لایه کانولوشن که به رنگ آبی نمایش داده شده است مشاهده کنید. هر نورون در لایه کانولوشن تنها به یک ناحیه محلی از لحاظ مختصات مکانی( طول و عرض) در توده ورودی متصل است اما این ارتباط در عمق بصورت کامل امتداد میابد(یعنی تمام کانال های رنگ را در بر میگیرد).توجه کنید که چندین نورون ( در این مثال ۵ نورون ) در راستای عمق وجود دارند که همگی به یک ناحیه در ورودی نگاه میکنند(توضیحات ببیشتر در ادامه داده میشود).
تصویر سمت راست ساختار یک نورون را نشان میدهد که دقیقا همانند چیزی است که در شبکه های عصبی معمولی مورد استفاده قرار میگیرد بعبارت دیگر نورون ها هیچ تفاوتی نسبت به قبل نکرده اند. آنها هنوز ضرب نقطه ای بین وزنها و ورودی ها را انجام داده و نتیجه را از یک تابع غیرخطی عبور میدهند و خروجی را تولید میکنند. تنها تفاوت در اینجا این است که اتصال دستخوش محدودیت شده است به این معنا که اتصالات آنها باید از لحاظ مکانی محلی باشد
ما تا به اینجا در مورد اتصال هر نورون به توده ورودی در لایه کانولوشن صحبت کردیم اما چیزی در مورد اینکه چه تعداد نورون در توده خروجی بایستی وجود داشته باشند و یا اینکه ترتیب قرار گیری آنها به چه صورت باید باشد صحبتی نکردیم.۳ فراپارامتر (Hyper parameter) اندازه توده خروجی را کنترل میکنند. این سه پارامتر عمق (depth) ,گام (stride) و لایه گذاری با صفر (zero-padding) هستند. در زیر به توضیح بیشتر این پارامترها میپردازیم.
عمق توده خروجی پارامتری است که ما میتوانیم خود انتخاب کنیم . این پارامتر تعداد نورون هایی که در لایه کانولوشن به یک ناحیه در توده ورودی متصل میشوند را کنترل میکند. این پارامتر همانند حالتی در شبکه های عصبی معمولی است که ما در یک لایه مخفی چندین نورون داشتیم که همه به یک ورودی متصل بودند. همانطور که جلوتر خواهیم دید تمام این نورون ها یاد میگیرند که برای ویژگی های مختلف موجود در ورودی فعال شوند. بعنوان مثال اگر لایه کانولوشن اول یک تصویر خام را بعنوان ورودی دریافت کند, نورون هایی که در امتداد بعد عمق قرار دارند ممکن است با مواجهه با لبه های جهتدار (oriented edges) و یا لکه های رنگ (blobs of color) فعال شوند. ما به مجموعه نورون هایی که همه به یک ناحیه یکسان از ورودی نگاه میکنند یک ستون عمقی یا depth column میگوییم.
ما باید گام (stride) را که بوسیله آن ستون های عمقی (depth column) را حول ابعاد مکانی (عرض و ارتفاع) معین میکنیم مشخص کنیم. زمانی که stride برابر با ۱ باشد ما یک ستون عمقی (depth column) جدید از نورون ها را به مختصات مکانی با فاصله تنها ۱ واحد مکانی از هم, اختصاص میدهیم. این باعث بوجود آمدن نواحی ادراکی دارای اشتراک زیاد بین ستونها و همچنین توده های خروجی بزرگ میشود. برعکس اگر ما گام ها (stride) را بزرگتر بگیریم نواحی ادراکی اشتراک کمتری داشته و توده خروجی نیز از لحاظ ابعاد مکانی کوچکتر میشود.
همانطور که بزودی خواهیم دید بعضی اوقات راحت تر است که مرز توده ورودی را با صفر بپوشانید(zero-pad) . به عبارت دیگر یعنی دور تصویر ورودی را با صفر پر کنیم . مثل اینکه یک سطر ۰ و یک ستون ۰ به ابتدا و انتهای تصویر اضافه کنیم اینطور تصویر ما در داخل قابی از صفر قرار خواهد گرفت مثل شکل زیر:
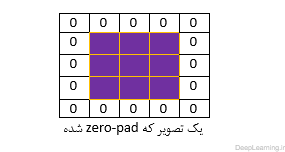
اندازه این Zero-padding یک فراپارامتر(hyper parameter) است . ویژگی خوب این پارامتر این است که بما اجازه کنترل کردن اندازه توده خروجی را میدهد. بطور خاص ما بعضی اوقات میخواهیم که دقیقا اندازه مکانی توده ورودی حفظ شود.
ما برای محاسبه اندازه (مکانی) توده خروجی میتوانیم از اندازه توده ورودی (W) اندازه ناحیه ادراکی نورون های لایه کانولوشن (F) , اندازه گام (stride) و مقدار zero padding که روی مرزهای توده ورودی اعمال شده استفاده کنیم . ما میتوانیم از فرمول:![]() برای محاسبه اینکه چه تعداد نورون مناسب است استفاده کنیم (با تست این فرمول میتوانید به درستی آن پی ببرید) اگر نتیجه این فرمول یک عدد اعشاری باشد این به این معناست که مقدار استفاده شده برای stride نادرست بوده و نورون ها را نمیتوان با این مقدار طوری کنار یکدیگر مرتب کرد که بخوبی در سرتاسر توده ورودی بصورت متقارن جای شوند. برای درک این فرمول مثال زیر را در نظر بگیرید .
برای محاسبه اینکه چه تعداد نورون مناسب است استفاده کنیم (با تست این فرمول میتوانید به درستی آن پی ببرید) اگر نتیجه این فرمول یک عدد اعشاری باشد این به این معناست که مقدار استفاده شده برای stride نادرست بوده و نورون ها را نمیتوان با این مقدار طوری کنار یکدیگر مرتب کرد که بخوبی در سرتاسر توده ورودی بصورت متقارن جای شوند. برای درک این فرمول مثال زیر را در نظر بگیرید .
تصویری از ترتیب (قرارگیری) مکانی.
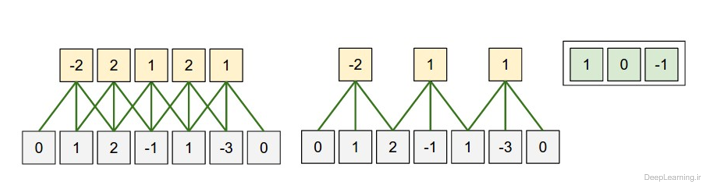
در این مثال تنها یک بعد مکانی (محور x) , یک نورون با ناحیه ادراکی با اندازه F = 3 و یک ورودی با اندازه W = 5 وجود دارد(۱,۲,-۱,۱,-۳). Zero padding هم برابر با P = 1 است. (یک صفر به دو طرف ورودی اضافه شده است)
در تصویر سمت چپ stride با اندازه S = 1 اعمال شده است که باعث اندازه خروجی :![]() شده است. در تصویر سمت راست stride با اندازه S = 2 باعث اندازه خروجی :
شده است. در تصویر سمت راست stride با اندازه S = 2 باعث اندازه خروجی :![]() شده است. توجه کنید که stride با اندازه S = 3 امکان پذیر نمیباشد چرا که با این مقدار نمیتوان نورون ها را بخوبی در سرتاسر توده جای داد. اگر از لحاظ فرمولی بخواهیم به این مسئله نگاه کنیم میبینیم که مقدار ۴=۲+۳-۵ بر ۳ قابل تقسیم نیست (بخش پذیر نیست). وزن نورونها در این مثال [۱,۰,-۱] (همانطور که در منتها الیه تصویر سمت راست نمایش داده شده است ) و بایاس آن برابر با ۰ میباشد.. این وزنها بین تمام نورون های زرد رنگ مشترک است (بخش اشتراک پارامترها را در زیر بخوانید)
شده است. توجه کنید که stride با اندازه S = 3 امکان پذیر نمیباشد چرا که با این مقدار نمیتوان نورون ها را بخوبی در سرتاسر توده جای داد. اگر از لحاظ فرمولی بخواهیم به این مسئله نگاه کنیم میبینیم که مقدار ۴=۲+۳-۵ بر ۳ قابل تقسیم نیست (بخش پذیر نیست). وزن نورونها در این مثال [۱,۰,-۱] (همانطور که در منتها الیه تصویر سمت راست نمایش داده شده است ) و بایاس آن برابر با ۰ میباشد.. این وزنها بین تمام نورون های زرد رنگ مشترک است (بخش اشتراک پارامترها را در زیر بخوانید)
استفاده از Zero-padding :
در مثال قبل (تصویر سمت چپ) توجه کنید که بُعد ورودی برابر ۵ و بعد خروجی نیز مساوی ۵ بود. به این خاطر این اتفاق رخ داد چرا که ناحیه ادراکی برابر با ۳ بود و ما از zero padding مساوی با ۱ استفاده کردیم . اگر zero padding یی وجود نداشت , توده خروجی تنها بعدی برابر با ۳ میداشت. چرا که تنها این تعداد نورون در سرتاسر ورودی اصلی میتوانستند جا بگیرند. بطور کلی تنظیم مقدار Zero padding بر اساس فرمول:![]() در زمانی که Stride برابر با S = 1 باشد اطمینان حاصل میکند که توده ورودی و توده خروجی هر دو از لحاظ مکانی دارای اندازه یکسانی خواهند بود. استفاده از Zero padding به اینصورت بسیار رایج بوده و ما توضیحات تکمیلی را جلوتر زمانی که در مورد معماری شبکه های کانولوشن بیشتر صحبت میکنیم خواهیم داد.
در زمانی که Stride برابر با S = 1 باشد اطمینان حاصل میکند که توده ورودی و توده خروجی هر دو از لحاظ مکانی دارای اندازه یکسانی خواهند بود. استفاده از Zero padding به اینصورت بسیار رایج بوده و ما توضیحات تکمیلی را جلوتر زمانی که در مورد معماری شبکه های کانولوشن بیشتر صحبت میکنیم خواهیم داد.
محدودیت های Stride
توجه کنید که ترتیب مکانی فراپارامترها (Hyper paramters) محدودیت های دوطرفه دارند. بعنوان مثال زمانی که اندازه ورودی برابر با ۱۰ بوده و هیچ zero padding استفاده نشده باشد (P=0) و اندازه فیلتر برابر با F=3 باشد بنابر این استفاده از stride یی با اندازه S = 2 غیر ممکن خواهد بود. چرا که:![]() که همانطور که مشاهده میکنید نتیجه یک عدد صحیح نبوده و فلذا نورون ها نمیتوانند بصورت متقارن و بخوبی در سرتاسر ورودی جای(قرار) بگیرند. بنابراین این مقادیر این فراپارامترها نامعتبر در نظر گرفته میشود و اگر شما سعی کنید یک شبکه عصبی کانولوشن با این مقادیر در یک کتابخانه مربوط به شبکه عصبی کانولوشن ایجاد کنید به احتمال بسیار زیاد با یک Exception مواجه خواهید شد. همانطور که جلوتر در بخش معماری های شبکه کانولوشن خواهیم دید, تنظیم اندازه ها در شبکه کانولوشن بصورت مناسب بطوری که تمامی ابعاد آن بدرستی کار کنند کار واقعا طاقت فرسایی میتواند باشد که البته با استفاده از Zero-padding و تعداد دیگری از راهکارهای طراحی تا حد بسیار زیادی میتوان از سختی آن کاهید.
که همانطور که مشاهده میکنید نتیجه یک عدد صحیح نبوده و فلذا نورون ها نمیتوانند بصورت متقارن و بخوبی در سرتاسر ورودی جای(قرار) بگیرند. بنابراین این مقادیر این فراپارامترها نامعتبر در نظر گرفته میشود و اگر شما سعی کنید یک شبکه عصبی کانولوشن با این مقادیر در یک کتابخانه مربوط به شبکه عصبی کانولوشن ایجاد کنید به احتمال بسیار زیاد با یک Exception مواجه خواهید شد. همانطور که جلوتر در بخش معماری های شبکه کانولوشن خواهیم دید, تنظیم اندازه ها در شبکه کانولوشن بصورت مناسب بطوری که تمامی ابعاد آن بدرستی کار کنند کار واقعا طاقت فرسایی میتواند باشد که البته با استفاده از Zero-padding و تعداد دیگری از راهکارهای طراحی تا حد بسیار زیادی میتوان از سختی آن کاهید.
[۱] یعنی تنها بخشی از عرض و ارتفاع را شامل میشود. (مثلا اگر عرض و ارتفاع تصویر به ترتیب برابر ۳۲ و ۳۲ باشد. فیلتر ممکن است اندازه برابر با ۴×۴ داشته باشد.
[۲] به متغیرهای مختلف که در نتیجه مسئله ای دخیل هستند در Machine learning بُعد گفته میشود. در اینجا هر پیکسل یک تصویر یک متغییر بحساب می آید (چرا که بصورت یک ورودی مجزا به شبکه ارائه میشود و مقدار آن در کارکرد شبکه موثر است ) . بنابر این یک تصویر با ۲۰x20x3 1200 بعد خواهد داشت. از این رو در اینجا ابعاد بالای تصاویر به معنای بزرگتر بودن اندازه تصاویر است.
نمونه واقعی از شبکه های عصبی کانولوشن
معماری Krizhevsky et al که برنده رقابت ImageNet در سال ۲۰۱۲ شد تصاویری با اندازه ۲۲۷x227x3 را بعنوان ورودی دریافت میکرد. در لایه کانولوشن اول این شبکه از نورون هایی با ناحیه ادراکی با اندازه F=11 , Stride با مقدار S=4 و zero padding P = 0 استفاده میشد. از آنجایی که ۵۵=۱+۴/(۱۱-۲۲۷) و عمق لایه کانولوشن برابر با K = 96 بود توده خروجی لایه کانولوشن اندازه ای برابر با ۵۵x55x96 داشت. هر کدام از ۵۵x55x96 نورون در این توده به ناحیه ای از ورودی با اندازه ۱۱x11x3 متصل بودند. علاوه بر آن تمام ۹۶ نورون در هر ستون عمقی (depth column) هم به یک ناحیه از ورودی با اندازه ۱۱x11x3 متصل بودند البته با وزنهای متفاوت.
اشتراک پارامتر
طرح اشتراک پارامتر در لایه های کانولوشن به منظور کنترل تعداد پارامترها مورد استفاده قرار گرفت. با استفاده از نمونه عینی که در بالا داده شد, ما میبینیم که ۵۵x55x96=290,400 نورون در لایه کانولوشن اول وجود دارد و هر کدام از آنها ۱۱x11x3=363 وزن و ۱ بایاس دارند. همه اینها با هم تشکیل ۲۹۰۴۰۰×۳۶۴=۱۰۵,۷۰۵,۶۰۰ پارامتر را تنها برای لایه اول شبکه کانولوشن میدهند. کاملا پیداست که این عدد بسیار بزرگی است.
ما میتوانیم با یک فرض منطقی تعداد بسیار زیادی ازاین پارامترها را کاهش دهیم. و آن فرض این است که اگر یک Patch feature برای محاسبه در یک موقعیت مکانی (x,y) مفید باشد پس باید برای محاسبه همان feature در موقعیت متفاوت (x2,y2) هم مفید باشد. به عبارت دیگر اگر یک برش دو بعدی از عمق را یک برش عمقی بنامیم (بعنوان مثال یک توده با اندازه ۵۵x55x96 دارای ۹۶ برش عمقی است که هر کدام دارای اندازه ۵۵×۵۵ میباشند) ما هر نورون در این برش عمقی را محدود به استفاده از یک مجموعه وزن و بایاس میکنیم . با این طرح اشتراک پارامتر, لایه کانولوشن اول در مثال ما حالا فقط ۹۶ مجموعه وزن یکتا خواهد داشت (یک مجموعه وزن برای هر برش عمقی ) که در کل برابر ۹۶x11x11x3 = 34,848 وزن یکتا یا ۳۴,۹۴۴ پارامتر (به اضافه ۹۶ بایاس) خواهد بود . متناوبا تمام ۵۵×۵۵ نورون موجود در هر برش عمقی حالا از یک مجموعه پارامتر استفاده میکنند. در عمل در حین Backpropagation هر نورون موجود در توده gradient را برای وزنهایش حساب میکند اما این gradient ها درسرتاسر هر برش عمقی جمع شده و تنها یک مجموعه وزن در هر برش را بروز میکند.
توجه کنید که اگر تمام نورون ها در یک برش عمقی از یک بردار وزن یکسان استفاده کنند بنابر این عملیات forward pass لایه کانولوشن میتواند در هر برش عمقی بصورت ضرب (convolution) بین وزنهای نورون با توده ورودی محاسبه شود (برای همین به آن لایه کانولوشن گفته میشود) بنابر این رایج است که به مجموعه وزن ها بعنوان یک فیلتر نگاه شود( یا یک کرنل). که با ورودی ضرب (convolve) شده است. نتیجه این عمل (Convolution) یک نگاشت فعالسازی (Activation map) است ( مثلا با اندازه ۵۵×۵۵ ) و مجموعه این Activation map ها برای هر فیلتر مختلف در راستای بعد عمق بر روی هم قرار گرفته تا توده خروجی را ایجاد کنند(مثلا با اندازه ۵۵x55x96)

فیلترهای نمونه که توسط Krizhevsky et al یادگرفته شده اند. هر کدام از این ۹۶ فیلتر نمایش داده شده در اینجا اندازه ای برابر با ۱۱x11x3 دارند و هر کدام از انها با ۵۵×۵۵ نورون در یک برش عمقی به اشتراک گذاشته شده اند. دقت کنید که فرض اشتراک پارامترها نسبتا منطقی هم هست. اگر کشف یک لبه افقی در جایی از تصویر مهم باشد, قائدتا برای سایر مکانها در تصویر هم باید بواسطه ساختار translationally-invariant تصاویر مفید باشد. بنابر این دیگر نیازی به یادگیری دوباره کشف لبه افقی برای تک تک ۵۵×۵۵ مکان مشخص در توده خروجی لایه کانولوشن نیست. یعنی لازم نیست تا این عمل یادگیری کشف لبه افقی برای تک تک مکان ها تکرار شود.
توجه کنید که بعضی اوقات فرض اشتراک پارامتر ممکن است منطقی بنظر نیاید. خصوصا زمانی که تصاویر ورودی به یک شبکه کانولوشن دارای ساختارهای وسط چین (specific centered structure) خاص باشند, که ما باید انتظار داشته باشیم , بعنوان مثال ویژگی های مختلفی از یک طرف تصویر نسبت به طرف دیگر یاد گرفته شود. یک نمونه عملی از این مورد زمانی است که تصاویر صورت وسط چین شده اند. ممکن است ما انتظار داشته باشیم که ویژگی های مختلف مخصوص مو (hair specific) و یا مخصوص چشم (eye-specific) بتوانند ( و باید) در موقعیتهای مکانی مختلف یاد گرفته شوند. در این حالت معمولا رایج است که طرح اشتراک پارامتر را کنار گذاشته و بجای آن خیلی ساده به آن لایه بصورت محلی متصل (Locally connected layer)گفته شود.
برای اینکه مطالبی که تا بحال بیان شد را بهتر درک کنیم در اینجا سعی میکنیم مفاهیم بیان شده را در قالب کد بیان کنیم . برای اینکار از زبان پایتون استفاده میکنیم که امروزه یکی از زبانهای بسیار پرکاربرد خصوصا در زمینه Deep learning و شبکه های کانولوشن است.
ما برای راحتی هرچه بیشتر از کتابخانه Numpy استفاده میکنیم که یکی از کتابخانه های مشهور پایتون در زمینه کار با عملیاتهای برداری است.سینتکس این کتابخانه هم شبیه به متلب بوده و کسانی که با متلب آشنایی دارند براحتی دستورات معادل را درک میکنند.
فرض کنید توده ورودی ما یک آرایه با نام X باشد. در اینصورت :
- برای بدست آوردن یک depth column در موقعیت (x,y) از دستور X [ x , y , : ] استفاده میکنیم
- برای بدست آوردن یک برش عمقی (depth slice) یا بطور مساوی همان نگاشت فعال سازی(activation map) در عمق d از دستور X[ : , : , d ] استفاده میکنیم.
فرض کنید توده ورودی X دارای ابعاد X.shape: (11,11,4) باشد این دستور یعنی توده ای با اندازه ۱۱x11x4 ایجاد شود که به معنای عرض و ارتفاع ۱۱ و عمق ۴ میباشد. حال فرض کنید ما از Zero padding استفاده نکنیم ( یعنی P=0 ) و اندازه فیلتر (یا همان ناحیه ادراکی ) برابر با F = 5 و stride هم برابر S = 2 باشد. با توجه به این اطلاعات ما میتوانیم اندازه مکانی (یعنی عرض و ارتفاع) توده خروجی را بدست بیاوریم . اندازه توده خروجی برابر ۴=۱+۲/(۵-۱۱) خواهد بود که به معنای توده ای با عرض و ارتفاع ۴ است . نگاشت فعال سازی (Activation map) نیز در توده خروجی (که از این به بعد به آن V میگوییم ) بصورت زیر خواهد بود ( دقت کنید ما تنها بعضی از محاسبات را در مثال زیر قید میکنیم)
- V[0,0,0] = np.sum(X[:5,:5,:] * W0) + b0
- V[1,0,0] = np.sum(X[2:7,:5,:] * W0) + b0
- V[2,0,0] = np.sum(X[4:9,:5,:] * W0) + b0
- V[3,0,0] = np.sum(X[6:11,:5,:] * W0) + b0
ذکر این نکته ضروری است که در numpy عملیات ضرب (*) که در بالا شاهد آن هستید عمل ضرب خانه به خانه (elementwise) را در آرایه انجام میدهد. نکته دیگر آنکه بردار وزن W0 بردار وزن مربوط به نورون ۰ بوده و b0 هم بایاس مربوط به آن میباشد. در اینجا فرض کردیم W0 ابعادی بصورت ۵x5x4 دارد . (W0.shape: (5,5,4) ) , چرا که اندازه فیلتر (یا همان ناحیه ادراکی) برابر با ۵ بوده و عمق توده ورودی نیز برابر با ۴ است. توجه کنید که در اینجا ما همانند شبکه های عصبی معمولی ضرب نقطه ای را انجام میدهیم. همچنین در اینجا مشاهده میکنید که ما در حال استفاده از یک وزن و بایاس هستیم (بواسطه اشتراک پارامتر) و ابعاد در راستای عرض در گام های ۲ تایی (مقدار Stride) افزایش پیدا میکنند. به منظور ساختن نگاشت فعال سازی(Activation map) دوم در توده خروجی بصورت زیر عمل میکنیم :
- V[0,0,1] = np.sum(X[:5,:5,:] * W1) + b1
- V[1,0,1] = np.sum(X[2:7,:5,:] * W1) + b1
- V[2,0,1] = np.sum(X[4:9,:5,:] * W1) + b1
- V[3,0,1] = np.sum(X[6:11,:5,:] * W1) + b1
نمونه ای از حرکت در راستای y:
- V[0,1,1] = np.sum(X[:5,2:7,:] * W1) + b1
نمونه ای از حرکت در هر دو راستای x وy:
- V[2,3,1] = np.sum(X[4:9,6:11,:] * W1) + b1
جایی که مشاهده میکنید ما در حال اندیس گذاری در بُعد عمقی دوم در V (اندیس ۱ ) هستیم به این خاطر است که ما در حال محاسبه نگاشت فعال سازی دوم (Activation map) هستیم و به همین دلیل مجموعه متفاوتی از پارامترها (W1) باید استفاده شود. در مثال بالا ما بخاطر خلاصه سازی از نوشتن تمامی عملیات هایی که در لایه کانولوشن برای پر کردن باقی بخش های آرایه خروجی V صورت میگیرد پرهیز کردیم. علاوه بر آن بیاد داشته باشید که این نگاشتهای فعال سازی (Activation maps) اغلب بصورت خانه به خانه توسط یک تابع فعال سازی مثل ReLU مورد پردازش قرار میگیرند (تا خروجی نهایی تشکیل شود) اما این مسئله در اینجا نشان داده نشده است.
خلاصه
در اینجا ما بصورت خلاصه مطالبی که در بالا به آن پرداختیم را مرور میکنیم
یک شبکه کانولوشن :
یک توده با اندازه W1 x H1 x D1 را بعنوان ورودی دریافت میکند که W نشانگر عرض , H نشانگر ارتفاع و D نشانگر عمق آن میباشد.
نیازمند ۴ فراپارامتر(Hyper parameter) است :
- تعداد فیلتر ها K
- اندازه وسعت مکانی(اندازه x , y) فیلترها )اندازه ناحیه ادراکی) F
- اندازه گام یا Stride S
- مقدار Zero padding P
تولید یک توده خروجی با اندازه W2 x H2 x D2 که :
- W2=(W1-F+2P)/S+1
- H2=(H1-F+2P)/S+1 (یعنی عرض و ارتفاع هر دو بطور مساوی بصورت متقارن محاسبه میشوند)
- D2=K
با اشتراک پارامتر, دارای F.F.D1 وزن به ازای هر فیلتر بوده که در کل F.F.D1).K) وزن و K بایاس میباشد.
برش dام ( با اندازه W2 X H2 ) ,در توده خروجی نتیجه انجام یک ضرب (convolution) معتبر بین فیلتر dام با توده ورودی با stride S بوده که سپس با بایاس d ام جمع شده است.
یک نمونه از مقادیر رایج برای فراپارامترهای توضیح داده شده در بالا بصورت F=3,S=1,P=1 است. البته شیوه ها و قوانین متداولی وجود دارند که باعث رسیدن به این مقادیر میشوند. (بخش معماری شبکه کانولوشن را برای اطلاعات بیشتر ببینید)
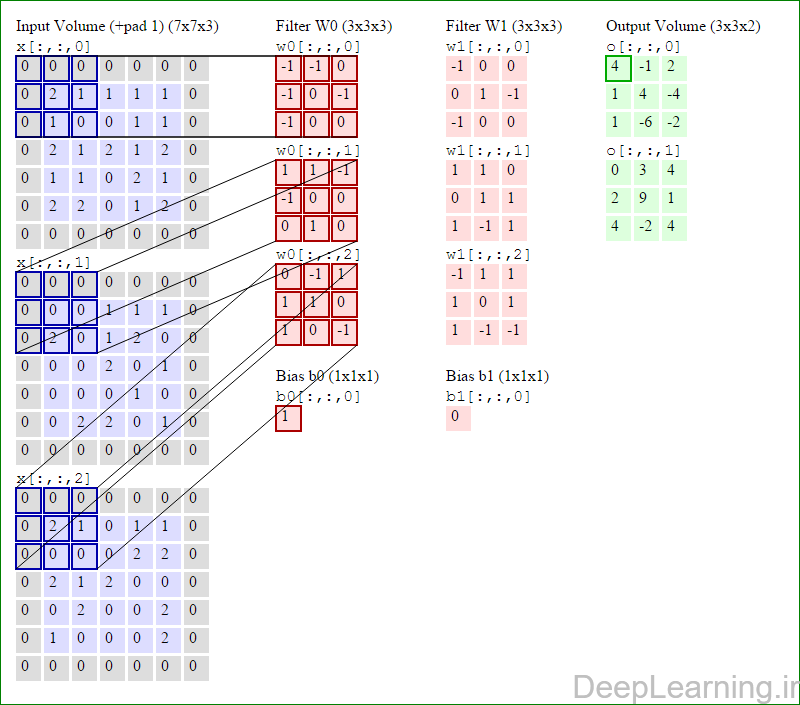
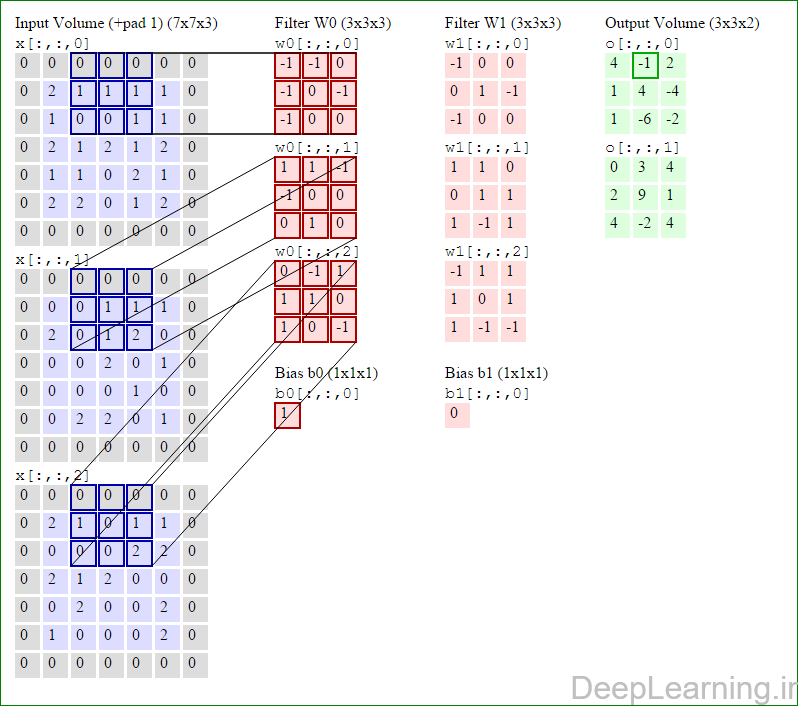
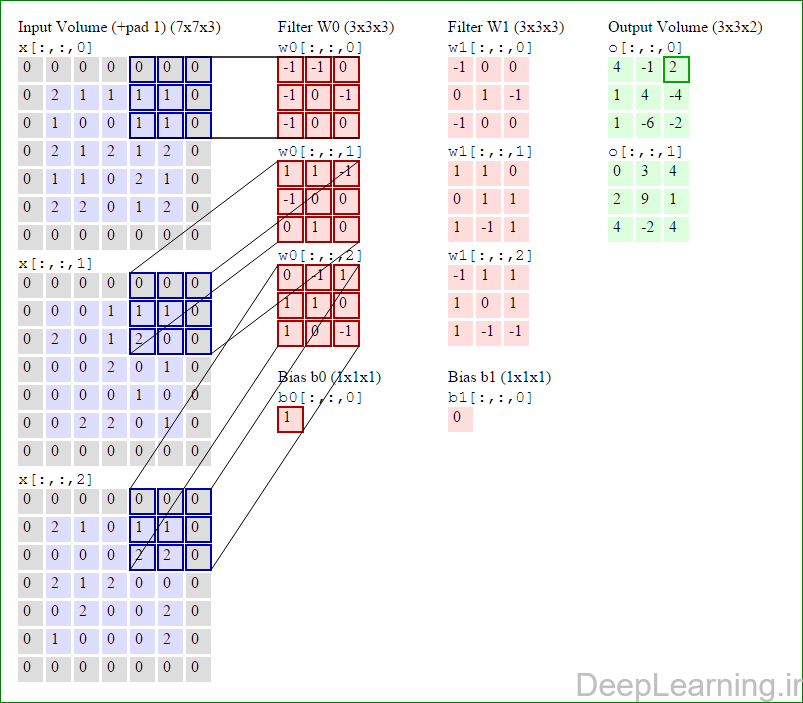
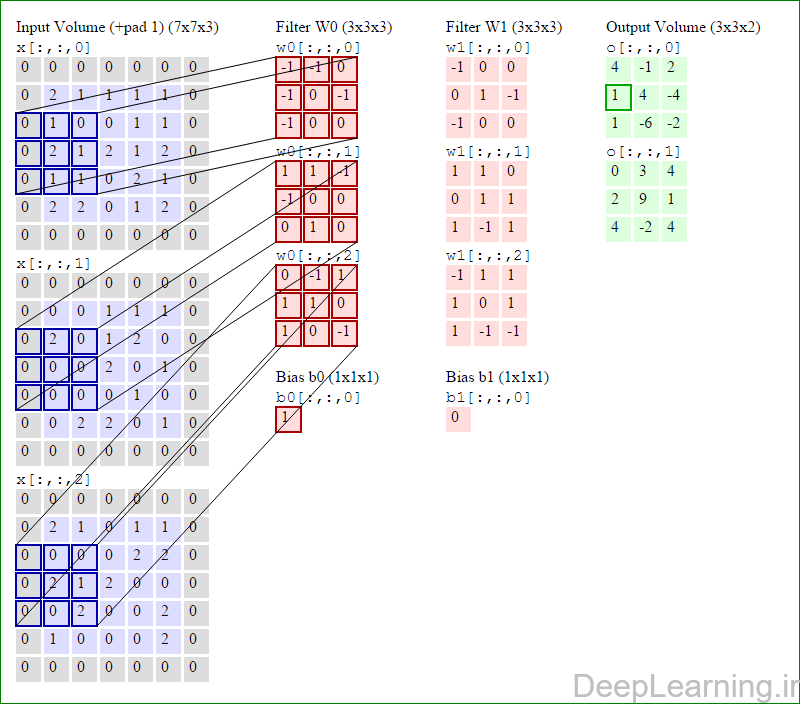
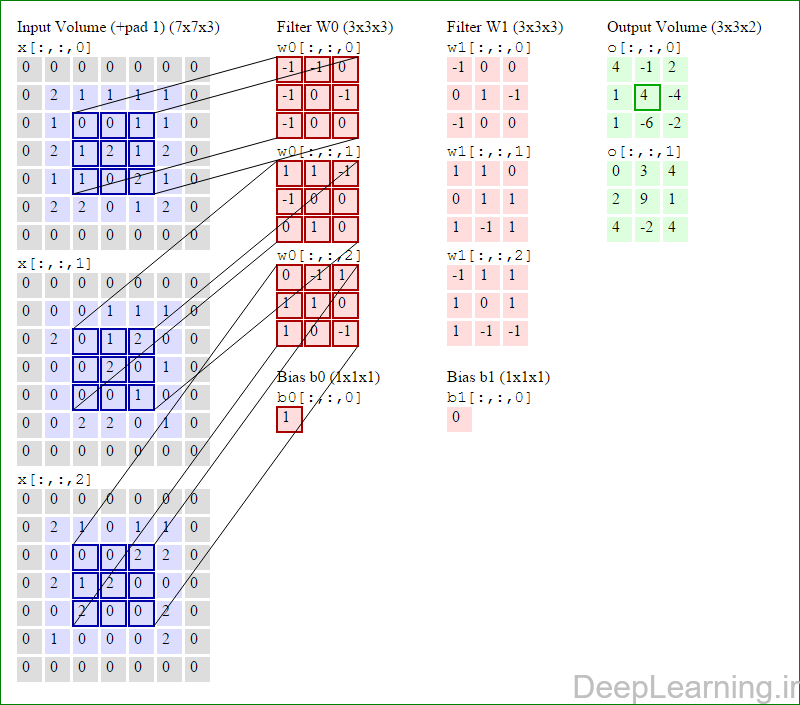
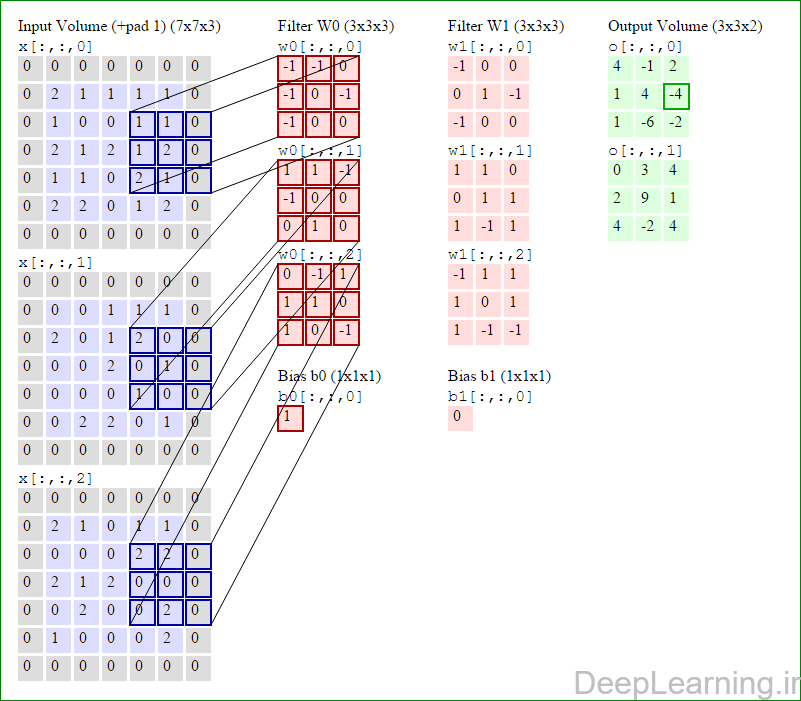
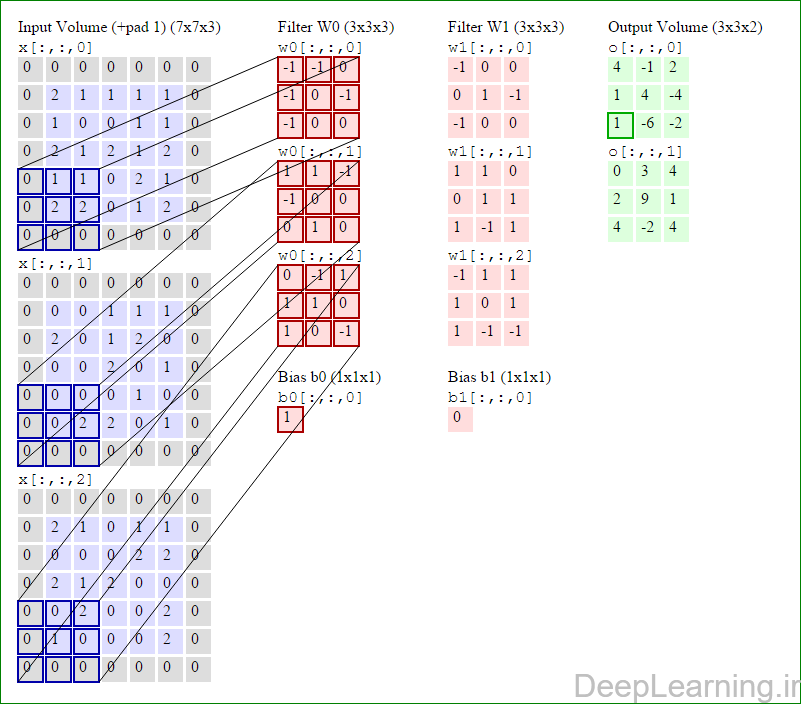
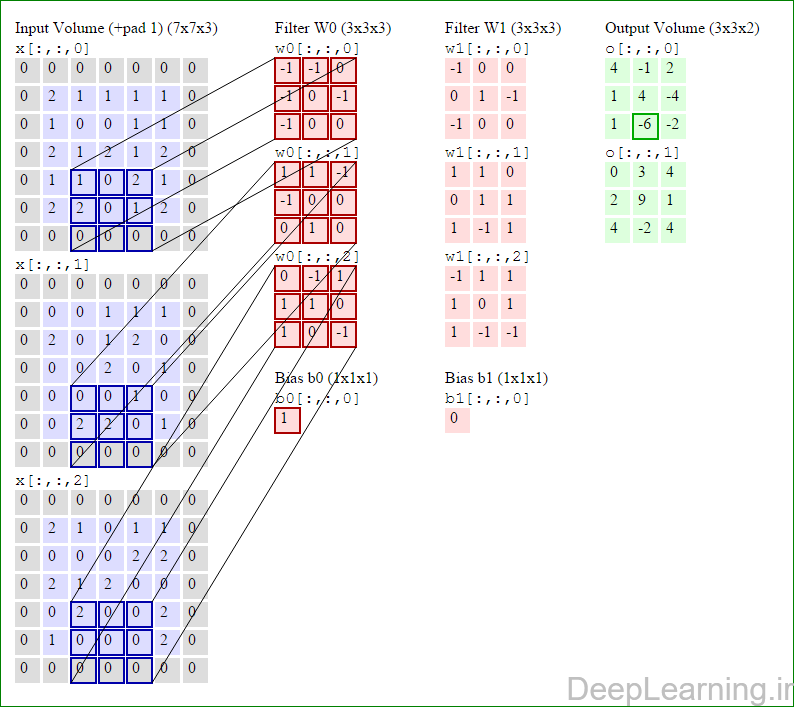
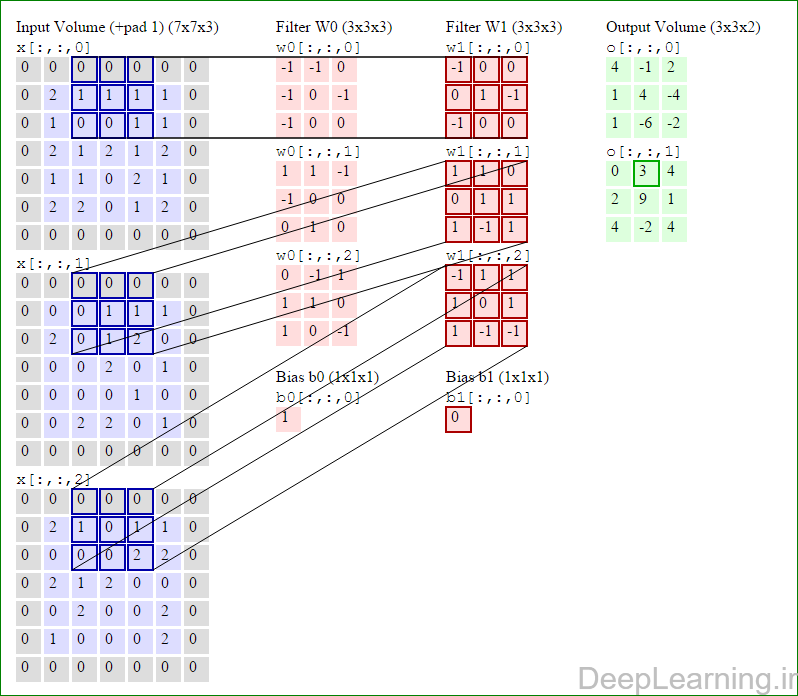
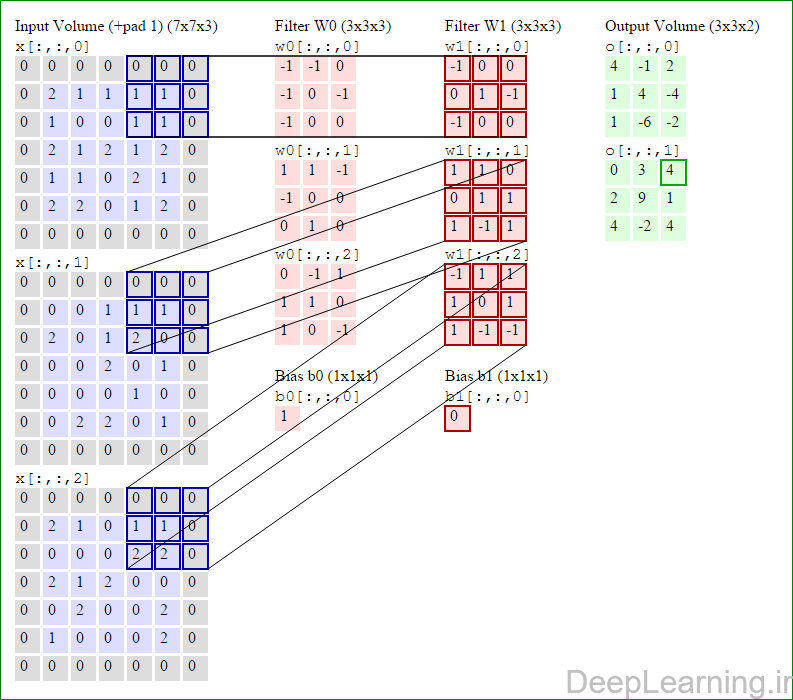
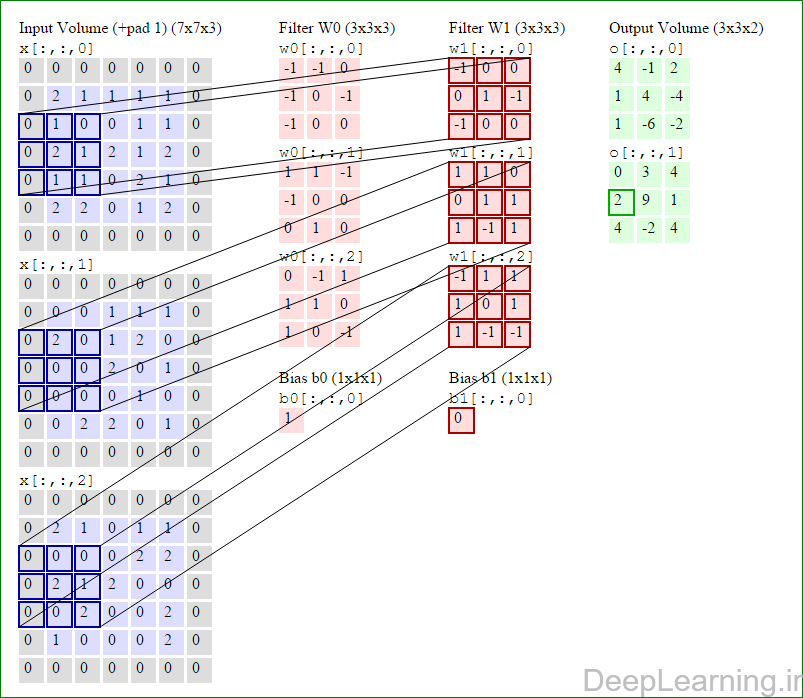
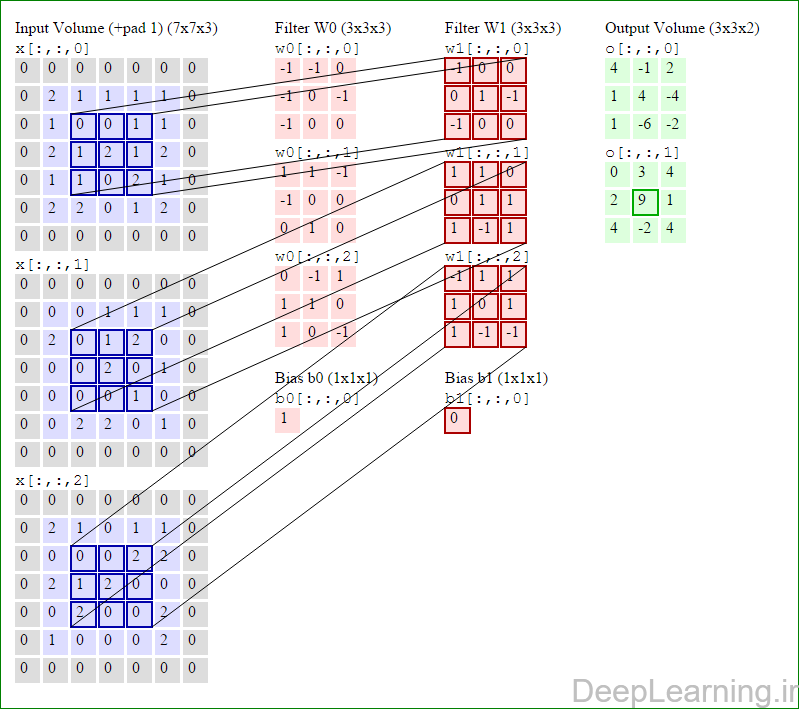
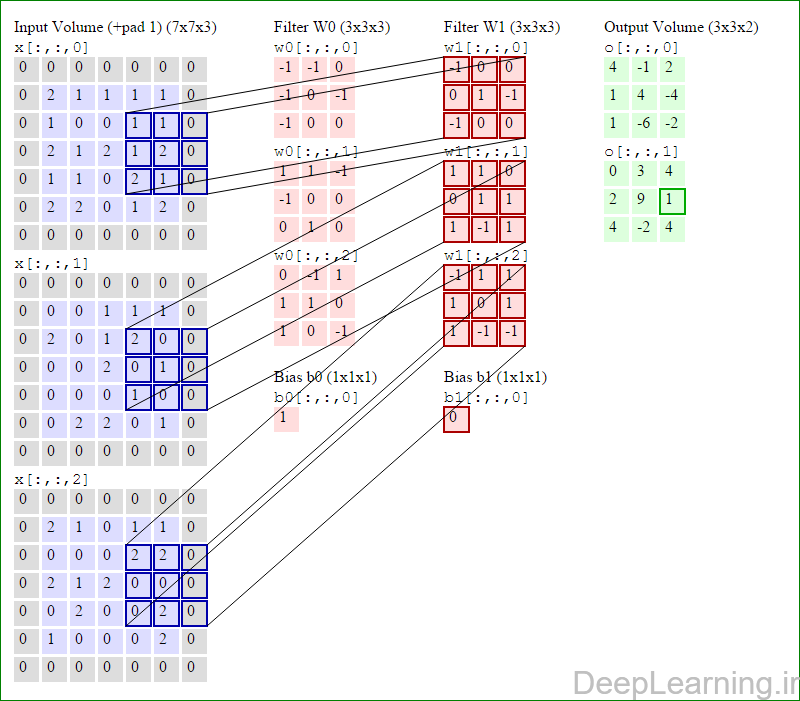
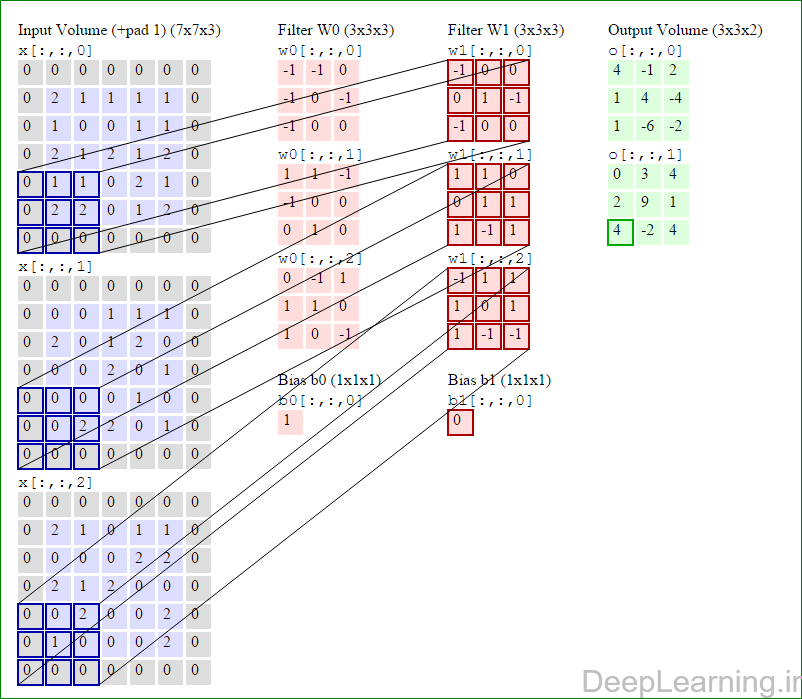
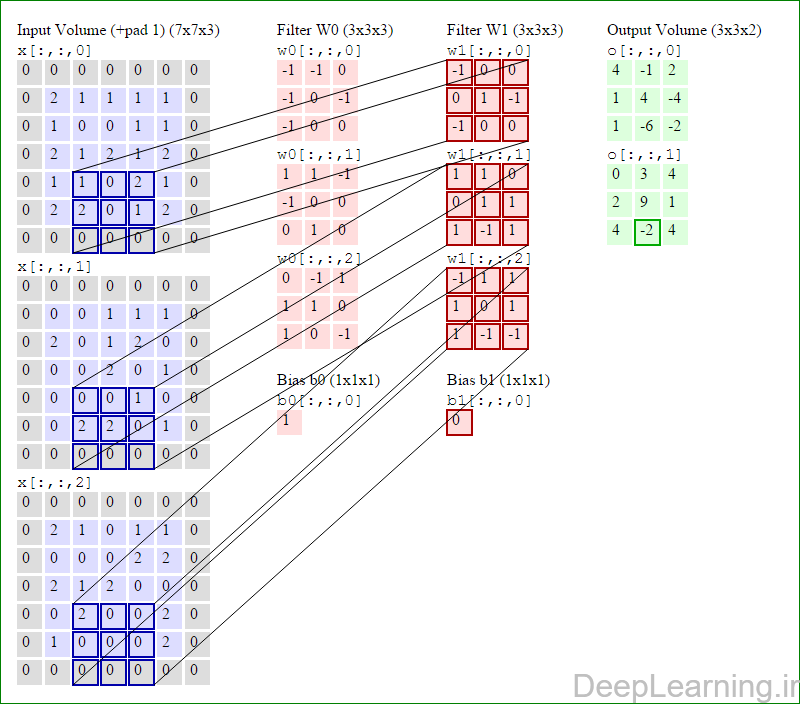
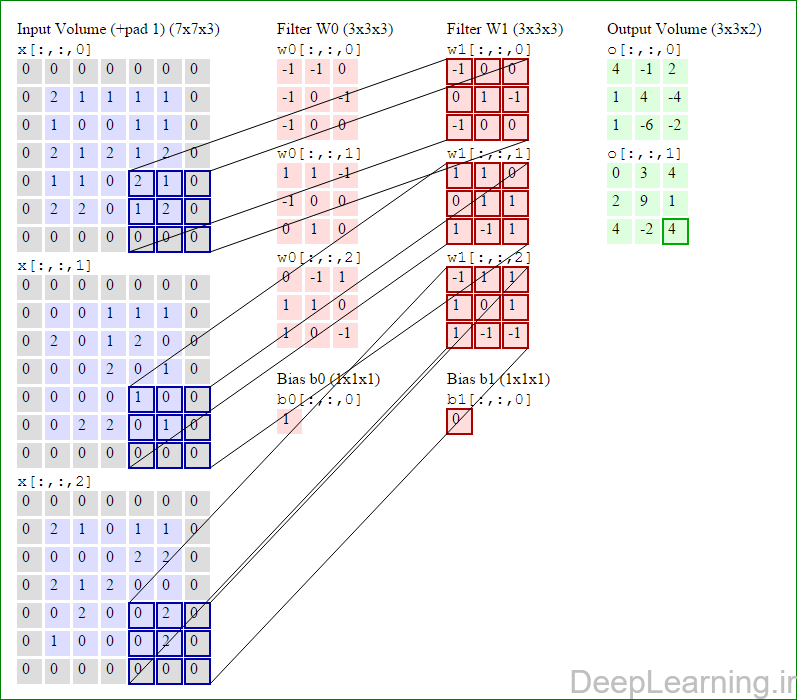
در این قسمت ما نحوه فعالیت صورت گرفته در یک لایه کانولوشن را گام بگام توسط تصویر نشان میدهیم . بخاطر اینکه نمایش حجم های سه بعدی کمی مشکل است تمام توده های سه بعدی (توده ورودی (با رنگ آبی ) , توده وزن ها ( با رنگ قرمز) و توده خروجی (با رنگ سبز) ) بصورت برش هایی نمایش داده شده اند. اندازه توده ورودی برابر با W1 = 5, H1 = 5,D1= 3 میباشد( به ترتیب معرف عرض, ارتفاع و عمق) , پارامترهای لایه کانولوشن نیز به ترتیب برابر با K=2 , F = 3 , S = 2 و P =1 میباشند که به معنای آن است که ما دو فیلتر با اندازه ۳×۳ داریم که با گام (stride) S =2 بر روی توده ورودی اعمال میشوند. بنابر این اندازه توده خروجی ما هم برابر با ۳=۱+ ۲/(۲+۳-۵) خواهد بود. علاوه بر این , توجه کنید که عمل Padding با مقدار P=1 بر روی توده ورودی اعمال شده که این عمل باعث ۰ شدن مرز های بیرونی توده ورودی شده است. در تصاویر زیر میبینید که تعداد تکرار عملیات به اندازه تعداد عناصر موجود در توده خروجی( به رنگ سبز) است در تصویر مشاهده میکنید که هر عنصر در توده خروجی از ضرب عنصر به عنصر توده وزن (ماتریس وزن برنگ قرمز ) با توده ورودی (برنگ آبی) و سپس جمع تمامی عناصر با هم و نهایتا افزودن بایاس به نتیجه نهایی بدست می آید.(Convolution) بعنوان مثال برای عنصر اول توده خروجی داریم :
( (۰*-۱)+(۰*-۱)+(۰*۰)+(۰*-۱)+(۲*۰)+(۱*-۱)+(۰*-۱)+(۱*۰)+
(۰*۰))+( (۰*۱)+(۰*۱)+(۰*-۱)+(۰*-۱)+(۰*۰)+(۰*۰)+(۰*۰)+(۲*۱)+
(۰*۰))+( (۰*۰)+(۰*-۱)+(۰*۱)+(۰*۱)+(۲*۱)+(۱*۰)+(۰*۱)+(۰*۰)+
(۰*-۱) )+۱=۴


پایان بخش دوم آموزش
سید حسین حسن پور
بهار ۹۵
بخش سوم رو هم انشاالله سر فرصت میزارم .
تو بخش سوم در مورد معماری ها و… بیشتر توضیح میدم
سلام . من یه سوال داشتم. منظور از این قسمتو نمیفهمم”توجه کنید که بعضی اوقات فرض اشتراک پارامتر ممکن است منطقی بنظر نیاید.” میشه یکم بیشتر توضیح بدید.یعنی چی موقعیت مکانی تصویر در کانولوشن در نظر گرفته نمی شه؟؟؟؟؟؟
سلام.
اون بخش داره میگه که فرض اشتراک پارامتر در زمانی که نیاز به جزییات بیشتری از ورودی در مکانهای مختلف هست استفاده نمیشه (نشه بهتره و بجاش) باید از locally connected layer بدون اشتراک وزن استفاده کرد.
این نکته مهمه که دقت کنید لایه کانولوشن هم یک لایه locally connected هست (برخلاف fully connected layer ) که و نورونها تنها به یک ناحیه از ورودی متصل هستن با اندازه receptive field (همون F که اندازه فیلتر ما رو مشخص میکرد).
حالا فرقشون چیه؟
تو لایه کانولوشن ما اشتراک پارامتر داریم . یعنی یه فیلتر یکسان روی تمامی پیکسلهای ورودی اعمال میشه.این فیلتر هم یه ماتریس وزن بیشتر نداره . پس همه پیکسلهای ورودی از وزنهای فیلتر بصورت اشتراکی استفاده میکنن. و ما طی آموزش به شبکه اجازه میدیم که این وزنها رو کم و زیاد کنه تا نهایتا به نتیجه مورد نظرمون برسیم. (عملیاتی هم که انجام میشه ضرب نقطه ای بین پیکسل و این فیلتر جمع نتیجه حاصل هست(که میگیم کانولوشن انجام دادیم).این عمل کانولوشن ما باعث ارائه یه translation invariance هم میشه. در قضیه لایه بصورت محلی متصل بدون اشتراک وزن کاری که کردن اینه که برخلاف قبل هر پیکسل درورودی یه فیلتر(ماتریس وزن) اختصاصی داره . یعنی مثلا اگر ما تصویر ورودی با اندازه ۱۲۸ در ۱۲۸ داشته باشیم . و تعداد ۲۵۶ فیلتر با اندازه ۵*۵ داشته باشیم میشه ۱۲۴ فیلتر رو روی تصویر ورودی جا داد و اعمال کرد (با گام ۱ اگه در نظر بگیریم) پس ما اینجا ۱۲۴*۱۲۴*۲۵۶*۵*۵ پارامتر داریم که باید محاسبه بشن و این درحالیه که در لایه کانولوشن ما فقط ۲۵۶*۵*۵ پارامتر داشتیم که باید train میشدند. نکته دیگه هم اینه که تو لایه Locally connected بدون اشتراک وزن ما عمل کانولوشن نداریم (یعنی ضرب نقطه ای و بعد جمع همه اعداد باهم) و فقط شرب نقطهای بین پیکسلهای ورودی با ماتریس وزن هرکدوم هست.
این قضیه تو DeepFace فکر میکنم اولین بار مطرح شد و نتایج خیلی خوبی هم تو دسته بندی تصاویر بدست آورد. متاسفانه تو Caffe هنوز پیاده سازی نشده و منم تست نکردم . اما تو Cuda-convnet و فکر میکنم Torch پیاده سازی شده.
بخش دوم صحبتتون رو هم متوجه نشدم . لطفا کامل بنویسید یا متن کامل رو قرار بدید تا توضیح بدم خدمتتون .
۱٫خب وقتی به جای لایه کانولوشن، لایه locally connected استفاده میشه دیگه این شبکه عصبی کانولوشنی نیست درسته؟۲٫ پس میتونیم بگیم شبکه کانولوشن برای وقتی که من میخوام رنگ چشم یک عکس رو بدونم کارایی خوبی نداره ولی برای تشخیص چهره که انسانه یا حیوان کاراییش خوبه؟ ۳٫اینکه چرا در جزئیات کارای خوبی نداره به دلیل اشتراک پارامتره .و اینکه خاصیت اشتراک پارامتر چیه؟(اشتراک پارامتر چجوریه که باعث میشه جزئیات از دست برن؟)
۴٫چرابه این نتیجه رسیدن که از اشتراک پارامتر استفاده کنن؟ و هدف هم کاهش تعداد پارامتر هاست فقط!
۵٫در قسمت قبل هم گفتین لایه ادغام پارامتر نداره یعنی چی؟ خب نرون های لایه کانولوشن که با روش های ادغام وصل میشن به یک نرون در لایه ادغام به هر کدوم یه وزنی میدیم دیگه. مثلا تو maxpooling به نرونی که مقدار تابع فعال سازیش بیشتره وزن یک و میدیم به بقیه صفر وصل میشن به یه نرون تو لایه ادغام درسته؟
۶٫ convolutional networks are well adapted to the translation invariance of images: move a picture of a cat (say) a little ways, and it’s still an image of a cat* *In fact, for the MNIST digit classification problem we’ve been studying, the images are centered and size-normalized. So MNIST has less translation invariance than images found “in the wild”, so to speak. Still, features like edges and corners are likely to be useful across much of the input space.
و اینو نمیفهمم! یعنی شبکه کانولوشن به تغییر جای شکل ها تو تصویر حساسیت نداره ولی شبکه عصبی معمولی حساسیت داره؟
سلام
اگر اصلا استفاده نشه درسته ولی در عمل این لایه به همراه لایه کانولوشن و بقیه لایه ها استفاده میشه . مثل لایه fully connected . (البته تو دیپ لرنینگ همیشه از شبکه کانولوشن استفاده نمیشه .میتونید از انواع دیگه هم استفاده کنید.)
بزارید اینطور جواب بدم در حالت کلی حرف شما درسته. وقتی نوبت به تصاویر صورت میرسه برای اینکه ویژگی های مختلف تو تصویر (مثل چشم و بینی و…) در جاهای مختلف یادگرفته بشن از اشتراک پارامتر استفاده نمیشه. از همون Locally connected layer بدون اشتراک وزن استفاده میشه.
و از اشتراک پارامتر معمولا در تصاویر طبیعی یا کلا Object recognition بطور کل استفاده میشه و منطقش هم به این شکل هست که خب من با یه تصویر مواجه هستم پس قائدتا منطقیه که یک ویژگی از بخشهای مختلف تصویر استخراج بشه . برای همین اشتراک وزن وجود داره و از این طریق فیلتر یکسانی که برای استخراج یک ویژگی استفاده میشه روی تمام تصاویر اعمال میشه و اینطور ویژگی مرتبط با اون فیلتر در بخشهای مختلف تصویر استخراج میشه.
از طرفی تا بحال برای اینکه دقت و کارایی تشخیص افزایش پیدا بکنه از افزایش عمق استفاده کردن . یعنی هرچقدر شما عمق شبکه خودتون رو بیشتر کنید جزییات و ویژگی های سطح بالاتری رو بدست میارید و میتونید استفاده کنید.
چیزی که من میتونم بگم اینه که احتمالا شما میتونید به همون دقتی که از طریق locally connected layer بدست میارید از طریق شبکه کانولوشن با عمق بیشتر بدست بیارید. ولی خب هزینه و مسائلی مثل overfitting و… مسائل مربوط به شبکه های عمیق رو هم باید تحمل کنید.
از طرفی تو لایه تماما متصل شبکه مجبور هست که ویژگی های مختلف رو تو جاهای مختلف تصویر بطور مجزا یادبگیره. مثلا صد جا دقیقا یه edge detector یکسان رو یاد بگیره در حالی که این قضیه در شبکه کانولوشن اینطور نیست و ما میگیم اگر یه جا edge detector مفید بود احتمالا جاهای دیگه هم هست و اینجاس که فیلترها با مفهوم اشتراک وزن معنا پیدا میکنن. یه نکته دیگه اینه که لایه های تماما متصل ویژگی های خاص تصاویر رو در نظر نمیگیرن و مثلا پیکسلهای کنار هم در ورودی رو با پیکسلهایی که از هم کاملا فاصله دارن یکجور برخورد میکنن باهاشون و این مساله باعث میشه استفاده از شبکه های تماما متصل تو بحثهای مربوط به تشخیص تصاویر بخوبی عمل نکنه و تعداد زیاد پارامترها هم خیلی سریع باعث over-fitting بشه.
دلیل دیگه استفاده از اشتراک وزن همون بحث کاهش تعداد پارامترها هست که خودتون اشاره کردید. این مساله هم سرعت پردازش رو خیلی خوب کرد و هم تو جلوگیری از over-fitting خیلی مفید هست.
۵٫ منظور از پارامتر نداشتن اینه که واقعا پارامتر (قابل یادگیری) نداره که در اموزش دخیل باشه یا بخواد بروز بشه . صرفا یه عملیات هست که روی خروجی توده ها اعمال میشه. اینو در مقابل پارامترهای قابل یادگیری بقیه شبکه قرار بدید متوجه میشید .
بعد اینکه نرونهای لایه کانولوشن وصل نمیشن به نورونهای موجود در لایه ادغام !. اصلا ضربی انجام نمیشه . فقط ماکسیمم اون ناحیه حساب میشه و در خروجی قرار میگیره.
۶٫بله . شبکه کانولوشن همونطور که بالا توضیح دادم translation invariance ارائه میکنه که اونم بخاطر در نظر گرفتن ماهیت محلی نواحی در تصاویر (و عملیات کانولوشن) هست. این قضیه در مورد شبکه عصبی معمولی که هیچکدوم از خاصیتهای تصاویر رو در نظر نمیگیره و یه ضرب نقطه ای صرف انجام میده صادق نیست.
یه نکته دیگه یادم رفت. ضمنا من نگفتم شبکه کانولوشن در جزییات کارایی خوبی نداره!! برای اینکه جزییات بیشتری از تصویر ورودی کشف بشه عمق شبکه کانولوشن رو زیاد میکنن. هرچقدر عمق بیشتر باشه ویژگی های سطح بالای بیشتری شناسایی میشه (مثل چشم بینی و ویژگی ها و جزییات بیشتر) پس شما کما کان میتونید بنظر من بدون استفاده از Locally connected layer بدون اشتراک وزن به نتیجه خوبی برسید اما! نکته اینجاست که ممکنه با استفاده از لایه بصورت محلی متصل بدون اشتراک وزن طی عمق خیلی کمتری به اون نتیجه برسید چون ویژگی های بیشتری رو بدست میده.
و نکته دیگه که یادم رفت بگم هم اینه که translation invariance در لایه بصورت محلی متصل بدون اشتراک وزن وجود نداره! و دلیل استفاده اش هم (احتمالا)بخاطر همین قضیه اس تا اینطور ویژگی های خاص در بخشهای مختلف یادگرفته بشه.
اولا خیلی ممنونم که به سوالام با حوصله و دقت پاسخ میدید.
۱من همین مفهوم translation invariance رو نمیدونم یعنی چی؟
۲و اینکه ما وقتی یک فیلتر اعمال میکنیم و یه feature map تو لایه کانولوشن ساخته میشه میگیم این فیچر مپ داره یک ویژگی را در مکان های مختلف تصویر ورودی نشون میده یعنی مثلا یک فیلتر میاد یه ویژگی مثل edge detector را در مکانهای مختلف تصویر بهمون میده بعد فیلتر دیگ یه ویژگی دیگه از تصویر رو میده پس اینم داره یه ویژگی رو تو مکانهای مختلف تصویر به دست میاره پس اینکی که شما میگین (از طرفی تو لایه تماما متصل شبکه مجبور هست که ویژگی های مختلف رو تو جاهای مختلف تصویر بطور مجزا یادبگیره. مثلا صد جا دقیقا یه edge detector یکسان رو یاد بگیره ) چه فرقی داره؟
۳٫و اینک توی آموزش شبکه مثلا با back propagation مگه ما نمیاییم خروجی هر نرون رو تو لایه کانولوشن با ضرب نرون هایی که تولایه قبلن در وزنشون و اعمال تابع فعال سازی به دست می آوریم. حالا باید بیاییم خروجی هر نرون را در لایه ادغام هم به دست بیاریم اینجا خروجی را چطور به دست می یاریم تا آخرش مقدار نرون های لایه خروجی مونو به دست بیاریم منهای مقدار هدف کنیم و بیاییم وزنها رو آپدیت کنیم.
میشه لطف کنید مرحله آموزش رو توضیح بدید.
مرسی از لطفتون
سلام خواهش میکنم .

۱٫ من بک گراند کامپیوتر ویژن ندارم اما چیزی که خودم فهمیدم از مقالات منظور این هست که یک تصویر اگر جابجا بشه (شیفت پیدا کنه) مشکلی تو تشخیصش نباشه .
ببینید وقتی شما یه تصویر دارید مثل این :
حالا اگه اون رو به چپ چند پیکسل شیفت بدید از لحاظ مقادیر پیکسل ها تصویر کاملا عوض شده درسته ؟
و این
اما ما میتونیم ببینیم که تصویر همون تصویره. تشخیص ماهیت یک تصویر با توجه به تمام اینگونه تغییراتی که روی اون اعمال شده رو میگن translation invariance برای توضیحات بیشتر اینوببینید خیلی خوبه .
(من سوال کردم تعریف دقیقتری که یکی از دانشجوهای هوش مصنوعی بمن دادن اینه :
(انتقال(translation) تصویر در واقع همه ی پیکسل های تصویر به اندازه ی ثابتی در جهت خاصی انتقال پیدا میکنن .)
کلا invariance که میاد یعنی بی تفاوتی نسبت به اون بخش اول (در اینجا translation یا انتقال در یک جهت خاص). rotation invariance هم یعنی بی تفاوت نسبت به چرخش. view invariance هم یعنی بی تفاوت نسبت به دیدهای مختلف! و الخ)
۲٫فرقش در اینه که ما یکبار یه edge decector یادمیگیریم و بعد برای بقیه جاها ازش استفاده میکنیم اما تو شبکه عصبی تماما متصل دقیقا مثلا یک edge detector چندیدن بار یادگرفته میشه اونم در جاهای مختلف تصویر که نیازی اصلا به این کار نیست. وقتی یکبار انجام شده و دقیقا همون هست چرا باید هزینه پردازشی متقبل بشیم برای یادگرفتن دوباره و چندین باره عینا همون ویژگی ؟
۳٫رو متوجه نشدم چی نوشتین . مشکلتون کجاست؟ مرحله آموزش رو نمیدونید چطور انجام میشه ؟ یا بک پراپگیشن رو نمیدونید چطور انجام میشه ؟
اینو فهمیدم از طرفی تو لایه تماما متصل شبکه مجبور هست که ویژگی های مختلف رو تو جاهای مختلف تصویر بطور مجزا یادبگیره. مثلا صد جا دقیقا یه edge detector یکسان رو یاد بگیره یعنی اینکه تو این شبکه یه ویژگی تکراری در یه مکان از تصویر چند بار یاد گرفته میشه . ولی سوال ۱ و۲ رو میشه بگید
اینو جواب دادم . اگر متوجه نشدید دوباره بفرمایید تا یه طور دیگه توضیح بدم.
من آموزش شبکه کانولوشنو با بک پراپگیشن میگم. مثلا ببینید میخاییم اینکارو بکنیم. هر واحد درلایه کانولوشن سیگنال های ورودی وزن دار خود را جمع می بندد و از تابع فعال سازی هیپربولیک برای محاسبه سیگنال خروجی استفاده می کند و این سیگنال به لایه ادغام فرستاده می شود.خب بعد شما میگید لایه کانولوشن به لایه ادغام وصل نیست بعد چجوری خروجی لایه ادغام محاسبه میشه میره به لایه خروجی؟؟؟؟؟ که لایه خروجی هم سیگنال های ورودی وزن دار خود را جمع می بندد و از تابع فعال سازی هیپربولیک برای محاسبه سیگنال خروجی استفاده می کند. و نتیجه فعال سازی محاسبه شده برای هر واحد خروجی با مقدار هدف مقایسه می شود و خطای مربوط به آن الگو برای هر واحد به دست می آید تا برای آپدیت وزنها استفاده شه. یعنی هیچ وزنی بین لایه ادغام و کانولوشن نیست؟
نه من منظورم این نبود که وصل نیست! منظورم در جواب شما بود که وزن و ضرب در نظر گرفته بودید بین این دو!
لایه ادغام در اصل داره عمل subsampling رو انجام میده . یعنی خروجیش همون خروجی لایه قبلشه که یک عملیات max ,min یا AVE یا هر عملیات دیگه ای دوباره انجام میشه تا توده جدید اندازه مکانیش کاهش پیدا کنه و توده جدید بدست بیاد
بعد این توده به لایه بعدی متصل میشه همین!
شما اینو دقیقا مثل Relu یا tanh در نظر بگیرید که روی تک تک نورونها اعمال میشدن.(تابع فعال سازی) (این حالا با یه فیلتر اعمال میشه رو توده قبل خودش). فک کنید بعد tanh یه تابع دیگه دارید بنام maxpooling مثلا. همین!
نه هیچ وزنی بین لایه ادغام (pooling ) و کانولوشن نیست.
ضمنا یه نکته مهم دیگه الان دیگه از اون Tanh استفاده نمیکنن!
پس چرا تو این مقاله(Implementation of Training Convolutional Neural Networks)
اومده تو آموزش وزنهای لایه ادغامم آپدیت کرده؟
متن اصلی یا خود مقاله رو لینک میکنید ؟
خیلی ممنونم از راهنمایی های شما واقعا سودمند و مفید بود تشکر
سلام
خواهش میکنم .
یک نکته فقط اگر مقالاتتون رو مثلا از سایت http://arxiv.org میگیرید دقت کنید تو منابع معتبر هم مقاله درج شده باشه . اگر نبود اون مقاله قابل استناد نیست.
تو این سایت هرکسی میتونه مقاله بزاره و صرفا وجود مقاله دلیلی بر صحت و یا درستی و معتبر بودن اون نیست .
از زحمتی که کشیدید و این مطالب ارزنده رو در اختیار همه قرار دادید بینهایت ممنون
بی صبرانه منتظر بخش سوم شبکه های کانولوشن هستیم
سلام.
خواهش میکنم .
خدا رو شکر که مفید واقع شد. انشاالله مباحث بعدی مثل بک پراپگیشن و توضیح بیشتر در مورد پیکربندی و طراحی یه مدل در شبکه کانولوشن و همینطور مسائلی مثل چطور بفهمم شبکه واقعا داره جواب درست بما میده یا نه رو تو بخش بعدی عرض میکنم .
متاسفانه الان بخاطر درگیری مراحل اخر پایان نامه ام وقت برای نوشتن ندارم انشاالله تموم شد این بخشها هم قرار میگیره.
اگر هم دیر جواب میدم ببخشید چون برای مدتی به اینترنت دسترسی ندارم .
سلام و روز بخیر
چند تا سوال داشتم از خدمتتون
اول اینکه ما پس از اعمال فیلترهای مختلف لایه کانولوشن (ر واقع اعمال کانولوشن روی تصویر ورودی با فیلتر های مختلف) به یه سری ماتریس میرسیم که الان این سری ماتریس اسمشون چیه؟ ویژگی های یادگرفته شده هستند؟ اسم اون فیلتر ها که با بک پروپگیشن وزن هاشون آموزش میبینن چی هست اسمشون؟ فیلترهای نهاییمون هستن؟
سوال دوم اینکه مقدار دهی اولیه وزن های فیلترهای لایه کانولوشن چجوریه؟ تصادفیه؟
سوال سوم اینکه نمیتونم درک کنم منظورتون از اینکه تو لایه اول ویژگی های سطح پایین یاد گرفته میشن بعد ویژگی های سطح بلا تو لایه های بالاتر چیه؟ منظورتون تو لایه های بالاتر لایه کانولوشن هست یا بجز اون لایه کانولوشن که خودش کلی لایه(فیلتر) داره میایم دوباره چند تا لایه کانولوشن(که هر کدوم چندتا فیلتر دارن ) میذاریم؟ اگه اینجوریه پس اونوقت باید بگیم ورودی های لایه کانولوشن دوم خروجی های لایه کانولوشن اول(خروجی فیلترهای لایه کانولوشن اول) هست؟
سوال چهارم اینکه منظورتون از pooling چیه؟ چجوری میاد ابعاد خروجی لایه کانولوشن رو کوچیک میکنه؟ میشه یه مثال بزنید؟
سوال پنجم اینکه میشه لطف کنید feed forward شبکه رو بنویسید؟ مثلا بگید خروجی لایه کانولوشن میره به یه تابع فعال سازی بعد تابع pooling بعد …(تا ما با ساز و کار شبکه بدون گیج شدن برخورد کنیم)
سوال ششم اینکه بعد تابع pooling یه سری فیچر(ویژگی) بدست میاد درسته؟ خب این ویژگی ها رو میدیم به یه شبکه عصبی معمولی دیگه تا دسته بندی کنه؟ آره؟ اگه آره لطفا بگید این شبکه عصبی معمولی چند لایست؟
سوال هفتم اینکه من الگوریتم بک پروپگیشن(یا اسم دیگرش پس انتشار خطا) رو بلدم اما میشه لطف کنید یک مثال از آپدیت کردن پارامترهای وزن های فیلتر های لایه کانولوشن رو اینجا قرار بدید؟
شرمنده سوال زیاد پرسیدم بنده تمام پست های شما رو مطالعه کردم و نظر دوستان رو هم همینطور،اما احسس من اینه که این قضیه برای بنده به خوبی جا نیوفتاده،ممنون میشم با پاسخ هاتون بنده رو در مسیر صحیح قرار بدین،در ضمن رشته من هوش هست
سپاسگذارم
سلام . روز شما هم بخیر
به اون ماتریس ها اصطلاحا میگن feature map . که این فیچر مپها رفته رفته با ضرب با وزنها باعث رسیدن ما به انتزاعات سطح بالا میشن.
فیتلتری که ازش صحبت میکنیم در حقیقت همون ماتریس وزن هست. که با عملیات بک پراپگیشن وزنها (و در صورت وجود بایاس ها) تنظیم میشن.
۲٫ بله وزن ها بصورت تصادفی مقداردهی میشن و روشهای مختلفی برای اینکار هست که برای معماری های عمیق Xavier تا بحال بهترین کارایی رو داشته.
۳٫ منظور همون لایه های بالاتر کانولوشن و تماما متصل هست. هر لایه کانولوشن یک تعداد فیچرمپ داره که از خصائص اون لایه کانولوشن هست.
کلا برای ساخت یه شبکه کانولوشن در ساده ترین حالتش سه نوع لایه داریم . لایه کانولوشن لایه pooling لایه تماما متصل.
حالا من میخوام یه شبکه کانولوشن بسازم کاری که میکنم اینه میام مثلا اینطور یه مدل برای خودم طراحی میکنم مثل زیر :
۸Cnn Relu 8pooling 16cnn Relu 16pooling 64Cnn Relu 64 pooling 128Cnn Relu 128pooling 256FullyConnected Relu 256FullyConnected Relu 10FullyConnected
همونطور که تو مثال بالا میبینی تعداد فیچرمپها (ouput) لایه کانولوشن و لایه پولینگ برابره چون لایه پولینگ فقط اندازه توده ورودی خودش رو کاهش میده . بعد از هر کانولوشن هم میبینی که یه لایه relu وجود داره (همون لایه Activation function هست که روی تک تک المنتهای توده ورودی خودش اعمال میشه . Relu هم یه تابع هست مثل Sigmoid ) . اون عددها که قبل از اسامی اومده نشونه تعداد خروجی های هر لایه است . لایه اخر هم ۱۰ تا خروجی داره چون مثلا این یه شبکه برای دسته بندی ۱۰ کلاس هست.(من پارامترهای دیگه مثل اندازه فیلتر ها و گامهاو… رو نیاوردم برای سادگی بیشتر)
۴٫فک کنم بالا مثالش اومده باشه! لایه pooling بسته به تابعی که انتخاب میکنید (مثلا Max یا Min یا Ave یا abs یا ….) و اندازه پنجره میاد کاهش اندازه انجام میده . مثلا فک کنید تابع ما Max هست و ما میخوایم یه لایه Max Pooling با اندازه فیلتر ۲ داشته باشیم . این میشه یه فیلتر ۲*۲ که روی توده ورودی لایه پولینگ اعمال میشه . ۲ *۲ یعنی یعنی ۴ تا المان از ورودی. (یه ماتریس بکشید مثلا با ۸ خونه. حالا ۴ تا ۴ تا جدا میکنیم . اول فیلتر ۲*۲ رو میزاریم در ابتدای ماتریس . بعد اگه با گام یک این فیلتر رو حرکت بدیم روی ماتریس میبینیم جمعا ۱۶ تا از این فیلترها رو میشه تو این ماتریس جا داد. خب حالا اگر ما ماکسیمم هر کدوم از این ۴ تا خونه رو هر بار بگیریم و در خروجی در یه ماتریس دیگه ذخیره کنیم چی میشه ؟ اندازه ماتریس ۸ در ۸ ما میشه ۴ در ۴ درسته ؟ این کاریه که لایه پولینگ انجام میده . حالا بسته به اندازه گام و اندازه فیلتری که انتخاب میکنیم این کاهش اندازه (ابعاد مکانی (طولو عرض) توده ورودی) بیشتر کاهش پیدا میکنه.
۵٫تو بخش منابع یادگیری عمیق چندتا لینک گذاشتم که میتونید سورس کد به زبان جاوا اسکریپت و یا سی++ و یا حتی پایتون اگر علاقه داشته باشید ببینید .
۶٫بعد لایه پولینگ میتونید به یه لایه تماما متصل وصل بشید یا اینکه میتونید به یه لایه کانولوشن وصل بشید و بعد از لایه کانولوشن به یه لایه تماما متصل وصل بشید . لایه پولینگ استفاده اش برای ایجاد translation invariance و همینطور کاهش ابعاد هست که بیشتر ازش استفاده میشه. اینکه ما یه اون اخر چند لایه تماما متصل باید بزاریم یا اینکه هر لایه چندتا خروجی باید داشته باشه (به غیر از لایه تماما متصل اخر که وظیفه دسته بندی رو بعهده داره و تعداد دسته ها مشخص هست) یه فراپارامتر هست که بر اساس تست و کار و تجربه بدست میاد. و اینطور تا جایی که من میدونم کسی نیومده بگه بر اساس فلان قانون و… تعداد لایه های تماما متصل و… باید انقدر باشه.
۷٫ مثل سوال شماره ۵ لطف کنید یه نگاهی به بخش منابع یادگیری بندازید قبلا یکسری موارد رو اونجا گذاشتم و سورس کدهایی هم که هست میتونه کمکتون کنه .
من فقط برای مدتی به اینترنت دسترسی ندارم برای همین اگر دیر جواب میدم بنده رو ببخشید.
بهتر بود منبع رو هم می نوشتید هم برای بیان اعتبار مطلب و هم به رسم امانت داری
http://cs231n.github.io/convolutional-networks
سلام و وقت شما بخیر
این منبع تو بخش منابع یادگیری عمیق از ابتدا قرار داده شده بود و هنوز هم هست(لطفا بخش متفرقه منابع رو ببینید).
تو آموزش های مربوط به دانشگاه استنفورد و اموزشهای دیگه ارجاع به بخش منابع دادم که برید و بخونید.
تو متن آموزش ها هم دقت کنید از ابتدا نوشتم که
و همینطور
بنظرم اگه پست های قبلی و یا بخش منابع رو یه نگاهی میکردید اول بهتر بود برادر عزیزم اما به هر حال باز هم دست شما درد نکنه از اینکه زحمت کشیدید و یکبار دیگه لینک کورس نوتهای دانشگاه استنفورد رو گذاشتید
در پناه خدا انشاالله همیشه موفق و سربلند باشید
حق با شماست، معذرت
سلام .
چیزی برای معذرت خواهی وجود نداره داداش گلم 🙂
در پناه خدا انشاالله همیشه موفق و سربلند باشی
[…] بحش دوم […]
سلام و ممنون به خاطر این آموزش خوب.
یه سوالی.
راهی هست که عکس های با سایز های مختلف رو با معماری یکسانی بشه عملیات کانوالو رو روشون انجام داد؟؟؟
سلام
خواهش میکنم .
اگه منظورتون اینه که دیتاست شما اندازه تصاویرش با اندازه تصاویری که یک معماری در ابتدا با اون آموزش دیده فرق میکنه ،( مثلا شما میخوایید از معماری الکس نت که با تصاویر با اندازه ۲۲۷ در ۲۲۷ کار کرد برای دیتاستی با تصاویر مثلا با اندازه ۳۲ در ۳۲ یا ۲۰۰ در ۲۰۰ استفاده کنید) بله مشکلی نیست.
دو راه دارید یا تصاویر ورودی ریسایز بشن به اندازه دیتاست اصلی (مثلا ۲۲۷ در ۲۲۷ ) یا اینکه تو لایه کانووشن اول اندازه فیلتر رو برای تصاویر جدید تغییر بدید بطوری که تنظیم شبکه در ادامه بهم نخوره.(مثلا تو الکس نت اندازه فیلتر لایه کانولوشن اول فک کنم ۱۱ بود که در اصل برای کاهش ابعاد تصاویر استفاده میشه. برای همین اگه مثلا دیتاست شما تصاویرش ۳۲ در ۳۲ باشه تو همون لایه اول به خطا بر میخورید و برنامه شما کرش میکنه)
اگه منظورتون اینه که یک دیتاست دارید با تصاویری با اندازه های مختلف اینجا شما حتما باید موقع ارائه به شبکه تصاویرتون رو ریسایز کنید و با یه اندازه به شبکه ارائه کنید. وگرنه این کاهش ابعادی که در ادامه شبکه اتفاق می افته بخاطر مچ نبودن با سایز یکسری تصاویر باعث ایجاد خطا و exception میشه و برنامه کرش میکنه.
سلام با تشکر از مطالب مفیدتون
آموزش بسیار عالی بود فقط قسمت آخرش که برنامه نویسی بود توضیحش خیلی کمه.میشه راهنمایی کنید واسه یادگیری numpy و python به چه منبعی مراجعه کنیم؟؟
سلام
یه آموزش برای یادگیری سینتکس پایتون با یکسری مثال اینجاس : http://cs231n.github.io/python-numpy-tutorial/
که خیلی خوبه.
به غیر از این باید یه کتاب یا آموزش ببینید اگه میخوایید با پایتون بصورت واقعی شروع به کار کنید.
سلام. خسته نباشید. ممنون بابت اطلاعاتی ک درباره شبکه عصبی کانولوشنی در اختیار گذاشتید.
یه سوال از خدمتتون دارم.
میگن لایه های کانولوشن باید از فیلترهای کوچک مثلا ۳ در ۳ یا ۵ در ۵ استفاده کنند. یا حداکثر اگر به تصویر ورودی نگاه می کنند میتونند از فیلترهای بزرگتر مثلا ۷ در ۷ استفاده کنن و اون هم باید عنوان بشه چون داریم به تصویر ورودی نگاه میکنیم از این اندازه فیلتر یا کرنل استفاده می کنیم..
حالا من یه جایی دیدم که از فیلترهایی با سایز خیلی بزرگ استفاده می شد مثلا فیلترهایی با سایز ۲۰ در ۲۰ ، ۱۶ در ۱۶… و تصاویرش هم تصاویر پزشکی بود. چرا از این فیلترهایی با این اندازه استفاده کردن؟ و از فیلترها با سایز کوچکتر مثلا ۵ در ۵ استفاده نکردن؟
سلام .
سلامت باشید
باید به تاریخی که اون مقاله سابمیت شده نگاه کنید که مربوط به چه زمانی هست. ۳ تا مساله اینجا میتونه دخیل باشه
۱٫معمولا از اندازه فیلتر بزرگ تو لایه اول خصوصا استفاده میکنن تا اندازه تصویر کاهش پیدا کنه و دیگه بقیه شبکه رو دست نزنن (مثلا یکی میاد از الکس نت استفاده میکنه اما چون الکس نت رو تصاویر۲۲۷ در۲۲۷ بود و اون تصاویرش بزرگته میاد اول با یه لایه بزرگتر یا اندازه تصویرش رو به این شکل کاهش میده که مچ بشه و برای لایه های بعدی مجبور به اعمال تغییرات نشه )
۲٫مقاله قدیمی بوده و مطالب جدید رو ندیدن.
۳٫ تحقیق به اندازه کافی نداشتن .
باید مقاله رو دید و گفت وگرنه احتمالات از اینکه کسی چرا اینکارو میکنه خیلی زیاد میتونه باشه . بیشتر مواقع که من دیدم همون مورد اول بوده . مگه اینکه الگوریتم یا معماری یا روش خاصی رو پیاده کرده باشن
اینم باید بدونید که فیلتر۳در۳ خصوصا بهترین سرعت و کارایی رو مثلا با cudnn ارائه میده و معمولا هم اگر کسی مشکل حافظه (یکی دیگه از دلایلی که بعضی ها از فیلترهای بزرگ استفاده میکنن اینه ) نداره با پشت سر هم قرار دادن لایه ها با اندازه ۳ در ۳ هم non-linearity بهتری میگیره و هم سرعت عالی تری (با استفاده از cudnn5 خصوصا) .
شما همیشه سعی کنید از ۳ در ۳ تا جایی که ممکنه استفاده کنید مگه اینکه بخوایید اول شبکه خصوصا یه کاهش ابعاد داشته باشید (همون مساله ۱)
ممنون بابت توضیحاتتون.
یه سوال دیگه هم داشتم. فرق شبکه عصبی کانولوشنی (CNN) با شبکه عصبی عمیق (Deep Neural Network=DNN) چی هست ؟
شبکه عصبی کانولوشن یکی از انواع شبکه های عصبی عمیق هست.
شبکه عصبی عمیق یه اسم کلی هست که اشاره به مجموعه ای از انواع مختلف شبکه های عصبی داره . مثل شبکه کانولوشن مثل DBN ها مثل LSTM ها و ….
دقت کنید که شبکه عصبی کانولوشن وقتی ارائه شد یک شبکه عمیق در زمان خودش بحساب میومد (LeNet5) ولی امروزه اون شبکه ابتدایی یک شبکه عمیق بحساب نمیاد.
بنابر این وقتی اسم شبکه کانولوشن رو در مقالات اخیر میخونید با چیزی که مربوط به قبل از سال ۲۰۱۲ هست خیلی فرق میکنه.در اصل هست شبکه عصبی کانولوشن عمیق
اما من یبار گفتم برای یه کاری از DNN استفاده کنم و گفتم که نمیخوام ویژگی استخراج کنم چون خودش کار استخراج ویژگی رو انجام میده.. حتی به من میگفتن از DNN میخوام استفاده کنم یا CNN؟ و من گفتم از DNN… بهم گفتن خب اگه نمیخوای ویژگی استخراج کنی بهتر نیست از CNN استفاده کنید؟
حتی یه مقاله خوندم که تفاوت CNN و DNN رو گفته بود…
من انگلیسی ام خیلی قوی نیست.. فقط تا جائیکه از اون مقاله متوجه شدم میگفت که CNN میاد با رابطه ریاضی که داره بهترین نقطه اتصال یا بهترین فیچر مپ (امیدوارم درست گفته باشم) رو پیدا میکنه اما DNN میاد یجورایی مثل ANN عمل میکنه ، یعنی اتصال به تمام نورون های لایه بعد.. تقریبا همچین چیزی گفته بود.
نمیدونم والله باید مقاله رو ببینم.
اینی که شما فرمایش میکنید بنظرم داشته در مورد Mlp صحبت میکردهو تفاوتش با CNN . باید مقاله رو بدید تا بتونم توضیح بدم خدمتتون .
مخفف چی بوده ؟ مطمئنید DBN نبوده ؟ چون ما چیزی بنام Neural network خالی نداریم . ما ANN داریم . یعنی Artificial neural network.این هم یک نوع خاصی از شبکه نیست یک مفهمومه .اشاره به پیاده سازی شبکه عصبی در کامپیوتر داره. چیزی که شاید ما خیلی استفاده میکنیم بعنوان شبکه عصبی در اصل یک شبکه عصبی پرستپرون چند لایه است که مخفف MLP یا همون Multi-layer preceptron هست که یکی از انواع بسیار پرکاربرد شبکه های عصبی مصنوعی هست. اینم یکی از انواع شبکه های فیدفوروارد هست که میشه Feed-forward neural networks . که شما وقتی میگید DNN ما (حداقل چیزی که من دیدم تا بحال) شبکه خاصی به این نام نداریم این یه نام کلی هست. Deep neural network . یک شبکه عصبی عمیق. تمام معماری های موجود در یادگیری عمیق هم انواعی از شبکه های عصبی هستن .
ممکنه اشاره به یه شبکه عمیق mlp بوده باشه که من البته ندیدم شخصا کسی استفاده کنه .
یا ممکنه اشاره اشون به یکی از انواع rnn ها بوده باشه و یا نوع خاص دیگه ای از شبکه
تو مقالات هم مهم اختصاری که استفاده میکنن نیست حتما باید بینید در چه زمینه ای استفاده کردن و معادل اصلی چی هست . خیلی خوب میشه اون مقاله رو هم اینجا قید کنید تا بهتر بشه نگاه کرد و نظر داد.
چیزی که من به قطع میتونم بگم با توجه به چیزهایی که دیدم و خوندنم اینه که DNN یک شبکه عصبی خاص نیست یک اسم کلی که به معماری های عمیق اشاره داره هست (مگه اینکه در مقاله خاصی بطور موردی اینو به اون مورد خاص اطلاق شده باشه)
http://ieeexplore.ieee.org/document/6936674/
عنوان مقاله :
Mandarin speech recognition using convolution neural network with augmented tone features
,
http://ieeexplore.ieee.org/document/7011421/
عنوان مقاله :
DaDianNao: a machine-learning supercomputer
چون من خیلی دنبال این بودم که تفاوت این دو تا رو بفهمم خیلی سرچ میکردم و به این مقاله ها رسیدم.
منظور اینها از DNN همون mlp و DBN و اتوانکودرهای عمیق بوده که قبل از ۲۰۱۲ معروف بودن.
مقاله اولی بنظر من خوب نوشته نشده بود. اما دومی مقاله خوبی بود. از هر دوتا از بخش رفرنسها میتونستید به مقالات ارجاعی اونها نگاه کنید و متوجه بشید منظورشون از DNN دقیقا کدوم معماری ها هستن .
شما موقع کارتون دقیق باید بگید اینطور نباید ارجاع بدید مگر اینکه همونطور که قبلا گفتم مثلا از شبکه کانولوشن غیرعمیق استفاده کنید و بخوایید اون رو با یک یا معماری های عمیق دیگه مثل DBN ها و … قیاس بکنید.
ممنون از شما بابت راهنمایی هاتون و مطالب خوبتون.
خواهش میکنم
در پناه خداوند انشاالله همیشه موفق و سربلند باشید
salam….kheili kheili mamnunam az matalebe kheili khubo aalitun
seyed jan key enshalla document matalebo tu sitet gharar midi ?
moteshaker
سلام .
انشاالله نهایی شد قرار میدم.
با عرض سلام.
ببخشید یه سوال در موردن نوشتن کد متلب شبکه های کانولوشنی دارم.
در مورد کارهایی که در این زمینه انجام شده، همیشه عمق اولین لایه کانولوشن کمه. این بخاطر اینه که لایه اول کانولوشن ، ویژگی های سطح پایین رو استخراج میکنه، و هر چقدر عمق کمتر باشه ویژگی های سطح پایین تر رو استخراج میکنه. تو لایه های بالاتر در مقالات میبینیم که عمق شبکه بیشتر شده، تعداد فیلترها بیشتر میشه تا ویژگی های سطح بالاتر استخراج بشه. مثلاً تو لایه ی اول تعداد کرنل ها (عمق) برابر با ۲۰ هست تو لایه دوم میشه برابر با ۵۰ و لایه بعدی باز هم بیشتر مثلاً ۱۰۰٫ و در نهایت تعداد ویژگی ها که در لایه دسته بندی (fully connected) قرار میگیره برابر با ۷۰ هست.
سوالم دقیقاً اینه : تنظیم این لایه ها، عمق این ها بصورت دستی انجام میشه ؟ مثلاً میگیم چون در لایه اول ، ویژگی های سطح پایین استخراج میشه عمقش رو کم در نظر می گیریم و در لایه های بالاتر عمقش رو بیشتر میذاریم؟ خودمون بصورت دستی افزایش می دیم و تنطیم میکنیم؟
تو تعریفش داریم که میگه کرنل های لایه قبل با feature map لایه قبل کانوالو میشه و feature map خروجی رو تولید میکنه؟ این یعنی تو کد متلب چطوری باید تعیین بشه؟
ممنون میشم راهنماییم کنید.
سلام
بله.مشخص کردن تعداد فیلترها (یا فیچرمپ ها یا خروجی ها یا عمق ) هر لایه یه فرا پارامتر هست که با سعی و خطا مشخص میشه . اما اصلی که وجود داره اینه که زیاد بودن عمق تو لایه (های) اول تاثیر خاصی در دقت نمیزاره چون یکسری فیلتر گابور ماننده از ورودی بدست میاد و اگر تعداد فیلتر ها رو از یه حدی بیشتر کنید نهایتا بصورت تکراری این فیلترها چند بار یادگرفته میشن و تاثیری ندارن (فکر کنید شما ۱ فیلتر دارید یک کارو انجام میده حالا ۱۰ تا دیگه عینا ا زهمون فیلتر کپی کنید! با این کار فقط سربار رو زیاد کردید و چیز جدیدی بدست نیاوردید ) و فقط بار پردازشی رو زیاد میکنه. برای همین شما در اکثر معماری ها میبینید برای لایه اول بسته به دیتاستی که معماری برای اون طراحی شده بین ۶۴ تا نهایتا ۱۲۸ هست و عمق بیشتر بصورت افزایشی در لایه های بعدی اعمال میشه و این باعث افزایش دقت میشه.(چون لایه های بالاتر روی توده های قبلی که بازنمایی از سطح قبل از خودشون هستن دارن اعمال میشن و افزایش تعداد فیلترها میتونه بازنمایی های مختلفی رو در سطح جدید ایجاد کنه)
همون اتفاقی که لایه کانولوشن روی تصویر ورودی انجام میده به همین شکل این عملیات روی توده های خروجی لایه های مختلف اعمال میشه .
برای کد متلب پیشنهاد میکنم یه نگاهی به matconvet بندازید لینکش در بخش ابزارها اومده.
سلام.
ممنون بابت توضیحاتتون.
۱- برای شبکه کانولوشنی به غیر از معماری matconvnet معماری های دیگه هم وجود داره؟
dagnn در این معماری برای چی استفاده میشه؟ برای چه حالتی؟
۲- در شبکه کانولشنی ، گفته میشه نیاز به پیش پردازش های زمانبر نیازی نیست. بحث حذف نویز هم خب جزء پیش پردازش محسوب میشه. اگه از یه الگوریتم حذف نویز خوب استفاده بشه، در نتایج cnn میتونه تاثیر بذاره یا بود و نبود الگوریتم حذف نویز تاثیری نداره؟ (من یجا خوندم که مثل اینکه تو سرعت همگرایی شبکه موثره)
۳- در مورد بحث تقویت مجموعه آموزشی یکم برام توضیح میدید ؟ خب برای این مسائل معمولاً ازشیفت دادن، چرخاندن ، آینه کردن تصاویر استفاده میکنن. اصلاً چرا شبکه کانولوشنی معماریش طوریه که حتما باید مجموعه تصاویر زیاد بهش داده بشه؟
۴- یه سوال دیگه در مورد تعداد فیچرمپ ها… ما میگیم که فیچرمپ های آخرین لایه مخفی میره تو لایه دسته بندی. و گفتیم این تعداد فیچرمپ ها بصورت دستی با سعی و خطا بدست میاد… الان این فیچرمپ هایی که در لایه دسته بندی قرار میگیره ، تعدادش معمولاً باید کمتر از تعداد فیچرمپ های آخرین لایه کانولوشن باشه؟ مثلاً میگیم لایه سوم کانولوشن مثلا ۱۰۰ تا فیچرمپ داره. حالا لایه آخر کانولوشن ۷۰ تا فیچرمپ تولید میکنه و همه این ۷۰ تا میره تو لایه دسته بندی و هر داده در کلاس مربوطه طبقه بندی میشه… مگه نمیگیم هر چقدر لایه ها رو جلوتر بریم (لایه های بالاتر) تعداد فیچرمپ ها زیاد میشه پس چرا مثلاً آخرین لایه مخفی نسبت به لایه های قبلش فیچرمپ کمتری بهش میدیم (با روش سعی و خطا) ؟
تشکر.
و ببخشید یک سوال دیگه.
مگه شبکه کانولوشنی خودش دسته بندی انجام نمیده پس چرا، در خیلی از مقالات میان فقط ویژگی ها رو با cnn آموزش میدن و بعد برای دسته بندی مثلاً از svm استفاده میکنن؟
و اینکه فرضا دو تا مقاله که شرایطش مشابه هست اما نتایج متفاوتی میده ، برمیگرده به آموزش شبکه. درسته؟ یکی بهتر تونسته شبکه رو آموزش بده بخاطر همین جواب بهتری گرفته ؟
ممنون.
معمولا کسایی که از svm استفاده میکنن هدفشون از اموزش با شبکه کانولوشن بدست اوردن فیچرهای خیلی خوبی هست که ارائه میکنه و برای یک کار خاص میخوان از اون فیچر ها استفاده کنن . چون در حالت کلی استفاده از svm بهبود خاصی رو باعث نمیشه. یکسری نمونه هم بوده که قصد داشتن ببین این مساله نسبت به حالت سنتی جطور جواب میده و ایا دسته بندی با اس وی ام بهتر هست یا نه.
دوتا مقاله یکسان منظوره یا دوتا مقاله متفاوت با شرایط یکسان؟
اگه هردو مقاله یکی باشن ممکنه یکی انتخاب پارامتر مناسبی نداشته باشه یا کمتر اموزش رو ادامه داده یا تو اپتیمای بدتری افتاده باشه. ولی اگر پیاده سازی مقالات صد در صد درست باشه و مراحل انجام هم همینطور اختلاف نتایج باید خیلی کم باشه.
سلام
مت کانونت معماری نیست یه تولباکس (کتابخونه) برای کار با شبکه های کانولوشن هست. کتابخونه و فریم ورک های دیگه هم هستن که بعضی ها رپر برای متلب ارائه میکنن و خیلی ها هم نه . اونایی هم که ارائه کردن معمولا پشتیبانی درستو حسابی ندارن. برای متلب برای کار با شبکه های کانولوشن مت کانونت بهترین هست.
dagnn شاید ساده بشه گفت ورژن پیشرفته تر simplenn هست که میتونید اطلاعات بیشتر و کامل ازش رو اینجا بخونید : http://www.vlfeat.org/matconvnet/mfiles/+dagnn/@DagNN/DagNN/ (من خودم با مت کانونت کار نمیکنم)
۲٫ این بستگی به ماهیت کار شما داره و میتونه تاثیر گذار باشه. کلا تو زمینه پیش پردازش اگه خوب کار بشه نتایج کارتون همیشه بهتر میشه. این حرف که نیازی به پیش پردازش نیست در حالت کلی درسته چون جواب خوبی میده اما اگر جواب خیلی خوب میخواید پیش پردازش یکی از روشهای بهبود دقت و همگرایی هست.
۳٫شبکه کانولوشن به تنهایی مطرح نیست شبکه کانولوشن عمیق هست که مهمه و همین عمق پارامترهای زیادی رو معرفی میکنه که باید تنظیم بشن . برای تنظیم این پارامترها هم نیاز به داده اس.
۴٫لایه آخر کار دسته بندی رو انجام میده و تعداد خروجیش برابر تعداد کلاسهای شماست. لایه (های) قبل از اخر رو سعی کنید به عنوان یک خلاصه از مهمترین ویژگی هایی که تا بحال یادگرفته شده در نظر بگیرید که این مهمترین ها میرن برای دسته بندی . برای همین شما میبنید که تا قبل از لایه دسته بندی ما یه افزایش فیچر مپ داریم و بعدش یه کاهش و معمولا اینطور بهتر جواب میده . کما فی السابق شما میتونید این قائده رو رعایت نکنید و این مساله رو خودتون تست کنید و ببینید چطور نیتجه میگیرید .
خیلی ممنون از توضیحاتتون.
لطف بزرگی میکنید که اطلاعاتتون رو در اختیار میذارید.
تشکر.
خواهش میکنم
در پناه خداوند موفق و سربلند باشید
سلام.
ببخشید من یه سوال در مورد تولباکس matconvnet از خدمتتون دارم. مشخص شدن سایز فیچرمپ و … در تابع v1-simplenn-display مشخص میشه؟ یعنی وقتی برنامه اجرا بشه با استفاده از این کد اون موارد نشون داده میشه؟ مثلاً data depth همون تعداد فیجرمپ هست یا data size سایز فیچرمپ هست؟ این سایز که توسط ما با سعی و خطا تنظیم نمیشه؟ خود برنامه تولید میکنه و اون رو به ما میده؟ data num چی هست؟ و همینطور rf size و rf offset ؟
ممنون.
سلام
من با مت کانونت کار نمیکنم و متاسفانه اطلاعی در این مورد ندارم
پیشنهاد میکنم سوالتون رو در سایت http://qa.deeplearning.ir بپرسید و کسایی که کار کردن بتونن راهنماییتون کنن.
بسیار متاسفم که عرض میکنم ترجمه شما بسیار نامفهوم است و خواننده با دانش قبلی در زمینه شبکه های عصبی نیز با چند بار خواندن و شمرده خواندن هم درک نمیکند چه گفته اید!
خواندن اصل مقاله راحت تر به نظر می رسد.
سلام .
بله نگارشش بی نقص نیست و من هم مترجم نیستم و بخاطر آشنا نبودن با معادل های فارسی یکم نامانوس شده . قبلا این بصورت محاوره ای نوشته شده بود و از اصطلاحات زبان اصلی استفاده کرده بودم.
منتها چون باید برای پایان نامه خودم همه چیز حتی معادلها فارسی سازی میشد من هم فرمت رو عوض کردم و سعی کردم به فرمت رسمی بنویسم که بعدا اگر کسی خواست استفاده کنه در داکیومنتی این امکان براش باشه و دیگه نیاز به تبدیل از محاوره به رسمی نباشه.
مطالب اینجا هم ترجمه صرف از یک مقاله نیست. بیشتر موارد آموزشهای دانشگاه استنفورد رو شامل میشه و مطالب مقالات دیگه هم داره
معمولا کسی مشکلی نداشت تا بحال و اگر هم بخشی رو متوجه نشد(که معمولا اگر کسی تا انتها رو بخونه متوجه همه چیز میشه بدون شک) با سوال تو سایت به جوابش میرسه.
شما هم اگر جایی مشکلی دارید یا بخشی رو متوجه نمیشید میتونید از بخش پرسش و پاسخ بپرسید تا من یا دوستان دیگه خدمتتون توضیحات کافی رو بدیم .
اگر هم معادل های بهتری سراغ دارید یا میتونید متون این آموزش رو ویرایش کنید و بقول خودتون قابل فهم تر کنید خوشحال میشیم و با کمال میل این contribution شما رو قبول میکنیم .
در پناه خدا انشاالله همیشه موفق و سربلند باشید
با سلام
ممنون از مطالب خوبتون خیلی استفاده کردم چندتا مفهوم روخوب متوجه نمیشم اگر یکم بازش کنید ممنون میشم
۱- منظور از فیلتر دقیقه چیه؟(از متن برداشت کردم که به وزن نرونها میگن فیلتر اما اینکه به چه تعداد از اونهایه فیلتر میگن و یا اینکه به تعداد لایه ها فیلتر داریم یا بیشر رو متوجه نمیشم)
۲- فیچرمپ برام گنگه و اینکه میگید با ازمون و خطا میشه به فیچر مپ مناسب رسید رو نمیفهمم
۳- چرا چند تا لایه تماما متصل داریم افزایش تعداد این لایه چ کمکی میکنه ؟ و اینکه چرا بعد از همه لایه های تماما متصل لایه relu قرار داره ب جز لایه آخر وظیفه اون لایه های ماقبل اخر چیه ؟
۴- مفهوم این جمله رو هم نفهمیدم “لایه پولینگ استفاده اش برای ایجاد translation invariance ”
ممنون از لطفتون
۱٫فیلتر = کرنل = ماتریس وزن
۲٫فیچر مپ خروجی ای هست که از اعمال فیلتر روی ورودی بدست میاد. تعداد فیچر مپ پس برابر تعداد فیلترها هست. و تعداد فیلترها هم یه فراپارامتره که با سعی و خطا برای هر کار خاصی مشخص میشه.
۳٫بطور خلاصه عمق بیشتر = تعداد لایه ها بیشتر =سطوح انتزاع بالاتر= افزایش قدرت شبکه . اخرین لایه وظیفه دسته بندی رو داره برای همین از relu استفاده نمیشه . شما میتونید از لایه تماما متصل استفاده نکنید. دلیل اینکه از لایه تماما متصل استفاده میشه برای ۱٫ بدست اوردن فیچر وکتور هایی از سطح بالاترین ویژگی های ما.
اینطور در نظر بگیرید که کل شبکه هرچی یادگرفته قراره در یک مثلا وکتور قرار بگیره / ۲٫ این لایه های تماما متصل حکم یه شبکه عصبی در دل شبکه کانولوشن هم ایفا میکنن و بنوعی غیرخطی بودن رو افزایش میدن . منتها تو استفاده های اخیر خیلی استفاده ازشون کم شده و بجاش از لایه کانلووشن استفاده میکنن تا میزان اورفیتینگ کاهش پیدا کنه اما همون رفتار رو بشه ارائه کرد.
۴٫ خیلی ساده یعنی تغییر مکان شی برای ما مهم نباشه. البته این قضیه توسط ماکس پولینگ ایجاد میشه و اونم بصورت جزئی .
ببخشید یه سوال رو یادم رفت
تو این مثال :”۸Cnn Relu 8pooling 16cnn Relu 16pooling 64Cnn Relu 64 pooling 128Cnn Relu 128pooling 256FullyConnected Relu 256FullyConnected Relu 10FullyConnected”
شما گفتیتد اعداد پشت لایه ها سایز خروجی لایه هست
سایز خروجی همون سایز لایه هست دیگه درسته ؟
مثلا اینجا لایه اول یه شبکه کانولوشن ۸*۸ هست که خروجی اونم یه توده ۸*۸ درسته ؟
نه اون تعداد فیلتر/فیچرمپ هست . نه اندازه توده خروجی .
یعنی لایه کانولوشن اول ۸ فیلتر داره و در نتیجه ۸ فیچرمپ تولید میشه. این ۸ فیچر مپ وارد لایه پولینگ بشن باز ۸ فیچر مپ (که کاهش ابعاد پیدا کردن) تولید میشه. دوباره لایه کانولوشن بعدی ۱۶ فیلتر داره و همینطور الی اخر.
ببخشید اگر یک نمونه سورس کد متلب برای کانوولوشن دارید لطفا برای من ارسال کنید چون خیلی سرچ کردم چیز زیادی پیدانکردم.خداخیرتون بده
متلب تو دیپ لرنینگ چندان مطرح نیست و منبع خاصی نمیتونید براش پیدا کنید
تنها تولباکسی که برای متلب هست و خیلی خوبه همین MatConvNet هست که توضیحش داده شده اما نسبت به بقیه فریم ورکها و کتابخونه ها مثل کفی و تنسورفلو و یا تورچ بنظر من خیلی ضعیفه و نه اون جامعه کاربری رو داره و نه به سرعت اونها بروز میشه و پشتیبانی گسترده ای داره .
بشدت پیشنهاد میکنم سویچ کنید رو پایتون که هم به متلب نزدیکه و هم اگر زبان برنامه نویسی کلا بلد باشید نهایتا دو سه روزه میتونید استارت هر پروژه ای رو بزنید باهاش. و مهتر از همه اینها بشدت منابع زیاد و خوبی داره
نهایتا اینکه برای نمونه مثال متلب بهتره به مثالهای مت کانونت مراجعه کنید .
سلام
میخواستم در مورد feature map هم اگر امکانش هست توضیح بدید که دقیقا چی هست …
سلام.
فیچر مپ در اصل همون خروجی حاصل از اعمال عملیات کانولوشن روی تصویر ورودی هست . وقتی شما روی یه تصویر عملیات کانولوشن رو انجام بدید خروجی هم یه تصویر میشه . ما اصطلاحا به این خروجی میگیم فیچرمپ.
یا به فارسی نقشه ویژگی یا نگاشت ویژگی .
دم شما گرم، خیلی خوب بود
با سلام و احترام
ممنون از وقتی که می گذارید و سپاس از مطالب بسیار عالیتون که به دانشجوهایی مثل من کمک بسیار زیادی میکنه مخصوصا که سایت فارسی هست و ما در سایت های فارسی زبان که اینقدر خوب مطالب رو خوب توضیح داده باشه میتونم بگم چنین سایت هایی نداریم ممنونم از لطفتون
در اخر اینکه امکانش هست مراجعی که ازشون در مطالب این قسمتشبکه CNNاستفاده کردید هم لطف کنید بذارید ممنونم ازتون
سلام
خواهش میکنم .تو بخش منابع یادگیری اوردم این منابع رو .
آموزش های بخش کانولوشن ۹۰ ۹۸ درصدش از آموزش های دانشگاه استنفورد گرفته شده یعنی اینجا
برای شروع خیلی خوب هستن اما به اینها بسنده نکنید.
بعد خوندن این اموزشها و کورس نوتهایی که لینکش رو تازه دادم سعی کنید ویدئوهای کورس رو هم ببینید . بعدش میتونید از بخش منابع یادگیری سایر ویدئوها و منابع مناسب رو پیگیری کنید.
میتونید از گروه تلگرام ما هم استفاده کنید که خیلی مطالب خوبی داره و افراد قوی و با تجربه ای تو این زمینه اونجا فعال هستن .
با سلام
من قبلا هم چن باری ازشما سوال پرسیدم و واقعا جوابهاتون خیلی کمک کرده. یه مساله ای ذهنمو مشغول کرده. بک پراپگیشن رو توی لایه ی کانولوشن و پوولینگ استفاده میکنیم و در هر کدوم هم یه تابع فعالسازی مثل reluو سیگویید و غیره. خوب حالا یه لایه ی رلو هم توی معماری معمولا بعد هر لایه ی کانولوشن هست. این به معنی اینه یه بار توی لایه ی کونولوشن حین بک پراپگیشن یه فعالسازی مثل سیگویید یا رلو استفاده میشه بعد یه بارم روی همون نورونهای لایه ی کونولوشن لایه ی relu میاد تابع فعالسازی رو برا کم کردن خطا اجرا میکنه؟
سلام
نه . این فرمی که لایه جداگانه ای برای RELU و SIGMOID و… هست و مثلا در کفی و بقیه پیاده سازی ها میبینید فقط بخاطر داشتن یک پیاده سازی بهینه اس. یک لایه میاد کانولوشن رو اعمال میکنه یک خروجی بدست میده
بعد این خروجی وارد تابع فعال سازی میشه و الی اخر . موقع بک پراپ هم بشکل معمول عمل میشه . دیگه خبری از یک لایه relu جدا و بعد دوباره در لایه کانولوشن یه لایه relu جداگانه باشه نیست!
توضیحتون رو فکر کنم اینجوری متوجه شدم. مثلا اگه یه شبکه رو در نظر بگیریم که به صورت
Conv Relu Conv Relu Pool Conv Pool Fc
باشه خروجی لایه ی کانولوشن وارد یه تابع بهینه سازی میشه. ولی این مساله هم هست که در واقع یه بار رو به جلو وزنها حساب میشه و در اخر از آخر به سمت اول شبکه برا اپدیت وزن ها میره یعنی همون بک پراپگیشن. مگه اینجور نیس؟
خوب وقتی در حین همین لایه ها رو به جلو بعد عقبگرد داریم بک پراپگیشن رو هم انجام میدیم داخل خود بک پراپگیشن هم از یک اکتیویشن فانکشن مثل سیگمویید هم استفاده میشه. یعنی اینجوریه که مثلا سیگمویید رو برا بک پرا استفاده کردیم و به طور مثال توی این مثال هم علاوه بر فعالسازی سیگویید برا هر بک پرا بعدش دو بار هم خروجی کانولوشنها وارد بهینه سازی رلو میشن. یعنی اینجوریه؟ ببخشدا خیلی سوال میپرسم. لایه ها رو جدا جدا متوجه شدم ولی اینکه بک پرا دقیقا از کی شروع میشه و همین چیزی که الان توضیحشو نوشتم رو نمیتونم متوجه بشم. آیا درست متوجه شدم؟؟
سلام .
ما یک فاز forward pass داریم که میشه ضرب ورودی در وزن ها + بایاس که همه اینها وارد یه تابع فعال سازی میشن و تا انتهای شبکه این فرایند رو داریم . به انتهای شبکه که میرسیم برای تنظیم پارامترها بر اساس میزان تاثیرشون در نتیجه نهایی میاییم از الگوریتم backpropagation یا اصطلاحا همون بک پراپ استفاده میکنیم . که خطا از لایه اخر محاسبه شده و به ترتیب لایه به لایه پارامترها بر اساس اون تنظیم میشن.
در بک پراپگیشن ما یه تابع فعال سازی نداریم . هرچیزی میتونه باشه . برای ما چیزی که مهمه بدست اوردن گرادیان محلی هر نورون و همینطور گرادایان خطا از لایه بعدی هست که با استفاده از اینها میزان تغییرات در وزن های یک نورون خاص مشخص میشه . حالا اون نورون میتونه توابع فعال سازی مختلفی داشته باشه که بر همون اساس هم گرادیان های محلی مختلفی بدست میاد. اگه سیگموید باشه یه چیزه اگه relu باشه یه چیز دیگه اس.
اون relu خودش یه تابع فعال سازی هست عین سیگموید یا tanh و …
بله متوجه شدم. ممنون از جوابتون
سلام
مرسی از اموزش خوبتون، یه سوال دارم اینکه من هنوز متوجه نشدم back prop دقیقا کجا اعمال میشه؟ مرحله ی فوروارد شامل عملیات کانولوشن و pooling میشه و بعد از کانولوشن یک Back prop زده میشه یا اینکه بعد از تمام کانولوشن ها و قبل از ورود به مرحله ی fc میایم back prop میزنیم؟ ممنون میشم این مورد و برام توضیح بدید
سلام .
ما دو فاز داریم . فاز forward pass و backward pass . (به اولی فاز فید فوروارد هم میگن ) فاز اول شامل اعمال تمامی ضرب و جمع و.. (عملیات کانولوشن پولینگ فولی کانکتد بچ نرمالیزیشن و… همه عملیاتهایی کهدر شبکه مشخص کردید ) میشه .
بعد از اینکه لاس محاسبه شد در انتهای شبکه نوبت به مرحله عقبگرد (یا همون بکوارد پس یا همون عملیات بک پراپگیشن (یا بک پراپ بقول شما) میشه و از انتهای شبکه تا ابتدای شبکه وزنها دستخوش تغییرات میشن تا لاس کمینه بشه.
با سلام خدمت ادمین گرامی
توی کتابخانه های deep learning مثل کافه یا تیانو از کدوم فرضیه برای آموزش شبکه های کانولوشنی استفاده می کنند: اشتراک وزن یا بدون اشتراک
سلام. ربطی به کتابخونه یا فریم ورک نداره.
لایه کانولوشن با اشتراک وزن هست.
در یک شبکه کانولوشن اما میشه انواع مختلفی از لایه ها رو استفاده کرد بعضی ها مثل کانولوشن اشتراک وزن دارن . بعضی ها هم مثل fully connected و locally connected بدون اشتراک وزن هستن.
با سلام و تشکر از توضیحات عالیتون. من بیشتر مطالب حتی سوال و جوابهارو مطالعه کردم یه سوال دارم خدمتتون.
۱)وقتی مثلا مثل مثالی که این بالا خودتون فرمودید که بین لایه ی کانوولوشن و پولینگ مثلا یه لایه relu هم وجود داره و تو جواب یکی از سوالات اینجور متوجه شدم که از لایه ی کانولوشن یه خروجی درمیاد وارد relu میشه آیا این اکتیویشن فانکشن همون فانکشنی هست توی محاسبات خروجی لایه ی کانوولوشن در حرکت رو به جلو استفاده میشه که تا اخر بره و بعد بک پراپگیشن انجام بشه برا آپدیت وزنها؟ یا نه این کلا یه تابع فعال سازیه و ربطی به محاسبه ی وزن ها رو به جلو نداره و خود لایه ی کانولوشن برا خودش هر جور تابعی مثل سیگویید داره و بعدشم خروجیش یه بارم وارد لایه ی relu میشه؟
۲)اینجور که متوجه شدم فقط در لایه های کانولوشن و فولی کانکتت ما بگ پرا داریم برا آپدیت وزنها چون فرمودید پولینگ فقط داره سایز رو کوچیک میکنه و از کانولوشن به پولینگ وزنی وارد نمیش بله؟
سلام .
۱٫relu همون تابع فعال سازی هست . اینکه میبینید بصورت جدا قرار داده شده فقط بخاطر بحث پیاده سازی هست . لایه کانولوشن اسمش روش هست عملیات کانولوشن رو انجام میده بعد هرچی شد وارد لایه relu یا sigmoid یا tanh یا …. میشه و توابع فعال سازی اعمال میشه و همینطور میره الی آخر
۲٫در لایه پولینگ ما پارامتر قابل تنظیم نداریم یعنی وزنی که بخواد بروز بشه در اون لایه ندلزیم.
بینهایت ممنونم. پس منظور اینه که بعد انجام عملیات کانولوشن تو لایه ی کانولوشن به منظور عملیات رو به جلو خروجی کانولوشن به همراه وزنها (ضرب ورودی در وزن ها + بایاس) وارد تابع فعالسازی میشه و به همین ترتیب تا اخر میره که بعدا برا عمل بک پراپگیشن رو به عقب و همون وزنها آپدیت بشن. درست متوجه شدم؟
باز هم ممنونم از توجهتون
سلام
نه. خروجی کانولوشن همون ماحصل ضرب ورودی در وزنها + بایاس بوده که عملیات کانولوشن روش انجام شده. هرچی شد میره وارد لایه relu میشه.
با سلام و تشکر از شما
cnn استخراج ویژگی را انجام میده یا فقط یادگیری ویژگی؟؟؟
سلام .
من تو پستهای اول سایت توضیح دادم اونو مطالعه کنید لطفا .
سلام
ممنون از مطالب خوبتون
مطالبی که شما مینویسین روان نیست(راحت با یکبار خواندن قابل فهم نیست)، لطفا مطالبتون رو ویرایش کنین و همچنین مطالبی را که می نویسن لطفا منبع ان را هم ذکر کنید.
سلام .
تا انتها مطالب رو مطالعه کنید متوجه میشید. برای ویرایش من قبول دارم منتها من وقت و فرصت این کارو ندارم مگه اینکه خود شما یا کاربرای دیگه وقت بزارن مطالب رو ویرایش کنن.
در مورد منابع هم بخش منابع یادگیری و رو ببینید. این آموزش برگرفته از اموزش دانشگاه استنفورد هست که لینک و ویدئوهاش اومده
باسلام و ممنون بابت آموزش خوبتون
سوال من اینه که در لایه آخر عمل تشخیص اینکه این عکس مربوط به کدوم دسته است به چه شکل است؟آیا در پایان خروجی را با به دسته بند (svm) بدیم تا عمل یادگیری انجام بشه یا نه به شکل دیگری هست؟اگر با یک مثال ساده توضیح دهید ممنون میشم
سلام . لایه اخر لایه دسته بند هست. اینجا از softmax استفاده میشه . ولی شما میتونید شبکه رو اموزش بدید بعد برای فاز دسته بندی از هر دسته بندی که دلتون میخواد استفاده کنید مثل svm یا هرچیز دیگه ای
وقتی مطالب تئوری رو خوندید و اموزش عملی با کفی یا تنسورفلو رو شروع کنید تو مثالها همه اینها رو به عینه میتونید ببینید و مشکلی نیست. ابتدا اموزشا رو بخونید و ببینید بعد حتما بصورت عملی انجام بدید .
ممنون بابت توضیحاتتون
پس یعنی من اینطور متوجه شدم مثلا پایان آموزش شبکه برای یک تصویر ما یک ماتریس (برای مثال) ۱۰*۱۰*۳ داریم (کلاس گربه) و ما اینو به دسته بند svm میدهیم با لیبل گربه و اینطور svm اموزش میبینه در انتها در قسمت تست همه این مراحل را طی میکنیم و ماتریس خروجی را به svm میدهیم و نتیجه رو به دست میاوریم
وقتی آموزش شبکه تموم شد شما باید نگاه کنید اخرین لایه شما چه چیزی ارائه میکنه . مثلا لایه ما قبل ip (که به اندازه تعداد کلاس ها هست) در الکس نت مثلا ۴۰۰۰ هست.(میتونید بسته به نیاز هر لایه ای رو استفاده کنید الزاما اخری میتونه نباشه اما عموما اخرین استفاده میشه) شما تصاویرتون رو به شبکه میدید و خروجی یه بردار ویژگی ۴۰۰۰ تایی دریافت میکنید به ازای هر تصویر. بعد میتونید با این بردار ویژگی هرکاری خواستید بکنید .
همه رو ذخیره کنید و بعد با لیبلهاش به یه svm بدید و svm رو ترین کنید. معمولا در این حالت شما بهبودی یا ندارید یا چندان چشمگیر نیست. و همین شیوه ای که فعلا در اموزش شبکه کانولوشن انجام میشده بهترین دقت رو ارائه میکنه.
مشکل من در حال حاضر اینکه متد اموزش شبکه کانولوشن رو درک نمیکنم…میشه بگید بطور دقیق در کدوم سری آموزشی درباره این متد بحث شده؟
سلام
این شبکه هیچ فرقی با شبکه عصبی معمول نداره . شبکه عصبی معمولی رو مطالعه کنید همه مواردش اینجا هم صدق میکنه
علاوه بر اینها آموزش یادگیری عمیق دانشگاه استنفورد یکی از بهترین هاست که اون رو هم میتونید ببینید. این اموزش هم برگرفته از کورس نوتهای دانشگاه استنفورد هست (همین که ویدئوش در سایت هم وجود داره)
باسلام و خسته نباشید
لطف میکنید کمی درباره softmax توضیح دهید و یا اگر لینک آموزش مناسبی هست معرفی کنید
سلام
تو کورس نوتهای دانشگاه استنفورد و فکر میکنم اموزش ماشین لرنینگ اندرو ان جی هم بود
این بخش رو بخونید همه اطلاعات مورد نیاز رو بدست میارید : http://cs231n.github.io/linear-classify/
میشه لطفا فارسی-انگلیسی اعداد رو تصحیح کنید؟ متن به این خوبی نوشتید متاسفانه به دلیل اینکه اعداد قابل درک نیستند (به دلیل جابجایی) نمیشه درک دقیقی از روند کار کسب کرد.
سلام
من خیلی سعی کردم که مشکل همه برطرف بشه، تا حد خیلی زیادی هم الان اکی هست و فقط دو سه جا اعداد فارسی و انگلیسی هستن که اونا رو هم تو وورد اگه کپی کنید بشکل درست نمایش داده میشن.
الان شما کجا مشکل دارید ؟
سلام
ببخشید منظورتان از بایاس در متن زیرچیست
وزن نورونها در این مثال [۱,۰,-۱] (همانطور که در منتها الیه تصویر سمت راست نمایش داده شده است ) و بایاس آن برابر با ۰ میباشد.. این وزنها بین تمام نورون های زرد رنگ مشترک است (بخش اشتراک پارامترها را در زیر بخوانید)
سلام منظور همون bias هست که در شبکه عصبی معمولی (mlp) هم وجود داره
سلام
یک سوال داشتم لطفا جواب بدید چالشهای شبکه عصبی کانولوشن میتونه چی باشه؟
سلام
دقیق تر بفرمایید منظورتون چیه تا بشه راهنمایی کرد
مثلا یکی از چالشهای شبکه کانولوشن مدت زمان طولانی اموزش شبکه های کانولوشن هست که باید راهکاری ارائه شود ایا به نظرتون چالش دیگری داره ؟
سلام این چالش بخودی خود چالش منحصر به شبکه های کانولوشن نیست .
بحث زمان طولانی آموزش مربوط به پارامترهای مختلفی میتونه باشه .
۱٫بخاطر معماری بد و غیربهینه(با پارامتر بسیار زیاد یا مصرف حافظه زیاد(فیچرمپ های زیاد و بزرگ) باشه
۲٫استفاده از توابع فعالسازی نامناسب باشه
و….
برای معماری های سنگین ما الان معماری های معادل سبکتر داریم که در بعضی موارد از تمامی معماری های سنگین تر مثل ResNet, GoogleNet,VGGNet,و … بهتر عمل میکنن . مثل SimpleNet .
یا معماری خیلی سبکی داریم مثل squeezenet که در حد الکس نت دقت ارائه میکنه با این تفاوت که الکس نت ۶۰ میلیون پارامتر داره اما squeezenet فقط ۱ مییلون پارامتر و الکس نت مثلا ۲۰۰ ۳۰۰ مگابایت فضا اشغال میکنه مدلش روی دیسک اما اسکویزنت تنها ۲ ۳ مگ!
از طرف دیگه معماری جدیدی مثل MobileNet داریم که وارد بحث خود لایه کانولوشن شده و اونو به دو لایه مجزا تفکیک کرده با همین کارش تعداد پارامترها رو بشدت کاهش داده و مثلا با ۴ میلیون پارامتر از گوگل نت و VGGNet که ۱۳۸ میلیون پارامتر داره در ایمیج نت بهتر عمل کرده
البته خود گوگلنت هم از لحاظ تعداد پارامتر از معماری های قبل خودش تعداد پارامتر خیلی کمتری داشت ولی خب از لحاظ تعداد محاسبات اعشاری خیلی سربار داشت (نسبت به معماری های جدید مثل سیمپل نت و موبایل نت و …)
شما در مورد شبکه عصبی کانولوشن اول باید مشخص کنید رو کدوم بخشش میخوایید کار کنید بعد دقیق بشید . شبکه کانولوشن عمیق چندتا زمینه کار داره
۱٫ طراحی معماری
۲٫طراحی تابع فعالسازی
۳٫طراحی مکانیزمهای رگیولاریزیشن
۴٫ بهبود قابلیت تشخیص
۵٫بهبود کارایی معماری با پارامتر کمتر
۶٫ویژوالیزیشن های دقیقتر و اینکه شبکه کانولوشن چطور داره کار میکنه و چطور میشه بهینه اش کرد
۷٫ نحوه آموزش شبکه کانولوشن
و….
اینا زمینه های مختلف هست که داره روش کار میشه شما هم بسته به شرایطتتون یکی رو انتخاب کنید و فاز تحقیق رو شروع کنید .
تا ممکن هست براتون از کلی گویی پرهیز کنید و سعی کنید دقیق بشید روی یه موضوع.
با تشکر از اینکه با حوصله به تمامی سوالات پاسخ میدهید
من در زمینه بهبود تشخیص دستنوشته با شبکه کانولوشن تحقیق میکنم و به دنبال چالشهای ان هستم
اگر شما منبعی دارید میشه برام معرفی کنید
با سپاس
سلام .
بطور اختصاصی من تو زمینه تشخیص دستنوشته کار نکردم باید کارهای انجام شده رو ببینید
خیلی راحت یه سرچ گوگل کنید مقالات مختلف رو میتونید پیدا کنید
از http://www.arxiv-sanity.com/ هم میتونید کمک بگیرید برای پیدا کردن مقالات حوزه موردنظرتون
با عرض سلام و ادب
ابتدا جا داره تشکر کنم از مطالب آموزشی شما که مفید واقع شده است
سوال داشتم
این قسمت به اشتراک گذاری پارامترها رو حالت اولیش رو متوجه نمیشم یعنی برام ملموس نیست
اون قسمتی که بعدش اتفاق میفته و پارامترها به آن روش محاسبه می شوند را میفهمم
اما ابتداش که پارامترهای زیاد داریم و علت داشتن اون مقدار از پارامتر را متوجه نمیشوم
سلام
کدوم بخش ؟ لطفا بخشی که مشکل دارید رو نقل قول کنید تا توضیح داده بشه خدمتتون
طرح اشتراک پارامتر در لایه های کانولوشن به منظور کنترل تعداد پارامترها مورد استفاده قرار گرفت. با استفاده از نمونه عینی که در بالا داده شد, ما میبینیم که ۵۵x55x96=290,400 نورون در لایه کانولوشن اول وجود دارد و هر کدام از آنها ۱۱x11x3=363 وزن و ۱ بایاس دارند. همه اینها با هم تشکیل ۲۹۰۴۰۰×۳۶۴=۱۰۵,۷۰۵,۶۰۰ پارامتر را تنها برای لایه اول شبکه کانولوشن میدهند. کاملا پیداست که این عدد بسیار بزرگی است.
میشه با مثال عملیاتی توضیح بدید که اگر اشتراک پارامترها اتفاق نمی افتاد چه می شد؟
با تشکر
داستان به این صورت هست که در حالت اولیه به ازای هر نورون ما یک وزن به ورودی داشته باشیم. این میشد همون شبکه عصبی معمولی (یا همون MLP ). هر نورون = یک وزن
اینجا یک حالت خاص رو بیان کرده. گفته خب ما به ازای هر نورون یک وزن نداشته باشیم بیاییم یک ماتریس از وزن داشته باشیم.
پس قبلا بود هر نورون یک وزن و الان شده هر نورون یک ماتریس وزن(چند وزن).
در ادامه باز گفتیم فرض کنید حالا این اتصال ما (اتصال بین وزن و ورودی) در عمق صورت بگیره.
یعنی اگه تصویر رنگی داشته باشیم هر سه کانال اون لحاظ بشه.
تصور کنید یک تصویر داریم با اندازه ۲۵×۲۵ پیکسل که رنگی هم هست . پس سه کانال ۲۵×۲۵ پیکسل داریم.
حالا ما میاییم یک فیلتر وزن با اندازه ۱۱ در ۱۱ پیکسل ایجاد میکنیم . و اون رو روی تصویر بالا اعمال میکنیم .
که این میشه همون ۳×۱۱×۱۱ چون روی هر سه کانال اعمال شده .
یعنی این تعداد وزن داریم که هر کدوم هم به یک پیکسل ورودی وصل هستن .
حالا تعداد نورون ها هم که مشخص هست و هر نورون هم این تعداد وزن داره و براحتی تعداد وزنها یا پارامترها رو میتونید بدست بیارید.
به این حالت ما اصطلاحا میگم locally connected .
سلام توی این مسئله تعداد نورون ها چندتاست؟ تعداد نورون چطور مشخص میشه؟
سلام.کدوم مساله؟
پس در اون حالت(حالت اول با پارامترهای زیاد) باید فیلتر اضافه کرد درسته؟
متوجه نشدم کدوم بخش ؟ MLP؟
و منظور شما از اضافه کردن فیلتر چیه ؟
ببخشید میشه اون حالت را روی تصویر بالا توضیح بدید؟
منظورتون تصاویر مربوط به نحوه ارتباط شبکه کانلووشن با اشتراک پارامتر و بدون اون هست ؟ (fully connected و locally connected ؟ )
یه سرچ ساده کنید تو گوگل تصاویر مختلف رو میتونید ببینید
مثلا این اسلاید رو من یه سرچ ساده کردم میتونید ببنید :
https://www.slideshare.net/zukun/p03-neural-networks-cvpr2012-deep-learning-methods-for-vision
تصاویر موردنظرتون رو باید ببینید اینجا (گوگل ایمیج سرچ هم انجام بدید تصاویر رو نشون میده بهتون)
منظورم اینه که اگر بخواهد حالت fully connected اتفاق بیافتد خب باید به ازای هر پیکسل یک وزن وجود داشته باشه این وزنها از کجا می آیند؟باید فیلتر اضافه شود؟
اون فقط یک مثال بود تا ایده اشتراک پارامتر رو جا بندازه براتون.
در شبکه کانلووشن برای بهینه سازی پیاده سازی هست که به ازای پیکسل های ورودی نورون ایجاد میشه و همه از یک ماتریس وزن یکسان استفاده میکنن (همه نورون های موجود در یک برش عمقی)
اگر fully connected باشه که میشه عینا همن چیزی که در شبکه عصبی چند لایه یا همون MLP وجود داره .
اگر منظور شما locally connected باشه که در در اونجا هر نورون یک ماتریس وزن (فیلتر، کرنل) اختصاصی داره و دیگه نورون ها حتی در برش عمقی هم مثل هم نیستن .
می بخشید کانوولوشن مگر locally conected نیست؟
شما میگویید در locally connected هر نورون یک ماتریس وزن اختصاصی داره
این درسته؟ این مگر در مورد fully connected صدق نمی کند؟
شما خوب توجه نکردید.
اینجا وقتی بحث از locally connected میشه در اصل منظور locally fully connected هست.یعنی همون لایه فولی کانکتد رو در نظر بگیرید بجای اینکه هر نورون به یک ورودی متصل باشه در آن واحد به چندتا متصل هست.
این باز یعنی تمامی نورونها در یک برش عمقی هرکدوم یک فیلتر وزن اختصاصی دارن
در لایه کانولوشن ما بصورت محلی به ناحیه ورودی متصل هستیم اما دقت کنید که تمامی نورونهای موجود در یک برش عمقی از “یک” فیلتر وزن استفاده میکنن.
چگونگی برچسب گذاری در مرحله آخر آموزش dbn
سلام
متاسفانه بنده با Deep Belief Network ها کار نکردم
این مساله رو در سایت پرسش و پاسخ پیگیری کنید
سلام
امیدوارم خوب باشید
بنده پروژه ارشدم با استفاده از این شبکه ها پیاده سازی کردم
شاید سوالم خنده دار باشه ولی در پایان نامه به نظر شما درست تر هست بنویسم لایه ی کانولوشن و … یا بهتر هست بنویسم لایه کانولوشن … یا اصلا فرقی نداره D:
اخه خوندن اولی روون تره ولی انگلر دوی هم یجورایی اشتباه نیست
سلام
من نظرم روی لایه کانولوشن هست اما باید با استاد راهنما چک نهایی رو انجام بدید. معمولا برای پایان نامه ها یکسری الگوها و نکات قابل توجه هست که باید از اونها تبعیت کنید و سایت آموزش و یا کتابخونه دانشگاهتون باید راهنماییتون کنه در این زمینه
با سلام خدمت شما دوست عزیز
آیا امکان اشتراک پروژه ای که کار کردین با بنده هست؟؟ یا بعبارتی میشه ازتون خواهش کنم کداتون رو به منم بدین. من خیلی دنبال کسی می گردم که با این شبکه ها پیاده سازی انجام داده باشه و با هم بریم جلو چون خودم یه سری ایده دارم برای پیاده سازی این پبکه ها که میشه ازشون مقاله های خوبی هم چاپ کرد. خوشحال میشم پاسختون مثبت باشه.
ایمیل بنده
taghymodarresi[at]gmail.com
هستش.
با سپاس فراوان
سلام. کدوم پروژه؟
از پاسختون سپاسگزارم،
پایان نامه تون منظورم بود که پیاده سازی شبکه های عمیق کانولوشن توش بود.
سلام
لطفا این بحث رو در ایمیل پیگیری کنید.
میتونید از بخش تماس با من هم پیام بفرستید یا از بخش درباره ما به ایمیلی که قرار دادم ایمیل بزنید
سلام…میشه لطفا توضیح بدید که تعدا فیلترها رو بر چه اساسی انتخاب میکینم؟سایز تصویر ورودی توی انتخاب فیلترهای لایه اول چه تاثیری دارد؟چرا توی لایه های بعدی تعداد فیلتر ها اضافه می شوند؟
سلام
سوالات زیادی قبلا پرسیده شده و جواب دادیم هم تو این سایت و هم بخش پرسش و پاسخ لطفا اونجا رو چک کنید.
اگه خیلی خلاصه بخواهیم توضیح بدیم اینطور باید بگیم که تعداد فیلترها ارتباط مستقیم با پیچیدگی مساله شما داره. چیزی که باید بدونید اینه که کلا در لایه های ابتدایی مفاهیم اولیه و ساده استخراج میشن مثل لبه ها و… بنابر این چون این مفاهیم ساده مشخص میشن افزایش فیلترهای زیاد تنها باعث تکرار فیلترهای مشابه میشه و عملا میبینید از یک حد خاصی به بعد تغییری در دقت دریافت نمیکنید. اما رفته رفته با افزایش لایه ها و فاصله گرفتن از ورودی به سطح انتزاع اضافه میشه یعنی مفاهیم انتزاعی تر بوجود میان (از ترکیب لایه های قبلی ) مثلا در لایه سوم مفاهیم سطح بالایی مثل بینی چشم و… (اگر صورت انسان رو فرض کنیم) به چشم میخورن که قائدتا بخاطر پیچیدگی بیشتروشن نیازمند منابع پردازشی بیشتری هستن (فیلترهای بیشتری برای کپچر کردن تغییرات و تفاوت ها و الگوهای مختلف نیاز هست) و به همین شکل الی اخر.
به همین دلیل هست که شما در شبکه های کانولوشنی میبینید با افزایش عمق شبکه عموما ما افزایش نورونها (یا فیلترها) رو در لایه ها شاهدیم.
البته این همه قضیه نیست و داستان پیچیده تره ولی خب برای خلاصه همین حد کفایت میکنه.
Parametr= channel_input∗ kernel_size∗kernel_size∗num_filter+ num_filter
سلام
برای محاسبه ی تعداد پارامترهای قابل تنظیم در لایه کانولوشن از این رابطه ی استفاده می شه درسته؟
چرا دو تا num_filter توی فرمول استفاده میشه؟؟
میشه مفهوم کلی بایاس رو توضیح بدین؟
سلام.
اگه به شکلی که در بخش دوم آموزش قرار دادم نگاه کنید متوجه میشید.
شما به تعداد کانال ورودی کرنل دارید و هر کرنل هم سایز kxk داره . حالا هر لایه میتونه n تا فیلتر خروجی داشته باشه که میشه n ضرب در این عدد .
هر لایه میتونه بایاس داشته باشه میتونه نداشته باشه اگر داشته باشه به ازای هر فیلتر خروجی یه بایاس خواهید داشت
پس تعداد بایاس شما مساوی تعداد فیلترهای خرروجی شماست. اگر ۵ تا فیلتر دارید ۵ تا بایاس هم دارید(اگر بایاس را فعال کنید برای اون لایه)
برای مفهوم کلی بایاس رو یه سرچ ساده کنید به اطلاعات کامل میرسید
سلام و وقت بخیر
سوال من این هست که ورودی شبکه کانولوشن باید حتما مربعی باشه؟ و این.ه وقتی یه سیگنال رو به شبکه کانولوشن میدیم چطور عمل میکنه؟
ورودی برای سیگنال به این صورت هست که ویژگی رو تو پنج باند فرکانسی استخراج کردیم بنابراین هرسیگنال یه ماتریس ۶۲ در ۵ هست که ۶۲ تعداد کانال هاست
سلام . نه هیچ الزامی ندارید. شما میتونید از کانولوشن ۱ بعدی یا ۲ بعدی و یا سه بعدی استفاده کنید .
معمولا برای کار با سیگنال شیوه های مختلفی هست چیزی که شاید خیلی رایج باشه تبدیل به spectogram هست و بعد اونو رو به شبکه تغذیه میکنن و ترین میکنن
تو حوزه سیگنالها معمولا ترکیبی از شبکه های بازگشتی و CNN هم رایجه.
برای آشنایی بیشتر میتونید مثلا نمونه مثالهایی از دسته بندی سیگنالهای EEG رو سرچ کنید.
سلام، متنش ترجمه بود؟ خیلی ناواضح و غیر قابل فهم بود!
سلام
نه ترجمه صرف نیست . این متن برگرفته از کورس نوت های دانشگاه استنفورد در سال ۲۰۱۶ هست
کدوم بخش مشکل دارید بفرمایید تا اگر نیاز داشتید مطلب بیشتر باز بشه
سلام ، می خواستم بدونم این که گفته شده عمق لایه کانولوشن ما ۹۶ از کجا به دست آوردیم؟
متشکر از مطالب جامع وکاملتون
سلام. عمق لایه کانولوشن یا بهتر بگیم تعداد کرنل های یک لایه کانولوشن یک فراپارامتره .
برای اطلاعات بیشتر میتونید مقالاتی مثل https://arxiv.org/abs/1608.06037 و نمونه کاملترش https://arxiv.org/abs/1802.06205 رو بخونید
سلام. امکانش نیست که هر لایه ی شبکه را جداگانه، یک سرور اجرا بکنه؟ منظورم اینه که لایه ها توسط چند تا سرور اجرا بشن بدون اینکه به خروجی هم نیاز داشته باشند. به صورت موازی
سلام
اگر نیاز به خروجی هم ندارند یعنی هرکدوم در اصل باید یک شبکه مجزا از هم باشند و در این صورت میتونید هر کدوم رو جداگانه بر روی یک سخت افزار ران کنید .
سلام. میشه لطف کنید فرق بین کرنل و وزن در لایه ها چیه؟
سلام. جفتشون به یک مفهوم اشاره دارن اینجا
سلام
بسیار متشکرم بابت توضیحاتون
بسیار واضح و کامل بودند
باسلام میشه در مورد پنهان نگاری تصویر در تصویر توسط شبکه های عصبی کانولوشن هم توضیح بدین؟
با عرض سلام و وقت بخیر خدمت شما
واقعا از مطالب ارزشمندتون تشکر می کنم
جناب یک موضوع شدیدا ذهن بنده رو درگیر کرده و هرچی هم چه فارسی و چه انگلیسی سرچ می کنم چیزی نتونستم پیدا کنم ممنون میشم راهنماییم کنین.
سوال در مورد خود فیلتر ها هست یعنی نوعشون البته در بحث برنامه نویسی در کراس. بزارین دقیقتر بگم. مثلا ما میگیم که در لایه اول کانولوشنی مثلا ۶۴ تا فیلتر قرار میدیم و در لایه بعدی ۱۲۸ و غیره. خوب در برنامه نویسی هم مثلا تحت keras صرفا تعداد فیلتر ها و ابعادشون رو مشخص می کنیم. ولی برای بنده جای سواله که این ۶۴ یا ۱۲۸ تا فیلتر چه فیلتر هایی هستن!! ماتریس این فیلترها چیه؟ آیا ما نمی تونیم برای این فیلتر ها اون فیلتر مد نظر خودمونو قرار بدین؟ اگه مثلا در کراس جایی نداره که فیلترها رو هم ما خودمون دستی تعریف کنیم(منظورم ماتریس فیلترهاست)؟
سلام
اون فیلترها در ابتدای کار صرفا مقادیر رندوم دارن و در حین آموزش هست که توسعه پیدا میکنند (در ابتدا یکسری ماتریس با مقادیر رندوم در نظر بگیرید)
شما میتونید فیلترهای خودتون رو لحاظ کنید ولی باید یادتون باشه اجازه اپدیت وزن ها رو دیگه ندید. عموما اجازه به توسعه فیلترهای مناسب توسط خود شبکه نتایج بهتری رو ارائه میده اما چیزی جلوی شما رو نمیگیره که فیلترهای خودتون رو لحاظ نکنید.
معمولا دو شیوه هست یا شما اول یک لایه رو میسازید و بعد وزنش رو چیزی که مدنظرتون هست ست میکنید یا از ابتدا از فرم فانکشنال لایه کانولوشن مثلا استفاده میکنید و همون ابتدا فیلتر موردنظر خودتون رو بهش اختصاص میدید.
هم تنسورفلو و هم پایتورچ و …. از این قبیل عملیات ها پشتیبانی میکنن و کافیه یک نگاهی به مستندات بندازید. (ماتریس وزن در لایه های مورد نظرتون رو بررسی کنید)
یه دنیا ممنونم از راهنماییتون
سلام وعرض ادب خدمت شما.
میخواستم ببینم چگونه میشه که شبکه های کانولوشنی رو واسه یک سری داده ماهواره ای با یک رزولوشن مثلا ۱۰km اموزش بدم و بعد واسه prediction از همون داده با رزولوشن بالاتری مثلا ۵km استفاده کنم و بخام که اون داده را ریزمقیاس کنم .یعنی ابعاد داده اولیه واسه train با ابعاد داده در مرحله test متفاوت باشد.؟؟
ممنون میشم اگر راهنمایی کنید
سلام.
سوالتون واضح نیست.بصورت پیشفرض رزولوشن بالاتر داده بیشتری داره نسبت به رزولوشن کمتر و من دقیقا نمیدونم شما دنبال چه کاری هستید. اگه قراره صرفا از فیچرهای بدست اومده استفاده کنید برای تمایز بین تصاویر در رزولوشن بالاتر این کار ممکنه اما پیشنهاد نمیشه چون خروجی بسیار دقیقی دریافت نمیکنید خصوصا در زمینه های مشابه. مگر اینکه تصاویر ناحیه مورد نظر شما از نظر عوارض زمین یکدست باشند در اون دو ارتفاع و تفاوت خاصی نکنند.
شما در ارتفاع بالا (رزولوشن کمتر) بسیاری از فیچرهای متمایز کننده ای که در رزولوشن بالاتر هست رو ندارید که بر مبنای اونها بتونید تشخیص خوبی در اون رزولوشن بدید (حداقل بصورت پیشفرض)
بحث سر ابعاد تصویر نیست بحث سر داده موجود در هر کدوم هست. اگر جفت تصاویر شما مربوط به یک رزولوشن بود بعد هرکدوم ابعاد مختلفی داشتند اونوقت میتونید تحت یک بعد یکسان اونها رو فید کنید (یا اینکه نکنید و شبکه تمام کانولوشنی داشته باشید و شبکه بتونه هر ورودی با هر ابعادی رو دریافت کنه (البته این ابعاد نسبت به چیزی که خود شبکه با اون ترین شده نباید بطور اساسی متفاوت باشه در این صورت شما خروجی مناسب دریافت نمیکنید))
من با اصطلاحات فارسی اشنا نیستم منظورتون از ریزمقیاس همون dowbsampleئه یا اشاره به کارکرد دیگه ای داره؟
اگه منظور کاهش ابعاد باشه، شما رزولوشن بالا رو بگیرید بعد downsample کنید داده از دست میدید ولی باز الزاما این مشابه رزولوشن ۱۰ کیلومتری نمیشه. شما در یک رزولوشن ۱۰ کیلومتری ناحیه بزرگتری از یک رزولوشن ۵ کیلومتری در اختیار دارید. اگر بگید من نواحی یکسان دارم در رزولوشن های متفاوت و با داون سمپل کردن سعی میکنم به یک اندازه برسونم سوای مطالب مطرح شده بالا چرا اساسا این کارو میکنید وقتی حجم عظیمی از داده رو میخوایید از بین ببریید و استفاده نکنید؟(باز عرض میکنم برداشت من از ریزمقیاس به معنای downsample منتج به این نظر میشه. من اشرافی به مطلب خاص مورد نظر شما ندارم بنابراین ضروریه اگر برداشت اشتباهی اینجا شده تصحیح بفرمایید و توضیحات بیشتری از ماهیت کارتون بدید که اگر اطلاع داشتم خدمتتون عرض کنم.
سلام.ممنونم بابت پاسختون.ولی فکر کنم منظورم رو نرسوندم.من در پروژه ای قصد دارم که محصولات ماهواره ای (صرفا تصویر rgb نیست ومنظور یک لایه رستری که اطلاعات مربوط به زمین مثلا دمای سطح را شامل میشود ) با رزولوشن خیلی پایین در حدود ۱۰کیلومتر را با استفاده از یک سری فیچر مربوط با ان محصول و خود محصول به عنوان لیبل یک مدل رگرسیون با استفاده از شبکه های کانولوشنی ایجاد کنم و مدل رو با فیچرهای رزولوشن پایین (۱۰km) اموزش بدم ودر مرحله تست همان فیچرها با رزولوشن بالاتر (۱km) را به مدل داده و در نهایت یک محصول جدید با رزولوشن ۱کیلومتر تولید کنم. من مدلم رو ساختم و مرحله اموزش رو انجام دادم ولی هنگام predict کردن داده با رزولشن بالاتر . شبکه ما خطا میدهد چون ابعاد داده ها در مرحله train و test با هم تطابق ندارد .در واقع چون تعداد سطر و ستون در داده های تست ده برابر شده این مشکل به وجود می اید. ناگفته نماند من در مدل خود از لایه globalaveragepooling به جای لایه ی flatten استفاده کردم چون ابعاد داده ها در دو مرحله تغییر میکند گفتم شاید با این کار بتونم جواب بگیرم.
الان خواستم بدونم چگونه میتونم این مسئله رو حل کنم.؟
ممنون از لطف ومحبت شما
سلام
یک ابزار برای طراحی گرافیکی شبکه cnn میخوام بهم معرفی کنید که به صورت شماتیک شکل مراحل مختلف انجام کار را در لایه ها طراحی کنم برای مقاله.
ممنون از راهنمایی شما.
سلام. اون اشکال در پاورپوینت ایجاد شدند. البته الان شما باید بتونید با midjourney و یا حتی ادوبی فتوشاپ/ فایرفلای بگید چی میخوایید و طرح مورد نظرتون ایجاد بشه! ابزارهای طراحی
هم سرجاش هست و میتونید استفاده کنید
سپاسگزارم
بسیار عالی بود و مفید