

بسم الله الرحمن الرحیم
مطالب زیر یکی از بهترین reviewهای ۲۰۱۵/۲۰۱۶ هست که من البته بعضی جاها رو دست زدم (یعنی اطلاعات بیشتری رو اضافه کردم برای کار خودم .تو ورژن مربوط به خودم RNN ها رو هم اضافه کرده بودم که ناقص بود برای همین برش داشتم تا کامل بشه و بعد احتمالا تو یه پست جداگانه بزارم . دقت کنید این review همه روشهای فعلی در یادگیری عمیق رو پوشش نمیده. از این بعنوان یکی از منابع استفاده کنید نه تنها منبع خودتون ).
اینم عیدی ما برای عید فطر 🙂
۱-۱- مقدمه
الگوریتم های یادگیری عمیق[۱] زیرمجموعه ای از الگوریتم های یادگیری ماشین هستند که هدف آنها کشف چندین سطح از بازنمودهای (نمایش)های توزیع شده[۲] از داده ورودی است. اخیرا الگوریتم های یادگیری عمیق زیادی برای حل مسائل هوش مصنوعی سنتی ارائه شده اند. در این بخش ما مروری بر بعضی از الگوریتم های به روز این مبحث در حوزه بینایی کامپیوتر خواهیم داشت. در ابتدا خلاصه ای از چندین روش یادگیری عمیق متفاوت و پیشرفت های اخیر آنها ارائه میکنیم و سپس بصورت خلاصه کاربردهای هر یک را در زمینه های مختلف بینایی [۳] همانند دسته بندی تصاویر,[۴] شناسایی اشیاء[۵], استخراج تصاویر[۶], قطعه بندی معنایی[۷] و برآورد ژست انسان[۸] توضیح میدهیم. در انتهای این بخش نیز گرایشات و مشکلات آینده در طراحی و آموزش شبکه های عصبی عمیق بصورت خلاصه ارائه میشود. .
۱-۲- روش ها و پیشرفت های اخیر
طی سالهای اخیر, یادگیری عمیق بصورت گسترده در حوزه بینایی کامپیوتر مورد مطالعه قرار گرفته است و به همین دلیل, تعداد زیادی از روش های مرتبط با آن بوجود آمده است.. بطور کلی, این روشها بر اساس روش پایه ای که از آن مشتق شده اند به ۴ دسته مختلف تقسیم میشوند که عبارتند از Convolutional neural networks , Restricted Boltzmann Machines (RBMS) , Autoencoders و در آخر Sparse Coding .
دسته بندی روش های یادگیری عمیق را به همراه کارهای انجام شده با هر یک از این روشها در شکل ۱ مشاهده میکنید .
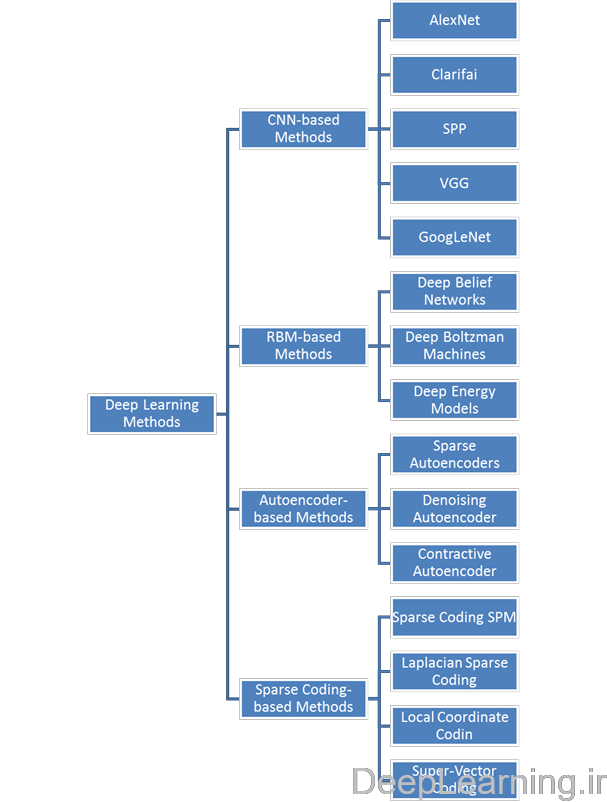
- دسته بندی روش های یادگیری عمیق به همراه چند نمونه از کارهایی انجام شده با هر کدام
۱-۲-۱-Convolutional Neural Neworks (CNNs)
شبکه های عصبی کانولوشن (CNN) یکی از مهمترین روش های یادگیری عمیق هستند که در آنها چندین لایه با روشی قدرتمند آموزش میبینند(۲۰) این روش بسیار کارآمد بوده و یکی از رایجترین روشها در کاربردهای مختلف بینایی کامپیوتر است. تصویر کلی یک معماری شبکه عصبی کانولوشن در شکل ۲ نمایش داده شده است . بطور کلی, یک شبکه CNN از سه لایه اصلی تشکیل میشود که عبارتند از : لایه کانولوشن, لایه Pooling و لایه تماما متصل. لایه های مختلف وظایف مختلفی را انجام میدهد. در شکل ۲ یک معماری کلی از شبکه عصبی کانولوشن برای دسته بندی تصاویر (۲۱) بصورت لایه به لایه نمایش داده شده است .در هر شبکه عصبی کانولوشن دو مرحله برای آموزش وجود دارد. مرحله feed forward و مرحله backpropagation یا پس انتشار .در مرحله اول تصویر ورودی به شبکه تغذیه میشود و این عمل چیزی جز ضرب نقطه ای بین ورودی و پارامترهای هر نورون و نهایتا اعمال عملیات کانولوشن در هر لایه نیست. سپس خروجی شبکه محاسبه میشود. در این جا به منظور تنظیم پارامترهای شبکه و یا به عبارت دیگر همان آموزش شبکه, از نتیجه خروجی جهت محاسبه میزان خطای شبکه استفاده میشود. برای اینکار خروجی شبکه را با استفاده از یک تابع خطا (loss function) با پاسخ صحیح مقایسه کرده و اینطور میزان خطا محاسبه میشود. در مرحله بعدی بر اساس میزان خطای محاسبه شده مرحله backpropagation آغاز میشود. در این مرحله گرادیانت هر پارامتر با توجه به قائده chain rule محاسبه میشود و تمامی پارامترها با توجه به تاثیری که بر خطای ایجاد شده در شبکه دارند تغییر پیدا میکنند. بعد از بروز آوری شدن پارامترها مرحله بعدی feed-forward شروع میشود. بعد از تکرار تعداد مناسبی از این مراحل آموزش شبکه پایان میابد.
انواع لایه های شبکه CNN
در حالت کلی, یک شبکه عصبی کانولوشن یک شبکه عصبی سلسله مراتبی است که لایه های کانولوشنی آن بصورت یک در میان با لایه های pooling بوده و بعد از آنها تعدادی لایه تماما متصل وجود دارد .
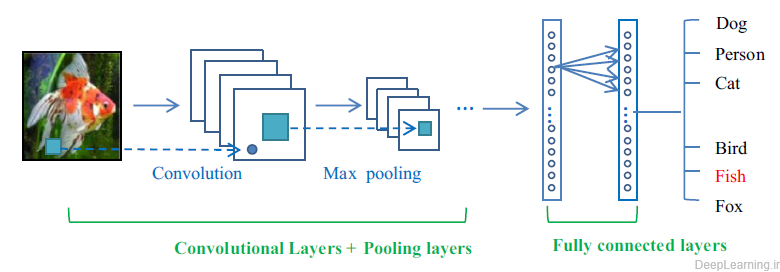
- یک طرح کلی از معماری یک شبکه عصبی کانولوشن
لایه کانولوشن :
در این لایه ها , شبکه CNN از kernel های مختلف برای convolve کردن تصویر ورودی و همینطور feature map های میانی استفاده میکند و اینگونه feature map های مختلفی همانند آنچه در شکل ۳ مشاهده میکنید ایجاد میکند. انجام عملیات convolution سه فایده دارد (۲۲) :
- مکانیزم اشتراک وزن در هر feature map باعث کاهش شدید تعداد پارامترها میشود
- اتصال محلی, ارتباط بین پیکسل های همسایه را یادمیگیرد
- باعث تغییر ناپذیری و ثبات نسبت به تغییر مکان شئ میشود
بواسطه فواید معرفی شده توسط عملیات convolution , بعضی از مقالات تحقیقاتی مشهور از آن جهت جایگزینی لایه های تماما متصل استفاده کردند تا با این کار سرعت فرآیند یادگیری را افزایش دهند (۲۳, ۲۴). یکی از روشهای جالب مدیریت لایه های کانولوشنی, روش (۱۹) Network in Network (NIN) است که در آن ایده اصلی جایگزینی لایه کانولوشنی با یک شبکه عصبی پرسپترون کوچک است که شامل چندین لایه تماما متصل با توابع فعال سازی غیرخطی است. به این ترتیب فیلترهای خطی با شبکه های عصبی غیرخطی جایگزین میشوند. این روش باعث بدست آوردن نتایج خوبی در دسته بندی تصاویر میشود.
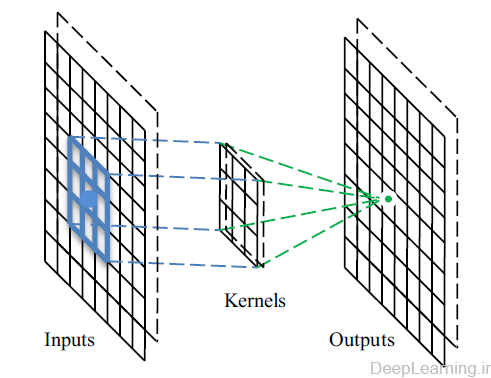
- عملیات لایه کانولوشن
لایه های pooling
یک لایه pooling معمولا بعد از یک لایه کانولوشنی قرار میگیرد و از آن برای کاهش اندازه feature map ها و پارامترهای شبکه میتوان استفاده کرد. همانند لایه های کانولوشنی, لایه های pooling بخاطر در نظر گرفتن پیکسل های همسایه در محاسبات خود, نسبت به تغییر مکان(translation) بی تغییر (با ثبات) هستند. پیاده سازی لایه Pooling با استفاده از تابع max (max pooling) و تابع Average (Average pooling) رایجترین پیاده سازی ها هستند. در شکل ۴ میتوانید نمونه ای از فرایند Max pooling را مشاهده کنید. با استفاده از فیلتر max pooling با اندازه ۲×۲ و stride ۲ یک feature map با اندازه ۸×۸ یک خروجی با اندازه ۴×۴ را ایجاد میکند.
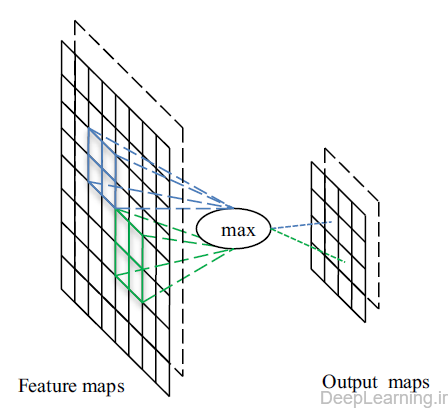
- عملیات max pooling
Boureau et al.(25) تحلیل نظری دقیقی از کارایی max pooling و average pooling ارائه داد. Scherer et al.(26) هم مقایسه ای بین این دو عملیات انجام داد و فهمید max pooling میتواند باعث همگرایی سریعتر , تعمیم بهتر (بهبود تعمیم دهی) و انتخاب ویژگی های نا متغیر بسیار عالی[۹] شود. طی سالهای اخیر پیاده سازی های سریع مختلفی از انواع مختلفی از CNN بر روی GPU انجام شده است که اکثر آنها از عملیات Max pooling استفاده میکنند (۲۱, ۲۷). .
لایه های POOLING از میان سه لایه شبکه های کانولوشن , تنها لایه ای هستند که بیشترین میزان مطالعه روی آنها انجام شده است. سه روش معروف در رابطه با این لایه وجود دارد که هرکدام اهداف متفاوتی را دنبال میکنند.
Stochastic pooling
یک کاستی max pooling این است که نسبت به overfitting مجموعه آموزشی [۱۰] حساس بوده, و تعمیم را سخت میکند. (۲۲) با هدف حل این مشکل, Zeiler et al.(28) روش stochastic pooling را پیشنهاد داد که در آن عملیات قطعی pooling با یک رویه اتفاقی[۱۱] جایگزین میشود. این رویه اتفاقی ,انتخاب تصادفی مقادیر در داخل هر ناحیه Pooling بر اساس یک توزیع چندجمله ای است. این عملیات شبیه max pooling استاندارد با تعداد زیادی کپی از تصویر ورودی که هر کدام تغییرشکل[۱۲] محلی کوچکی دارند است. طبیعت تصادفی (stochastic) بودن برای جلوگیری از مشکل Overfitting مفید بوده و به همین دلیل از آن در این روش استفاده شده است.[۱۳]
Spatial pyramid pooling (SPP)
معمولا روش های مبتنی بر شبکه های عصبی کانولوشن نیازمند یک تصویر ورودی با اندازه ثابت هستند. این محدودیت ممکن است باعث کاهش دقت تشخیص برای تصاویری با اندازه دلخواه شود. به منظور حذف این محدودیت , He et al(29) از یک معماری شبکه عصبی کانولوشن معمولی استفاده کرد با این تفاوت که لایه pooling آخر را با یک لایه spatial pyramid pooling جایگزین نمود. این لایه قادر به استخراج نماد ها (تصاویر) با اندازه ثابت از تصاویر (یا نواحی) دلخواه است. این روش باعث ایجاد یک راه حل قابل انعطاف برای مدیریت مقیاس ها, اندازه ها و aspect ratio های مختلف میشود که میتوان از آن در هر ساختار و معماری CNNی استفاده کرده و کارایی آنرا افزایش داد.
Def-pooling
مدیریت و رسیدگی به تغییر شکل[۱۴] یک چالش اساسی در بینایی کامپیوتر است. خصوصا در زمینه های مربوط به تشخیص اشیاء (object recognition) . Max pooling و Average pooling برای مدیریت تغییر شکل (deformation) مفید اند اما قادر به یادگیری محدودیت تغییر شکل (deformation) و مدل هندسی اجزای شئ نیستند. به منظور مقابله بهتر با تغییر شکل (deformation) , Ouyang et al. (30) یک لایه pooling جدید با تغییر شکل محدود (deformation constrained pooling layer) معرفی کرد. که به def-pooling layer معروف است. تا به این وسیله مدل عمیق (deep model) بدست امده با یادگیری تغیرشکل الگوهای دیداری (deformation of visual patterns.) غنی شود. از این لایه میتوان بجای لایه max pooling در هر سطحی از انتزاع استفاده کرد.
میتوان از ترکیب چندین نوع مختلف لایه pooling که هر کدام با هدف و شیوه متفاوتی توسعه پیدا کرده اند, کارایی یک شبکه عصبی کانولوشن را افزایش داد.
لایه تماما متصل
بعد از آخرین لایه Pooling , همانطور که در شکل ۲ مشاهده میشود, لایه های تماما متصل وجود دارند که feature map های ۲ بعدی را به feature vector یک بعدی جهت ادامه فرآیند feature representation تبدیل میکند.
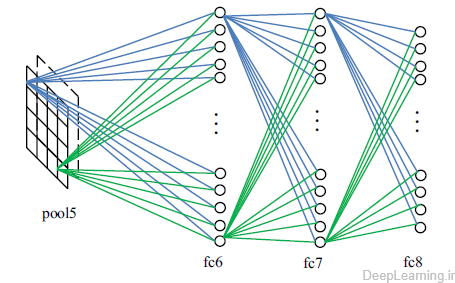
- عملیات لایه های تماما متصل که بعد از آخرین لایه Pooling قرار گرفته اند
لایه های تماما متصل همانند همتایان خود در شبکه های عصبی مصنوعی سنتی عمل میکنند و تقریبا ۹۰% پارامترهای یک شبکه CNN را شامل میشوند. لایه تماما متصل بما اجازه میدهد تا نتیجه شبکه را در قالب یک بردار با اندازه مشخص ارائه کنیم . ما میتوانیم از این بردار برای دسته بندی تصاویر(۲۱) استفاده کنیم و یا اینکه از آن جهت ادامه پردازش های بعدی بهره ببریم .(۳۱)
تغییر ساختار لایه های تماما متصل رایج نیست , اما یک نمونه در روش Transferred learning(32) انجام شد که در آن پارامترهای فراگرفته شده توسط ImageNet(21) حفظ شده اما لایه تماما متصل آخر با دو لایه تماما متصل جایگزین شد تا شبکه با اینکار بتواند با فعالیتهای تشخیص بینایی جدید انطباق پیدا کند.
مشکل بزرگ این نوع لایه ها این است که دارای تعداد بسیار زیادی پارامتر اند. که نتیجه این امر هزینه پردازشی بسیار بالایی است که در زمان آموزش بایستی صرف شود. بنابر این یک روش که معمولا بکاربرده میشود و نتایج رضایت بخشی نیز دارد این است که یا کلا این لایه ها حذف شوند و یا تعداد اتصالات در این لایه ها توسط روشهایی کاهش یابد. بعنوان مثال GoogLeNet(23) یک شبکه عمیق و گسترده را طراحی کرد که در آن هزینه محاسباتی ثابت نگه داشته شده است . این کار با تعویض معماری تماما متصل با معماری بطور پراکنده متصل صورت گرفت.
استراتژی آموزش (Training strategy)
در قیاس با shallow learning , فایده یادگیری عمیق این است که میتوان معماری های عمیق (deep architecture) را جهت یادگیری اطلاعات انتزاعی تر ایجاد کرد . اما تعداد بسیار زیاد پارامترهای معرفی شده, ممکن است سبب مشکل overfitting شود. اخیرا روش های regularization زیادی در مقابله با Overfitting ارائه شده است مثل روش stochastic pooling که در قبل به آن اشاره کردیم . در این بخش ما چند تکنیک و روش regularization را که سبب بهبود کارایی شبکه میشود را معرفی میکنیم .دقت کنید که الزاما تمامی تکنیک های معرفی شده در این بخش ,خاص شبکه های عصبی کانولوشن نیستد. یعنی این تکنیک ها قابل اعمال در شبکه های عصبی مصنوعی سنتی هم هستند (مثل شیوه dropout )
Droppout و DropConnect
تکنیک Dropout توسط Hinton et al.(33) ارائه شد و توسط Baldi et al. (34) هم بصورت کامل توضیح داده شد. روش dropout به منظور جلوگیری از overfitting معرفی شد. و نحوه کار آن به این صورت است که در هر مرحله از آموزش, هر نورون یا با احتمال ۱-p (از شبکه) بیرون انداخته شده (dropped out) و یا با احتمال p نگه داشته میشود, بطوریکه نهایتا یک شبکه کاهش داده شده باقی بماند. یالهای ورودی و خروجی به یک نود بیرون انداخته شده (dropped-out node) نیز حذف میشوند.اینگونه تنها شبکه کاهش یافته بر روی داده ها در آن مرحله آموزش خواهد دید.(بعد از این کار) نودهای حذف شده سپس به همراه وزنهای سابق آنها(قبل از حذف شدن) دوباره به درون شبکه وارد میشوند. این تکنیک بعدا در (۳۵-۴۰) بهبود پیدا کرد. Warde-Farley et al.(38) در تحقیقات خود بهینگی dropout ها را مورد تحلیل قرار داد و نهایتا عنوان کرد که dropout یک شیوه یادگیری گروهی بسیار موثر است.
یک نمونه معروف مشتق شده از Dropout به(۴۱) DropConnect معروف است که بصورت تصادفی وزنها را بجای مقادیر فعالسازی حذف میکند. آزمایشات نشان دادند که این روش میتواند پایاپای و حتی بهتر از روش Dropout در انواع گوناگونی از Benchmark های استاندارد عمل کند. هرچند با سرعت کمتر. شکل ۶ مقایسه ای از یک معماری بدون حذف (No Drop) , Dropout و DropConnect را نشان میدهد. (۴۱)

- مقایسه ای بین شبکه های No-Drop , Dropout و DropConnect.
Data augmentation
معمولا زمانی که از یک CNN برای تشخیص شئ (object recognition) استفاده میشود, از data augmentation برای تولید داده های اضافی بدون تحمیل هزینه برچسب گذاری بیشتر استفاده میکنند. شبکه AlexNet(21) از دو شکل مشخص data augmentation استفاده کرد . اولین شکل data augmentation شامل ایجاد image translation و انعکاس های افقی (horizontal reflections) بود, و دومین شکل شامل تغییر شدت نور در کانالهای RGB تصاویر بود. Howard et al.(42) با انتخاب AlexNet(21) به عنوان مدل پایه خود و بعد با اضافه کردن تبدیلات (transformations) اضافی که توسعه image crops با پیکسلهای اضافی و افزودن تغییرات رنگی بیشتر (color manipulations) بود, باعث بهبود translation invariance و Color Invariance شد. این شیوه data augmentation بصورت گسترده توسط تعدادی از تحقیقات اخیر مورد استفاده قرار گرفته است.. (۲۳, ۲۹) Dosovitskiy et al.(43) یک شیوه یادگیری ویژگی بدون سرپرست (unsupervised feature learning) مبتنی بر data augmentation ارائه داد که در آن شیوه کار به اینصورت است. این روش ابتدا بصورت تصادفی تعدادی image patch را انتخاب کرده و آنها را بعنوان یک کلاس جانشین در نظر میگیرد, سپس این کلاسها را با اعمال تبدیلات مربوط به translation , scale , رنگ و contrast گسترش(بسط) داده و نهایتا یک شبکه CNN را جهت تشخیص و تمایز بین این کلاسهای جانشین(surrogate classes) آموزش میدهد. ویژگی های فراگرفته شده توسط این شبکه نتایج خوبی را در زمینه های مختلف دسته بندی نشان میدهد. Wu et al.(44) علاوه بر روش های کلاسیک همانند scaling, rotating و cropping از color casting, تکنیک های lens distortion و vignetting نیز بهره برد که همین امر باعث ایجاد نمونه های آموزشی بیشتر با پوشش گسترده تری شد.
پیش آموزش و تنظیم دقیق (pre-training and fine-tuning)
پیش آموزش (pre-training)به معنای آماده سازی (مقدار اولیه دادن) شبکه با پارامترهای از قبل آموزش داده شده بجای پارامترهای تصادفی است. این روش در مدلهای مبتنی بر CNN بسیار محبوب است چرا که فرآیند یادگیری را تسریع کرده و همینطور قابلیت تعمیم را بهبود میبخشد. Erhan et al.(45) شبیه سازی های گسترده ای را بر روی الگوریتم های فعلی انجام داد تا دلیل اینکه شبکه های از قبل آموزش داده شده از شبکه هایی که بصورت سنتی آموزش داده میشوند بهتر کار میکنند را بفهمد. از زمانی که AlexNet (۲۱) توانست به کارایی فوق العاده ای دست پیدا کند و بعد از انتشار آن بصورت عمومی , روش های بسیار زیادی AlexNet را که بر روی مجموعه تصاویر ImageNet2012 آموزش دیده بود, بعنوان مدل عمیق پایه (baseline deep model) خود انتخاب کردند. (۳۱, ۳۲, ۴۶) و بعد با روش های اختصاصی خود شروع به تنظیم دقیق (بهینه سازی) (fine-tuning) پارامترهای آن کردند. البته روش های دیگری(۳۰, ۴۷, ۴۸) نیز هستند که با آموزش بر روی مدلهایی مثل Clarifai(49), GoogLeNet (23), و VGG(50) کارایی بهتری ارائه میکنند. تنظیم دقیق (بهینه سازی) (fine-tuning) مرحله ای بسیار حیاتی برای تصحیح کردن مدلهاست تا با مجموعه داده ها و کارهای(فعالیتهای) خاص وقف پیدا کنند. بطور کلی تنظیم دقیق (بهینه سازی) (fine-tuning) نیازمند برچسب برای دسته های مختلف در مجموعه داده آموزشی جدید است که برای محاسبه تابع خطا مورد استفاده قرار میگیرد.
در این حالت, تمامی لایه های مدل جدید بجز لایه خروجی آخر که به تعداد برچسب دسته های مجموعه داده جدید بستگی دارد و بصورت تصادفی مقدار میگیرد, بر اساس مدل از قبل آموزش داده شده مثل AlexNet(21) مقدار دهی میشوند. البته در بعضی موارد, بدست آوردن برچسب دسته ها برای مجموعه داده جدید کار سختی است. برای حل این مشکل, یک تابع هدف یادگیری شباهت (similarity learning objective function) ارائه شد تا بعنوان تابع خطا (loss function) بدون برچسب کلاسها مورد استفاده قرار بگیرد. (۵۱). بنابر این اینطور, عمل backpropagation بصورت معمولی کار کرده و مدل هم میتواند لایه به لایه تصحیح شود. (بهتر شود)
نتایج تحقیقات زیادی وجود دارند که چگونگی انتقال بهینه یک مدل از پیش آموزش داده شده را توضیح میدهند. یک راه جدیددر (۵۲) ارائه شده است که میزان عمومی و یا خاص بودن یک لایه را میتوان بصورت عددی مشخص کرد یعنی اینکه ویژگی های در آن لایه تا چه اندازه از یک کاربرد به کاربرد دیگر بخوبی منتقل شوند. محققان در این تحقیق نتیجه گرفتند که مقدار دهی اولیه یک شبکه با ویژگی های منتقل شده تقریبا از هر تعدادی از لایه ها میتواند باعث بهبود کارایی regularization بعد از بهینه سازی در یک مجموعه داده جدید شود.
علاوه بر روش های regularization که قبلا توضیح داده شدند, روش های رایج دیگری مثل weight decay , weight tying و …. هم وجود دارند. (۱۱). . روش weight decaying با اضافه کردن یک عبارت به تابع هزینه به منظور مجازات پارامترها, باعث جلوگیری آنها از دقیقا مدل کردن داده های آموزشی میشود و اینطور باعث تعمیم مثالهای جدید میشود. (۲۱) .
Weight tying به مدلها اجازه میدهد تا با کاهش تعداد پارامترها در شبکه های عصبی کانولوشن, نمایش های خوبی از داده ورودی را یاد بگیرند(۵۳) . نکته جالب دیگر که باید به آن توجه کرد این است که میتوان برای افزایش کارایی این روشهای regularization را با هم ترکیب کرد و اینطور نیست که تنها قادر به استفاده از یکی از این روشها در معماری خود باشیم .
معماری شبکه های عصبی کانولوشن
با پیشرفت های اخیر استفاده CNN در حوزه بینایی کامپیوتر , مدلهای معروفی از شبکه های عصبی کانولوشن بوجود آمدند. در این بخش ما مدلهایی که بیشتر متداول بوده را مورد مطالعه قرار میدهیم و سپس خصوصیات هریک را در کاربردهای آنها بصورت خلاصه عنوان میکنیم .
پیکربندی و دستاوردهای چند مدل CNN معمولی در جدول ۱ آورده شده است.
AlexNet یک معماری قابل توجه برای شبکه عصبی کانولوشن است که شامل ۵ لایه کانولوشنی و سه لایه تماما متصل است. این معماری تصاویر با اندازه ۲۲۴x224x3 را بعنوان ورودی دریافت کرده و سپس با انجام عملیات های convolution و pooling پی در پی و نهایتا ارسال نتایج به لایه های تماما متصل تصویر ورودی را مورد پردازش قرار میدهد. این شبکه بر روی مجموعه داده ImageNet آموزش دیده و در آن از تکنیک های مختلف regularization همانند data augmentation , Dropout و…. استفاده شده است . این معماری برنده رقابت ILSVRC2012(16) شد و باعث افزایش ناگهانی علاقه به مبحث شبکه های عصبی کانولوشنی عمیق شد.
اما این معماری ۲ مشکل بزرگ دارد که عبارتند از :
- این معماری نیازمند تصاویری با اندازه ثابت است
- هیچ درک درستی از اینکه چرا این معماری به این خوبی کار میکند وجود ندارد.
در سال ۲۰۱۳ , Zeiler et al.(54) روش نمایش بصری نوینی را معرفی کرد که با استفاده از آن میشد فعالیت های صورت گرفته درون لایه های یک شبکه عصبی کانولوشن را مشاهده کرد.
| روش | سال | مقام | پیکربندی | دستاورد |
| AlexNet | ۲۰۱۲ | اول | ۵ لایه کانولوشن + ۳ لایه تماما متصل | معماری مهمی که باعث علاقه بسیاری از محققان در زمینه بینایی کامپیوتر شد |
| Clarifai | ۲۰۱۳ | اول | ۵ لایه کانولوشن + ۳ لایه تماما متصل | باعث شد تا اتفاقاتی که در داخل شبکه رخ میدهد قابل دیدن باشند |
| SPP | ۲۰۱۴ | سوم | ۵ لایه کانولوشن + ۳ لایه تماما متصل | با ارائه spatial pyramid pooling محدودیت اندازه تصاویر را از میان برداشت |
| VGG | ۲۰۱۴ | دوم | ۱۵-۱۳ لایه کانولوشن + ۳ لایه تماما متصل | ارزیابی کاملی از شبکه با عمق افزایشی |
| GoogLeNet | ۲۰۱۴ | اول | ۲۱ لایه کانولوشن + ۱ لایه تماما متصل | افزایش عمق و عرض شبکه را بدون افزایش نیازمندی های محاسباتی |
| ResNet | ۲۰۱۵ | اول | ۱۵۲ لایه کانولوشن +۱ لایه تماما متصل | افزایش عمق شبکه و ارائه روشی جهت جلوگیری از اشباع شدگی گرادیانت |
- مدلهای مطرح CNN به همراه پیکربندی و دستاوردهای هریک در مسابقات ILSVRC
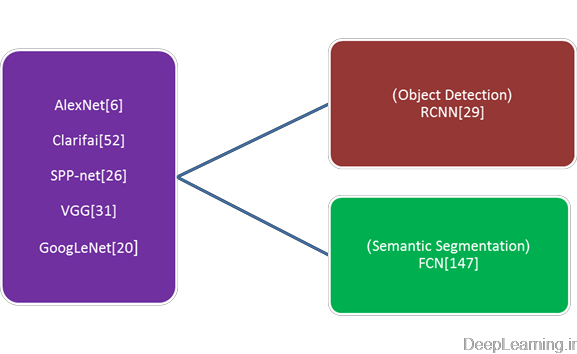
- مدلهای پایه CNN و مدلهای مشتق شده از آنها
این نمایش های بصری به آنها اجازه داد تا معماری هایی که عملکرد به مراتب بهتری از AlexNet در رقابت دسته بندی ImageNet داشتند را پیدا کرده و اینطور مدل نتیجه شده آنها, Clarifai بالاترین کارایی را در رقابت ILSVR2013 بدست آورد.
برای حل “محدودیت نیاز به یک رزولوشن ثابت برای تصاویر ورودی” هم , He et al.(46) یک استراتژی pooling جدید ارائه کرد (spatial pyramid pooling) تا به این وسیله محدودیت اندازه تصویر را از بین بردارد. معماری SPP-net بدست آمده از این روش, علیرغم متفاوت بودن طراحی ها, قادر به بهبود دقت در تعداد متنوعی از معماری های CNN منتشر شده است .
علاوه بر پیکربندی رایج شبکه های عصبی کانولوشن (۵ لایه کانولوشنی به اضافه ۳ لایه تماما متصل) روش های دیگری هم وجود دارند که سعی میکنند شبکه های عمیقتری را مورد کاوش و بررسی قرار دهند.برخلاف AlexNet , VGGNet(50) عمق شبکه را با اضافه کردن تعداد بیشتری از لایه های کانولوشن و استفاده از فیلترهای کانولوشنی کوچک در تمام لایه ها افزایش داد.به همین صورت, Szegedy et al. (23)مدلی بنام GoogLeNet را ارائه داد که ساختار بسیار عمیقی داشت (دارای ۲۲ لایه بود) و توانست در رقابت ILSVRC2014(16) مقام اول را کسب کند. علیرغم کارایی دسته بندی بسیار بالا که توسط مدلهای مختلف بدست آمد, مدلهای مبتنی بر CNN و کاربردهای مختلف آنها تنها محدود به دسته بندی تصاویر نیستند. بر اساس این مدلها, چارچوبهای جدیدی بدست آمد تا برای استفاده در کارهای سخت دیگری همانند شناسایی شیئ (object detection) , Semantic segmentation و… قابل استفاده باشند.
دو چارچوب مشتق شده معروف در این زمینه وجود دارد : RCNN(Regions with CNN features) (31) و FCN(Fully convolutional network(48) ) که به ترتیب در اصل برای object detection و semantic segmentation طراحی شده اند. ایده اصلی RCNN ایجاد پیشنهادهای چندگانه (multiple object proposals) , استخراج ویژگی ها از هریک با استفاده از یک CNN و سپس دسته بندی هر پنجره کاندید, با یک SVM خطی مختص هر دسته, است. طرح “تشخیص از طریق ناحیه ها” (recognition using regions) کارایی دلگرم کننده ای در Object detection بدست آورد و کم کم به معماری کلی برای الگوریتم های نوید بخش اخیر در شناسایی اشیاء (object detection) تبدیل شده است. (۵۵-۵۸)
البته کارایی RCNN بیش از حد روی دقت مکان شئ تکیه دارد که همین امر ممکن است قدرت آنرا محدود کند. علاوه بر این, ایجاد و پردازش تعداد زیادی از پیشنهادها ممکن است بهینگی آنرا کاهش دهد. پیشرفت های اخیر در این حوزه (۵۵, ۵۶, ۵۸-۶۰) عمدتا بر روی این دو مبحث تمرکز کرده اند.
RCNN مدلهای CNN را بعنوان یک استخراجگر ویژگی (feature extractor) مورد استفاده قرار داده و هیچ تغییری در شبکه اعمال نمیکند. اما برخلاف آن, FCN روشی برای از نو طرح کردن مدلهای CNN بصورت شبکه های تمام کانولوشنی ارائه میکند و قادر به تولید خروجی هایی با اندازه متناسب بصورت بهینه است.گرچه FCN عمدتا برای semantic segmentation ارائه شده است اما این تکنیک را میتوان در کاربردهای دیگر نظیر دسته بندی تصاویر (۶۱) , لبه یابی(۶۲) وغیره نیز مورد استفاده قرار داد.
گذشته از ایجاد مدلهای متنوع, کاربرد این مدلها یکسری خصوصیتها را نشان میدهد:
شبکه های عظیم
یک ایده شهودی این است که کارایی شبکه های کانولوشن را با افزایش اندازه آنها که شامل افزایش عمق (تعداد سطوح) و عرض آن (تعداد واحدها در هر سطح) (۲۳) افزایش دهیم. هم GoogLeNet(23) و هم VGGNet(50) که پیشتر توضیح داده شده اند, از شبکه های بسیار بزرگ , به ترتیب با ۲۲ و ۱۹ لایه استفاده کردند و با این کار نشان دادند که افزایش اندازه برای دقت تشخیص تصویر سودمند است.
آموزش چندین شبکه بطور مشترک میتواند سبب کارایی بهتر نسبت به آموزش یک شبکه به تنهایی شود. محققان بسیاری وجود دارند (۳۰, ۶۳, ۶۴) که شبکه های بزرگی را با ترکیب ساختارهای عمیق مختلف بصورت آبشاری طراحی کرده اند که در آن خروجی یک شبکه توسط شبکه دیگر مورد استفاده قرار میگیرد . این مسئله در شکل ۸ نمایش داده شده است. ساختار آبشاری را میتوان برای استفاده در کارهای مختلف مورد استفاده قرار داد و عملکرد شبکه های ابتدایی (یعنی خروجی آنها) ممکن است با توجه به کاربرد موردنظر تغییر کند. بعنوان مثال Wang et al.(64) دو شبکه را برای object extraction بهم متصل کرده و اولین شبکه برای object localization مورد استفاده قرار گرفت که خروجی آن مختصات متناظر با شئ بود. Sun et al.(63) شبکه های کانولوشنی سه سطحی با دقت طراحی شده را برای شناسایی نقاط کلیدی صورت (facial keypoints) ارائه داد که در آن سطح اول تخمین های اولیه بسیار قدرتمندی را فراهم میکرد در حالی که دو سطح بعدی اقدام به تنظیم دقیق (بهینه سازی =fine-tuning ) این تخمین اولیه میکردند. به همین شکل, Ouyang et al. (30) یک طرح آموزش چند مرحله ای که توسط Zeng et al.(65) ارائه شده بود را مورد استفاده قرار داد. به این معنی که دسته بندی کننده هایی در مراحل قبلی بصورت مشترک با دسته بندی کننده هایی در مرحله فعلی کار کرده تا به نمونه هایی که اشتباها دسته بندی شده اند رسیدگی کنند.

- ترکیب ساختارهای عمیق بصورت آبشاری
چندین شبکه :
یک گرایش دیگر در کاربردهای فعلی این است که بجای طراحی یک معماری منفرد (single architecture)و آموزش مشترک تمام شبکه های داخلی آن به منظور اجرای یک کار(فعالیت) , نتایج چندین شبکه را که هر کدام قادر به اجرای مستقل کاری هستند, ترکیب کنند. این مسئله در شکل ۹ نمایش داده شده است.
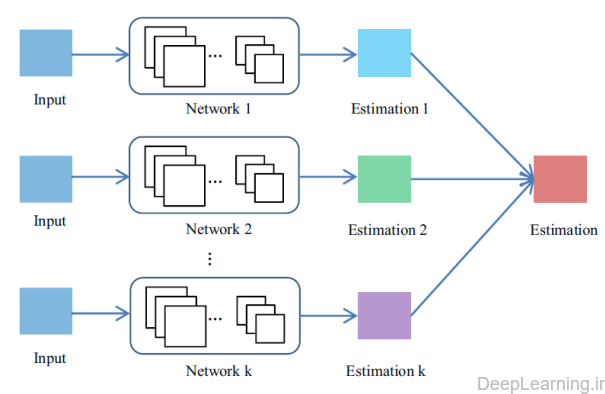
- ترکیب نتایج حاصل از چند شبکه
Miclut et al. (66) نشان داد که چگونه باید نتایج نهایی را در زمان دریافت مجموعه امتیازات ایجاد کرد. قبل از AlexNet(21) , Ciresan et al. [5] روشی بنام Multi-Column DNN (MCDNN) ارائه کرد که در آن چندین ستون DNN با هم ترکیب شده و تخمین های آنها میانگین گرفته میشد. این مدل توانست به نتایج قابل رقابت با انسان در کارهایی مثل تشخیص ارقام با دست نوشته شده یا علامتهای راهنمایی رانندگی (traffic signs) دست پیدا کند. اخیرا Ouyang et al. (30) آزمایشی را جهت ارزیابی کارایی استراتژی های ترکیب مدلها باهم, انجام داد. طی این آزمایش او ۱۰ مدل را با تنظیمات مختلف آموزش داده و سپس آنها را در یک طرح میانگین گیری (averaging scheme) با هم ترکیب کرد. نتایج حاصله نشان دادند که مدلهای تولید شده به این شکل, تنوع بالایی داشته و بصورت مکمل نسبت به همدیگر عمل میکنند که همین امر باعث بهبود نتایج تشخیص (detection results) میشود.
شبکه های متنوع (Diverse networks)
گذشته از تغییر ساختار CNN , بعضی از محققان تلاش کردند تا اطلاعات را از منابع دیگری مثل ترکیب آنها با ساختار های کم عمق (shallow structures) و ادغام اطلاعات متنی(زمینه ای) (integrating contextual information) , بدست آورده و به مدل ارائه کنند.
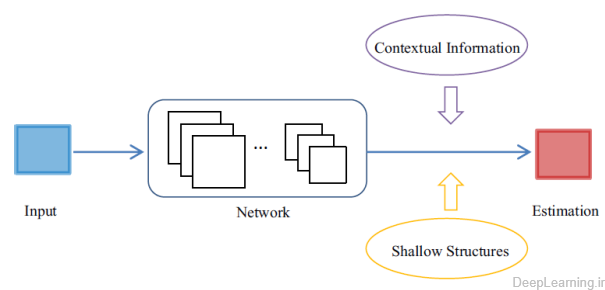
- ترکیب یک شبکه عمیق با منابع اطلاعاتی دیگر
روش های کم عمق (shallow methods) میتوانند دیدی اضافی از مشکل ارائه دهند. در ادبیات (تحقیقات) (literature) میتوان نمونه هایی در باره ترکیب روش های کم عمق با چارچوب های یادگیری عمیق یافت (۶۷). این به عبارت دیگر یعنی یک روش یادگیری عمیق را گرفته و از آن برای استخراج ویژگی ها مورد استفاده قرار دهیم . سپس این ویژگی ها را به یک روش shallow learning مثل یک SVM ارائه کنیم . یکی از بهترین و موفقترین الگوریتم ها در این زمینه روش RCNN(31) است که ویژگی های CNN بسیار متمایز را به یک SVM ارائه کرده تا کار تشخیص شئ (object detection)نهایی انجام شود. علاوه بر این, شبکه های عصبی کانولوشن عمیق و بردار های فیشر (Fisher Vectors) مکمل یکدیگر بوده و میتوانند در صورت ترکیب شدن با هم بصورت قابل ملاحظه ای دقت دسته بندی تصاویر را بهبود دهند. (۶۸)
گاهی اوقات اطلاعات متنی (زمینه ای) (contextual information) برای یک فعالیت مثل تشخیص شئ (object detection) موجود بوده و امکان ادغام اطلاعات متنی سراسری با اطلاعات جعبه شناسایی (bounding box) وجود دارد. در رقابت تشخیص بینایی مقیاس بزرگ ImageNet در سال ۲۰۱۴ (به اختصار ILSVRC2014) تیم برنده, تمامی امتیازات خام مربوط به تشخیص (raw detection scores) را بهم متصل کرده و آنها را با خروجی های حاصله از یک چارچوب دسته بندی سنتی(traditional classification framework) با استفاده از context refinement(69) ترکیب کرد. بطور مشابه, Ouyang et al. (30), نیز امتیازات دسته بندی تصاویر (۱۰۰۰ دسته ای) را بعنوان ویژگی های متنی برای object detection مورد استفاده قرار داد.
۱-۲-۲-Restricted Boltzmann Machines (RBMs)
یک ماشین بولتزمن محدود شده (Restricted Boltzmann Machines (RBMs)) یک شبکه عصبی مولد تصادفی (generative stochastic neural network) است که توسط Hinton et al. در سال ۱۹۸۶ ارائه شد .(۷۰) یک RBM گونه ای از یک ماشین بولتزمن (Boltzman Machine) است که دارای محدودیتی است که در آن واحدهای مشخص (visible units) و واحدهای پنهان(hidden units) باید تشکیل یک گراف دو قسمتی(bipartite graph) را دهند . این محدودیت باعث ایجاد الگوریتم های آموزشی بهینه تر ,علی الخصوص الگوریتم واگرایی تقابلی مبتنی بر گرادیانت (gradient-based contrastive divergence) میشود. (۷۱).از آنجایی که این مدل یک گراف دو قسمتی (bipartite graph) است, واحدهای پنهان (hidden units) H و واحدهای مشخص (visible units) V1 بصورت مشروط مستقل اند. بنابر این در معادله زیر
![]()
هم H و هم V1 توزیع بولتزمن را برآورده(satisfy) میکنند. با ورودی V1 ما میتوانیم H را از طریق ![]() بدست بیاوریم. به همین شکل ما میتوانیم مقدار V2 را از طریق
بدست بیاوریم. به همین شکل ما میتوانیم مقدار V2 را از طریق ![]() بدست بیاوریم . با تنظیم پارامترها, ما میتوانیم اختلاف بین V1 و V2را به حداقل برسانیم و H نتیجه شده بعنوان یک ویژگی خوب از V1 عمل خواهد کرد.
بدست بیاوریم . با تنظیم پارامترها, ما میتوانیم اختلاف بین V1 و V2را به حداقل برسانیم و H نتیجه شده بعنوان یک ویژگی خوب از V1 عمل خواهد کرد.
Hinton(72) توضیح مبسوطی در این زمینه داد و یک راه عملی برای آموزش RBMها فراهم کرد. در (۷۳)مشکلات اصلی آموزش RBM ها و دلایل زیربنایی آنها مورد بحث قرار گرفته و یک الگوریتم جدید که شامل نرخ یادگیری قابل تطبیق (Adaptive learning rate) و گرادیانت بهبود یافته برای رفع مشکلات مطرحی بود, ارائه شد. یک نمونه مشهور از RBM را میتوان در (۷۴)یافت. این مدل واحدهای دودویی (binary unites) را به همراه واحدهای خطی تصحیح شده نویزدار (noisy rectified linear units) به منظور حفظ اطلاعات در مورد شدتهای نسبی(relative intensities) در حین گردش اطلاعات در لایه ها تقریب میزند. نه تنها این اصلاح (refinement) در این مدل بخوبی کار میکند بلکه بصورت گسترده در روشهای مختلف مبتنی بر CNN نیز بکار برده میشود(۲۱, ۲۸).
با استفاده از RBM ها بعنوان ماجول های یادگیری, ما میتوانیم مدلهای عمیق Deep Belief Networks(DBNs) , Deep Boltzman Machines(DBMs) و Deep Energy Models(DEMs) را ایجاد کنیم .مقایسه میان این سه مدل در شکل ۱۱ نشان داده شده است . DBN ها دارای اتصالات بیجهت (undirected connections) در دو لایه بالایی که تشکیل یک RBM را داده و دارای اتصالات هدایت شده(جهت دار) در لایه های پایینی هستند .DBM ها دارای اتصالات بیجهت بین تمامی لایه های شبکه هستند. DEM ها هم دارای واحدهای پنهان قطعی (deterministic hidden units) برای لایه های پایین و واحدهای پنهان تصادفی (stochastic hidden units) برای لایه بالا (top hidden layer) هستند. (۷۵).
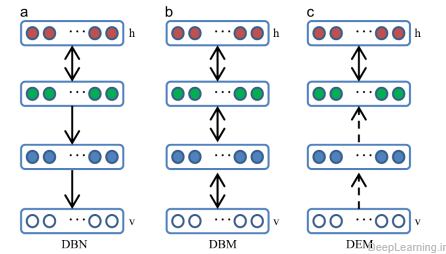
- مقایسه سه مدل عمیق DBNوDBM و DEM
خلاصه ای از این سه مدل به همراه نمونه کارهای انجام شده با آنها را در جدول ۲ مشاهده میکنید .
خلاصه ای از روشهای مبتنی بر RBM .
| مراجع | نکات منفی(کاستی ها) | نکات مثبت | مشخصه ها | روش |
| Yanming Guo et all(review) | بخاطر فرآیند مقداردهی اولیه, ایجاد یک مدل DBN از لحاظ محاسباتی هزینه بر است | ۱٫شبکه را بطور مناسب مقداردهی اولیه میکند و تا حدودی از افتادن در بهینه محلی ضعیف جلوگیری میکند
۲٫ فرآیند آموزش بدون سرپرست است که به همین علت ضرورت وجود داده برچسب گذاری شده برای آموزش را از بین میبرد.
|
اتصالات بدون جهت در دو لایه بالایی و اتصالات جهت دار در لایه های پایینی | DBN |
| Yanming Guo et all(review) | بهینه سازی مشترک(joint optimization) زمان بر است | با ورودی های مبهم بوسیله استفاده از بازخورد بالا به پایین بهتر برخورد میکند | اتصالات بی جهت بین تمامی لایه ها در شبکه
|
DBM |
| Yanming Guo et all(review) | وزن اولیه فراگرفته شده ممکن است همگرایی خوبی نداشته باشد
|
مدلهای مولد بهتری را با اجازه دادن به لایه های پایینی به تطبیق با آموزش لایه های بالایی ایجاد میکند. | واحدهای پنهان قطعی در لایه های زیرین و واحدهای پنهان تصادفی در لایه مخفی بالایی | DEM |
- خلاصه ای از سه مدل و نمونه کارهای انجام شده هریک
شبکه باور عمیق یا همان Deep Belief Network (DBN)توسط Hinton ارائه شد. (۷۶) این شبکه پیشرفت قابل ملاحظه ای در یادگیری عمیق بود. DBN یک مدل مولد احتمالی است که توزیع احتمال مشترک بر روی داده های قابل مشاهده و برچسب ها را فراهم میکند. یک DBN ابتدا از یک استراتژی یادگیری حریصانه لایه به لایه بهینه (efficient layer by layer greedy learning strategy ) برای مقدار دهی اولیه (پارامترهای) شبکه عمیق (deep network) استفاده کرده و سپس تمامی وزنها را بطور مشترک با خروجی های مورد انتظار بدقت تنظیم (fine-tune) میکند.
رویه یادگیری حریصانه دو فایده دارد(۷۷) . ۱) مقدار دهی اولیه مناسبی را برای شبکه ایجاد میکند و با اینکار به سختی ای که در انتخاب پارامتر وجود داشته و ممکن است باعث انتخاب local optima ضعیف شود تا حدی پاسخ میدهد ۲)رویه یادگیری بدون سرپرست (unsupervised ) بوده و به هیچ برچسب دسته ای (class label) نیاز ندارد بنابر این ضرورت داده برچسب دار برای آموزش را از میان برمیدارد. ایجاد یک مدل DBN اما از لحاظ محاسباتی کار بسیار پرهزینه ای است چراکه نیازمند آموزش چندیدن RBM بوده و مشخص هم نیست که چگونه میتوان حداکثر احتمال آموزش برای بهینه سازی مدل را تقریب زد. (۷۶).
DBN ها با موفقیت توجه محققان را به یادگیری عمیق معطوف کردند و در نتیجه, گونه های زیادی از آنها تولید شدند (۷۸-۸۱)
Nair et al.(81) یک DBN تغییر یافته را توسعه داد که در آن مدل لایه بالایی از یک ماشین بوتلزمن درجه ۳ (third order Boltzman Machine) برای تشخیص اشیاء (object recognition) استفاده میکرد .مدل ارائه شده در (۷۸)یک مدل دو لایه از تصاویر طبیعی را با استفاده از sparse RBM ها که در آن لایه اول فیلترهای محلی, جهت دار و لبه ای را یاد گرفته و لایه دوم تعداد متنوعی از ویژگی های contour را به همراه گوشه ها و تقاطعها دریافت میکرد. فرا گرفت. به منظور بهبود قدرت مدل در برابر انسداد (occlusion) و نویزهای تصادفی(random noie) , Lee et al.(82) از ۲ استراتژی استفاده کرد.استراتژی اول بهره بردن از اتصالات تنک (sparse connection) در لایه اول DBN به منظور regularize کردن مدل بود و استراتژی دوم توسعه یک الگوریتم حذف نویز احتمالاتی (probabilistic de-noising algorithm) بود. درصورتی که قصد این را داشته باشیم تا از این شبکه در فعالیت های بینایی کامپیوتر استفاده کنیم ,به مشکل برخواهیم خورد. مشکل DBN این است که آنها ساختار ۲بعدی یک تصویر ورودی را در نظر نمیگیرند. برای رفع این مشکل, شبکه باور عمیق کانولوشنی (Convolutional Deep Belief Network) یا به اختصار CDBN ها معرفی شدند(۷۹). CDBN از اطلاعات مکانی پیکسهای همسایه با معرفی RBM کانولوشنی, بهره میبرد و با این کار یک مدل مولد translation invariant که بخوبی با تصاویر با اندازه های بزرگ مقیاس پذیر است ایجاد میکند. این الگوریتم در(۸۳) بیشتر بسط داده شد و کارایی بسیار عالی در تایید صورت(face verification) بدست آورد.
۱-۲-۳-Deep Boltzmann Machines (DBMs)
ماشین بولتزمن عمیق یا به اختصار DBM , توسط et al.(84) Salakhutdinov ارائه شد و یکی دیگر از الگوریتم های یادگیری عمیق است که در آن, واحدهای پردازشی در لایه هایی قرار میگیرند.در قیاس با DBN ها که دو لایه بالایی تشکیل یک مدل گرافی بی جهت و لایه های پایینی تشکیل یک مدل مولد جهت دار را میداد, DBM دارای اتصالاتی در سراسر ساختار خود است .
همانند RBM , DBM هم یکی از زیرمجموعه های خانواده Boltzmann است. تفاوت انها در این است که DBM ها دارای چندین لایه حاوی واحدهای پنهان (hidden units) بوده که واحدهای موجود در لایه های با شماره فرد بصورت شرطی مستقل از لایه های با شماره زوج هستند و بلعکس.
با وجود واحدهای مشخص (visible units) محاسبه توزیع خلفی ( Posterior) بر روی واحدهای پنهان ,دیگر قابل پیگیری نیست , که این نتیجه تعامل (interactions) بین واحدهای پنهان است. در زمان آموزش شبکه, یک DBM بصورت مشترک تمامی لایه های یک مدل بدون سرپرست خاص (specific unsupervised model) را آموزش داده و بجای بیشینه سازی احتمال بصورت مستقیم, از الگوریتم مبتنی بر احتمال بیشینه تصادفی (stochastic maximum likelihood) یا به اختصار SML برای بیشینه سازی مرزپایینی در احتمال استفاده میکند. (۸۵) به عبارت بهتر این به معنای اعمال تنها یک و یا چند بروز آوری با استفاده از روش Markov chain Monte Carlo (MCMC) بین هر بروز آوری پارامتر است. به منظور جلوگیری از رسیدن به local minima ضعیف که بسیاری از واحدهای پنهان را بطور غیرفعال رها میکند, یک استراتژی آموزش مبتنی بر لایه حریصانه نیز به لایه ها در زمان پیش آموزش شبکه DBM که بسیار شبیه همان چیزی است که در DBN(76) انجام میشود, اضافه میشود.
آموزش مشترک بهبودهای نویدبخشی را هم در احتمال و هم در کارایی دسته بندی feature learner های عمیق به ارمغان اورده است . اما کاستی مهم DBM ها پیچیدگی زمانی استنتاج تقریب است که بسیار بالاتر از DBNهاست. که همین امر بهینه سازی مشترک پارامترهای DBM را برای مجموعه داده های عظیم غیرعملی میکند. به منظور افزایش بهره ور ی (بهینگی) DBM ها , بعضی از محققان الگوریتم استتنتاج تقریبی را معرفی کرده اند (۸۶, ۸۷)که از یک مدل تشخیص (recognition model) برای مقداردهی اولیه مقادیر متغییرهای پنهان(latent variables) در تمام لایه ها استفاده میکند و اینطور بطور موثری باعث تسریع استنتاج (inference) میشود. روشهای زیاد دیگری هم وجود دارند که بدنبال بهبود اثرگذاری DBM ها هستند. بهبودها یا در مرحله پیش آموزش (۸۸, ۸۹)و یا در ابتدای مرحله آموزش (۹۰, ۹۱) میتوانند اتفاق بیفتند. بعنوان مثال Montavon et al. (90) یک لم مرکزی (centering trick) برای بهبود ثبات یک DBM ارائه کرد و آنرا بیشتر افتراقی و مولد(discriminative and generative) کرد. طرح آموزشی پیش بینی چندگانه (۹۲) (Multi-prediction training scheme) به منظور آموزش مشترک DBM مورد بهره برداری قرار گرفت که باعث شد عملکرد به مراتب بهتری از متدهای قبلی در دسته بندی تصاویر مطرح شده در (۹۱)را داشته باشد.
۱-۲-۴-مدل انرژی عمیق (Deep Energy Model (DEM))
DEM توسط Ngiam et al. (75), ارئه شده و روشی نوین برای آموزش معماری های عمیق است. برخلاف DBN ها و DBM ها که در خصوصیت داشتن چندین لایه پنهان تصادفی (multiple stochastic hidden layers) دارای اشتراک هستند, DEM به منظور بهینگی آموزش و استنتاج تنها یک لایه حاوی واحدهای پنهان تصادفی(stochastic hidden units) دارد.
این مدل از شبکه های عصبی feed forward برای مدل کردن از energy landscape بهره برده و قادر است تمامی لایه ها را در آن واحد آموزش دهد. با ارزیابی کارایی این مدل بر روی تصاویر طبیعی, مشخص میشود که آموزش مشترک چندین لایه باعث بهبود کمی و کیفی نسبت به آموزش لایه به لایه حریصانه (greedy layer-wise training) میشود. Ngiam et al. (75) از Hybrid Monte Carlo (HMC) برای آموزش این مدل استفاده کرد. گزینه های دیگری همانند واگرایی تقابلی (contrastive divergence) , score matching و … نیز وجود دارند. کارهای مشابه ای را نیز میتوان در [۷۴](۹۳) یافت.
هرچند RMB ها مثل شبکه های عصبی کانولوشن برای کاربردهای بینایی کامپیوتر مناسب نیستند, اما نمونه های خوبی که از RMB ها جهت استفاده در فعالیتهای مربوط به بینایی کامپیوتر بهره بردند نیز وجود دارد. The Shape Boltzmann Machine توسط Eslami et al.(94) برای استفاده در کارهای مدلینگ binary shape images ارائه شد که توزیع احتمال با کیفیتی (high quality probability distributions) بر روی object shape ها هم به منظور واقعگرایی مثالها از توزیع (realism of samples from the distribution) و هم تعمیم به مثالهای جدید همان shape class را فرا میگرفت. Kae et al. (95) مدل CRF و RBM را با هم ترکیب کرد تا هم ساختار محلی و هم سراسری در قطعه بندی صورت را مدل کند . که این امر باعث کاهش پیوسته خطا در برچسب گذاری صورت(face labeling) شد. یک معماری عمیق جدید که برای تشخیص صدا (phone recognition) ارائه شد (۹۶)ماجول feature extraction یک RBM Mean-Covariance را با DBN استاندارد باهم ترکیب کرد. این روش هم با مشکلات نابهینگی نمایشی (representational inefficiency issues) GMM ها و هم یک محدودیت مهم در کار قبلی که DBN ها در تشخیص صدا بهره برده بود ,مقابله میکند.
۱-۲-۵- Autoencoder
Autoencoder نوع خاصی از شبکه عصبی مصنوعی است که برای encode کردن بهینه یادگیری مورد استفاده قرار میگیرد(۹۷) بجای آموزش شبکه و پیش بینی مقدار هدف Y در ازای ورودی X , یک autoencoder آموزش میبینید تا ورودی X خود را بازسازی کند. بنابر این بردارهای خروجی همان ابعاد بردار ورودی را خواهند داشت. فرآیند کلی یک autoencoder در شکل ۱۲ نشان داده شده است. در حین این فرآیند, autoencoder با کمینه سازی خطای نوسازی (reconstruction error) بهینه میشود. کد متناظر همان ویژگی فراگرفته شده است.
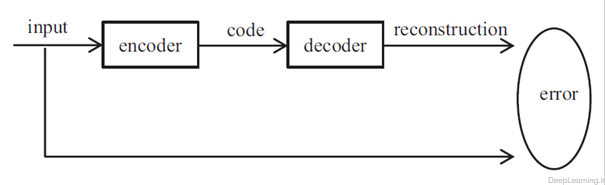
- فرآیند کلی یک autoencoder
بطور کلی, یک لایه ی تنها ,قادر به دریافت ویژگی های متمایز از داده خام نیست . محققان در حال حاضر از autoendocer عمیق استفاده میکنند که کد یادگرفته شده از autoencoder قبلی را به autoencoder بعدی جهت به انجام رساندن کار خود ارسال میکنند.
Autoencoder عمیق (deep autoencoder) توسط Hinton et al.(98) ارائه شد و هنوز بصورت گسترده در مقاله های اخیر مورد مطالعه قرار میگیرد (۹۹-۱۰۱) . یک Autoencoder عمیق اغلب با گونه ای از عملیات back-propagation مثل روش conjugate gradient آموزش میبینید. هرچند اغلب این مدل کارآمد و موثر است , اما درصورت وقوع خطا در لایه های اول میتواند بشدت ناکارآمد شود. این مسئله ممکن است باعث شود تا شبکه میانگین داده های آموزشی را بازسازی کند. یک روش مناسب جهت حذف این مشکل پیش آموزش (pre-training) شبکه با وزن های اولیه که راه حل نهایی را تقریب میزنند است. (۹۸) گونه هایی از autoencoderها هم وجود دارند که پیشنهاد کردند نمایش ها (representation) را تا حد امکان با توجه به تغییرات در ورودی ثابت نگه داشته شوند.
در جدول شماره ۳ , لیستی شامل گونه های معروف autoencoder به همراه خلاصه ای از خصائص و فواید آنها آمده است.
| روش | ویژگی ها | نکات مثبت |
| Sparse Autoencoder | Adds a sparsity penalty to force the representation to be sparse | ۱٫ Make the categories to be more separable
۲٫ Make the complex data more meaningful ۳٫ In line with biological vision system |
| Denoising Autoencoder | Recovers the correct input from a corrupted version | More robust to noise |
| Contractive Autoencoder | Adds an analytic contractive penalty to the reconstruction error
function |
Better captures the local directions of variation dictated by the data |
| Saturating autoencoder | Raises reconstruction error for inputs not near the data manifold | Limits the ability to reconstruct inputs which are not near the data manifold |
| Convolutional autoencoder | Shares weights among all locations in the input, preserving spatial
locality |
Utilizes the 2D image structure |
| Zero-bias autoencoder | Utilizes proper shrinkage function to train autoencoders without
additional regularization |
More powerful in learning representations on data with very high intrinsic dimensionality |
- لیستی شامل گونه های معروف autoencoder به همراه خلاصه ای از خصائص آنها
۱-۲-۶-Sparse autoencoder
Sparse autoencoder ها بدنبال استخراج ویژگی های پراکنده (sparse features) از داده خام هستند. پراکندگی نمودها میتواند یا از طریق جریمه (penalizing) بایاس های واحد پنهان (۷۸, ۱۰۲, ۱۰۳)(hidden unit biases) و یا مستقیما با جریمه (penalizing) خروجی مقادیر واحد پنهان بدست بیایند. (۱۰۲, ۱۰۴) بازنمودهای پراکنده (sparse representations) دارای چندین فایده احتمالی اند (۱۰۳)که عبارتند از : ۱) استفاده از نمودهای با ابعاد زیاد باعث افزایش احتمال انکه دسته های متفاوت براحتی همانند نظریه موجود در SVM , قابل جداشدن از هم باشند میشود. ۲ )نمودهای پراکنده (sparse representations) برای ما تفسیر ساده ای از داده ورودی پیچیده را در قالب تعدادی بخش فراهم میکنند. ۳) دید بیولوژیکی از نمودهای پراکنده در نواحی دیداری ابتدایی استفاده میکند. (۱۰۵)
گونه بسیار مشهوری از sparse autoencoder یک مدل ۹ لایه ای بصورت محلی متصل با pooling و نرمال سازی contrast است .(۱۰۶). این مدل به سیستم اجازه میدهد تا یک صورت یاب را بدون نیاز به برچسب زنی تصاویر بصورت “حاوی صورت و بدون صورت ” آموزش دهد. ویژگی یاب (feature detector) حاصل , برای translation , scaling و چرخش خارج از plane (out-of-plane rotation) بسیار قدرتمند است.
۱-۲-۷-Denoising autoencoder
به منظور افزایش قدرت این مدل, Vincent مدلی بنام denoising autoencoder (DAE) (107, 108) را ارئه داد که قادر به بازیابی ورودی صحیح از نسخه خراب بود. و به این ترتیب مدل را به گرفتن(capture) ساختار توزیع ورودی مجبور میکرد. فرآیند یک DAE در شکل ۱۳ نشان داده شده است .
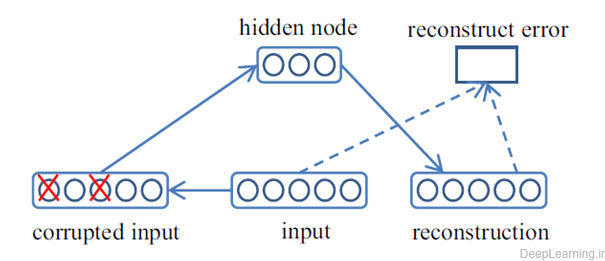
- Denoising autoencoder
۱-۲-۸-Contractive autoencoder
Contractive autoencoder یا به اختصار CAE , توسط Rifai et al.(109) ارائه شد که دنباله DAE بوده و انگیزه مشابه ای از یادگیری قدرتمند نمودها (representation) با آن داشت . (۷۶). در حالی که DAE با تزریق نویز در مجموعه آموزشی باعث قدرتمند کردن تمامی عملیات mapping میشد, CAE با اضافه کردن جریمه contactive تحلیلی (Analytic contractive penalty) به تابع خطای بازسازی به این مهم دست پیدا میکرد.
هرچند تفاوتهای قابل توجه بین DAE و CAE توسط Bengio et al. (76) عنوان شدند , اما Alain et al.(110) بیان کرد که DAE و یک شکل از CAE بسیار نزدیک به هم هستند. یک DAE با نویز خرابی کوچک (small corruption noise) را میتوان بصورت گونه ای از CAE که در آن جریمه contactive بجای اینکه بروی encoder باشد بر روی کل تابع نوسازی بوده در نظر گرفت. هم DAE و هم CAE هردو بصورت موفقیت آمیزی در رقابت transfer learning و بی سرپرست (unsupervised) مورد استفاده قرار گرفتند.(۱۱۱)
۱-۲-۹-Sparse Coding
Sparse Coding نوعی روش بدون سرپرست است که به منظور یادگیری مجموعه over-complete از توابع پایه (basic functions) برای توصیف داده ورودی مورد استفاده قرار میگیرد.(۱۱۲) . این روش مزیتهای متعددی دارد (۱۱۳-۱۱۶) بعنوان مثال میتوان به این موارد اشاره کرد : ۱) این روش قادر به بازسازی بهتر توصیفگر[۱۵] با استفاده از چندین پایه[۱۶] و گرفتن(دریافت) ارتباطات بین توصیف گرهای مشابه که دارای پایه های مشترک اند, است . ۲)پراکندگی این اجازه را میدهد تا بازنمود [۱۷] , خصائص برجسته تصاویر را دریافت کند ۳)این روش همسو با سیستم بینایی بیولوژیکی است که استدلال میکند ویژگی های پراکنده سیگنالها برای یادگیری مفید هستند. ۴) مطالعه آمار تصاویر نشان میدهد کهimage patch ها سیگنالهای پراکنده هستند. ۵) الگوها با ویژگی های پراکنده از لحاظ خطی بیشتر قابل جداسازی هستند.
الگوریتم های مطرح Sparse coding
در این بخش ما به توضیح تعدادی از الگوریتم های مطرح Sparse Coding در حوزه بینایی کامپیوتر میپردازیم . در شکل ۱۴ بعضی از این الگوریتم ها به همراه دستاوردها و مشکلات آنها نمایش داده شده اند.
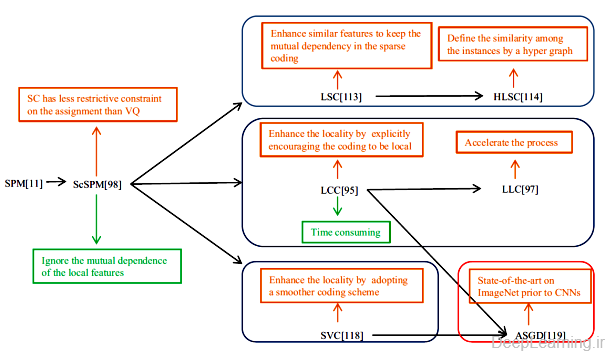
- دستاوردها و مشکلات تعدادی از الگوریتم های مطرح Sparse Coding
یک نمونه از الگوریتم های sparse coding , الگوریتم sparse coding SPM یا به اختصار ScSPM(115) است. که بسطی(extension) از الگوریتم (۱۱۷) Spatial Pyramid Matching (SPM) است برخلاف SPM که از vector quantization (VQ) برای نمایش تصویر استفاده میکند, ScSPM از Sparse coding(SC) به همراه multi scale spatial max pooling برای این منظور استفاده میکند. Codebook مربوط به Sparse coding یک over-complete basis بوده و هر ویژگی (feature) قادر به فعالسازی تعداد کمی از آنها میباشد. در قیاس با VQ , sparse coding خطای بازسازی بسیار کمتری را بواسطه قید نسبتا آزاد تری (less restrictive constraint) که بروی عمل انتساب لحاظ میکند دارد. Coates et al در رابطه با دلایل موفقیت spars coding نسبت به vector quantization تحقیقات بیشتری انجام داد و نتایج را در قالب مقاله ای (۱۱۸) با جزییات فراوان ارائه نمود. یک اشکال ScSPM این است که این روش بصورت جداگانه با ویژگی های محلی برخورد میکند(deals with) و به این ترتیب وابستگی دوطرفه بین آنها را نادیده میگیرد. که این خود باعث حساسیت بیش از حد به feature variance میشود. این یعنی sparse code ها ممکن است حتی برای ویژگی های مشابه هم نیز بشدت تغییر کنند.
به منظور برطرف سازی این مشکل, , Gao et al.(119) طی مقاله ای , روش Sparse Coding لاپلاسی (Lapacian Sparse Coding) یا به اختصار LSC را ارائه کرد که در آن ویژگی های مشابه نه تنها به مراکز دسته های بطور بهینه انتخاب شده انتساب داده میشوند بلکه تضمین میشود که مراکز دسته های انتخابی مشابه یکدیگر هم باشند. در شکل ۱۵ تفاوت بین K-means , Sparse Coding و Laplacian Sparse Coding نمایش داده شده است .
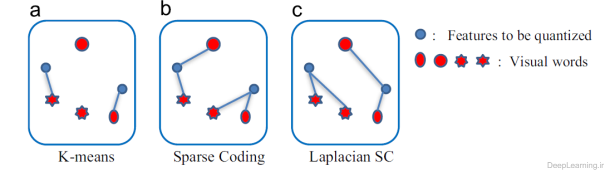
- تفاوت بین K-means , Sparse Coding و Laplacian Sparse Coding
با افزودن قید حفظ محلی بودن به اهداف sparse coding , روش LSC قادر به حفظ وابستگی دوطرفه در روش sparse coding است . Gao et al.(120) هم بعدتر روش Hypergraph Laplacian Sparse Coding یا به اختصار HLSC را که LSC را توسعه میداد ارائه کرد. روش او برای حالتی بود که شباهات در میان نمونه ها توسط یک hyper graph تعریف میشد. هر دو روش LSC و HLSC به قدرت sparse coding اضافه کردند.
روش دیگری که با استفاده از آن میشود مشکل حساسیت (بیش از حد) را برطرف کرد روش Hierarchial Sparse Coding است که توسط Yu et al. (121) ارائه شد. این روش یک مدل Sparse Coding 2 لایه را که لایه اول هر Patch را بطور جداگانه encode و لایه دوم بصورت مشترک مجموعه از patchها که به یک گروه تعلق داشتند encode میکرد, معرفی کرد. با این کار, این مدل با مدل کردن وابستگی مرتبه بالا (high order dependency) patch ها در همان ناحیه محلی تصویر بهترین استفاده را از ساختار فضای همسایه ای میبرد. علاوه بر آن, این یک روش تمام خودکار برای یادگیری ویژگی ها از سطح پیکسلی است و دیگر بعنوان مثال نیازی به طراحی دستی ویژگی SIFT نیست . Sparse coding سلسله مراتبی (Hierarchical Sparse Coding) در تحقیق دیگری (۱۲۲) برای یادگیری ویژگی های تصاویر بصورت بدون سرپرست مورد استفاده قرار گفته است. این مدل بعدها توسط Zeiler et al.(123) مورد استفاده قرار گرفت.
علاوه بر حساسیت, روش دیگری نیز وجود دارد که برای بهبود الگوریتم ScSPM کاربرد دارد. این روش با در نظر گرفتن خاصیت محلی بودن (locality) سعی در بهبود الگوریتم ScSPM دارد. Yu et al. (114) با توجه در نحوه کار الگوریتم مشاهده کرد که نتایج ScSPM به محلی بودن گرایش دارند یعنی ضرایب غیرصفر معمولا به پایه های نزدیک (nearby bases) اختصاص داده میشوند. به خاطر همین نتایج آنها پیشنهاد اعمال تغییری در ScSPM را دادند که از آن به Local Coordinate Coding یا به اختصار LCC یاد میشود. در این روش که بصورت صریح coding را ترغیب به محلی بودن میکند. آنها همینطور بصورت تئوری نشان دادند که محلی بودن (locality) قادر به ارتقاء و بهبود پراکندگی (sparsity) بوده و sparse coding برای یادگیری تنها در زمانی که codeها محلی باشند سودمند است . بنابر این بهتر است تا داده های مشابه ابعاد غیرصفر در code هایشان داشته باشند. هرچند LCC نسبت به sparse coding کلاسیک از لحاظ محاسباتی برتری دارد اما هنوز نیازمند حل مسئله بهینه سازی L1-norm که زمان گیر است میباشد. به منظور تسریع فرآیند یادگیری یک روش coding عملی بنام Locality Constrained Linear Coding یا به اختصار LLC توسط (۱۱۵) معرفی شد. که میتوان به آن بعنوان یک پیاده سازی سریع از LCC که regularization L1-norm با regularization L2-norm جایگزین شده است دید. شکل ۱۶ مقایسه بین VQ , ScSPM و LLC(115) را نشان میدهد .
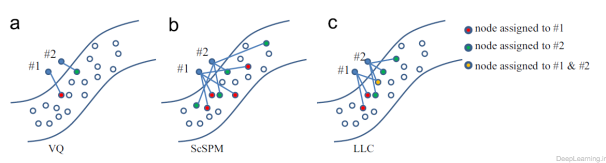
- مقایسه بین VQ , ScSPM و LLC[97]
علاوه بر LLC , مدل دیگری نیز وجود دارد که به super vector coding یا به اختصار SVC معروف بوده و sparse coding محلی را تضمین میکند (۱۲۴). با دریافت X , SVC آندسته از مختصاتی که به همسایگی x مربوط هستند را جهت دستیابی به نمایش پراکنده (sparse representation) فعال میکند. SVC یک بسط ساده از VQ است که با گسترش VQ درجهات مماس محلی بدست آمده و به همین دلیل روش coding یکدست تری است .
یک نتیجه جالب توجه که در (۱۲۵) نشان داده شده است, این است که در این مقاله روش averaging stochastic gradient descent (ASGD) با الگوریتم LLC و SVC به منظور افزایش مقیاس پذیری دسته بندی تصاویر در مجموعه داده های عظیم, ترکیب شده و توانست قبل از ظهور معماری های CNN در رقابت ImageNet و کسب بهترین نتایج, نتایج بسیار عالی در این رقابت را کسب کند.
یک روش معروف دیگر بنام Smooth Sparse Coding (SSC) وجود دارد که در (۱۲۶) ارائه شد. این روش با ترکیب شباهت همسایگی و اطلاعات موقتی (temporal information) در sparse coding توانست به کدهایی دست پیدا کند که بجای یک نمونه انفرادی یک همسایگی را نمایش داده و خطای مربع میانگین بازسازی کمتری داشته باشد.
اخیرا He et al.(127) چارجوب یادگیری ویژگی بدون سرپرست جدیدی بنام Deep Sparse Coding یا به اختصار DeepSC را ارائه کردند که Sparse Coding را با استفاده از یک معماری چند لایه بسط داده و توانسته بهترین کارایی را در میان روشهای sparse coding مطرح شده در قبل بدست آورد.
۱-۲-۱۰- بحث
برای مقایسه بین این ۴ دسته از روشهای یادگیری عمیق و بدست آوردن درک درستی از آنها, خلاصه ای از فواید و مشکلات هریک با توجه به خصائص متنوع آنها در جدول شماره ۴ آمده است .
در جدول زیر در کل ۹ خصیصه وجود دارد. که در آن Generalization یا تعمیم پذیری اشاره به این دارد که روش مورد نظر برای رسانه ها (تصویر, صدا و…) و کاربردهای متنوعی مثل تشخیص صدا (speech recognition) , تشخیص تصویر (visual recognition) و … موثر بوده است. یادگیری بدون سرپرست (Unsupervised learning) هم اشاره به توانایی یادگیری خودکار یک مدل عمیق (deep model) بدون تفسیر نظارتی است (without supervisory annotations). یادگیری ویژگی (feature learning) هم توانایی یادگیری خودکار ویژگی ها بر اساس یک مجموعه داده است . آموزش بلادرنگ (real-time training) و پیش بینی بلادرنگ (real-time prediction) هم به ترتیب اشاره به بهره وری(efficiency) یادگیری و فرآینده ای استنتاجی هستند. ادراک بیولوژیکی (Biological understanding) و توجیه نظری (Theoretical justification) هم نشانگر آن هستند که آیا روش مورد نظر دارای شالوده بیولوژیکی یا مبانی نظری است یا خیر.
Invariance یا تغییرناپذیری اشاره به این دارد که آیا روش مورد نظر در مقابل تبدیلاتی (transformations) همانند : چرخش, scale , و translation مقاوم است یا خیر. مجموعه آموزشی کوچک یا Small training set هم اشاره به توانایی یادگیری یک مدل عمیق با استفاده از تنها تعداد کمی نمونه است . این نکته حائز اهمیت است که جدول زیر تنها یافته های کلی فعلی را نمایش داده و صبحتی از فرصتهای آینده و یا نمونه های اختصاصی نمیکند.
| خصائص | CNN | RBM | AutoEncoder | Sparse coding |
| Generalization | بله | بله | بله | بله |
| Unsupervised learning | خیر | بله | بله | بله |
| Feature learning | بله | بله* | بله* | خیر |
| Real-time training | خیر | خیر | بله | بله |
| Real-time prediction | بله | بله | بله | بله |
| Biological understanding | خیر | خیر | خیر | بله |
| Theoretical justification | بله* | بله | بله | بله |
| Invariance | بله* | خیر | خیر | بله |
| Small training set | بله* | بله* | بله | بله |
- توجه: ‘بله’ اشاره به این دارد که دسته دراین خصوصیت بخوبی عمل میکند. در غیر اینصورت با خیر علامت گذاری میشود. ‘بله*’ اشاره به توانایی ابتدایی و یا ضعیف دارد
۱-۲-۱۱-کاربردها و نتایج آنها
یادگیری عمیق (یادگیری عمیق ) بصورت گسترده در زمینه های گوناگونی از بینایی کامپیوتر همانند دسته بندی تصاویر (image classification) , تشخیص اشیاء (object detection) , قطعه بندی معنایی(semantic segmentation) و بازیابی تصاویر(image retrieval) و برآورد ژست انسان (human pose estimation) که فعالیتهایی کلیدی برای درک تصویر اند مورد استفاده قرار گرفته است . در این بخش ما بصورت خلاصه به پیشرفت های یادگیری عمیق در این ۵ ناحیه اشاره میکنیم .
دسته بندی تصاویر (Image classification)
فعالیت دسته بندی تصاویر شامل برچسب گذاری تصاویر ورودی با یک احتمال از حضور دسته خاصی از اشیا بصری میشود. (یعنی آیا یک دسته خاص مثل سگ در یک تصویر وجود دارد یا خیر). این مسئله در شکل ۱۷ نشان داده شده است .

- نمونه ای از دست بندی تصاویر توسط AlexNet
قبل از یادگیری عمیق , شاید محبوب ترین وپراستفاده ترین روشها در زمینه دسته بندی تصاویر (image classification) روشهای مبتنی بر bags of visual words یا به اختصار BoW(128) بودند که ابتدا یک تصویر بصورت یک histogram از کلمات دیداری کوانتیزه[۱۸] شده(یعنی کلمات در قالب اعداد بیان شدند), و سپس بعنوان ورودی این histogram به یک دسته بندی کننده (معمولا یک SVM(129) ) تغذیه میشد. این معماری مبتنی بر آمار بدون ترتیب بود تا بتواند هندسه فضایی (spatial geometry) را در توصیف گرهای BoW ترکیب کند. Lazebnik et al. (117)روش spatial pyramid را با این روش ادغام کرد. که تعداد کلمات بصری درون یک مجموعه از زیر ناحیه های یک تصویر (image sub-regions) را بجای کل ناحیه شمارش میکرد .بعدا این معماری با import مسائل بهینه سازی sparse coding در ایجاد codebookها بیشتر بهبود پیدا کرد (۱۲۵) و توانست بهترین کارایی را در رقابت ImageNet در سال ۲۰۱۰ بدست آورد. Sparse coding یکی از الگوریتم های پایه یادگیری عمیق (یادگیری عمیق ) است و نسبت به الگوریتمهای دستی طراحی شده مثل HOG(130) و LBP (131) بیشتر متمایزکننده(more discriminative) است. روشهای مبتنی بر BoW تنها نگران آمار مرتبه ۰ [۱۹] بوده ( مثل تعداد کلمات بصری) و اطلاعات بسیار زیادی از تصویر را دور میریزند. روش ارائه شده توسط Perronnin et al.(132) بر این مشکل فائق آمده و آمار مرتبه بالاتری با استفاده از Fisher Kernel [135] استخراج کرد و اینطور توانست به نتایج بسیارعالی در رقابت دسته بندی تصاویر در سال ۲۰۱۱ دست یابد. در این فاز, محققان میل به تمرکز بر روی آمار مرتبه بالاتر دارند که هسته اصلی یادگیری عمیق است.Krizhevsky et al. (21) هم با استفاده از آموزش یک شبکه CNN بزرگ بر روی دیتابیس ImageNet (133) و کسب بهترین نتیجه در رقابت ImageNet سال ۲۰۱۲ توانست اثبات کند که شبکه های عصبی کانولوشن علاوه بر تشخیص ارقام دست نویس (۲۰) بخوبی میتوانند دردر حوزه دسته بندی تصاویر هم عمل کنند. این شبکه توانست با کسبtop-5 error rate 15.3%توانست به رتبه اول دست پیدا کرده و فعالیت چشمگیری در حوزه تحقیقات پیرامون شبکه های عصبی کانولوشن ایجاد کند. در شکل ۱۸ نتایج رقابت ImageNet از سال ۲۰۱۲ تابه حال نمایش داده شده است.
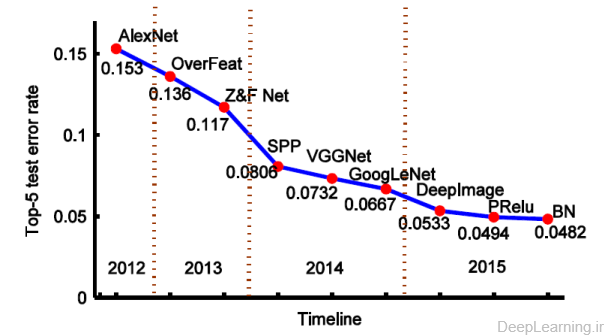
- نتایج رقابت ها
OverFeat (134) یک روش چندمقیاسه و پنجره لغزان (multiscale and sliding window) ارائه داد که قادر به یافتن مقیاس بهینه تصویر (optimal scale of the image) و انجام فعالیتهای گوناگون مثل دسته بندی , localization و کشف (detection) در آن واحد بود. این الگوریتم توانست نرخ خطای ۵تای اول (top-5 error rate) را به ۱۳٫۶% کاهش دهد . Zeiler et al. (54) هم تکنیک بصری سازی نوینی را معرفی کرد که باعث ارائه دیدی از کارکرد لایه های میانی شبکه میشد و بوسیله آن مدل جدیدی را تنظیم کرد که توانست AlexNet را شکست داده و به نرخ خطای ۵ تای اول ۱۱٫۷%رسیده و نفر اول رقابت ILSVRC در سال ۲۰۱۳ شود.
ILSVRC 2014 شاهد رشد سریع یادگیری عمیق بود چرا که بیشتر شرکت کنندگان از شبکه های عصبی کانولوشن بعنوان پایه مدلهای خود استفاده کرده بودند. این بار هم پیشرفت چشمگیری در دسته بندی تصاویر اتفاق افتاد و نرخ خطا تقریبا نسبت به ILSVRC2013 نصف شد. مدل SPP-net(46) محدودیت ثابت بودن اندازه تصویر ورودی را از میان برداشت که همین مسئله باعث افزایش دقت در انواع گوناگونی از معماری های شبکه عصبی کانولوشن بدون توجه به طراحی های متفاوت در آنها, شد. شبکه Multiple SPP-net نرخ خطای ۵ تای اول را به ۸٫۰۶% کاهش داده و به مقام سوم در رقابت دسته بندی ILSVRC2014 دست پیدا کرد. علاوه بر بهبودهای صورت گرفته در مدل CNN سنتی, ویژگی دیگری که در میان مدلهای اول (top-performing) مشترک بود, عمیقتر شدن معماری در آنها بود که در GoogLeNet(23) (مقام اول ILSVRC2014 ) وVGGNet(50) (مقام دوم رقابت ILSVRC2014 ) به ترتیب به ۶٫۶۷% و ۷٫۳۲% درصد نرخ خطا دست پیدا کردند کاملا مشهود است .
علیرغم ظرفیت بلقوه مدلهای بزرگ, آنها از مشکلات overfitting و underfitting در زمانهایی که داده آموزشی و یا زمان آموزش کم باشد رنج میبرند. به منظور جلوگیری از این کاستی ها, Wu et al. (44) استراتژی های جدیدی (یعنی تصاویر عمیق (deep image) ) را برای data augmentation و استفاده از تصاویر multi-scale توسعه داد . آنها یک ابررایانه عظیم برای شبکه های عصبی عمیق ساختند و یک الگوریتم موازی بسیار بهینه را توسعه دادند . نتایج دسته بندی تقریبا ۲۰% بهبود نسبت به نتایج قبلی با نرخ خطای ۵ تای اول ۵٫۳۳% را نشان میداد. اخیراHe et al.(135) واحد خطی تحصیح شده پارامتری (Parametric Rectified Linear Unit) را جهت ایجاد واحدهای فعالسازی تصحیح شده سنتی(traditional rectified activation units) ارائه داد و از آن یک روش مقداردهی اولیه (آماده سازی ) (initialization method) قدرتمند (robust) مشتق کرد. این طرح (روش) برای اولین بار سبب رسیدن به نرخ خطای ۵ تای اول ۴٫۹۴% شد و توانست کارایی انسانی (با ۵٫۱% خطا) را پشت سر بگذارد . نتایج مشابه توسط Ioffe et al.(4) بدست امد که در آن او با استفاده از مجموعه ای از شبکه های نرمال شده دسته ای (ensemble of batch normalized networks) توانست به نرخ خطای ۴٫۸% برسد.
تشخیص اشیاء (Object detection)
تشخیص اشیاء (Object detection) فعالیتی متفاوت اما بسیار مرتبط با فعالیت دسته بندی تصاویر است . برای دسته بندی تصاویر, کل تصویر بعنوان ورودی استفاده میشود و برچسب دسته اشیاء درون تصویر تخمین زده میشوند. برای تشخیص اشیاء (object detection) علاوه بر نمایش اطلاعات مربوط به حضور یک کلاس داده شده , همانطور که در شکل ۱۹ نشان داده شده است ما نیازمند این هستیم که مکان نمونه (یا نمونه های) مورد نظر در تصویر را نیز تخمین بزنیم. یک پنجره تشخیص (detection window) در صورتی صحیح در نظر گرفته میشود که محفظه خروجی دور نمونه(outputted bounding box) یافت شده اشتراک زیادی با شی هدف ما داشته باشد ( معمولا بیشتر از ۵۰% باشد)

- شناسایی اشیا توسط RCNN
دیتاست های چالش برانگیز PASCAL VOC , فراگیرترین دیتاست برای ارزیابی تشخیص اشیا (object detection) است. این دیتابیس شامل ۲۰ دسته یا کلاس است . در حین فاز آزمایش یک الگوریتم باید بتواند بدرستی محفظه های شناسایی اشیا (bounding boxes) مربوط به هر کلاس را پیش بینی کند.(یعنی با کشیدن یک مربع یا مستطیل بدور هر شکل موجود در تصویر بگوید هر تصویر به کدام دسته یا کلاس تعلق دارد.) در این بخش ما پیشرفت های اخیر در روش های deep learning برای تشخیص اشیاء را بر اساس دستاوردهای آنها در VOC 2007 و VOC 2012 شرح میدهیم. پیشرفت های مرتبط در جدول ۵ نمایش داده شده اند.
| روش | داده آموزشی | Voc2007 | Voc2012 | |||
| mAP(VGG-Net) | mAp(A/C-Net) | mAP(AlexNet) | mAP(VGG-Net) | |||
| DPM | ۰۷ | ۲۹٫۰۹% | – | – | – | |
| DerecrorNet | ۱۲ | ۳۰٫۱۴% | – | – | ||
| DeepMultiBox | ۱۲ | ۲۹٫۲۲% | – | – | – | |
| RCNN | ۰۷ | ۵۴٫۲% | ۶۲٫۲% | – | – | |
| RCNN+BB | ۰۷ | ۵۸٫۵% | ۶۶٫۰% | – | ||
| RCNN | ۱۲ | – | – | ۴۹٫۶% | ۵۹٫۲% | |
| RCNN+BB | ۱۲ | – | – | ۵۳٫۳% | ۶۲٫۴% | |
| SPP-NET | ۰۷ | ۵۵٫۲% | ۶۰٫۴% | |||
| SPP-NET | ۰۷+۱۲ | ۶۴٫۶% | ||||
| SPP-NET + BB | ۰۷ | ۵۹٫۲% | ۶۳٫۱% | |||
| FCRN | ۰۷ | – | ۶۶٫۹% | – | ۶۵٫۷% | |
| FCRN | ۰۷++۱۲ | – | ۷۰٫۰% | – | ۶۸٫۴% | |
| RPN | ۰۷ | ۵۹٫۹% | ۶۹٫۹% | |||
| RPN | ۱۲ | ۶۷% | ||||
| RPN | ۰۷+۱۲ | – | ۷۳٫۲% | |||
| RPN | ۰۷++۱۲ | – | ۷۰٫۴% | |||
| MR_CNN | ۰۷ | – | ۷۴٫۹% | – | ۶۹٫۱% | |
| MR_CNN | ۱۲ | – | – | – | ۷۰٫۷% | |
| FGS | ۰۷ | ۶۶٫۵% | – | |||
| FGS +BB | ۰۷ | ۶۸٫۵% | ۶۶٫۴% | |||
| NoC | ۰۷+۱۲ | ۶۲٫۹% | ۷۱٫۸% | ۶۷٫۶% | ||
| NoC+BB | ۰۷+۱۲ | ۷۳٫۳% | ۶۸٫۸% | |||
Note: Training data: “۰۷”: VOC07 trainval; “۱۲”: VOC2 trainval; “۰۷þ۱۲”: VOC07
trainval union with VOC12 trainval; “۰۷þþ۱۲”: VOC07 trainval and test union with
VOC12 trainval; BB: bounding box regression; A/C-Net: approaches based on
- AlexNet or Clarifai (54); VGG-Net: approaches based on VGG-Net(50)
سابقا,قبل از فرا رسیدن موج یادگیری عمیق , (DPM)(136) Deformable Part Model موثرترین روش برای تشخیص اشیاء بود. این روش از مدلهای deformable part بهره میبرد و اشیاء را در تمامی مقیاس ها و مکانهای تصویر به شیوه ای جامع تشخیص میداد. بعد از ادغام یکسری روش post-processing مثل bounding box prediction و context rescoring , این مدل توانست به میانگین دقت ۲۹٫۰۹% در مجموعه آزمایش VOC 2007 دست پیدا کند. از آنجایی که روش های یادگیری عمیق (خصوصا روش های مبتنی بر شبکه عصبی کانولوشن) توانسته بودند به کارایی های سطح بالایی در فعالیتهای دسته بندی تصاویر دست پیدا کنند, محققان شروع به استفاده از آنها در حوزه تشخیص اشیاء کردند.
یک روش یادگیری عمیق ابتدایی برای تشخیص اشیا توسط Szegedy et al.(137) ارائه شد. در این مقاله الگوریتمی بنام DetectorNet معرفی شد که آخرین لایه AlexNet(21) را با یک لایه رگراسیون (regression layer) جایگزین میکرد. این الگوریتم توانست مکان اشیاء را بخوبی بدست آورده و به نتایج قابل رقابت با پیشرفته ترین الگوریتم های آن زمان در VOC2007دست پیدا کند. به منظور پشتیبانی از چندین نمونه از یک شی در تصویر , DeepMultiBox(138) نیز یک مدل شبکه عصبی (saliency-inspired neural network) را به نمایش گذاشت.
یک طرح کلی برای سیستم های تشخیص اشیاء موفق فعلی ایجاد منبع بزرگی(large pool) از محفظه های کاندید(candicate boxes) و دسته بندی آنها با استفاده از ویژگی های CNN است . بهترین نمونه این روش, طرح RCNN است که توسط Girshick et al. (31). ارائه شد. این طرح از جستجوی انتخابی (Selective search) (139)برای ایجاد پیشنهاد اشیاء استفاده میکرد و ویژگی ها شبکه عصبی کانولوشن را برای هر پیشنهاد استخراج میکرد. این ویژگی ها سپس به یک دسته بندی کننده (کلاسیفایر) SVM تغذیه شده تا مشخص شود پنجره های کاندید مربوطه شامل شی مورد نظر هستند یا خیر.RCNN ها Benchmark را تا حد بسیار زیادی بهبود دادند و به مدل پایه برای بسیاری از الگوریتم های نویدبخش دراین زمینه تبدیل شدند. (۲۱, ۵۵, ۵۶, ۵۸, ۶۰).
الگوریتم های مشتق شده از RCNN ها بطور کلی به دو دسته تقسیم میشوند. دسته اول بدنبال تسریع فرآیند آموزش و آزمایش است . هرچند RCNN دقت بسیار عالی در تشخیص اشیاء دارد اما بواسطه اینکه بطور جداگانه هر پیشنهاد شی ای را انتخاب و بعد پردازش میکند از لحاظ پردازشی بسیار سنگین است . در نتیجه بعضی از الگوریتم های معروف که بدنبال بهینگی این مدل بودند پدیدار شدند. الگوریتمهای SPP-net(46) FRCN(55), RPN(56), YOLO(140) , و … از این دسته اند. دسته دوم عمدتا بدنبال بهبود دقت RCNN ها هستند. کارایی طرح “recognition using regions” یا تشخیص از طریق ناحیه ها بشدت به کیفیت فرضیه شی وابسته است . در حال حاضر, الگوریتم های پیشنهاد شی زیادی وجود دارد که objectness(141) ,selective search(139) , object proposals (142) category-independent , BING (143) و edge boxes(144) et al نمونه هایی از این دست هستند.
این طرح ها و روشها بصورت جامع در (۱۴۵) مورد ارزیابی قرار گرفتند. اگرچه این روش ها در پیدا کردن مکانهای تقریبی اشیاء خوب هستند اما معمولا قادر به مکان یابی دقیق تمام شی از طریق یک محفظه تنگ (tight bounding box) نیستند. که همین مسئله باعث ایجاد بزرگترین منبع خطای تشخیص در آنها شده است. (۱۴۶, ۱۴۷) بنابر این برای حل این مشکل روشهای زیادی بوجود آمدند تا به تصحیح این مکان یابی ضعیف بپردازند.
یک جهت مهم در این روش ها ترکیب آنها با روش های قطعه بندی معنایی (semantic segmentation) است .(۵۸, ۶۰, ۱۴۸) بعنوان مثال روش SDS پیشنهاد شده توسط Hariharan et al.(60) از قطعه بندی (segmentaion) برای حذف (mask-out) پس زمینه در یک عملیات تشخیص استفاده میکند که این کار باعث بهبود کارایی در تشخیص اشیا ( از ۴۹٫۶% به ۵۰٫۷% بدون رگراسیون محفظه تشخیص (bounding box regression)) شد. از طرف دیگر روش UDS(148) تشخیص اشیاء و فرایند قطعه بندی معنایی را در یک چارجوب با اجبار ثبات آنها و ادغام اطلاعات متنی ,باهم ترکیب کرد. این مدل کارایی خوبی در هر دو فعالیت از خود نشان داد. کارهای مشابه مثل segDeepM که توسط Zhu et al.(58) ارائه شد و MR_CNN در(۵۷) هم که از قطعه بندی به همراه مدارک اضافی برای افزایش دقت در تشخیص اشیاء استفاده کردند نیز وجود دارند. روشهای دیگری هم وجود دارند که سعی میکنند بصورت های دیگری به مکان یابی دقیقی دست پیدا کنند .بعنوان مثال FGS(59) از طریق ۲ روش به حل این مشکل پرداخته است . ابتدا یک الگوریتم سرچ بهینه (fine-grained) برای بهینه سازی تکراری مکان توسعه داد و سپس یک دسته بندی کننده (کلاسیفایر) شبکه عصبی کانولوشن را به همراه یک هدف SVM ساخت یافته (structured SVM objective) برای بالانس کردن بین دسته بندی و مکان یابی آموزش داد. ترکیب این روشها کارایی امیدوارکننده ای در دیتاست های چالش برانگیز از خود نشان داده است.
گذشته از تلاشهای صورت گرفته در مکان یابی اشیاء , چارجوب NoC در (۱۴۹) تلاش میکند تا تلاشها را بسمت دسته بندی اشیاء تکامل دهد. بجای شبکه پرسپترون چند لایه این مقاله ساختارهای NoC مختلفی را جهت پیاده سازی دسته بندی کننده اشیاء امتحان کرده است.
جمع آوری مقدار زیادی از برچسب های سطح تصویر نسبت به جمع آوری داده تشخیص و بعد برچسب گذاری آن با استفاده از محفظه های شناسایی (bounding box) دقیق بسیار ارزانتر و ساده تر است . بنابر این یک چالش اصلی در مقیاس پذیری (scaling) تشخیص اشیا, دشواری بدست آوردن تصاویر برچسب گذاری شده برای تعداد زیادی دسته است .(۱۵۰, ۱۵۱) . Hoffman et al.(151) الگوریتم Deep Detection Adaption (DDA) را برای یادگیری تفاوت بین دسته بندی تصاویر و تشخیص اشیاء, با تبدیل دسته بندی کننده های(کلاسیفایرها) دسته ها به detector ها بدون داده های حاشیه نویسی شده با محفظه شناسایی (bounding box annotated data) ارائه داد. این روش پتانسیل تشخیص هزاران دسته که فاقد تفسیر های (حاشیه نویسی)محفظه شناسایی هستند را دارد.
دو روش نوید بخش و مقیاس پذیر (۱۵۲)ConceptLeaner و BabyLearning(153) هستند. هردو اینها قادر به یادگیری دقیق مفهوم یابها (concept detectors) بدون حاشیه نویشی فراوان مفاهیم بصری هستند. از آنجایی که جمع آوری تصاویر برچسب گذاری شده ضعیف ارزان است, ConceptLeaner یک الگوریتم max-margin hard instance learning را جهت کشف مفاهیم بصری از مجموعه تصاویر برچسب گذاری شده نویزدار توسعه داد. در نتیجه, این روش پنانسیل یادگیری مفاهیم از وب را بصورت مستقیم دارد. از طرف دیگر روش Baby- Learning(153) تعامل یک نوزاد با دنیای فیزیکی را شبیه سازی کرده و میتواند نتایج قابل مقایسه ای را با روش های مبتنی بر آموزش کامل به همراه تعداد کمی نمونه برای هر دسته از اشیاء و تعداد زیادی ویدئو بدون برچسب آنلاین بدست آورد. در جدول شماره ۴ علاوه بر خود الگوریتم , چندین فاکتور که میتوانند باعث بهبود کارایی شوند نشان داده شده است ( ۱)مجموعه آموزشی بزرگ ۲)مدل پایه عمیقتر ۳) رگراسیون محفظه شناسایی )
بازیابی تصاویر (Image retrieval)
بازیابی تصاویر بدنبال یافتن تصاویری است که شامل یک شی یا صحنه مشابه با تصویر مورد جستجو, همانند آنچه در شکل ۲۰ نمایش داده شده است, باشند. موفقیت AlexNet(21) اینرا به ذهن متبادر کرد که ویژگی های نمایان شده در لایه های بالایی یک شبکه عصبی کانولوشن که برای دسته بندی تصاویر آموزش دیده است, را میتوان به عنوان توصیفگر خوبی برای دسته بندی تصاویر مورد استفاده قرار داد. مطالعات بسیار زیادی با همین انگیزه, از شبکه های عصبی کانولوشن برای فعالیت های بازیابی تصاویر استفاده کردند. [review] این مطالعات به نتایج قابل رقابت در قیاس با روش های سنتی همانند VLAD و Fisher Vector دست پیدا کردند. در پاراگراف بعدی ما ایده اصلی موجود در این روشهای مبتنی بر شبکه عصبی کانولوشن را معرفی میکنیم .

Gong et al.(154) با الهام از Spatial Pyramid Matching ایده نوعی reverse SPM را ارائه کرد که patch ها را در مقیاس های چندگانه با شروع از کل تصویر و سپس با ادغام (pool) هر مقیاس بدون توجه به اطلاعات مکانی آن ,استخراج میکرد. سپس پاسخهای patch محلی را با استفاده از encoding VLAD در مقیاس بهتری تجمیع میکرد. طبیعت بدون ترتیب VLAD به ایجاد نمود بدون تغییر بهتری کمک میکرد.سپس مقادیر عمیق سراسری اصلی با ویژگی های VLAD برای رسیدن به مقیاس های بهتر متصل شده تا تشکیل یک نمایش جدید از تصویر را بدهد.
Razavian et al.(155) [165] از ویژگی های استخراج شده از شبکه OverFeat بعنوان یک نمود تصویری کلی برای استفاده در فعالیت های مختلف مربوط به حوزه بینایی کامپیوتر استفاده کرد. او ابتدا مجموعه آموزشی را با استفاده از نمونه های چرخانده شده و crop شده تغییر داد . سپس برای هر تصویر چندیدن Subpatch با اندازه های مختلف از مکان های مختلف استخراج کرد. هر sub-patch برای نمود CNN خود محاسبه میشود. فاصله بین تصویر اصلی و تصویر جستجو شده برابر میانگین فاصله هر subpatch از تصویر اصلی قرار داده میشود. با توجه به موفقیت های اخیر که روش های یادگیری عمیق بدست آورده اند, تحقیق انجام شده در (۵۱)بدنبال ارزیابی این است که آیا یادگیری عمیق میتواند فاصله معنایی در بازیابی تصاویر مبتنی بر محتوا (content-based image retrieval (CBIR))را پر کند یا خیر. نتایج نوید بخش آنها نشان میدهد که مدلهای شبکه عصبی کانولوشن از پیش آموزش دیده بر روی دیتاست های عظیم را میتوان بصورت مستقیم برای استخراج ویژگی در فعالیت های CBIR جدید مورد استفاده قرار داد.
اگر از این روش به منظور feature representation در زمینه جدیدی استفاده شود, مشخص شده است که similarity learning باعث بهبود کارایی بازیابی میشود. در ادامه با حفظ مدلهای عمیق با یک هدف similarity learning و یا دسته بندی در زمینه جدید میتوان بطور قابل ملاحظه ای دقت را نیز بهبود داد. روش متفاوت دیگری در (۱۵۶) ارائه شده است که در آن,ابتدا patchهای تصویری شی مانند با استفاده از یک شی یاب کلی (general object detector) استخراج شده و سپس یک ویژگی CNN از هر object patch با مدل از پیش آموزش دیده AlexNet استخراج میشود.با آزمایشات فراوانی که محققان در این تحقیق خود انجام دادند نهایتا به این نتیجه رسیدند که روش آنها قادر به کسب بهبود قابل توجهی در دقت با همان میزان هزینه فضایی(space consumption) و هزینه زمانی میباشد.
در آخر بدون استفاده از sliding windows و یا multiple-scale patches Babenko et al.(157) بر روی توصیفگرهای جامعی که تمام تصویر را با استفاده از یک مدل CNN به یک بردارنگاشت میکرد تمرکز کرد. مشخص شد که بهترین کارایی نه در لایه بالایی شبکه بلکه در لایه ای که دو سطح پایین تر از خروجی بود مشاهده شده است. نتیجه مهمی که در اینجا وجود دارد این است که تاثیر سوء PCA بر روی کارایی CNN کمتراز VLAD و یا Fisher Vector ها است . بنابر این کم حجم سازی PCA (PCA compressing) برای ویژگی های CNN بهتر عمل میکند. در جدول ۶ نتایج بازیابی تصاویر در چند دیتاست عمومی نشان داده شده است.
| روشها | Holidays | Paris6K | Oxford5K | UKB |
| Babenko et al | ۷۴٫۷ | – | ۵۵٫۷ | ۳٫۴۳ |
| Sun et al | ۷۹٫۰ | – | – | ۳٫۶۱ |
| Gong et al | ۸۰٫۲ | – | – | – |
| Razavian et al | ۸۴٫۳ | ۷۹٫۵۰ | ۶۸٫۰ | –(۹۱٫۱) |
| Wan et al | – | ۹۴٫۷ | ۷۸٫۳ | – |
- نتایج
مشکل جالب دیگری که در ویژگی های CNN وجود دارد این است که کدام لایه بیشترین اثر را در کارایی نهایی دارد؟ بعضی از روشها ویژگی ها را در لایه تماما متصل دوم استخراج میکنند (۱۵۴, ۱۵۶)
در حالی که بعضی دیگر از روش ها , از لایه تماما متصل اول در مدل CNN خود برای image representation بهره میبرند. (۱۵۵, ۱۵۷) علاوه بر اینها, این انتخابها ممکن است برای دیتاست های مختلف هم تغییر کند(۵۱)بنابر این ما فکر میکنیم تحقیقات بیشتر در زمینه ویژگی های هر لایه هنوز یک مسئله حل نشده (open problem)باقی مانده است .
Semantic Segmentation
طی نیم سال اخیر تعداد زیادی از تحقیقات حول فعالیت قطعه بندی معنایی (semantic segmentation) متمرکز شده اند و نتایج آنها نوید دهنده پیشرفتهای قابل ملاحظه ای هستند.[review] دلیل اصلی موفقیت آنها, استفاده از مدلهای CNN ناشی میشود که قادر به مقابله با تخمین های سطح پیکسلی با استفاده از شبکه های از پیش آموزش دیده بر روی دیتاست های با مقیاس بزرگ هستند.Semantic segmentation با دسته بندی در سطح تصویر (image-level classification) و تشخیص سطح شی (object –level detection) متفاوت بوده و نیازمند mask های خروجی است که دارای توزیع مکانی دو بعدی باشند .
برای semantic segentation , پیشرفتهای اخیر در روش های مبتنی بر CNN را میتوان بصورت زیر خلاصه کرد :
- Detection-based segmentation.
- FCN-CRFs based segmentation.
- Weakly supervised annotations.
Detection-based segmentation
این روش تصاویر را بر اساس پنجره های کاندید خروجی حاصله از فاز تشخیص شی قطعه بندی میکند. [review]
RCNN (31) و SDS(60) ابتدا پیشنهادهایی برای هر ناحیه (region proposals) را برای تشخیص شی تولید کرده و سپس از روش های اضافی برای قطعه بندی ناحیه و انتساب پیکسلها به برچسب کلاس از فاز تشخیص استفاده میکردند. Hariharan et al.(158) روشی را بر مبنای SDS(60) ارائه کرد که در آن hypercolumn در هر پیکسل را بعنوان برداری از فعالسازی ها در نظر گرفت و به این وسیله به بهبود عظیمی دست پیدا کرد. یک مشکل قطعه بندی بر اساس تشخیص, هزینه اضافی زیاد بابت تشخیص اشیاء است. Dai et al.(159) بدون استخراج نواحی از تصاویر خام ,یک روش convolutional feature masking (CFM) را به منظور استخراج پیشنهادها بصورت مستقیم از feature mapها طراحی کرد .از آنجایی که feature map های کانولوشنی تنها یکبار نیازمند محاسبه شدن هستند, روش بهینه و کارامدی است هرچند که خطاهای ایجاد شده توسط پیشنهادها و ]فاز[ تشخیص شی معمولا در مرحله قطعه بندی پخش میشوند.
FCN-CRFs based segmentation.
دراین روش که استراتژی محبوبی شده و پایه ای برای انجام semantic segmentation شده است با جایگزینی لایه های تماما متصل با لایه های کانولوشنی بیشتر, به قطعه بندی معنایی پرداخته میشود. (۴۸, ۱۶۰) . Long et al. (48) معماری نوینی را تعریف کرد که در آن اطلاعات معنایی از یک لایه جامع عمیق به همراه اطلاعات ظاهری از یک لایه کم عمق مناسب برای تولید قطعه بندی های دقیق و با جزییات استفاده کرد. DeepLab (۱۶۰)مدل FCN مشابه ای را ارئه کرد که علاوه بر موارد فوق, از نیروی conditional random fields (CRFs) نیز در FCN برای بازیابی دقیق مرزها استفاده کرد . , Lin et al. (161) به جای استفاده از CRF ها بجای یک مرحله post-processing بطور مشترک FCN و CRF را بوسیله آموزش قطعه به قطعه , آموزش داد. به همین شکل (۱۶۲)نیز CRF ها را به صورت یک recurrent neural network(RNN) تدبل کرد که میشد آنرا به عنوان بخشی از یک مدل FCN اضافه کرد.
Weakly supervised annotations.
علاوه بر پیشرفت هایی صورت گرفته در مدلهای قطعه بندی, بعضی کارها بر روی قطعه بندی با سرپرست ضعیف (weakly supervised segmentation) تمرکز کرده اند. Papandreou et al.(163) قطعه بندی چالش برانگیزتری را با داده آموزشی بطور ضعیف حاشیه نویسی شده (weakly annotated training data) مثل محفظه های شناسایی (bounding boxes) و یا برچسب های سطح تصویر ( image-level labels) مورد مطالعه قرار داد.به همین شکل روش BoxSup(164) از حاشیه نویسی های محفظه شناسایی (bounding box annotations) جهت تخمین ماسکهای قطعه بندی (segmentation masks) که برای بروز آوری شبکه بصورت تکراری مورد استفاده قرار میگرفتند, بهره برد. این کارها نشان داند که کارایی عالی در زمان ترکیب تعداد کمی از تصاویر حاشیه نویسی شده در سطح پیکسل با تعداد زیادی از تصاویر حاشیه نویسی شده با محفظه شناسایی بدست می آید.
خصوصیات اصلی روش های بالا و مقایسه بین نتایج آنها در PASCAL VOC 2012 درجدول ۷ نمایش داده شده است .
| روشها | آموزش | Val2012 | Test2012 | توضیحات |
| SDS | VOC extra | ۵۳٫۹ | ۵۱٫۶ | Region proposals on input images |
| CFM | VOC extra | ۶۰٫۹ | ۶۱٫۸ | Region proposals on feature maps |
| FCN-8s | VOC extra | – | ۶۲٫۲ | One model; three strides |
| Hypercolumn | VOC extra | ۵۹٫۰ | ۶۲٫۶ | Region proposals on input images |
| DeepLab | VOC extra | ۶۳٫۷ | ۶۶٫۴ | One model; one stride |
| DeepLab-MSc-LargeFOV | VOC extra | ۶۸٫۸ | ۷۱٫۶ | Multi-scale; Field of view |
| Piecewise-DCRFs | VOC extra | ۷۰٫۳ | ۷۰٫۷ | ۳ scales of image; 5 models |
| CRF-RNN | VOC extra | ۶۹٫۶ | ۷۲٫۰ | Recurrent Neural Networks |
| BoxSup | VOC extraþCOCO | ۶۸٫۲ | ۷۱٫۰ | Weakly supervised annotations |
| Cross-Joint | VOC extraþCOCO | ۷۱٫۷ | ۷۳٫۹ | Weakly supervised annotations |
برآورد ژست انسانی (Human pose estimation)
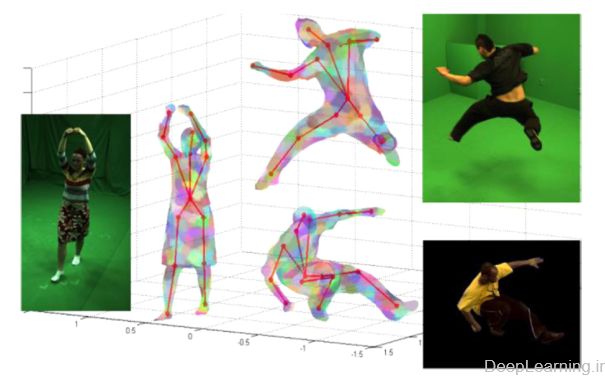
Human pose estimation همانطور که در شکل ۲۱ نشان داده شده است ,بدنبال تقریب محل مفاصل انسان در تصاویر و یا دنباله ای از تصاویر است. تقریب این مسئله برای بازه گسترده ای از کاربردها بسیار حائز اهمیت است . بعنوان مثال میتوان به نظارت ویدئویی (video surveilance), تحلیل رفتار انسان, تعامل انسان و رایانه (human-computer interation (HCI)), بعنوان نمونه هایی از این دست اشاره کرد. این مسئله اخیرا بشدت مورد مطالعه قرار گرفته است [review] . اما این فعالیت بواسطه تغییرات بسیار زیاد در ظاهر افراد , پس زمینه های پیچیده و همینطور عوامل مخل دیگر مثل , نور (illumination), زاویه دید, مقیاس (scale) و … کار بسیار چالش برانگیزی است . در این بخش ما بطور عمده روش های یادگیری عمیق را برای تقریب مفصلبندی انسان از طریق تصاویر ثابت بطور خلاصه مورد بحث قرار میدهیم هرچند این طرح ها را میتوان با ویژگی های حرکتی به منظور بهبوبد کارایی آنها در ویدئوها نیز مورد استفاده قرار داد. (۱۶۵-۱۶۷).
بطور معمول, تقریب ژست انسان, شامل چندین مشکل مثل تشخیص افراد در تصاویر, کشف و توصیف بخش های مختلف بدن انسان و مدل سازی پیکربندی مکانی آنها میشود. قبل از یادگیری عمیق بهترین روشهای تقریب ژست انسان, مبتنی بر کشف کننده های اعضای بدن بودند. یعنی ابتدا اعضای بدن انسان را کشف و بعد توصیف کرده و سپس روابط متنی(contextual) بین اعضای محلی را اعمال میکردند. . یک نمونه از این روش ها , ساختارهای مصور یا pictorial structures(168) است که از مدل درختی برای دریافت (capture) روابط هندسی بین بخشهای متصل بهم بهره برده و توسط روش های مبتنی بر بخش معروف مختلفی توسعه داده شده است . (۱۶۹-۱۷۲).
از آنجایی که الگوریتم های یادگیری عمیق قادر به فراگیری ویژگی های سطح بالا اند و به همین دلیل در مقابل تغییرات المان های مخل محیطی مقاوم بوده و همچنین به موفقیت های زیادی در حوزه های مختلف بینایی کامپیوتر دست پیدا کرده اند, اخیر بشدت مورد توجه محققان برای استفاده در این حوزه قرار گرفته اند.
ما کارایی مربوط به الگوریتم های یادگیری عمیق را در دو دیتاست معروف Frames Labeled In Cinema (FLIC) (173) و Leeds Sports Pose (LSP)(174) بصورت خلاصه قرار دادیم . FLIC شامل ۳۹۸۷ تصویر آموزشی و ۱۰۱۶ تصویر جهت آزمایش است که از فیلم های محبوب هالیوودی که شامل افراد مختلف در حالات متنوع بوده بدست آمده است.این تصاویر با برچسب هایی برای بخش بالایی بدن حاشیه نویسی شده اند. LSP و extension آن شامل ۱۱۰۰۰ تصویر آموزشی و ۱۰۰۰ تصویر جهت آزمایش از ورزشکاران که از سایت Flickr به همراه حاشیه نویسی ۱۴ مفصل بدن بوده میباشد. دو ملاک ارزیابی که بصورت گسترده مورد قبول واقع شده است درصد اعضای درست یا Percentage of Correct Parts (PCP)(175) و درصد مفصل های تشخیص داده شده یا Percent of Detected Joins(PDJ) (173) میباشد که ملاک اول نرخ تشخیص صحیح اعضای بدن را اندازه گرفته و ملاک دوم نرخ مفاصل تشخیص داده شده را مشخص میکند. در زیر, جدول شماره ۸ مقایسه ای بین روش های گوناگون یادگیری عمیق بر روی دیتاست FLIC با فاصله نرمال شده ۰٫۰۵ را نشان میدهدو جدول ۹ مقایسه PCP بر روی دیتاست LSP را نشان میدهد.
| PDJ(PCK) | سر | سرشانه | آرنج | مچ |
| Jain et al | – | ۴۲٫۶ | ۲۴٫۱ | ۲۲٫۳ |
| DeepPose | – | – | ۲۵٫۲ | ۲۶٫۴ |
| Chen et al | – | – | ۳۶٫۵ | ۴۱٫۲ |
| DS-CNN | – | – | ۳۰٫۵ | ۳۶٫۵ |
| Tompson et al | ۹۰٫۷ | ۷۰٫۴ | ۵۰٫۲ | ۵۵٫۴ |
| Tompson et al | ۹۲٫۶ | ۷۳ | ۵۷٫۱ | ۶۰٫۴ |
| Torso | سر | بازوها-بالا | بازوها پایین | پاها بالا | پاها پایین | میانگین | |
| Quyang et al | ۸۵٫۸ | ۸۳٫۱ | ۶۳٫۳ | ۴۶٫۶ | ۷۶٫۵ | ۷۲٫۲ | ۶۸٫۶ |
| DeepPose | – | – | ۵۶ | ۳۸ | ۷۷ | ۷۱ | – |
| Chen et al | ۹۲٫۷ | ۸۷٫۸ | ۶۹٫۲ | ۵۵٫۴ | ۸۲٫۹ | ۷۷ | ۷۵ |
| DS-CNN | ۹۸ | ۸۵ | ۸۰ | ۶۳ | ۹۰ | ۸۸ | ۸۴ |
درکل, روشهای یادگیری عمیق در تقریب ژست انسان, را میتوان بر اساس نحوه مدیریت تصاویر ورودی به پردازش جامع و یا پردازش مبتنی بر بخش دسته بندی کرد.
روش های پردازش جامع میل به تکمیل وظایفشان در یک قالب سراسری دارند. و مدلی را بصورت صریح برای هر بخش مجزا و روابط مکانی آنها مشخص نمیکنند. یک نمونه از این مدل , DeepPose است که توسط Toshev et al.(176) ارائه شده است. این مدل روش تقریب ژست انسان را بصورت مشکل رگراسیون مشترک فرموله کرده و بصورت صریح مدل گرافیکی و یا بخش یابی را برای تقریب ژست انسانی مشخص نمیکند.
بطور خاص, این مدل از معماری دو لایه ای بهره میبرد که در آن لایه اول به رفع ابهام بین بخش های بدن بصورت جامع پرداخته و تقریب ژست اولیه را ایجاد میکند. لایه دوم هم نقاط مفاصل را برای تقریب بهبود میدهد. این مدل به پیشرفتهایی در چندین دیتاست چالش برانگیز دست یافته است. اما روشهای مبتنی بر جامع بودن(holistic based methods) از بی دقتی در نواحی با دقت بالا رنج میبرند چرا که یادگیری رگراسیون بردارهای ژست پیچیده مستقیم از تصاویر دشوار است .
روش های پردازشی مبتنی بر بخش (part based methods) پیشنهاد میکنند تا بخشهای بدن بصورت انفرادی یافت شده و سپس توسط یک مدل گرافیکی با اطلاعات مکانی ترکیب شود. , Chen et al.(177) بجای آموزش شبکه با استفاده از کل تصویر, از part patch های محلی و background patch ها برای آموزش DCNN استفاده کرد تا احتمالات شرطی حضور یک بخش و ارتباطات مکانی آنرا فراگیرد.
با ترکیب با مدلهای گرافیکی , این الگوریتم توانست کارایی خوبی بدست بیاورد. علاوه بر آن , Jain et al. (178)چندین شبکه عصبی کانولوشن کوچک را به منظور انجام دسته بندی اعضای بدن دودویی مستقل آموزش داد و بعد از آن از مدل مکانی ضعیف سطح بالاتر (higher level weak spatial model) برای حذف خطوط قوی و اعمال یکدستی ژست سراسری استفاده کرد. به همین شکل Tompson et al.(179) معماری های ConvNet چندن رزولوشنه طراحی کرد تا heat-map رگراسیون احتمال برای هر بخش از بدن را بدست اورد که بعد از ان مدل گرافیکی ضمنی برای سازگاری بیشتر مفصل استفاده شود.
این مدل بعدها در (۱۸۰)بیشتر بسط داده شد و در آن عنوان شد که لایه های pooling در شبکه های عصبی کانولوشن باعث محدود شدن دقت مکان یابی مکانی شده و به همین علت برای بازیابی افت دقت رخ داده در فرایند pooling تلاش کردند. آنها بطور ویژه روش آمده در (۱۷۹) را با اضافه کردن یک لایه Dropout مکانی بادقت طراحی شده و ارائه یک شبکه نوین که از ویژگی های کانولوشنی لایه پنهان جهت بهبود دقت locality مکانی(spatial locality) دوباره استفاده میکرد بهبود دادند.
روشهایی نیز وجود دارند که پیشنهاد میکنند به منظور دستیابی به تقریب ژست انسان دقیقتر هم ظاهر بخش محلی و هم دید جامع بخشها با هم ترکیب شوند. بعنوان مثال Ouyang et al.(181) از Deep Belief Network(DBN) یک مدل عمیق چند منبعی را مشتق کرد که تلاش میکرد تا از سه منبع اطلاعات مفاصل انسانی. یعنی ترکیب نوع, امتیاز ظاهری و تغیرشکل بهره برده و با ترکیب نمایه های سطح بالای آنها الگوهای مفصلی مرتبه بالا انسان را فرابگیرد. از طرف دیگر, Fan et al.(182) یک شبکه عصبی کانولوشنی دو منبعی (DS-CNN) را ارائه کرد تا دید جامع و جزئی را در شبکه عصبی کانولوشن ادغام کند.این شبکه part patch ها و body patch ها را بعنوان ورودی دریافت کرده تا اطلاعات متنی و محلی را برای تقریب ژست دقیقتر با هم ترکیب کند.
از آنجایی که بیشتر روشها تمایل به طراحی معماری های feed-forward جدید دارند, Carreira et al. [211] (183)یک مدل خود تصحیح کن (self-correctng) بنام Iterative Error Feedback(IEF) را ارائه کرد که قادر به دربرگرفتن ساختار غنی در هر دو فضای ورودی و خرجی با استفاده از feedback بالا به پایین میباشد. این مدل نتایج امیدوارکننده ای از خود به نمایش گذاشته است.
۱-۲-۱۲-گرایشات و چالشها (Trends and challenges)
درک تئوریک (Theoretical understanding)
هرچند نتایج بسیار خوبی با استفاده از روش های یادگیری عمیق در حوزه بینایی کامپیوتر بدست آمده است اما هنوز تئوری زیرینی که باعث این نتایج خوب میشود نامشخص باقی مانده است . و هنوز درک درستی از اینکه چه معماری ای بهتر از دیگری کارمیکند وجود ندارد. تصمیم گیری در باره اینکه چه ساختاری , و یا چه تعداد لایه و یا چه تعداد واحدپردازشی در هر لایه مناسب یک کار و فعالیت خاص است بسیار دشوار است. همینطور این روشها نیازمند دانش خاصی برای انتخاب مقادیر معقولی (sensible values) مثل learning rate , قدرت regularizer و … هستند. طراحی معماری ها تا بحال مبتنی بر روش الله بختکی و ad-hoc بوده است . البته Chu et al.(184) یک روش تئوریک برای مشخص کردن تعداد feature map های بهینه ارائه کرده است اما این روش تئوریک تنها برای receptive fieldهای بشدت کوچک کاربرد دارد. به منظور درک بهتر معماری های شبکه عصبی کانولوشن Zeiler et al. (54) هم یک روش بصری سازی (visualization techniqe) معروف برای معماری های شبکه عصبی کانولوشن ارائه کرد که باعث ارائه دیدی از آنچه در حال اتفاق افتادن در درون یک شبکه عصبی کانولوشن بود شد. این روش با مشخص کردن الگوهای قابل تفسیر توانست امکاناتی جهت بهتر سازی طراحی معماری فراهم سازد. تکنیک مشابه ای توسط Yu et al.(185). هم ارائه شد. گذشته از بصری سازی ویژگی ها (نمایش ویژگی ها) , RCNN(31) تلاش کرد تا الگوی یادگیری CNN را کشف کند. محققان در این روش کارایی را لایه با لایه در حین فرآیند آموزش مورد آزمایش قرار داند و فهمیدند که لایه های کانولوشن بیشتر ویژگی های کلی را یادگرفته و بیشترین ظرفیت نمایشی شبکه عصبی را دارند در حالیکه لایه های تماما متصل خاص دامنه هستند (domain specific). علاوه بر تحلیل ویژگی های شبکه عصبی کانولوشن , Agrawal et al.(186) تاثیرات استفاده از استراتژی های معروف بر روی کارایی شبکه عصبی کانولوشن مثل fine-tuning و pre-training را مورد بررسی بیشتر قرار داد . و درکهای عینی بر مبنای مدارکی را جهت استفاده مدلها در مسائل مربوط به computer vison ارائه کرد.
علی رغم پیشرفت بدست امده در تئوری یادگیری عمیق , هنوز جای زیادی برای درک بهتر و بهینه سازی معماری های شبکه عصبی برای بهبود خصائص دلخواهی مثل invariance و تشخیص کلاس (class discrimination) وجود دارد.
Human-level vision
دید انسانی کارایی قابل توجهی در کاربردها و فعالیت های حوزه بینایی کامپیوتر دارد. چه در نمایش های بصری ساده و یا تحت تغییرات هندسی , تغییرات پس زمینه و مسدود سازی.دید در سطح انسان (human level vison) میتواند یا به پرکردن خلا معنا در قالب دقت و یا ارائه دیدهای جدید از مطالعات مغز انسان برای ادغام در معماری های یادگیری ماشین اشاره کند. در مقایسه با ویژگی های سطح پایین سنتی, یک شبکه عصبی کانولوشن از ساختار مغز انسان تقلید کرده و فعال سازی های چند لایه ای برای ویژگی های سطح میانی و سطح بالا ایجاد میکند. مطالعه ای که در (۵۱)صورت گرفت بدنبال ارزیابی اینکه چقدر بهبود ارزیابی میتواند توسط توسعه تکینیک های یادگیری عمیق حاصل شود و آیا ویژگی های عمیق کلید دلخواهی برای پر کردن خلا معنایی در دراز مدت هستند یا خیر بود. همانطور که در شکل ۱۸ مشاهده میکنید , خطای دسته بندی تصاویر در آزمایش ImageNet از ۱۰% در سال ۲۰۱۲(۲۱) به ۴٫۸۲% در سال ۲۰۱۵ (۴) کاهش یافته است.این پیشرفت امیدوارکننده بازدهی شبکه عصبی کانولوشن را تایید میکند. بطور خاص,نتایج موجود در (۴) فراتر از نتایج کسب شده توسط انسان رفت. اما ما نمیتوانیم با این نتایج به این نتیجه برسیم که کارایی نمایشی یک شبکه عصبی کانولوشن در حد و اندازه های مغز انسان است (۱۸۷) . بعنوان مثال تولید تصاویری که براحتی توسط انسان غیرقابل شناسایی باشند آسان است اما یک شبکه عصبی کانولوشن جدید با اطمینان ۹۹٫۹۹ درصد باور دارد که ان شکل حاوی اشیاء قابل شناسایی است .(۱۸۸) این نتیجه تفاوت بین دید انسان و مدلهای فعلی شبکه عصبی کانولوشن را نشان میدهد و این کلی گرایی شبکه های عصبی در بینایی کامپیوتر را مورد تردید قرار میدهد. مطالعه ای که در (۱۸۷)انجام شد نشان داد که همانند IT cortex , شبکه های عصبی کانولوشن اخیر میتوانند فضاهای ویژگی یکسانی برای هر دسته و فضاهای ویژگی متفاوت برای بقیه دسته ها ایجاد کنند این نتیجه نشان میدهد که شبکه های عصبی کانولوشن ممکن است دیدی برای درک فرایند بینایی پستان داران اولیه فراهم کند . در تحقیق دیگری (۱۸۹) محققان یک روش جدید را برای decode مغز برای داده های fmri با استفاده از داده های بدون برچسب و شبکه های عصبی کانولوشن زمانی چند لایه در نظر گرفتند. که چندین لایه فیلتر زمانی را فراگرفته و مدلهای decoding مغزی قدرتمندی را آموزش داد. هنوز مشخص نیست آیا مدلهای CNN که مبنی بر مکانیزم های محاسباتی اند شبیه به سیستم بینایی پستانداران اولیه هستند یا خیر اما با تقلید و استفاده از سیستم بینایی پستان دارن اولیه پتانسیل برای پیشرفتهای بیشتر وجود دارد .
مدلهای بزرگتر ظرفیت بلقوه بیشتری را به نمایش گذاشته اند و گرایش پیشرفتهای اخیر به این سمت بوده است . اما کمبود داده اموزشی ممکن است اندازه و قدرت این مدلها را محدود کند. خصوصا زمانی که بدست آوردن داده های تماما برچسب گذاری شده واقعا گران تمام میشود. اینکه چگونه باید بر نیاز به تعداد عظیمی از داده های آموزشی فائق آمده و یا شبکه های عظیم را چگونه بصورت کارا آموزش باید داد هنوز مشخص نشده است . در حال حاضر دو روش و راه حل برای بدست آوردن داد ههای اموزشی بیشتر وجوددارد . روش اول استفاده از روشهای مختلف تغییر داده مثل تغییر اندازه (scale), چرخش و یا crop کردن تصاویر از داده های آموزشی فعلی است . علاوه بر روش های فوق Wu et al. (44) روشهای دیگری مثل color casting , vignetting و lens distortion را مورد استفاده قرار داد . روش دوم برای جمع آوری نمونه های آزمایشی از الگوریتم های weak learning استفاده میکند.
اخیرا بازه ای از مقالات بر روی یادگیری مفاهیم بصری از موتورهای جستجوی تصاویر منتشر شده اند . (۱۹۰, ۱۹۱). .
Zhou et al. (152) برای افزایش مقیاس سیستم های تشخیص بینایی کامپیوتر روش ConceptLearner را ارائه کرد که میتواند بطور خودکار هزاران مفهوم بصری یاب را از مجموعه تصاویر بصورت ضعیف برچسب گذاری شده فرابگیرید. علاوه بر آن, به منظور کاهش هزینه های حاشیه نویسی محفظه شناسایی برای تشخیص اشیاء تعداد زیادی روش با سرپرست ضعیف (weakly supervised) با برچسب گذاری حضور شی در سطح تصویر ظهور پیدا کرده اند.(۱۹۲)
با این اوصاف توسعه بیشتر تکنیک ها برای ایجاد یا جمع آوری داده های آموزشی جامع بیشتر که شبکه ها را قادر به یادگیری بهتر ویژگهایی که قدرتمند بوده و تحت تغییراتی مثل تبدیلات هندسی و مسدود سازی قرار داشته کند, امیدوار کننده است.
Time complexity
شبکه های عصبی کانولوشن ابتدایی نیازمند منابع محاسباتی زیادی بودند و بنابر این از آنها در کابردهای بلادرنگ استفاده نمیشد. یکی از گرایشات امروزه دراین حوزه توسعه معماری هایی است که اجازه اجرای CNN را بصورت بلادرنگ میدهد. تحقیقی که در (۴۷) انجام شد , مجموعه ای از آزمایشات را تحت یک زمان محدود انجام داد و مدلهایی را پیشنهاد داد که برای کاربردهای بلادرنگ سریع بوده و در عین حال قابل رقابت با مدلهای معمول CNN بودند. علاوه بر آن ثابت سازی پیچیدگی زمانی نیز به درک تاثیر فاکتورهایی مثل عمق, تعداد فیلترها, اندازه فیلتر و … کمک میکند. تحقیق دیگری (۱۹۳)تمامی محاسبات اضافی را در فرایندهای feedforward و backpropagation حذف کرد که باعث افزایش سرعت ۱۵۰۰ برابری شد. این مدل انعطاف خوبی برای مدلهای CNN با طراحی ها و ساختارهای مختلف دارد و بخاطر پیاده سازی بهینه آن با GPU به کارایی بالایی دست پیدا میکند . Ren et al. [review] اپراتورهای کلیدی در شبکه های عصبی کانولوشن را به فرم های برداری تبدیل کرد تا موازی سازی بالایی با استفاده از اپراتورهای ماتریسی/برداری بدست آورد. محققان در این تحقیق در ادامه چارجوب واحدی را برای کاربردهای بینایی سطح بالا و سطح پایین فراهم کردند.
More powerful models
بخاطر اینکه الگوریتم های مربوط به یادگیری عمیق در حوزه های مختلفی از بینایی کامپیوتر به نتایج بسیار عالی با فاصله بسیار زیاد دست پیدا کرده اند, پیشرفت و جلو زدن از آنها را چالش برانگیز تر کرده است . چندین جهت تحقیقاتی ممکن است برای مدلهای قدرتمندتر وجود داشته باشه . اولین جهت افزایش قابلیت تعمیم پذیری با افزایش اندازه شبکه ها است (۲۳, ۱۹۴) شبکه های بزرگتر قادرند بطور معمول, کیفیت کارایی بهتری ارائه کنند اما در این شبکه ها باید مراقب مشکلاتی مثل Overfitting و نیاز به منابع محاسباتی زیاد باشیم. جهت دوم ترکیب اطلاعات از چندین منبع است . ترکیب ویژگی (feature fusion) برای مدت زیادی است که محبوب و جذاب مانده است . و این ترکیب را میتوان به دو نوع دسته بندی کرد. ۱) ویژگی های هر لایه را ترکیب کن . لایه های مختلف ویژگی های مختلفی را فرامیگیرند (۳۱) . خیلی جالب میشد اگر میتوانستیم الگوریتمی را توسعه دهیم که ویژگی های حاصل از هر لایه را تکمیلی(مکملی) کند. بعنوان مثال DeepIndex(195) پیشنهاد کرد که چندین ویژگی CNN را با چندین اندیس معکوس (multiple inverted indices) شامل لایه های مختلف در یک مدل یا چندین لایه از مدلهای مختلف ادغام کند. ۲)ویژگی های انواع مختلف را با هم ترکیب کن . ما میتوانیم مدلهای جامعتری با ادغام با ویژگی های انواع دیگر مثل SIFT بدست بیاوریم . به منظور بهبود کارایی بازیابی تصاویر , DeepEmbedding(196) از ویژگی های SIFT برای ایجاد یک ساختار اندیس معکوس استفاده کرد و ویژگی های CNN حاصل از patch های محلی را برای بهبود قدرت matching استخراج کرد.
جهت سوم برای رسیدن به مدلهای قدرتمند تر طراحی شبکه های عمیق خاصتر است . در حال حاضر تقریبا تمام طرحهای مبتنی بر شبکه های عصبی کانولوشن از یک شبکه مشترک برای پیشبینی های خود استفاده میکنند. که ممکن است به اندازه کافی متمایزکننده نباشد.یک جهت نویدبخش آموزش مخصوص تر شبکه عمیق است یعنی ما باید بیشتر بر روی نوع شی ای که علاقمند به آن هستیم تمرکز کنیم . تحقیق انجام شده در (۳۰)تایید کرد که حاشیه نویسی سطح شی مفیدتر از حاشیه نویسی سطح تصویر برای تشخیص اشیاء است. میتوان به این بعنوان نوعی خاص از شبکه عمیق که بر روی اشیاء بجای کل تصویر تمرکز میکند نگاه کرد. راه حل احتمالی بعدی آموزش شبکه های مختلف برای دسته های مختلف است . بعنوان مثال (۱۹۷)بر روی این شهود که تشخیص همه کلاسها به یک میزان نبوده و یک کلاسیفایر جامع اولیه برای CNN به همراه چند شبکه عصبی کانولوشن خوب طراحی کرد. با استفاده از استراتژی دسته بندی جامع به خوب , میتوان به کارایی بسیار عالی در CIFAR100 دست پیدا کرد.
سید حسین حسن پور متی کلایی ۹ تیر ۱۳۹۵
[۱] Deep learning
[۲] distributed representation
[۳] vision
[۴] image classification
[۵] Object detection
[۶] image retrieval
[۷] semantic segmentation
[۸] human pose estimation
[۹] superior invariant features
[۱۰] training set
[۱۱] stochastic procedure
[۱۲] deformation
[۱۳] استفاده از این روش در این پایان نامه باعث کاهش شدید دقت (از ۹۹% به ۴۳% ) در دیتاست MNIST گشت. فلذا استفاده از این روش توصیه نمیشود!
[۱۴] deformation
[۱۵] descriptor
[۱۶] bases
[۱۷] representation
[۱۸] Quantized visual words
[۱۹] Concern the Zero order statistics
[M1]in which the first layer learns local,
oriented, edge filters, and the second layer captures a variety of
contour features as well as corners and junctions
لیست ارجاعات (این لیست از بک آپ اندتوت پایان نامه من گرفته شده برای همین من ادیت نشده فعلا میزارم(همه مطالب بالا در این لیست هست اما چیزایی هم اینجا هست که بالا نیومده پس این رفرنسایی که تو انتهای مقاله اصلی هست نیست (هرچند۹۸ ۹۹ درصد اونه))
۱٫ Alex K, Sutskever I, Geoffrey EH. ImageNet Classification with Deep Convolutional Neural Networks. 2012:1097–105.
۲٫ He K, Zhang X, Ren S, Sun J. Deep Residual Learning for Image Recognition. CoRR. 2015;abs/1512.03385.
۳٫ He KaZ, Xiangyu and Ren, Shaoqing and Sun, Jian. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. The IEEE International Conference on Computer Vision (ICCV). 2015:1026-34
۴٫ Ioffe S, Szegedy C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. CoRR. 2015;abs/1502.03167.
۵٫ Bordes A, Glorot X, Weston J, Bengio Y, editors. Joint learning of words and meaning representations for open-text semantic parsing. International Conference on Artificial Intelligence and Statistics; 2012.
۶٫ Ciresan D, Meier U, Schmidhuber J, editors. Multi-column deep neural networks for image classification. Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on; 2012: IEEE.
۷٫ Cireşan DC, Meier U, Schmidhuber J, editors. Transfer learning for Latin and Chinese characters with deep neural networks. Neural Networks (IJCNN), The 2012 International Joint Conference on; 2012: IEEE.
۸٫ Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J, editors. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems; 2013.
۹٫ Ren JS, Xu L. On vectorization of deep convolutional neural networks for vision tasks. arXiv preprint arXiv:150107338. 2015.
۱۰٫ Deng L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Transactions on Signal and Information Processing. 2014;3:null-null.
۱۱٫ Schmidhuber J. Deep learning in neural networks: An overview. Neural Networks. 2015;61:85-117.
۱۲٫ Bengio Y. Deep Learning of Representations: Looking Forward. In: Dediu A-H, Martín-Vide C, Mitkov R, Truthe B, editors. Statistical Language and Speech Processing: First International Conference, SLSP 2013, Tarragona, Spain, July 29-31, 2013 Proceedings. Berlin, Heidelberg: Springer Berlin Heidelberg; 2013. p. 1-37.
۱۳٫ Bengio Y. Learning Deep Architectures for AI. Found Trends Mach Learn. 2009;2(1):1-127.
۱۴٫ Bengio YaC, A. and Vincent, P. Representation Learning: A Review and New Perspectives. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2013;35:1798-828.
۱۵٫ LeCun Y. Learning Invariant Feature Hierarchies. In: Fusiello A, Murino V, Cucchiara R, editors. Computer Vision – ECCV 2012 Workshops and Demonstrations: Florence, Italy, October 7-13, 2012, Proceedings, Part I. Berlin, Heidelberg: Springer Berlin Heidelberg; 2012. p. 496-505.
۱۶٫ Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision. 2015;115(3):211-52.
۱۷٫ Wu R, Yan S, Shan Y, Dang Q, Sun G. Deep Image: Scaling up Image Recognition. CoRR. 2015;abs/1501.02876.
۱۸٫ He K, Zhang X, Ren S, Sun J. Deep Residual Learning for Image Recognition. CoRR. 2015;abs/1512.03385.
۱۹٫ Lin M, Chen Q, Yan S. Network In Network. CoRR. 2013;abs/1312.4400.
۲۰٫ LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE. 1998;86(11):2278-324.
۲۱٫ Krizhevsky A, Sutskever I, Hinton GE, editors. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems; 2012.
۲۲٫ Zeiler MD. Hierarchical convolutional deep learning in computer vision: NEW YORK UNIVERSITY; 2013.
۲۳٫ Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, et al., editors. Going deeper with convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۲۴٫ Oquab M, Bottou L, Laptev I, Sivic J, editors. Is object localization for free?-weakly-supervised learning with convolutional neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۲۵٫ Boureau Y-L, Ponce J, LeCun Y, editors. A theoretical analysis of feature pooling in visual recognition. Proceedings of the 27th international conference on machine learning (ICML-10); 2010.
۲۶٫ Scherer D, Müller A, Behnke S. Evaluation of pooling operations in convolutional architectures for object recognition. Artificial Neural Networks–ICANN 2010: Springer; 2010. p. 92-101.
۲۷٫ Cireşan DC, Meier U, Masci J, Gambardella LM, Schmidhuber J. High-performance neural networks for visual object classification. arXiv preprint arXiv:11020183. 2011.
۲۸٫ Zeiler MD, Fergus R. Stochastic pooling for regularization of deep convolutional neural networks. arXiv preprint arXiv:13013557. 2013.
۲۹٫ He KaZ, X. and Ren, S. and Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2015;37:1904-16.
۳۰٫ Ouyang W, Luo P, Zeng X, Qiu S, Tian Y, Li H, et al. Deepid-net: multi-stage and deformable deep convolutional neural networks for object detection. arXiv preprint arXiv:14093505. 2014.
۳۱٫ Girshick RaD, Jeff and Darrell, Trevor and Malik, Jitendra. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2014:580-7.
۳۲٫ Oquab M, Bottou L, Laptev I, Sivic J, editors. Learning and transferring mid-level image representations using convolutional neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014.
۳۳٫ Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR. Improving neural networks by preventing co-adaptation of feature detectors.(Deeplearning.ir) arXiv preprint arXiv:12070580. 2012.
۳۴٫ Baldi P, Sadowski PJ, editors. Understanding dropout. Advances in Neural Information Processing Systems; 2013.
۳۵٫ Ba J, Frey B, editors. Adaptive dropout for training deep neural networks. Advances in Neural Information Processing Systems; 2013.
۳۶٫ Wager S, Wang S, Liang PS, editors. Dropout training as adaptive regularization. Advances in neural information processing systems; 2013.
۳۷٫ Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research. 2014;15(1):1929-58.
۳۸٫ Warde-Farley D, Goodfellow IJ, Courville A, Bengio Y. An empirical analysis of dropout in piecewise linear networks. arXiv preprint arXiv:13126197. 2013.
۳۹٫ Wang S, Manning C, editors. Fast dropout training. Proceedings of the 30th International Conference on Machine Learning; 2013.
۴۰٫ McAllester D. A PAC-Bayesian tutorial with a dropout bound. arXiv preprint arXiv:13072118. 2013.
۴۱٫ Wan L, Zeiler M, Zhang S, Cun YL, Fergus R, editors. Regularization of neural networks using dropconnect. Proceedings of the 30th International Conference on Machine Learning (ICML-13); 2013.
۴۲٫ Howard AG. Some improvements on deep convolutional neural network based image classification. arXiv preprint arXiv:13125402. 2013.
۴۳٫ Dosovitskiy A, Springenberg JT, Brox T. Unsupervised feature learning by augmenting single images. arXiv preprint arXiv:13125242. 2013.
۴۴٫ Wu R, Yan S, Shan Y, Dang Q, Sun G. Deep image: Scaling up image recognition. arXiv preprint arXiv:150102876. 2015;22:388.
۴۵٫ Erhan D, Bengio Y, Courville A, Manzagol P-A, Vincent P, Bengio S. Why does unsupervised pre-training help deep learning? The Journal of Machine Learning Research. 2010;11:625-60.
۴۶٫ He K, Zhang X, Ren S, Sun J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2015;37(9):1904-16.
۴۷٫ He K, Sun J, editors. Convolutional neural networks at constrained time cost. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۴۸٫ Long J, Shelhamer E, Darrell T, editors. Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۴۹٫ Zeiler MD, Fergus R. Visualizing and Understanding Convolutional Networks. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T, editors. Computer Vision – ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I. Cham: Springer International Publishing; 2014. p. 818-33.
۵۰٫ Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:14091556. 2014.
۵۱٫ Wan J, Wang D, Hoi SCH, Wu P, Zhu J, Zhang Y, et al., editors. Deep learning for content-based image retrieval: A comprehensive study. Proceedings of the ACM International Conference on Multimedia; 2014: ACM.
۵۲٫ Yosinski J, Clune J, Bengio Y, Lipson H, editors. How transferable are features in deep neural networks? Advances in Neural Information Processing Systems; 2014.
۵۳٫ Ngiam J, Chen Z, Chia D, Koh PW, Le QV, Ng AY, editors. Tiled convolutional neural networks. Advances in Neural Information Processing Systems; 2010.
۵۴٫ Zeiler MD, Fergus R. Visualizing and understanding convolutional networks. Computer vision–ECCV 2014: Springer; 2014. p. 818-33.
۵۵٫ Girshick R. Fast R-CNN. The IEEE International Conference on Computer Vision (ICCV). 2015.
۵۶٫ Ren S, He K, Girshick R, Sun J, editors. Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems; 2015.
۵۷٫ Gidaris S, Komodakis N, editors. Object Detection via a Multi-Region and Semantic Segmentation-Aware CNN Model. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۵۸٫ Zhu Y, Urtasun R, Salakhutdinov R, Fidler S, editors. segdeepm: Exploiting segmentation and context in deep neural networks for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۵۹٫ Zhang Y, Sohn K, Villegas R, Pan G, Lee H, editors. Improving object detection with deep convolutional networks via bayesian optimization and structured prediction. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۶۰٫ Hariharan B, Arbeláez P, Girshick R, Malik J. Simultaneous Detection and Segmentation. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T, editors. Computer Vision – ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VII. Cham: Springer International Publishing; 2014. p. 297-312.
۶۱٫ Yoo D, Park S, Lee J-Y, Kweon I, editors. Multi-scale pyramid pooling for deep convolutional representation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops; 2015.
۶۲٫ Xie S, Tu Z, editors. Holistically-nested edge detection. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۶۳٫ Sun Y, Wang X, Tang X, editors. Deep convolutional network cascade for facial point detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013.
۶۴٫ Wang X, Zhang L, Lin L, Liang Z, Zuo W, editors. Deep joint task learning for generic object extraction. Advances in Neural Information Processing Systems; 2014.
۶۵٫ Zeng X, Ouyang W, Wang X, editors. Multi-stage contextual deep learning for pedestrian detection. Proceedings of the IEEE International Conference on Computer Vision; 2013.
۶۶٫ Miclut B. Committees of deep feedforward networks trained with few data. Pattern Recognition: Springer; 2014. p. 736-42.
۶۷٫ Weston J, Ratle F, Mobahi H, Collobert R. Deep learning via semi-supervised embedding. Neural Networks: Tricks of the Trade: Springer; 2012. p. 639-55.
۶۸٫ Simonyan K, Vedaldi A, Zisserman A, editors. Deep fisher networks for large-scale image classification. Advances in neural information processing systems; 2013.
۶۹٫ Song Z, Chen Q, Huang Z, Hua Y, Yan S, editors. Contextualizing object detection and classification. Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on; 2011: IEEE.
۷۰٫ Hinton G, Sejnovski T. Learning and Re-learning in Boltzmann Machines, PDP. MTI Press; 1986.
۷۱٫ Carreira-Perpinan MA, Hinton G, editors. On Contrastive Divergence Learning. AISTATS; 2005: Citeseer.
۷۲٫ Hinton G. A practical guide to training restricted Boltzmann machines. Momentum. 2010;9(1):926.
۷۳٫ Cho K, Raiko T, Ihler AT, editors. Enhanced gradient and adaptive learning rate for training restricted Boltzmann machines. Proceedings of the 28th International Conference on Machine Learning (ICML-11); 2011.
۷۴٫ Nair V, Hinton GE, editors. Rectified linear units improve restricted boltzmann machines. Proceedings of the 27th International Conference on Machine Learning (ICML-10); 2010.
۷۵٫ Ngiam J, Chen Z, Koh PW, Ng AY, editors. Learning deep energy models. Proceedings of the 28th International Conference on Machine Learning (ICML-11); 2011.
۷۶٫ Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2013;35(8):1798-828.
۷۷٫ Arel I, Rose DC, Karnowski TP. Deep machine learning-a new frontier in artificial intelligence research [research frontier]. Computational Intelligence Magazine, IEEE. 2010;5(4):13-8.
۷۸٫ Lee H, Ekanadham C, Ng AY, editors. Sparse deep belief net model for visual area V2. Advances in neural information processing systems; 2008.
۷۹٫ Lee H, Grosse R, Ranganath R, Ng AY, editors. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. Proceedings of the 26th Annual International Conference on Machine Learning; 2009: ACM.
۸۰٫ Lee H, Grosse R, Ranganath R, Ng AY. Unsupervised learning of hierarchical representations with convolutional deep belief networks. Communications of the ACM. 2011;54(10):95-103.
۸۱٫ Nair V, Hinton GE, editors. 3D object recognition with deep belief nets. Advances in Neural Information Processing Systems; 2009.
۸۲٫ Tang Y, Eliasmith C, editors. Deep networks for robust visual recognition. Proceedings of the 27th International Conference on Machine Learning (ICML-10); 2010.
۸۳٫ Huang GB, Lee H, Learned-Miller E, editors. Learning hierarchical representations for face verification with convolutional deep belief networks. Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on; 2012: IEEE.
۸۴٫ Salakhutdinov R, Hinton GE, editors. Deep boltzmann machines. International conference on artificial intelligence and statistics; 2009.
۸۵٫ Younes L. On the convergence of Markovian stochastic algorithms with rapidly decreasing ergodicity rates. Stochastics: An International Journal of Probability and Stochastic Processes. 1999;65(3-4):177-228.
۸۶٫ Salakhutdinov R, Larochelle H, editors. Efficient learning of deep Boltzmann machines. International Conference on Artificial Intelligence and Statistics; 2010.
۸۷٫ Salakhutdinov R, Hinton G. An efficient learning procedure for deep Boltzmann machines. Neural computation. 2012;24(8):1967-2006.
۸۸٫ Hinton GE, Salakhutdinov RR, editors. A better way to pretrain deep boltzmann machines. Advances in Neural Information Processing Systems; 2012.
۸۹٫ Cho K, Raiko T, Ilin A, Karhunen J. A two-stage pretraining algorithm for deep Boltzmann machines. Artificial Neural Networks and Machine Learning–ICANN 2013: Springer; 2013. p. 106-13.
۹۰٫ Montavon G, Müller K-R. Deep Boltzmann machines and the centering trick. Neural Networks: Tricks of the Trade: Springer; 2012. p. 621-37.
۹۱٫ Goodfellow IJ, Courville A, Bengio Y. Joint training deep boltzmann machines for classification. arXiv preprint arXiv:13013568. 2013.
۹۲٫ Goodfellow I, Mirza M, Courville A, Bengio Y, editors. Multi-prediction deep Boltzmann machines. Advances in Neural Information Processing Systems; 2013.
۹۳٫ Elfwing S, Uchibe E, Doya K. Expected energy-based restricted Boltzmann machine for classification. Neural Networks. 2015;64:29-38.
۹۴٫ Eslami SA, Heess N, Williams CK, Winn J. The shape boltzmann machine: a strong model of object shape. International Journal of Computer Vision. 2014;107(2):155-76.
۹۵٫ Kae A, Sohn K, Lee H, Learned-Miller E, editors. Augmenting CRFs with Boltzmann machine shape priors for image labeling. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013.
۹۶٫ Dahl G, Mohamed A-r, Hinton GE, editors. Phone recognition with the mean-covariance restricted Boltzmann machine. Advances in neural information processing systems; 2010.
۹۷٫ Liou C-Y, Cheng W-C, Liou J-W, Liou D-R. Autoencoder for words. Neurocomputing. 2014;139:84-96.
۹۸٫ Hinton GE, Salakhutdinov RR. Reducing the dimensionality of data with neural networks. Science. 2006;313(5786):504-7.
۹۹٫ Zhang J, Shan S, Kan M, Chen X. Coarse-to-fine auto-encoder networks (cfan) for real-time face alignment. Computer Vision–ECCV 2014: Springer; 2014. p. 1-16.
۱۰۰٫ Zhou Y, Arpit D, Nwogu I, Govindaraju V. Joint Training of Deep Auto-Encoders. arXiv preprint arXiv:14051380. 2014.
۱۰۱٫ Jiang X, Zhang Y, Zhang W, Xiao X, editors. A novel sparse auto-encoder for deep unsupervised learning. Advanced Computational Intelligence (ICACI), 2013 Sixth International Conference on; 2013: IEEE.
۱۰۲٫ Goodfellow I, Lee H, Le QV, Saxe A, Ng AY, editors. Measuring invariances in deep networks. Advances in neural information processing systems; 2009.
۱۰۳٫ Poultney C, Chopra S, Cun YL, editors. Efficient learning of sparse representations with an energy-based model. Advances in neural information processing systems; 2006.
۱۰۴٫ Ngiam J, Coates A, Lahiri A, Prochnow B, Le QV, Ng AY, editors. On optimization methods for deep learning. Proceedings of the 28th International Conference on Machine Learning (ICML-11); 2011.
۱۰۵٫ Simoncelli EP. 4.7 Statistical Modeling of Photographic Images. 2005.
۱۰۶٫ Le QV, editor Building high-level features using large scale unsupervised learning. Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on; 2013: IEEE.
۱۰۷٫ Vincent P, Larochelle H, Bengio Y, Manzagol P-A, editors. Extracting and composing robust features with denoising autoencoders. Proceedings of the 25th international conference on Machine learning; 2008: ACM.
۱۰۸٫ Vincent P, Larochelle H, Lajoie I, Bengio Y, Manzagol P-A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research. 2010;11:3371-408.
۱۰۹٫ Rifai S, Vincent P, Muller X, Glorot X, Bengio Y, editors. Contractive auto-encoders: Explicit invariance during feature extraction. Proceedings of the 28th international conference on machine learning (ICML-11); 2011.
۱۱۰٫ Alain G, Bengio Y. What regularized auto-encoders learn from the data-generating distribution. The Journal of Machine Learning Research. 2014;15(1):3563-93.
۱۱۱٫ Mesnil G, Dauphin Y, Glorot X, Rifai S, Bengio Y, Goodfellow IJ, et al. Unsupervised and Transfer Learning Challenge: a Deep Learning Approach. ICML Unsupervised and Transfer Learning. 2012;27:97-110.
۱۱۲٫ Olshausen BA, Field DJ. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vision research. 1997;37(23):3311-25.
۱۱۳٫ Raina R, Battle A, Lee H, Packer B, Ng AY, editors. Self-taught learning: transfer learning from unlabeled data. Proceedings of the 24th international conference on Machine learning; 2007: ACM.
۱۱۴٫ Yu K, Zhang T, Gong Y, editors. Nonlinear learning using local coordinate coding. Advances in neural information processing systems; 2009.
۱۱۵٫ Wang J, Yang J, Yu K, Lv F, Huang T, Gong Y, editors. Locality-constrained linear coding for image classification. Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on; 2010: IEEE.
۱۱۶٫ Yang J, Yu K, Gong Y, Huang T, editors. Linear spatial pyramid matching using sparse coding for image classification. Computer Vision and Pattern Recognition, 2009 CVPR 2009 IEEE Conference on; 2009: IEEE.
۱۱۷٫ Lazebnik S, Schmid C, Ponce J, editors. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on; 2006: IEEE.
۱۱۸٫ Coates A, Ng AY, editors. The importance of encoding versus training with sparse coding and vector quantization. Proceedings of the 28th International Conference on Machine Learning (ICML-11); 2011.
۱۱۹٫ Gao S, Tsang IW-H, Chia L-T, Zhao P, editors. Local features are not lonely–Laplacian sparse coding for image classification. Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on; 2010: IEEE.
۱۲۰٫ Gao S, Tsang IW-H, Chia L-T. Laplacian sparse coding, hypergraph laplacian sparse coding, and applications. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2013;35(1):92-104.
۱۲۱٫ Yu K, Lin Y, Lafferty J, editors. Learning image representations from the pixel level via hierarchical sparse coding. Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on; 2011: IEEE.
۱۲۲٫ Zeiler MD, Krishnan D, Taylor GW, Fergus R, editors. Deconvolutional networks. Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on; 2010: IEEE.
۱۲۳٫ Zeiler MD, Taylor GW, Fergus R, editors. Adaptive deconvolutional networks for mid and high level feature learning. Computer Vision (ICCV), 2011 IEEE International Conference on; 2011: IEEE.
۱۲۴٫ Zhou X, Yu K, Zhang T, Huang TS. Image classification using super-vector coding of local image descriptors. Computer Vision–ECCV 2010: Springer; 2010. p. 141-54.
۱۲۵٫ Lin Y, Lv F, Zhu S, Yang M, Cour T, Yu K, et al., editors. Large-scale image classification: fast feature extraction and svm training. Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on; 2011: IEEE.
۱۲۶٫ Balasubramanian K, Yu K, Lebanon G. Smooth sparse coding via marginal regression for learning sparse representations. arXiv preprint arXiv:12101121. 2012.
۱۲۷٫ He Y, Kavukcuoglu K, Wang Y, Szlam A, Qi Y, editors. Unsupervised Feature Learning by Deep Sparse Coding. SDM; 2014: SIAM.
۱۲۸٫ Csurka G, Dance C, Fan L, Willamowski J, Bray C, editors. Visual categorization with bags of keypoints. Workshop on statistical learning in computer vision, ECCV; 2004: Prague.
۱۲۹٫ Boser BE, Guyon IM, Vapnik VN, editors. A training algorithm for optimal margin classifiers. Proceedings of the fifth annual workshop on Computational learning theory; 1992: ACM.
۱۳۰٫ Dalal N, Triggs B, editors. Histograms of oriented gradients for human detection. Computer Vision and Pattern Recognition, 2005 CVPR 2005 IEEE Computer Society Conference on; 2005: IEEE.
۱۳۱٫ Wang X, Han TX, Yan S, editors. An HOG-LBP human detector with partial occlusion handling. Computer Vision, 2009 IEEE 12th International Conference on; 2009: IEEE.
۱۳۲٫ Perronnin F, Sánchez J, Mensink T. Improving the fisher kernel for large-scale image classification. Computer Vision–ECCV 2010: Springer; 2010. p. 143-56.
۱۳۳٫ Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L, editors. Imagenet: A large-scale hierarchical image database. Computer Vision and Pattern Recognition, 2009 CVPR 2009 IEEE Conference on; 2009: IEEE.
۱۳۴٫ Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. CoRR. 2013;abs/1312.6229.
۱۳۵٫ He K, Zhang X, Ren S, Sun J, editors. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۱۳۶٫ Felzenszwalb PF, Girshick RB, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2010;32(9):1627-45.
۱۳۷٫ Szegedy C, Toshev A, Erhan D, editors. Deep neural networks for object detection. Advances in Neural Information Processing Systems; 2013.
۱۳۸٫ Erhan D, Szegedy C, Toshev A, Anguelov D, editors. Scalable object detection using deep neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014.
۱۳۹٫ Uijlings JR, van de Sande KE, Gevers T, Smeulders AW. Selective search for object recognition. International journal of computer vision. 2013;104(2):154-71.
۱۴۰٫ Redmon J, Divvala SK, Girshick RB, Farhadi A. You Only Look Once: Unified, Real-Time Object Detection. CoRR. 2015;abs/1506.02640.
۱۴۱٫ Alexe B, Deselaers T, Ferrari V. Measuring the objectness of image windows. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2012;34(11):2189-202.
۱۴۲٫ Endres I, Hoiem D. Category independent object proposals. Computer Vision–ECCV 2010: Springer; 2010. p. 575-88.
۱۴۳٫ Cheng M-M, Zhang Z, Lin W-Y, Torr P, editors. BING: Binarized normed gradients for objectness estimation at 300fps. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014.
۱۴۴٫ Zitnick CL, Dollár P. Edge boxes: Locating object proposals from edges. Computer Vision–ECCV 2014: Springer; 2014. p. 391-405.
۱۴۵٫ Hosang J, Benenson R, Schiele B. How good are detection proposals, really? arXiv preprint arXiv:14066962. 2014.
۱۴۶٫ Dai Q, Hoiem D, editors. Learning to localize detected objects. Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on; 2012: IEEE.
۱۴۷٫ Hoiem D, Chodpathumwan Y, Dai Q. Diagnosing error in object detectors. Computer Vision–ECCV 2012: Springer; 2012. p. 340-53.
۱۴۸٫ Dong J, Chen Q, Yan S, Yuille A. Towards unified object detection and semantic segmentation. Computer Vision–ECCV 2014: Springer; 2014. p. 299-314.
۱۴۹٫ Ren S, He K, Girshick R, Zhang X, Sun J. Object detection networks on convolutional feature maps. arXiv preprint arXiv:150406066. 2015.
۱۵۰٫ Hoffman J, Guadarrama S, Tzeng E, Donahue J, Girshick R, Darrell T, et al. From large-scale object classifiers to large-scale object detectors: An adaptation approach. Proc Adv Neural Inf Process Syst. 2014:3536-44.
۱۵۱٫ Hoffman J, Guadarrama S, Tzeng ES, Hu R, Donahue J, Girshick R, et al., editors. LSDA: Large scale detection through adaptation. Advances in Neural Information Processing Systems; 2014.
۱۵۲٫ Zhou B, Jagadeesh V, Piramuthu R, editors. Conceptlearner: Discovering visual concepts from weakly labeled image collections. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۱۵۳٫ Liang X, Liu S, Wei Y, Liu L, Lin L, Yan S, editors. Towards computational baby learning: A weakly-supervised approach for object detection. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۱۵۴٫ Gong Y, Wang L, Guo R, Lazebnik S. Multi-scale Orderless Pooling of Deep Convolutional Activation Features. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T, editors. Computer Vision – ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VII. Cham: Springer International Publishing; 2014. p. 392-407.
۱۵۵٫ Razavian A, Azizpour H, Sullivan J, Carlsson S, editors. CNN features off-the-shelf: an astounding baseline for recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops; 2014.
۱۵۶٫ Sun S, Zhou W, Li H, Tian Q, editors. Search by detection: Object-level feature for image retrieval. Proceedings of International Conference on Internet Multimedia Computing and Service; 2014: ACM.
۱۵۷٫ Babenko A, Slesarev A, Chigorin A, Lempitsky V. Neural Codes for Image Retrieval. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T, editors. Computer Vision – ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I. Cham: Springer International Publishing; 2014. p. 584-99.
۱۵۸٫ Hariharan B, Arbeláez P, Girshick R, Malik J, editors. Hypercolumns for object segmentation and fine-grained localization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۱۵۹٫ Dai J, He K, Sun J, editors. Convolutional feature masking for joint object and stuff segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۱۶۰٫ Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv preprint arXiv:14127062. 2014.
۱۶۱٫ Lin G, Shen C, Reid I. Efficient piecewise training of deep structured models for semantic segmentation. arXiv preprint arXiv:150401013. 2015.
۱۶۲٫ Zheng S, Jayasumana S, Romera-Paredes B, Vineet V, Su Z, Du D, et al., editors. Conditional random fields as recurrent neural networks. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۱۶۳٫ Papandreou G, Chen L-C, Murphy K, Yuille AL. Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation. CoRR. 2015;abs/1502.02734.
۱۶۴٫ Dai J, He K, Sun J, editors. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۱۶۵٫ Pfister T, Charles J, Zisserman A, editors. Flowing convnets for human pose estimation in videos. Proceedings of the IEEE International Conference on Computer Vision; 2015.
۱۶۶٫ Jain A, Tompson J, LeCun Y, Bregler C. MoDeep: A Deep Learning Framework Using Motion Features for Human Pose Estimation. In: Cremers D, Reid I, Saito H, Yang M-H, editors. Computer Vision — ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, Singapore, November 1-5, 2014, Revised Selected Papers, Part II. Cham: Springer International Publishing; 2015. p. 302-15.
۱۶۷٫ Pfister T, Simonyan K, Charles J, Zisserman A. Deep convolutional neural networks for efficient pose estimation in gesture videos. Computer Vision–ACCV 2014: Springer; 2014. p. 538-52.
۱۶۸٫ Felzenszwalb PF, Huttenlocher DP. Pictorial structures for object recognition. International Journal of Computer Vision. 2005;61(1):55-79.
۱۶۹٫ Wang F, Li Y, editors. Beyond physical connections: Tree models in human pose estimation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013.
۱۷۰٫ Tian Y, Zitnick CL, Narasimhan SG. Exploring the spatial hierarchy of mixture models for human pose estimation. Computer Vision–ECCV 2012: Springer; 2012. p. 256-69.
۱۷۱٫ Dantone M, Gall J, Leistner C, Gool L, editors. Human pose estimation using body parts dependent joint regressors. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013.
۱۷۲٫ Pishchulin L, Andriluka M, Gehler P, Schiele B, editors. Poselet conditioned pictorial structures. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013.
۱۷۳٫ Sapp B, Taskar B, editors. Modec: Multimodal decomposable models for human pose estimation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2013.
۱۷۴٫ Johnson S, Everingham M, editors. Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation. BMVC; 2010.
۱۷۵٫ Eichner M, Marin-Jimenez M, Zisserman A, Ferrari V. 2d articulated human pose estimation and retrieval in (almost) unconstrained still images. International journal of computer vision. 2012;99(2):190-214.
۱۷۶٫ Toshev A, Szegedy C, editors. Deeppose: Human pose estimation via deep neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014.
۱۷۷٫ Chen X, Yuille AL, editors. Articulated pose estimation by a graphical model with image dependent pairwise relations. Advances in Neural Information Processing Systems; 2014.
۱۷۸٫ Jain A, Tompson J, Andriluka M, Taylor GW, Bregler C. Learning human pose estimation features with convolutional networks. arXiv preprint arXiv:13127302. 2013.
۱۷۹٫ Tompson JJ, Jain A, LeCun Y, Bregler C, editors. Joint training of a convolutional network and a graphical model for human pose estimation. Advances in neural information processing systems; 2014.
۱۸۰٫ Tompson J, Goroshin R, Jain A, LeCun Y, Bregler C, editors. Efficient object localization using convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015.
۱۸۱٫ Ouyang W, Chu X, Wang X, editors. Multi-source deep learning for human pose estimation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014.
۱۸۲٫ Fan X, Zheng K, Lin Y, Wang S, editors. Combining local appearance and holistic view: Dual-source deep neural networks for human pose estimation. Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on; 2015: IEEE.
۱۸۳٫ Carreira J, Agrawal P, Fragkiadaki K, Malik J. Human Pose Estimation with Iterative Error Feedback. CoRR. 2015;abs/1507.06550.
۱۸۴٫ Chu JL, Krzyżak A. Analysis of feature maps selection in supervised learning using convolutional neural networks. Advances in Artificial Intelligence: Springer; 2014. p. 59-70.
۱۸۵٫ Yu W, Yang K, Bai Y, Yao H, Rui Y. Visualizing and Comparing Convolutional Neural Networks. arXiv preprint arXiv:14126631. 2014.
۱۸۶٫ Agrawal P, Girshick R, Malik J. Analyzing the performance of multilayer neural networks for object recognition. Computer Vision–ECCV 2014: Springer; 2014. p. 329-44.
۱۸۷٫ Cadieu CF, Hong H, Yamins DL, Pinto N, Ardila D, Solomon EA, et al. Deep neural networks rival the representation of primate it cortex for core visual object recognition. PLoS Comput Biol. 2014;10(12):e1003963.
۱۸۸٫ Nguyen A, Yosinski J, Clune J, editors. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on; 2015: IEEE.
۱۸۹٫ Firat O, Aksan E, Oztekin I, Vural FTY. Learning Deep Temporal Representations for Brain Decoding. arXiv preprint arXiv:14127522. 2014.
۱۹۰٫ Divvala S, Farhadi A, Guestrin C, editors. Learning everything about anything: Webly-supervised visual concept learning. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2014.
۱۹۱٫ Chen X, Shrivastava A, Gupta A, editors. Neil: Extracting visual knowledge from web data. Proceedings of the IEEE International Conference on Computer Vision; 2013.
۱۹۲٫ Song HO, Lee YJ, Jegelka S, Darrell T, editors. Weakly-supervised discovery of visual pattern configurations. Advances in Neural Information Processing Systems; 2014.
۱۹۳٫ Li H, Zhao R, Wang X. Highly efficient forward and backward propagation of convolutional neural networks for pixelwise classification. arXiv preprint arXiv:14124526. 2014.
۱۹۴٫ Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR. 2014;abs/1409.1556.
۱۹۵٫ Liu Y, Guo Y, Wu S, Lew MS, editors. DeepIndex for accurate and efficient image retrieval. Proceedings of the 5th ACM on International Conference on Multimedia Retrieval; 2015: ACM.
۱۹۶٫ Zheng L, Wang S, He F, Tian Q. Seeing the big picture: Deep embedding with contextual evidences. arXiv preprint arXiv:14060132. 2014.
۱۹۷٫ Yan Z, Zhang H, Piramuthu R, Jagadeesh V, DeCoste D, Di W, et al., editors. HD-CNN: Hierarchical Deep Convolutional Neural Networks for Large Scale Visual Recognition. Proceedings of the IEEE International Conference on Computer Vision; 2015.
لطفا اگه اشکالی یا مشکلی دیدید اطلاع بدید. خیلی ممنونم 🙂
التماس دعا
خسته نباشید عالی بود. مخصوصا این قسمتش سرحالم کرد “طراحی معماری ها تا بحال مبتنی بر روش الله بختکی و ad-hoc بوده است .” :)))
سلام آقای حسن پور
واقعا خسته نباشید.منکه دارم دونه دونه مقاله ترجمه میکنم برای دیپ لرنینگ میفهمم با این مطالب چه لطف بزرگی در حق بقیه انجام دادید.
مطالب عالی هستن اما بنظرم پست های طولانی یکم خواننده رو خسته میکنه اگه مطالب سایت دسته بندی بشن حجم مطالب مربوط ب هر پست کمتر میشه.تو این پست از حوزه های مختلف توضیحاتی دادید برای آشنایی که هرکدومشون میتونن جداگانه در نظر گرفته بشن،اینجور دسترسی خواننده به مطالب راحتتر میشه.
در کل دستتون درد نکنه عالی بود آقای مهندس
سلام
خواهش میکنم
یکی از دلایلی که دسته های مختلفی هنوز ایجاد نکردم بخاطر آماده نبودن مطالب اون بخش هست . این هم چون یک مقاله بود کامل گذاشتم .
ولی فرمایش شما هم منطقیه . انشاالله طی روزهای آینده سعی میکنم مطلب رو به چند بخش تقسیم کنم و بعدا هم سر فرصت دسته بندی ها رو مرتب کنم.
التماس دعا
سلام، آقای حسن پور من از سه جهت از شما تشکر می کنم
۱- بخاطر اینکه اندوخته های علمی خود را بدون هیچ توقعی با دیگران به اشتراک می گذارید.
۲- بخاطر اینکه به سوالات و ایمیل ها در اسرع وقت پاسخ می دهید و تا جایی که می توانید در جهت کمک کردن به دیگران گام بر می دارید.
۳- بخاطر شخصیت غنی ، معرفت بالا و گشاده دستی که من حسش می کنم و برداشتش کردم.
« اَلَم یَعلَم بِاَن الله یَری »
موفق باشید
سلام
خیلی ممنونم شما لطف دارید
خدا رو شکر که این مطالب تونسته مفید واقع بشه براتون
التماس دعا
سلام
وقت شما به خیر
عباداتتان مقبول و عیدتان مبارک
خواهشمند هستم در صورت امکان فایل pdf ی جهت دانلود مطالبتان قرار داده شود.
سپاس فراوان
سلام
خیلی ممنون عیدشما هم مبارک و طاعات و عبادات شما هم قبول حق انشاالله
انشاالله در اولین فرصت این کارو انجام میدم
التماس دعا
ممنون از لطف شما
محتاج دعا
این لینک دانلود PDF همین صفحه اس :
http://uploadboy.com/mkj8j88v9ewc/1890/pdf
تا وقتی سر فرصت تبدیل کنم این انشاالله کار شما رو راه میندازه بنظرم
سپاس فراوان از لطف شما.
بسم الله الرحمن الرحیم
با سلام
از مطالب مفیدی که گذاشتید خیلی تشکر می کنم.
لطفا توضیحاتی راجع به Feature Learning و ارتباط آن با یادگیری عمیق بفرمائید و یا گروه یا منابعی را برای این موضوع معرفی کنید.
با سپاس فراوان
سلام .
الان اکثر اموزش ها و ویدئوها در این باره توضیح میدن . توضیحات خوب رو میتونید از بخش منابع یادگیری پیدا کنید. خصوصا لینک summer school و آموزش دانشگاه استنفورد رو اگر ندیدید رو حتما ببینید.
سلام …ممنون بابت مطالب مفیدی که گذاشنتید
شماره منابعی که در متن ذکر کردید با منابع ارائه شده انتهای صفحه هم خوانی ندارن لطفا در صورت امکان ترتیب اصلی منابع استفاده شده را ارائه دهید….با تشکر
سلام.
اخرین باری که یادم میاد منابع همه درست بودن.(چون کپی پیست از بخشهایی از پایان نامه خودم بود) کدوم بخش مشکل داره ؟
البته من انشالله اگه هفته بعد فرصت بکنم شیوه رنفرنسی رو عوض میکنم که اسم مقاله بیاد تو متن که دیگه دردسر پیدا کردن مقاله از مرجع انتهایی کمتر بشه .
ولی فعلا بخاطر درگیری زیادی که طی یک هفته اینده دارم نمیرسم این کارو بکنم.
سلام
ترتیب بسیاری از منابع با متن همخوانی نداره
مثلا بخش پیش آموزش Fine Tuning:و( AlexNet(21);VGG(50); Clarifi(49)GoogleNet(23,Erhan et all (45
بخش معماری شبکه های عصبی کانولوشن:( He et all (46); Szegedy et all (23
بخش کاربردهای یادگیری عمیق- دسته بندی تصاویر:
۱۳۰ تا ۱۳۵، ۱۱۷، ۲۱
تشخیص اشیا: ۱۳۶ و ۱۳۷
بازیابی اشیا: ۵۱- -۱۶۵- ۱۵۴تا ۱۵۷
چالش ها ۵۴-۱۸۴
ممنون میشم ترتیب اصلی این منابع و بگید.
با تشکر
بله متوجه شدم.
من متاسفانه متنی که اینجا قرار دادم ورژن خیلی قدیمی کارم بود و رفرنسها رو وارد داکیومنت نکرده بودم . ورژن الانم با چیزی که اینجا هست فرق می کنه برای همین رفرنسها پس و پیش شده . (مثلا الکس ۲۱ تو رفرنس جدید من ۲ هست نه ۲۱! بقیه هم به همین شکل).
من یکم وقت میبره تا نسخه جدید رو با سایت همگام کنم و یکسری تغییرات بدم .در حال حاضر اصلا وقت نمیکنم برم طرفش . (تا انشالله هفته اینده)
شما هم میتونید از رفرنسهای مقاله اصلی استفاده کنید که فک کنم ۹۸ ۹۹ درصد یکی باشه . لینک مقاله اصلی هم در ابتدای پست اومده .
خیلی ممنون که اطلاع دادید انشاالله در اسرع وقت این نسخه رو بروز میکنم.
با سلام و احترام
با تشکر از مطالب ارائه شده ، من قصد دارم که با استفاده از کد گذاری تنک روشی برای بازنمایی تصاویر جهت ایجاد یک طبقه بندی کننده استفاده کنم. ویژگیهایی که از تصاویر استخراج می شوند از نوع SURF و SIFT هستند. بعد از استخراج ویژگی ها و اعمال فرآیند کد گذاری تنک باید عمل Max pooling را بر روی بردار ویژگی های تنک اعمال کرد سپس بردار ویژگی های بدست آمده را به طبقه بندی کننده ارسال کرد.
سوال من این است که فرآیند Max pooling را چگونه باید بر روی ویژگی های SURF اعمال کرد. من مطالب زیادی را پیرامون این موضوع مطالعه کرده ام ولی متاسفانه هنوز انقدر اشراف پیدا نکرده ام که بتوانم این الگوریتم (SPM)را پیاده سازی کنم . لطفا اگر ممکن است در این خصوص راهنمایی بفرمایید.
اگر کد زبان C الگوریتم SPM دارید لطفا برای من ارسال فرمایید.
با تشکر فراوان
بابک
سلام .
من متاسفانه تو این زمینه کار نکردم و اطلاعی ندارم .
بهترین راه حل برای شما ۱٫ سوال در بخش پرسش و پاسخ و بعد ارجاع اون به گروه یادگیری عمیق در تلگرام هست که اگر کسی کار کرده راهنمایی کنه
و یا بهتر تو Quora سوالتون رو بپرسید. فعلا کورا بهترین مکان برای پرسش و پاسخ های حوزه یادگیری عمیق هست.
با سلام. یک سوال داشتم آیا با شبکه عصبی باور عمیق (DBN) می توان پیش بینی های سری های زمانی را انجام داد؟ متشکر می شم اگر جواب دهید. ممنون
من با DBN ها کار نکردم . نمونه ای هم به چشمم نخورده از این موضوع . کلا DBN ها تقریبا دیگه استفاده نمیشن. و برای کار روی سری های زمانی از LSTM ها زیاد استفاده میشه الان
سلام
برای نمودار هایی که استفاده شده از جایی اوردینشون یا نتایج جستجوی خودتون هست و خودتون زحمتش رو کشیدین.
به طور مثال من برای سمینار خودم می خوام از نمودارایی که کشیدین استفاده کنم اما نمی دونم به چی رفرنس بدمشون.
سلام . نمودارها اکثرا مربوط به مقاله deep-learning for visual understanding a review هست.فکر نمیکنم نمودارهای خودم رو توش قرار داده باشم چون ویرایشش کرده بودم.
شما مقاله رو ببینید متوجه میشید
برای ارجاع هم میتونید بطور مشخص هم از اون مقاله استفاده کنید و هم به سایت ارجاع بدید چون همه مطالبی که اینجاس در مقاله نیست
با سلام
ممنون ازمطالب خوبتون
سوالی که از خدمتتون داشتم اینه که در شبکه های عصبی کانولوشن استخراج ویژگی صورت نمیگیرد بلکه یادگیری ویژگی انجام میشه، حالا سوال اینه این اتفاق در ۳ مرحله ای که شبکه داره درکدام قسمت انجام میشه؟
۲)آیا الگوریتم خاصی برای یادگیری در شبکه وجوددارد؟
سلام
منظورتون رو از سه مرحله شبکه متوجه نشدم
اما اون هسته اصلی این یادگیری ویژگی مربوط به عملیات کانولوشن و فیلترهای یادگرفته شده و اعمال این عملیات روی بازنمایی های سطوح مختلف هست (که ماحصل اعمال عملیات کانولوشن از مرحله قبل میشه)
سلام
ممنون از مطالب خوب و کاربردی تون
شما با شبکه های چندوظیفه ای عمیق آشنایی دارید؟
منبع خوبی برای آشنایی با ان شبکه ها سراغ ندارید؟
سلام منظورتون Multi-task هست ؟ با این لفظ من برخورد نداشتم .
اگر منظور انجام دوتا کار در یک شبکه هست برای افزایش دقت یک کار شبکه های مختلفی اومده که از این بحث استفاده میکنن تو سگمنتیشن ها و دیتکشن ها و…
شما لکچر ۸ دانشگاه استنفورد رو ببینید که در مورد سگمنتیشن و دیتکشن صحبت میکنه و فک کنم لکچر ۱۱ ببینید منظور همین نوع شبکه ها هست یا نه . (ماهیت منظورم هست نه کاربردی که تو لکچر توضیح داده میشه مثل سگمنتیشن و…)
برای آشنایی بهترین چیز فعلا مقاله های این حوزه است و برای پیدا کردن این مقاله ها و یا سوال در موردش بهترین جا سایت Quora.com هست.
سلام
بله منظورم Multi-task learning هست، ممکنه که چندوظیفه با هم انجام بشن برای افزایش دقت یک کار، ولی لزوما هدف این نیست و برخی اوقات هدف رسیدن به معماری واحدی برای انجام چندوظیفه است. این روش اغلب برای حوزه هایی که وظایف اشتراکات خوبی با هم دارند و می توانند به هم کمک کنند مورد استفاده قرار می گیره.
متاسفانه من تا حالا کسی رو پیدا نکردم که در این زمینه تجربیاتی داشته باشه
بسیار ممنونم از راهنمایی هاتون، حتما مراجعه می کنم
سلام . خیلی ممنونم که توضیح بیشتر دادید
من منظورم از کار یه فعالیت کلی هست (مثلا دیتکشن مرحله کلسیفیکیشن و رگرشن با هم رو داره که یکی کار دسته بندی (تشخیص) رو انجام میده و دیگری یه bounding box دور تصویر مشخص میکنه تو سگمنتیشن هم به همین صورت و ایل اخر ) من با لفظ معماری های end-to-end برخورد داشتم با اینجور کارها .یعنی به چیزی که شما میگید میگن یک معماری end-to-end. و اگر همینی باشه که من فکر میکنم با توجه به توضیحاتی هم که دادید حتما اون دو لکچر رو ببینید .
سلام
منظورم از ۳لایه ، لایه کانولوشن-لایه poolingو لایه تماما متصل هست
یادگیری ویژگی در کدام مرحله صورت می گیرد؟
سلام
الگوریتم انواع معماری مثل alex رو چطوری میشه پیدا کرد. اکثر مقالات کلی بحث کردند وشبه کد و یا الگوریتم دقیقی ارائه نکردند اما برای پیاده سازی بهشون نیاز هست
ممنون
لعنت خدا بر یزید
سلام
من منظورتون رو از الگوریتم انواع معماری متوجه نمیشم . اما اگه منظورتون پیاده سازی لایه هایی(الگوریتم) مثل dropout یا الگوریتم مقداردهی اولیه Xavier و که در این معماری ها استفاده شده باشه شما در درجه اول باید به مقاله ای که این الگوریتم ها رو نوشتن مراجعه کنید که البته تو رفرنس همون مقالات هست.
معمولا بهترین و سریعترین راه نگاه به پیاده سازی کتابخونه ها و یا فریم ورکهای معروف مثل caffe و… هست .
ممنون
مثلا برای تطبیق مقاله شبه کد داره ولی برای شبکه عصبی هنوز همچین چیزی رو پیدا نکردم
میخوام بدونم شما که در این عرصه کار کردید همچین موردا رو تو مقاله ها دیدید.؟
بیشتر مقالات میگم مثلا alexnet imageNET فلان ویژگی رو دارند ولی مراحل پیاده سازی لایه به لایه رو نگفتند
باید از HELP نرم افزار پیدا کنم.؟هنوز بین متلب و کافه استادمون مشخص نکرده و بیشتر اساتید کافه رو نمشناسند متاسفانه
خواهش میکنم .
شبکه که داستانش مشخصه ! من هنوز متوجه نمیشم شما گیر کارتون کجاست!
الکس نت صرفا همون LeNet5 هست که عمیق تر شده و دو سه تا نوآوری اضافه تر داشت. یکی استفاده از Relu یکی استفاده از local resonse normalization و یکی هم استفاده از دراپ اوت اگر اشتباه نکرده باشم که توضیح اینها تو مقالات اصلیشون که تو مقاله الکسنت رفرنس داده شده اومده.
بقیه معماری شبکه دقیقا همونه. یعنی شما چیز دیگه ای نیاز نداری بدونید و کافیه مشخصات لایه ها رو بدونید تا پشت سر هم اونا رو پیاده کنید (مثل اندازه کرنل و…) البته اگه شیوه پیاده سازی و یا نمونه پیاده سازی الکس نت بطور خاص مد نظر باشه خود الکس کریژوسکی cuda-convnet که همون کد و پیاده سازی مقاله اس رو منتشر کرد همون موقع (https://code.google.com/p/cuda-convnet/ )
برای مقاله های دیگه هم هرچی باشه (اگه مقاله معتبر باشه) اطلاعات مقاله معمولا کافی هست و اگر هم احیانا نباشه پیاده سازی ازش ارائه میکنن. اینم بگم بعنوان مثال که بچ نورمالیزیشن گوگل وقتی اومده بود محققا مشکل داشتن با پیاده سازیش تا اینکه گوگل خودش یک سمپل داد و با توضیحات بیشتر مرتفع شد.
نکته اخر هم تو دیپ لرنینگ سراغ متلب تا میتونید نرید متلب زیاد فعال نیست تو این زمینه (البته تو زمینه شبکه کانولوشن رپر متلب برای کفی هست از طرفی تولباکس خیلی خوب مت کانونت هم هست ولی همین و بس برای زمینه های دیگه ، دیگه خبری از تولباکس مناسب یا رپر مناسب نیست)
ممنون .
من دارم درس دانشگاه استنفورد رو میخونم.هر چند هنوز به CNN نرسیدم.برای استفاده از این تولباکس ها نیاز به دونستن تئوری نیست ولی فکر کنم برای طراحی شبکه که بتونه کار خاصی رو انجام بده نیاز هست؟
برای استفاده از caffe باید سی پلاس پلاسم رو تقویت کنم؟
ببخشید سوالات پراکنده هستند
سلام
برای اینکه بتونید کاری کنید تاکید میکنم حتما مبانی رو بخونید.
برای Caffe برای شروع نیازی به دونستن هیچ زبان برنامه نویسی ای ندارید میتونید از زبان اسکریپتی که خیلی سر راسته برای تعریف معماری شبکه و پاراترهای مختلف اون استفاده کنید
و یک شبکه رو براحتی آموزش بدید و تست کنید.
برای کارهای پیچیده تر که لازمه اش برنامه نویسی هست میتونید از زبان برنامه نویسی مثل سی++ و پایتون و یا متلب (پیشنهاد نمیکنم) میتونید ازش استفاده کنید.
از همه زحماتتون ممنون.
اجرکم عندالله
خواهش میکنم .
در پناه خدا انشاالله همیشه موفق و سربلند باشید
التماس دعا
با سلام و درود خدمت شما
اولا به خاطر حسن انتخابتون در مطالبی که ارائه فرمودین و زمانی که در پاسخ گویی به نظرات لحاظ می فرمایید بسیار سپاسگذارم.
دوما سوالی که از خدمتتون داشتم این که برای استخراج بهترین ویژگیهای یک تصویر که به صورت دقیق توصیف کننده ی آن تصویر باشه از بین انواع شبکه هایی که معرفی فرمودین به نظر خودتون کدوم عملکرد بهتری خواهد داشت؟
و اینکه آیا لازم است برای افزایش کارایی هر شبکه تغیراتی مثل تغییر الگوریتم یا تعداد لایه ها لحاظ کنیم یا پیشفرضهایی که در طراحی هر شبکه بیان شده است مناسب و دقیق عمل می کنند.
با سپاس
سلام .
خواهش میکنم.
معماری های مختلفی اومدن که هرکدوم محسنات/معایب خودشون رو دارن .
در ساده ترین شکل، معماری ResNet معماری خوبی هست. البته معماری جدید WRN یا wide residual network هم اومده که کارایی بهتری از اون داره. قبل از wrn هم stochastic depth که ورژن دیگه ای از ResNet هست که کارایی اون رو خیلی خوب کرد که البته از wrn بهتر نیست.
بعد از اینا DenseNet اومده . و بین اینها باز معماری های دیگه ای هست که هر کدوم ویژگی های خاص خودشونو دارن .مثلا یکی تعداد پارامترهاش کمتر دقت خوبی میده یکی تعداد پارامترش زیاده ولی دقتش بالاتره و….(من اگه خدا بخواد تا یکی دو هفته دیگه انشاالله یه مطلب در این باره میزارم تو سایت)
به غیر از اینها شبکه های spatial transformer, soft/hard attention ها هم خوبن که بهتره نگاه کنید به مقاله هاشون . لکچر ۱۳ دانشگاه استنفورد در این باره یکسری مطلب میگه که ببینید بدردتون میخوره
در مورد تغییر ، بله معمول هست . ولی معمولا اول با یه معماری پایه تست میکنن هرچی بدست اومد رو میبینن و بعد شروع به تغییر بخشای مختلف میکنن تا بتونن بهترین نتیجه رو با توجه به دیتاست خودشون بگیرن .
(برای حل این مشکل, یک تابع هدف یادگیری شباهت (similarity learning objective function) ارائه شد تا بعنوان تابع خطا (loss function) بدون برچسب کلاسها مورد استفاده قرار بگیرد. (۵۱). بنابر این اینطور, عمل backpropagation بصورت معمولی کار کرده و مدل هم میتواند لایه به لایه تصحیح شود. (بهتر شود) ) .
سلام .
در مورد این بخش ، اگر داده های جدیدی که داشتیم لیبل داشتند که دیگه لازم نیست similarity learning استفاده بشه درسته ؟
سلام
بله اگه داده لیبل گذاری شده به اندازه کافی هست نیاز به این کار نیست .
با سلام و احترام. ممنون از زحماتتون. می شه در مورد learning multiple levels of representation یه توضیحی بدید. ممنونم.
سلام
فکر کنم دوتا پست اول سایت رو بخونید متوجه بشید .
اگر نشدید بفرمایید تا من یه توضیحی بدم
من اين متن رو تازه خوندم البته فقط قسمت cnn رو… واقعا عالي و جامع بود
فقط يك نكته كوچك كه ورودي تصاوير AlexNet بايد سايز ٢٢٧ داشته باشه نه ٢٢٤ هرچند تو مقاله اصلي هم خورده ٢٢٤ ولي با سايز خروجي در نمياد. اين مطلب رو از آموزش استنفورد ميگم و براي جلوگيري از سردرگمي فك ميكنم مفيده
سلام
فرمایش شما درسته .
دلیل اینکه اینجا هم ۲۲۴ اومده فقط بخاطر بحث رفرنس به مقالات و حفظ امانتداری هست وگرنه بعنوان مثال در همه مثالهای caffe,tensorflow,… اندازه ۲۲۷ استفاده شده و میشه
و باز اگر هم کسی سوالی براش پیش میومد براحتی با یه پرسش در کامنت یا سایت پرسش و پاسخ به جواب مورد نظرش میرسید.
به هر حال نکته خوبی رو اشاره کردید و خوب شد که تو نظرات هم قرار گرفت خیلی ممنون 🙂
سلام
اگر ممکنه نحوه نصب تنسورفلو رو هم در سایت قرار دهید
ممنون
سلام
نصب تنسورفلو که خیلی سر راست و بی دردسر هست !
باشه انشاالله تا انتهای هفته یک آموزش قدم به قدم از اون رو در سایت قرار میدم.
(فقط اگر تا دو سه روز اینده دیدید خبری نشد حتما دوباره یاداوری کنید بهم!)
ممنون از انتشار مطالب
میشه لطف کنید و بگید فرق استخراج ویزگی با یادگیری ویژگی چیه؟با مثال و نمونه ممنون لینک دانشگاه استنفورد هم بذارید ممنون میشم
سلام
اینجا رو مطالعه کنید فکر کنم جوابتون رو بگیرید اگر نگرفتید باز بفرمایید
اگه کورس نوت دانشگاه استنفورد منظورتونه اینجاس (از بخش منابع یادگیری هم میتونستید ببینید)
سلام
در متن بالا که مطالعه می کنم
مطالبی با اندیس داخل پرانتز بیان شده
که هیچی در موردش نیست
مثل Transferred learning(32)
میشه راهنمائی کنید ارجاع به چیه ؟؟؟
سلام اونها ارجاعات به مقاله اصلی هستن . بطور خاص اشاره به این مقاله میکنه : Learning and transferring mid-level image representations using convolutional neural networks
متاسفانه لیست ارجاعات پایین مربوط به این نسخه از متن نیست مربوط به یک ورژن جدیدتر هست اشتباها من چند ماه پیش طی یک اپدیت قرار دادم. برای همین همخوانی نداره .
انشاالله اگه فراموش نکردم این بخش رو با ارجاعات مربوط به همین نسخه بروز میکنم بزودی
———–
آپدیت :
لیست ارجاعات رو تصحیح کردم . میتونید استفاده کنید
خیلی ممنون از زحماتتون برای جمع آوری و انتشار این مطالب،
اینم ی سورس خوب از RBM ها که جاش توی مطالب خالی بود ( البته شاید جایی بوده توی سایت و من ندیدم!) به هر حال اینم خیلی روونه و امیدوارم به دوستان کمک کنه: https://deeplearning4j.org/restrictedboltzmannmachine
کل مطلب هم از این قرار هست که ی RBM مثل یه شبکه ی feed forward درنظر گرفته میشه، منتها بدون لایه ی خروجی.
۱٫ وردوی به شبکه داده میشه،
۲٫ یک خروجی توسط تابع فعال ساز ساخته میشه،
۳٫بعد این خروجی داده میشه به لایه ی ورودی ، اختلافش با لایه ی ورودی به عنوان خطا در نظرگرفته میشه ،
۴٫ این خطا برای ابدیت وزن ها استفاده میشه، ( در واقع مثل autoencoder میمونه)
۵٫ این کار تا زمانی ادامه پیدا میکنه که خطا از ی حدی پایین تر بیاد.
[…] های یادگیری عمیق[۱] زیرمجموعه ای از الگوریتم های یادگیری ماشین هستند که […]
[…] بینایی [۳] همانند دسته بندی تصاویر,[۴] شناسایی اشیاء[۵], استخراج تصاویر[۶], قطعه بندی معنایی[۷] و برآورد ژست […]
[…] های یادگیری عمیق[۱] زیرمجموعه ای از الگوریتم های یادگیری ماشین هستند که […]
باسلام از اطلاعات خوبتون
میشه لطفا درباره l1 و l2 بیشتر توضیح بدید و اینکه ایا مختص یادگیری عمیق هستند یا اینکه در شبکه عصبی هم استفاده میشن؟
فاصله L1 و L2 منظور شماست ؟ چه توضیحی مد نظر شماست ؟
نه مختص یادگیری عمیق نیستند . فکر میکنم تو کامنتا یا در بخش پرسش و پاسخ قبلا به یک سوال مشابه جواب دادم . لطفا چک کنید.
سلام
ممنون از لطفتون بابت این مطلب عالی
زنده باشید
سلام دوست عزیز
بابت مطالبی که رایگان در اختیار دیگران قرار میدید ممنونم.
از شما یه راهنمایی میخواستم اونم اینه که من به حوزه بینایی ماشین علاقه دارم به همین دلیل مشغول یادگیری بودم که متوجه شدم که بینایی ماشین زیر شاخه هوش مصنوعی است و برای اینکه بتوانم تخصصی کار کنم بایستی یادگیری ماشین و یادگیری عمیق رو هم آموزش ببینم.
ودر حین یادگیری این دروس متوجه شدم بایستی طراحی الگوریتم و ساختمان داده را هم تسلط داشته باشم که بتوانم الگوریتم های بینایی ماشین رو طراحی کنم.
حالا میخواستم بدونم آیا این مسیری که من دارم می رم برای بینایی ماشین صحیح هست یا نه?
در ضمن اگر مطالب دیگری هم هست که باید آموزش ببینم ممنون میشم راهنمایی کنید.
در ضمن رشته تحصیلی من برق است
سلام .
طراحی الگوریتم و ساختمان داده رو میتونید بصورت موردی بخونید و برید جلو که وقت زیادی از دست ندید. هرجا یک مفهوم دیدید که نمیدونید چیه میتونید سرچ کنید بعد تعمیق کنید یا از بقیه سوال کنید راهنماییتون کننن.
استارت کار رو اول با یک کورس ماشین لرنینگ بزنید مثل کورس اندرو ان جی در کورس ایرا تا ایده اولیه بگیرید و با مبانی اشنا بشید
بعد یک کورس بینایی ماشین رو ببینید مثلا کورس جورجیا تک که تو بخش منابع یادگیری معرفی کردیم میتونه خوب باشه.
بعد میتونید یک کورس یادگیری دیپ لرنینگ رو ببینید اموزش اندرو ان جی در کورس ایرا هم خوبه ولی اموزش دانشگاه استنفورد هم خیلی خوبه .
بعد برای تعمیق میتونید حالا یک کتاب مرجع یادگیری ماشین و بینایی ماشین و یا دیپ لرنینگ بگیرید و تعمیق کنید اطلاعاتتون رو.
اگه بخوایید پیش نیازی اینطور برید جلو که اول طراحی الگوریتم بعد ساختمان داده و… خوبه ولی وقت و زمان زیادی میگیره از شما مگه اینکه بصورت سطح بالا بخونید ایده های کلی بیاد دستتون و پیش برید و وارد جزییات نشید در گام اول
در گام های بعدی بصورت عمقی میتونید مفاهیم مختلفی که بکارتون میاد رو مطالعه کنید ولی اول سطحی و برای اشنایی با مفاهیم بخونید تا سریعتر پیش برید .
سلام
خیلی ممنون از پاسخ تون واقعا بهم کمک کرد.
امیدوارم همیشه موفق باشید.
سلام آقای مهندس، وقتتون بخیر
یه سوال کلی تو حوزه کاربرد CNN برای segmentation دارم و اون اینه که آیا روشهای ارائه شده با CNN ها برای segmentation با نظارت هستند و داده های label خورده را استفاده می کنند یا خیر مثلاً شبکه های fcn-crf based بدون هیچ نظارتی و درواقع بدون وجود هیچ نگاشت یا ماسک باینری متناظر با تصویر تحت آموزش آنقدر ویژگی در سطوح مختلف استخراج می کنند که شبکه خودش اطلاعات معنایی و محلی را ادغام کرده و می تواند آموزش ببیند؟
با توجه به اینکه شما در دسته بندی و معرفی CNN ها در مقابل سایر deep neural network ها فرمودید CNN ها بدون نظارت نیستند و استراتژی های ارائه شده برای کاربرد segmentation را به نحو بسیار خوبی به سه category تقسیم کردید که آخرین category از آنها semi supervised می باشد. میخواستم بدونم استراتژی های fcn-crf based یا detection based با نظارت هستند و لزوماً هر تصویر برای آموزش یک تصویر متناظر annotate شده در حد پیکسل دریافت می کند یا خیر؟
هدف خودم اسفاده از CNN ها برای segmentation در تصاویر پزشکی است که دیتابیس مد نظر تصاویر متناظر annoatete شده ندارد.
۲ نکته مهم در ارتباط با کاربردی که مد نظر دارم این است که:
اولاً من نمیخواهم مثل semantic segmentation بر روی دیتاست PASCAL Context تصویر به مثلا ۴ قسمت فرد، آسمان، اسب، علف تقسیم شده و ماهیت هر قسمت مشخص شود که چیست، بلکه فقط به سه بخش cluster شدن تصویر کفایت میکند و لازم نیست ۲۰ category از اول تعریف کنم و لزوما هر ناحیه برچسب یکی از آنها را دریافت کند.
دوماً segmentation را به عنوان یک بخش میانی در کارم استفاده خواهم کرد و نیازی به سنجیده شدن دقت segmentation ام ندارم که لزوم وجود تصاویر annotate شده برای کارم احساس شود.
با توجه به مواردی که ذکر کردم، به نطر جنابعالی راه کارهای کدام پژوهش ها قابل استفاده است و اگر هیچ کدام، با توجه به داده هایی که موجود دارم و استفاده ای که از segmentation دارم، چطور میتونم CNN هایی که برای کاربرد cassification ارائه شده اند برای task خودم که cluster کردن تصویر به سه بافت مختلف است استفاده کنم؟
ممنون و سپاسگزارم
سلام
من در سگمنتیشن تخصص ندارم و زمان خیلی زیادی هم از وقتی که یکسری مطالعه اولیه رو این موضوع داشتم میگذره با این حال
در مورد سوال اولی که کردید تو بحث fcn-crf دیتا لیبل دار هست(یعنی اون ground truth mask وجود داره) و بعد با crf نتیجه بدست اومده بهبود میدن.
اینکه سگمنتیشن قراره انجام بدید اما دقتش براتون مهم نیست یکم گیج کننده اس. سگمنتیشن مگر قرار نیست نواحی مورد نظر شما رو بشما ارائه کنه؟ خب این بحث اگه بخوبی انجام نشه در ادامه پایپ لاین احتمالی شما به مشکل میخورید!
اینکه بدون داشتن ماسکهای مورد نظر و انوتیت کردن سگمنتیشن انجام بدید بعنوان مثال شدن میشه مثلا یک مدل ساده رو برای دسته بندی ترین کنید بعد با جریان گرادیان یا با چک فیچرها به یک دیتکتورهایی که هرکدوم به یک بخش حساسیت نشون میدن برسید و نهایتا از اونها مثل چیزی که در ورکشاپ گفتیم برای مشخص کردن نواحی استفاده کنید ولی این خیلی مشکلات مختلف داره اولین و مهمترینش اینه که دقیق نیست و دومیش هم اینه که مدل شما در درجه اول باید بخوبی کار کنه و دقت تشخیص عالی داشته باشه تا نتایج نسبتا قابل استفاده ای ارائه بده به این شکل. که این بنظر میاد با بحث اصلی شما کاملا در تضاد هست (شما سگمنتیشن رو به عنوان یک زیر بخشی برای بهبود نتیجه مدل میخوایید و نه به خودی خودش درسته؟ ). به غیر از این چون من خودم تو سگمنتیشن کار نکردم نمیدونم تو این مورد خاص چه کارهایی انجام شده و چه روشهایی پیشنهاد دادن .
من پیشنهاد میکنم اینجا(http://blog.qure.ai/notes/semantic-segmentation-deep-learning-review) و اینجا(https://meetshah1995.github.io/semantic-segmentation/deep-learning/pytorch/visdom/2017/06/01/semantic-segmentation-over-the-years.html) رو هم ببینید و با نویسنده ها ارتباط برقرار کنید بنظر میاد تو این زمینه تجربه خوبی داشته باشن و بطور خاص بتونن بخوبی کمکتون کنن .
علاوه بر اون یک مقاله مربوط به امسال هم هست که برای اون دید پایپ لاینی که قبلا صحبتش شد شاید بتونه ایده خوبی بشما بده اونو مطالعه کنید :
https://arxiv.org/abs/1710.05126 (البته خودم مطالعه نکردم متنش رو فقط ابسترکت گذرا دیدم)
علاوه بر اون حتما کارهای مرتبط این حوزه رو هم چک کنید تا اگر تکنیکی هست که بدرد شما میخوره پیدا و استفاده کنید و دیگه چرخ رو از اول اختراع نکنید یا در حالت دیگه ایده بگیرید و بحثی رو برای کار خودتون بهبود یا تغییر بدید .
این ریویو هم ببینید : https://link.springer.com/article/10.1007/s13735-017-0141-z
ضمنا در سایت سوال کردید ؟ اگر نه اینکارو بکنید بعضی از عزیزان روی سگمنتیشن کار کردن خیلی بهتر از من باید بتونن راهنماییتون کنن.
لطفا سایتهایی مثل Quora رو فراموش نکنید منبع بسیار عالی ای برای پرسش سوال هستن.
ببخشید که دیر جواب دادم چون تخصص نداشتم و مطالب سابقی هم که خونده بودم بیشترش فراموش شده باید یک مختصر جستجویی میکردم تا بتونم کمکی خدمت شما بکنم .
باز هم عرض میکنم حتما در کورا و امثالهم بپرسید تا در زمانتون صرفه جویی بشه
سلام
بسیار ممنونم از توضیحات خوبتون آقای مهندس.
منظورم از اینکه گفته بودم دقت segmentation برام مهم نیست این نبود که دقت پایین هم کفایت میکنه در واقع منظورم این بود که نداشتن ground truth mask ها هیچ مشکلی ایجاد نمیکنه، چون ماههیت اصلی مساله classification است و من قصد دارم به عنوان یک module و در واقع یک بخش اولیه از شبکه segmentation رو انجام بدم و نیازی نیست دقت را با معیارهایی مثل IOU و امثالهم بسنجم و از این لحاظ درگیر بررسی دقت segmentation نیستم و در واقع نمیتونم باشم. اما همونطور که فرمودید چون دقت بخش بندی در بقیه مراحل تأثیرگذار خواهد بود حتماً باید به این مساله توجه کنم که به فکر یک segmentation بر اساس ویژگی هایی که در بعضی از feature map ها به نظر میاد کارمو راه میندازن نباشم و نتایج segmentation بر اساس این ویژگی ها رو بررسی کنم که در صورت داشتن خطای واضح یا چنین ماجولی استفاده نکنم و تلاش کنم شبکه ای با لایه های مناسب برای classification task این موضوع پیشنهاد کنم یا اینکه دنبال متادیتا های دیگه ای برای بالا بردن دقت این ماجول مهم و همونطور که شما فرمودید زیربنای کار باشم.
از راهنمایی های مفیدی که فرمودید نهایت قدردانی را دارم.
سلام آقای مهندس
بخاطر سخنرانی خوب دیروزتون در کارگاه سپاسگزارم و ازتون میخوام منابع خوبی که برای locally connected layer میدونید معرفی بفرمایید.
خیلی ممنونم
سلام .
خواهش میکنم .
دقیقا چه چیزی رو میخوایید یاد بگیرید ؟ کلا ماهیت لوکالی کانکتد رو چی هست یا نه یک زمینه یا کاربرد خاص مدنظرتونه؟
سلام
آقای مهندس در واقع هر دو رو. اول اینکه من در مورد locally connected ها همونطور که شما قبلا در سایت نوشته بودید فقط اینو میدونم که یه چیزی بینابین fully connected ها و convolutional ها هستند اما ساز و کارشون رو آنطور که باید درک کنم کاملاً نمیدونم که اینجا چه اتفاقی می افتد و آیا عملیات کانولوشن انجام میشه یا نه اگر حسب تفاوت اسمیشون با کانولوشنی ها این عملیات هم انجام نمیشه پس اطلاعات موجود در یک همسایگی چطور مدیریت میشن و با چه عملیاتی دقیقا ویژگی ها مهندسی می شوند.
دوم اینکه میخوام بدونم برعکس cnn ها که translation invariance هستند، این خاصیت چقدر در این لایه ها وجود ندارد، در واقع آیا این لایه ها میتونن به مکان object ها در تصویر هم بسیار حساس باشند مثل face که با جنابعالی صحبت کردیم و در حد ویژگی های پایه ای مثل لبه ها، به مکان نیز حساس باشند و آن را نیز آموزش ببینند.
از توضیحات خوبتون ممنون خواهم بود. در صورتی که مقالات و منابع خوبی برای مطالعه این موضوع نیز معرفی بفرمایید ممنون میشم.
سپاسگزارم
سلام
ایده لوکالی کانکتد ترکیب این دو هست . یعنی در فولی کانکتد ما اصلا همسایگی معنا نداره اما در کانولوشن دیدیم که در نظر گرفتن همسایگی چقدر میتونه مفید باشه در بدست دادن ویژگی های محلی خوب.
حالا گفتن خب این بحث همسایگی رو بدون ویت شرینگ لحاظ کنیم .
نتیجه میشه لوکالی کانکتد لیر که مثل کانولوشن هست با این تفاوت که در هر ناحیه ورودی ما یک مجموعه فیلتر جداگانه لحاظ میکنیم (قبلا یک فیلتر همه جا لحاظ میشد در ورودی ، روی پچ های مختلف، اینجا هر پچ متفاوت هست )
برای همین مجموعه فیلترهای مختلف روی بخشها و نواحی مختلف ورودی لحاظ میشه و ایده اینه که هر بخشی متفاوت از بخشای دیگه هست و در یک موقعیت خاص باید دنبال یکسری ویژگی بود نه همه جا.
در بحث صورت هم ایده اینه وقتی تصاویر وسط چین داشته باشیم (از صورت افراد _ یعنی دیتای ما همه به این فرمت هست (مثل عکس پرسنلی مثلا)) اونوقت میشه از لوکالی کانکتد استفاده کرد که هرکدوم یک بخشی از صورت رو تجزیه تحلیل کنن و ویژگی های خاص هر بخش رو ارائه بدن . در زمان تست هم چون تصاویر همین فرم رو دارن و تغییر خاصی ندارن مثلا ویژگی های پایین تصویر لب و چونه و… رو بدست میدن مثلا در وسط تصویر بینی لحاظ میشه و در طرفین هم گوش و چشم ها. و نیازی نیست که مثلا برای گوش در پایین یا وسط یا بالای تصویر دنبال چیزی باشیم . هر بخش ثابت هست.
برای کار شما هم البته بنظر میاد اینطور نیست که صرفا از ابتدا نیاز به استفاده از لوکالی کانکتد داشته باشید. میتونید بعوان مثال چند لایه کانولوشن در ابتدای معماری داشته باشید تا ویژگی های سطح پایین و میانه رو بدست بدن بعد به لوکالی کانکتد رو بیارید و سعی کنید یکسری فیلترهای سطح بالاتر که وابسته به مکان هستن رو توسعه بدید.
باید تست کنید ببینید اینطور نتیجه بهتری میگیرید یا خیر (از نظر تئوری این کار بهینه تره چون به هر صورت نیاز به یکسری ویژگی های پایه حداقل نیاز دارید که ویژگی های سطح بالاتر با توجه به اونها توسعه پیدا میکنن و اشتراک اونها مشکلی ایجاد نمیکنه و همگرایی رو باید تسریع کنه و لی اینکه حدش چقدر باشه خوب نیاز به بحث و تست داره)
در مورد مقالات واقعیتش لوکالی کانکتدها زیاد مرسوم نیستن (حداقل تو حوزه ای که من کار کردم و بیشتر درگیرش بودم) من هم ندیدم زیاد استفاده بشن. ولی بنظرم اگه کتاب دیپ لرنینگ ایان گودفیلو رو بخونید تو فصل نهم اگر اشتباه نکرده باشم که در مورد کانولوشن و مکس پولینگ و امثالهم صحبت میکنه بنظرم میاد در مورد طراحهای دیگه مثل لوکالی کانکتد لیر هم بحث میکرد بخونید خوبه .
مدل از پیش ترین شده با لوکالی کانکتد لیر من ندیدم و بعیده برای ایمیج نت وجود داشته باشه
در ارتباط با سوال قبلیم هم متوجه شدم که کارهایی که تو حوزه segmentation با cnn ها انجام شدند همه ground truth mask رو دارن و supervised learning هستند، اما من دنبال روشی برای unsupervised clustering/segmentation هستم برای داده هایی که فقط میخوام به سه کلاستر تقسیم بشن و در همه داده ها هر سه کلاستر حضور دارند و علاوه بر آن anomaly وجود ندارد و در واقع هدفم جایگزینی کلاسترینگ هاو سگمنتیشن های traditional با deep هست که با احتمال بالا intensity inhomogenity را نیز آموزش ببینند و نتایج خوبی را در اختیار قرار دهند.
بله بنظر اینطور میاد ولی حتما از عزیزانی که کار کردن پرس و جو کنید
دوتا لینک پایین خوبن علاوه بر اون از بخش منابع یادگیری سایت یک لینک به مقالات مطرح در هر بخش داده شده اونجا رو ببینید و برید به github repository کسی که شر کرده مطالب رو و ببینید ایا اطلاعی در این زمینه داره یا نه (بطور خاص درمورد سگمنتیشن)
و این بحث رو مطرح کنید و مطمئن بشید .
خیلی سریع و سرسری چیزی رو بعنوان تمام شده در نظر نگیرید . حتما اول تا میتونید فاز تحقیق اولیه رو کامل و با دقت تمام انجام بدید که بعد که استارت زدید دچار اما و اگر نشید یا ببینید بعدا روش سریعتر و بهتری بوده و شما انتخابش نکردید.
بعنوان مثال با یک سرچ ساده در arxiv-sanity میتونید نمونه های انجام شده بصورت unsupervised رو ببینید : کلیک کنید و بعد بیشتر دقیق بشید و ببینید چه استفاده ای میتونید بکنید. اگر چیزی مستقیما نتونستید ازش در بیارید میتونید به محققان و نویسنده های بعضی مقالات ایمیل بدید و سوالتون رو مطرح کنید و راهنمایی بگیرید (جهت دهی ، مسیر، راهنمایی …)
اینها همه کارها و قدمهایی هست که “باید” انجام بدید قبل از اینکه یک طرحی رو پیاده کنید. هرچقدر این فاز رو دقیقتر و کاملتر انجام بدید میتونید مطمئن باشید کیفیت کار شما به مراتب خیلی عالی تر خواهد بود و همینطور راحت تر به مقصد میرسید.
سلام
بسیار ممنونم آقای مهندس، عالی بود جوابهاتون. توضیحات فوق العاده شما خیلی کمکم میکنه. ضمن اینکه من مقدمات دیپ لرنینگ رو هم علاوه بر خوندن مقالات متعدد با کمک سایت خوب شما یادگرفتم که جا داره اینجا باز هم از جنابعالی تشکر کنم. بسیار مفید بود صحبتهاتون، در مورد راهنمایی هاتون هم در ارتباط با تحقیقات قبل انتخاب روش و طراحی شبکه مورد نظرم ممنونم.
با آرزوی موفقیت روزافزون برای شما
سلام
خواهش میکنم . امیدوارم در پناه خداوند همیشه موفق و سربلند باشید
با سلام
آقای مهندس لطف می کنید مبحث surrogate classes رو در data augmentation یه کم بیشتر بهمون توضیح بدید که ساز و کارش چیه؟
ممنون
سلام . نکته خاصی نداره بحثش اینه که در ترینینگ بیایید از تصاویر ورودی یکسری patch تهیه کنید و اونها رو تحت ترنسفورمیشن های مختلف به شبکه ارائه کنید و اینطور شبکه فیچرهای invariant بهتر یادبگیره. نکته اش اینه که patch ها حتما باید حاوی شی(کلاس) یا بخشی از یک کلاس باشن.و قرار نیست رندوم رندوم باشن مثلا در یک تصویر که یک سگ وجود داره اون سگ یا بخشی از اون در پچ باید باشه قرار نیست بره یه پچ ازچمن ورداره مثلا. همین (یعنی اون پچ رو ببینید کلاس مورد نظر یا بخشی از اون مشخصه پچ خیلی کوچیک نیست که ادم فرض کنه یک تکه رندوم انتخاب شده بی حساب و کتاب مقاله رو بخونید مشخصه کاملا)
بعد هم در مقاله یکسری توضیحات تکمیلی در این مورد میدن که مثلا ما برای فلان دیتاست چه تعداد استفاده کردیم و دقت چه شد و از این بحثها
اصل مقاله خیلی قبلتر در مورد unsupervised learning بود تا یکسری ویژگی مناسب بدست بده بعدا اومدن سوپروایزدش رو هم با سی ان ان ارائه کردن.
اون مقالاتی که رفرنس داده شده رو بخونید مشخصه همه چی.
سلام
خیلی ممنون از توضیحات خوبتون
منظور جنابعالی این مقاله هست؟
Unsupervised feature learning by augmenting single images
ان شاالله همیشه موفق باشید.
سلام.
بله
ممنون.
سلام. تشکر از اطلاعات مفید شما. من میالم در متن پایان نامه به این نوشته ها ارجاع دهم ، چه منبعی را ذکر کنیم؟
اینها برداشته شده از پایان نامه بنده اس میتونید هم به اون ارجاع بدید هم به رفرنسایی که زده شده ارجاع بدید یا به اصل مقاله (Deep learning for visual understanding: A review) ارجاع بدید.
با سلام
ببخشید آقای حسن پور، توابع loss function مثل soft max در بک پراپ کاربرد دارند؟ در واقع میخوام بدونم بعد از عمل دسته بندی توسط لایه یا لایه های fc نتایج با برچسب های واقعی در حین training مقایسه که میشن و نتیجه به عنوان خطا به سیستم فیدبک داده میشه، توابع هزینه در واقع فرمول محاسبه همین خطا هستند یا برداشت من اشتباه است؟
سلام
توابع هزینه ورودی رو از اخرین لایه دریافت میکنن و بعد یک خطایی بدست میاد (بسته به ماهیت مساله فرم تابع خطا متفاوت هست ) و بعد این خطا توسط الگوریتم بک پراپگیشن در شبکه اعمال میشه (هر پارامتر به نسبت میزان تاثیر در خروجی تنظیم میشه)
سلام
ممنونم از شما
سلام
آقای مهندس عذرخواهی میکنم میشه در مورد کانولوشن ۱*۱ تو معماری googlenet توضیح بدید؟ عملکرد این فیلتر معادل یک عدد اسکالر به چه شکلی است؟
کانولوشن های موجود در شبکه های عصبی کانولوشنی فقط تو حوزه مکان اعمال میشن یعنی فیلترهای کانولوشن تو حوزه spatial می لغزن فقط و عملیات ضرب نقطه ای انجام میشه یا در عمق توده ورودی هم هر کدام از فیلترها کانوالو میشن و هر کدام یک feature map جدید حاصل میکنن؟ منظور از فیلترهای ۳*۵*۵ چیست؟ یعنی کانولوشن سه بعدی با فیلترهای سه بعدی رو توده های سه بعدی ورودی انجام میشه؟
سلام
عملیات کانولوشن معمولی روی تک تک کامالهای ورودی اعمال میشه
وقتی شما مینویسید ۵x5x3 یعنی . سه فیلتر ۵×۵ دارید که هر کدوم از این فیلترها بر تمام فیچرمپهای ورودی اعمال میشن
یعنی اگه شما ۱۰ تا فیچرمپ ورودی داشته باشید . هر فیلتر عینا روی ۱۰ فیچرمپ اعمال میشه و بعد نتایج اونها با هم ترکیب میشه . و خروجی میشه یه فیچرمپ
در انتها هم خروجی این ۵x5x3 3 تا فیچرمپ هست
کانولوشن ۱در۱ هم مثل کانولوشن معمولی هست با این تفاوت که ابعادش ۱×۱ ئه. کماکان مثل قبل بر روی تمامی کانالها اعمال میشه و نتایج ترکیب میشن.
اگه توضیح بیشتری نیازه دقیقتر سوالتون رو مطرح کنید
مممنون از توضیحاتتون آقای مهندس
آقای مهندس میشه مفهوم depthwise separable convolution را در مقابل pointwise separable convolution برامون توضیح بدید؟
خیلی ممنونم
سلام
depthwise separable convolution کاری که میکنه اینه هر فیلتر بصورت جداگانه روی یک کانال اعمال میشه ولی نتایج ترکیب نمیشن . الان مال n تا فیچرمپ جداگانه داریم که فیلتر روی اونها اعمال شده .
در گام بعدی برای ترکیب اونها ما از یک کانولوشن ۱در۱ استفاده میکنیم.میشه اینجا هر فیلتر روی چند کانال هم اعمال بشه ولی نرمش اینه که هر فیلتر روی یک کانال اعمال بشه.
من در یک پست جداگانه سعی میکنم اینو کامل توضیح بدم انشاءالله.
(البته اگه مقاله اصلی رو بخونید و همینطور اسلایدی که خدمتتون هست باید همه چیز مشخص باشه براتون)
سلام
متشکرم از توضیحاتتون.
آقای مهندس من با توجه به اسلایدهای جنابعالی این مطلب رو اینطور متوجه شدم که برای کاهش پارامترها بعد از اعمال هر فیلتر به تک تک کانال ها، برعکس حالت معمولی که با هم نتایج ترکیب (جمع) می شوند، اینجا با یک کانولوشن ۱*۱ اقدام به ترکیب نتایج حاصل از کانوالو فیلتر و کانال ها می کند.
اما سوالی که با توجه به توضیحات اخیر شما پیش میاد اینه که فرمودید نرمش اینه که هر فیلتر روی یک کانال اعمال بشه، اگر منظورتون اینه که هر کدوم از فیلترهای لایه اخیرمون روی یکی از کانال ها یا فیچرمپ های قبلی اعمال میشن، که با عملکرد لایه های کانولوشنی که تا کنون آشنا شدیم (هر فیلتر روی همه کانال ها اعما و نتایج ترکیب شده به عنوان خروجی اون فیلتر و به همین ترتیب فیلتر دوم روی همه کانال ها و…) همخونی نداره، لطف می کنید توضیح کوتاهی بدید؟
ممنون
سلام
بله درسته . این یک حالت خاص از حالت نرمال هست که در اون اصطلاحا میگیم depth multiplier برابر ۱ هست . یعنی هر فیچرمپ در یک کانال (با عمق ۱ ) کانوالو میشه. اما در حالت نرمال و طبیعی ما depth multiplier برابر تعداد کانالهاس یعنی هر فیلتر بر روی تمامی کانلها اعمال میشه.
در اسلاید و ارائه ما چیزی که در مقاله موبایل نت اومده بود رو توضیح دادیم و اون حالت depth multiplier مساوی ۱ رو دیدیم . (هر فیلتر رو یک کانال ورودی اعمال میشه) حالات دیگه ای هم هست یعنی میتونید مشخص کنید مثلا هر فیلتر روی n کانال اعمال میشه.
و با مشخص کردن n میتونید تقریبا یک حد وسطی بین این دو انتخاب کنید اگر دلتون بخواد.
و در ادامه هم میبنید که که با کانولوشن ۱در۱ (یا همون pointwise convolution) دوباره مثل چیزی که در حالت نرمال داریم عمل میشه (هر فیلتر روی تمامی کانالهای وروی اعمال میشه) که نهایتا همونطور که قبلا اشاره شد ، میبینیم یک عملیات در دو مرحله پیاده سازی شده و با محدود سازی عمق در بخش اول سربار به طرز چشم گیری کاهش پیدا میکنه.
من بعد از پست بچ نرمالیزیشن انشاءالله به این مبحث میپردازم و سعی میکنم یک توضیح مفصل در این باره بدم تا نکات مبهم و یا گیج کننده (اگر وجود داشته باشه) برطرف بشه.
خیلی ممنون آقای حسن پور
اگه اجازه بدید اون چیزی که از توضیحاتتون متوجه شدم را با یه مثال بیان کنم تا شما بفرمایید که درست است یا مرحله آخر را برای محدودسازی عمق درست متوجه نشده ام.
در نظر بگیریم ۶ کانال یا فیچرمپ در ورودی یک لایه داریم و ۳ فیلتر میخواییم به اونها اعمال بشه، در حالت استاندارد هر کدام از فیلترها به همه کانال ها اعمال میشد و نتایج ترکیب میشد و در نتیجه خروجی لایه ۳ فیچرمپ در اثر اعمال سه فیلتر به تمامی کانال ها بو، اما در حالت محدود سازی عمق با در نظر گرفتن یه حد وسط که فرمودید، هر یک از سه فیلتر به ۲ کانال اعمال میشن و نتیجه هر فیلتر با دو کانال ترکیب (جمع) میشه و سپس مجدداً ۳ نگاشت خروجی تحت تاثیر یک عملیات کانولوشن یک در یک به یک فیچر مپ تبدیل میشن و به این ترتیب تاثیر فیلتری که فقط بر روی دو کانال اعمال شده بود بر روی نتایج کانال های دیگر هم در مرحله دوم اعمال خواهد شد، ضمن اینکه در نهایت (در این مثال) عمق این لایه را به نسبت ۱ به ۳ کاهش داده ایم. درسته؟!
سلام.
تقریبا بزارید بیشتر توضیح بدم :
حالتی که شما ازش اسم بردید به group convolution هم معروف هست و بله به این شکل کار میشه (با این تفاوت که در این بحث ما معمولا دیگه از لایه کانولوشن ۱در۱ در انتها استفاده نمیکنیم. ایده اینجا اینه که تعداد کانال ورودی رو به دسته هایی تقسیم کنیم و هر دسته رو به یک فیلتر بدیم) و ما اینو در الکس نت هم داشتیم.
در ایده depthwise separable convolution اما ایده کاهش سربار پردازشیه. و چیزی که این سربار رو باعث میشه اینه که یک فیلتر داره روی تمام کانالهای ورودی اعمال میشه.
و اگه اندازه اون فیلتر بزرگ باشه و تعداد اون فیلترها هم زیاد سربار خیلی زیاد میشه.
حالا اینها یک فرض رو بهش پرداختن . گفتن ما برخلاف قبل میاییم یک محدودیتی رو اعمال میکنیم. هر کانال یک فیلتر خاص خودشو داشته باشه. همین
بعد برای اینکه ترکیب این فیلترها رو هم داشته باشیم از یک فیلتر دیگه (کانولوشن یک در یک) استفاده میکنیم و این بار خیلی عادی هر فیلتر روی تمامی کانالها اعمال و نتایج ترکیب شده اونها رو بعنوان خروجی استفاده میکنیم .
این چیزی بود که بحث کردیم و میدونیم. تا اینجا میدونیم
که (اگه بر اساس مقاله موبایل نت بخواییم پیش بریم)
۱٫ پس تعداد فیلترهای ما در depthwise conv برابر با تعداد کانالهای ورودی میشه
۲٫بعد از اون هم از یک کانولوشن ۱در۱ استفاده میکنیم تا فیچرمپهایی که از مرحله ۱ بدست اومد رو با هم ترکیب کنیم (هر فیلتر روی تمامی فیچرمپها اعمال میشه و یک فیچرمپ جدید بدست میده و اینکار برای n فیلتر ما انجام میشه )
نتیجه ؟ ما بجای اینکه بیاییم این اعمال فیلترها رو توسط یک فیلتر بزرگتر انجام بدیم اون رو توسط یک فیلتر کوچکتر انجام دادیم . (یک فیلتر ۳×۳ رو شکوندیم به دو مرحله . مرحله اول اعمال ۳×۳ به ازای هر یک کانال ورودی . و در مرحله دوم اعمال ۱×۱ به ازای همه فیچرمپ ها)
اینطور سربار ما بشدت کاهش پیدا کرد و ما تونستیم مدل بزرگتری(نسبت به قبل) رو ترین کنیم و دقت بهتری بگیم .
اما سوال!
آیا این کاری که کردیم معادل واقعا اون چیزی هست که قبلا اتفاق می افتاد؟ بزارید مثال بزنیم
ما یک لایه کانولوشن جدید داریم . کرنل ۳×۳ و تعداد هم ۱۰ تا .
ورودی این لایه ما هم یک توده هست با ۲۰ فیچرمپ .
حالا سوال . آیا
(۳x3x20)10x
(یعنی هر فیلتر ۳در۳ در تمام ۲۰ فیچرمپ اعمال بشه ، و چون ۱۰ تا از این فیلترها داریم ۱۰ بار این کار تکرار بشه )
واقعا مساوی این چیزی هست که ما اینجا صحبتش رو کردیم ؟ یعنی ما اگه بیاییم بنویسیم
۳x3x20
یعنی ۲۰ تا فیلتر ۳در۳ (یعنی هر فیلتر دریک کانال اعمال شده)
و بعد بنویسیم
(۱x1x20)10x
یعنی فیلتر ۱در۱ درتمام ورودی ضرب بشه و چون ۱۰ تا از این فیلترها داریم این کار ۱۰ بار تکرار بشه .
آیا واقعا اینا یک کارو دارن انجام میدن ؟
وقتی به فرمت ضربها نگاه میکنیم . میگیم خب بنظر اینطور میاد بجای اینکه ضرب رو در اندازه فیلتر بزرگتر کنیم رفتیم روی اندازه فیلتر ۱در۱ کردیم و البته اونجا هم همه کانالهای ورودی رو لحاظ کردیم . پس فرقی نباید داشته باشن. اما واقعا اینطور نیست. واقعا اینها یک کار رو انجام نمیدن . در مورد اول هر فیلتر بطور جداگانه روی تمام کانالها اعمال میشه و اون بحث همسایگی لحاظ میشه و اگر ارتباطی وجود داشته باشه شکل میگیره . اما در حالت دوم اینطور نیست.اینجا ما ترکیب انواع مختلف فیلترها رو داریم (در حالت اول ما رپرزنتشن حاصلمون ترکیب اعمال فیلتر روی تمامی کانالها بود یعدی دید ما روی تمام توده ورودی از منظر فیلتر ما بود. اما اینجا در حالت دوم ما رپرزنتشن حاصلمون از ترکیب دیدهای مختلف روی بخشهای مختلف توده ورودی هست)
تا اینجای بحث چیزی که داشتیم مرتبط با معماری موبایل نت و بحثی که اونها کردن بود. اونها ایده ای که بالا مطرح کردیم رو عنوان کردنو گفتن خوبه.
حالا اگه بخواییم اصطلاحا این گپ بین دو حالت (استاندارد و depthwise ) رو کاهش بدیم چیکار میتونیم بکنیم ؟
میشه بجای اینکه هر فیلتر به یک کانال نگاه بکنه به مجموعه ای از این کانالها نگاه کنه. و بعد ادامه رو بریم .
اینجا هم باز دو راه پیش میاد
۱٫ تعمیم این روش به روشی که موبایل نت استفاده کرد
۲٫عدم استفاده از کانولوشن ۱در۱ در انتها و صرفا استفاده از بحث group convolution (یعنی هر کرنل رو محدود به چند کانال ورودی کنیم نه همه )
نمیدونم توضیحات مناسب بود یا نه . اگه جایی نیاز به توضیح داره بگید.
سلام
خیلی ممنون
سپاسگزارم، توضیحات خیلی خوب بود و کاملاً متوجه شدم.
سلام
امیدوارم خوب باشید
بنده می خواستم از این شبکه های برای شناسایی و تشخیص سلول های خون استفاده کنم(پروژم هست)
میخواستم بدونم حجم کار چقدره؟؟ آیا آشنا شدن و پیاده سازی این شبکه ها خیلی پیچیدست و مشکلات خیلی زیادی در طی طراحیش باید برطرف کرد؟؟
دوم اینکه تا حدودی شبکه های عصبی معمولی رو بلدم و میدونم روند کار چطوری هست
آیا ارتباطی با اونها داره و اصلا بلد بودنشون به کار میاد؟؟ یا وقتمو سرف یادگیری اونها تلف نکنم و مستقیما برم سراغ شبکه کانولوشن
سلام
حجم کار به خودتون و کارتون که قراره انجامش بدید بستگی داره اینکه نکته خاصی داره یا نه و یا چقدر بهبود برای شما کفایت میکنه و…
آشنایی با این شبکه ها سخت نیست . اینها پیچیده هم نیستن فقط باید مبانی پایه اونها رو مطالعه کنید و بدونید. البته وقتی قراره از شبکه های از پیش ساخته استفاده کنید اگر خودتون قراره طراحی کنید که خیلی داستان داره
تا اینکه معماری بهینه و خوبی ارائه کنید برای همین هم معمولا در ۹۰درصد کاربردها از معماری های از پیش ساخته استفاده میشه .
بله ارتباط دارن و اگر قراره اینجا خوب کار کنید باید درک خوبی هم از شبکه های عصبی و سیستم کاریشون داشته باشید. من چندتا کتاب و منبع در بخش منابع یادگیری معرفی کردم میتونید اونا رو بخونید مثل کتاب مارتین هاگان یا سایمون هایکن . البته اموزشهای دیپ لرنینگ استنفورد که ویدئوهاش هم هست یک مقدمه ای بر شبکه های عصبی میگن و بعد وارد بحثهای دیپ لرنینگ و …. میشن اونم ببینید بد نیست . آموزش اندرو ان جی هم همینطور که لینکهاش در گروه یادگیری عمیق ما در تلگرام هست تو اینترنت هم سرچ کنید
با تشکر از شما
میخواستم بدونم که آیا این شبکه های پیش ساخته که فرمودین یعنی کد نویسی شده و آماده هستن؟
یا اینکه باید کد نویسی بشن
یعنی شبه های آمده جهت آموزش دادن هست که تحت کودا نوشته شده باشن و نمونه ها رو بدیم و بیشتر روی مقایسش با روش های دیگه مطالعه کنیم؟
سلام .
بر اساس هر فریم ورکی بخوایید کار کنید بله از قبل معماری نوشته شده هست و شما فقط ازش استفاده میکنید. هم در کراس هم در پای تورچ هم در تنسورفلو و هم در کفی و….
اون بخش اخر صحبتتون رو متوجه نشدم
با سلام
من چندتا سوال داشتم آقای مهندس.
اول اینکه solver چیه و در فرایند training دقیقا چه کاربردی داره؟
دوم اینکه نرخ یادگیری دقیقاً چیه؟
سوم اینکه underfitting چه زمانی رخ میده؟ وقتی زمان آموزش به اندازه کافی نباشه یا خیر وقتی مدل کم عمق باشه؟
چهارم اینکه چطور می توان یک heatmap از خروجی لایه آخر شبکه گرفت؟
پنجم اینکه آیا اگر از توابع فعالسازی هم بعد از لایه ها استفاده نکنیم، لایه های کانولوشنی با اینکه عملیات خطی را انجام می دهند، باز هم وقتی لایه کانولوشنی بعدی به نتیجه قبلی اعمال میشه خاصیت غیر خطی ایجاد نمیکنه؟
در واقع میخوام بدونم خاصیت غیر خطی و امکان تقریب زدن ویژگی های سطح بالا رو فقط مدیون فعال سازی ها هستیم یا چند لایه پشت سر هم که کانولوشن اعمال میشه خودش یک عملیات غیر خطی میشه که با استفاده از اطلاعات همسایگی که فیلترها آموزش میبیین سطوح انتزاع بالاتری رو بازنمایی میکنن و ویژگی های پیچیده تری رو میتونن تقریب بزنن؟
سپاسگزارم
سلام . سالور به مجموعه تنظیمات مربوط به عمل بهینه سازی گفته میشه. نرخ یادگیری شما چقدره از چه الگوریتمی برای بهینه سازی استفاده میشه و از این دست موارد
نرخ یادگیری ، یک ضریبه که اندازه گام اپدیت رو مشخص میکنه.
اندرفیتینگ یعنی شبکه ظرفیت یادگیری رو نداره . ربطی به داده اموزشی یا کم عمق بودن یا ترینینگ کم و زیاد نداره . وقتی ظرفیت یادگیری نداشته باشه شما ۱ ترابایت داده هم بدید یا ۱۰ سال هم ترین کنید باز شبکه چیزی یاد نمیگیره
برای گرفتن هیت مپ میتونید راحت فیچرمپ مورد نظر رو بگیرید بعد ریسایزش کنید به اندازه تصویر ورودی بعد با matplotlib اونها رو نمایش بدید. متد imshow مت پلات لیب دوتا ارگومان براش میفرستید cmap=”coolwarm”, alpha=0.7 که مربوط به هیت مپ و میزان ترکیب دو تصویر هست
همین.
شما وقتی تابع غیرخطی لحاظ میکنید بین کانولوشنهای مختلف این تابع غیرخطی هست که باعث میشه این سلسله مراتب معنا پیدا کنن و کانولوشن هربار با نگاشت غیرخطی جدیدی سرو کار داشته باشه
پس جواب میشه توابع غیرخطی + ماهیت سلسله مراتبی.ترکیب این دو هست که باعث میشه به این ویژگی ها و بازنمایی ها دست پیدا کنیم. یک کدوم رو حذف کنید این رابطه از بین میره.
سلام مجدد
ببخشید آقای حسن پور من یه سوال هم به سوالات قبلی اضافه میکنم و اون اینکه میخواستم ازتون بپرسم میشه شبکه ها رو طوری طراحی کرد که input اونها به جای مربعی بودن مستطیلی باشه. یعنی در واقع برای تصاویری که مطمئنیم aspect ratio آنها اگر حفظ شود ماهیت تصویر بهتر ارائه می شود به شبکه، چه راهکارهایی برای طراحی شبکه با این خصوصیت داریم و موانع احتمالی را چطور باید مدیریت کنیم؟ چون من فک میکنم ما با مربعی کردن اجباری تصاویر همون اول کار کلی information را از دست می دهیم و قبل از بوجود اومدن هرگونه co-variate خودمون توزیع داده رو عوض میکنیم.
متشکرم از اینکه با حوصله به سوال هامون جواب میدید
سلام
هیچ اجباری به استفاده از تصاویر مربعی نیست. میتونید از تصاویر با حفظ aspect ratio استفاده کنید.
برای شکبه فرقی نداره تصاویر شما مربعی باشه یا نباشه. در بحثی که در کارگاه داشتیم این مبحث رو با بحث multicrop توضیح دادیم .
شما هربار بخشی از تصویر رو دریافت میکنید و به شبکه ارائه میدید و در انتها هم موقع تست یا از dense evaluation استفاده میکنید یا اینکه خیلی معمولی چند کراپ در تست میگیرید و نتایج رو میانگین میگیرید .
دقت کنید اینجا برای این اینطور گفتیم تا بشه از مدلهای از پیش ترین شده که روی یک سایز ثابت ترین شدن ما بتونیم استفاده کنیم (این مدلها هم الان عموما aspect ratio رو لحاظ میکنن مثلا میگن طرف کوچکتر ۲۵۶ و طرف بزرگتر بر اساس aspect ratio افزایش پیدا کنه هرچقدر که هست دیگه نمیشه ۲۵۶ در ۲۵۶٫ و چون سایز همه تصاویر یکسان نیست اینجا با یک سایز یکسان از این تصاویر نمونه برداری میشه(کراپ). اگه سایز تمام تصاویر شما یکیه شما میتونید این نمونه برداری رو نداشته باشید و کل تصویر رو ارائه کنید و شبکه هم کارشو انجام میده. ولی میتونید همنطور که در ایمیل هم خدمت شما گفتم از بحث نمونه برداری برای دیتااگمنتیشن استفاده کنید. یعنی اینجا دیگه بحث این نیست تصویر بزرگه نمیشه یکجا تصویر رو به شبکه داد (بخاطر سربار پردازشی و…) اینجا بحث ما اینه که ما از قصد میخواییم نمونه های مختلفی از یک تصویر به شبکه ارائه کنیم و اینطور هم بطور مصنوعی داده رو افزایش داده باشیم وهم حالات مختلف از یک تصویر رو شبکه باهاش مواجه بشه و نهایتا در بحث تعمیم بتونه بخوبی عمل کنه.
ضمنا لطف کنید اینطور سوالات رو در سایت پرسش و پاسخ مطرح کنید .خیلی بهتره چون هم سریعتر ممکنه جواب بگیرید و هم برای بقیه قابل استفاده هست و اینجا بین کامنتها گم نمیشه.
سلام
خیلی ممنون از توضیحات خوبتون.
حتماً، همین کار رو انجام میدم.
در پناه حق موفق و سربلند باشید
سلام. شبکه های GAN جز کدوم یکی از این ۴ دسته قرار میگیرند؟
شبکه های GAN زیرمجموعه شبکه های بدون سرپرست هستند.
دقت کنید این ۴ دسته بندی که اینجا اومده قابل تعمیم یا پوشش دهنده همه انواع روشهای حوزه یادگیری عمیق نیست . این یکی از بهترین مقالات ریویویی تو سال ۲۰۱۵ بود که “تا اون زمان” توضیحات خیلی خوبی نسبت به روشهای “مطرح” تو دیپ لرنینگ میداد. ۳ سال پیش من ترجمه اش کردم برای کار و پایان نامه خودم بعدش اینجا گذاشتم تا بقیه استفاده کنن. طی این سه سال پیشرفتهای خیلی زیادی حاصل شده که اینجا قید نشده. از این مقاله به عنوان “یکی” از منابع برای بدست اوردن اطلاعات بیشتر استفاده کنید ولی فقط به همین قرار نیست بسنده کنید
سلام خسته نباشید.
درباره ی الگوریتم های یادگیری DL زیر شاخه ی الگوریتم های با نظارت از کجا میتونم شروع کنم برای پایان نامه؟
لطفا راهنمایی کنید.سپاس
سلام
متوجه نشدم! واضح تر بفرمایید تا راهنمایی کنم
سلام، وقت بخیر
در مورد شبکه های inception و جایگاه اونها در دسته بندی هایی که کردین توضیح میدین.
ممنون
سلام شبکه های inception که از ماجول inception تشکیل شدن ادامه سری معماری های مبتنی بر NIN (Network in Network) هستن.
اینها همه شبکه های کانولوشنی هستند.
نتایج مسابقه ILSVRC در سالهای ۲۰۱۶ و ۲۰۱۷ به چه صورتی بوده؟ و همچنین الان از بین همه معماری ها کدومش بالاترین دقت رو داره؟
سلام
تعداد معماری ها خیلی زیاد شده اما برجسته ترین اونها در سال ۲۰۱۶ دنز نت بوده و بعدش هم اواخر ۲۰۱۷ معماری SeNet از مقاله Squeeze-and-Excitation Networks استیت آو در آرت جدیدرو ثبت کرده.
خیلی ممنونم
ببخشید برای پیاده سازی شبکه های کانولوشنی شخصا کدوم فریمورک رو پیشنهاد می کنید؟
سلام
تنسورفلو و پای تورچ انتخاب های خوبی هستن.
تنسورفلو پشتیانی رسمی از ویندوز داره اما پای تورچ هنوز نه (البته میتونید از پای تورچ در ویندوز هم استفاده کنید بخش ابزارها رو ببینید))
همینطور جامعه کاربری تنسورفلو خیلی بزرگتر از پای تورچ هست.
از پایتورچ بیشتر برای کارهای تحقیقاتی و اکادمیک استفاده میشه در حالی که تنسورفلو در هم در کارهای تحقیقاتی و هم صنعتی استفاده میشه.
سلام بسیار ممنونم مطلب بسیار عالی بود
سلام.توضیحی درباره الگوریتم های deep learning میخواسنم که چگونه کار میکنند؟مثل backprop.یا max pooling
منیع فارسی اگه هست لطفا بهم معرفی کنید.تشکر آقاسید
سلام.
الگوریتم های زیادی وجود داره باید خاص تر بشید.
مواردی که سوال کردید در بخش پرسش و پاسخ مطالب و توضیحات مختلفی براشون هست میتونید اونجا رو چک کنید.
سلام و عرض ادب
خسته نباشید میگم بابت این متن
آیا این مقاله به صورت فایل PDF موجود می باشد؟؟
سلام.
نه فرصت نکردم به PDF تبدیل کنم. انشاءالله انجام شد در همین پست قرار میگیره
با سلام واحترام
لطفا بفرمایید شکل شماره ۱ و تقسیم بندی یادگیری عمیق به چهار قسمت را از کدام منبع میشه پیدا کرد؟
همچنین در مقاله زیر تقسم بندی به شکل دیگری انجام شده و به جای گروه Sparse Coding ، گروه Restricted Boltzmann Machines (RBMS) آمده است.
لینک مقاله: (بخش Abstract)
https://www.sciencedirect.com/science/article/pii/S0925231216315533?via%3Dihub
با تشکر.
سلام .
اینجا رو چک کنید قبلا اشاره کردم
سلام اگر ممکنه در مورد denoising autoencoder بیشتر توضیح بدین من بازم نفهمیدم که چطور هستش چون یک مقاله ای دارم در مورد deep patient رو میخوام ارائه بدم بیشتراز این روش استفاده کرده ممنون از مقاله خوبتون
سلام.
باشه سعی میکنم یه مقاله مفصل در مورد اتوانکودرها بنویسم اما درخواستها خیلی زیاده و منم واقعا سرم شلوغه خیلی شلوغ.
سعی میکنم موارد پایه رو کم کم قرار بدم اما شما هم در این بین سعی کنید از بخش پرسش و پاسخ استفاده کنید و سرچ کنید در این باره قبلا سوال شده و لینک و منابع مختلفی ارایه شده
سلام شما در مورد RNNها مطلبی ننوشتید. در حالی که یکی از زیر مجموعه های DEEP LEARNING ..هستش RECAURENT NAURAL NETWORK
سلام.
انشاالله سر فرصت در سایت قرار میگیره
میشه در مورد Weakly supervised annotations یه توضیحی بدین ؟ ممنون
سلام خدا قوت
ممنون از مطالبتون که بسیار کارامد است و وقت می گذارین تا مطالب خوب و کاربردی برای فرزندان ایران بذارید
خدا قوت
من تازه کار هستم و توی سن ۳۸ سالگی (خخخ) می خوام روی مباحث هوش مصنووعی وارد بشوم
خب از پردازش تصویر هم شروع کردم
ممکمن من را بیششتر راهنمایی کنید
در خصوص انواع روشها و دسته بندی شبکه های عمیق ناحیه پایه؟؟!!
مطالب میخوام که بیشتر درک کنم
ترجیحا فارسی که سرعت مطالع ام بیشتر بشه تا این حوزه رو سریعا درک کنم و بعدش برم سراغ منابع خارجی
تشکر از آقا سید
سلام آقای حسن پور
من دیتاستی دارم که نصف تصاویر اون رو نویز میدم، تعداد تصاویر دیتاستم افزایش پیدا نمیکنه، خواستم بدونم به این کار هم میشه گفت Data Augmentation یا نه ؟
باتشکر
سلام تغییر تصاویر به هر نحوی جزو دیتا اگمنتیشن بحساب میاد(البته عموما زمانی این مساله حائز اهمیته که داده اصلی و اشکال مختلف اون با هم به شبکه ارائه بشن تا شبکه داده های متفاوت بیشتری رو ببینه)
سلام
ضمن تشکر از مطالب ارزنده و مفیدی که بی مضایقه منتشر کردید. در مورد مدل جدید EfficientNet اگر اطلاعات دارید لطفا راهنمایی بفرمایید.
باسلام و تشکر از مطالب مفید شما
ببخشید سوالی در مورد الگوریتم های یادگیری عمیق داشتم :
۱- اگر الگوریتم بخواهد ورودی دستگاه نوروفیدبک یا ورودی سنسور را بگیرد و بر اساس این ورودی ها الگو بسازد تا حرکت بعدی را پیشنهاد دهد. آیا اینگونه الگوریتم ها از قبل وجود دارند و آماده استفاده هستند و فقط ما ورودی را وارد این الگوریتم ها می کنیم ؟ یا باید اینگونه الگوریتم برنامه نویسی شود؟ در واقع الگوریتمی که به عنوان موتور هوشمند یادگیری کار کند.
ببخشید چون آشنایی نداشتم با این الگوریتمها این سوال رو پرسیدم.
خیلی ممنون
سلام.
الگوریتم های یادگیری عمیق سعی دارند همین کارو انجام بدن. با دریافت ورودی سعی در بدست اوردن الگوهای یکتا در اونها میکنن و بر اساس اونها تصمیم گرفته میشه(بسته به هرمساله)
اما بکارگیری این الگوریتم ها و فرموله کردن اونها بر اساس هر مساله خودش چالش خودشو داره.
سلام و درود
کاش ویدئو آموزشی هم میذاشتید آپارات الان از گروه های رقیب بیشتر رشد میکردید، حیفه ملت برن از جای دیگه یاد بگیرن، خیلی قلم خوبی دارید خداقوت
آقا یک سوال برام پیش اومد، الان مقالات و کامنت هارو دیدم یک موضوع خیلی مبهمه
گفته میشه مثلا داده هارو ۸۰-۲۰ تقسیم کنید برای آموزش و تست، خب برای تشخیص چهره که مثلا ۱۰۰نفرآدم داده داریم، چنین تقسیمی خنده داره، شبکه روی ۸۰نفر/داده یادمیگیره بعد اورفیت میشه برای ۲۰نفر تست چون توی داده آموزش نبودن و یادشون نگرفته 😐 (از هرکس یک عکس داریم)
ممنون میشم این موضوع رو برام باز کنید، آیا میشه کل ۱۰۰داده رو آموزش بدیم؟
سلام
متاسفانه من بشدت سرم شلوغه و حتی فرصت نکردم مقالات یکی دو سال پیش رو منتشر کنم انشاءالله سرم خلوت تر شد اینکارو میکنم
مضافا اینکه بقیه فعال شدن خیلی خوبه من زمانی این سایت رو استارت زدم که در ایران کسی نبود و برای گسترشش تو کشور زحمت کشیدم الان که الحمدالله خیلی ها استارت زدن من هم به کارهای دیگه ام میتونم برسم
در مورد تشخیص چهره هم کلا مساله فرق میکنه برای این موضوع ما از triplet loss استفاده میکنیم یا اخیرا لاسهای مارجینال مثل Arcface, sphereface, adacos, و… یعنی ماهیت کار عوض میشه و شما یک تابع شباهت رو تقریب میزنید
و ملاک شما میشه اگر من تصویر دو فرد یکسان رو بدم این تابع (شبکه) مقدار کمینه رو بمن بده و اگر افراد متفاوت هستن مقدار بیشینه رو .
وقتی رو یه دیتاست با اندازه مناسب ترین کردید حالا روی افراد زیادی میتونید تیست کنید . برای تشخیص چهره افراد هم خودتون دیتاست نسازید از دیتاست های موجود استفاده کنید همون کفایت میکنه
مگر اینکه بعدا ببینید مثلا فلان دیتاست بایاس داره نسبت به یک نژاد و… و رو دیتای شما خوب جواب نمیده و بعد برید سراغ تهیه دیتاست خودتون .
در مورد تقسیم هم باز بسته به ماهیت کار داره مثلا تو حالتی که شما تابع شباهت رو تقریب میزنید فرقی نداره که مثلا روی علی و حسن ترین کرده باشید و بعد زهرا و حسین هم تو تست مورد ارزیابی قرار بدید چون تابع شما باید بتونه در هر حالت مقدار مناسب رو بده .
اگر ۱۰۰ کلاس دارید (۱۰۰ نفر) و بخوایید یه کلسیفیکیشن معمولی داشته باشید برای تست هم ۱۰۰ کلاس دارید از همون افراد فقط داده ها رو کمتر میکنید . یعنی اگر هر کلاس ۱۰ تا عکس داشته باشه شما ۸ تا رو یا ۷ تا رو میزارید برای ترین و ۲ یا ۳ تا رو برای تست میزارید کنار
که البته این روش خوبی نیست به دلایل مختلف من جمله اینکه اگر فرد دیگه ای اضافه بشه مجبورید از اول ترین کنید .
سلام
توی آیا راجب SVM هم نوشته یا مقاله ای دارید؟
من سرچ کردم تو سایت ندیدم
با تشکر
سلام
خیر. مطالب این سایت برای معرفی یادگیری عمیق طرح و نوشته شده.
سلام خسته نباشید یک سوال داشتم، برای شبکه های DNN سیگنال رو به صورت خام وارد شبکه می کنیم یا این که باید قبلش ویژگی هاشو استخراج کنیم و اون ها رو به شبکه بدیم؟
ممنون میشم راهنمایی کنید
سلام بسته به مساله داره. بعضی ها خام ارائه میکنن بعضی ها یک بازنمایی جدید مثلا با spectrogram ایجاد میکنن و بعد به شبکه میدن. نوع شبکه ها و شیوه های ارائه اونها متفاوت و متنوع هست.
سلام جناب مهندس وقتتون بخیر.
آیا در خصوص attention detection و روشهایی که دارد مقاله ای که بطور جامع توضیح داده باشد می توانید معرفی کنید؟
سلام.
باید مقاله های مرتبط رو بخونید. من سروی ندیدم در این رابطه خاص .
البته یکسری وبلاگ از میدیوم … ه ست که میتونید بخونید و شاید خوب باشه براتون.
خیلی ممنون. لطف کردید.
سلام وقت بخیر
ممنون برای اطلاعات کاملی که ارایه دادید.
یک سوال؟
ایا شبک های از پیش آموزش دیده مثل AlexNet و یا GoogleNet بر شبکه های عصبی تخاصمی GAN ارجحیت دارن؟
سلام
دقیق متوجه نشدم منظورتون رو .
ماهیت اینها کاملا متفاوت هست. (یکی زیرمجموعه مدلهای دیسکرمنیتو و دیگری زیر مجموعه مدلهای جنریتیو هست)
شبکه هایی مثل الکس نت و گوگل نت و… شبکه هایی هستن که برای کلسیفیکیشن استفاده شدن(بصورت سوپروایز ترین شدن و میشن(مدل دیسکرمنیتو)) هرچند میتونید برای کارهای دیگه هم ازشون استفاده کنید بعنوان بک بون یا فیچراکسترکتور)
اما شبکه های گن جنریتیو هستن و بصورت ان سوپروایزد ترین میشن و کلا متشکل از دو زیرشبکه هستن که تو ساخت اون زیرشبکه ها (بخش جنریتور و بخش دیسکرمنیتور)
اگر جواب نگرفتید لطفا واضح تر سوالتون رو بپرسید