
بسم الله الرحمن الرحیم
در اینجا میخوام آموزش و اطلاعات مورد نیاز در مورد Caffe رو بدم انشاالله .(بعدا انشاالله اگه ویکی سایت راه افتاد مطالب اینجا منتقل میشه اونجا).
(فعلا ترتیب مطالب درست نیست. سر فرصت انشاالله تقدم و تاخر مطالب رو درست میکنم. فعلا بخش به بخش میزارم)
تو این آموزش من سعی کردم در مواردی مثل:
- یکسری اطلاعات کلی از Caffe و مشتقاتش مثل DIGITS
- prototxt و فرمت پروتوکل بافر گوگل که ازش در Caffe استفاده میشه
- تنظیمات مختلف مربوط به لایه ها و blob ها
- تنظیمات solver و انواع مختلف نرخ های یادگیری و…
- نحوه انجام fine-tuning و transfer learning در Caffe
- نحوه کار با Caffe!
- نصب و پیگربندی Caffe و wrapper های پایتون و متلب اون در ویندوز و لینوکس
رو پوشش بدم . یه نکته خیلی مهم اینه که مستندات الان تمامی اطلاعات بخش مستندات Caffe رو در خودش داره و همچنین اطلاعات خیلی بیشتر از اون . فقط نکته اینجاست که مستندات هر دو باید بروز بشن . من مطالبی که اینجا هست رو برای پایان نامه ام تقریبا یکسال پیش نوشتم و سر وقت اینها هم بروز میشه (بعنوان مثال در مورد لایه Batch-normalization نه در مستندات Caffe چیزی هست و نه اینجا چون بخش اطلاعات لایه ها از مستندات Caffe گرفته شده بود ولی من بعدا اضافه میکنم از این موارد داریم نسبتا ولی مشکلی نیست)
Caffe
Caffe یکی از معروف ترین و همینطور یکی از سریعترین چارجوبها برای توسعه برنامه ها در حوزه deep learning است که در ابتدا توسط Yangqing Jia در دوران تحصیلش در مقطع Phd در دانشگاه UC Berkeley توسعه داده شد. در حال حاضر Caffe بصورت Open source انتشار داده شده و توسط مرکز آموزش و بینایی دانشگاه برکلی ایالات متحده آمریکا توسعه داده میشود.
از ویژگی های بارز این چارچوب که باعث محبوبیت بسیار زیاد آن شده است میتوان به موارد زیر اشاره کرد:
معماری بیانی
در Caffe مدلسازی و بهینه سازی ها توسط فایل پیکربندی بدون آنکه هیچ نیازی به برنامه نویسی آنها باشد انجام میشوند. انتخاب بین اجرای training توسط CPU و یا GPU تنها با مشخص کردن یک flag در فایل پیکربندی قابل انجام است. و بعد از آن مدل آموزش دیده براحتی قابل انتقال به سیستم های دیگر جهت اجرا خواهد بود.
کد قابل توسعه
این چارچوب دائما در حال توسعه است . تنها در سال اول انتشار Caffe , این پروژه توسط بیش از ۱۰۰۰ برنامه نویس (توسعه دهنده) fork شد و هرکدام دستاوردها و تغییرات قابل توجهی را در پروژه به ارمغان آوردند.بلطف این افراد, این چارچوب از آخرین نتایج رخ داده در حوزه deep learning هم در کد و هم در مدلها دنباله روی میکند.
سرعت
بواسطه پیاده سازی بسیار بهینه و استفاده از GPU ها این چارچوب در حال حاضر سریعترین چارچوب توسعه با استفاده از Convolutional Network برای deep learning است. Caffe بعنوان مثال قادر به پردازش بیش از ۶۰ میلیون تصویر در روز با استفاده از یک کارت گرافیک GPU Nvidia K40 است. این یعنی تنها ۱ میلی ثانیه به ازای تشخیص هر تصویر(در زمان تست) و ۴ میلی ثانیه به ازای آموزش هر تصویر (در زمان آموزش) است.
جامعه کاربری
Caffe به بسیاری از پروژه های تحقیقاتی, نمونه های اولیه استارتاپها و حتی برنامه های صنعتی در مقیاس بزرگ نیرو میبخشد و از آن استفاده میشود.به همین دلیل جامعه کاربری بزرگی داشته که caffe user-groups و Github نمونه هایی از این دست هستند.
DIGIT
یکی دیگر از نمونه های بسیار موفق و پرکاربرد Caffe تولکیت DIGIT است که توسط شرکت NVIDIA مبتنی بر Caffe ایجاد شده است. این تولکیت بواسطه اجرای اختصاصی بر روی پردازنده های گرافیکی و استفاده از کتابخانه cuDDN شرکت Nvidia بسیار سریع بوده و امکانات بسیار خوبی همانند ارائه رابط گرافیکی جهت ایجاد مدل و همینطور نمایش (visualization) از داده های رد و بدل شده در داخل شبکه بصورت بلادرنگ ارائه میکند. در DIGITS براحتی میتوان تغییرات در حال رخ دادن را در feature map ها و filter ها مشاهده کرد. مدلهای ایجاد شده توسط آن هم دارای سازگاری ۱۰۰% با چارچوب Caffe هستند و همچنین مدلهای از پیش آموزش داده شده توسط Caffe نیز براحتی قابل استفاده در این چارچوب میباشند.
EXpRESSo
(توضیحات بعدا)
Caffe Installation
Caffe را میتوان در لینوکس و ویندوز براحتی نصب و استفاده کرد.
آموزش و نحوه نصب Caffe در لینوکس در صفحه اصلی سایت Caffe وجود دارد. برای کامپایل و استفاده از آن در ویندوز میتوان به این دو منبع مراجعه کرد.
۱٫ Caffe-Windows
۲٫ Caffe-Wikki
در اینجا به منظور آشنایی مقدماتی با این چارچوب نحوه مدل کردن یک شبکه بعنوان نمونه را گام به گام توضیح میدهیم. در این بین اطلاعات مورد نیاز در رابطه با نحوه مدل کردن و گزینه های پیش رو در هر بخش نیز عنوان میشود.
تعریف شبکه MNIST
MNIST یک دیتاست حاوی تصاویر ارقام دستنویس است که برای تحقیقات در حوزه بینایی کامپیوتر مورد استفاده قرار میگیرد. در اینجا ما همانند شبکه LeNet شبکه ای را طراحی میکنیم که با استفاده از این دیتاست آموزش دیده و نهایتا قادر به تشخیص اعداد دستنویس باشد.
Caffe برای تعریف مشخصات یک شبکه از فرمت protobuf شرکت گوگل (با پسوند prototxt) استفاده میکند. هر لایه بصورت جداگانه با ورودی و خروجی هایی که در اصل آرایه های چند بعدی هستند تعریف میشوند. به این نوع آرایه ها در Caffe اصطلاحا blob گفته میشود که حاوی اطلاعات و داده های مورد نیاز هر لایه همانند مشتق ها و داده ها بوده و برای نقل و انتقال بهتر داده های بین لایه ها ایجاد شده است. لایه ها بصورت عمودی یکی بعد از دیگری قرار گرفته بطوری که لایه ورودی در پایین و لایه خروجی در بالا قرار میگیرد. هر لایه دارای تعداد مشخصی blob پایینی و بالایی با ابعاد مشخص است. با متصل کردن این blob ها و لایه ها است که یک شبکه عصبی عمیق ایجاد میشود. در زیر نحوه تعریف یک لایه که دارای دو blob ورودی و سه blob خروجی است بعنوان نمونه نشان داده شده است :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
l a y e r { name : "NameOfLayer" # has to be unique type : "LayerType1" # has to be one of the types in layer catalogue bottom : " bottom blob 1 " bottom : " bottom blob 2 " top : " top blob 1 " top : " top blob 2 " top : " top blob 3 " layer_specific_params { param1 : value1 param2 : " value2 " param3 : value3 } } |
در زمان تعریف هر لایه, نام لایه ها باید یکتا باشد. همینطور در بخش type باید نام یکی از type هایی که توسط Caffe پشتیبانی میشود قرار داده شود.
همانطور که قبلا اشاره کردیم برای ایجاد یک مدل در caffe باید معماری مورد نظر خود را در قالب protocol buffers با پسوند prototxt تعریف کنیم .
Protocol Buffers یک روش برای serialize کردن داده های ساخت یافته است و معمولا از آن در برنامه ها برای ارتباط با دیگر برنامه ها در بستر شبکه استفاده میشود. این روش شامل یک زبان توصیف رابط (Interface description language) که ساختار بعضی از داده ها را توصیف کرده و یک برنامه که از توصیف ایجاد شده سورس کد ایجاد میکند است.
Google برای استفاده داخلی خود Protocol Buffers را توسعه داد و کامپایلرهایی را نیز برای C++ , Java و Python ایجاد کرد که بصورت رایگان و متن باز قابل استفاده هستند.البته پیاده سازی های دیگری نیز برای زبانهای دیگری مثل C# , JavaScript , Go , Perl , PHP , Ruby , Scala و Julia وجود دارد.
هدف اصلی Protocol Buffers ارائه سادگی و کارایی است و بطور خاص به گونه طراحی شده است تا از XML کوچکتر و سریعتر باشد. هرچند هدف اصلی آن تسهیل ارتباطات در شبکه است ,اما سادگی و سرعت آن باعث میشود تا Protocol Buffers بعنوان یک راه جایگزین برای class ها و struct های داده محور سی++ خصوصا در زمانی که interoperability با سایر زبانها و سیستم ها در آینده مدنظر است تبدیل شود.
نحوه کار با این روش به این صورت است که ابتدا برنامه نویس ساختارهای داده ای (که به آنها message یا پیام گفته میشود) و سرویس ها را در یک فایل تعریف proto (proto definition file) تعریف میکند. سپس با استفاده از برنامه protoc آنرا کامپایل کرده و سورس کدهایی ایجاد میکند که توسط برنامه مبدا و مقصد این ساختارهایی داده ای قابل فراخوانی هستند. بعنوان مثال example.proto فایلهای example.pb.cc و example.pb.h را ایجاد میکند که در آن کلاسهای سی++ برای هر پیام و سرویسی که در فایل example.proto تعریف شده است ایجاد وجود دارد.
در protocol buffers انواع داده ای (data types) با نام فیلدها (field names) مرتبط میشوند و از طریق اعداد صحیح هر field مشخص میشود ( داده protocol buffer تنها شامل اعداد میشود و نه نام fieldها تا با اینکار نسبت به سیستم های دیگر مقداری صرفه جویی در فضا و پهنای باند انجام شود.)
در زیر یک نمونه فایل تعریف proto را مشاهده میکنید که در آن سه پیام (ساختار داده ای) با نامهای Point , Line و Polyline تعریف شده اند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//polyline.proto message Point { required int32 x = 1; required int32 y = 2; optional string label = 3; } message Line { required Point start = 1; required Point end = 2; optional string label = 3; } message Polyline { repeated Point point = 1; optional string label = 2; } |
پیام Point دو قلم داده اجباری x و y را تعریف میکند. قلم داده ای label اختیاری است. هر قلم داده دارای یک tag است. این tag بعد از علامت مساوی تعریف میشود. بعنوان مثال x دارای tag 1 است.
پیامهای Line و Polyline هردو از Point استفاده میکنند که این چگونگی استفاده از داده های ترکیبی در protocol buffers را نشان میدهد. Polyline فیلدی بنام repeated دارد که همانند یک بردار (vector) عمل میکند. این طرح را میتوان با استفاده از یک کامپایلر به یک یا چند زبان دیگر تبدیل کرد. Google کامپایلری بنام protoc ارائه کرده است که میتوان از آن برای تولید سورس کدهایی برای C++,Java و یا Python استفاده کرد. کامپایلرهایی برای زبانهای دیگر نیز وجود دارد که در اینجا از ذکر آنها خود داری میکنیم.
بعد از آنکه یک نسخه برای زبان سی++ بصورت بالا ایجاد شد, یک سورس کد سی++ میتواند بصورت زیر از پیامهای آن استفاده کنید :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// polyline.cpp #include "polyline.pb.h" // generated by calling "protoc polyline.proto" Line* createNewLine(const std::string& name) { // create a line from (10, 20) to (30, 40) Line* line = new Line; line->mutable_start()->set_x(10); line->mutable_start()->set_y(20); line->mutable_end()->set_x(30); line->mutable_end()->set_y(40); line->set_label(name); return line; } Polyline* createNewPolyline() { // create a polyline with points at (10,10) and (20,20) Polyline* polyline = new Polyline; Point* point1 = polyline->add_point(); point1->set_x(10); point1->set_y(10); Point* point2 = polyline->add_point(); point2->set_x(20); point2->set_y(20); return polyline; } |
شما با مراجعه به فایل caffe.proto میتوانید تعاریف و مشخصات مربوط به لایه ها و پارامترهای آنها را در caffe را مشاهده کنید.
خب تا به اینجا ما در مورد نحوه تعریف “انواع داده ” صحبت کردیم و فهمیدیم برای تعریف انواع داده ای آنرا در فایلی با پسوند .proto با شیوه ای که ذکرش رفت ذخیره میکنیم . و همینطور فهمیدیم چطور از طریق زبانهای برنامه نویسی میتوان از این داده ها و… استفاده کرد. اما در Caffe ما معمولا به این شیوه عمل نمیکنیم و معمولا نیاز به تعریف نوع داده جدیدی توسط ما نیست. بلکه ما از طریق فایلهای پیکربندی به مدلسازی و بهینه سازی شبکه خود میپردازیم. برای اینکار ما از انواع داده ای که قبلا در caffe تعریف شده است استفاده میکنیم . نحوه کار بسیار ساده بوده و به این صورت است که ما مراحل و تنظیمات مورد نظر خود را با استفاده از انواع داده ای که پیشتر تعریف شده اند در قالب فایلی با پسوند .prototxt ذخیره کرده و از آن برای کنترل مراحل آموزش و تست در Caffe استفاده میکنیم .
بعنوان نمونه , یک فایل پیکربندی که برای شبکه LeNet مورد استفاده قرار میگیرد بصورت زیر تعریف شده است :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# The train/test net protocol buffer definition net: "examples/mnist/Mnist_demo_LeNet.prototxt" # test_iter specifies how many forward passes the test should carry out. # In the case of MNIST, we have test batch size 100 and 100 test iterations, # covering the full 10,000 testing images. test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.01 momentum: 0.9 #solver_type: ADAGRAD weight_decay: 0.0005 #weight_decay: 0.0005 # The learning rate policy lr_policy: "inv" gamma: 0.0001 power: 0.75 # Display every 100 iterations display: 100 # The maximum number of iterations max_iter: 10000 # snapshot intermediate results snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" # solver mode: CPU or GPU solver_mode: GPU |
در این فایل همانطور که مشاهده میکنید تنها با استفاده از داده هایی که قبلا تعریف شده است ما نحوه آموزش و تست شبکه را مشخص کرده ایم . و با ارائه این فایل به برنامه Caffe و تنظیم پارامترهای دیگر که در ادامه در مورد آنها توضیح خواهیم داد عملیات آموزش و تست را به انجام میرسانیم .
معماری caffe و توضیح نقل و انتقلات داده ها
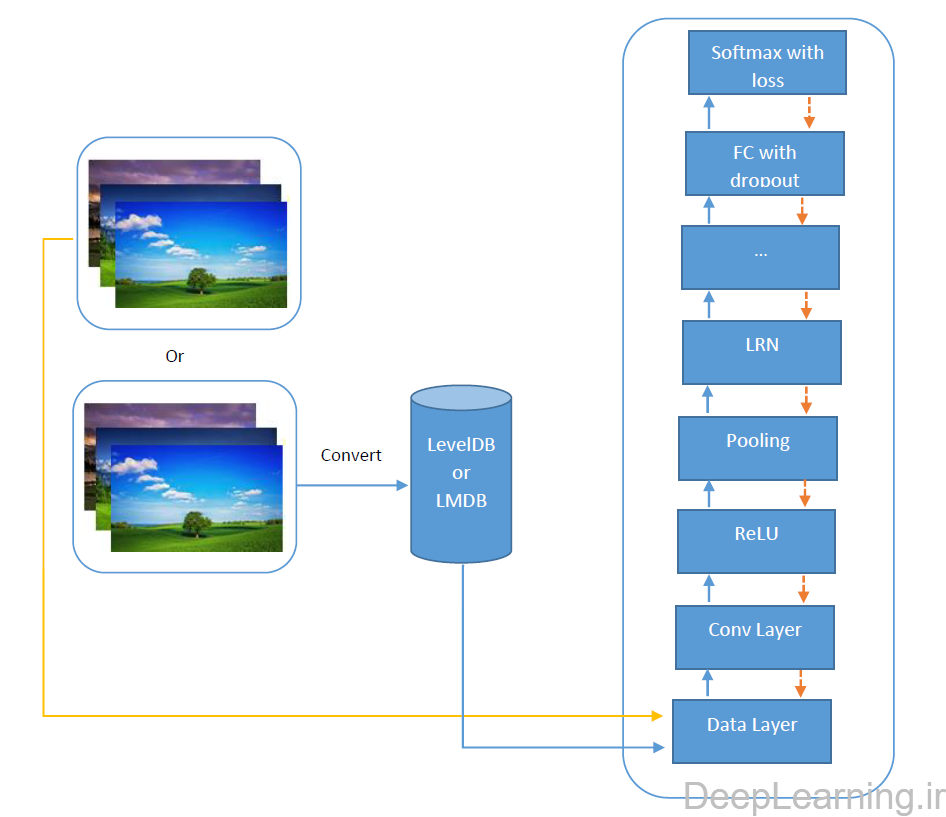
در شکل فوق یک معماری نوعی در caffe را مشاهده میکنید. اطلاعات یا در قالب فایلهای معمول تصاویر و یا با استفاده از دیتابیس های بهینه از طریق لایه داده به شبکه تغذیه شده و سپس لایه های مختلف پردازش های متفاوتی را بر روی تصاویر انجام داده و بعد از انجام forward pass , در لایه آخر خطا محاسبه شده و طی عملیات backpropagation پارامترهای شبکه تنظیم میشوند. در ادامه درمورد لایه های مختلف و پارامترهای هرکدام توضیح داده میشود.
در Caffe انواع مختلفی از لایه ها وجود دارند که در ادامه به آنها میپردازیم .
(ابتدا انواع مختلف لایه ها رو توضیح میدم بعد انشاالله در مورد solver ها توضیح داده میشه و بعد یه مثال عملی دوباره میزنم که دقیقا متوجه بشیم داستان از چه قراره.
نکته دوم. لایه هایی که توضیحی ندارن سرفرصت توضیحات موردنیازشون رو میزارم انشاالله)
Vision Layers
Vision layers یا لایه های بینایی معمولا تصاویر را بعنوان ورودی دریافت کرده و تصاویر دیگری را بعنوان خروجی تولید میکنند. بعنوان نمونه, یک تصویر در دنیای واقعی ممکن است تک کاناله (c=1) همانند تصاویر grayscale بوده و یا ۳ کاناله (c=3) باشد. اما در اینجا ویژگی متمایز کننده یک تصویر ساختار مکانی آن است. معمولا یک تصویر دارای طول و عرض h>1 و w>1 است. این ساختار ۲بعدی بطور طبیعی باعث میشود تا تصمیمات مشخصی را بتوان در مورد چگونگی پردازش ورودی اتخاذ کرد. بطور خاص اکثر لایه های بینایی با اعمال عملیات مشخصی بر روی تعدادی ناحیه برای تولید نواحی متناظر برای خروجی کار میکنند. برخلاف اینها, لایه های دیگر (با تعداد معدودی استثنا در این زمینه) ساختار مکانی ورودی را در نظر نگرفته و بطور خاص ورودی را بصورت یک بردار بزرگ با ابعاد chw (مخفف تعداد کانال * طول * عرض تصویر ورودی)در نظر گرفته و با آن کار میکنند.
Convolution
- نوع لایه : Convolution
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/convolution_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/convolution_layer.cu
- پارامترها (ConvolutionParameter convolution_param)
- ضروری
- num_output(c_o) : تعداد فیلترها
- kernel_size یا (kernel_h و kernel_w) : طول و عرض هر فیلتر را مشخص میکند
- بشدت پیشنهاد میشود
- weight_filler ] پیشفرض [type: “constant” value: 0 :
- اختیاری
- bias_term (پیشفرض :true ) : مشخص میکند که آیا مجموعه ای از بایاس ها را به خروجی فیلترها اعمال شود یا خیر
- pad (یا pad_h و pad_w ) (مقدار پیشفرض ۰) مشخص کننده تعداد پیکسلهایی که به اطراف ورودی اضافه میشود
- stride (یا stride_h و stride_w) (مقدار پیشفرض ۱): مشخص کننده فاصله ای است که فیلترها با توجه به آن در ورودی اعمال میشوند.
- group (g) (مقدار پیشفرض ۱): اگر g>1 باشد ما اتصال هر فیلتر را به یک زیرناحیه از ورودی محدود میکنیم. بصورت خاص کانال های ورودی و خروجی به g , group تقسیم میشوند و کانالهای گروه خروجی iام تنها به کانالهای گروه ورودی iام متصل خواهند بود. بعنوان مثال اگر g=2 باشد نیمه اول فیلترها تنها به نیمه اول کانالهای ورودی متصل خواهند شد و به همین صورت نیمه دوم فیلترها تنها به نیمه دوم کانالهای ورودی متصل خواهند شد.
- ورودی
- n * c_i * h_i * w_i (c_i یعنی تعداد کانال ورودی, h_i یعنی ارتفاع ورودی, w_i یعنی عرض ورودی (
- خروجی
- n* c_o * h_o * w_o (c_o یعنی تعداد کامال خروجی, h_o یعنی ارتفاع خروجی, w_oیعنی عرض خروجی) که h_o از رابطه بدست می آید . w_o نیز به همین صورت محاسبه میشود.
- نمونه
- ضروری
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" # نرخ یادگیری و ضریب تنزل (decay multiplier) برای فیلترها param { lr_mult: 1 decay_mult: 1 } # نرخ یادگیری و ضریب تنزل (decay multiplier) برای بایاس ها param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 # 96 فیلتر برای آموزش خواهیم داشت kernel_size: 11 # اندازه هر فیلتر 11*11 است stride: 4 # بصورت 4 پیکسل در میان. فیلترها را اعمال میکنیم weight_filler { # از توزیع Gaussian با انحراف معیار 0.01برای مقداردهی اولیه فیلترها استفاده میکنیم type: "gaussian" std: 0.01 # (میانگین پیشفرض :0)انحراف معیار } bias_filler { type: "constant" # بایاس ها را با صفر مقدار دهی اولیه میکنیم. value: 0 } } } |
نکته:
lr_mult و decay_mult ضرایب مربوط به نرخ یادگیری و تنزل وزن (weight decay) هستند که در مقادیر مورد نظر خود ضرب میشوند. بعبارت بهتر lr_mult در نرخ یادگیری ای که در فایل solver قید شده است ضرب میشود و نرخ یادگیری موثر در لایه مورد نظر را موجب میشود. همین مساله در مورد weight decay صدق میکند. به این صورت فرد میتواند تاثیر نرخ یادگیری و weight decay را در لایه های مختلف کم و زیاد نماید.
همانطور که در مثال بالا مشخص است از این ضرایب دو نمونه وجود دارد . دلیل این مساله این است که یک نمونه از این ضرایب برای فیلترها و نمونه دیگر برای بایاس ها استفاده میشود.
این ضرایب بیشتر در زمان fine-tuning استفاده میشوند هرچند در موارد غیره نیز استفاده دارند.
Pooling
- نوع لایه : Pooling
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/pooling_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/pooling_layer.cu
- پارامترها (PoolingParameter pooling_param)
- ضروری
- kernel_size : یا (kernel_h و kernel_w) : طول و عرض هر فیلتر را مشخص میکند
- اختیاری
- pool (پیشفرض MAX ): روش pooling را مشخص میکند. در حال حاضر مقادیر MAX , AVE و یا STOCHASTIC قابل استفاده هستند
- pad (یا pad_h و pad_w ) (مقدار پیشفرض ۰) مشخص کننده تعداد پیکسلهایی است که به اطراف ورودی اضافه میشود
- stride (یا stride_h و stride_w) (مقدار پیشفرض ۱): مشخص کننده فاصله ای است که فیلترها با توجه به آن در ورودی اعمال میشوند.
- ورودی
- n * c * h_i * w_i
- خروجی
- n * c * h_o * w_o که مقادیر h_o و w_o به همان صورتی که در لایه convolution محاسبه میشدند بدست می آیند.
- نمونه
- ضروری
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX # عملیات pooling را در یک ناحیه 3*3 انجام بده kernel_size: 3 # عمل pooling را با گام 2 پیکسل انجام بده. یعنی بر روی blob پایینی به فاصله دو پیکسل در میان فیلتر را اعمال کن stride: 2 } } |
Local Response Normalization (LRN)
- نوع لایه : LRN
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/lrn_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/lrn_layer.cu
- پارامترها (LRNParameter lrn_param)
- اختیاری
- local_size (مقدار پیشفرض :۵) تعداد کانالها جهت تجمیع (برای cross channel LRN ) و یا اندازه ضلع مربع ناحیه برای تجمیع (برای within channel LRN)
- alpha (پیشفرض ۱) : پارامتر مقیاس گذاری (نکته انتهایی را ببینید)
- beta (پیشفرض ۵) : توان (نکته انتهایی را ببینید)
- norm_region (پیشفرض ACROSS_CHANNELS) : مشخص میکند آیا کانالهای مجاور (ACROSS_CHANNELS) تجمیع شوند یا مناطق مکانی نزدیک (WITHIN_CHANNEL)
- اختیاری
نکته:
لایه نرمال سازی پاسخ محلی (local response normalization layer) نوعی از lateral inhibition را با نرمال سازی بر روی نواحی ورودی محلی به انجام میرساند. در حالت ACROSS_CHANNELS , نواحی محلی در امتداد کانالهای نزدیک بسط پیدا میکنند اما هیچ اندازه مکانی ای ندارند (یعنی به شکل local_size x 1 x 1 هستند). در حالت WITHIN_CHANNEL , نواحی محلی بصورت مکانی بسط پیدا میکنند اما هرکدام در کانال جداگانه ای هستند. (یعنی دارای شکل ۱ x local_size x local_size هستند ) هر مقدار ورودی بر ![]() تقسیم میشود که در آن , n اندازه هر ناحیه محلی بوده و عمل جمع بر روی ناحیه ای که در مرکز آن مقدار قرار گرفته است انجام میشود. (zero padding در صورت نیاز اضافه میشود)
تقسیم میشود که در آن , n اندازه هر ناحیه محلی بوده و عمل جمع بر روی ناحیه ای که در مرکز آن مقدار قرار گرفته است انجام میشود. (zero padding در صورت نیاز اضافه میشود)
Batch Normalization:
این لایه با نام BatchNorm همون تکنیک گوگل در ماه می ۲۰۱۵ که بشدت باعث بهتر شدن خروجی شبکه میشه رو پیاده سازی میکنه . اطلاعات بیشتر بعدا اضافه کنم.
im2col
Im2col یک لایه کمکی است که کار تبدیل تصویر به ستون را انجام میدهد. یعنی تصویر را در قالب یک وکتور تبدیل میکند. برای کار با Caffe نیازی به دانستن این مطلب نیست . اما خوب است بدانید که Caffe برای انجام ضرب ماتریسها از این تکنیک برای افزایش سرعت استفاده میکند. به اینصورت که تمامی patchها را در قالب یک ماتریس قرار داده و سپس عمل ضرب را انجام میدهد.
Loss Layers
خطا,زیان یا اتلاف, یادگیری را با مقایسه یک خروجی با یک مقدار مورد نظر (مقدار هدف) و سپس اختصاص یک هزینه برای کاهش آن , به پیش میبرد. اتلاف خود در مرحله forward pass محاسبه شده و گرادیانت آن نیز توسط backward pass محاسبه میشود.
Softmax
نوع لایه : SoftmaxWithLoss
لایه اتلاف softmax اتلاف لگاریتمی چندجمله ای softmax ورودی را محاسبه میکند. از لحاظ مفهمومی کاملا شبیه لایه softmax یی است که بعد از آن لایه multinomial logistic loss قرار گفته باشد. این لایه گرادیانت پایدار تری از لحاظ عددی ارائه میکند.
Sum-of-Squares / Euclidean
- نوع لایه : EuclideanLoss
لایه اتلاف اقلیدیسی یا Euclidean loss layer جمع مربعات تفاوت بین دو ورودی را محاسبه میکند.![image004]()
Hinge / Margin
- نوع لایه : HingeLoss
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/hinge_loss_layer.cpp
- پیاده سازی مبتنی بر GPU : —
- پارامترها (HingeLossParameter hinge_loss_param)
- اختیاری
- norm (مقدار پیشفرض: L1 ) : norm مورد استفاده را مشخص میکند. در حال حاضر L1 و L2 پشتیبانی میشوند.
- اختیاری
- ورودی
- n * c * h * w برای پیشبینی ها
- n * 1 * 1 * 1 برای برچسب ها
- خروجی
- ۱ * ۱ * ۱ * ۱ برای خطای محاسبه شده
- نمونه
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# L1 Norm layer { name: "loss" type: "HingeLoss" bottom: "pred" bottom: "label" } # L2 Norm layer { name: "loss" type: "HingeLoss" bottom: "pred" bottom: "label" top: "loss" hinge_loss_param { norm: L2 } } |
The hinge loss layer computes a one-vs-all hinge or squared hinge loss.(DeepLearning.ir) Convolutionn
- Sigmoid Cross-Entropy
نوع لایه : SigmoidCrossEntropyLoss
Infogain
- نوع لایه : InfogainLoss
Accuracy and Top-k
لایه Accuracy با توجه به هدف, به خروجی تولید شده یک امتیاز اختصاص میدهد. این لایه در واقع یک لایه اتلاف نیست و هیچ مرحله عقب گردی ندارد و صرفا نشان دهنده میزان نزدیکی خروجی تولید شده به هدف مورد نظر است.
Activation / Neuron Layers
بطور کلی , لایه های Activation/Neurons عملگرهایی هستند که بصورت مولفه به مولفه (element wise) عمل خود را انجام میدهند. به اینصورت که یک blob پایینی (bottom blob) را دریافت کرده و یک blob بالایی (top blob) را با همان اندازه تولید میکنند. در لایه هایی که در زیر خواهیم دید, از انجایی که اندازه های ورودی و خروجی یکسان هستند, آنها را در نظر نمیگیریم:
- ورودی
- n * c * h * w
- خروجی
- n * c * h * w
ReLU / Rectified-Linear and Leaky-ReLU
- نوع لایه : ReLU
- پیاده سازی مبتنی بر CPU : /src/caffe/layers/relu_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/relu_layer.cu
- پارامترها (ReLUParameter relu_param)
- اختیاری
- negative_slope (مقدار پیشفرض : ۰ ) این گزینه مشخص میکند که آیا تاثیر بخش منفی با استفاده از ضرب آن در یک مقدار شیب اعمال شود یا اینکه مقدار آن برابر ۰ تنظیم شود .
- نمونه
- اختیاری
|
1 2 3 4 5 6 7 8 |
layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" } |
نحوه کار به اینصورت است که اگر یک مقدار همانند x بعنوان ورودی دریافت شود, لایه ReLU خروجی را برابر با x قرار میدهد اگر x>0 باشد. و اگر مقدار x<=0 باشد, مقدار negative_slope * x را تولید خواهد کرد. زمانی که پارامتر مقدار شیب منفی (negative slope) تنظیم نشده باشد, این لایه همانند تابع ReLU استاندارد عمل میکند و max(x,0) را محاسبه میکند. این لایه همچنین از محاسبه درجا (in-place computation) پشتیبانی میکند به این معنی که blob پایینی و بالایی میتوانند اشاره به یکجا داشته باشند تا اینطور در مصرف حافظه صرفه جویی شود.
Sigmoid
- نوع لایه : Sigmoid
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/sigmoid_layer.cpp
- پیاده سازی مبتنی بر GPU : /src/caffe/layers/sigmoid_layer.cu
- نمونه
|
1 2 3 4 5 6 7 8 |
layer { name: "encode1neuron" bottom: "encode1" top: "encode1neuron" type: "Sigmoid" } |
لایه sigmoid , خروجی را با استفاده از sigmoid(x) برای هر مولفه x محاسبه میکند.
TanH / Hyperbolic Tangent
- نوع لایه : TanH
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/tanh_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/tanh_layer.cu
- نمونه
|
1 2 3 4 5 6 7 8 |
layer { name: "layer" bottom: "in" top: "out" type: "TanH" } |
لایه TanH, خروجی را با استفاده از tanh(x) برای هر مولفه x محاسبه میکند.
Absolute Value
- نوع لایه : AbsVal
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/absval_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/absval_layer.cu
- نمونه
|
1 2 3 4 5 6 7 8 |
layer { name: "layer" bottom: "in" top: "out" type: "AbsVal" } |
لایه AbsVal , خروجی را با استفاده از abs(x) برای هر مولفه x محاسبه میکند.
Power
- نوع لایه : Power
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/hinge_loss_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/power_layer.cu
- پارامترها (PowerParameter power_param)
- اختیاری
- power (مقدار پیشفرض : ۱)
- scale (مقدار پیشفرض : ۱)
- shift (مقدار پیشفرض: ۰)
- نمونه
- اختیاری
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
layer { name: "layer" bottom: "in" top: "out" type: "Power" power_param { power: 1 scale: 1 shift: 0 } } |
لایه Power خروجی را بصورت (shift + scale * x) ^ power برای هر مولفه x محاسبه میکند.
BNLL
- نوع لایه : BNLL
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/bnll_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/bnll_layer.cu
- نمونه
|
1 2 3 4 5 6 7 8 |
layer { name: "layer" bottom: "in" top: "out" type: BNLL } |
لایهBNNL (مخفف binomial normal log likelihood ) خروجی را بصورت log(1 + exp(x)) برای هر مولفه x محاسبه میکند.
Data Layer
داده ها در Caffe از طریق data layer ها وارد شبکه میشوند. آنها در پایین ترین بخش یک شبکه قرار میگیرند. داده ها میتوانند بصورت های مختلفی خوانده شوند میتوان آنها را از دیتابیس های بهینه ای مثل LevelDB یا LMDB و یا بطور مستقیم از حافظه و یا اگر بهینگی موضوع مهمی نیست از روی دیسک با فرمت HDF5 و یا فرمتهای معمول تصاویر خواند.
عملیاتهای پیش پردازش بر روی ورودی (همانند mean subtraction , scaling , random cropping و mirroring ) با مشخص کردن TransformationParameter ها قابل استفاده هستند.
Database
- نوع لایه : Data
- پارامترها
- ضروری
- source : نام پوشه ای که حاوی دیتابیس است
- batch_size : تعداد ورودی هایی که در یک زمان پردازش میشوند
- اختیاری
- rand_skip : این تعداد از ورودی را در ابتدا رد کن, برای sgd نامتقارن مفید است.
- backend : (مقدار پیش فرض : LEVELDB ) مشخص میکند که از LEVELDB استفاده شود یا LMDB .
- ضروری
In-Memory
- نوع لایه : MemoryData
- پارامترها
- ضروری
- batch_size, channels, height, width : اندازه توده ورودی که از حافظه قرار است خوانده شود را مشخص میکند.
- ضروری
لایه memory data داده ها را بصورت مستقیم از حافظه میخواند بدون آنکه آنها را کپی کند. برای استفاده از آن, فرد باید MemroryDataLayer::Reset را در C++ و یا Net.set_input_arrats را در پایتون فراخوانی کند تا به این وسیله یک منبع پیوسته از داده (بصورت یک آرایه ۴ بعدی سطر محور )را مشخص کرده و به اینصورت در هر بار یک توده با اندازه batch_size از آن خوانده شود.
HDF5 Input
- نوع لایه : HDF5Data
- پارامترها
- ضروری
- source : نام فایلی که باید از آن خوانده شود
- batch_size
- ضروری
HDF5 output
- نوع لایه : HDF5Output
- پارامترها
- ضروری
- file_name: نام فایلی که باید در آن نوشته شود.
- ضروری
لایه خروجی HDF5 output برعکس عملکرد لایه های دیگر در این بخش عمل میکند. این لایه blob ورودی خود را بر روی دیسک مینویسد (write میکند)
لازم به ذکر است که لایه HDF5 عملیات prefetching را برخلاف سایر لایه ها در thread جداگانه ای انجام نمیدهد. همینطور این لایه تنها میتواند داده های float32 و float64 را ذخیره کند و این به معنای حجم بسیار زیاد تصاویر در این فرمت است.
نکته: لایه HDF5 از هیچ پیش پردازشی مثل لایه data پشتیبانی نمیکند. به همین منظور برای انجام یکسری از این عملیات ها یا بایستی ورودی از قبل پیش پردازش شده و بعد ذخیره گردرد و یا از لایه هایی مثل MVN استفاده شود.
Images
- نوع لایه : ImageData
- پارامترها
- ضروری
- source : نام فایل متنی که هر سطر آن شامل آدرس یک فایل و برچسب آن است
- batch_size : تعداد تصاویری که در یک دسته قرار داده میشوند
- اختیاری
- rand_skip
- shuffle (پیشفرض false )
- new_height,new_width : اگر این بخش تنظیم شود, تمامی تصاویر با توجه به این اندازه ها resize میشوند.
- ضروری
Windows
نوع لایه : WindowData
این لایه داده مورد نیاز شبکه را از طریق پنجره هایی از تصاویر ورودی که توسط یک window data file مشخص میشود, فراهم میکند.
Dummy
DummyData برای توسعه و اشکالزدایی مورد استفاده قرار میگیرد. DummyDataParameter را ببینید.
Common Layers
Inner Product
- نوع لایه : InnerProduct
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/inner_product_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/inner_product_layer.cu
- پارامترها (InnerProductParameter inner_product_param)
- ضروری
- num_output(c_o) : تعداد فیلترها
- بشدت پیشنهاد میشود
- weight_filter (مقدار پیشفرض type: ‘constant’ value: 0 است)
- اختیاری
- bias_filter (مقدار پیشفرض type: ‘constant’ value: 0 است)
- bias_term (مقدار پیشفرض true است): با تنظیم این گزینه مشخص میکنیم که آیا مجموعه ای از بایاس ها را در خروجی فیلترها اعمال شود یا خیر.
- ورودی
- n * c_i * h_i * w_i
- خروجی
- n * c_o * 1 * 1
- نمونه
- ضروری
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
layer { name: "fc8" type: "InnerProduct" # learning rate and decay multipliers for the weights param { lr_mult: 1 decay_mult: 1 } # learning rate and decay multipliers for the biases param { lr_mult: 2 decay_mult: 0 } inner_product_param { num_output: 1000 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } bottom: "fc7" top: "fc8" } |
لایه InnerProduct (که به آن لایه تماما متصل یا fully connected layer هم گفته میشود) با ورودی همانند یک بردار ساده برخورد کرده و یک خروجی بشکل یک بردار واحد (که ارتفاع و عرض blob ان ۱ است )تولید میکند.
Splitting
لایه Split یک لایه کاربردی است که blob ورودی را به چندین blob خروجی تقسیم میکند. از این لایه در زمانی که یک blob به چندیدن لایه خروجی باید تغذیه شود مورد استفاده قرار میگیرد.
Flattening
لایه Flatten یک لایه کاربردی است که یک ورودی با شکل n*c*h*w را به یک خروجی برداری ساده با شکل n*(c*h*w) تبدیل میکند(اصطلاحا آنرا مسطح میکند).
Reshape
- نوع لایه : Reshape
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/reshape_layer.cpp
- پارامترها (ReshapeParameter reshape_param)
- اختیاری
- shape
- ورودی
- یک blob با ابعاد دلخواه
- خروجی
- همان blob با ابعاد تغییر یافته که توسط reshape_param مشخص شده است.
- نمونه
- اختیاری
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
layer { name: "reshape" type: "Reshape" bottom: "input" top: "output" reshape_param { shape { dim: 0 # بُعد را از لایه زیرین کپی کن dim: 2 dim: 3 dim: -1 # باتوجه به بقیه ابعاد این بُعد را بدست بیاور } } } |
لایه Reshape را میتوان برای تغییر ابعاد ورودی آن مورد استفاده قرار داد بدون آنکه تغییری در داده آن رخ دهد. دقیقا مثل لایه Flatten تنها ابعاد تغییر پیدا میکنند و در این حین هیچ داده ای در طی این فرآیند کپی نمیشود.و در نتیجه عملیات بسیار بهینه انجام میشود.
ابعاد خروجی توسط ReshapeParam مشخص میشوند. اعداد مثبت بصورت مستقیم مورد استفاده قرار میگیرند و ابعاد blob خروجی را مشخص میکنند. علاوه بر آن, دو مقدار ویژه هم برای هر ابعاد قابل قبول است که میتوان از آنها استفاده کرد.
- مقدار ۰
- یعنی ابعاد مورد نظر را از لایه پایینی کپی کن. این یعنی اگرلایه پایینی ۲ را بعنوان اولین بعد خود داشت, لایه بالایی هم اگر dim: 0 را برای اولین بعد خود مشخص کرده بود ,برای اولین بعد خود عدد ۲ را تنظیم خواهد کرد.
- مقدار ۱-
- این مقدار به معنای ” از بقیه ابعاد , اندازه این بعد را بدست بیاور” است. این رفتار شبیه مقدار ۱- در numpy و یا [] در متلب است . این بعد محاسبه میشود تا تعداد مولفه کلی به اندازه لایه پایینی باشد. تنها از یک ۱- در عملیات reshape استفاده کرد.
بعنوان یک نمونه مثال دیگر , با تعریف reshape_param { shape { dim: 0 dim: ‐1 } } باعث میشود تا لایه دقیقا مثل لایه Flatten عمل کند
Concatenation
- نوع لایه : Concat
- پیاده سازی مبتنی بر CPU : ./src/caffe/layers/concat_layer.cpp
- پیاده سازی مبتنی بر GPU : ./src/caffe/layers/concat_layer.cu
- پارامترها (ConcatParameter concat_param)
- اختیاری
- axis (مقدار پیشفرض ۱) : مقدار ۰ برای اتصال در راستای num و ۱ برای اتصال در راستای channels است
- ورودی
- n_i * c_i * h * w برای هر blob ورودی i از ۱ تا k
- خروجی
- اگر axis =1 باشد : n_1 * (c_1 + c_2 + … + c_K) * h * w, و تمام n_i ورودی باید همنام باشند.
- اختیاری
- نمونه
|
1 2 3 4 5 6 7 8 9 10 11 12 |
layer { name: "concat" bottom: "in1" bottom: "in2" top: "out" type: "Concat" concat_param { axis: 1 } } |
لایه Concat یک لایه کاربردی است که چندین blob ورودی را بهم متصل کرده و یک blob خروجی واحد تولید میکند.
Slicing
لایه Slice یک لایه کاربردی است که یک لایه ورودی را به چندیدن لایه خروجی در راستای بعد داده شده (در حال حاضر تنها num یا channel ) و اندیس های هر برش, برش میزند.
نمونه
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
layer { name: "slicer_label" type: "Slice" bottom: "label" #نمونه ای از برچسب با شکل N x 3 x 1 x 1 top: "label1" top: "label2" top: "label3" slice_param { axis: 1 slice_point: 1 slice_point: 2 } } |
axis اشاره به target axis یا محور هدف دارد. slice_point اشاره به اندیس های موجود در بعد انتخاب شده دارد ( تعداد اندیس ها باید مساوی تعداد blob های بالایی منهای یک باشد)
Elementwise Operations
نوع لایه : Eltwise
Argmax
نوع لایه : ArgMax
Softmax
نوع لایه : Softmax
Mean-Variance Normalization
نوع لایه : MVN
توضیحات بیشتر در مورد Loss
در Caffe مثل بیشتر مباحث موجود در Machine learning , یادگیری از طریق یک تابع خطا میسر شده و هدایت میشود. یک تابع خطا با نگاشت تنظیمات پارامترها (یعنی وزنهای فعلی شبکه ) به یک مقدار عددی و مشخص کردن میزان “بد بودن” یا “نامناسب بودن” این پارامترها هدف یادگیری را مشخص میکند. بنابر این, هدف یادگیری یافتن تنظیماتی برای این وزنهاست بگونه ای که مقدار تابع خطا به حداقل برسد.
خطا در Caffe توسط فاز forward pass محاسبه میشود. هر لایه مجموعه ای blob (پایینی) ورودی دریافت کرده و مجموعه ای از blob های (بالایی) خروجی را تولید میکند. خروجی بعضی از این لایه ها را میتوان در یک تابع خطا مورد استفاده قرار داد . یک انتخاب معمول برای تابع خطا برای کارهای دسته بندی ۱ در مقابل همه (one vs all classification) استفاده از تابع SoftmaxWithLoss است که تعریف آن بعنوان مثال بصورت زیر انجام میشود :
|
1 2 3 4 5 6 7 8 9 |
layer { name: "loss" type: "SoftmaxWithLoss" bottom: "pred" bottom: "label" top: "loss" } |
در یک تابع SoftmaxWithLoss , blob بالایی یک عدد است که حاصل میانگین خطا در یک mini-batch میباشد.
Loss weights
برای آندسته از شبکه هایی که چندین لایه در آنها خطا تولید میکنند (مثل شبکه ای که هم ورودی را با استفاده از یک لایه SoftmaxWithLoss دسته بندی کرده و هم با استفاده از لایه EculideanLoss آنرا را بازسازی میکند), از loss weight میتوان برای مشخص کردن اهمیت نسبی آنها استفاده کرد.
در Caffe لایه هایی که دارای پسوند Loss هستند, در تابع خطا مشارکت دارند اما سایر لایه ها تنها برای محاسبات میانی مورد استفاده قرار میگیرند. با این وجود, هر لایه ای میتواند با اضافه کردن فیلد loss_wieght: <float> در تعریف خود, بعنوان خطا برای هر blob بالایی تولید شده توسط آن مورد استفاده قرار گیرد. لایه هایی که دارای پسوند Loss هستند, بصورت ضمنی دارای این فیلد با مقدار loss_wieght:1 برای اولین blob بالایی خود (و loss_weight:0 برای سایر blob های بالایی) هستند .سایر لایه ها بصورت ضمنی دارای loss_weight:0 برای تمام blob های بالایی خود هستند. بنابر این میتوان لایه SoftmaxWithLoss بالایی را بصورت زیر هم نوشت :
|
1 2 3 4 5 6 7 8 9 10 |
layer { name: "loss" type: "SoftmaxWithLoss" bottom: "pred" bottom: "label" top: "loss" loss_weight: 1 } |
به هر حال, هر لایه ای که قادر به انجام عمل backpropagation باشد ممکن است یک loss-weight غیرصفر دریافت کند که به آن, بعنوان مثال اجازه regularize کردن فعالسازی های تولید شده توسط بعضی از لایه های میانی شبکه را در صورت نیاز میدهد .برای خروجی های non-singlton به همراه خطای غیرصفر, خطا خیلی ساده از طریق جمع کردن تمام ورودی های Blob حاصل میشود.
خطای نهایی در Caffe , سپس با تجمیع خطای وزن دار در سراسر شبکه بصورت شبه کد زیر محاسبه میشود :
|
1 2 3 4 5 6 |
loss := 0 for layer in layers: for top, loss_weight in layer.tops, layer.loss_weights: loss += loss_weight * sum(top) |
توضیحات بیشتر در مورد Blob و لایه ها
شبکه های عمیق مدلهای ترکیبی اند که بطور طبیعی بصورت مجموعه ای از لایه های بهم متصل که بر روی توده هایی از داده کار میکنند هستند.Caffe نیز یک شبکه را لایه به لایه با توجه به الگوی مدل خاص خود تعریف میکند. یک شبکه یک مدل را بطور کامل از پایین به بالا از داده ورودی تا خطای نهایی تعریف میکند. همانطور که داده ها و مشتقات توسط گذرهای رو به جلو و رو به عقب (forward and backward pass) در شبکه جریان پیدا میکنند, Caffe اطلاعات را در قالب blob ها ذخیره کرده , انتقال داده و مورد پردازش قرار میدهد. یک blob آرایه استانداردی است که رابط حافظه برای شبکه را یکی[۱] ساخته است. در گام بعد , این لایه است که بعنوان زیربنای مدل و محاسبات وارد عمل میشود. شبکه بعنوان مجموعه ای از ارتباطات بین لایه ها ادامه پیدا میکند. جزییات هر blob به نحوه ذخیره سازی و انتقال اطلاعات در و میان لایه ها در درون شبکه میپردازد.
عمل حل شبکه یا اصطلاحا Solving بصورت جداگانه تنظیم شده تا فاز بهینه سازی و مدلسازی شبکه از هم جدا نگه داشته شوند.
Blob storage and communication
یک Blob , wrapper ی بدور داده واقعی است که توسط Caffe پردازش شده و در شبکه انتقال داده میشود. همچنین در سطوح پایین, قابلیت همگام سازی (synchronization) بین CPU و GPU را فراهم میکند. یک Blob از لحاظ ریاضی, یک آرایه N بعدی است که بصورت مدل آرایه بهم پیوسته زبان سی ذخیره میشود.(همانند آرایه ها در سی ذخیره میشوند).
Caffe از Blob ها برای ذخیره سازی و همینطور انتقال داده ها استفاده میکند. Blob ها رابط حافظه واحدی را برای نگهداری داده ها مثل دسته های تصاویر, پارامترهای مدل (شبکه), و مشتقات برای بهینه سازی فراهم میکنند.
Blob ها با همگام سازی از CPU به GPU در صورت نیاز سربار محاسباتی و ذهنی حاصل عملیاتهای ترکیبی CPU/GPU را پنهان میکنند. اختصاص حافظه در سیستم میزبان (رم سیستم) و یا GPU (رم GPU)به منظور استفاده بهینه از حافظه در زمان تقاضا (بصورت Lazy ) انجام میگیرد.
ابعاد یک blob معمولی برای دسته های تصاویر بصورت N x K x H x W که به ترتیب معرف تعداد دسته, تعداد کانال , ارتفاع و نهایتا عرض میباشند. حافظه Blob بصوت سطری بوده به همین دلیل آخرین یا سمت راست ترین بعد سریعتر از سایر ابعاد تغییر میکند. بعنوان مثال در یک blob 4بعدی , مقدار موجود در اندیس (n,k,h,w) بطور فیزیکی در اندیس (n x k +k) x H + h) x W + w قرار دارد.
همانطور که در ابتدا اشاره شد, N به اندازه دسته داده اشاره دارد. پردازش دسته ای خروجی بهتری در انتقالات و پردازش توسط GPu دارد. بعنوان مثال, برای آموزش ImageNet با دسته های ۲۵۶ تایی تصویر, N=256 است.
K یا کانال به بُعد ویژگی (feature dimension) اشاره دارد بعنوان مثال برای تصاویر RGB این مقدار برابر با K=3 است.
هرچند بسیاری از blob ها در مثالهای Caffe 4 بعدی و در زمینه کاربرد تصاویر هستند, اما از آنها میتوان در کاربردهای غیر تصویری نیز براحتی استفاده کرد. بعنوان مثال, اگر شما تنها به شبکه های تماما متصل مشابه شبکه چندلایه پرسپترون معمولی نیاز دارید, از blob های ۲ بعدی (Shape(N,D)) استفاده کنید و innerProductLayer را (که در ادامه توضیح داده ایم) فراخوانی کنید.
ابعاد blob پارامتر بسته به نوع و نحوه پیکربندی لایه تغییر میکند. برای یک لایه کانولوشن با ۹۶ فیلتر ۱۱ x 11 و ۳ blob ورودی , اندازه blob پارامتر برابر با ۹۶ x 3 x 11 x 11 میشود. به همین صورت برای یک لایه تماما متصل / inner product با ۱۰۰۰ کانال خروجی و ۱۰۲۴ کانال ورودی , blob پارامتر اندازه ای برابر با ۱۰۰۰ x 1024 خواهد داشت.
برای داده های سفارشی (custom data) شما نیازمند ایجاد ابزار آماده سازی ورودی خود و یا لایه داده جدیدی هستید. با این وجود, زمانی که داده وارد شد,کار شما به اتمام میرسد و ماژولار بودن لایه ها بقیه کارها را برایتان انجام میدهد.
جزییات پیاده سازی :
از آنجایی که هم مقادیر و هم گرادیانت های هر blob برای ما حائز اهمیت هستند, هر blob دو توده داده ای data و diff را در خود ذخیره میکند که مورد اول همان داده معمولی است که منتقل میشود و مورد دوم گرادیانتی است که توسط شبکه محاسبه شده است.
علاوه بر آن, از آنجایی که این مقادیر هم میتوانند بر روی CPU و هم GPU ذخیره شوند, دو ره دسترسی به آنها وجود دارد:
- راه const که هیچ تغییری در مقادیر نمیدهد و
- راه mutable که مقادیر را میتوان تغییر داد.
|
1 2 3 4 |
const Dtype* cpu_data() const; Dtype* mutable_cpu_data(); |
به همین صورت این مسئله برای GPU و توده diff نیز این مسئله صادق است .
دلیل چنین طراحی این است که , یک blob از کلاس SyncedMem برای همگام سازی مقادیر بین CPU و GPU به منظور پنهان سازی جزییات همگام سازی و به حداقل رساند انتقال داده استفاده میکند. قانون کلی به این صورت است که, اگر قصد تغییر مقادیر را ندارید همیشه از نمونه const استفاده کنید و هیچگاه اشاره گرها را در اشیاء خود ذخیره نکنید. هر دفعه ای که شما بر روی یک blob کار میکنید, توابع را برای دستیابی به اشاره گرها فراخوانی کنید چرا که SyncedMem نیازمند این است که بداند در چه زمانی داده ها را کپی کند.
در عمل زمانی که GPUیی در دسترس باشد, فرد میتواند با استفاده از کدهای CPU (یعنی بدون استفاده از GPU ) داده ها را از دیسک به یک blob بارگذاری کرده, سپس کرنل دستگاه (GPU) را برای انجام محاسبات مبتنی بر GPU فراخوانی کرده , blob را به لایه بعدی انتقال داده و بدون اینکه جزییات سطح پایین را در نظر بگیرد,کارایی سطح بالایی را بدست آورد.تا زمانی که تمامی لایه ها پیاده سازی مبتنی بر GPU داشته باشند, تمام داده های میانی و گرادیانت ها در GPU باقی میمانند.
اگر قصد بررسی این که چه زمانی یک blob داده خود را کپی میکند دارید به مثال زیر دقت کنید:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// Assuming that data are on the CPU initially, and we have a blob. const Dtype* foo; Dtype* bar; foo = blob.gpu_data(); // data copied cpu‐>gpu. foo = blob.cpu_data(); // no data copied since both have up‐to‐date contents. bar = blob.mutable_gpu_data(); // no data copied. // ... some operations ... bar = blob.mutable_gpu_data(); // no data copied when we are still on GPU. foo = blob.cpu_data(); // data copied gpu‐>cpu, since the gpu side has modified the data foo = blob.gpu_data(); // no data copied since both have up‐to‐date contents bar = blob.mutable_cpu_data(); // still no data copied. bar = blob.mutable_gpu_data(); // data copied cpu‐>gpu. bar = blob.mutable_cpu_data(); // data copied gpu‐>cpu. |
Layer computation and connections
لایه جز اصلی یک مدل و یک واحد بنیادین در محاسبات به شمار میرود. لایه ها عملیات های convolution , pooling , ضرب داخلی (inner products) , اعمال توابع غیرخطی rectified-linear و sigmoid و سایر تبدیلات مؤلفه محور(element wise transformations) , نرمال سازی , بارگذاری داده ها و محاسبه خطاها با استفاده از Softmax و hinge را انجام میدهند. در بخش های بعدی به تفصیل در باره لایه ها , پارامترها و عملیات های انجام شده توسط هریک توضیح میدهیم.
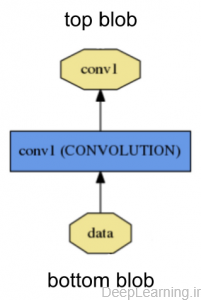
هر لایه از طریق اتصالات “پایینی” ورودی خود را دریافت کرده و از طریق اتصالات “بالایی” خروجی تولید(ارائه) میکند.
هر نوع لایه , سه بخش محاسباتی حیاتی را تعریف میکند که عبارتند از : setup , forward و backward.
- setup: وظیفه آماده سازی لایه و مقداردهی اولیه آن و اتصالات آن در زمان ایجاد مدل(شبکه) را دارد.
- forward : با دریافت ورودی از (لایه) پایین, خروجی را محاسبه کرده و آنرا به (لایه)بالا ارسال میکند.
- backward: با دریافت گرادیانت نسبت به خروجی (لایه)بالایی, گرادیانت را نسبت به ورودی محاسبه کرده و آنرا به (لایه)پایین ارسال میکند. هر لایه دارای پارامتر, گرادیانت را نسبت به پارامترهایش محاسبه کرده و آنرا بصورت داخلی ذخیره میکند.
علاوه بر این, دو تابع forward و backward وجود دارند که یکی برای CPU و دیگری برای GPU پیاده سازی شده اند. اگر شما نسخه GPU را پیاده سازی نکنید, لایه از تابع مبتنی بر CPU بعنوان پشتیبان استفاده میکند.این مسئله ممکن است در زمانی که قصد انجام آزمایشات سریع داشته باشید مفید باشد, هرچند که ممکن است هزینه انتقال داده اضافی به همراه داشته باشد (ورودی ها در این حالت از GPU به CPU کپی شده و خروجی ها نیز دوباره از CPU به GPU کپی میشوند)
لایه ها دو مسئولیت کلیدی در عملیات صورت گرفته در شبکه دارند. یکی forward pass است که ورودی ها را دریافت کرده و خروجی ها را تولید میکند و دیگری backward pass است که گرادیانت خروجی را دریافت کرده و گرادیانت پارامترها را با توجه به پارامترها و ورودی محاسبه میکند که به نوبه خود به لایه های ابتدایی بصورت پس انتشار (back-propagated) منتقل میکند.
ایجاد لایه های سفارشی بواسطه قابلیت ترکیبی شبکه و ماژولار بودن کد آن ,به تلاش زیادی نیاز ندارد. تنها کافیست برای اینکار, setup , forward و backward را برای لایه جدید تعریف کنید. حال لایه جدید برای استفاده در شبکه آماده بوده و براحتی همانند سایر لایه ها میتوانید از آن استفاده کنید.
Net definition and operation
یک شبکه , بطور مشترک یک تابع و گرادیانت آنرا با استفاده از ترکیب و محاسبه دیفرانسیل خودکار تعریف میکند. ترکیب تمامی خروجی های هر لایه , تابعی را برای انجام یک وظیفه محوله محاسبه کرده و ترکیب پس گذر (backward ) تمامی لایه ها گرادیانت خطا را محاسبه کرده تا کار مورد نظر فراگرفته شود. مدلهای Caffe موتورهای یادگیری ماشین انتها-به-انتها هستند.
یک شبکه مجموعه ای از لایه های بهم متصل در یک گراف محاسباتی (بطور دقیقتر, یک گراف جهت دار بدون دور (DAG)) است. Caffe تمامی حسابرسی های مربوط به هر گراف مربوط به لایه ها را انجام میدهد تا از صحت (correctness) گذرهای پیشرو و پس رو (forward and backward pass) اطمینان حاصل کند. یک شبکه نوعی, با یک لایه داده که داده ها را از دیسک میخواند شروع شده و به یک لایه خطا که خطای شبکه را برای کارهایی مثل classification و یا reconstruction محاسبه میکند پایان میابد.
یک شبکه در قالب مجموعه ای از لایه ها و اتصالات آنها با استفاده از یک زبان مدلسازی متنی تعریف میشود . در زیر یک دسته بندی کننده رگراسیون لوجیستیکی ساده را به همراه چارت و تعریف آن مشاهده میکنید:
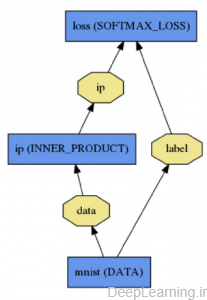
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
name: "LogReg" layer { name: "mnist" type: "Data" top: "data" top: "label" data_param { source: "input_leveldb" batch_size: 64 } } layer { name: "ip" type: "InnerProduct" bottom: "data" top: "ip" inner_product_param { num_output: 2 } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip" bottom: "label" top: "loss" } |
آماده سازی و مقداردهی اولیه مدل توسط Net::Init() انجام میشود. آماده سازی عمدتا دو کار انجام میدهد. یکی قالب بندی گراف کلی با ایجاد blob ها و لایه ها و سپس فراخوانی تابع Setup هر لایه و دیگری حسابرسی مواردی از قبیل ارزیابی صحت معماری کلی شبکه. همچنین, در حین آماده سازی, شبکه مراحل آماده سازی خود را با log کردن آن در INFO گزارش میدهد که نمونه ای از این اطلاعات را در زیر مشاهده میکنید:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
I0902 22:52:17.931977 2079114000 net.cpp:39] Initializing net from parameters: name: "LogReg" [...model prototxt printout...] # construct the network layer‐by‐layer I0902 22:52:17.932152 2079114000 net.cpp:67] Creating Layer mnist I0902 22:52:17.932165 2079114000 net.cpp:356] mnist ‐> data I0902 22:52:17.932188 2079114000 net.cpp:356] mnist ‐> label I0902 22:52:17.932200 2079114000 net.cpp:96] Setting up mnist I0902 22:52:17.935807 2079114000 data_layer.cpp:135] Opening leveldb input_leveldb I0902 22:52:17.937155 2079114000 data_layer.cpp:195] output data size: 64,1,28,28 I0902 22:52:17.938570 2079114000 net.cpp:103] Top shape: 64 1 28 28 (50176) I0902 22:52:17.938593 2079114000 net.cpp:103] Top shape: 64 (64) I0902 22:52:17.938611 2079114000 net.cpp:67] Creating Layer ip I0902 22:52:17.938617 2079114000 net.cpp:394] ip <‐ data I0902 22:52:17.939177 2079114000 net.cpp:356] ip ‐> ip I0902 22:52:17.939196 2079114000 net.cpp:96] Setting up ip I0902 22:52:17.940289 2079114000 net.cpp:103] Top shape: 64 2 (128) I0902 22:52:17.941270 2079114000 net.cpp:67] Creating Layer loss I0902 22:52:17.941305 2079114000 net.cpp:394] loss <‐ ip I0902 22:52:17.941314 2079114000 net.cpp:394] loss <‐ label I0902 22:52:17.941323 2079114000 net.cpp:356] loss ‐> loss # set up the loss and configure the backward pass I0902 22:52:17.941328 2079114000 net.cpp:96] Setting up loss I0902 22:52:17.941328 2079114000 net.cpp:103] Top shape: (1) I0902 22:52:17.941329 2079114000 net.cpp:109] with loss weight 1 I0902 22:52:17.941779 2079114000 net.cpp:170] loss needs backward computation. I0902 22:52:17.941787 2079114000 net.cpp:170] ip needs backward computation. I0902 22:52:17.941794 2079114000 net.cpp:172] mnist does not need backward computation. # determine outputs I0902 22:52:17.941800 2079114000 net.cpp:208] This network produces output loss # finish initialization and report memory usage I0902 22:52:17.941810 2079114000 net.cpp:467] Collecting Learning Rate and Weight Decay. I0902 22:52:17.941818 2079114000 net.cpp:219] Network initialization done. I0902 22:52:17.941824 2079114000 net.cpp:220] Memory required for data: 201476 |
دقت کنید که ایجاد شبکه مستقل از دستگاه است یعنی وابسته به اجرا توسط CPU و یا GPU نیست.همانطور که قبلا در این رابطه توضیح داده بودیم blob ها و لایه ها جزییات پیاده سازی ها را از تعریف مدل پنهان میکنند. بعد از ایجاد شبکه, شبکه با تنظیم یک switch که در Caffe::mode() تعریف شده و با Caffe::set_mode() تنظیم میشود, میتواند توسط CPU و یا GPU اجرا شود. لایه ها نیز از روتین های GPU و یا CPU متناظر خود که نتایج یکسانی (حتی در سطح خطاهای عددی) تولید میکنند, استفاده میکنند.switch بین CPU و GPU یکپارچه و مستقل از تعریف مدل است.
فرمت مدل
مدلها بصورت متنی و در قالب protocol buffers تعریف میشوند.(prototxt) در حالی که مدلهای یادگرفته شده در قالب فایلهایی با نام .caffemodel با استفاده از binary protocol buffer سریالایز میشوند (binaryproto)
این فرمت مدل, توسط الگوی protobuf در Caffe.proto تعریف شده است. کدهای موجود در این فایل واضح بوده و بصورت مبسوط کامنت گذاری شده اند. در ادامه بیشتر در این باره توضیح میدهیم.
Caffe به دلایل زیر از Google Protocol Buffer استفاده میکند:
- رشته های دودویی با اندازه حداقلی در زمان serialized شدن
- Serialization بهینه
- فرمت متنی قابل خواندن توسط انسان که با نسخه دودویی آن سازگار است
- پیاده سازیهای بهینه interface آن در زبانهای مختلف بخصوص C++ و Python
تمامی این دلایل باعث انعطاف و بسط پذیری مدلسازی در Caffe میشوند.
[۱] unified
بخش بعدی : توضیحات در مورد Solver
بخش سوم:اینترفیس ها و نحوه اجرا
بخش چهارم:fine-tuning
بخش پنجم:مثال عملی
بابا دستمریزاد حرف نداری داداش
سلام اگه امکانش هست یه clone از ماشین مجازی که لینوکس و caffe رو نصب کردین بگیرید و اینجا قرار بدید ، آخه نصبش زمانبر هست ، از طرفی نمیشه cuda و cunn رو دانلود کرد (تحریم هستم ) ممنون.
سلام.
نصب CPU_only اصلا سخت نیست و براحتی انجام میشه و نیازی هم به cudnn نداره .
اگر هم بخوام با پشتیبانی کارت گرافیک این کارو بکنم برای هر کار گرافیکی نمیشه و حجمش میره بالا. چون کارتهای گرافیکی مختلف compute capability های مختلفی دارن (از بخش ابزارها میتونید لیست کارتها رو با مشخصاتش ببینید).
برای همین عملی نیست.
نکته دیگه اینکه تو ماشین مجازی چون کارت گرافیک وجود نداره نمیشه از cuda , cudnn استفاده کرد و فقط میشه بصورت cpu_only کامپایل کرد. که اگر باز قرار بر این باشه کامپایلش چه در ویندوز چه در لینوکس به مراتب ساده تر از دانلود اون هست.
من سعی میکنم یکی دو ورژن cuda , cudnn رو یه جای دیگه آپلود کنم که کسایی که مشکل دارن بتونن دانلود کنن.
آپدیت :
من سه بیلد مختلف ساختم و تا جایی که تونستم سعی کردم کارتهای گرافیک مختلف پوشش داده بشه .
یک بیلد با پشتیبانی از cudnnv4
یک بیلد با پشتیبانی از کارت گرافیک (۷٫۵ cuda) و بدون پشتیبانی از cudnn
یک بیلد هم CPU_only که نیازی به کارت گرافیک نیست و با سی پی یو اجرا میشه .
در این بیلد ها هم رپرهای متلب (ورژن۲۰۱۴b) و پایتون (ورژن۲) بیلد شده و اماده استفاده هستن .
تموم شد سعی میکنم تو یه پست جداگانه لینک بدم .
خب میتونید از اینجا دانلود کنید : http://deeplearning.ir/آموزش-caffe-بخش-سوم-اینترفیس-ها-و-نحوه-اجرا/
ممنون از وقتتون . راستش بعد از تماشایی ویدیو ها و تحقیق بیشتر و با توجه به گزارش کار هایی که در انتهای ترم http://cs231n.stanford.edu/ ارایه شده بود ، به سمت theano رفتم و در حال یادگیری هستم هر چند caffe به مراتب نسبت به فریم ورک های دیگه ساده تر است اما خوب مختص تصاویر هست و کارهایی خارج از این حوزه نمبشه انجام داد، من دانشجویی ترم دوم هستم و هدفم کار در همین حوزه هست . Theano رو بر روی لینوکس نصب کردم اما برای ترین شبکه های بزرگ به علت نداشتن کارت گرافیک قدرتمند به مشکل برخوردم ، استفاده از دیتابیسی مثل image net برای اموزش واقعا زمان بر هست ، هر چند مدل های pretrained وجود داره اما سعی کردم یه شبکه رو از scratch آموزش بدم . سعی کردم از
http://aws.amazon.com/ که یه فضای کاری با یک gpu قدرتمند در اختیار کاربر قرار میده استفاده کنم اما هنوز گام verification رو نتونستم به اتمام برسونم ، اگه قبلا با این سیستم ابری کار کردید لطفا راهنمایی کنید ، متشکرم
سلام . RNN ها هم به Caffe اضافه شده منتها هنوز داکیومنتشن درست و حسابی نداره .
Torch هم از این نظر فک کنم از Caffe سرتر باشه یه سر به تورچم بزنید بد نیست (و همینطور Deeplearning4J هرچند سرعتش نسبت به دوتای دیگه کمتره)
در مورد aws نه متاسفانه چون تحریم هستیم سرویس به ما نمیدن و امکان خریدش هم نیست.
فکر میکنم اگه موضوع عمومی باشه تو Quora بپرسید احتمالا جواب بگیرید از کسایی که قبلا استفاده کردن
سلام و وقت بخیر
اول بابت آموزشتون تشکر می کنم
ی سوال داشتم در رابطه با بقیه شبکه ها
توی این آموزش فرمودین که از شبکه LeNet استفاده کردین، می خواستم بدونم امکانش هست که من شبکه عصبی خودم رو طراحی کنم و از اون استفاده کنم؟
امکان افزودن حافظه خارجی هست؟
ممنون میشم راهنمایی بفرمایید
سلام
خواهش میکنم .
بله شما میتونید خودتون شبکه اتون رو طراحی کنید. اینکه از leNet استفاده شده فقط برای آشنایی اولیه است.
متوجه سوال آخر نشدم. لطفا بیشتر توضیح بدید.
ممنونم
همونطور که می دونید در حال حاضر با استفاده از یک حافظه خارجی در کنار برخی از شبکه های عصبی موفق به بهبود عملکرد اون شبکه شدند، می خواستم بدونم اینجا هم امکان اضافه کردن یک حافظه خارجی به شبکه عصبی که استفاده می کنیم هست؟ اگر هست، چطوری؟
باز هم خیلی خیلی ممنون
سلام .
خواهش میکنم
نه متاسفانه من به همچین چیزی برنخوردم. ممنون میشم مقاله یا مطلبی که این مساله رو بهش پرداخته معرفی کنید تا ببینم چیه.
علاوه بر اون من ممنون میشم اگه درمورد چیزی صحبت میکنید تا جایی که ممکنه از اصطلاحات زبان اصلی استفاده کنید بجای فارسی تا اینطور منم متوجه بشم و اگر چیزی به چشمم خورده باشه بتونم بگم.
این لینک رو ببینید لطفا : https://www.microsoft.com/en-us/research/publication/recurrent-neural-networks-with-external-memory-for-language-understanding/
سلام خیلی ممنونم از لینکتون.
من RNN کار نکردم برای همین اینو ندیده بودم تا حالا.
Caffe پشتیبانی از RNN اش تازه شروع شده و بعیده بنظرم که این قابلیت رو داشته باشه از طرفی باید حتما سوال کنید چون مستنداتش اصلا کامل نیست و اگرم باشه (یعنی پیاده سازی کرده باشن این قابلیتاش رو )چیزی نیست که ببینید مگه اینکه سوال کنید از توسعه دهندگانش .
تو گروه Caffe هم میتونید سوال کنید ولی ممکنه یکم وقت بگیره .
خیلی ممنون از راهنمایی هاتون 🙂
سلام خسته نباشید
پس از نصب ویژوال استودیو ۲۰۱۳ بعدش باید کودا نصب کنم
چه نسخه ای برای گرافیک۵۴۰M مناسبه؟
بعدش چی ؟
ممنون
سلام
زنده باشید . شما باید cuda 7.5 رو نصب کنید.
احتمالا کارتتون از cudnn v4 پشتیبانی نکنه ولی چک کنید و مطمین بشید . اگر میکرد cudnnرو هم نصب و فعال کنید . (ورژن های قدیمی caffeاز cudnn v3پشتیبانی میکردن اما اخرین ورژن دیگه نمیکنه)
سلام
ببخشید از کجا بفهمم که کارتم ازcudnn پشتیبانی میکنه یا نه؟
و اینکه cudnn یرای ویندوز ۸ چیزی نداره
برای ویندوز ۷ و ۱۰ بود ولی برا ۸ چیزی ندیدم
ممنون
کارتهایی که compute capability بالای ۳ دارن(یعنی ۳ و بالاتر) از cudnn پشتیبانی میکنن .
ویندوز ۷ و ۸ و ۸٫۱ یکی هستن . ویندوز ۱۰ فایل نصب جداگانه داره
سلام
وقت بخیر
ببخشید نصبcudnn مثل نصب opencvمیمونه؟
از گجا بفهمم open cvدرست نصب شده؟
بعد از نصب کودا و اپن سی وی و cudnnکدوم دیپندنسی رو باید نصب کنم؟
ممنون
سلام . نه cudnn یه فایل کمپرس شده اس که دانلود و اکسترکت میکنید به مسیر usr/local/cuda
من لینک اموزش لینوکس رو قبلا تو بخش ابزارها دادم . میتونید از این استفاده کنید :
https://github.com/tiangolo/caffe/blob/ubuntu-tutorial-b/docs/install_apt2.md
هرچند تو صفحه اصلی caffe هم دیپندنسی ها اومده
اینم باید بدونید که caffeجدید از cudnnv4و cudnnv5پشتیبانی میکنه (پشتیبانی از V3 دیگه انجام نمیشه.)
مسیری که تا الان رفتم اینه:
نصب ویژوال استودیو ۲۰۱۳
نصب cuda 7.5
کپی کردن cudnn توی پوشه cuda در درایو نصب ویندوز
بعدش باید برم سراغ نگت ها؟و..؟
ممنون
الان باید تو پوشه windows که در روت caffe هست فایل CommonSettings.props رو ویرایش کنید (پسوند ,example اش رو حذف کنید اول)
بعد تنظیمات مورد نیاز رو اعمال کنید بر اساس توضیحاتی که در بخش ابزارها دادم و . نوع بیلد رو هم از نوع Release انتخاب کنید (پیشفرض Debug هست) بعد بزنید کامپایل کنید.
موقع کامپایل خودش هر دیپندنسی نیاز داشته باشه دانلود میکنه.
ببخشید الان پایتون . anacodia را نصب کردم
چه تنظیمات دیگری لازمه قبل از build?
برای buld باید به کدوم قسمت برم؟
چیز خاصی فکر نکنم باقی مونده باشه. اگه چیزایی که در بخش ابزارها گفتم رو انجام داده باشید نباید مشکلی باشه.
برای بیلد کردن وقتی SOLUTION رو باز میکنید باید بیلد رو روی Release تنظیم کنید مثل شکل زیر:
http://upload.ustmb.ir/uploads/17_161479410995871.jpg
بعد میتونید روی دکمه سبز رنگ بزنید برای کامپایل .
البته شما روی اسم solution همونی که سمت راست مشخصه Caffe Solution راست کلیک کنید و Build All رو انتخاب کنید تا همه چیز کامپایل بشه باهم .
توی commanدستورا رو نوشتم
میرم تو روت cafee، buildنیستش
مراحل اشتباه انجام دادم؟
تو تلگرام پیام بدید یا یه سوال در بخش پرسش و پاسخ ایجاد کنید و تمام گام هایی که انجام دادید رو با تصویر قرار بدید تا همونجا پیگیری کنیم و انشاالله مشکل شما حل بشه اینطور من کمک زیادی نمیتونم بکنم .
ُسلام
ممنون از آموزش فوق العادتون
متاسفانه من این مطالبتون رو برعکس مطالب گذشتتون خوب درک نکردم ، ی چندتا سوال دارم اگر ممکنه لطف کنید راهنماییم کنید
۱- من نتونستم فاسل caffe.proto رو پیدا کنم میشه بگید کجاست ؟
۲-در ابتدای توضیح در مورد لایه ها با یک شکل نحوه ترتیب قرار گیری لایه ها و انتقالات رو نشون دادید لایه بینایی جاش کجاس و دقیقا کارش چیه ؟(اگر ممکنه با مثال توضیح بدید)
۳-در لایه کانولوشن یه پارامتر به نام “group ” تعریف شده ، این طور که من فهمیدم مثلا اگر برابر ۲ باشه ورودی دوقسمت میشه نرون های لایه کانولوشنم دوقسمت و هر قسمت از ورودی فقط به بخشی متناظر خودش در لایه کانولوشن متصل میشه و این اتصال به همین ترتیب در عمق ادامه داره ، حالا سوال من اینه این تقسیم چه جوری انجام میشه (در راستای طول یا عرض یا اصلا رندوم هر نرون میره تو یه دسته ای و در عمق هموا نرون ادامه داره)؟ و کارایی این امر چیه؟
۴-ورودی لایه کانولوشن “n * c_i * h_i * w_i” ، این n که در ابتدا اومده چیه ؟ مگه ورودی عمق *طول*عرض نیست ؟
۵-لایه LRN ، فقط فهمیدم که لایه نرمالسازیه و اینکه کاراییش چیه (خروجی استفاده از این لایه چیه) و انحوه عملیاتش رو اصلا نفهمیدم اگر میشه بیشتر بازش کنید که چه جوری کار میکنه
۶-خطلا چ جوری محاسبه میشه ؟ آیا در forward pass تو هر لایه خطا محاسبه میشه و به لایه بعدی داده میشه و در نهایت این خطا به Loss Layers فرستاده میشه و این لایه با بک پروپگیشن در مرحله backward pass پس هر لایه رو به ترتیب از اخر ه اول اصلا میکنه ؟؟؟ یا اینکه بعد از لایه اتصال کامل خروجی به Loss Layers داده میشه و اون میزان خطا رو محاسبه میکنه و در مرحله backward pass هر لایه رو از اخربه اول اصلاح میکنه ؟
۷-کلیه لایه های Softmax ، Sum-of-Squares / Euclidean ، Hinge / Margin ، Sigmoid Cross-Entropy ، Infogain ، Accuracy and Top-k جز Loss Layers محسوب میشن و در هر شبکه فقط از یکی از آنها اونم یکبار بعد از لایه اتصال کامل استفاده میشود ؟
۸-چرا در تعریف لایه تماما متصل ، تعریف bottom و top را در اخر آوردید در صورتیکه در لایه های دیگر در ابتدا بود فرقی نمیکنه یا تو این لایه اینجوریه؟
۹-لایه های Splitting ، Flattening ، Reshape ، Concatenation ،Slicing که بیشترشون تحت عنوان لایه کاربردی معرفی شدن چه جور لایه ای هستن ؟ کجا معماری استفاده میشن؟ مثل لایه کانولوشن چندبار استفاده میشه یا مث لایه تماما متصل یکبار ؟
وای ببخشید سوالام زیاد شد بقیشو بعد میپرسم انتظار ندارم همه این سوالات رو یکباره جواب بدید میدونم تعدادش زیاده به مرور جواب بدید ممنون میشم
با تشکر
عذر خواهی مجدد برای تعدد سوال
موفق باشید
سلام. خواهش میکنم.
من مختصر توضیح میدم چون سرم واقعا شلوغ هست. شما هم باید یک همتی بکنید پیش نیازها رو بخونید حداقل یا خودتون هم سرچ بکنید اگر متوجه نشدید سوال کنید.
۱.مسیر فایل ممکنه تغییر کرده باشه فعلا مسیرش caffe/src/caffe/proto هست . (یعنی وارد پوشه کفی بعد src و الی اخر)
۲.لایه بینایی منظور لایه ای هست که اشاره به ورودی و خروجی تصویری اون داره . vision_layers الان وجود نداره . قبلا یه هدر فایل بود عملیات ها و خصایص یکسان در این نوع لایه ها از اون مشتق میشد بعدا حذف شد و اطلاعاتش بین لایه های مختلف پخش شده
۳.گروپ اولین بار توسط الکس کریژوسکی ایجاد شد تا مشکل کمبود حافظه اش برطرف بشه. من تاثیری ندیدم ازش .
۴.n تعداد نمونه ها در هر بچ هست
۵.تو بخش دوم یا سوم در موردش توضیح دادم
۶٫خطا از لایه اخر محاسبه میشه و بعد با استفاده از الگوریتم بک پراپرگیشن بر اساس تاثیر هر پارامتر اون خطا اعمال میشه روی اون پارامتر. باید شبکه عصبی رو بخونید بخش بک پراپگیشن.
۷.بله جز لایه های لاس هستن اما بسته به معماری ممکنه از چندتا از اینها هم استفاده بشه. در شبکه های معمولی فقط یکی استفاده میشه.لایه تماما متصل هم میتونه ۰ یا هرتعدادی که هرکس دوست داره استفاده کنه.لزومی به وجود تنها ۱ لایه یا حتما ایکس لایه نیست.
۸.متوجه نشدم اما اگه ترتیب نوشتنشون منظورتونه ترتیب نوشتن مهم نیست.
۹.اینا لایه هایی هستن که اسمشون روشونه برای ایجاد انعطاف بیشتر در طراحی معماری ها قرار داده شدن. یکی توده ورودی رو به چند قسمت تقسیم میکنه یکی برای وصل کردن دوتا توده هبم استفاده میشه و همینطور الی اخر. نه محدودیتی در استفاده از اینها ندارید. معماری مد نظر شما و الگوریتمی که در ذهنتون هست مشخص کننده نوع و تعداد استفاده از این لایه هاس .
ممنون از لطفتون
سلام و عرض ادب
برای ایمپورت کردن
به مسیر زیر رفته
C:\caffe_win-master\caffe_win-master\Build\x64\Release
تا اونو اضافه کنم
۱) باید اونو تو پوشه نصب پایتون کپی کنم؟
۲)چرا pycaffe در C:\caffe_win-master\caffe_win-master\Build\x64\Releaseموجود نیست؟
ممنون
سلام
اون مسیر Release و باید به Path اضافه کنید.
اگر موقع کامپایل بخش مربوط به پایتون رو True کرده باشید یه پوشه بنام pycaffe هم ایجاد میشه اونجا که از اون برای ایمپورت میتونید استفاده کنید.
ببخشیدpycaffe تو بیلد باید باشه دیگه حتما؟
سلام بله.
NOTE: If Python support is enabled, PythonDir (below) needs to be
set to the root of your Python installation. If your Python installation
does not contain debug libraries, debug build will not work.
منظور این توضیحات رو نفهمیدم. باید برم تو پوشه نصب پایتون و ببینم پوشه دیباگ داره یا نه؟
شما به دیباگ نیاز ندارید. این داره میگه که پایین جایی که miniconda نوشته شده (اگه مینی کوندا یا اناکوندا رو نصب نکردید) باید مسیری که پایتون اونجا نصبه رو بدید تا بتونه پایتون و کتابخونه ها و خلاصه هر چیزی که نیاز داره رو پیدا کنه . روت محل نصب پایتون منظور هست.
سلام مهندس جون عزیزت یه کمکی بهم بکن میخوام caffe راه اندازی کنم ولی نمیدونم از کجا شروع کنم همه چیم دانلود کردم وقتی sln میخوام باز کنم یه ارورcudn7 نات فاند میده
سلام .
با یه خط که چیزی مشخص نمیشه برادر من .
شما حداقل یه سوال تو بخش پرسش و پاسخ بپرسید و اون خطایی که میگرید رو قرار بدید به اضافه کارهایی که کردید من همونجا اگه فهمیدم مشکل چیه راهنماییتون میکنم .
سلام من میخام یک شبکه vgg تا لایه پنجم استفاده کنم و بعد دکانولوشن و بعد پارتیشن بندی و یک لایه spatial pyramid و نهایتا لایه تماما متصل استفاده کنم.
میشه خواهشا لطف کنید مراحل درست کار رو بهم بگید.
الان من باید اول vgg رو در caffe/src/caffe/proto فایل تعریف کنم؟بعد لایه دکانولوشن؟
حالا پارتیشن بندی و لایه بعدی رو چطور میتونم تعریف کنم؟
یا اصلا باید کل کد رو در پایتون بنویسم بعد مراحل تست و ترین رو با کفه انجام بدم؟
خواهشا یه توضیحی بدید و اگر منبع خوبی میشناسید در این راستا معرفی کنید.
خیلی ممنونم.
سلام
مثالهایی که در سایت اومده رو مطالعه کنید کاملا متوجه میشید
نه کافیه شما فایلها prototxt رو ویرایش کنید. اگه از VGG میخوایید استفاده کنید کافیه از ModelZoo کفی فایلهاش رو دانلود و خیلی راحت استفاده کنید .
اگرم بخواییو تغییری درش بدید خیلی راحت با notepad یا notepad++ بازش کنید و لایه ها رو کم و زیاد کنید .
میتونید در پایتون هم کد بزنید اما اصلا پیشناد نمیشه
سلام
ممنون از توضیحات خوبتون
اگر امکانش هست لایه Reshape رو توضیح دهید خوب متوجه نشدم dim 0 dim 1 , …
سلام
این لایه در حالت عادی کاربردی نداره صرفا وقتی یک کار خاصی که لازمه اش تغییر شکل ورودی باشه داشته باشید ازش استفاده میشه
اون dim هم بعد توده ورودی هست. در توده ورودی ما بچ داریم کانال داریم طول و عرض داریم . که اینها به این موارد اشاره دارن .
توضیحات reshape رو هم ببینید خوبه
سلام
ببخشید اینکه مباحث blob مطرح شده و اینکه این مباحث در پشت پرده صورت میگیرد آیا نیاز هست به اینکه بدونیم این blobها چجوری ذخیره می شوند یا اینکه چکارهایی پشت پرده صورت میگیرد ضروری هست و اینکه اشاره شده چه موقع از const استفاده شود یا چه موقع از mutable ، آیا دونستن اینها کارساز هست ؟ کجاها بدرد میخورد ؟
در حالت کلی اینجوری برداشت کردم که اطلاعات شبکه در blob ها ذخیره میشوند و بنظرم تنها جایی بدرد میخورند که برای visualization بکار رود
اگر قرار باشه کد بزنید و یا معماری شبکه رو از طریق کد نویسی پیاده کنید و کارهای متفرقه انجام بدید دونستن اینها لازمه .
سلام. من قصد دارم که از نتایج caffe بر روی شبیه ساز شبکه بر تراشه یا NoC یا SoC استفاده کنم. خواستم ببینم آیا امکانش هست؟ منظورتون از پیاده کردن معماری شبکه از طریق کدنویسی همین چیزیه که من گفتم. من قصد دارم مثلا بهترین شبکه برای اتصال چند GPU را برای شبکه های عصبی ارائه دهم.
سلام.متوجه منظور شما نشدم که میخوایید چیکار کنید کمی بیشتر توضیح بدید لطفا
سلام
وقت شما بخیر
خیلی ممنون بابت توضیحات عالی
من سخت افزار کافی برای اجرای کدها ندارم، آیا جایی سروری هست که بشه کد هارو در اون اجرا گرفت؟
سلام.
میتونید اینجا رو چک کنید. از بین سایتهای خارجی سایت فلوید هاب رو میتونید استفاده کنید.
سلام
ممنون از توضیحاتتون
من برای نصب caffe در اوبونتو مراحل زیر رو رفتم
نصب opencv 3
نصب درایور nvidia روی لینوکس
نصب cuda 9.0
نصب cudnn v7
در نهایت به چندین ارور در هنگام کامپایل caffe برخوردم که میگفت یک سری کتابخونه ها کمه که خوشبختانه بعد از نصب اونها تونستم caffe رو در پایتون import کنم.
اما چیزی که خیلی ذهنم رو درگیر کرده اینه که من نصب opencv رو براساس یک دستورالعمل که در نت پیدا کردم انجام دادم که طبق توصیه ی اون opencv رو روی یک محیط مجازی ( virtual environment ) در لینوکس انجام دادم.
اما بعد از اون بقیه ی نیازمندی ها و کامپایل caffe رو خارج اون محیط انجام دادم.
حالا نمی دونم این مسئله در آینده برام مشکلی ایجاد میکنه یا نه ؟؟
سلام. نه مشکلی ندارید فقط هر زمان نیاز به کار با اوپن سی پی داشتید باید وارد اون محیط بشید چون اونجا فعالش کردید.
خیلی ممنون
یک سوال دیگه هم از خدمتتون داشتم. من تازه کار با لینوکس و کفی رو شروع کردم و به هیچ عنوان نمی دونم برای شروع کار با کفی با از کجا شروع کنم. توضیحات شما بسیار مفید بود اما سوال من اینجاست که این فایل های مربوط به معماری شبکه توسط چه نرم افزاری و در کجا باید ایجاد بشه ؟؟
سلام. یا با اسکریپت پایتون طراحی میشه یا دستی تو نوت پد یا هر ادیتور دیگه ای طراحی میشه.
آموزش کفی که اینجا هست رو بخونید مشخصه. بعدش هم به مثالهای notebook تو پوشه اگزمپلز نگاه کنید خوبه.
سلام در مورد فایل .caffemodel چجوری ایجاد می شه ؟؟ و دقیقا کارش چیه ؟؟
سلام فایل caffemodelحاوی وزنهای یادگرفته شده مدل شماست و از اون برای تست یا فاین تون استفاه میشه.
یعنی شما میرید روی دیتاستتون مدلتون رو اموزش میدید بعد به یک دقت خوب میرسید حالا یه snapshotمیگیرید و خروجی میشه یک فایل با فرمت caffemodel بعد از این فایل برای بارگذاری وزنهای یادگرفته شده و اجرای برنامه مورد نظرتون استفاده میکنید (مثلا تشخیص یک حیوان یا …. )
میتونید با مشخص کردن snapshot iteration در سالور مشخص کنید در هر چند تکرار در میون ساخته بشه این فایل (مثلا هر ۵۰۰ تکرار یا هر ۱ ایپاک یک اسنپ شات تولید بشه) . یا اینکه میتونید از طریق زبان سی++ یا رپر پایتون بصورت مستقیم دستور رو اجرا کنید (برای اینکار البته باید خودتون فرایند ترینینگ رو کدنویسی کنید )
سلام ببخشید من قصد دارم داخل پروژم از کفی استفاده کنم. قصد دارم کفی رو به پروژم اضاف کنم. برای اضاف کردن کفی به سی میک چه کاری باید انجام بدم که هنگام اینکلود کردنش به مشکل نخورم؟
سی میک یکسری کانفیگ فایل داره اونها رو تنظیم کنید نباید مشکلی داشته باشید
البته کار راحت تر اینه از پروژه ایجاد شده توسط سی میک استفاده کنید و فایلای خودتون رو منتقل کنید اونجا اینطور دیگه نگران برطرفکردن خطاهای مربوط به پیدا نکردن پیش نیازها نیستید