

بسم الله الرحمن الرحیم
این بخش سوم آموزش شبکه های کانولوشن هست که طبق معمول بروز میشه بخشهای مختلفش(منظورم بیشتر بخش دستاوردهای جدید هست (لایه های جدید و تغییرات این حوزه )). بخش بک پراپگیشن رو انشاالله تو یه پست جداگانه میزارم اینجا بزارم بد میشه (چون توضیحات خاص خودشو داره و اینطور بهتره)
پیاده سازی بصورت ضرب ماتریسی :
توجه کنید که عملیاتی که در بالا انجام دادیم به کانولوشن معروف است (یا به فارسی ضرب پیچشی (با تشکر از خانم سلیمیان) (در اصل به همین دلیل است که به این لایه لایه کانولوشن گفته میشود!) این عملیات ضرب نقطه ای(یعنی هر عنصر را با عنصر نظیر خود ضرب کردن) را بین ناحیه محلی ورودی با فیلتر انجام میدهد . یک روش رایج در پیاده سازی لایه کانولوشن بهره بردن از همین اصل است بدین صورت که عملیات forward pass یک لایه کانولوشن را بصورت یک ضرب ماتریسی که شرحش در زیر رفته است به انجام برسانیم و اینگونه پیاده سازی ای بسیار سریع و کارا ارائه کنیم(بجای ضرب ترتیبی عناصر, همه عناصر با هم در یک زمان ضرب شوند و نتیجه حاصل شود) :
ابتدا هر کدام از نواحی محلی در تصویر ورودی را به ستون تبدیل میکنیم (این عملیات به im2col معروف است).بعنوان مثال اگر ورودی ما حجمی بصورت ۲۲۷x227x3 داشته باشد و بخواهیم آنرا با فیلترهایی با اندازه ۱۱x11x3 به همراه stride s =4 ضرب پیچشی (convolve) کنیم(نکته در انتهای متن و کامنت رو ببینید), بلوکهایی با اندازه ۱۱x11x3 پیکسل را به یک بردار ستونی با اندازه ۱۱x11x3=363 تبدیل میکنیم . با تکرار این عمل بر روی ورودی با گام ((stride S=4 ناحیه در طول عرض و ارتفاع بدست میدهد که نهایتا باعث ایجاد ماتریس خروجی X_col با اندازه [۳۶۳×۳۰۲۵] خواهد شد که هر ستون این ماتریس یک ناحیه ادراکی (receptive field) بوده و تعداد ۵۵×۵۵=۳۰۲۵ نمونه از آنها در کل وجود خواهد داشت. دقت کنید از انجایی که نواحی ادراکی با هم اشتراک دارند (overlap) هر عدد در توده خروجی ممکن است چندین بار در ستونهای مختلف تکرار شود.
وزنهای شبکه کانولوشن هم به همین شکل به بردار های سطری تبدیل میشوند. بعنوان مثال اگر ۹۶ فیلتر(منظور مجموعه وزنها میباشد) با اندازه ۱۱x11x3 وجود داشته باشد (تعداد وزنها برابر با تعداد عناصر موجود در ناحیه ادراکی است یعنی اگر اندازه ناحیه ادراکی برابر با ۱۱x11x3 است بنابر این به همین تعداد وزن نیز وجود دارد) این عمل باعث ایجاد ماتریس W_row با اندازه [۹۶×۳۶۳] خواهد شد.
حالا نتیجه عملیات کانولوشن (ضرب نقطه به نقطه) برابر با اجرای یک ضرب ماتریسی بزرگ خواهد بود. (np.dot(W_row, X_col)) . این عملیات نتیجه ضرب نقطه ای بین تمام فیلترها و تمام نقاط نواحی ادراکی را بما خواهد داد. در مثال ما خروجی این عملیات یک ماتریس با اندازه [۹۶ x 3025] خواهد بود که نتیجه ضرب نقطه ای بین هر فیلتر در هر موقعیت را میدهد.
نهایتا نتیجه بالا بایستی دوباره به فرم صحیح آن بصورت [۵۵x55x96] تغییر شکل داده شود.
نکته منفی این روش مصرف حافظه بالای آن است چرا که بعضی از مقادیر در توده ورودی چندین بار در X_col تکرار شده اند. اما از طرف دیگر نکته مثبتی که این روش دارد این است که پیاده سازی های بسیار بهینه ای از ضرب ماتریس ها در کتابخانه های مختلفی همانند BLAS وجود دارد که میتوان از آنها بهره برد و به کارایی و افزایش سرعت بالایی دست پیدا کرد . علاوه بر آن میتوان از این ایده در عملیات Pooling که در ادامه به آن خواهیم پرداخت نیز استفاده کرد .
عملیات BackPropagation
عملیات Backpropagation برای یک عملیات کانولوشن (هم برای داده و هم وزن ها ) هم یک عملیات کانولوشن (اما با فیلترهای از لحاظ مکانی برعکس شده (spatially filipped filters) ) میباشد.
لایه Pooling
قرار دادن یک لایه Pooling بین چندین لایه کانولوشنی پشت سر هم در یک معماری کانولوشن امری رایج است . کارکرد این لایه کاهش اندازه مکانی (عرض و ارتفاع) تصویر (ورودی) بجهت کاهش تعداد پارامترها و محاسبات در داخل شبکه و بنابر این کنترل overfitting است .لایه Pooling بصورت مستقل بر روی هر برش عمقی از توده ورودی عمل کرده و آنرا با استفاده از عملیات MAX از لحاظ مکانی تغییر اندازه (resize) میدهد. رایجترین شکل استفاده از این لایه به صورت استفاده این لایه با فیلترهایی با اندازه ۲×۲ به همراه stride S=2(گام) است که هر برش عمقی در ورودی را با حذف ۲ عنصر از عرض و ۲ عنصر از ارتفاع کاهش داده و باعث حذف ۷۵% مقادیر موجود در آن برش عمقی میشود. هر عملیات MAX در اینجا ماکسیمم بین ۴ عدد (یک ناحیه ۲×۲ در برش عمقی) را بدست میدهد. در اینجا بُعد عمق بدون تغییر باقی میماند.
بطور کلی لایه Pooling :
یک توده با اندازه W1 x H1 x D1 را بعنوان ورودی دریافت میکند که W نشانگر عرض , H نشانگر ارتفاع و D نشانگر عمق آن میباشد.
نیازمند ۲ فراپارامتر است :
- اندازه وسعت مکانی(اندازه x , y) فیلترها )اندازه ناحیه ادراکی) F
- اندازه گام یا Stride S
یک توده خروجی با اندازه W2 x H2 x D2 تولید میکند که :
- (یعنی عرض و ارتفاع هر دو بطور مساوی بصورت متقارن محاسبه میشوند)
بواسطه اینکه این لایه یک تابع ثابت از ورودی را محاسبه میکند هیچ پارامتری به شبکه اضافه نمیکند.
دقت کنید که استفاده از zero padding در لایه pooling عمومیت ندارد و این کار صورت نمیگیرد.
این نکته حائز اهمیت است که تا بحال در عمل لایه max pooling به دو صورت ,بیشتر رایج بوده و مورد استفاده قرار گرفته است . صورت اول آن با F=3 و S=2 (که به overlapping pooling معروف است) طراحی شده و صورت دوم که رایج تر است با F=2 و S=2 طراحی میشود. عملیات Pooling با نواحی ادراکی بزرگتر بیش از حد مخرب بوده و به همین دلیل در عمل معمولا یکی از دو حالت فوق مورد استفاده قرار میگیرند.
General Pooling
علاوه بر max pooling واحدهای pooling قادر به اجرای توابع دیگری نظیری average pooling و یا حتی L2-norm pooling نیز هستند.Average pooling در ابتدا اغلب مورد استفاده قرار میگرفت تا اینکه اخیرا در قیاس با max pooling که در عمل ,عملکرد بهتری از خود ارائه داده است گرایش به آن از بین رفته است.
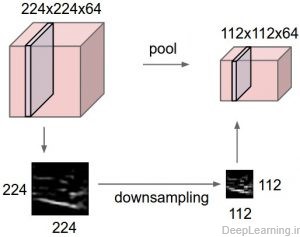
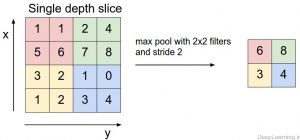
نمایش لایه max-pooling و چگونگی کاهش ابعاد
لایه Pooling توده ورودی را در هر برش عمقی بصورت مستقل(یعنی هر برش بدون توجه به برش دیگر) از لحاظ مکانی کاهش میدهد (اصطلاحا downsample میکند). تصویر سمت چپ: در این مثال توده ورودی با اندازه ای برابر با [۲۲۴x224x64] را با اندازه فیلتر F=2 و Stride S=2 به توده خروجی با اندازه [۱۱۲x112x64] کاهش داده شده است. توجه کنید که عمق توده بدون تغییر حفظ شده است . تصویر سمت راست : رایجترین عملیات downsampling عملیات max است که به همین علت به این لایه ,لایه max pooling گفته میشود اینجا از stride با اندازه ۲ استفاده شده است. به عبارت ساده تر این به این معناست که ماکسیمم ۴ عدد گرفته شده است (یک مربع ۲×۲ کوچک.)
Backpropagation
(توضیحات بصورت جداگانه در یک پست دیگه ارائه میشه)
دستاوردهای جدید در این حوزه :
Fractional Max Pooling روشی را جهت انجام عملیات pooling پیشنهاد میکند که در آن از فیلترهای کوچکتر از اندازه ۲×۲ استفاده میشود. این روش با تولید تصادفی نواحی pooling همراه با فیلترهایی با اندازه ۱×۱ , ۱×۲ , ۲×۱ و یا ۲×۲ به منظور پوشش سطح نگاشت فعال سازی انجام میشود. این Grid ها بصورت تصادفی در هر forward pass ایجاد میشوند و در زمان آزمایش (Test time) میتوان با میانگین گیری از چندین grid به تخمینی در این زمینه دست پیدا کرد .(state of the art دیتاست Cifar10 با این روش بدست اومده!)
Striving for Simplicity: The All Convolutional Net پیشنهاد حذف لایه pooing در ازای استفاده از معماری ای که در آن تنها از لایه های تکراری کانولوشن استفاده شده است را میدهد. به منظور کاهش اندازه تصویر, آنها استفاده از گام های بزرگتر در لایه کانولوشن را بصورت هر از چندگاهی, پیشنهاد میکنند.
بواسطه کاهش شدید در اندازه تصویر[۱] (که تنها برای دیتاست های کوچک برای کنترل با overfitting سودمند است) , گرایش مقاله ها به سمت حذف لایه Pooling در شبکه های کانولوشن جدید است.
(در زیر لیستی از لایه های جدید این حوزه رو میبینید اونهایی که توضیح ندارن و مابقی بعدا بروز میشن انشاالله )
لایه Normalization
تعداد زیادی لایه Normalization جهت استفاده در معماری های شبکه های کانولوشن پیشنهاد شده اند که بعضی اوقات بقصد پیاده سازی طرحهای بازداری [۲]که در مغز انسان مشاهده شده است بوده اند. اما این لایه ها اخیرا از مد افتاده اند چرا که در عمل میزان اثربخشی آنها حتی در صورت وجود بسیار ناچیز بوده است. [۳]
Lateral inhibitiondh یا همون بازداری جانبی, در بینایی برای افزایش شفافیت سیگنالهای ورودی به مغز مورد استفاده قرار میگیرن. در انتها هم این بحث بیشتر توضیح داده شده.
این بخش هم توضیحاتی هست که من در ایمیل در این باره به یکی از دوستانی که سوال کرده بودن در این رابطه دادم :
سلام…….داستانش هم از این قراره که تو نوروبایولوژی (عصب شناسی) ما یه مفهومی داریم بنام Lateral inhibition که به فارسی شاید گفت منع جانبی . یعنی چی؟ این مفهوم به ظرفیت یک نورون برانگیخته شده برای بی اثر کردن(یا کاهش اثر) همسایه هاش اشاره داره.اساسا ما به یه افزایش قابل توجه نیاز داریم تا یه شکلی از ماکسیمای محلی داشته باشیم . این مسئله باعث ایجاد کنتراست در اون ناحیه میشه و بنابر این بلطبع باعث افزایش درک حسی(یا sensory perception) میشه. افزایش درک حسی چیز خوبیه برای همین هم در ابتدا در شبکه کانولوشن سعی در پیاده سازیش کردن .این لایه این مفهوم رو که تازه صحبتش رو کردیم سعی میکنه پیاده کنه . این لایه زمانی که ما با نورونهای ReLU سرو کار داریم مفید هست دلیلش هم اینه که نورونهای ReLU فعالسازی های نامحدود (unbounded) دارن و ما به LNR نیاز داریم تا اوناو نرمالیزه کنیم . ما میخوایم ویژگی های فرکانس بالا با پاسخهای بزرگ رو کشف کنیم. اگه ما عملیات نرمالسازی رو در همسایگی محلی نورون برانگیخته انجام بدیم حساسیت بنسبت به همسایه هاش باز بیشتر میشه. در همین زمان این کار باعث تعدیل پاسخ هایی که بصورت یکنواخت بزرگ در هر همسایگی هستن میشه. اگه تمامی مقادیر بزرگ باشن نرمالسازی اونها باعث کاهش همه اونا میشه بنابر این ما میخوایم نوعی از inhibition یا بازداری رو ایجاد کنیم و نرونهای با برانگیختگی بزرگ رو تقویت کنیم. این مساله توضیحش تو بخش ۳٫۳ مقاله کریژوسکی اومده (لینک)اطلاعات بیشتر در مورد Lateral inhibition رو میتونید از اینجا بخونیدمن تو ترجمه inhibition scheme رو طرح های باز داری معناش کردم.
لایه تماما متصل (Fully Connected layer)
نورونهایی که در یک لایه تماما متصل قرار دارند با تمام نورون های موجود در لایه قبلی ارتباط دارند دقیقا همانند همان چیزی که در شبکه های عصبی معمولی دیده میشود. بنابراین میتوان از ضرب ماتریسی و سپس جمع نتیجه حاصله با بایاس جهت محاسبه خروجی تمامی نورون ها (فعالسازی ها) در یک لحظه استفاده کرد . بطور خلاصه تمامی قوانین مطرحی در شبکه های عصبی معمولی در این بخش صادق است .
لایه Batch-Normalization:
لایه ELU:
لایه PReLU:
تبدیل لایه های تماما متصل به لایه های کانولوشنی Converting Fully connected layers to convolutional layers))
ذکر این نکته حائز اهمیت است که تنها تفاوت بین یک لایه تماما متصل و کانولوشنی این است که نورون ها در لایه کانولوشن تنها به یک ناحیه محلی از ورودی متصل هستند و پارامترها را با یکدیگر به اشتراک میگذارند. البته نورونها در هر دو لایه ضرب نقطه ای را انجام میدهند بنابر این شکل عملکردی (functional form) آنها یکسان بوده و همانطور که در ادامه خواهید دید تبدیل این دولایه به یکدیگر کاملا ممکن و عملی است.
به ازای هر لایه کانولوشن لایه تماما متصلی وجود دارد که دقیقا همان تابع forward را پیاده سازی میکند. ماتریس وزن در این حالت ماتریس بزرگی خواهد بود که تمام درایه های آن به غیر از بلوکهای خاصی (بواسطه اتصال محلی) که وزنها در بسیاری از آنها با یکدیگر برابر اند (بواسطه اشتراک پارامتر) صفر است.
به همین شکل میتوان هر لایه تماما متصل را به یک لایه کانولوشن تبدیل کرد . به عنوان مثال یک لایه تماما متصل با K = 4096 فیلتر که به توده ورودی ای با اندازه ۷x7x512 نگاه میکند را میتوان بصورت یک لایه کانولوشنی با ناحیه ادراکی با اندازه F=7 , P=0 zero padding , S=1 گام یا stride و K=4096 فیلتر ایجاد کرد . به عبارت دیگر در اینجا ما اندازه فیلتر(ناحیه ادراکی) را دقیقا برابر با اندازه توده ورودی قرار میدهیم و اینطور اندازه خروجی برابر با ۱x1x4096 میشود چرا که تنها یک ستون عمقی را میتوان در توده ورودی جای داد که این دقیقا باعث نتایج یکسان با لایه تماما متصل اولیه میشود.
تبدیل لایه تمام متصل به لایه کانولوشنی (FC>CONV conversion)
از بین این دو تبدیل, تبدیل لایه تماما متصل به لایه کانولشنی در عمل مفیدتر است . بعنوان مثال یک معماری شبکه کانولوشن را در نظر بگیرید که یک تصویر با اندازه ۲۲۴x224x3 را بعنوان ورودی دریافت میکند و سپس از مجموعه ای از لایه های کانولوشنی و Pooling جهت کاهش اندازه تصویر به اندازه ۷x7x512 استفاده میکند (در معماری Alexnet که در ادامه با آن آشنا میشوید, این عمل توسط ۵ لایه Pooling که اندازه ورودی را با فاکتور ۲ هر بار کاهش داده تا آنکه آنرا به اندازه ۲۲۴/۲/۲/۲/۲/۲ =۷ برساند, انجام میشود ). در ادامه AlexNet از ۲ لایه تماما متصل با اندازه ۴۰۹۶ استفاده کرده و سپس در لایه تماما متصل آخر با ۱۰۰۰ نورون امتیاز دسته ها (class scores) را حساب میکند. ما با توجه به نکات گفته شده در بالا میتوانیم این شبکه های تماما متصل را به شبکه کانولوشنی معادل آنها تبدیل میکنیم . برای این کار بصورت زیر عمل میکنیم :
اولین لایه تماما متصل را که به توده ای با اندازه ۷x7x512 نگاه میکند با یک لایه کانولوشنی که از فیلتر با اندازه F=7 استفاده میکند تعویض میکنیم تا توده خروجی با اندازه ۱x1x4096 بدست بیاید.
لایه تماما متصل دوم را با یک لایه کانولوشنی که از فیلتر با اندازه F=1 استفاده میکند عوض میکنیم تا توده خروجی با اندازه ۱x1x4096 را بدست بیاوریم.
نهایتا آخرین لایه کانولوشن را مثل مرحله قبل با یک لایه کانولوشنی که از فیلتر با اندازه F=1 استفاده میکند تعویض میکنیم تا خروجی نهایی ۱x1x1000 حاصل شود.
هر کدام از این تبدیلات لایه تماما متصل به لایه کانولوشنی در عمل ممکن است نیازمند تغییراتی (نظیر تغییر شکل / تغییر ابعاد) در ماتریس وزن W باشد. در ادامه مشخص میشود که این تبدیل به ما اجازه میدهد تا در یک forward pass بصورت بسیار بهینه ای موقعیت های مکانی زیادی را در تصاویر بزرگتر پیمایش کنیم.
به عنوان مثال اگر تصویری با اندازه ۲۲۴×۲۲۴ توده ای با اندازه ۷x7x512 نتیجه دهد , این به معنای کاهش ۳۲ برابری است , بنابر این forwarding یک تصویر ۳۸۴×۳۸۴ پیکسلی در یک معماری تبدیل شده , همان توده را با اندازه ۱۲x12x512 نتیجه خواهد داد .چرا که ۳۸۴/۳۲=۱۲ . با گذشت از ۳ لایه کانولوشنی بعدی که ما تازه از لایه تماما متصل تبدیل کرده ایم توده نهایی با اندازه ۶x6x1000 نتیجه خواهد شد چرا که (۱۲ – ۷)/۱ + ۱ = ۶ میشود. توجه کنید که بجای یک بردار حاوی امتیاز کلاسها با اندازه ۱x1x1000 , ما حالا یک آرایه ۶×۶ کامل از امتیاز کلاسها از تصویر ۳۸۴×۳۸۴ پیکسلی را بدست می آوریم .
انجام عمل Forwarding در شبکه کانولوشن تبدیل شده برای یکبار بسیار بهینه تر از تکرار آن در شبکه کانولوشن اصلی در تمام ۳۶ مکان است چرا که این ۳۶ ارزیابی محاسبات مشترک دارند. این نکته اغلب در عمل برای بدست آوردن کارایی بهتر در زمانهایی که مثلا تغییر اندازه تصویر به تصویر بزرگتر رایج است مورد استفاده قرار میگیرد.نحوه استفاده به این صورت است که از یک شبکه کانولوشن تبدیل شده جهت ارزیابی امتیاز دسته ها در نقاط مکانی زیادی استفاده شده و سپس میانگین این امتیازات گرفته میشود.
سوال: اگر ما قصد این را داشتیم تا بطور بهینه ای شبکه کانولوشن اصلی را بر روی تصویر با stride کمتر از ۳۲ پیکسل اعمال کنیم آنوقت چطور میتوانستیم این عمل را به انجام برسانیم ؟ ما میتواتسنیم از چندیدن forward pass برای این منظور استفاده کنیم . بعنوان مثال دقت کنید اگر ما میخواستیم از stride با اندازه ۱۶ پیکسل استفاده کنیم ما میتوانستیم با ترکیب توده های دریافتی توسط عمل forwarding در شبکه کانولوشن تبدیل شده در دوبار این کار را انجام دهیم . بار اول آن را بر روی تصویر اصلی و بار دوم بر روی تصویری که ۱۶ پیکسل از لحاظ مکانی در راستای عرض و ارتفاع تغییر کرده است اعمال کنیم .[۴]
ConvNet Architectures
تا به اینجای کار ما دیدیم که شبکه های عصبی تنها از سه لایه Conv , Pool (بصورت پیشفرض ما Max Pool را در نظر میگیریم مگر اینکه خلاف آن عنوان شود) و لایه FC (یا تماما متصل) تشکیل میشوند. همچنین ما تابع فعال سازی RELU را در قالب یک لایه که تابع فعال سازی را بر روی تک تک عناصر اعمال میکند در نظر میگیریم . در این بخش ما خواهیم دید که چگونه این لایه ها با یکدیگر ترکیب شده و یک شبکه عصبی کانولوشن را تشکیل میدهند.
Layer Patterns
رایجترین شکل یک معماری شبکه عصبی کانولوشن ترکیب چند لایه Conv-RELU است که بعد از آنها لایه های POOL قرار میگیرند و این قالب یا طرح انقدر تکرار میشود تا تصویر ورودی به اندازه دلخواه کوچک شود. معمولا در این زمان است که از لایه های تماما مرتبط استفاده میشود. آخرین لایه تماما متصل حاوی خروجی نظیر امتیاز دسته ها میباشد . به عبارت دیگر رایجترین معماری شبکه عصبی کانولوشن طرحی همانند زیر دارد :
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
که در اینجا *نشانه تکرار و POOL? هم به معنای وجود یک لایه POOLing اختیاری است. معمولا مقادیر N,M و K بصورت N>=0 (و معمولا N<=3 ) , M>=0 , K>=0 (و معمولا K<3) میباشند. در زیر شما میتوانید تعدادی از معماری های رایج شبکه کانولوشن را مشاهده کنید :
- INPUT -> FC
معماری فوق یک کلاسیفایر خطی را پیاده سازی میکند. در اینجا مقادیر N = M = K همگی برابر با ۰ هستند
- INPUT -> CONV -> RELU -> FC
- INPUT -> [CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC
در اینجا نیز شاهد هستیم که هر لایه کانولوشن بین ۲ لایه POOLing قرار گرفته است
- INPUT -> [CONV -> RELU -> CONV -> RELU -> POOL]*3 -> [FC -> RELU]*2 -> FC
در اینجا هم میبینیم که دو لایه کانولوشن قبل از هر لایه Pooling قرار گرفته اند . بطور کلی این شیوه برای شبکه های بزرگ و عمیق ایده خوبی است چرا که چندین لایه کانولوشن ترکیب شده ویژگی های پیچیده تر بیشتری از توده ورودی قبل از اینکه توسط عملیات Pooling از بین بروند میتواند بدست بیاورد.
معمولا سعی کنید از ترکیب لایه کانولوشن با فیلتر کوچکتر نسبت به لایه کانولوشنی با اندازه ناحیه ادراکی(فیلتر) بزرگتر استفاد کنید. فرض کنید شما سه لایه کانولوشن با اندازه فیلتر ۳×۳ را با هم ترکیب میکنید (دقت کنید که بین این لایه ها هم لایه RELU وجود دارد) با این ترتیب هر نورون در لایه کانولوشن اول یک دید ۳×۳ از توده ورودی دارد . یک نورون که در لایه کانولوشن دوم قرار دارد یک دید ۳×۳ از لایه کانولوشن اول و به همین صورت یک دید ۵×۵ از توده ورودی دارد.به همین شکل یک نورون در لایه کانولوشن سوم یک دید ۳×۳ از لایه کانولوشن دوم دارد و از این جهت یک دید ۷×۷ هم از توده ورودی دارد. فرض کنید بجای این سه لایه کانولوشن ۳×۳ (منظور با اندازه فیلتر ۳×۳ است) ما فقط بخواهیم از یک لایه کانولوشن به همراه نواحی ادراکی با اندازه ۷×۷ استفاده کنیم . نورون های موجود در این لایه دارای اندازه ناحیه ادارکی خواهند بود که برابر با اندازه توده ورودی است (۷×۷) که البته این کار کاستی ها و مشکلاتی نیز به همراه دارد. مشکل اول این است که در این حالت, نورون ها یک تابع خطی از ورودی را محاسبه میکنند در حالی که ترکیب سه لایه کانولوشن در حالت قبل ,یک تابع غیر خطی از ورودی را که باعث بیان بهتر ویژگی های ورودی میشود محاسبه میکند. دومین مشکل این است که اگر فرض کنیم تمام توده ها C کانال داشته باشند بنابر این یک لایه کانولوشن ۷×۷ تعداد ![]() پارامتر خواهد داشت در حالی که سه لایه کانولوشن ۳×۳ تنها
پارامتر خواهد داشت در حالی که سه لایه کانولوشن ۳×۳ تنها ![]() پارامتر خواهند داشت. همانطور که دیدیم ترکیب لایه های کانولوشن با اندازه فیلتر کوچک در مقابل استفاده از یک لایه کانولوشن با اندازه فیلتر بزرگتر بما اجازه میدهد تا ویژگی های قدرتمندتر بیشتر را با پارامترهای کمتری از ورودی را بیان کنیم . در حالت اول هم مشکلی که وجود دارد اگر قصد استفاده از backpropagation را داشته باشیم نیاز به حافظه بیشتری نسبت به حالت دوم است
پارامتر خواهند داشت. همانطور که دیدیم ترکیب لایه های کانولوشن با اندازه فیلتر کوچک در مقابل استفاده از یک لایه کانولوشن با اندازه فیلتر بزرگتر بما اجازه میدهد تا ویژگی های قدرتمندتر بیشتر را با پارامترهای کمتری از ورودی را بیان کنیم . در حالت اول هم مشکلی که وجود دارد اگر قصد استفاده از backpropagation را داشته باشیم نیاز به حافظه بیشتری نسبت به حالت دوم است
Layer Sizing Patterns
تا به اینجا ما صحبتی از فراپارامترهای رایجی که در هر لایه یک شبکه کانولوشن مورد استفاده قرار میگیرند نکردیم . در اینجا ما ابتدا قوانین کلی مرتبط با مدیریت اندازه معماری های شبکه کانولوشن را بیان کرده و سپس به این قوانین به همراه توضیحی از نمادها میپردازیم .
لایه ورودی (Input layer) ( که حاوی تصویر ورودی است ) باید چندین بار بر ۲ قابل تقسیم (پخش پذیر ) باشد. اعداد رایح در این زمینه شامل ۳۲ (مثلا تصاویر موجود در دیتاست CIFAR-10 ) 64 , 96 (مثل تصاویر موجود در دیتاست STL-10 ) و یا ۲۲۴ (مثل شبکه های ImageNet متداول) ,۳۸۴ و ۵۱۲ هستند.
لایه های کانولوشن باید از فیلتر هایی کوچک (مثل ۳×۳ و یا نهایتا ۵×۵ ) با Stride S =1 و خصوصا zero padding توده ورودی بصورتیکه لایه کانولوشن ابعاد مکانی (عرض و ارتفاع) توده ورودی را تغییر ندهد استفاده کنند. به عبارت ساده تر این به این معناست که زمانی که F=3 باشد استفاده از zero padding با مقدار P=1 ابعاد اصلی ورودی را حفظ خواهد کرد. به همین ترتیب زمانی که F=5 باشد zero padding با مقدار P=2 باعث حفظ ابعاد ورودی خواهد شد . برای یک مقدار F کلی , میتوان نشان مشاهده کرد که باعث حفظ اندازه ورودی میشود. اگر به هر دلیلی نیازمند استفاده از فیلترهایی با اندازه های بزرگتر باشیم (مثلا فیلترهایی با اندازه ۷×۷ ) , باید عنوان کنیم که تنها استفاده از این اندازه در لایه اول کانولوشن که مستقیما به تصویر ورودی نگاه میکند متداول است .
لایه های Pooling وظیفه downsample کردن یا کاهش دادن ابعاد مکانی (عرض و ارتفاع) ورودی را دارند. رایجترین تنظیمات برای این لایه استفاده از max pooling به همراه ناحیه ادراکی با اندازه ۲×۲ ( یعنی F=2) و stride با مقدار S=2 میباشد. توجه کنید که این پیکربندی لایه pooling باعث نابودی ۷۵% مقادیر در توده ورودی میشود ( بخاطر downsampling 2 عنصر هم در ارتفاع و هم درعرض ). یک پیکربندی کمتر متداول دیگر نیز وجود دارد که در آن از نواحی ادراکی با اندازه ۳×۳ و stride با مقدار S=2 استفاده میشود. استفاده از نواحی ادراکی با اندازه ای بزگتر از این مقدار در لایه pooling بسیار نادر است چرا که در این صورت این لایه بیش از حد پراتلاف خواهد شد( یعنی بیش از حد داده ها را حذف میکند) و معمولا این کار باعث بدتر شدن کارایی نیز میشود.
طرحی که در بالا مشاهده کردید از این جهت جذاب است که لایه های کانولوشن همگی اندازه مکانی ورودی خود را حفظ میکنند. در حالی که لایه های POOL به تنهایی مسئول کاهش اندازه توده ها هستند. در روش های دیگری که ما از stride هایی با مقادیر بیشتر از ۱ استفاده میکنیم و یا در لایه های کانولوشن از zero padding در ورودی استفاده نمیکنیم, لازم است که با دقت بسیار زیادی توده های ورودی در سرتاسر شبکه کانولوشن را تحت نظر داشته و اطمینان حاصل کنیم تمامی stride ها و فیلتر ها با همدیگر سازگار بوده و همخوانی داشته باشند و معماری شبکه کانولوشن بصورت متقارن و مناسبی بهم متصل باشد.
چرا باید از stride با مقدار ۱ دریک لایه کانولوشن استفاده کرد؟
در عمل مقادیر کوچک stride بهتر عمل میکنند. علاوه بر آن همانطور که قبلا گفته شد, stride با مقدار ۱ بما اجازه میدهد تا وظیفه downsampling را به عهده لایه Pooling بگذاریم و لایه های کانولوشن به وظیفه خود که تبدیل توده ورودی از بصورت عمقی است بپردازند.
چرا باید از padding استفاده کرد ؟
علاوه بر فایده حفظ اندازهای مکانی (عرض و ارتفاع) بعد از لایه های کانولوشن که قبلا هم به آن اشاره شد, انجام این کار در واقع باعث افزایش کارایی میشود.. اگر در لایه های کانولوشن در ورودی از zero padding استفاده نمیکردیم, و تنها عمل کانولوشن را انجام میدادیم , در اینصورت اندازه تودهها بعد از هر لایه کانولوشن به میزان کمی کاهش می یافت و اطلاعات موجود در مرزها(ی بیرونی توده) بسیار سریع از بین میرفتند.
اعمال تغییرات با توجه به محدودیت های حافظه
در بعضی حالات, (خصوصا در ابتدای معماری های شبکه عصبی کانولوشن) میزان مصرف حافظه با قوانین ارائه شده در بالا بسرعت افزایش پیدا میکند. بعنوان مثال فیلتر کردن یک تصویر با اندازه ۲۲۴x224x3 با سه لایه کانولوشن و ۶۴ فیلتر با اندازه ۳×۳ و zeropadding برابر P=1 باعث ایجاد یک توده با اندازه ۲۲۴x224x64 خواهد شد. این میزان برابر با ۱۰ میلیون عدد و یا ۷۲ مگابایت حافظه (به ازای هر تصویر هم برای اعداد و هم گرادیانت آنها) است. از آنجایی که GPU های فعلی توسط حافظه bottleneck شده اند شاید نیاز به تغییراتی در این زمینه باشد. در عمل افراد ترجیح میدهند تا تنها تغییرات را در لایه کانلووشن اول شبکه اعمال کنند. بعنوان مثال, یک تغییر میتواند استفاده از فیلتر با اندازه ۷×۷ و stride S=2 در لایه کانولوشن اول باشد ( همانطور که در شبکه ZF دیده میشود). نمونه دیگر AlexNet است که از فیلترهایی با اندازه ۱۱×۱۱ و Stride با مقدار S=4 در لایه کانولوشن اول خود استفاده کرد.
مطالعات موردی
در حوزه شبکه های کانولوشنی چندین معماری وجود دارد که نام اختصاصی دارند. معروف ترین آنها را در زیر مشاهده میکنید .
شبکه LeNet:
اولین کاربردهای موفقیت امیز شبکه های عصبی کانولشن توسط Yann LeCun در سال ۱۹۹۰ توسعه داده شدند. از میان آنها, معماری LeNet معروفترین آنهاست که برای خواند کدهای پستی , ارقام و… مورد استفاده قرار گرفته بود.
معماری AlexNet
اولین نمونه ای که شبکه های عصبی را در Computer Vision به محبوبیت رساند AlexNet بود. این معماری توسطAlex Krizhevsky , Ilya Sutskever و Geoff Hinton توسعه داده شد. AlexNet در رقابت ILSVRC در سال ۲۰۱۲ ارائه داده شد و توانست با اختلاف فاحشی نسبت به جایگاه دوم به پیروزی برسد. این شبکه اساس معماری شبیه LeNet داشت با این تفاوت که عمیقتر, بزرگتر بود و همچنین از ترکیب چندین لایه کانولوشن با هم استفاده میکرد ( در گذشته یک لایه کانولوشن که بعدش یک لایه Pool قرار میگرفت رایج بود )
ZF
برنده رقابت ILSVRC 2013 شبکه کانولوشنی بود که توسط Matthew Zeiler و Rob Fergus توسعه پیدا کرده بود. بعدها این شبکه به نام ZF که مخفف نام توسعه دهندگان آن است معروف شد. این معماری ورژن بهینه شده ای از AlexNet بود که با تغییر فراپارامترهای معماری , بطور خاص با افزایش اندازه لایه های کانولوشن میانی این بهینه سازی انجام شده بود.
GoogLeNet
برنده رقابت ILSVRC 2014 هم شبکه عصبی کانولوشنی بود که توسط Szegedy et al از طرف گوگل توسعه داده شده بود . ویژگی جدیدی که این معماری عرضه کرده بود توسعه یک ماجول مفهومی (Inception Module ) بود که بشدت تعداد پارامترهای شبکه را کاهش میداد ( ۴ میلیون پارامتر را با ۶۰ میلیون پارامتر AlexNet مقایسه کنید!)
VGGNet
برنده جایگاه دوم در رقابت ILSVRC 2014 شبکه عصبی کانولوشنی بود که توسط Karen Simonyan و Andrew Zisserman توسعه داده شده بود که بعدها با نام VGGNet معروف شد.ویژگی جدیدی که این معماری عرضه کرده بود , این بود که نشان داد عمق شبکه یک مولفه حیاتی برای کارایی خوب است. ورژن نهایی بهترین شبکه آنها شامل ۱۶ لایه CONV/FC و بصورت خوش آیندی یک معماری بشدت همگن (homogeneous ) که تنها دارای فیلتر با اندازه ۳×۳ در لایه کانولوشن و فیلتر ۲×۲ در لایه pooling از ابتدا تا به انتها بود. بعدا مشخص شد که برخلاف قدرت کمتر دسته بندی نسبت به GoogLeNet , VGGNet در چندین وظیفه یادگیری انتقالی (Multiple transfer learning tasks) از GoogLeNet بهتر عمل میکند. بنابر این شبکه VGG در حال حاضر محبوبترین انتخاب برای Feature extraction از تصاویر است . بطور خاص مدل از پیش آموزش داده شده آنها برای استفاده در کتابخانه Caffe وجود دارد . یک کاستی این شبکه این است که حافظه مصرفی و تعداد پاراامتر بسیار زیادی دارد (۱۴۰ میلیون پارامتر )
توضیحات بیشتر VGGNET
VGGNet از لایه های کانولوشن با اندازه فیلتر ۳×۳ , stride برابر ۱ و zero padding برابر P=1 و لایه های Pooling با اندازه فیلتر ۲×۲ با همراه stride برابر با S=2 و بدون هیچ zero paddingیی تشکیل شده است . در زیر ما اندازه هر تصویر در هر مرحله را ثبت میکنیم اینطور میتوانیم هم اندازه تصویر و تعداد کلی وزنها را تحت نظر داشته باشیم .
INPUT: [224x224x3] memory: ۲۲۴*۲۲۴*۳=۱۵۰K weights: 0
CONV3-64: [224x224x64] memory: ۲۲۴*۲۲۴*۶۴=۳٫۲M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: ۲۲۴*۲۲۴*۶۴=۳٫۲M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: ۱۱۲*۱۱۲*۶۴=۸۰۰K weights: 0
CONV3-128: [112x112x128] memory: ۱۱۲*۱۱۲*۱۲۸=۱٫۶M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: ۱۱۲*۱۱۲*۱۲۸=۱٫۶M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: ۵۶*۵۶*۱۲۸=۴۰۰K weights: 0
CONV3-256: [56x56x256] memory: ۵۶*۵۶*۲۵۶=۸۰۰K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: ۵۶*۵۶*۲۵۶=۸۰۰K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: ۵۶*۵۶*۲۵۶=۸۰۰K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: ۲۸*۲۸*۲۵۶=۲۰۰K weights: 0
CONV3-512: [28x28x512] memory: ۲۸*۲۸*۵۱۲=۴۰۰K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: ۲۸*۲۸*۵۱۲=۴۰۰K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: ۲۸*۲۸*۵۱۲=۴۰۰K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: ۱۴*۱۴*۵۱۲=۱۰۰K weights: 0
CONV3-512: [14x14x512] memory: ۱۴*۱۴*۵۱۲=۱۰۰K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: ۱۴*۱۴*۵۱۲=۱۰۰K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: ۱۴*۱۴*۵۱۲=۱۰۰K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: ۷*۷*۵۱۲=۲۵K weights: 0
FC: [1x1x4096] memory: ۴۰۹۶ weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: ۴۰۹۶ weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: ۱۰۰۰ weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
همانطور که در شبکه های کانولوشنی متداول است , میبینید که بیشترین حافظه مصرفی در لایه های کانولوشن ابتدایی مصرف شده اند و بیشترین تعداد پارامترها نیز در لایه های تماما متصل آخر وجود دارند. در این مورد خاص, اولین لایه تماما متصل دارای ۱۰۰ میلیون وزن از ۱۴۰ میلیون وزن موجود در سراسر شبکه میباشد.
ResNet:(برنده رقابت ایمیج نت در سال ۲۰۱۵ با ۱۵۲ لایه)
NiN:
ملاحظات محاسباتی :
بزرگترین گلوگاهی که باید در زمان ساخت یک معماری شکبه کانولوشن مد نظر قرار دهید حافظه است . بسیاری از GPU های جدید حافظه ای با اندازه ۳, ۴ و ۶ گیگابایت دارند و تنها مدلهای معدودی دارای حافظه های بیشتری نظیر ۱۲ گیگابایت هستند که میتوان در این بین به سری تایتان ایکس شرکت انویدیا اشاره کرد. مواردی که در زیر لیست شده اند مهمترین منابع حافظه ای هستند که باید زیرنظر گرفته شوند.[۵]
اندازه توده های لایه میانی :
اینها تعداد اعداد در هر لایه کانولوشن و همچنین گرادیانت های(با اندازه مساوی) آنها هستند. معمولا بیشترین تعداد این مقادیر در لایه های ابتدایی شبکه کانلولشن ( لایه های کانولوشن اول) وجود دارد. اینها بخاطر انکه برای backpropagarion مورد نیاز هستند نگهداری میشوند. اما یک پیاده سازی هوشمندانه که شبکه کانولوشن را تنها در زمان آزمایش اجرا میکنید, میتواند در اصل با ذخیره مقادیر فعلی در هر لایه و حذف مقادیر قبلی در لایه های پایینی بشدت این مقدار را کاهش دهد.
اندازه پارامترها :
اینها همان اعدادی هستند که پارامترهای شبکه , گرادیانتهای آنها در زمان backpropagation و معمولا هم یک مرحله cache درصورتی که از momentum , Adagrad , و یا RMSProp استفاده میکنند را در خود نگه میدارند. بنابر این حافظه ای که برای ذخیره سازی بردار پارامتر استفاده میشود معمولا باید حداقل با فاکتور ۳ یا عددی در این حدود ضرب شود.
هر پیاده سازی شبکه کانولوشن نیازمند نگهداری حافظه متفرقه مثل image data batches و شاید ورژن اافزایش یافته انها و… باشد .
زمانی که شما یک تخمین کلی از تمام مقادیر (برای خروجی نرونها, گرادیانت آنها و موارد متفرقه ) بدست اوردید . حال باید آنرا به گیگابایت تبدیل کنید . تعداد اعداد را گرفته و آنرا در ۴ ضرب کنید تا تعداد بایتهای مورد نیاز را بدست آورید ( چون هر عدد اعشاری در ۴ بایت ذخیره میشود و یا اگر از دابل استفاده میکنید در ۸ ضرب کنید ) و سپس چندیدن بار بر ۱۰۲۴ تقسیم کنید تا به مقدار حافظه به کیلوبایت , مگابایت و نهایتا گیگابایت برسید . اگر شبکه شما در حافظه جا نمیشود یک روش ابتکاری جهت جای دادن آن کاهش اندازه batch است چرا که بیشترین میزان حافظه معمولا توسط خروجی نرونها مصرف میشود.
بصری سازی آنچه شبکه عصبی کانولوشن یاد میگیرد
چندین روش برای فهمیدن و نمایش بصری اطلاعات درونی یک شبکه عصبی کانولوشن در تحقیقات سالهای اخیر توسعه و ارائه شده است که تا حدودی بعنوان پاسخی به انتقاد معمول ” ویژگی های یاد گرفته شده در شبکه های عصبی قابلیت تفسیر ندارند” بودند. در این بخش ما بصورت خلاصه وار تعدادی از این روشها و کارهای مرتبط را مورد بررسی قرار میدهیم.
نمایش بصری (Visualizing) مقادیر فعال سازی و وزن های لایه اول :
مقادیر فعال سازی در لایه ها :
سرراست ترین روش نمایش بصری , نمایش مقادیر فعال سازی شبکه در حین forward pass است. برای شبکه های ReLU , فعال سازی ها معمولا ابتدا بشکل لکه های متراکم شروع شده و بعد با ادامه پیدا کردن آموزش (training) این فعال سازی ها پراکنده تر و محلی تر میشوند. یک نکته بسیار مهم که در اینجا با نمایش بصری قابل مشاهده است, این است که بعضی نگاشتهای فعال سازی ممکن است تماما برای تعداد زیادی ورودی صفر باشند. که این به معنای فیلترهای از کار افتاده (dead filter) بوده و میتواند نشانه ای از overfitting باشد.


یک نمایش بصری از مقادیر فعال سازی در اولین لایه کانولوشن.
تصویر اول: نمایش بصری مقادیر فعال سازی در اولین لایه کانولوشن تصویر دوم: نمایش بصری مقادیر فعال سازی در پنجمین لایه کانولوشن در یک شبکه AlexNet آموزش دیده که در حال نگاه به تصویر یک گربه است هر مربع نمایش داده شده در بالا, یک نگاشت فعال سازی متناظر با تعدادی فیلتر است. توجه کنید که مقادیر این فعال سازی ها پراکنده ( بیشتر مقادیر صفر هستند که در این نمایش بصری بصورت سیاه نمایش داده شده اند) و محلی هستند.
فیلتر های لایه کانولوشن و تماما متصل (Conv/FC Filters):
روش دوم نمایش بصری وزنهاست. معمولا وزنها در لایه کانولوشن اول که مستقیما به مقادیر پیکسل های خام تصویر نگاه میکنند قابل تفسیرترین پارامتر هستند, اما نمایش بصری وزنهای عمیقتر(وزنها در لایه های عمیقتر شبکه) در شبکه هم ممکن است . نمایش بصری وزنها به این دلیل مفید است چون که شبکه هایی که بخوبی آموزش دیده اند معمولا فیلترهای خوب و یکنواختی را بدون هیچ قالب نویزداری (noisy patterns) نمایش میدهند. قالب های نویزدار میتوانند نشانه شبکه ای باشند که به اندازه کافی آموزش ندیده است و یا احتمالا نشانه regularization ضعیفی باشد که باعث overfitting شده است .
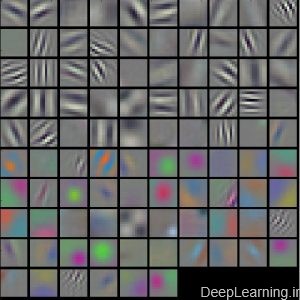

یک نمایش بصری از فیلترهای یادگرفته شده در لایه کانولوشن اول
تصویر اول : نمایش بصری فیلترها در لایه کانولوشن اول تصویر دوم : نمایش بصری فیلترها در لایه کانولوشن دوم یک شبکه AlexNet آموزش دیده. توجه کنید که وزن های لایه اول خیلی خوب و یکنواخت هستند که نشانه همگرایی خوب شبکه است. ویژگی های رنگی و سیاه و سفید (color/grayscale) به این دلیل با هم دسته بندی شده اند چون AlexNet دارای دو جریان پردازش جداگانه است که نتیجه آشکار این معماری این است که یک جریان ویژگی های سیاه و سفید فرکانس بالا را ایجاد کرده و جریان دیگر ویژگی های رنگی فرکانس پایین را ایجاد میکند. وزنهای لایه کانولوشن دوم به این اندازه(لایه اول) قابل تفسیر نیستند اما مشخص است که آنها هنوز هم یکنواخت, خوش فرم و عاری از هرگونه قالب نویزدار هستند.
بدست آوردن دوباره تصاویری که بصورت بیشنه ای یک نورون را فعال میکنند (Retrieving images that maximally activate a neuron)
یک روش دیگر نمایش این است که یک دیتاست عظیم از تصاویر را گرفته و شبکه را توسط این تصاویر تغذیه کنیم و در این حین , کنترل کنیم کدام تصاویر بعضی از نورون ها را بصورت بیشینه ای فعال میکنند. . ما سپس میتوانیم برای بدست اوردن درکی از انچه که نورون دارد بدنبال آن در ناحیه ادراکی خود میگردد با نمایش این تصاویر برسیم . یکی از این نمایش های بصری ( از میان سایر روشها), روشی است که در مقاله ” Rich feature hierarchies for accurate object detection and semantic segmentation ” توسط Ross Grshick et al توضیح داده شده است.

تصاویری که نورون های لایه Pooling پنجم در یک شبکه AlexNet را به بیشترین میزان فعال کرده اند. مقادیر فعال سازی و ناحیه ادراکی یک نورون مشخص با رنگ سفید نمایش داده شده است. (بصورت خاص, توجه کنید که نورون های لایه Pool5 (پنجمین لایه Pooling ) تابعی از یک قسمت نسبتا بزرگ از تصویر ورودی هستند ). میتوان دید که بعضی از نورون ها نسبت به بالا تنه, متن, و یا نقاط درخشان حساس هستند.(واکنش میدهند)
یک اشکال این روش این است که نورون های لایه ReLU الزاما هیچ معنایی به تنهایی ندارند. بلکه مناسبتر این است که چندین نورون لایه ReLU را بعنوان بردارهای اولیه (basis vectors) بعضی فضاها که نمایانگر پچ های تصاویر(image patches) هستند در نظر بگیریم . به عبارت دیگر, نمایش بصری(visualization), در حال نمایش patchهایی که در لبه توده ای از تصاویر(at the edge of cloud of representation) , در راستای محورهایی (اختیاری) که متناظر با وزنهای فیلتر هستند, است. میتوان این مسئله را از این واقعیت مشاهده کرد که نورونها در شبکه کانولوشن بصورت خطی در فضای ورودی عمل میکنند بنابر این چرخش اختیاری فضا ممکن نیست. این نکته در مقاله ای بنام Intriguing properties of neural networks توسط Szegedy et al مورد بررسی بیشتر قرار گرفت که در آن آنها نمایش بصری مشابه ای را در راستای جهت های دلخواه در فضای نمایشی (تصویر) انجام دادند.
Embedding the codes with t-SNE
شبکه های عصبی کانولوشن را میتوان بعنوان تبدیل تدریجی تصاویر به نمایش هایی که در آن دسته ها (کلاسها) توسط یک کلاسیفایر خطی جدا شده اند, در نظر گرفت. ما میتوانیم به ایده خوبی در باره توپولوژی این فضا با تعبیه تصاویر در دو بعد بصورتی که نمایش بُعد پایین دارای فاصله های نسبتا یکسان نسبت به نمایش بُعد بالای آنها است برسیم . روش های تعبیه سازی زیادی توسعه داده شده اند که از بصیرت(intuition) تعبیه بُردارهای با بعد بلند در فضای با بعد کوتاه در حالی که فاصله های متقابل از هم حفظ شده اند استفاده میکنند. در میان آنها t-SNE یکی از معروفترین روشهایی است که نتایج از لحاظ بصری زیبایی را تولید میکند.
برای تولید یک تعبیه, ما میتوانیم مجموعه ای از تصاویر را گرفته و از شبکه عصبی کانولوشن برای استخراج کدهای CNN استفاده کنیم .( مثلا در AlexNet بردار ۴۰۹۶ بعدی دقیقا قبل از کلاسیفایر (دسته بندی کننده), و بطور حیاتی شامل غیرخطی ReLU ) . ما سپس اینها را وارد یک t-SNE کرده و یک بردار دو بعدی برای هر تصویر بدست میاوریم. تصاویر متناظر سپس میتوانند در قالب یک grid به نمایش در آیند.

تعبیه t-SNE مجموعه ای از تصاویر بر اساس کدهای CNN آنها.
- تصاویری که در کنار هم قرار دارند در فضای نمایش CNN هم بهم نزدیک هستند, که به معنای آن است که CNN آنها را بسیار شبیه به هم “میبیند”. دقت کنید که شباهت اغلب مبتنی بر کلاس (دسته) و معنایی بوده تا مبتنی بر رنگ و پیکسل. برای اطلاعات بیشتر در چگونگی تولید این نمایش , سورس کد آن و نمایش های مرتبط بیشتر در مقیاس های متفاوت به [۶]t-SNE visualization of CNN codes. مراجعه کنید.
مسدود سازی بخشهایی از تصویر
فرض کنیدکه یک شبکه عصبی کانولوشن تصویری را بعنوان تصویر یک سگ دسته بندی میکند. حالا یک سوال مهم, ما چطور میتوانیم مطمئن باشیم که شبکه در اصل دارد سگ را انتخاب میکند و نه اطلاعات محتوایی از پس زمینه و یا اشیاء دیگری در تصویر را؟ به عبارت دیگر چطور مطمئن شویم که شبکه واقعا سگ را شناسایی کرده و صرفا جواب دسته بندی آن بخاطر وجود اطلاعات دیگری در تصویر نیست ؟ یک راه برای فهمیدن اینکه پیشبینی شبکه از کدام بخش از تصویر دارد می آید این است که احتمال دسته دلخواه (در اینجا دسته سگ ها) را بعنوان یک تابع از مکان یک شی مسدود شده رسم کنیم . این یعنی اینکه ما بر روی نواحی مختلف تصویر حرکت کرده و یک پچ را بر روی تصویر قرار دهیم که تمام آن ناحیه را برابر صفر قرار دهد.و بعد به احتمال کلاس نگاه کنیم . ما میتوانیم احتمال را بصورت یک نقشه گرمایی (heat map) 2 بعدی نمایش دهیم . این روش در مقاله Mathew Zeiler با عنوان Visualizing and Understanding Convolutional Networks آمده است .
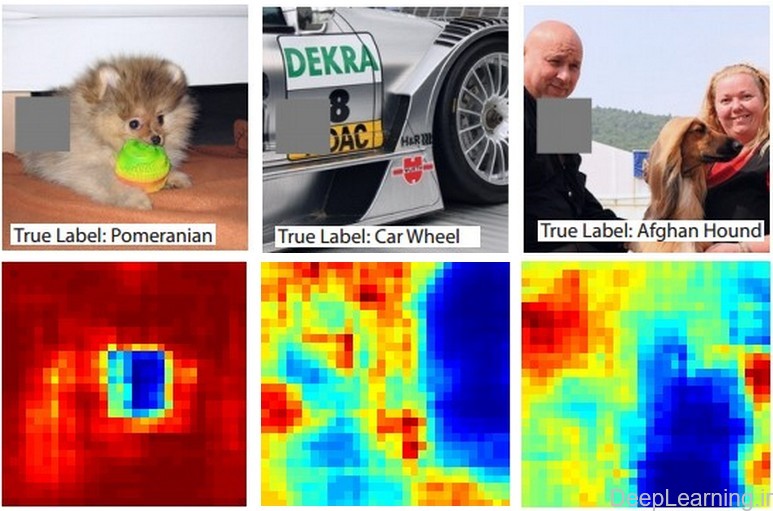
سه تصویر ورودی (در بالا) و heatmap های متناظر با هر کدام (در پایین)
- دقت کنید که ناحیه مسدود کننده بصورت خاکستری نشان داده شده است. در همان حین که ما مسدود کننده را بر روی تصویر حرکت میدهیم (میلغزانیم/اسلاید میکنیم) احتمال کلاس صحیح را نیز ثبت کرده و سپس آنرا بصورت یک heatmap ( که در زیر هر تصویر نمایش داده شده است) نمایش میدهیم. بعنوان مثال در سمت چپ ترین تصویر ما میبینیم که احتمال تصویر سگ Pomeranian زمانی که مسدود کننده صورت سگ را میپوشاند کاهش پیدا میکند و اینطور ما بسطحی از اطمینان میرسیم که در اصل این صورت سگ است که باعث امتیاز بالای دسته بندی میشود. حال بطور برعکس , میبینیم که صفر کردن بقیه نواحی تصویر تاثیر نسبتا ناچیزی در امتیاز کلاس دارد که باز موید نتیجه قبلی است . یعنی صورت سگ مسئول بیشترین امتیاز کسب شده تصویر برای دسته بندی بوده و مابقی اجزای تصویر تاثیر بسیار ناچیزی در امتیاز مورد نظر داشته اند.
[۲] inhibition schemes
[۳] برای اطلاعات بیشتر در این زمینه میتوان به Cuda-convnet Library API آقای Alex Krizhevsky مراجعه کرد.
[۴] میتوانید نحوه انجام این تبدیل را در عمل در قالب کد (با استفاده از کتابخانه Caffe ) در Net Surgery مشاهده کنید.
[۵] با ورود نسل جدید کارتهای گرافیکی انویدیا در معماری پاسکال ما شاهد افزایش حجمی حافظه و همینطور کارایی این کارتها در حوزه یادگیری عمیق و خصوصا محسابات مورد نیاز شبکه کانولوشن هستیم. در زمان بروز آوری این نگارش کارتهای GTX1070,GTX1080 با ۸ گیگابایت رم از سری جدید معرفی شده اند (اما هنوز به بازار وارد نشده اند)
[۶] http://cs.stanford.edu/people/karpathy/cnnembed/
توضیحات Lateral inhibition
در مورد local response normalization یک مطلبی تو یکی از وبلاگها قبلا دیده بودم که اینجا نقل به مضمونش رو گذاشتم جالب توضیح داده (لینکش رو پیدا کردم قرار میدم الان یادم نمیاد کجا بود) در زیر هم ترجمه Lateral inhibition رو از ویکی پیدیا رو گذاشتم اینم بگم که مطلب زیردر ویکی پیدیا با تصاویر بخوبی نمایش داده شده که دیدنش خالی از لطف نیست. اینم بگم که لایه normalization که بالا توضیحش اومده بعنوان مثال تو دیتاست ImageNet طبق گزارش اومده در مقاله VGGNet تاثیر (چندانی) نداشته برای همین در مدل VGGNet بعنوان مثال استفاده نشده . (این مدل مقام دوم کلسیفیکیشن ایمیج نت و مقام اول دیتکشن رو کسب کرده در سال ۲۰۱۴)
بازداری بصری یا Visual Inhibition
lateral inhibition یا بازداری جانبی باعث افزایش کنتراست و شفافیت (sharpness) در پاسخ بصری میشود. این پدیده بعنوان مثال در شبکیه چشم پستاندارن رخ میدهد.در تاریکی یک محرک نوری کوچک باعث بهبود فوتو ریسپتورها (rod cells یا سلولهای میله ای)ی مختلف میشود.
سلولهای میله ای در مرکز محرک نوری سیگنال “روشن” را به مغز منتقل میکنند در حالی که سلولهای میله ای دیگر در خارج محرک سیگنال “تاریک” را به مغز ارسال میکنند.این تفاوت بین روشنایی و تاریکی باعث ایجاد تصویری شفافتر(sharper) میشود. این مکانیزم همنچنین باعث ایجاد اثر بصری باند ماخ (Mach Band) میشود.
بازداری جانبی بینایی (Visual Lateral inhibition) فرایندی است که در آن سلولهای فوتو ریسپتور به مغز در درک تفاوت موجود در یک تصویر کمک میکنند. نور الکترومغناطیسی وارد چشم شده و سپس از قرنیه مردم و سپس لنز چشم عبور کرده و سپس از سلولهای ganglion,amacrine,bipolar و سلولهای افقی گذشته تا به سلولهای میله ای فوتو ریسپتور که نور را جذب میکنند برسد. این سلولهای میله ای بوسیله انرژی موجود در نور تحریک شده و یک سیگنال عصبی محرک را به سمت سلولهای افقی آزاد میکند .
سیگنال محرک اما تنها از طریق سلولهای میله ای در مرکز ناحیه ادراکی سلول Ganglion قابل انتقال است چرا که سلولهای افقی با ارسال یک سیگنال بازداری به سلولهای میله ای همجوار برای ایجاد توازنی که به پستاندارن اجازه درک تصاویر واضح تر را میدهد پاسخ میدهند.
سلولهای ganglion شبکیه کماکان یک پاسخ عصبی محرک را تنها از سلول میله ای مرکزی دریافت خواهند کرد. سلول میله ای مرکزی پاسخ عصبی محرک خود را مستقیما به سلولهای bipolar ارسال میکند این سلولها هم سپس این سیگنال را به سمت سلولهای ganglion باز ارسال میکنند._سلولهای bipolar نقش رله را ایفا میکنند)
بازداری ایجاد شده توسط سلولهای افقی باعث ایجاد سیگنال متوازن تر و متمرکز تری برای سلولهای ganglion شبیکه میشود که متعاقبا به کورتکس سلبرال از طریق عصب بینایی ارسال میشوذ.
توضیحات در مورد Convolve:
یک توضیح مهم اینه که convolve به معنای ضرب نقطه به نقطه نیست .در اصل به معنای ضرب پیچشی هست (با تشکر از سرکار خانوم سلیمیان که معادل فارسی رو لطف کردن). عملیات کانولوشن یعنی ضرب مولفه به مولفه یا همون عنصر به عنصر دوماتریس با هم (در اینجا ناحیه ادراکی از ورودی با ماتریس وزن که ما بهش میگیم فیلتر ) نکته ای که باید دقت کنید اینه که در تعریف کانولوشن یکی از دو ماتریس جای سطر و ستونهاش برعکس میشه و بعد بین ماتریس حاصل و ماتریس اول ضرب مولفه به مولفه انجام میشه) و سپس جمع همه عناصر ماتریس حاصل با هم . یعنی وقتی دو ماتریس با هم ضرب شدن بصورت مولفه به مولفه یک ماتریس سوم حاصل میشه (آموزش شبکه کانولوشن بخش دوم – بخش انتهایی اون رو ببینید جایی که ۱۰ ۲۰ تا تصویر من گذاشتم! ) . حالا درایه های ماتریس سوم رو با هم جمع باید کرد این میشه عملیات کانولوشن که تو درس computer vision بچه ها میخونن و ازش تو کارهای مختلف استفاده میکنن.
نکته مهم بعدی اینه که شما تو آموزش بالا و همینطور احتمالا ۱۰۰ درصد بقیه اموزشهای یادگیری عمیق میبنید که خبری از برعکس کردن یا بهتر بگم چرخش (flip)سطر و ستون نمیبینید! هرچی هست خیلی معمولی تو ماتریس رو مولفه به مولفه ضرب و بعد هم درایه ها رو با هم جمع میکنن و بعنوان خروجی ارائه میکنن. دلیل این مساله اینه که کاری که در اصل اینجا اتفاق داره میوفته کانولوشن نیست! correlation هست. کاری که ما داریم میکنیم اینجا discrete correlation بهش میگن که تو شبکه های عمیق نتیجه معادل discrete convolution رو بما میده . برای همین تقریبا همه کتابخونه ها و چارچوبهایی که تو این حوزه دارن کار میکنن کانولوشن رو بصورت correlation پیاده سازی میکنن.
(برای درک بهتر کانولوشن در حالت کلی میتونید اینجا و اینجا رو هم ببینید)
من هم تو متن برای اینکه هی convolve رو تکرار نکنم و احیانا باعث گیج کردن کسی نشم بجاش از کلمه ضرب نقطه ای (و بعد جمع!) استفاده کردم. حالا اگه معادل بهتری براش میشناسید به فارسی لطفا راهنمایی کنید تا متن ویرایش بشه.
معادل فارسیش هم که لطف کردن به ابتدای این بخش اضافه کردم در جاهای دیگه اگر چیزی دیدید لطفا اطلاع بدید که معادل فارسیش رو من بزارم .
با تشکر
یک توضیح مهم اینه که convolve به معنای ضرب نقطه به نقطه نیست . عملیات کانولوشن یعنی ضرب مولفه به مولفه یا همون عنصر به عنصر دوماتریس با هم (در اینجا ناحیه ادراکی از ورودی با ماتریس وزن که ما بهش میگیم فیلتر) و سپس جمع همه عناصر ماتریس حاصل با هم . یعنی وقتی دو ماتریس با هم ضرب شدن بصورت مولفه به مولفه یک ماتریس سوم حاصل میشه (آموزش شبکه کانولوشن بخش دوم – بخش انتهایی اون رو ببینید جایی که ۱۰ ۲۰ تا تصویر من گذاشتم! ) . حالا درایه های ماتریس سوم رو با هم جمع باید کرد این میشه عملیات کانولوشن که تو درس computer vision بچه ها میخونن و ازش تو کارهای مختلف استفاده میکنن.(البته باز این عملیات کورولیشن هست که بعنوان نکته اخر اموزش اشاره کردم و توضیح کامل دادم و گفتم که اینجا بطور خاص معادل عملیات کانولوشن هست)
من هم تو متن برای اینکه هی convolve رو تکرار نکنم و احیانا باعث گیج کردن کسی نشم بجاش از کلمه ضرب نقطه ای و بعد جمع! استفاده کردم.
[…] لایه نرمال سازی پاسخ محلی (local response normalization layer) نوعی از lateral inhibition را با نرمال سازی بر روی نواحی ورودی محلی به انجام […]
یه ممنون آقای حسن پور
عالی بود…واقعا برای کسی که تازه میخواد یادگیری عمیق و شبکه کانولوشن کار کنه اینهمه مطلبی ک شما اینحا جمع کردید واقعا یه نعمت بزرگه…باتوجه به اینکه اینا همه حاصل اینهمه مدت زحمت شما هستن واقعا امیدوارم جواب اینهمه خوبی و زحمتتون رو ببینید به بهترین نحو ممکن…
موفق و تندرست باشید
سلام
خدا رو شکر که براتون مفید بود.
خیلی ممنونم همینطور شما
در پناه حق موفق و سربلند باشید
سلام.
درباره شبکه عصبی کانولوشنی ، چند تا سوال داشتم. فقط امیدوارم زود جواب بدید ، چون متاسفانه فرصتم خیلی کم هست. تشکر.
۱- در شبکه عصبی کانولوشنی چند لایه کانولوشن و پولینگ پشت هم قرار می گیرند. و : هر کرنل با لایه قبل کانوالو میشه و در تابع فعالسازی قرار داده میشه و فیچر مپ خروجی رو تولید میکنه. // من جاهای مختلف در مورد این شبکه دیدم که تابع فعالساز بعد از دو لایه (کانولوشن و پولینگ / دوباره : کانولوشن و پولینگ ، که اینجا اصلا فعالساز استفاده نکرده) تازه یعد از لایه بعدی کانولوشن اومده تابع فعالساز استفاده کرده ؟ (من اینو هم تو مقاله ها و حتی تو یه کد دیدم) برای جای سوال هست که آیا در لایه های اول تایع فعالساز استفاده نمیشه و نیازی نیست ؟ یا استفاده میشه ؟
۲- و یه سوال دیگه که برام پیش اومده اینه که اگر من کدی بنویسم برای این شبکه ،آیا میشه وقتی کد اجرا میشه فهمید که تعداد ویژگی هر بار که بعد از کانولوشنی کاهش پیدا میکنه ، تعداد ویژگی هامون چند تا میشه؟ یا نمیشه و فقط باید در توضیحات گفت که تعداد ویژگی لایه کانولوشن بعد از استفاده از لایه پولینگ ، کاهش پیدا میکنه ، اما ما نمیتونیم دقیقا متوجه بشیم تعداد ویژگی رو نمیتونیم با عدد بگیم که این مقدار شده ؟
۳- دسته بندی تو این شبکه با ویژگی های استخراجی از آخرین لایه کانولوشنی انجام میشه… من برای مقایسه با سایر الگوریتم ها ، باید بیام تعداد ویژگی رو کاهش بعد بدم. درسته ؟ یه سوال که برام ایجاد میشه اینه که وقتی من با تعداد ویژگی های مختلف مثلاً ۵۰ ، ۱۰۰ ، ۱۵۰ شبکه رو تست میکنم با الگوریتم های مثل ماشین بردار پشتیبان و پارامترهای ارزیابی مثل حساسیت و … رو بدست میارم ، الان سوالم اینجاست البته یکم از شبکه کانولوشنی فاصله گرفتم! ببنید ما میگیم هر چقدر تعداد ویژگی بیشتر باشه کارایی دسته بندی بالاتر میره.. خب اگه این در همه پارامترهای ارزیابی اینطور نباشه ، یعنی هر چقدر تعداد ویژگی ما بیشتر بشه امتیاز پارامترهای ارزیابی ما صعود نکنه بلکه نزول کنه ، این چرا اینطور میشه؟
۳- من میخوام برای پروژه ام ساختار شبکه کانولوشنی رو مثل مقاله ها ، داشته باشم .. همون ساختاری که کانولوشن ، پولینگ ، و fully connected هست … این ساختار رو من با چه نرم افزاری میتونم رسم کنم و در پروژه ام بذارم ؟ (چون صددرصد این ساختار در اجرای کد مربوط به این برنامه تولید نمیشه)
سلام.
۱٫نه این ربطی به این نداره.معمولا شما همیشه بعد کانولوشن تابع فعال سازیش رو قرار میدید مگه اینکه بجای یکبار بخوایید به هر دلیلی چندبار عمل کانولوشن صورت بگیره.
اونایی که میبینید این کارو کردن صرفا دنبال انجام عمل کانولوشن بودن.یعنی بجای اینکه یکبار عمل کانولوشن رو در ورودی انجام بدن چندبار این کارو کردن و بعد بعد کاهش بعد دادن و نهایتا تابع فعال سازی رو لحاظ کردن. (Lenet5 که نمونه اولیه شبکه کانولوشن بود مثلا اینطورعمل کرد)
۲٫بعد لایه کانولوش اگه لایه پولینگ قرار بدید (یا حتی تو خود لایه کانولوشن اندازه فیلتر رو بزرگتر کنید) کاهش ابعاد رو داریم. ویژگی هایی که شما ازش صحبت میکنید همون پارامترهای قابل یادگیری هستن که در هر زمانی میتونید محاسبه کنید.
۳٫من متوجه نشدم این بخش رو
۴٫اون ساختار رو میتونید با نرم افزارهای مختلف هم بسازید دستی و هم میتونید اگر مثلا از Caffe استفاده میکنید از اسکریپت خود Caffe و یا این سایت استفاده کنید.
ممنون از پاسخ هاتون.
۱- در مورد stride ، مقدار stride رو در لایه های کانولوشن برابر با ۱ قرار می دیم تا وظیفه کاهش سایز fetaure map رو بذاریم به عهده لایه pooling. در لایه های بعدی کانولوشن که دیگه لایه pooling نداریم بلکه تابع فعالساز relu داریم که روی تک تک لایه ها ( منظور از لایه ها همون feature map هست. درسته؟ ) اعمال می کنیم ، باید مقدار stride ور بیشتر بذاریم مثلاً برابر با ۲٫ تا وظیفه کاهش سایز feature map درست انجام بشه. درست میگم؟
۲- در مورد padding اگه مقدارش برابر با صفر باشه ، به چه معنی هست؟
تشکر.
سلام
خواهش میکنم .
۱٫من متوجه نشدم .یعنی چی “در لایه های بعدی کانولوشن که دیگه لایه پولینگ نداریم…”
ببینید هر لایه کانولوشن یه تعداد کانال یا خروجی داره که شما میتونید برای کاهش ابعاد این توده سه بعدی از pooling استفاده کنید و یا حتی با اعمال اندازه فیلتر و استراید بزرگتر در لایه کانولوشن این کار رو صورت بدید.
لایه پولینگ یک توده سه بعدی رو دریافت میکنه و اندازه اونو کاهش میده . به همین شکل لایه relu روی یه توده سه بعدی اعمال میشه (در اصل روی تک تک مولفه ها اعمال میشه) و یه توده سه بعدی بعنوان نتیجه ارائه میکنه.
در ادامه شبکه این دست شماست که کاهش ابعاد رو داشته باشید یا نه چه با پولینگ چه با لایه کانولوشن. یادتون باشه یکی از مهمترین دلیلی که ما از کاهش ابعاد استفاده میکنیم کاهش پارامترهای محاسباتی هست.
۲٫اینجا توضیح داده شده : http://deeplearning.ir/آموزش-شبکه-کانولوشن-بخش-دوم/
[…] بعدی: آموزش شبکه کانولوشن بخش سوم […]
با عرض سلام و خسته نباشید
من به تازگی شروع به مطالعه شبکه های کانولوشن کردم و به دنبال یک کد ساده در متلب هستم تا بتونه مثلا با استفاده از شبکه های کانولوشن یک پروژه کوچکی رو انجام بده مثلا تشخیص چهره یا دستخط یا ….، هدفم ازین کار تسلط بیشتر به جزییات این شبکه به صورت عملی هست . به طور خاص یک فایل زیپ را از لینک زیر دانلود و سعی در اجرای اون کردم:
http://www.robots.ox.ac.uk/~vgg/practicals/cnn/
ولی با خطای زیر مواجه شدم :
Attempt to execute SCRIPT vl_nnconv as a function:
C:\Users\mohsen\Downloads\Compressed\practical-cnn-2015a\matconvnet\matlab\vl_nnconv.m
Error in exercise1 (line 20)
y = vl_nnconv(x, w, []) ;
به عبارت دیگه ام فایل بالا را نمیشناسه …با مراجعه به این برنامه متوجه شدم تمامی خطوط آن به صورت کامنت هست یعنی به رنگ سبز و هیچ خطی برای اجرا وجود ندارد. ممنون میشم اشکال به وجود امده را برام توضیح بدین …….ایا مشکل در برنامه هست یا در نحوه اجرای من؟ من این فایلها رو به مسیر متلب اضافه کردم و کار خاص دیگه ای انجام ندادم ….ایا نیاز به کامپایل داره یا اینکه مثلا تولباکس متکانونت را قبلش باید نصب کنم؟…..داخل این فایل فشرده پوشه ای به نام متکانونت هست و فکر میکنم نیازی به اینکار نباشه…..
همچنین اگه کدی در متلب سراغ دارین که مثلا خودتون یا یکی از دوستانتون نوشته و پروژه ای را با استفاده از شبکه های کانولوشن انجام میده ممنون میشم در اختیار من قرار بدید.
یه سوال دیگه….برای کار در زمینه شبکه های کانولوشن استفاده از متلب بهتره یا زبان دیگه ای را مثل پایتون پیشنهاد میدین؟….من با متلب کار کردم ولی با زبانهای دیکه هیچ آشنایی ندارم…..پیشاپیش از توجه تون متشکرم
سلام .
من متاسفانه با لینکی دادید کار نکردم. اما نگاهی که کردم بنظرم اومد مراحل متختلف رو توضیح دادن و همون پیش برید باید جواب بگیرید.
مت کانونت بنظر من برای استفاده ازش نیاز نصب به تولباکسش بود ولی مطمئن نیستم چون کار نکردم باهاش.
در مورد متلب و دیپ لرنینگ باید بگم استفاده خاصی نداره و تو این حوزه بدون شک زبان پایتون هست که بشدت استفاده میشه و بعدش هم سی++ و لوا (که مختص تورچ هست) . متلب اونم خیلی ضعیف توسط بعضی از فریم ورکهای مشهور پشتیبانی میشه مثل CAFFE . تورچ هم خیلی وقته که پشتیبانی از متلب رو کنار گذاشته . بدون استثنا تمامی فریم ورکهای معروف تو این زمینه رپر پایتون ارائه کردن و بشدت هم پشتیبانی میشه ازش.
منم پیشنهاد میکنم متلب رو کنار بزارید و استارت کارتون رو با پایتون بزنید. از لحاظ سینتکس خیلی به متلب شبیه هست و خیلی سریع بنظرم میتونید استارت بزنید.
برای شروع میتونید از CAFFE استفاده کنید که نیازی به یک خط برنامه نویسی هم نداره . میتونید مدلتون رو طراحی کنید پارامترها رو تغییر بدید و شبکه رو اموزش بدید و خروجی کار رو ببینید . آموزش کار با CAFFE تو سایت هست.
اگر قصد برنامه ریزی بلند مدت دارید پیشنهاد میکنم برید سراغ تورچ یا تنسور فلو (مگه اینکه اختصاصی با شبکه های کانولوشن بخوایید کار کنید که CAFFE کماکان میتونه گزینه خوبی باشه ولی تورچ باز پیشنهاد میشه خیلی)
اگه بک گراند جاوا دارید یا با اون راحت ترید فریم ورک DeepLearning4J هم خیلی عالیه و مستندات خیلی خوبی داره و میتونید ازش استفاده کنید.
با سلام از شبکه های عصبی کانولوشن در موارد غیر کارهای تصویری هم استفاده میشود؟
برای مثال مانند شبکه های عصبی معمولی در پیش بینی سری های زمانی هم میتوان از آن استفاده کرد؟
سلام . بله
ولی در سری های زمانی بیشتر lstm ها هستن که فعلا رو بورس هستن و دارن استفاده میشن.
با سلام
خیلی ممنون آقای حسن پور
من خیلی به این آموزشها احتیاج داشتم
سپاسگزارم
سلام
خواهش میکنم
با سلام و تشکر از توضیحات خیلی مفیدتون. من مطالب دانشگاه استنفوردم خوندم مطالب شمارم. ممنونم شما با زبانی ساده تر و کاملتر توضیح فرمودید. یه چن تا جا دچار گیجی شدم. میشه زود جواب سوالاتمو بدید با اینکه شمام خیلی درگیرید!!!
۱-بعد از هر کانولوشن قبل رفتن به لایه ی پولینگ یه تابع فعالسازی relu انجام میشه. بله؟ خوب این تابع چرا هر بار بین دو تا لایه باید انجام بشه؟
۲- توی هر لایه ی کانولوشن ما در واقع بک پراپگیشن رو انجام میدیم؟ تا آخرین لایه ی کانولوشن بله؟ و آیا هر کدوم از بک پراپگیشن ها در واقع فاز train هستش؟ یا آخرین بک پراپگیشن همون train اصلیمونه؟
۳- بعضی جاها آخرین لایه ی کانولوشن که داره میچسبه به فول کانکشن رو گفتن hidden layer آیا این درسته؟ مگه همه ی لایه هایی که از ورودی تا خروجی میزاریم جزو hidden layer نیستن؟
ببخشید سوالاتم زیاده ولی این سوالا منو سردرگم کرده. و میشه مطلب بک پروپگیشن اینکه چه جوری توی شبکه های CNN کلا چه جوری انجام میشه رو هم به زودی قرار بدید؟
سلام
۱.relu یه تابع فعال سازی هست که استفاده از relu باعث ایجاد nonlinearityبهتر شبکه میشه. اگر شما reluرو بردارید میبینید سرعت همگرایی شبکه بشدت کاهش پیدا میکنه.(یعنی هیچ تابع فعال سازی ای نباشه بین لایه ها) و اگر عمق شبکه هم زیاد باشه و از روشهای جدید استفاده نکنید اموزش شبکه های خیلی عمیق ممکن نیست. میتونید از توابع فعال سازی دیگه هم استفاده کنید. این تابع مثل تابع sigmoidیا tanhدر شبکه های عصبی معمولی هست که ضرب وزن ها در ورودی ها وارد اون میشد و یک خروجی تولید میکرد (تابع فعال سازی) (البته مزایای relu بیشتره (نسبت به نمونه هایی مثل tanhو sigmoid اما در ساده ترین شکل چیزی که عرض کردم هست)
۲.عمل بک پراپ از انتهای شبکه شروع میشه و تا ابتدای شبکه انجام میشه لایه به لایه و پارامترها بر این اساس تنظیم میشن . این عمل جزءی از عملیات ترینینگ بحساب میاد
۳.من یادم نمیاد به این برخورده باشم ولی اگر کسی این حرف رو زده احتمالا منظورش این بوده که لایه های قبلی بعنوان یه فیچر اکسترکتور استفاده شدن و لایه های تماما متصل اخر رو یک شبکه عصبی در نظر گرفته که از اون ویژگی ها داره استفاده میکنه . باید منظور دقیق رو از اون کسی که این حرف رو میزنه بپرسید منظورش چی بوده .
۴. خیلی وقته در نظر دارم این کارو انجام بدم منتها بخاطر مشغله هی عقب می افته . انشاالله سعی میکنم زودتر این کارو انجام بدم .
ممنونم از اینکه به سرعت جوابمو دادید. یه سوالیم پیش اومد. فرمودید پراپگیشن از انتهای شبکه شروع میشه. این یعنی بعد اینکه تا فول کانکشن رفتیم رسیدیم حالا برای ترین شبکه از آخرین لایه ی کانولوشن تا ابتدای شبکه لایه به لایه هر شبکه کانولوشن روجدا جدا بک پراپگیشن میکنیم؟ اونوقت مجمعش چی میشه؟ یعنی این قسمت توضیح رو خوب متوحه نشدم 🙁
و اینکه امکانش هس یه شبکه ساده رو تز اول تا آخر وداخلش همراه تابع فعالسازی و بک پراپگیشن بعنوان مثال بگید چطور پیش میره؟
ممنون و معذرت از اینکه خیلی سوال می پرسم
بک پراپگیشن در شبکه های عصبی معمولی هم هست! انتهای شبکه یعنی آخرین لایه شبکه حالا هرچی که میخواد باشه از اونجا شروع میشه گرادیانتها محاسبه میشن و به همین شکل لایه به لایه به عقب بر میگرده . حالا ممکنه یکی در میون لایه fully connected یا کانولوشن باشه فرقی نمیکنه در هر کدوم بک پراپگیشن انجام میشه .
من فعلا وقت نمیکنم اما سعی میکنم زمانی که بک پراپ در شبکه کانولشون رو میخوام توضیح بدم اینم در نظر بگیرم (البته اگه یادم نره)
اما تا اون زمان یه مثال از بک پراپ در آموزش شبکه کانولوشن دانشگاه استنفورد هست که خیلی قشنگ توضیح داده و میتونید استفاده کنید . تصویری هم هست.
متشکرم
سلام
ممنون بابت اطلاعات خوبی که در سایتتان گذاشتید.من دو سوال دارم.
۱- امکانش هست یه توضیحی در مورد شبکه های دکانولوشن بدید .
۲- تاجاییکه من متوجه شدم شبکه های کانولوشن استخراج ویژگی می کند و در قسمت لایه تماما متصل در واقع نقش همان شبکه های عصبی معمولی رادارد.درکل یعنی ویژگی های استخراج شده در کانولوشن وارد شبکه این لایه تماما متصل شده و طبقه بندی انجام میشود. مشکل من اینجاست من هنوز درک نمیکنم. نحوی دادن داده ترین (train)برای آموزش این شبکه به چه نحو است.ما یکسری ماتریس داریم که در واقع ویژگی های ماهستند که از بخش کانولوشن تولید شده و حالا ما باید یکسری سمپل مشخص کنیم که به عنوان داده آموزشی که نوع کلاس آنها مشخص باشد تا شبکه آموزش ببیند.الان با این ویژگی های تولید شده چطور اینکار صورت میگیرد و اصلا مگه مکان این سمپل ها مشخص هست که بگوییم مقدار ویزگی های تولید شده از کانولوشن چیست؟ درحالیکه در شبکه عصبی معمولی برای اموزش دقیقا مکان و نوع کلاس اون پیکسل آموزشی مشخص میشد و بعد با توجه به برداری ویژگی هر کلاس شبکه آموزش میدید.
امکانش هست توضیح بیشتری در این زمینه بدید.متاسفانه هیچ منبعی توضیح دقیی در این زمینه نداده و من خیلی عجله دارم. متشکرم
سلام .
من انشاالله سرفرصت یه پست اختصایصی در مورد اینها میزنم . فعلا همینقدر بدونید که از این لایه برای upsampling استفاده میشه و برخلاف اسمش عمل عکس کانولوشن رو انجام نمیده! بهش میگن ۱/۲ strided convolution یا convolution transpose و یا upconvolution .
اگه لکچر ۱۳ دانشگا استنفورد رو ببینید کامل در این مورد توضیح داده شده .
۲٫ من اصلا متوجه نشدم ! لطفا یکم واضح تر بفرمایید سوالتون رو.
با سلام
با تشکر فراوان از مطالب فوق العادتون من برای دومین دفه دارم مطالبتون رو میخونم با وجود اینکه یادگیری ماشین و پردازش تصویر و بینایی ماشین اصلا نمیدونستم و شبکه عصبی خیلی خیلی محدود اطلاع داشتم ولی مطالبتون واقعا کمکم کرد . جسارتا من چندتا سوال داشتم که تو چند کامنت میپرسم
۱- ممکنه این اصطلاحات رو ولو کوتاه توضیح بدید :
۱-گرادیانت
۲-بک پروپگیشن
۳-feed forward
۴-back forward
۵-forward pass
۶-forwarding
البته تا حدودی مفهوم بعضیاش رو از مطالبتون فهمیدم ولی لطف کنید یه توضیح مختصر بدید ممنون میشم
سلام
خواهش میکنم
گرادیانت و بک پراپگیشن و forwardpass و بک وارد پس همه اینا رو اگه شبکه عصبی بخونید متوجه میشید.
گرادیانت همون شیب خط در یک نقطه هست و از این طریق مسیری اپدیت مشخص میشه (به کدوم سمت حرکت بشه که خطا کمینه بشه)
فورورارد پس همون فازی هست که وزن ها در ورودی ها ضرب میشن و همینطور میرن تا اخر شبکه
بک وارد پس هم به مرحله ای میگن که خطا از انتهای شبکه محاسبه میشه و تاثیرش میاد تا ابتدای شبکه
بک پرپگیشن هم الگوریتمی هست که این تاثیر بر روی هر پارامتر در شبکه رو مشخص میکنه
فورواردینگ هم شاید اشاره به همون فاز forward pass داشته باشه باید کل جمله رو بگید .
سلام مجدد
بینهایت سپاس گذارم
FORWARDING تو این متن اینجاها اومده بود
این به معنای کاهش ۳۲ برابری است , بنابر این forwarding یک تصویر ۳۸۴×۳۸۴ پیکسلی در یک معماری تبدیل شده , همان توده را با اندازه ۱۲x12x512 نتیجه خواهد داد
نجام عمل Forwarding در شبکه کانولوشن تبدیل شده برای یکبار بسیار بهینه تر از تکرار آن در شبکه کانولوشن اصلی در تمام ۳۶ مکان است چرا که این ۳۶ ارزیابی محاسبات مشترک دارند.
سلام .
بله این forwarding اشاره به همون فاز forward-pass داره.
یه چند تا سوال دیگه هم داشتم اگر لطف کنید راهنماییم کنید
۱-Lateral inhibitiondh رو تا حدودی متوجه شدم البته نحوه عملکردش رو نه به نظرم نتیجه این وضوح بالاتر تصویره تو شبکیه چشمه ولی کاربرد این تو شبکه های کنولوشن نفهمیدم چیه ؟ آیا یه لایه مجزاس ؟
۲- این سه تا لایه Batch-Normalization ، ELU ، PReLU فقط اسم بردید اگر ممکنه توضیحی راجبشون بدید که اصلا چین ؟
۳- تو متن گفته شده که” سعی میکنیم از فیلترهای کوچک نسبت به بزرگ استفاده کنیم مگر در بعضی موارد خاص اونم در لایه اول ” دلیل استفاده از فیلترهای بزرگ فقط کوچک کردن سایز تصور ورودیه ؟
۴-تو معماری VGGNET ابتدا تعداد لایه های هر لایه کانالوشن(K) کمن ولی در ادامه در لایه های بعدی این تعداد افزایش پیدا میکنه ولی در لایه های اتصال کامل این روند تا حدودی برعکس یعنی اول لایه زیاده ود نهایت کم میشه علت این روند چیه ؟
۵- آیا ممکنه یه راه کار یا متد منطقی برای یافتن تعداد لایه های کانلاشون در هر شبکه و تعداد لایه های هر لایه کانالوشن بیان کرد ؟ تعداد این لایه ها به چی بستگی داره؟
۶-تو متن گفته شده “ک نورون که در لایه کانولوشن دوم قرار دارد یک دید ۳×۳ از لایه کانولوشن اول و به همین صورت یک دید ۵×۵ از توده ورودی دارد.به همین شکل یک نورون در لایه کانولوشن سوم یک دید ۳×۳ از لایه کانولوشن دوم دارد و از این جهت یک دید ۷×۷ هم از توده ورودی دارد”
آیا میشه نتیجه گرفت تعداد لایه کانولوشن استفاده شده در هر شبکه کانالوشن بسته به فیلتر استفاده شده و سایز تصویر ورودی داره یعنی اونقدر لایه کانولوشن استفاده میکنیم تا نورون لایه کانولوشن اخر دید کاملی از تصاویر ورودی داشته باشه ؟
ببخشید پر حرفی کردم و زیاد سوال پرسیدم
از لطفتون سپاس گذارم
۱٫بله تحت یه لایه مجزا پیاده سازی میشه و اسمش Local contrast normalization هست. که همونطور که در متن گفتم کارش افزایش کنتراست در ورودیه. عملا استفاده دیگه نمیشه. بجاش از بچ نورمالیزیشن استفاده کنید که تاثیرش خیلی واضح هست.
۲٫دوتا لایه اول nonlinearity هستن مثل سیگموید مثل relu مثل tanh و… هر دوتا هم پارسال اگه اشتباه نکره باشم معرفی شد. prelu برای رفع مشکل relu (dead relu ها) توسط تیم توسعه و تحقیقات مایکروسافت ارائه شد همراه یه الگوریتم مقداردهی اولیه که ما بهش میگیم msra.
ELU هم به همین شکل ولی من شخصا فایده خاصی ازش ندیدم . یعنی بهبود خاصی ندیدم . prelu یه چیزایی داشت ولی اینو نه . خودتون باید تست کنید رو معماری و یا دیتاستتون ببینید براتون اکی هست یا نه . مثلا ELU تو سیفار۱۰۰ دقت خیلی خوبی گرفته بود اگر درست یادم باشه اما سیفار ۱۰ به اون اندازه خوب نبود.
۳٫بله
۴٫دلیل اصلیش کاهش سربار محاسباتی جلوگیری از اورفیتینگ و نهایتا خلاصه سازی فیچرهایی که تا بحال یادگرفتیمه .
۵٫مقاله ما که آقا محسن تو گروه گذاشتن رو بخونید خوبه . شاید یکسری ایده بگیرید . در کل قانون خاصی کسی تا بحال عنوان نکرده . اما چیزی که هست اینه که شما هرچه به طرف انتهای شبکه میرید دوست دارید اطلاعات انتزاعی و سطح بالاتری بدست بیارید و این مهمه و بر همین اساس هم تصمیم گیری ها انجام میشه. برای همین هم هرچقدر بالاتر میرید این فیچرمپها افزایش پیدا میکنه تا اطلاعات بیشتری بتونید بدست بیارید . (در شکل ساده . در سناریوهای پیچیده(معماری منظورمه) داستان فرق میکنه ) شما برای استارت کارتون همین قانون اولیه رو لحاظ کنید نتایج خوبی میگیرید
۶٫تعداد لایه تابعی از تعداد فیلتر نیست. ربطی هم به سایز تصویر ورودی نداره. نمیتونید فقط بر این اساس عمل کنید. این یه observation از معماری هایی مثل vggnet و الکس نت بوده . قانون نیست که شما بگید مثلا خب الان من مثلا n تا لایه دارم و در نتیجه لایه اخر دید کاملی از ورودی داره پس کافیه و دیگه ادامه ندم . نه اینطوری فکر نکنید.
خواهش میکنم .
سلام
ببخشید پررویی میکنم یه سوال دیگه دارم با یه پیشنهاد و یه خواهش ممنون میشم باز هم راهنماییم کنید
اول سوالم :
۱-معماری بشدت همگن (homogeneous ) که تنها دارای فیلتر با اندازه ۳×۳ در لایه کانولوشن و فیلتر ۲×۲ در لایه pooling از ابتدا تا به انتها بود. بعدا مشخص شد که برخلاف قدرت کمتر دسته بندی نسبت به GoogLeNet , VGGNet در وظایف یادگیری انتقال چندگانه (Multiple transfer learning tasks) از GoogLeNet بهتر عمل میکند. بنابر این شبکه VGG در حال حاضر محبوبترین انتخاب برای Feature extraction از تصاویر است
۱ تو متن گفته شده” معماری VGGNet به شدت همگن است که در وظایف یادگیری انتقال چندگانه از GoogLeNet بهتر عمل میکنه” مفهوم معماری همگن و وظایف انتقال یادگیری چیه ؟
پیشنهادم اینه کاش سایر معماری هایی که معرفی کردید مث VGGNet درمورد لایه هاش و ترتیب قرار گرفتنشون یکیم بیشتر توضیح میدادید
و در اخر خواهشمم اینه در صورت امکان و داشتن وقت پستی که مربوط به عملیات Backpropagation رو در اولویت قرار بدید
از زحماتتون واقعا ممنونم و بهترینها رو براتون آرزو دارم
با تشکر
سلام
خواهش میکنم این چه حرفیه.
من متاسفانه سرم بشدت شلوغ شده. خیلی زیاد. خصوصا از دیروز که من حتی فرصت نکردم به ایمیل هام جواب بدم.
انشاالله سرم خلوت شد برنامه های زیادی دارم که بخاطر کمبود وقت همه اشون فعلا عقب افتادن.
در مورد سوالتون هم معماری همگن یعنی همه جا به یک شکل داره عمل میشه. تو متن هم اشاره کرده . این معماری رو شما با مثلا گوگل نت یا رز نت و… مقایسه بکنید متوجه میشید که اونا ماجول های مختلفی دارن که با فیلترهای مختلف کار میکنن.
در مورد سوال دوم هم اینجا رو بخونید اگر مشکل داشتید بپرسید.
و خیلی ممنون از دعا و آرزوی خوبتون
در پناه حق انشالله همیشه موفق و سربلند باشید
سلام
روزتان بخیر بابت راهنمایی های همیشگیتان
سوال اول:با مطالعاتی که انجام دادم متوجه شدم شبکه های کانوشن (شبکه های عصبی کانولوشن)برای استخراج ویژگی های شکل و لبه بیشتر کاربرد دارد.مثلا اگر دو شی داشته باشیم از جهات شکل و لبه دقیقا مشابه باشد ولی از لحاظ طیف (رنگ) متفاوت باشد توانایی classification ویا segmentation بین این دو شی را ندارد؟آیا این جمله درست است؟
در مجموع این شبکه ها چه ویژگی هایی از یک شی را در اولویت استخراج قرار می دهند؟ تنها لبه ها و شکل ها؟ قادر به استخراج ویژگی های طیف و هندسه وغیره نیستند؟
سوال دوم: این شبکه ها بیشترین قابلیتشان در تصاویر با قدرت تفکیک(رزولیشن) بالا مثلا یک متر میباشد؟ برای تصاویر با رزولیشن مثلا ۱۰ متر نیز قابلیت دارند؟
آیا امکان دارد مقاله ای بمن معرفی کنید که قبل از ورود به شبکه های عصبی کانولوشن استخراج ویژگی کرده و به عنوان ورودی به cnn داده سپس توسطcnn مجدد استخراج ویژگی کردند؟
باتشکر .انشاله همیشه به موفقیتهای بیشتر از این دست یابید.
سلام
نه این حرف صحیحی نیست . شبکه های کانولوشن محدود به شکل و لبه ها نیستند و همه سطوح انتزاعات رو در بر میگیرن
برای تست این قضیه براحتی میتونید خودتون تست کنید و نتیجه رو ببینید.
علاوه بر اون فعالیت در حوزه های مختلفی مثل پردازش متن و همینطور semantic segmentation و… دلیل دیگه ای بر این مدعاست.
در مورد سوال دو هم برای شبکه اندازه ورودی مهم نیست. هرچقدر بیشتر بهتر. برای استفاده و دیدن نتایج خوب هم باید معماری و سخت افزار مورد نیاز تهیه بشه.
من شخصا الان حضور ذهن ندارم. ولی مقالات اولیه خصوصا طی سالهای ۲۰۱۳ و ۲۰۱۴ رو نگاه کنید باید از این نمونه ها زیاد ببینید. سالهای اولیه مثل ۲۰۱۲ تا نهایتا ۲۰۱۴ اینجور چیزا خیلی بیشتر بود. الان هم نمیگم نیست ولی اون دوره زمانی این چیزا بیشتر مد بود و بیشتر میتونید پیدا کنید.
در پناه خداوند انشاالله همیشه موفق و سربلند باشید
سلام
آقای حسن پور من در کامنت قبلی از شما پرسیدم آیا کانولوشن توانایی شناسایی ویژگی های غیر لبه و گوشه و.. رادارد؟ مثلا رنگ.
شما پاسخ دادید بله. یعنی همانند شبکه های عصبی مصنوعی آنها قادر به تفکیک ویژگی های دیگر هم می باشند.
اما من امروز درون سایتتون با این شکل مواجه شدم
http://www.amax.com/blog/wp-content/uploads/2015/12/blog_deeplearning3.jpg
در واقع شما میگویید با لبه ها و گوشه ها که در لایه های مختلف ایجاد میشود که درواقع باز ترکیبی از همان لبه و.. هست شبکه هایCNN کار میکنند. درمورد پردازش متن که درکامنت بالا گفتیدمتن نیز متشکل از خطوط هست نه رنگ.درصورتی حرف شما درست است که من یک متن مشابه با دو رنگ مختلف داشته باشم.اگر قادر به تفکیک این دو باشد حق با شماست.
به متن زیر که در سایتان قرار دادید توجه کنید .خودتان نیز اینجا اشاره به ترکیب لبه و… کردید که ترکیب آنها در لایه های بعدی ویژگی های پیچیده را تشکیل میدهد.که این ویژگی های پیچیده باز متشکل از همین لبه هاست.”
ببخشید من کاملا گیج شدم.و چون در رشته ما در این زمینه کار نشده میخوام مطمین شم که اگه پیاده سازیش میکنم حتما جواب میده.ببخشید وقتتونم میگیرم.شاید سوالاتم برای شما که کامپیوتر خوندید خیلی مبتدی باشه
“”یادگیری عمیق یا همون Deep learning
در یادگیری ویژگی سلسله مراتبی ما ویژگی های غیرخطی چندین لایه رو استخراج میکنیم و بعد اونها رو به یک کلاسیفایر (دسته بندی کننده) پاس میدیم که اونم هم تمامی این ویژگی ها رو با هم ترکیب میکنه تا بتونه پیش بینی ای رو انجام بده. هرچقدر این سلسله مراتب لایه ها بیشتر (عمیقتر) باشه در نتیجه ویژگی های غیرخطی بیشتری هم بدست میاد برای همین هم هست که ما علاقه داریم از تعداد لایه های بیشتری در یادگیری عمیق استفاده کنیم (در اصل اون بخش دوم یادگیری عمیق از همین اصل نشات گرفته و اشاره به سلسله مراتب عمیقی داره که تو یادگیری ویژگیها بما کمک میکنه.) از طرف دیگه این ویژگی های پیچیده رو ما نمیتونیم بصورت مستقیم از تصویر ورودی بدست بیاریم. میشه از لحاظ ریاضی نشون داد که بهترین ویژگی هایی که میشه از یه تصویر با استفاده از یک لایه (بدون سلسله مراتب) بدست آورد فقط لبه ها و توده ها (edge ها و blob ها) هستن. دلیلش هم اینه که اینها نهایت اطلاعاتی هست که ما میتونیم از یه تبدیل غیرخطی از تصویر ورودی بدست بیاریم. برای بدست آوردن و یا تولید ویژگی هایی که شامل اطلاعات بیشتری هستند ما نمیتونیم بصورت مستقیم روی تصویر ورودی کار کنیم و لازمه برای اینکار ویژگی های اولیه خودمون رو (مثل لبه ها و توده ها) دوباره تبدیل کنیم تا ویژگی های پیچیده تری که شامل اطلاعات بیشتری برای تمایز بین کلاسها مورد نیاز هست بدست بیاد.
این نحوه کار که ما در یادگیری عمیق میبینیم در اصل ایده گرفته شده از مغز انسان و نحوه کار visual cortext در مغز انسان هست. در مغز انسان هم نورون های مربوط به سلسله مراتب اولیه در ویژوال کورتکس مغز اطلاعاتی که دریافت میکنن حساس به لبه ها و توده ها هستن و بعد خروجی اونها در یک سلسله مراتب بعدی ادامه پیدا میکنه تا اینکه نورونهای به ساختار های پیچیده تری مثل صورتها حساسیت نشون بدن.”
سلام
اون تصویر مربوط به شبکه DBN هست که برای مثال و دادن ایده از اینکه با چی طرف هستید استفاده شده.
ملاک توانایی شبکه کانولوشن چیزایی که در تصویر اومده نیست. یادتون باشه اون یه متن خیلی ساده و اولیه برای “آشنایی” افراد مختلف هست که هیچ زمینه ای ندارن .
در مورد پردازش متن اصلا بحث رنگ و… نیست. بحث سر درک خود متن هست. من بفهمم فلان جمله در مورد چه چیزیه یا یکسری مقاله مشابه هم برای بر اساس محتوا یا حوزه کاری مشخص بشه برای من و بینهایت مثال دیگه. رنگ یه ویژگی هست مثل بقیه ویژگی ها. اگر در چیزی عنصر تعیین کننده باشه حتما لحاظ میشه.
در مورد اون متنی هم که من گفتم باز اون توضیحی خیلی ساده از اتفاقاتی هست که می افته. در ساده ترین شکل ممکن سعی کردم توضیح بدم منظور از ویژگی های سلسله مراتبی چیه . چیزی که برای شمای خواننده قابل درک و ملموس باشه. چطور ما از ویژگی های سطح پایین به ویژگی هایی سطح بالا میرسیم . اینجا ما صورت رو ساده کردیم و فقط در مورد شکل و تصویر که خیلی ملموسه برای ما صحبت کردیم . شما درک خوبی از چهره آدم دارید. میدونید یکی رو بخوایید تشخیص بدید کل صورتش رو نگاه میکنید. (انتزاع سطح بالا) . حالا همین صورت خودش از بخشهای مختلف تشکیل شده چشم ابرو لب بینی و… اینا سطح دیگه ای از انتزاع هستن. و باز شما میدونید که مثلا یک چشم خودش از یکسری خط و خطوط تشکیل شده . این ایده بشما میده که یک شبکه چطور به سطح خوبی از انتزاع درمورد داده ورودی خودش میرسه . این تصویر بود. ورودی میتونه یه متن باشه . ورودی میتونه ویدیو باشه و… در اصل کار تغییری ایجاد نمیشه. کماکان این سلسله مراتب هست که طی میشه.
اول شبکه یکسری ویژگی های سطح پایین بدست میاره (در تصاویر یه چیزه در متون یه چیز دیگه اس و به همین شکل در هر نوعی متفاوت هست) بعد در ادامه با ترکیب این ویژگی ها با هم به ویژگی های سطح بالا میرسه.
شما اگر آموزش شبکه های کانولوشن رو ببینید متوجه فیلترهای رنگی ای که در مرحله اول بدست میان هم میشید. متوجه میشید که اگر رنگ هم در تصاویر شما وجود داشته باشه در صورت موثر بودن لحاظ میشه.
برای همین نگران نباشید .
قبلا هم عرض کردم شما میتونید تحقیق بکنید از کاربردهای بسیار زیاد این شبکه . بخش پیشینه تحقیق هست که ببینید خوبه برای شروع . و حتما آموزش شبکه های کانولوشن رو ببینید. و سعی کنید خودتون تست کنید تا بصورت عملی این قضیه رو ببینید. اموزش های لازم همه در سایت هست برای اینکار.
یه نکته دیگه که اضافه کنم اینه تشخیص انواع مختلف ورودی ها (جنس تکسچر نوع و…) توسط شبکه کانلوشن خیلی خیلی بهتر از انسانهاس. یعنی اگه بشما چندتا گربه نشون بدن از نژادهای مختلف به احتمال خیلی زیاد قادر به تشخیص نیستید اما شبکه کانولوشن براحتی از پس این کار بر میاد. رقابت ایمیج نت و حتی CIFAR۱۰ هم نمونه های خیلی خوبی هستن که میتونید برید و ببینید و تست کنید.
من خیلی پوزش میخوام یکی بدلیل سوالات زیادم و دوم اینکه وقتتون رو میگیرم.
استاد من خیلی حساس هستند و سری قبل بمن گفتند این شبکه ها قابلیت بیشترشان در شناسایی شکل یک شی هست. با اینکه من توحوزه های مختلف در این زمینه مقاله های مختلف خوندم باز نگران هستم و دلیل این همه سوالات تکراریم این هست.شما به بزرگی خوتان منو ببخشید
وشاید دلیل دیگر آن این هست که من بخش آخر ویژگی هایی را کانولوشن استخراج میکنه و مثلا میشه ۴۰۲۶*۱*۱ درکش برام سخت هست.بخصوص اینکه عدد ۴۰۲۶ مثلا طبق چه رابطه ای بدست آمده.و این افزایش عدد در بعد عمق (بعد سوم) در هر مرحله کانولوشن برچه اساس است.براساس فرمول خاصی این اعداد تغییر می کند.
۲۲۷×۲۲۷×۳————۵۵×۵۵×۹۶———۲۷×۲۷×۲۵۶——–۱۳×۱۳×۳۸۴———۱۳×۱۳×۳۸۴—– ۱۳×۱۳×۲۵۶ و غیره
من خیلی متشکرم.خیلی خیلی خیلی بابت سایت خوبتان و راهنمایی های ارزنده تان و صبوریتان.انشاله پاداش این همه کمکهایی که به انسانهایی که حتی نمیشناسیدشون را در نزدیکترین زمان ازخدا بگیرید.ممنونم
سلام .
خواهش میکنم . هیچ نیازی به پوزش خواستن نیست خواهر من.کاملا درک میکنم. مشکلی نیست.
ویژگی های آخر برای انسان قابل درک نیست. نیازی هم نیست که باشن.به زبون خیلی ساده میشه گفت این خلاصه ای از همه ویژگی های مهم در داده های ورودی ماست.
تا قبل از اون لایه ما یکسری ویژگی مختلف با استفاده از لایه های کانولوشن بدست میاریم . حالا سعی میکنیم هرچی یادگرفتیم رو خلاصه کنیم . این بخش میشه سطح بالاترین ویژگی های موجود در داده ما که بر اساس اون تصمیم گیری میشه.
اون افزایش عدد در بعد عمق که میبینید در اصل نشانگر تعداد فیلتر ماست.یه فرا پارامتره که شما مشخص میکنید. ما میدونیم که هرچقدر در عمق شبکه پیش بریم اطلاعات سطح بالاتری بدست میاد. چه چیزی این اطلاعات رو بدست میده؟ همین فیلترها.این فیلترها روی ورودی ها اعمال میشن و یه نگاشت جدیدی از ورودی ایجاد میکنن که ما بهش میگیم فیچرمپ. بعد این فیچرمپ دوباره توسط یه فیلتر دیگه روش عملیات انجام میشه و یه نگاشت تازه از نگاشت قبلی بدست میاد(اینطوری اطلاعات مختلف تو سلسله مراتب مختلف بدست میاد) برای همین ما رفته رفته تعداد این فیلترها رو زیاد میکنیم تا اطلاعات بیشتری هرکدوم بدست بیارن. از همون ابتدای شبکه تعدادش رو بالا در نظر نمیگیریم چون میدونیم اون اوایل اطلاعات سطح پایین هستن و یکسری تعداد محدود فیلتر کفایت میکنه . اگه بیشتر کنیم میدونیم تاثیر خاصی در دقت نمیزاره . به همین شکل ما میدونیم تعداد این فیلترها در لایه های میانی و بالایی تاثیرشون خیلی زیاده . برای همین اینطور عمل میکنیم .
این هم که میگم میدونیم از تجربه و عمل هست. یعنی خود شما میتونید تو معماری تون, تو شبکه ای که میسازید, دقیقا این قضیه رو تست کنید و نتیجه رو ببینید.
بخش آخر مقاله https://arxiv.org/pdf/1608.06037v3.pdf رو ببینید تا متوجه سلسه مراتب بشید(خصوصا مثال در مورد سر )
بخش ویژوالیزیشن تو آموزش شبکه های کانولوشن هم هست که میتونید ببینید همینطور بخش پیشنیه تحقیق که در مورد کارهای ویژوالیزیشن کار شده مثل کار(https://arxiv.org/pdf/1311.2901v3.pdf) ببینید خوبه.
همینطور ویدیو یوسینسکی رو حتما ببینید :http://yosinski.com/deepvis خیلی جالبه (فیلترشکن داشته باشید)
با عرض سلام و وقت بخیر
از مطالب بسیار مفیدی که در سایت گذاشتید متشکرم ٰ من ارشد هوش مصنوعی دانشگاه نجف آباد میخونم و میخوام روی تشخیص چهره با استفاده ار دیپ لرنینگ کار کنم زمان کمی برای ارایه سمینار دارم و توو این زمین فقط رسیدم چندتا خلاصه بخونم بیس کار را متوجه شدم اما برای نواوری در مقاله شدیدا دچار مشکلم میخواستم ازتون بپرسم که شما راهکاری برای این قضیه دارید مثلا دستورالعملی برای ارایه مقاله یا یه منبع فارسی ٰ توی مقالات روش کار رو خیلی خلاصه گفته و من روشی که تو ذهنمه نتونستم مشابهشو پیدا کنم اما اساتید بهم میگن که حتما قبلا کسی از این روش استفاده کرده نمیدونم چیکار کنم میتونین راهنماییم کنین
میدونم خواسته زیادیه اگرهم نمیشه بازم ممنون بابت سایت خوبتون
سلام .
در مورد نوآوری تنها راهش خوندن مقالات حوزه کاری خودتون هست. چون این حوزه ها خیلی زیاد و خیلی سریع دارن پیشرفت میکنن کلا قابل قیاس با هیچ دوره ای نیست!
و چون تخصصی هستن واقعا نمیشه انتظار داشت همه بدونن تو همه حوزه ها چه خبره و چی state of the art هست و چی انجام شده .
بهترین پیشنهادی که میتونم بدم پرسیدن سوال تو سایت Quora و stackoverflow هست (بخش cross validation ) تا ببینید محققایی که تو این حوزه هستن چه کمکی میتونن بکنن .
Quora خیلی فعالتره تو دیپ لرنینگ و ادمهای بزرگی مثل یان لیکان جفری هینتون ایان گود فیلو و بنجیو و … و تقریبا همه بزرگان دیپ لرنینگ اونجا هم هستن.
محققا و مهندسان شرکتهای بزرگی مثل فیس بوک و گوگل و تویتر و… هم هستن و وقتی سوال میپرسید میتونید انتخاب کنید چه افرادی سوال شما رو ببینن بطور خاص! و اگر خواستن راهنمایی کنن شمارو
نکته بعدی اینکه به حرف اساتید اینطور بسنده نکنید و ول نکنید. اتفاقا کاری که باید بکنید اینه بگردید بین مقالات دقیقا دنبال همین موضوع ببینید اگر انجام شده کامل بخونید و ببینید دقیقا همون ایده شماست یا نه اگر بود ببینید جای بهبود داره یا نه معمولا همیشه ایده یک نفرد صد در صد پیاده نمیشه و با یکسری شباهت ها و تفاوت هاس که جای کار میزاره برای ادم . اما مطمئن باشید با خوندن مقالات مختلف حوزه خودتون به ایده های خیلی بیشتری میرسید اصل هم دقیقا همینه .
یک پیشنهاد دیگه هم اینه که سوالتون رو تو بخش پرسش و پاسخ ما مطرح کنید و لینکش رو در گروه تلگرام بزارید و ببینید اونجا کسی هست که تو حوزه بینایی (تشخیص چهره) کار کرده باشه یا نه . من بنظرم میاد چند نفری بودن تو گروه که تو این زمینه کار کردن یا سوالی داشتن شما اگه پیام های گروه رو بخونید هم احتمالا بتونید این افراد رو پیدا کنید و براشون پیام بزارید و ارتباط برقرار کنید .
و یه نکته دیگه اگر هرزمانی به اطلاعاتی رسیدید بنظرم ایده خوبیه که اطلاعاتی که بدست اوردید رو پخش کنید تا کمکی بشه به بقیه مثل همین کاری که من کردم و باعث جلو افتادن خیلی ها شد.
تو این زمینه میتونید وبلاگ بزنید و یا حتی اگر خواستید مطالبتون رو خودتون اینجا (مثل بقیه دوستان) با بقیه به اشتراک بزارید و کسایی که سوال دارن از خودتون کمک بگیرن .
به هر حال امیدوارم زودتر به چیزی که نیاز دارید برسید .
انشاالله در پناه خداوند همیشه موفق و سربلند باشید
با سلام
در خصوص مطالبی که ارائه دادید جایی که به صورت بصری عملکرد لایه های مختلف رو نشون دادید بهترین درک رو داشتم و پیشنهادی که دارم اینکه بعد خوندن متن هر کسی در ذهنش به تصویر سازی از فرایند یا درکی که داشته خواهد داشت اما اگر این تصویر قبل از خوندن متن ارائه بشه به شدت در درک مطالب تاثیر گذار خواهد بود.
و یک سوال:
برای دسته بندی آبجکت ها در تصاویر بزرگ ( مثلا تصاویر ماهواره ای) گاهی یه آبجکت بسته به موقعیت فیزیکی اش مشخص میشود چه کلاسی دارد ( مثلا یه مستطیل در جاده احتمالا ماشین است و مستطیل مشابه خارج جاده شاید یه کلبه یا خانه باشد) برای دسته بندی آبجکتها در چنین تصاویری راهکاری وجود دارد( آیا شبکه عصبی کانولوشن قدرتی در این زمینه دارد)
و اینکه داده ورودی میتواند یه تصویر رنگی در سه سطح (قرمز و سبز و آبی) باشد اما با روشهایی میتوان سطوح دیگری را نیز اضافه کرد ( مثلا بخش بندی تصویر و انحراف معیار در هر بخش یا بلور کردن تصویر و یا بردن تصویر به فضای رنگی دیگر به جای سبز و قرمز و آبی) این داده ها آیا لازم است توسط ما تولید و به عنوان ورودی داده شوند یا به گونه ای در درون شبکه به اطلاعاتی که ممکنه باشه توجه شده و نیازی به این کار نیست
سلام .
برای بخش اول اگر کمی واضح تر بفرمایید ممنون میشم . دقیقا کدوم بخش مدنظر شماست؟
برای سوال اولتون شما تصویر رو به شبکه ارائه میکنید و بسته به تعداد تصاویری که دارید از هر کلاس شبکه میتونه با قدرت بیشتری این تفکیک رو انجام بده.چیزی هم که مهمه دیتای متنوع و زیاده با تعداد کم فکر نمیکنم دقت خوبی بدست بیارید.
شبکه کانولوشن به پیش پردازش نیازی نداره اما این به این معنا نیست که پیش پردازش مفید نیست و یا تاثیری نمیذاره . اتفاقا برعکس انجام پیش پردازش میتونه تاثیر خیلی مشخصی در خروجی ای که دریافت میکنید بزاره .
اینکه چه مجموعه عملیاتی برای اینکار خاص لازمه من شخصا اطلاعی ندارم چون کار نکردم با تصاویر ماهواره ای . اما در حالت کلی, mean subtraction ,ZCA معمولا همیشه تاثیر مثبت میزارن و تقریبا برای گرفتن دقت مناسب در تصاویر طبیعی و معمول ازشون استفاده میشه.
معمولا پیشنهادی که داده میشه و من شخصا خودم انجام میدم اینه اول بدون هیچ پیش پردازش خاصی به غیر از mean subtraction و یا نرمالسازی شبکه رو روی داده مورد نظر آموزش میدم . بعد سعی میکنم تا جایی که ممکنه دقت افزایش پیدا کنه . بعد که به ماکسیمیم دقت رسیدیم حالا پیش پردازشهای مختلف رو میشه روی داده اعمال کرد و نتیجه رو دید. چون معماری شبکه و پارامترها تا حد خیلی زیادی طی مراحل قبل تنظیم شدن در زمان اعمال پیش پردازش ها میشه براحتی تاثیر هر عمل و موثر بودن اون رو دید و چک کرد.
تو زمینه تصاویر ماهواره ای با شبکه CNN فک کنم کارهای مختلفی انجام شده برای ایده گرفتن معمولا باز کاری که انجام میشه رجوع به مقالات مشابه هست و چک کردن اینکه اونها چه مراحلی رو طی کردن و به چه صورت عملیاتها انجام شده . الان تقریبا همه زمینه ها بصورت تخصصی اینطور پیش میرن. یعنی رجوع به کارهای انجام شده تو حوزه مورد نظر ، تست و استفاده از دستاوردها و یا نتایج اونها و نهایتا تکمیل و بهبود اون روشهاست
سلام
در خصوص بخشی که متوجه نشدید. چون فردی مبتدی با CNN هستم وقتی از مفاهیم و نحوه عمکرد لایه های مختلف صحبت می شد سخت مفاهیم رو درک میکردم اما با مثال تصویری که در آموزش بخش دوم ارائه کردید درک بهتری از عملکرد داشتم و پیشنهادی که داشتم در خصوص موارد دیگر نیز چنین تصویر سازی صورت گیرد ( مثلا اتفاقی که در لایه های دیگر شبکه رخ میدهد).
و البته سوال دیگر اینکه برخی شبکه هایی که تا کنون ارائه شده اند State of art هستند و اگر بخواهم ساختار آنها را منطبق با مساله ای که دارم تغییر دهم. میتوانید سر نخی بدهید تا به هدف مورد نظر راحتتر نزدیک شوم ( قطعا پاسخ مشخصی دارد. اما راهنمایی پخته و سازنده شما تاثیر گذار و قوت قلبی است برای مسیری که در حال طی شدن است).
امیدوارم در فعالیتهای پژوهشی که خواهم داشت افتخار همکاری با حضرت عالی را در عرصه های علمی داشته باشم.
سلام
بله ایده خوبی دادید انشاالله خدا توفیق داد سعی میکنم این مساله رو لحاظ کنم .
در مورد بحث دوم قائده مشخصی وجود نداره در مورد تغییر معماری ها برای یک حوزه خاص. ارائه معماری جدید و یا تغییر یا تنظیم معماری ها خودش بخشی از فاز کار تو حوزه یادگیری عمیق هست. بطور کلی شما باید بسته به میزان داده و ماهیت مساله و شرایطی که دارید معماری رو مشخص و تغییرات رو اعمال کنید.
شما استارت کار رو بزنید بعد اگر مشکلی بود در سایت پرسش و پاسخ بپرسید بنده یا دیگران اگر بلد بودیم حتما راهنمایی میکنیم .
سلام
بسیار ممنون از مطالب خوب و ترجمه ی خوبتون. فرموده بودین بخش بک پراپگیشن رو تو یه پست جداگانه میذارین. فکر میکنم اون رو بذارین دیگه یه منبع کامل فارسی برای شروع شبکه های کانولوشن بشه اینجا.
منتظر مطلب های خوبتونیم 🙂
سلام .
انشاالله .
متاسفانه فعلا وقت ندارم یه پست اختصاصی بهش اختصاص بدم چون زمان زیادی از من میگیره .
و باز اگه سرچ بکنید الان دیگه کامل این بحث رو خیلی ها توضیح دادن و میتونید استفاده کنید.
من هم سرم خلوت شد این قضیه رو حتما لحاظ میکنم . هم بک پراپ در شبکه های عصبی معمولی و هم کانولوشن .
[…] آموزش شبکه کانولوشن بخش سوم | یادگیری عمیق – Deep learning […]
سلام
بسیار ممنون از سایت بی نظیرتون. یک سوال داشتم. اگه درست بگم بزرگترین مشکل آموزش شبکه های کانولوشنی عمیق مساله overfitting هست درست میگم یا نه ؟ برای حل این مشکل راه چه راه کارهایی وجود دارد. آیا صرفا استفاده از داده های خیلی زیاد (مثلا طبقه بندی سه کلاسه با ۵۰۰۰۰ داده آموزشی) میتواند این مشکل را حل کند یا نه.
سلام .
خواهش میکنم
نه بزرگترین مشکل این شبکه ها اورفیت کردن نیست. بزرگترین مشکلشون یکی دوتا نبود یکی از مهمترین هاش vanishing gradient بود . یکی دیگه اش saturating gradients بود تو سیگموید. یکی دیگه بحث exploding gradients بود (مشکلات مرتبط با مقداردهی اولیه بود) و….
اینا که حل شد مهمترین مساله در مورد شبکه های عمیق با تعداد پارامتر زیاد بحث داده زیاد بود و کماکان هست . اونم دلیلش بخاطر اون تعداد پارامتر زیاد این جور شبکه هاس و مختص کانولوشن هم نیست.(تو این حوزه هم داره کارهایی میشه که بعدا انشاالله شاید بیشتر توضیح دادم تو سایت)
خود کانولوشن بخاطر بحث اشتراک پارامتر و localityش تو اورفیت کردن بهتر از انواعی مثل MLP هست.
بله یکی از راه های مبارزه با اورفیت داده بیشتر هست که البته اختصاص به شبکه کانولوشن فقط نداره و در همه سناریوها این قضیه صدق میکنه .
سلام
خداقوت و دست مریزاد بابت مطالب مفیدتون
من میخواستم برای تشخیص صرع از روی EEG از کانولوشن استفاده کنم. داده های ورودی عدد و ماتریس هستن. به نظرتون از کانولوشی میشه نتیجه خوبی گرفت؟
سلام بله تا جایی که من اطلاع دارم شبکه کانولوشن و ترکیب اون با rnn فعلا استفاده میشه و نتایج خوبی هم ارائه میکنن.
با عرض سلام و وقت بخیر
از مطالب بسیار مفیدی که در سایت گذاشتید متشکرم
اگر امکان داره یه توضیح جامع در رابطه با کاربردهای cnn و همچنین الگوریتم های cnn بزارین ممنون میشم. (اگر با مثال باشه خیلی عالیه)
سلام .
بخش پیشینه تحقیق رو مطالعه کنید لطفا.
با سلام.
وقت بخیر. عذر میخام که مجددا مزاحم وقت جنابعالی شدم.
اگر امکان داره در مورد data agumentation و نحوه اعمالش به شبکه بیشتر توضیح بدین.
من تا اونجایی که متوجه شدم هدف از تقویت داده کاهش overfitting است. درسته؟ من توی مقاله ای که در مورد دسته بندی تومورهای مغزی بود، این طور متوجه شدم که با چرخش برش ها این عمل انجام میشه.ولی این موضوع را درک نمیکنم. یعنی بعد از کدام لایه این عمل انجام میشه؟
اگر امکان داره بیشتر در این مورد راهنماییم بفرمایید.
سپاسگزارم.
سلام
در سایت پرسش و پاسخ من فکر میکنم سوال مشابه پرسیده شده باشه و اونجا جواب هم دادیم اونجا رو حتما چک کنید .
اما بطور خلاصه Data Augmentation روی تصاویر ابتدا اعمال میشه . دوتا هدف اصلی وجود داره . ۱٫ افزایش دیتا بصورت مصنوعی ۲٫ مقاوم کردن خروجی شبکه نسبت به تغییرات ورودی (ازلحاظ انتقال (shift) و یا distortion های مختلف در ورودی)
مقابله با اورفیتینگ هم یکی از نکات( مثبتی) هست که با ارائه دیتای بیشتر صورت میگیره .
دیتااگمنتیشن معمولا در لایه دیتا انجام میشه . یا از قبل تصاویر رو پیش پردازش میکنن و بعد تمام دیتای حاصل رو به شبکه ارائه میکنن . یا اینکه این عمل بصورت بلادرنگ و در زمان اجرا (زمان اموزش ) اعمال میشه .
مثلا کفی در لایه data خودش از چند نوع عملیات پشتیبانی میکنه مثل mirroring که اطلاعات بیشتر در اموزش کفی (بخش لایه ها ) که در سایت توضیح دادم اومده .
بقیه چارچوب ها هم مثل تنسورفلو و تورچ و یا کتابخونه های سطح بالا مثل کراس این قابلیت ها رو ارائه میدن و حتی اگر هم ندن شما خوتون میتونید پیاده سازی کنید .
با سلام و تشکر از راهنماییهاتون
من اینجور متوجه شدم که که لایه های موجود اعم از کانولوشن و پولینگ اینا همون هیدن لیرها هستند و در آخر که خروجی کانولوشن ها ضرب وزنها و جمع با بایاسها هست وارد فول کانتکتد مالتی لیر پرسپترون میشه و اونجا مثل شبکه های عصبی معمولی یه سری محاسبات هست انجام میشه به صورت فول کانکتد و از یه تابع فعالسازی خود شبکه ی عصبی میگذره و بعد با خروجی ها یه مقدار خطا محاسبه میشه و بعد بک پرا داره برگرده و همه ی وزن های داخل فول کانکتد و همه ی وزنهای کانولوشن لیر ها رو تا به اولش آپدیت کنه. روال به صورت خلاصه همینه؟ اگه نه به همین توصیف چه جوره روالش؟
سوال دومم اینکه در اخر شبکه کانولووشن بعضی وقتا یه softmax قرار داده شده من رفتم مطالعش کردم یه سری فرمول و ایناس. هدف از قرار دادنش چیه؟ یعنی وقتی هست علاوه بر train با شبکه ی عصبی یه الگوریتم کلسیفیکشن دیگه ای قرار داده میشه؟ این قسمتش گیجم میکنه.
باز هم ممنون از پاسخهای مفیدتون سلامت باشید.
سلام
من درست متوجه فرمایش شما نشدم اما هر لایه کانولوشن خودش یه تابع فعال سازی داره که اینجا در قالب یک لایه جداگانه معرفی میشه معمولا. از این جهت یه لایه کانولوشن با یه لایه مخفی تو شبکه mlp یکیه .
بصورت خلاصه روال به این شکل هست که ورودی وارد لایه کانولوشن اول میشه عملیات کانولوشن (بخونید ضرب ) بین وزن و ورودی انجام میشه + بایاس میشه و از تابع فعال سازی میگذره و میره به لایه بعد و اینکار ادامه پیدا میکنه
نهایتا به انتهای شبکه میرسه خطا محاسبه میشه و عمل بک پراپ شروع میشه تا وزنها بروز بشن.
سافتمکس برای دسته بندی استفاده میشه (میتونید از svm هم استفاده کنید مثلا ) برای اینکه ما برای هر کلاس یه احتمال داشته باشیم . یعنی در انتها بجای اعداد بی سرو ته ما بگیم مثلا کلاس ۱ ۸۰ درصد کلاس ۲ ۱۰ درصد کلاس ۳ ۵ درصد و نهایتا کلاس چهار هم ۵ درصد احتمال جواب بودن دارن .
توضیحات خیلی خوبی تو همون کورس نوتهای دانشگاه استنفورد هست از اینجا مطالعه کنید(از ابتدا بخونید خیلی بهتره)
ممنونم
سلامی دوباره و با تشکر از جواب های خیلی مفیدتون
۴ تا سوال داشتم. یکی اینکه مثلا اگه تصویر ورودی ما ۳۲*۳۲ باشه و مثلا ۲ تا فیلتر بانک ۵*۵ اعمال کنیم و خروجی کانولوشن بعد محاسبات کانولوشنش بشه دو تا خروجی۲۸*۲۵ .حالا این دو تا ماتریس ۲۸*۲۸ وارد تابع فعالسازی مثلا Relu میشه یعنی تابع فعالسازی هم روی تک تک المانهای ماتریس اعمال میشه؟ و خروجی تابع فعالسازی بازم همون دو ماتریس ۲۸*۲۸ ما هستش که بعدش مثلا وارد یه پولینگ لیر میشه که فقط اندازش رو کوچکتر کنه. و به همین ترتیب بره.. این تفکر درسته؟
دومین سوال اینکه پیاده سازی تابع رلو یا هر تابع فعالسازی روی ماتریس خروجی کانولوشن لیر تو وبسایتی جایی به صورت دیتیل یا حتی با کد هستش؟
سومین سوالم اینکه وقتی تا اخر عملیات انجام میشه و بعد خطا محاسبه شده و یک بک پرا داریم تا وزنها رو آپدیت کنیم یعنی وقتی یه برگشت به عقب داریم دوباره با توجه به مقدار خطا مثل بک پرا پگیشن شبکه های عصبی وزن هارو آپدیت میکنه. و دوباره تو عملیات رو به جلو همون کارهای کانولوشن و پولینگ و اینا تا اخر ادامه پیدا میکنه ؟همینجوری میره تا خطا به کمترین مقدار بره؟
چهارم اینکه آیا هر بار تو عملیات رو به جلو ورنهای اپدیت شده از بک پرا مرحله ی قبل استفاده میشه؟ و این وزن که میگیم آپدیت میشه همون مقادیر ماتریسهای خروجی از لایه های رلو و فولی کانتکتد هستش؟
پنجمین سوالم اینکه وقتی با بک پراپگیشن ما در واقع داریم شبکه رو اموزش میدیم و میگیم میتونیم از softmax یاsvm هم استفاده کنیم این چه جوری میشه؟ یعنی دیگه بک پرا نداریم و اونجا الگوریتمهای کلسیفیکیشن دیگه ای رو اعمال میکنیم؟
واقعا معذرت میخوام که انقد سوال پشت سر هم مطرح کردم
سلام
۱٫بله اینکه میبینید relu خودش یه لایه جداگانه شده صرفا بخاطر بحثهای پیاده سازی بهینه است. یه لایه کانولوشن مثل یه لایه mlp هست. هر لایه یک نورون داره مثل mlp. هر نورون هم یک عملیات غیرخطی انجام میده. تو mlp صرفا یک ضرب نقطه ای بین ورودی و وزنها انجام میشد که بعد با بایاس جمع میشد و وارد یه تابع فعال سازی میشد و بعد خروجیش میرفت به لایه بعدی. اینجا هم همونه منتها بجای یه ضرب نقطه ای معمولی ما عملیات کانولوشن داریم (که اونم البته ضربه!ولی خب شکلش متفاوت). بنابر این تمامی خروجی لایه کانولوشن باید از یک تابع فعال سازی عبور کنن و برای اینکار هم از لایه relu یا انواع دیگه استفاده میشه. دقت کنید که شما بدون استفاده از تابع فعالسازی هم میتونید کار کنید(تست کنید) اما میبینید همگرایی شما بشدت ضعیف میشه و کاهش پیدا میکنه.
خروجی لایه ای مثل relu توده فعالسازی هست (منظور از فعالسازی activations هست ) با همون ابعاد توده ای که اول واردش شد.
تابع relu که همون Max(0,x) هست ولی در حالت کلی بله شما خیلی راحت با سرچ کردن میتونید تعداد زیادی مورد پیدا کنید. میتونید به سورس کد کفی یا تنسورفلو و … هم نگاه کنید و دقیقا ببینید چطور پیاده سازی کردن .
بله در مرحله بک پراپگیشن خطا روی وزنها اعمال میشه و اونها تنظیم میشن و در دور جدید ورودی ها با وزنهای بروز شده مواجه هستند و این عمل انقدر تکرار میشه تا شبکه به همگرایی مناسب برسه
به این سوال بالا جواب دادم اما در مورد ادامه اش باید بگم چیزی که آپدیت میشه مقادیر توده های ورودی نیست بلکه همون کرنل ها(یا ماتریس وزن ها) هستند که به روز میشن . توده خروجی لایه های relu و امثالهم همون فیچرمپ های ما هستن که از اعمال ورودی ما در وزنها و سپس گذر از توابع غیرخطی بدست میان .
در مورد softmax که از multinomial logistic lossیا همون cross entropy استفاده میشه .(البته انتخاب لاس مناسب بر اساس هدفی که داریم انتخاب میشه ولی خب به صورت) برای svm هم از hinge loss استفاده میشه و مشکلی از نظر بک پراپ وجود نداره چون نهایتا یک لاس نیاز هست که باید محاسبه بشه و بعد با بک پراپ در شبکه منتشر و اعمال بشه .
البته مرسوم نیست که در خود شبکه عصبی بیاییم مستقیما از svm یا انواع دیگه دسته بند ها استفاده کنیم شیوه اصلی به این صورت هست که ابتدا شبکه رو آموزش میدن و بعد بعنوان یک فیچر اکسترکتور ازش استفاده میکنن و نهایتا ویژگی های استخراج شده رو با هر دسته بندی که فرد بخواد براحتی استفاده میکنه میخواد svm باشه میخواد چیز دیگه باشه و این البته خیلی مرسوم هست و زیاد هم استفاده میشه .
سلام
توضیحاتتون واقعا مفید بودن ممنونم. فقط یه موضوعی رو متوجه نشدم فرمودید”در مورد softmax که از multinomial logistic lossیا همون cross entropy استفاده میشه .(البته انتخاب لاس مناسب بر اساس هدفی که داریم انتخاب میشه ولی خب به صورت) برای svm هم از hinge loss استفاده میشه و مشکلی از نظر بک پراپ وجود نداره چون نهایتا یک لاس نیاز هست که باید محاسبه بشه و بعد با بک پراپ در شبکه منتشر و اعمال بشه ” یعنی آیا بهآخر شبکه که میرسه یه مقداری بنام لاس هم محاسبه میشهو با بک پراپ به سمت عقب پخش میشه؟ لاس چی هست و چرا محاسبه میشه و وقتی رو به عقب میره چطوری تاثیر میزاره روی وزنهای آپدیت شده؟؟ نمودار لاس که توی دیجیتس میکشه همونه؟
و دوم اینکه حالا اگه سافت مکس یا هر چیزی نباشه ما با همون بک پراپ میتونیم شبکه رو آموزش بدیم؟ خوب این سافت مکس فرمودید “سافتمکس برای دسته بندی استفاده میشه برای اینکه ما برای هر کلاس یه احتمال داشته باشیم ” یعنی اگه ۱۰تا کلاس خروجی داریم. اون مقدار درصده برا هر کلاس احتمال اینکه شبکه اونو تخمین بزنه چقده؟ یا معنی اون درصده اینه که دیتاستمون چند درصدشو این کلاس تشکیل داده؟ کلا این درصدی که به هر کلاس میده مفهومش چیه؟ توی اموزش شبکه به چه دردی میخوره؟
سوم اینکه برا فیلتر بانک ها یا همون کرنل ها که تو هر خونه عددی در نظر گرفته میشه رو از روی چه منطقی مقادیرشو میدیم؟ و این فیلتر بانکها در واقع بعد عمل بک پراپ آپدیت میشن ؟
سلام
بک پراپگیشن یک الگوریتم credit assignment هست. یعنی هرکدوم از پارامترها با توجه به میزان تاثیری که در خطای انتهای شبکه(لاس) دارن به همون نسبت و میزان تغییر کنند.
سافتمکس یک تابع است که روی خروجی شبکه اعمال میشه . وقتی خروجی شبکه رو ببینید متوجه میشید با اعداد خام مواجه میشید با استفاده از سافتمکس براحتی میشه احتمال برای هر دسته رو مشخص کرد.مثلا وقتی شما یک تصویر به شبکه میدید در انتهای شبکه میتونید ببینید هر کلاس چه احتمالی داره . مثلا سه کلاس دارید سگ گربه و صندلی! میبینید شبکه با احتمال ۸۰درصد گربه رو انتخاب کرده که صحیح هست و ۱۹درصد سگ و ۱ درصد هم احتمال صندلی!
ربطی به دیتاست نداره . پیشنهاد میکنم این بخش رو مطالعه کنید : http://cs231n.github.io/linear-classify/#softmax
این سوالها همه قبلا جواب داده شدن . لطفا بخش پرسش و پاسخ رو حتما جستجو کنید
این اعداد فراپارامتر هستند و جزو چیزهایی هستند که باید تنظیم بشن . قائده اختصاصی نداره یک قانون کلی هست که این فیلترها رفته رفته تعدادشون بیشتر بشه (همگام با اون اندازه فیچرمپ ها کاهش پیدا میکنه ) .
بله فیلترها یا همون کرنلها یا همون ماتریس های وزن، با عمل بک پراپ تنظیم میشن.
سلامت و پاینده باشید
سلام…
بابت مطالب مفیدی که قرار می دهید خیلی ممنون…
یک سوال داشتم….
در کدی که برای پیاده سازی شبکه کانولوشن است به softmax برخوردم… میخواستم اگر امکانش هست توضیح مختصری در موردآن بدهید…
سپاس
سلام
اتفاقا در کامنت قبلی در همین باره کمی صحبت شد .
میتونید از این لینک استفاده کنید : http://cs231n.github.io/linear-classify/#softmax
خیلی ممنون….
اینطور که متوجه شدم سافتمکس آخرین لایس… وبرای هر تصویر نهایتا یک عددی میدهد که با خروجی مطلوب باید مقایسه شود تا خطا بدست بیاید … درسته؟
بعد من اینطور متوجه شدم که در بخش فیدفوروارد شبکه کانولوشن ورودی ااگر بعنوان مثلا ۲۰ تصویر باشد میاد اینو چند تا چند تا انتخاب میکند بعد وارد لایه ها ی شبکه میکند و کانولوشن وپولینگ صورت میگیرد در نهایت بعد از عبور از لایه تمام متصل از سافتمکس عبور میکند و برای هر تصویر یک عدد داریم که باید با لیبل آن مقایسه شود…
در بخش Backpropagation
دقیقا چه اتفاقی می افتد؟
مرسی بابت وقتی که می گذارید…
نه سافتمکس کارش اینه که به دسته های مختلف احتمال نسبت میده . یعنی چی ؟ یعنی شما اگر ۴ تا دسته داشته باشید مثل میز صندلی کیف کتاب وقتی یک عکسی به شبکه میدید یکسری محاسبات انجام میشه که نهایتا اخر شبکه ۴ تا عدد شما خواهید داشت. اینجا سافتمکس میاد این عددهای خام رو تبدیل به احتمال میکنه یعنی مثلا میز ۰٫۱۸ صندلی ۰٫۷ کیف ۰٫۱ کتاب ۰٫۰۲ که جمع همه اینها با هم میشه ۱ (یعنی ۱۰۰درصد) و هرکدوم از این عددها رو میتونید بصورت احتمال تفسیر کنید. مثلا ۱۸درصد میز! ۷۰درصد صندلی والی اخر
برای اینکه درک براتون ساده تر باشه کاری به این نداشته باشید چندتا چندتا تصویر واردش میشه اون بحث پیاده سازی هست (و موازی سایزی برای افزایش سرعت) . هر تصویر یک برچسب داره . وارد شبکه میشه عملیات کانولوشن انجام میشه و لایه های مختلف رو طی میکنه تا برسه به اخر شبکه و خطاش محاسبه بشه یعنی عددی که بدست اومده انتهای شبکه با برچسب قیاس میشه یک خطا بدست میاد و اون خطا از طریق بک پراپگیشن در سراسر شبکه دوباره پخش میشه و هر وزنی به اندازه تاثیری که در بدست اومدن عدد نهایی داشته تاثیر میپذیره . مثلا اگر جواب غلط بود و وزنی تاثیر زیادی روی عد بدست اومده داشته اون وزن بیشتر از بقیه مجازات میشه.
با سلام
یه سوالی داشتم البته شاید خیلی سوال ابتدایی هست چون من زمینه ی زیادی از ایمیج پروسسینگ ندارم. وقتی یه سری تصاویر ام ار آی یا سی تی اسکن داریم که به رنگ آبی و مشکی هستش اینام جزو تصاویر آر جی بی محسوب میشه دیگه بله؟ چون سیاه و سفید نیستن ولی خوب فقط طیف آبی هم نیستن. یعنی منظورم اینه تو ورودی ما اینارو سه بعدی در نظر میگیریم دیگه؟
سوال بعدی اینکه تصاویر سیاه و سفید عمقشون یک هستش؟ چون میگن سه رنگ تو ار جی بی یعنی عمق سه!! این حرف درستیه؟
سوال سوم هم اینکه حالا رو تصاویر ار جبی بی وقتی یه کرنل ۵*۵ داریم گفته میشه برا هر سه طیف رنگ جدا جدا فیلتر رو اعمال میکنیم اونوقت برا تصاویر سیاه و سفید چطوره؟
سلام .
شخصا با تصاویر CTScan کار نکردم اما بچه هایی که کار کردن میگفتن این تصاویر سه بعدی هستند (یعنی در اصل یک مجموعه فریم از تصاویر هستند) و بله اگر اشتباه نکرده باشم RGB هستند
درمورد سیاه و سفید بودن باید دقت کنید که ملاک رنگ نیست میتونه RGB باشه تصویر اما درش فقط از رنگ سیاه استفاده شده باشه. تصاویر سیاه و سفید یا اصطلاحا gray scale تک کاناله هستن و بله عمقشون ۱ هست بقول شما.
در مورد شبکه های کانولوشن اینطور نیست جداگانه روی فیلترها لحاظ نمیشه. بلکه همه باهم لحاظ میشن.
چه تصویر شما تک کاناله باشه مثل تصاویر Grayscale چه سه کاناله باشه مثل RGB یا nکاناله باشه مثل تصاویر ctscan اون فیلتر ها در همه عمق اعمال میشن .
یعنی اگر یه فیلتر ۵×۵ بزنید و ورودی سه کاناله باشه هر سه کانال لحاظ میشن و خروجی شما میشه یه فیچرمپ اگر یکی باشه همون یکی لحاظ میشه اگر n تا باشه همه اون ها لحاظ میشن .
متشگرم
فقط یه سوال فرق دو بعدی و سه بعدی چیه توی تصاویر و آیا تفاوتی تو کاربا شبکه های کانولوشن داریم؟
فرق خاصی ندارن توده سه بعدی ورودی منظور ویدئو هست و همین تصاویر مثل CTSCAN
از کانولوشن سه بعدی هم میشه استفاده کرد و هم از کانولوشن معمولی. کانولوشن سه بعدی خب قائدتا دقت بهتری میده و ماهیت زمانی رو حفظ میکنه اما سربار بسیار زیادی داره از طرفی یک کانولوشن ۲بعدی یا همون معمولی ماهیت زمانی رو از بین میبره و خب سریعتره و سربار کمتری داره .
با سلام و قدر دانی از بابت توضیحاتی که صبورانه مینویسید.
من یه شبکه Cnn رو با یه سری تصاویر سه بعدی با سایز ۲۲۴*۲۲۴ توسط دیجیتس ترین کردم و یکی از سمپلهارو که برا تستش دادم به شکلی که پایین مینویسم با شبکه الکس نت مدل کرده اولش رو متوجه میشم که اومده نود و شش تا فیلتر با ابعداد ۱۱*۱۱ داده و تو لایه ی کانولوشن اول در واقع نود و شش تا تصویر با ابعداد ۵۴ در ۵۴ داریم.
الان مشکلی تو لایه ی پولینگ ندارم ولی بعد لایه ی کانولوشن دوم به بعد متوجه نمیشم مثلا این عدد ۴۸ تو لایه کانولوشن دوم و یا ۱۹۲ تو لایه کانولوشن چهارم چیه؟ و ظاهرا لایه ی کانولوشن جهارم وپنجم یه جورایی انگاری تکرار لایه های کانولوشن دوم و سومه.
و یه سوالم در رابطه با فولی کانکتد که تو این سه تا فولی کانکتد اون اعداد چه چیزیو نشون میدن؟ (لایه ها رو با && جدا کردم)
input 3*224*224&&Conv1 dataShape[96 3 11 11],Conv1 dataShape[96 54 54]&Pool1[96 27 27]&&Conv2[256 48 5 5]Conv2[256 27 27]&&Pool2[256 13 13]&&Conv3[384 256 3 3]Conv3 [384 13 13]&&Conv4[384 192 3 3]Conv4[384 13 13]&&Conv5[256 192 3 3]Conv5[256 13 13]&&Pool5[256 6 6]&&Fc6[4.96 32 16]Fc6[4096]&&Fc7[4096 4096]Fc74096]&&Fc8[2 4096]Fc8[2]&&Softmax[2]
سلام
اینو از کجا خوندید؟ باید مقاله ای که این توش مطرح شده رو بگید تا بشه فهمید منظورش چیه .
من یک توضیح تکمیلی هم بدم در پیاده سازی اولیه معماری الکس نت برای مقابله با مساله کمبود حافظه هر توده رو به دو بخش تقسیم میکردن . برای همین یک توده با ۹۶ فیلتر به دوتا ۴۸ تا تقسیم میشد و همینطور برای بقیه لایه ها اینو. داشتیم. اما این شیوه شما با این همخونی نداره باید مقاله اش رو بدید تا بشه دید و فهمید منظورشون چی بوده .
با سلام و احترام
من تمام مطالب رو خوندم و بسیار لذت بردم اما چون آشنایی چندانی با شبکه های عصبی و کار با آنها ندارم یه نکته ای رو متوجه نشدم
فرض کنید ما مثلا تصاویر پزشکی CT رو به عنوان ورودی به این شبکه دادیم و هدف تشخیص یک بیماری خاص با استفاده از شبکه عصبی کانولوشن باشه، میشه لطفا بفرمایید بعد از اینکه تمام این مراحل انجام شد خروجی دقیقا چیه؟ آیا خروجی یک تصویره یا چندین تصویر در کناره هم یا اصلا تصویر نیست؟؟؟
اگر تصویر نیست، این خروجی به چه طریقی باید به تصویر تبدیل بشه تا بر اساس این تصویر نتیجه گیری انجام بشه؟ و آیا حتما لازمه این خروجی به تصویر تبدیل بشه تا بتوان نتیجه گیری کرد و مثلا بیماری رو تشخیص داد؟
ممنون میشم درباره خروجی این شبکه برای این مثال خاص(تشخیص بیماری) توضیحات کامل بدید تا متوجه بشم
سلام
در حالت ساده شما یه مساله دسته بندی دارید . آیا یک تصویر CTSCAN دارای یک بیماری خاص هست یا نیست . (بیمار بودن یا سالم بودن دوتا دسته اس)
در این مساله ها ما بسته به تعداد دسته ها خروجی های مختلفی داریم که عدد هستند (در اصل احتمال دسته ها . مثلا ۸۰درصد بیمار یا ۲۰درصد سالم. یا مثلا اگه ۴ دسته داشته باشیم مثل سگ گربه هواپیما ماشین و و کار ما مشخص کردن این باشه که تصویر ورودی کدوم یکی از این دسته هاست خروجی ما میش ۴ تا احتمال یعنی مثلا ۲۰درصد سگ ۷۹ درصد گربه ۰٫۵درصد هواپیما ۰٫۵درصد ماشین … )
یک مساله دیگه داریم بنام Detection اینجا علاوه بر اینکه گفته میشه تصویر متعلق به کدوم دسته اس (مثلا بیمار یا سالم) دور اون بخشی که نمایانگر بیماری یا سالم بودنه یک bounding box یه اصطلاحا یک پنجره کشیده میشه .این چیزا بیشتر تو حوزه تشخیصی مثل تشخیص تومور مطرحه ولی خب تو حوزه های دیگه هم بسته به ماهیت کار میتونه کاربرد داشته باشه. (مثل شناسایی چهره و مشخص کردن صورت، یا تشخیص عابر پیاده و مشخص کردن عابر، یا تشخیص تابلوهای راهنمایی رانندگی و مشخص کردن مکان و خود تابلو وبینهایت مثال دیگه…)
اینجا داده خروجی دو نوع هست . یک نوع که همون عدد (احتمال دسته هاست ) و نوع دیگه هم باز عدده (مختصات پنجره )
با سلام
در خصوص سوالی که در مورد معماری الکس نت که براتون لایه به لایه با اعدادش نوشته بودم اینه که این یه سری ایمیجه که داده شده به دیجیتس انویدیا و خودش با معماری الکس نت اینو طراحی کرده و مقاله نیس خودم دادم به دیجیتس با دیفالتهاش اینارو نشون داد. میتونم عکسهاشو که تو هر لایه در آورده رو بفرستم ولی ظاهرا از اینجا امکانش نبود. ایمیلتونو میتونم درخواست کنم؟
سلام
بله خدمت شما : Coderx7@Gmail.com (آدرس تماس در بخش درباره ما هم وجود داره)
با سلام
من یه سوال کلی داشتم. در حال حاضر وقتی میخواییم با شبکه های کانولوشن کار کنیم آیا با همون معماری های موجود الکس نت.گوگل نت و… کار میکنیم یا خودمون یه معماری با تعدادی لایه های کانولوشن و پولینگ میسازیم ؟و از اکتیویشن فانکشن های لازم استفاده میکنیم! یا تغییراتی تو معماریهای موجود انجام میدیم؟ فک کنم کدهای آماده ی زیادی برا همین معماریهای موجود هست وقتی یکی کد میزنه آیا همون کدهارو تغییر میده؟ یا کلا معماری جدیدی رو کد میکنه؟ بعضی منابع مستقیم نوشتن که مثلا الکس نتو استفاده کردن ولی بعضیا تو بعضی منابع چیزی بعنوان نام شبکه عنوان نکردن.
و سوال دوم اینکه برا اینکه مثلا اولش با کفی و بعد تنسورفلو کار کنیم باید تا چه حد پایتون رو یاد بگیریم؟
ممنون میشم جواب سوالمو بفرمایید
سلام
هردوتا کار رو میتونید انجام بدید.
در ۹۹درصد اوقات از شبکه های معروف و از قبل طراحی شده استفاده میشه. طراحی معماری کار راحتی نیست و اطلاعات زیادی لازم داره تا یک معماری *بهینه* طراحی بشه.
از اون ۹۹دصد دوباره در درصد خیلی بالایی از کارها صرفا به تغییر اطلاعات سطحی از یک معماری بسنده میشه مثل تغییر تعداد کلاسها، تنظیم پارامترهای اموزش شبکه و از این دست کارها (بیشتر از اون نیازی نیست)
و در درصد کمی هست که نیازمند تغییرات بیشتر در یک معماری فعلی
و درصد خیلی کمتری طراحی و ارائه یک معماری جدید هست .
در مورد کد زدن همه اینها برمیگیرده به ماهیت کار. هرکدوم از معماری های جدید معمولا یکسری اصول و ایده جدید معرفی کردن که افراد میتونن از اونها در طراحی معماری یا حتی کار خودشون استفاده کنن.
در مورد مقالات هم باید عنوانش قید بشه و خونده بشه تا بشه نظر داد.
نکته دیگه اینکه از الکس نت استفاده نکنید . الکس نت معماری قدیمی و خیلی غیربهینه اس هست معماری های به مراتب بهتر از اون وجود دارند. هم از لحاظ سبکی مثل Squeezenet که هم رده الکس نت کار میکنه (دقت الکس نت رو میده با تعداد پارامتر خیلی کمتر) و یا معماری هایی مثل , wrnet, densenet, VGGNet, resnet, googlenet و… که دقت ها خیلی بالاتری دن اما سربار زیادی دارن و یا معماری های دیگه ای مثل SimpleNet که دقت بالا و سربار کم دارن و امثالهم
من اگر فرصت کنم انشاءالله یک توضیح مناسب سعی میکنم در این موارد بدم در سایت ولی خودتون هم باید بتونید با یک جستجوی ساده به اطلاعات خوبی برسید.
برای کفی که لازم نیست یک خط پایتون بدونید (برای اشنایی اولیه) برای آشنایی بیشتر مثل تنسورفلو هست که پایین عرض میکنم .
برای تنسورفلو یا کلا هر فریم ورکی دیگه ای که رابط پایتون ارائه میکنه دونستن اطلاعات اولیه و مفاهیم اصلی پایتون کفایت میکنه .
من یک سایت معرفی کردم در بخش منابع یادگیری همون رو بخونید با سینتکس و مفاهیم اصلی آشنا بشید میتونید تنسورفلو و بقیه رو بخوبی کارکنید.
شاید نهایتا دو روز آشنایی با این موارد زمان شما رو بگیره (اگر برنامه نویس باشید و یا به یک زبان دیگه بخوبی تسلط داشته باشید) و بعد براحتی میتونید پیش برید.
با سلام و عرض احترام
وقتی صحبت از بک پراپ توی شبکه های کانولوشن هست. فک کنم اینجوری خوندم که در واقع ما مقادیر فیلترها یا همون کرنل ها رو توی هر بک پراپ در حال آپدیت کردن هستیم. چن تا سوال داشتم خدمتتون.
سوال اولم اینکه: آیا این آپدیت فقط شامل لایه های کانولوشن میشه؟ یا لایه ی پولینگ هم جزو این آپدیتها هست؟ فک کنم تو مقاله ی الکس نت در مورد اپدیت پولینگ لیر هم چیزایی نوشته شده.
سوال دوم اینکه آپدیت شدن بر اساس خطایی که حساب میشه شامل فولی کانکتد میشه؟ اگه بله اونجا رو عین کرنل ۱*۱*۴۰۹۶ میبینیمش؟ و مقادیر پیکسل ۴۰۹۶تا خونه در حال آپدیت شدنه؟
ممنون میشم توضیح بفرمایید.
سلام
در بک پراپ فقط لایه های کانولوشن و فولی کانکتد وزنهاش بروز میشن . لایه هایی مثل پولینگ و… پارامتر قابل یادگیری ندارن که وزنی بروز بشه.
فولی کانکتد به ازای هر نورون با هر پیکسل یک وزن وجود داره و دقیقا همون حالت شبکه عصبی mlp معمولی اینجا هم صادقه .
با سلامو تشکر بابت راهنماییهاتون
توی شبکه گوگل نت من هر چقد لایه هارو نگا میکنم میبینم با فرمولهایی که توی کانولوشن یا پولینگ لیرها داشتیم مقادیر خروجی درست در نمیاد. مثلا توی همین اولین لایه کانولوشنش ورودی ۲۲۴*۲۲۴ هستش و ۶۴ تا کرنل با سایز ۷*۷ داده و استراید ۲ و زیرو پدینگ ۳٫ خوب اگر با همون فرمول که داریم حساب کنیم.
۱۱۲٫۵=۱+(۲/((۲*۳)+(۲۲۴-۷))) این یه مقدار اعشاریه. در حالیکه تو خود شبکه گوگل نت خروجی رو ۱۱۲ نوشته. یا توی پولینگ ها هم همینجوریه حالا اگه بگیم به فرض پولینگرو اومده اورلپینگ گرفته ولی چراتوی لایه های کانولوشن مقدار محاسبه شده با مقدارش که خودشون نشون دادن متفاوته؟
سلام
اگه درست منظورتون رو متوجه شده باشم اگه خروجی دقیق بدست نمیارید و اعداد اعشاری بدست میان برای بعضی از شبکه ها من جمله گوگل نت مساله ای نیست .
خود کتابخونه ها و فریم ورکها یا رند میکنن یا اکسپشن میدن قبلا این بحث اکسپشن دادن زیاد بود و خیلی اعصاب خورد کن
اما الان دیگه نه اینطور نیست اگر اعشاری باشه نتیجه خود کتابخونه رندش میکنه معمولا.
اگر من بد متوجه شدم لطفا بفرمایید
واقعا ممنون.متوجه شدم دقیقا منظورم همین موضوع بود که آیا رند میشه یا نه؟ بازم متشکرم
با سلام و خسته نباشید
چرا درشبکه گوگل نت لایه اخر پولینگ لیر هست اونم از نوع AVG pooling. همیشه آخر شبکه هامون فولی کانکتد بود اینجا از فولی کانکتد استفاده نکرده پس چطوری تو لایه ی اخر نورونها به صورت کامل وصل میشن؟
سوال دوم اینکه در اخر از loss3 linear classifier استفاده کرده. این کلسیفایر از همون تابع cost function or loss function استفاده میکنه؟ چطوری طبقه بندی میکنه کلاسهارو؟ و چرا از یه کلسیفایر linear استفاده میکنه؟
سلام
هیچ الزامی برای استفاده از لایه تماما متصل در انتهای شبکه نیست . هرچند خیلی رایجه .
اینجا اگر بقول شما لایه فولی کانکتدی وجود نداره احتمالا از روش global pooling استفاده شده که اولین بار در مقاله Network in Network ارائه شد.
در این روش ایده اینه که هر فیچر مپ نمایانگر یک دسته باشه . یعنی شما در لایه کانولوشن ماقبل پولینگ میایید تعداد کرنل ها رو برابر تعداد دسته ها قرار میدید و بعدش یک global pooling میزنید . اینطور بعد از لایه پولینگ شما یک وکتور به تعداد کلاسها دارید که براحتی میتونید به سافتمکس ارائه اش کنید و الی آخر
در مورد سوال سافتمکس هم قک کنم قبلا جواب داده باشم به سوال مشابه (سایت پرسش و پاسخ رو چک کنید )
اما بطور خلاصه هردو سافت مکس هستن یکی بدون لاس و برای نمایش دقت و… استفاده میشه و دیگری سافتمکسی هست که بعدش loss Cross Entropy قرار گرفته اینجا رو بخونید خوبه :http://caffe.berkeleyvision.org/tutorial/layers/softmaxwithloss.html
در خصوص سوال بالا در مورد استفاده از linear اشتباهی سوال کردم ذهنیت non رو اشتباهی فرض کرده بودم. و اینکه کلسیفایرشsoftmax with loss هست که تفاوتش با softmax چیه در کل؟
با سلام و احترام
در مورد گوگل نت من وقتی کد رو نگاه میکنم و حتی مدلش رو که تو همه منابع رسم کردن توی دو قسمت inception 4b & inception 4e علاوه بر اینکه هر کدوم از این دوتا اینسپشن ها به لایه ی بعدی ربط داره به صورت جداگانه از هر کدوم هم یه شاخه ی مستقل که متشکل از این قسمتهاست تشکیل شده:
Avg pool>>Conv>>Fully connected>>Fully Conected>>Softmax activation
حالا یه سوال اینکه مزیت استفاده از این کار چیه؟ چون خروجی همین دو تا شاخه به هیچ جا نرفته!!! انگاری هیچ استفاده ای از این قسمت نمیشه چون تو concat هم استفاده نشدن که بره به لایه ی بعدی. فقط یه جا دیدم اسم این قسمتها رو بانام auxiliary classifiers نشون داده. ودر توضیحش اینجوری نوشته:
“”The purpose of these classifiers is to amplify the gradient signal back through the network, attempting to improve the earlier
representations of the data. However, with the introduction of batch normalization, these classifiers have been ignored in recent models
حالا من بازم این توضیحو متوجه نشدم و اینکه اصلا خروجی این دو قسمت داره چیکار میکنه چرا وسط شبکه داره کلسیفیکیشن انجام میده! و اینکه گفته نرمالایزشن استفاده شده تو مدلای جدید این قسمتو نمیخواد. من از کد کافی که تو دیجیتس هست دارم کار میکنم توی اون کد هم نرمالایزیشن لیرهارو داریم هم این دو تا شاخه ی مستقل که از دو تا inception ایجاد شده را دارم.
سوال دوم اینکه در خصوص سوال قبلی که پرسیده بودم تو لایه ی اخری فقط پولینگ هست و بعدش میره تو سافتمکس. این علت رو متوجه شدم ولی باز تو همون مدل شمایی گوگل نت اومده بعد AVG pooling یه لایه ی فولی کانکتد کشیده بعدا رفته به سافتمکس. در حالیکه تو کدش بعد همین پولینگ رفته به سافتمکس و عین شکلش تو کدش چیزی به نام فولی کانکتد وجود نداره!! آیا منظورش اینه که خروجی AVG pooling عین فولی کانکتد داره به شکل یک وکتوره میره به سافتمکس؟
ممنون میشم پاسخ بفرمایید
سلام auxiliary classifiers یک راهی بود که گوگل اولین بار تو معماریش استفاده کرد و ایده اش هم این بود که با اینکار در معماری های عمیق (قبل از معرفی بچ نرمالیزیشن بود این داستان) باعث انتقال بهتر گرادیان به ابتدای شبکه و آموزش دیدن لایه ها بشه .
در عمل الان استفاده نمیشه به این شکل و بر اساس چیزی که خودشون بعدا تو مقاله های بعدی (فکر میکنم اینسپشن ورژن ۳ یا ۴) گزارش کردن گفتن تاثیری نداره وجودش.
از خروجی این کلسیفایرها هیچ استفاده ای نمیشه صرفا تنها دلیل وجودشون همون چیزی بود که عرض کردم .
من معماری گوگل نت رو دقیقا خاطرم نیست که آیا صرفا به global pooling بسنده کرده بودن یا اینکه بعد از اون یک لایه FC هم استفاده کردن . اگر دیدید در معماری ها اخرش لایه FC بود و قبلش هم یک لایه کانولوشن با تعداد کرنلهایی برابر با تعداد دسته ها و یه گلوبال پولینگ بوده اگر اینکار صورت بگیره معمولا برای ایجاد غیرخطی بیشتر در شبکه اس.
در بعضی مقاله ها هم صرفا لایه FC و softmax رو در معماری لحاظ نمیکنن و فقط معماری اصلی (قبل از دسته بندی ) رو نمایش میدن و در موردش صحبت میکنن چون اون بخش اخری هیچ نیازی به توضیح یا تفسیر نداره و نقشش مشخصه .
اگر چیزی غیر از این میبینید فایل معماری رو بدید تا چک بشه ببینم در مورد چی دارید صحبت میکنید.
متشکرم از پاسخهاتون. فقط دو تا مساله اینکه:
اینکه میفرمایید انتقال گرادیان به ابتدای شبکه!!! این جمله یعنی در حین بک پراپ استفاده ی خاصی از این مقادیر auxiliary classifiers میشه؟ چطوری استفاده میشه؟؟ چون توی کد همچنان از این auxiliary classifiers استفاده شده. چون تو کد نرمالایزیشنش بچ نیست.
سوال در مورد فولی کانکتد که پرسیده بودم توی کد کافی که داخل دیجیتس هست و در سایت github هم هست در آخر شبکه چیزی کدی مربوط به فولی کانکتد نیست ولی تو خود مقاله گوگل نت Going Deeper with Convolutions توی شمایی که نشون داده در قسمت انتهای شبکه اومده بعد یه Avg pooling یدونه فولی کانکتد کشیده بعدش فرستاده به سافت مکس. این قسمتشه که سردرگمم کرده در حالیکه تو متن خود مقاله تاکید کرده که Avg pooling رو جای فولی کانکتد داره استفاده میکنه.
سلام
اجازه بدید واضح تر توضیح بدم
در مقاله اول گوگل (معماری گوگل نت) اینطور ادعا شده که چون گوگل نت شبکه عمیقی بوده مساله انتقال گرادیان در تمامی لایه ها مساله مهمی بوده که باید بهش میپرداختن. (کلا قبل از ارائه بچ نرمالیزیشن این واقعا یک چالش جدی بود برای عمیقتر کردن مدلها ) . از طرفی با مشاهدات قبلی در شبکه های کم عمقتری که روی ایمیجنت به دقت مناسبی رسیدن، میبینیم که هرچقدر ویژگی های تولید شده توسط لایه های وسطی متمایزتر باشن (بقول خودشون more discriminative باشن) کارایی شبکه بمراتب بهتر خواهد بود. حالا ایده اینها این بوده که ما بیاییم برای این لایه های وسط با استفاده از همین classifier ها این مساله رو شدت ببخشیم. با قرار دادن این دسته بندها ما سیگنال گرادیانی که منتشر میشه رو افزایش میدیم و کمی هم رگیولایریزیشن براش در نظر میگیرم . نهایتا این دسته بندها حکم چندتا شبکه کانولوشن کوچکتر رو بازی میکنن که بعد از خروجی اینسپشن ماجولهای ۳ و ۴ قرار میگیرن و در زمان ترینینگ لاس های مربوط به این دسته بندها با لاس اصلی تجمیع شده و بعد سیگنال گرادیان باتوجه به اون منتشر میشه . در زمان تست هم که کلا این دسته بندها حذف میشن و صرفا در بحث آموزش مورد استفاده قرار میگیرن .
در مقاله Inception v3 یا همون Rethinking the inception module هم در بخش auxiliary classifiers گفته میشه که ایده اولیه این بوده که این کار انتقال گرایان مفیدتر به لایه های پایینی و سودمند کردن سریع اونها و همینطور بهتر کردن همگرایی بوده.
در ادامه توضیح میده که از نظر همگرایی بود و نبود اینها هیچ تفاوتی نمیکنه . از نظر دستیابی به دقت بهتر هم وجود axiliary classifier ها به میزان خیلی کمی بهبود ارائه میکنه . باز در ادامه اگه مطالعه کنید میبینید گفتن با حذف دسته بندهای پایینی هیچ تاثیری در دقت هم مشاهده نمیشه و نهایتا همینطور پیش میرن تا به این نتیجه گیری میرسن که کلا این دسته بندها نقش یک رگیولایزر رو بازی میکنن و نه چیز دیگه .
لینک گیت هاب رو بدید لطفا (در نظر داشته باشید گوگل نت مقاله اولیه، اینسپشن ۲، اینسپشن ۳ اینسپشن ۴ و…. معماری های متفاوتی هستن دقت کنید همه رو با نام گوگل نت در نظر نگیرید)
با سلام و تشکر از بابت توجهتون
لینک github که کد گوگل نت وجود داره رو همینجا قرار میدم. در این کد همون دو تا auxiliary classifiers نوشته شده ولی در قسمت آخر مستقیم رفته داخل همون Avg pooling در حالیکه من توی همه ی شماهای گوگل نت که ترسیم شدن نگاه میکنم بعد Avg pooling به یک فولی کانکتد رفته بعد وارد کلسیفایر شده.
https://github.com/NVIDIA/DIGITS/blob/master/digits/standard-networks/caffe/googlenet.prototxt
من فقطمقاله ی اصلیگوگل نت Going Deeper with Convolutions و Rethinking the inception module و network in networl رو مطالعه کردم به جز اینها انگاری فرمودید مقالات مربوط به اینسپشن ۲ و ۳ و… هست امکانش هست اسم اونهارو بفرمایید؟
سلام
چیزی که فرستادید همون چیزی هست که تو مقاله googlenet وارد شده . اینجا از global pooloing استفاده نکرده و همونطور که در مقاله اومده یک پولینگ میانگین زده شده با اندازه کرنل ۷ و بعد هم یک لایه FC وجود داره .
جدول ۱ و همینطور شکل ۳ در مقاله اصلی دقیقا این مساله رو نشون مده .
خود digits اون لایه فولی کانکتد رو قرار میده (اونو بر اساس تعداد کلاس مشخص میکنه )
مقاله Going deeper with convolutions همون مقاله اولیه googlenet هست. یا اصطلاحا inception v1 . در مقاله معرفی بچ نرمالیزیشن (Batch Normalization: Accelerating Deep Network Training by
Reducing Internal Covariate Shift ) inception v2 معرفی شد و در مقاله Rethinking the inception module ورژن سوم یعنی inception v3 معرفی شد. ورژن چهارم هم Inception-v4, Inception-ResNet an and the Impact of Residual Connections on Learning هم که اسمش روشه . البته ورژنهای دیگه هم اومدن که از روشهای معرفی شده دیگه استفاده کردن مثل depthwise convolution و امثالهم که یه سرچ کنید پیدا میکنید.
متشکرم از بابت راهنماییهای ارزندتون
با سلام و عرض تشکر فراوان بابت اطلاعات مفید این سایت
با تجربه و تسلط شما به موضوع می خواستم بدونم محدودیت یا عیب شبکه های عصبی کانوولوشنی چیه؟به خصوص با هدف طبقه بندی.
ممنون می شم پاسخ بفرمائید.
سلام .
نسبت به چه چیزی؟
سلام و عرض ادب
بنده تازه با سایت شما آشنا شدم و بسیار از شما تشکر میکنم بابت مطالب بسیار خوبتون، یک سوال از شما داشتم. از یادگیری عمیق آیا میشه برای کلاسیفیکیشن داده هایی که الزاما تصویر نیستند استفاده کرد؟ و اینکه آیا میشه اونها رو با سیستمهای تصمیم گیری فازی ترکیب کرد بنظر شما؟
سلام
یادگیری عمیق صرفا برای دسته بندی تصویر نیست و خیلی از حوزه ها و کارها رو در بر میگیره .
بله شدن امکانش هست منتها باید به مقالات این حوزه اگر کسی کار کرده باشه مراجعه کنید. سایت axiv sanity میتونه شروع خوبی برای پیدا کردن کارهای مرتبط احتمالی باشه
سلام ..
در یک قسمت از مطالبتون فرمودید که “سعی کنید از ترکیب لایه کانولوشن با فیلتر کوچکتر نسبت به لایه کانولوشنی با اندازه ناحیه ادراکی(فیلتر) بزرگتر استفاد کنید.”
من برای دادگان mnist دو ساختار مختلف از شبکه های کانولوشنال امتحان کردم ..که در ساختار اول از دولایه کانولوشن با اندازه فیلتر فیلتر ۵ در ۵ استفاده کردم که در لایه اول ۶ فیلتر ولایه دوم ۸ فیلتر بعد هر لایه هم لایه پولینگ قرار دادم بازشناسیم شد ۹۷٫۷ و خطای تستم در حد صدم شد درحالیکه خطای آموزشم در در حد هزارم بود(overfitting) برا همین ساختارو عوض کردم و از یک لایه کانولوشن استفاده کردم و اینبار از ۲۰ فیلتر ۹ در ۹ برا کانوالو استفاده کردم و درصد صحتم شد ۹۸٫۸ و خطای تستو ترینم هردو در حد صدم شد.. و نتایجم با گفته شما انگار همخونی نداره .. نمیدونم توجیهش چیه!!!
سلام .
زمانی که میخوایید یک مساله رو مورد کنکاش بیشتر قرار بدید چندتا نکته همیشه باید مدنظرتون باشه دوتا از پیش پا افتاده ترین موارد نکته های زیر هست :
اولین بحث ، بحث مقداردهی های اولیه است و اینکه اگر هرچیزی رو قراره تست کنید به یک بار اجرا بسنده نکنید حتما حداقل بین ۳ تا ۶ بار تست بگیرید تا با رنج تغییرات آشنا بشید . ممکنه در یک اجرا بدترین مقداردهی اولیه نصیب شما شده باشه و یا برعکس و این باعث اشتباه شما در تصمیمگیری بشه.
نکته بعدی بحث تعداد پارامتر استفاده شده در شبکه است.
دونستن این مساله که یک مدل خطی دقت ۹۸ درصد به بالا در ام نیست بدست میاره و در نتیجه ام نیست ملاک خوبی برای تستها نیست اصلا و قابل تعمیم به دیتاست های پیچیده تر و معمول نیست. سعی کنید از CIFAR10 استفاده کنید حداقل.
سعی کنید دقت بالای ۹۹ درصد بدست بیارید این چیزی هست که میتونه بشما نشون بده کجای کار ایستادید. اگر نتونید به دقت بالای ۹۹ برسید یعنی کارتون شدیدا لنگ میزنه.ببینید با کدوم روش بهتر نتیجه میگیرید تو این بخش
حالا مشکل شما چیه؟
تفاوت دقتی که گرفتید احتمالا بخاطر اجرای یکباره هست چندبار تکرار کنید تا رنج تفاوت واقعی رو پیدا کنید. اما علت واقعی تفاوت بر میگرده به تعداد پارامتر متفاوت دو شبکه ای که طراحی کردید . شبکه اول حدود ۱۶۰۰ پارامتر و شبکه دوم حدود ۴۸۰۰ پارامتر داره.
یکی دیگه از علل افزایش دقت شما میتونه اندازه فیچرمپ های بزرگتر نسبت به قبل باشه. در حالت اول شما خیلی سریع کاهش ابعاد رو دارید که در حالت دوم اینطور نیست.
کلا سعی کنید از کاهش ابعاد سریع پرهیز کنید تا لایه های بیشتری با داده ورودی بتونن کار کنن .
میتونید تعداد پارامترهای شبکه اول رو مثل دوم زیاد کنید تا ببینید با تعداد پارامتر یکسان چقدر تفاوت دارن
ضمنا از کرنل ۳در۳ استفاده کنید بجای ۵در۵ ویا اندازه های دیگه تا هم سرعت و هم دقت بیشتری بدست بیارید.
دوتا لایه ۳در۳ پشت سر هم همون فیلد ادراکی که فیلتر ۵در۵ ارائه میکنه رو ارائه میکنن +nonlinearity بیشتری ارائه میکنن.
سلام.. من کرنلارو ۳ در ۳ کردم ..و نتیجه کمی بهتر شد وسریعترم شد..
اما نکته ای که تو دو لایه کانولوشن وجود داره برای داده امنیست اینه که خطای تستم مثلا میشه ۰٫۱۸ صدم در حالیکه خطای ترینم در حد ۰٫۰۰۱ میشه ..و نمی دونم چطوری باید رفعش کنم( تابع فعالسازیمم رکتی فایر گذاشتم) چندبارم ترین کردم ولی این اختلافه هست..:(
اما یک لایه کانلوشن اینطوری نیس
کار که خیلی زیاد میتونید انجام بدید
اولین کار شما میتونه افزایش تعداد پارامترها باشه . وقتی پاراتمرها رو افزایش بدید میبنید دقت کمی بهتر میشه اما از یک جایی به بعد دیگه پیشرفتی ندارید
اینجا باید برید سراغ عمیقتر کردن شبکه اتون .
ایده اینه اول یک شبکه عمیق لاغر طراحی کنید بعد کم کم به عرضش اضافه کنید. مثلا اول یک شبکه ۵ ۶ لایه ای طراحی کنید که لایه ها عرضشون رفته رفته زیاد بشه مثلا اگر لایه اول شما ۱۶ تا فیلتر داره لایه دوم شما ۱۸ تا یا ۲۰ تا داشته باشه بعدی ۲۲ یا ۲۵ تا داشته باشه و همینطور الی اخر . (اعدادی که مثال زدم صرفا برای ایده دادن بود میتونید هر عددی بزارید ) و بعد رفته رفته عمق رو باز افزایش بدید تا به دقت مورد نظر برسید. منظور عرض هم تعداد فیلتر ها هست.
داده تون رو میتونید نرمال کنید و با نرمال کردن میبینید بهبود بدست میارید
با انجام همین سه کار میتونید بهبود قابل توجهی داشته باشید.
سلام میشه تفاوت بین batch , patch رو در یادگیری عمیق توضیح بدیت ؟ مفاهیم مربوط به این دو چی هست؟
سلام .
پچ یعنی تکه اما بچ یعنی دسته .
patch های تصویر یعنی تکه هایی از تصویر.
بچ هایی از تصاویر یعنی دسته هایی از تصاویر. یعنی چند تصویر . ایده هم اینه که در شبکه ها برای تسریع عملیات از پردازش موازی استفاده میکنن. یعنی بجای ایینکه یک تصویر هربار در هر زمان پردازش بشه چند تصویر با هم به شبکه داده میشه و پردازش میشن. اصطلاحا به تعداد تصاویری که با هم در این سناریوها استفاده میشن میگن بچ . یک بچ ۱۰۰ تایی یعنی ۱۰۰ تا تصویر که به شبکه ارایه میشه.
خیلی ممنون از توضیح کاملتون
با سلام
ممنون از مطالب بسیار مفیدتون
من دوتا سوال داشتم
۱- من هرجا راجب t-sne مطلبی میبینم وقتی میخواد مقایسه انجام بده یا خروجی رو نمایش بده انگار این الگوریتم تصاویر مشابه رو کنار هم قرار میده و ی جورایی تصاویر رو خوشه بندی میکنه در صورتی که خود برنامه رو که بررسی کردم t-sne فقط کاهش بعد میده و تو دستبندی تصاویر انگار نقشی نداره اگر ممکنه راجب کاربرد این الگوریتم توضیح بدین و اینکه آیا درست فهمیدم ؟من واقعا تو این مسئله گیج شدم
۲- مثالای t-sne با ۶۰۰۰ داده است ولی من برای پروژشم باید برای ۲۰۰هزار داده این کار رو انجام بدم برای همین به مشکل سخت افزار و کمبود رم برخوردم اگر ممکنه برای راهکار این معضل راهنماییم کنید
با تشکر
سلام خدمت استاد
من یه سوال آنی دارم همین امروز ببخشید دیر پیگیر شدم. مقصر خودمم کمکم کنید خواهشاا
من یه پایان نامه دارم که قرار تشخیص حالات چهره رو انجام بدیم.
پیش پردازش
استخراج ویژگی با فیلتر گابور
طبقه بندی رو Fast -CNN
انتخاب کردم
حالا سوالم اینه وقتی تو مرحله استخراج ویژگی با گابور ویژگی ها استخراج میشن مگه یه بردار نیست ؟ چه جوری اونو میدیم به شبکه Fast -CNN؟
چون تا جایی که میدونم ورودی شبکه عصبی باید تصاویر باشن که بتونیم فیلتر انتخاب کنیم و عملیات کانووال رو انجام بدیم و استخراح ویژگی کنیم…
حالا جریان چه جوری میشه آیا ورودی fast Rcnn
میشه بردار ویژگی باشه که دوباره از ویژگی ها استخراج ویژگی انجام بدیم؟
بعد اگه بردار باشه ورودی اعمال فیلتر و عملیات کانولوشن ضرب و…چه جوری انجام میشه…
سلام.
نمیدونم چرا میخوایید از گابور استفاده کنید؟ فیلتر گابور تنها یکی از فیلترهایی هست که در سطح اول یک معماری کانولوشنی توسعه پیدا میکنه و اگر فقط بخوایید خودتون از گابور استفاده کنید دیگه استفادتون از CNN برای چیه؟
سلام آقای حسن پور یه سوال دارم ازتون.
من با استفاده از معماری VGG16 یک تعداد تصاویر رو توی ۱۰ تا کلاس دسته بندی میکنم. پس از آموزش دادن نتیجه به صورت زیر نمایش داده میشه.
[[۴۷۱ ۱ ۰ ۱ ۰ ۰ ۱ ۱ ۰ ۱]
[ ۰ ۴۳۲ ۰ ۰ ۰ ۰ ۱ ۱ ۰ ۰]
[ ۰ ۰ ۴۱۶ ۰ ۰ ۰ ۲ ۱ ۲ ۰]
[ ۰ ۰ ۰ ۴۳۰ ۳ ۰ ۰ ۰ ۰ ۰]
[ ۱ ۰ ۰ ۰ ۴۳۲ ۰ ۱ ۰ ۱ ۰]
[ ۲ ۰ ۰ ۰ ۰ ۳۹۱ ۰ ۱ ۰ ۰]
[ ۱ ۱ ۰ ۰ ۰ ۰ ۴۰۵ ۰ ۰ ۰]
[ ۰ ۰ ۰ ۰ ۰ ۰ ۲ ۳۸۶ ۰ ۰]
[ ۱ ۱ ۰ ۰ ۰ ۲ ۴ ۰ ۳۵۷ ۲]
[ ۱ ۱ ۲ ۰ ۱ ۰ ۰ ۰ ۸ ۴۱۷]]
Test set accuracy is: 0.9885304659498207
سپس وقتی به تصاویر دیتاستم نویز زیاد اعمال میکنم و دوباره آموزش رو انجام میدم . باز هم accuracy تقریبا ۹۸ درصد میشه.
خواستم بدونم که اعمال نویز روی تصاویر توی نتیجه نهایی تاثیری نداره ؟
سلام
بستگی به میزان نویز و ماهیت تصویر داره. هرچه میزان نویز بیشتر باشه و یا دیتاست شما کوچکتر عموما شبکه رو بیشتر دچار مشکل میکنه.
البته برای اینکه robust تر کنن شبکه رو از نویز هم در تصاویر استفاده میشه در زمان ترینینگ(در صورتی که ورودی بطور ویژه با نویز سرو کار داشته باشه). نکته دیگه اینه که الگوریتم های رگیولاریزیشن مثل ویت دیکی و یا دراپ اوت هم شبکه رو نسبت به نویز تقویت میکنن (استفاده دراپ اوت در لایه های ابتدایی حکم تزریق نویز به تصاویر ورودی شبکه رو ایفا میکنه و در ادامه شبکه هم باز بنوعی همین رویه ادامه داره ولیدر مورد فیچرهای سطح بالا انجام میشه نه پیکسل های سطح پایین). به همین خاطر هم شبکه در حذف بعضی نویزهای ساده بسته به شرایط میتونه عمل کنه و شما نتایج خوبی بگیرید.
ولی باید دقت کنید این confusion matrixیی که رسم کردید مربوط به ولیدیشن هست یا ترینینگ؟ اگر ترینینگ باشه نشانه اورفیت هست و اعتباری بهش نیست. اگر مربوط به ولیدیشن باشه و خطایی صورت نداده باشید یعنی شبکه در تشخیص و برطرف سازی نویز مناسب عمل کرده.
ممنون از پاسختون
در مورد confusion matrix قبل از آموزش با استفاده از train_test_split مقدار ۲۰درصد از دیتاست رو به test اختصاص میده و بعد از آموزش، مدل رو با test image پریدیکت میکنه و نتایج رو نشون میده.
نکته ای که هست اینه که با اینکه دقت ۹۸ درصدی رو نشون میده. وقتی یک تصویر نویزی(با همان مقدار نویز که به train image داده ایم) که برای اولین بار توسط مدل دیده میشه پریدیکت درستی نداره و اعداد درستی نشون نمیده، به عنوان نمونه :
/ Unnamed: 0 c0 c1 c2 c3 c4
img_1370.jpg 3.120228e-04 0.000625 0.983408 0.001701 0.000487
c5 c6 c7 c8 c9
۲٫۲۸۲۳۹۰e-04 0.000647 0.010078 0.001129 1.384012e-03
تصویر acc: http://s9.picofile.com/file/8357361068/download.png
تصویر loss: http://s8.picofile.com/file/8357361084/download1.png
دیتاست نزدیک به ۱۸هزار تصویر داره که به همه اونا یک نوع نویز با یک مقدار ثابت اعمال شده.
نمونه درست نیفتاد تصویرش اینه:
http://s8.picofile.com/file/8357362892/simple.jpg
بهتره این سوال رو در سایت پرسش و پاسخ بپرسید اونجا بهتره.
اما فعلا باید بگم میتونه دلایل مختلفی داشته باشه. ولی شما تصاویر تمامی تصاویر رو نویز دار میکنید (منظور کل دیتاست هست قبل از اینکه ترین و تست رو جدا کنید؟) یا خیر
تصاویر تست با نویز تست میشن یا بدون نویز.
از بین تصاویر تست دوباره خروجی گرفتید ببینید باز صحیح پیش بینی میشن یا اونا هم مشکل دارن؟
اگه دقت کنید میبینید لاس ولیدیشن شما از ترینینگ شما کمتره این میتونه چندتا دلیل داشته باشه.
۱٫میتونه بخاطر وجود رگیولاریزیشن در دیتای شما باشه (مثلا استفاده از دراپ اوت)
۲٫میتونه بخاطر عدم تناسب داده شما در تست و ترین باشه. یعنی یا داده تست شما خیلی آسون بوده یا نمونه های سختی در ترینیگ شما وجود داشته که باعث شده با این مساله مواجه بشید.
این نیاز به بررسی و مرتفع سازی داره. چون اساسا داره میگه شبکه در داده ای که ندیده خیلی خوب عمل میکنه اما در داده ای که روش اموزش دیده نتونسته بخوبی عمل کنه (در بهترین حالت/معمول ترین حالت حفظ نمونه ها صورت بگیره یا همون اورفیت کنه)
نکته ۱ اگر باشه منطقیه و مساله داده شما نیست بلکه رگیولاریزیشن شماست. اگر نکته ۱ باشه شما مشکلی در تعمیم نباید داشته باشید.
نکته دیگه که قبلا هم گفتم اینه برای اینکه شبکه بتونه بخوبی تعمیم بده در زمینه مواجهه با نویز لازمه اش اینه دیتای مناسبی (از نظر تعداد) ببینه. باید بررسی کنید آیا کلا برای تمامی کلاسها و همه نمونه ها اشتباه پیش بینی رو انجام میده یا نه (اگر نداد که خب میشه بحث اول اگر همه رو اشتباه جواب میده هم میشه گفت بخاطر بخش اوله و هم محتمل تر از اون متفاوت بودن توزیع تصاویریه که شما برای پیش بینی از اونها دارید استفاده میکنید. )
به كل تصاوير ديتاست(اعم از تست و ترين) نويز يكسان اعمال ميكنم.
توي معماري هم از دراپ اوت استفاده شده هست
موارد دیگه ای که عرض کردم رو هم چک کنید تا بتونید به یه نتیجه مشخص برسید.
اینکه از دراپ اوت استفاده میکنید میتونه در کاهش لاس ولیدیشن نسبت به ترینینگ دخیل بوده باشه میتونه نبوده باشه برای اینکه مطمئن باشید باید اون موارد دیگه ای که عرض کردم رو هم چک کنید.
سلام آقای حسن پور
دوتا سوال در مورد epoch ها در زمان ترینینگ داشتم اونم اینکه اگه تعداد epoch هامون کم باشه(مثلا ۱۵تا ) و دقت بالایی داشته باشیم این یک مزیت به حساب میاد ؟
و اینکه ایا برای تعداد epoch ها قانون خاصی وجو داره که مثلا بگن نباید کمتر از ۵۰تا باشه؟
سلام.
بستگی به مدلتون و ماهیت کارتون داره. برای بعضی کارها ممکنه ۱۰ تا ایپاک یا کمتر هم دقت خیلی خوبی بهتون بده و برای برخی کارها چند صد ایپاک نیاز باشه. بیشتر تو دیتاست هایی که ساده باشن و کم حجم اینو میبنید دیتاست های بزرگتر و پیچیده تر ایپاک های بیشتری نیاز دارن.
معمولا با افزایش ایپاک از یک تعداد خاصی دقت بدتر میشه . این تعداد خاص هم برای هر کاری متفاوته. نه قانونی وجود نداره که بگه ۵۰ تا ایپاگ باید باشه یا کمتر یا بیشتر. بسته به ماهیت کار شما و تنظیمات شما داره.
سلام آقای حسن پور
من یه سوال داشتم، البته توی بخش پرسش و پاسخ مطرح کردم ولی جوابی نگرفتم واسه همین اینجا مزاحمتون میشم.
من لایه های اخر VGG19 رو تغییراتی دادم و به نتایج زیر رسیدم خواستم بدونم که این نتایج قابل قبول هست؟ یعنی نموداری که به دست اومده مشکل خاصی نداره ؟
https://qa.deeplearning.ir/?qa=blob&qa_blobid=8911391168008755936
https://qa.deeplearning.ir/?qa=blob&qa_blobid=11625047953792321011
باتشکر
سلام. منظورتون از نتایج قابل قبول چیه؟ نمودار هایی که نمایش دادید نکته خاصی ندارن و نرمال هستن
سلام
یعنی دقتی که به دست میاد ۹۸ درصد هست که برای من قابل قبوله فقط خواستم بدونم که توی نمودار مشکل خاصی مثل overfitting هست یا نه
سلام. همیشه تا حدودی اورفیت رخ میده و میتونید اینو تو نمودارهای خودتون هم ببینید. از علائم اورفیت اینه که ترینینگ لاس شما کم و کم تر میشه (رفته رفته) اما ولیدیشن شما به همون شکل به سمت بدتر شدن میره (لاس افزایش پیدا میکنه دقت کاهش پیدا میکنه) و برای همین قبل از بدترشدن نتیجه ترینینگ رو متوقف میکنند یا از بهترین ایپاک استفاده میکنند.
اگر به نمودار خودتون دقت کنید این نکته رو میتونید ببینید.
سلام
ممنون از راهنماییتون
اگه بخوام این اورفیت رو تا حدودی کاهش بدم چیکار میتونم بکنم ؟ از دراپ اوت استفاده کنم ؟ اگه اره کدوم قسمت از معماری این دراپ اوت رو قرار بدم ؟
استفاده از ریگولاریزیشن مثل ویت دیکی مثل دراپ اوت و یا استفاده ازدیتا اگمنتیشن از جمله روشهایی هست که میتونید برای مبارزه با اورفیتینگ استفاده کنید.
این وابسته به معماری شما و میزان داده شما است. بطور کلی بخواییم بگیم میتونید از لایه دراپ اوت در تمامی لایه ها استفاده کنید اما این هم میتونه سربار ایجاد کنه و هم اگر مراقب نباشید باعث اندرفیت شبکه شما بشه. اول سعی کنید دراپ اوت رو روی لایه هایی که تعداد نورون های بیشتری دارن استفاده کنید از کم شروع کنید برید بالا
سلام آقای حسن پور
واقعا دستتون درد نکنه که وقت میذارید و به سوالای ما جواب می دین کارتون عالیه.
به عنوان آخرین سوال، همانطور که گفتم توی لایه های اخر Vgg19 تغییراتی انجام دادم و دقتی که برای دیتاستم به دست میارم ۹۸ درصد میشه از طرفی هم تعداد پارامترها کاهش پیدا کرده و از ۱۴۰ میلیون شده ۳۳ میلیون.
خواستم بدونم اینکه توی همه زمینه ها بهبود داشتم جای شک نداره؟ یعنی هم پارامترام کم شده(محاسبات کمتر شده)، هم دقتم افزایش پیدا کرده ، به مراتب لاس هم کاهش پیدا کرده.
بیشترین تعداد پارامترهای وی جی جی نت در همون لایه های اخره پس اگر اونها رو تتغییر بدید و کمتر کنید تعداد پارامترهای شبکه هم تغییر زیادی میتونه بکنه و این عادیه .
دقت ۹۸ درصد بدست اوردن روی مدلی که قبلا روی ایمیج نت ترین شده و برای کاری فاین تون شده (و تصاویر هم ماهیت نسبتا مشابه و کافی باشه) معمولا عادیه . یعنی بصورت پیشفرض با فاین تون باید انتظار دقت بسیار بالاتری رو نسبت به حالت ترین معمولی رو دیتای (کم) خودتون داشته باشید. اینکه به چه حدی دقت برسه بسته به دیتاست نهایی شما (تعداد تصاویر و میزان نزدیکی اون با تصاویر ترین شده قبلی (ایمیج نت) و همینطور ماهیت و پیچیدگی اون تصاویر ) هست.
سلام
دیتاست من ۲۰هزار تا تصاویر رانندگان در حالت های مختلف رانندگیه(مثل صحبت با موبایل هنگام رانندگی) توی ۱۰تا کلاس، من توی بخش ترین به تصاویر ترین یک در میان نویز زیادی اعمال می کنم. بعد ترین هم تصاویر تست رو کاملا نویزی میکنم و عمل پریدیکت رو انجام می دم ، وقتی vgg19 اورجینال باشه دقت ۹۵ درصد میشه و وقتی لایه های اخر رو تغییر میدم دقت ۹۸درصد میشه(البته تمام لایه های vgg19 رو خودم دستی مینویسم یعنی از جایی دانلود نمیکنم).
منظور من این بود که آیا تعداد پارامترها با دقتی که به دست میاد رابطه مستقیم داره ؟ یعنی هرچی پارامتر بیشتر باشه دقت بیشتر میشه و اگه کمتر باشه دقت کمتر میشه(این جمله درسته ؟)
تعداد پارامتر ارتباط با دقت شما داره اما الزاما پارامتر بیشتر همیشه بهترین دقت رو بشما نمیده چون به همون میزان نیازمند داده بیشتر جهت ترین وزنهای موجود هستید با مساله اورفیت هم به همین خاطر شما در گیری بیشتری دارید. برای همین هم هست که وقتی پارامتر ها رو کمتر کردید دقتتون بهتر شد.
اگه از صفر استارت میزنید بهتره از معماری های دیگه استفاده کنید معماری ویجی جی نت یکی از غیربهینه ترین معماری هاست! معماری های به مراتب بهینه تری وجود دارن که میتونید استفاده کنید.
ممنون اینو من برای پایان نامم انجام میدم نصف راهو اومدم دیگه نمیتونم معماری دیگه سوییچ کنم.
به نظرتون میشه به این نتایج اتکا کرد؟؟ هدفم اینه که شبکه رو نسبت به تصاویر نویزی مقاوم کنم الان هم دقت ۹۸ میده.
نمودارهاتون مشکلی رو نشون نمیدن و نرمال هستن اگه فرایند ترینینگ و تست شما هم بدرستی پیاده شده باشه مشکلی ندارید
سلام .یه سوال داشتم ..جوابش خیلی برام مهمه .ممنون میشم جواب بدین
من برای پایان نامم دارم روی تشخیص نمادهای اشاره ای در زبان انگلیسی با استفاده از شبکه کانولوشن کار میکنم
من اینجا آزمایشاتم رو روی تغییر توابع بهینه سازی به خاطر اهمیت وزن ها در خروجی شبکه انجام دادم و از توابع adam ،sgd و rmsprop استفاده کردم…در ضمن آزمایشات روی دو تا مجموعه داده انجام شده..مجموعه ASL که ۸۷۰۰۰ تصویر دارد و مجموعه داده ای که خودم جمع آوری کردم ۱۰۰۰ تصویر داره و روی این مجموعه data augmentation رو اعمال کردیم..در نتایج آزمایشات روی مجموعه asl تابع بهینه rmsprop نوسانات زیادی داشته توی نمودار خطا و دقت وتوی آزمایشات روی مجموعه داده خودم نتایج sgd نوسانات زیادی داشته …علت این نوسانات توی نتایج چی میتونه باشه ؟؟؟
میتونه به خاطر استفاده از لایه dropout باشد؟؟؟؟
یا اندازه مجموعه داده؟؟
خواهش میکنم جواب بدید
سلام در ایمیلی که دادید پاسخ دادم خدمتتون
سلام آقای حسن پور
یه سوال در مورد بخش تبدیل لایه تمام متصل به لایه کانولوشنی داشتم، اونم اینکه ایا با انجام اینکار ممکن هست که دقتمون هم بیشتر بشه یا فقط میتونه برابر بشه؟
سلام
لایه کانولوشن به تنهایی تعیین کننده نیست خیلی المان دیگه هست که میتونه تاثیر گذار باشه.
ممکنه دقتتون بهتر بشه یا بدتر بشه . دلیل بهتر شدن میتونه هم بخاطر انتخاب اندازه کرنل باشه در مقابل تماما متصل هم میتونه بخاطر کاهش تعداد پارامترهای یادگیری باشه
به همین شکل ممکنه بخاطر کاهش پارامترهای قابل یادگیری(با فرض کاهش) (بسته به مدل و ماهیت کار داره) دقت شما بدتر بشه .
میشه این جمله رو گفت که چون بجای لایه کاملا متصل از لایه های کانولوشنی استفاده میکنیم، شبکه عمیق تر میشه و میتونه دقت رو بهبود بده؟
عمق دست شماست میتونید عمیق تر کنید میتونید نکنید. بستگی داره دنبال حفظ عمق اصلی شبکه باشید یا نه.
اما اگه فرض بگیریم در نسخه کانولشنال معماری شما عمیق تر بشه و اگر فرض بگیریم در نسخه اصلی عمق شبکه عمق بهینه نبوده باشه بله باعث بهتر شدن دقت شما میشه.
سلام
بنده منظور این قسمت رو متوجه نمیشم.
By stacking smaller kernels, instead of using a single layer of kernels with a large receptive field, a similar function can be rep- resented with less parameters.
سلام
منظور اینه از اندازه کرنلهای کوچکتر بجای بزرگتر استفاده کنید. یه اندازه فیلتر ۵در۵ اندازه بزرگتری از ورودی رو میبینه اما همین رو میتونید با اعمال ۲ لایه با کرنل ۳در۳ هم بدست بیارید. و فرقش در اینه که در حالت دوم هم تعداد پارامتر کمتری خواهید داشت و هم ناحیه ادراکی به همان نسبت در اختیار دارید.
سلام آقای حسن پور
توی این قسمت CONV3-64: [224x224x64]
منظور از فیلتر ۶۴ چیه ؟ مگر برای انجام عمل کانولوشن نباید فیلتر ما ماتریسی n*n باشه؟
مثل:
۱ ۰ ۱
۰ ۱- ۰
۱ ۰ ۱
سلام. سوالتون واضح نیست. لطفا بیشتر توضیح بدید
منظورتون ۶۴ عدد فیلتر یعنی چی هست؟اگر بله منظور ۶۴ عدد فیلتر هست. به ازای هر فیلتر ما یک فیچرمپ در خروجی خواهیم داشت.
در تصویر زیر یک کرنل رو نشون میده روی تصویر وردی اعمال میشه
https://blog.faradars.org/wp-content/uploads/2018/12/Convolutional-Neural-Networks05.gif
اینکه میگید ۶۴ تا فیلتر داریم، یعنی ۶۴ بار از این کرنل بر روی تصویر اعمال میشه؟
شما ۶۴ کرنل مختلف دارید نه یکی که ۶۴ بار اعمال بشه.
ممنون، این کرنل ها به صورت تصادفی از -۱ تا ۱ مقداردهی میشن ؟
این رنج در عمل استفاده نمیشه و بیشتر برای آموزش و مثال هست. در عمل الگوریتم های مختلفی مثل xavier, msra, etc استفاده میشن . قدیمها (یعنی قبل از سال ۲۰۱۵ ) برای مقداردهی اولیه از mean=0, std=0.1 الی ۰٫۰۱ استفاده میشد و سمپل میشد.
سلام
من يجايي در مورد داده افزايي خونده بودم كه نوشته بود فقط برو روي تصاوير ترين انجام بشه و نياز نيس رو تصاوير وليديشن هم صورت بگيره، خواستم بدونم دليلش چيه؟
ممنون
سلام . عموما به این شکل هست و این مساله مربوط به بحث ترینینگ میشه . خیلی ساده بخواییم بگیم اینکار صورت میگیره تا مدل اصطلاحا فیچرهای خوبی رو یاد بگیره. مشخصا بعد از اینکه فیچرها یادگرفته شد نیازی نیست همون فرایند دوباره طی بشه در ولیدیشن.
دقت کنید که عرض کردم عموما و این یعنی شما میتونید طرح های مختلفی برای ولیدیشن داشته باشید و ورودی رو با ترنسفورمیشن های مختلف هم لحاظ کنید اگر در کار مورد نظر شما مثمر ثمر هست (اما عمومیت نداره بستگی بشما داره و یوزکیستون)
ممنون، میشه دقیقا بگین وظیفه کلی ولیدیشن چیه تو زمان آموزش؟
ولیدیشن ست قراره یک نمونه از داده تست شما باشه قراره بشما دیدی بده که مدلتون رو داده تست واقعی به چه صورت عمل میکنه
(البته در بعضی اوقات در بعضی دیتاستها و کارها میبینید که ولیدیشن ست و تست ست به یک چیز اشاره دارن ولی در هر صورت معیاری هستن برای سنجش کارایی مدل بر روی داده هایی غیر از ترینینگ)
سلام آقای حسن پور
اون قسمت که میگید لایه تماما متصل رو با لایه کانولوشنال عوض میکنیم، با حذف لایههای تماما متصل از شبکه، طبقهبندی نهایی با لایه کانولوشنال چگونه صورت میپذیره؟
سلام
برای این دو حالت انجام میشه.
۱٫ کلسیفایر شما در هر صورت یک لایه تماما متصل هست
۲٫ کلسیفایر شما هم یک لایه کانولوشن خواهد بود که فیچرمپ خروجیش ۱×۱ هست (به تعداد کلاسهای فیچرمپ دارید با اندازه ۱×۱ ) اگر اندازه فیچرمپ ها بیشتر از ۱×۱ باشه با adaptive pooling یا global pooling اون رو قبل از اخرین لایه کانولوشن که حکم کلسفایر شما رو ایفا میکنه اندازه اش رو به سایز درلخواه در میارن.
سلام
ممنون بابت آموزش عالی تون
نگاه کنید من توضیحات و استفاده CNN رو برای تصاویر الان بلدم کلی هم آموزش خب هست
چیزی که خیلی مبهمه و سردر نمیارم، اینه که چطور ویدئو دسته بندی کنیم(محتواهای video clssficatn هم کم و گنگه)
الان ویژگی های مدنظرمون در ویدئو، در مجموعه ای از فریم هاشه و از تک فریم چیزی در نمیاد، اینو نمیفهمم چطور توی پایتورچ یا حالت های دیگه هندل کنم… شما ایده ای دارید؟
سلام در ویدئو کلسیفیکیشن روش های مختلفی وجود داره اما یکی از سر راست ترین ها استفاده از ConvLstm هست.(علاوه بر کانولوشن سه بعدی) . سمپل هم اتفاقا زیاده یه سرچ کوچیک کنید خیلی اطلاعات بدست میارید .
شما باید در درجه اول دنبال state of the art این حوزه باشید بعد پیاده سازی اونها رو تو گیت هاب بگیرید . مثلا یکی از معماری های اخیر Slow fast هست (مربوط به پارساله) و اینم رپو پایتورچ اون هست : https://github.com/facebookresearch/SlowFast
سلام ممنون میشم تماس بگیرید۰۹۱۷۴۲۸۶۲۳۲
سلام
خیلی کامل و عالی بود
دمتون گرم
من یک سوال برام پیش اومده ک هیچطور به جوابش نرسیدم ممنون میشم اگر ممکنه راهنمایی کنید
الان متوجه نمیشم که فیلترها و کرنل برچه اساسی انتخاب میشن
مثلا الان کلی مسائل دیگه متن تصویر خاص و حتی ویدئو داریم، قرار نیست گل و بلبل تشخیص بدیم.
حتی داریم باتوجه به مسئله خاص تصویر باینری میدیم به شبکه، الان چطور باید فیلتر مناسب مسئله مون رو تولید/طراحی یا انتخاب کنیم؟! یعنی مهم نیست که مسئله مون چیه از فیلتر لبه و … باید استفاده کنیم؟! اصلا متوجه نمیشم توی کانولوشنی ویژگی فیلتر ها برچه اساسی طراحی/تولید میشن!؟ از کجا فیلتر بیاریم خلاصه 🙂
ممنون میشم اگر توضیح/آموزش/وب سایت/ یا عنوانی برای سرچ بهم بدید خیلی گیج شدم!
سلام فیلترها حین اموزش توسعه پیدا میکنن و لازم نیست شما فیلتر خاصی رو طراحی یا تولید کنید.
اگر منظورتون همین نبود واضح تر توضیح بدید لطفا
متوجه شدم. بسیار نیک و عالی… ممنون حسین آقا ارادتمندیم 🙂
سلام ، ممنون از مطالب مفیدی که ارائه کردید
ببخشید می خواستم بدونم وقتی یک شبکه را در متلب آموزش می دهیم ، چطور می تونیم وزن های شبکه آموزش دیده را جایگزین مقادیر initial بکنیم. من یک شبکه yolov2 ،آموزش دادم ولی به طور کامل آموزش ندیده و می خوام که هر بار وزن های آخر را جایگزین وزن های جدید بکنم ، خودم کل شبکه آموزش دیده را جایگزین شبکه اولی در برنامه می کنم ولی باز هنگام شروع آموزش مقادیر validation loss و … مقادیر بالایی هستند.
ممنونم
سلام
من متاسفانه با متلب آشنایی ندارم و نمیتونم راهنماییتون کنم.
سلام و دست مریزاد خدمت استاد گرامی جناب آقای حسن پور
من میخواستم از شبکه های کانولوشنی برای تشخیص اختلال عمیق افسردگی از دیتاست EEG استفاده کنم.
آیا منبعی وجود داره که کار رو از پایه آموزش بده ؟
بسیار ممنون میشم اگه راهنمایی بفرمایید.
با سپاس
سلام
منظور شما از پایه دقیقا چیه؟از چه سطحی؟
باید بتونید مطالب مورد نیازتون رو براحتی با سرچ بدست بیارید. اگر دقیقتر توضیح بدید شاید بهتر بشه راهنماییتون کرد.