
بسم الله الرحمن الرحیم
خب میخوام انشاالله اگر خدا بخواد به مرور بخش هایی از اسناد و داکیومنتهایی که قبلا خودم نوشتم رو تو سایت قرار بدم .
قرار بود این کار رو بعد از تموم شدن دفاعم بزارم ولی خب این قضیه داره برای من خیلی کش پیدا میکنه (کاغذ بازی دانشگاه و الان وزارت خارجه! و تایید مدارک استاد راهنمام و… ) و نمیدونم آخرش چی میشه . توکل بخدا .
برای همین تصمیم گرفتم زودتر کارو پیش ببرم . این مطالبی که میزارم نوشته های خودم هست که قراره بخشی از مستندات پایان نامم باشه و ماه ها قبل نوشتمشون ولی هنوز کار دارن و ویرایش نشدن برای همین هر بار یه بخشی رو قرار میدم.
تو بخش اول در مورد کلیات شبکه های کانولوشنی صحبت میکنم و انشاالله طی پست های بعدی وارد جزییات بیشتر میشم.(مطالبی که اینجا اومده و بعدا انشاالله میاد تمام آموزشهای شبکه عصبی کانولوشن دانشگاه استنفورد رو پوشش میده و علاوه بر اون توضیحات تکمیلی و موارد بیشتری هم در بر داره تا مطلب بهتر جا بیوفته.
توجه:
- منبع این اطلاعات آموزش دانشگاه استنفورد هست : من فقط بخش شبکه های کانولوشن رو اینجا میزارم حتما بقیه بخشها رو بخونید چون عالی هستند.
شبکه های کانولوشن :
شبکه های عصبی کانولوشن تا حد بسیار زیادی شبیه شبکه های عصبی مصنوعی هستند که در بخش قبلی در مورد آنها توضیح داده شد. این نوع شبکه ها متشکل از نورونهایی با وزنها و بایاسهای قابل یادگیری (تنظیم) هستند.[۱] هر نورون تعدادی ورودی دریافت کرده و سپس حاصل ضرب وزنها در ورودی ها را محاسبه کرده و در انتها با استفاده از یک یک تابع تبدیل(فعال سازی) غیرخطی نتیجه ای را ارائه دهد. کل شبکه همچنان یک تابع امتیاز (Score function) مشتق پذیر(differentiable) را ارائه میکند, که در یک طرف آن پیکسل های خام تصویر ورودی و در طرف دیگر آن امتیازات مربوط به هر دسته قرار دارد. این نوع شبکه ها هنوز یک تابع هزینه (Loss function) (مثل SVM,Softmax) در لایه آخر (تماما مرتبط یا fully connected) دارند و تمامی نکات مطرحی در مورد شبکه های عصبی معمولی در اینجا هم صادق است.
با توجه به مطالب گفته شده ,تفاوت شبکه عصبی کانولوشن با شبکه عصبی مصنوعی در چه چیزی میتواند باشد ؟ معماری های شبکه های عصبی کانولوشن بصورت صریح فرض میکنند که ورودی های آنها تصاویر هستند , با این فرض ما میتوانیم ویژگی های مشخصی را درون معماری تعبیه (encode) کنیم .با این عمل تابع پیشرو (forward function) را میتوان بصورت بهینه تر پیاده سازی کرد و همینطور با این کار میزان پارامترهای شبکه نیز بشدت کاهش پیدا میکند.
خلاصه معماری
همانطور که ما میدانیم, شبکه های عصبی یک ورودی دریافت میکنند (در قالب یک بردار ) و سپس آنرا از تعدادی لایه مخفی (Hidden layer) عبور میدهند. و نهایتا یک خروجی که نتیجه پردازش لایه های مخفی است در لایه خروجی شبکه ظاهر میشود. هر لایه مخفی از تعدادی نورون تشکیل شده که این نورون ها به تمام نورون های لایه قبل از خود متصل میشوند. نورونهای هر لایه بصورت مستقل عمل کرده و هیچ ارتباطی با یکدیگر ندارند. آخرین لایه تماما متصل (fully connected layer) به لایه خروجی (output layer) معروف است و معمولا نقش نمایش دهنده امتیاز هر دسته(class) را ایفا میکند.
شبکه های عصبی معمولی برای تصاویر معمول(full images) بخوبی مقیاس پذیر نیستند. بعنوان مثال تصاویر موجود در دیتاست CIFAR-10 [2] اندازه ای برابر با 32x32x3 دارند (۳۲ پیکسل عرض, ۳۲ پیکسل ارتفاع و ۳ کانال رنگ ) . بنابر این یک نورون با اتصال کامل (fully connected) در لایه مخفی اول یک شبکه عصبی معمولی 32x32=3072 وزن خواهد داشت . این مقدار شاید در نظر اول مقدار قابل توجهی بنظر نیاید اما بطور واضح مشخص است که این معماری تماما مرتبط قابل استفاده برای تصاویر بزرگتر نخواهد بود. برای مثال یک تصویر با اندازه متعارف تر مثل ۲۰۰ x 200 x 3 باعث میشود که یک نورون 200x200x3=120,000 وزن داشته باشد!. علاوه بر این ما قطعا خواهان تعداد بیشتری از این نورون ها خواهیم بود , پس تعداد پارامترها بسرعت افزایش پیدا میکند . مشخص است این اتصال کامل (Full connectivity) باعث اتلاف (wasteful) بوده و تعداد بسیار زیاد پارامترها هم بسرعت باعث overfitting خواهد شد.
توده های سه بعدی از نورونها!(۳d volumes of neurons):
شبکه های عصبی کانولوشن از این واقعیت که ورودی شامل تصاویر است استفاده کرده و معماری شبکه را به روش معقولی محدود کردند. بطور خاص, برخلاف یک شبکه عصبی معمولی, لایه های یک شبکه عصبی کانولوشن (به اختصار ConvNet) شامل نورونهایی است که در سه بعد عرض, ارتفاع و عمق قرار گرفته اند(مرتب شده اند).(دقت کنید که کلمه عمق در اینجا اشاره به بُعد سوم یک توده فعال سازی (activation volume)[3] دارد و به معنای عمق یک شبکه عصبی کامل که به معنای تعداد لایه های موجود در آن است نمیباشد.). بعنوان یک مثال, تصاویر ورودی از دیتاست CIFAR-10 ,هر کدام یک توده ورودی حاوی مقادیر فعال سازی[۴] an Input volume of activations)) هستند که دارای ابعاد 32x32x3 (عرض, ارتفاع و عمق ) هستند. همانطور که جلوتر خواهیم دید, هر نورون در هر لایه بجای اتصال با تمام نورون ها در لایه قبل تنها به ناحیه کوچکی از لایه قبل از خود متصل است. علاوه بر آن, لایه خروجی نهایی برای تصاویر رقابت CIFAR-10 دارای 1x1x10 بُعد خواهد بود., چرا که همگام با رسیدن به انتهای معماری شبکه ConvNet ما اندازه تصویر را کاهش میدهیم بگونه ای که در انتها تصویر کامل ورودی ما به یک بردار حاوی امتیاز دسته ها (کلاسها) کاهش پیدا میکند و ما با یک بردار که حاوی امتیاز هر دسته است مواجه خواهیم بود. این امتیازات در امتداد بعد عمق(depth dimension) مرتب شده اند. نمایشی از این عمل را در زیر میتوانید مشاهده کنید :
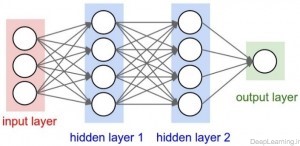
یک شبکه عصبی معمولی با ۳ لایه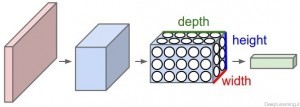 یک شبکه عصبی کانولوشن
یک شبکه عصبی کانولوشن
همانطور که در تصویر بالا میبینید در هر لایه, یک شبکه عصبی کانولوشن (ConvNet) نورون های خود را در ۳ بعد مرتب میکند (عرض , ارتفاع و عمق ) هر لایه یک شبکه ConvNet ورودی را در قالب یک توده سه بعدی به یک توده سه بعدی خروجی از مقادیر فعال سازی نورونها تبدیل میکند. در این مثال لایه ورودی قرمز رنگ حاوی تصویر است(مقادیر پیکسل های تصویر) بنابر این عرض و ارتفاع آن ابعاد تصویر خواهند بود و عمق آن هم برابر با ۳ خواهد بود (کانال های قرمز, سبز و آبی مربوط به تصویر)
یک شبکه ConvNet از چند لایه تشکیل میشود و هر لایه شیوه کار ساده ای دارد. که در آن یک توده سه بعدی ورودی دریافت کرده و آن را با استفاده از توابعی مشتق پذیر (differentiable function) که ممکن است با پارامتر یا بدون پارامتر باشند به یک توده سه بعدی خروجی تبدیل میکند.
[۱] از آنجایی که مقادیر مربوط به این پارامترها ی مراحلی بصورت خودکار تنظیم میشود, ما از ان به یادگیری یاد میکنیم , چرا که شبکه عصبی گام بگام با یادگیری این پارامترها قادر به انجام وظیفه شناسایی محول شده به آن میشود.
[۲] یکی از دیتاست های معروف که جهت رقابتهای جهانی پردازش تصویر مورد استفاده قرار میگیرد. این دیتاست شامل ۶۰ هزار تصویر رنگی با اندازه ۳۲×۳۲ پیکسل در ۱۰ دسته مختلف است. (CIFAR-10 and CIFAR-100 datasets, 2012)
[۳] توده فعال سازی یا Activation volume به یک توده سه بعدی حاوی مقادیر عددی گفته میشود که بعنوان ورودی به تابع فعال سازی ارسال میشوند, برای همین به آنها توده فعال سازی گفته میشود. مقادیر موجود در این توده ها ممکن است مقادیر متناظر به پیکسلهای خام تصاویر باشند (توده فعال سازی ورودی) و یا نتیجه پردازش های انجام شده تا لایه خاصی در شبکه باشند (بعنوان مثال توده فعال سازی در لایه دوم یعنی مقادیر عددی در لایه دوم که نتیجه عملیاتهای لایه های قبل تا لایه فعلی است (ضرب وزنها در خروجی حاصل از لایه قبل و…)
[۴] در اینجا مقادیر فعال سازی چیزی جز مقادیر مربوط به پیکسل های خام تصاویر ورودی نیستند.
لایه های مورد نیاز برای ایجاد یک شبکه ConvNet
همانطور که در بالا اشاره کردیم, هر لایه شبکه کانولوشن یک توده فعال سازی را از طریق یک تابع مشتق پذیر به توده فعال سازی دیگر تبدیل میکند. ما از سه نوع اصلی لایه ها برای ساخت یک معماری شبکه کانولوشن استفاده میکنیم . این لایه ها عبارتند از : لایه کانولوشن, لایه Pooling و لایه تماما متصل (Fully connected layer) که دقیقا همانند همان که در شبکه های عصبی معمولی میبینیم است . ما این لایه ها را روی هم قرار میدهیم تا یک معماری کامل از شبکه کانولوشن ایجاد کنیم .
برای روشن تر شدن بیشتر مباحث بالا یک شبکه کانولوشن ساده برای دسته بندی دیتاست CIFAR-10 ایجاد میکنیم . برای اینکار ما میتوانیم یک معماری با لایه های لایه ورودی , لایه کانولوشن, لایه RELU , لایه POOL , لایه FC داشته باشیم .
لایه ورودی (Input layer) شامل مقادیر پیکسل های خام تصویر ورودی ما هستند . یعنی در اینجا ما یک تصویر با عرض ۳۲ , ارتفاع ۳۲ و ۳ کانال رنگ قرمز,سبز , آبی خواهیم داشت.
لایه کانولوشن (CONV layer) این لایه خروجی نورونهایی که به نواحی محلی در ورودی متصل هستند را محاسبه میکند. عمل محاسبه هم از طریق ضرب نقطه ای بین وزن های هر نورون و ناحیه ای که آنها به آن(توده فعال سازی ورودی) متصل هستند صورت میگیرد. نتیجه این عمل یک توده با اندازه
32x32x12 میشود.
لایه RELU بر روی تک تک نورون ها یک تابع فعال سازی مثل max(0,x) (که آستانه گذاری را بر روی ۰ انجام میدهد یعنی مقادیر منفی را صفر در نظر میگیرد) را اعمال میکند. این کار تغییری در اندازه توده از مرحله قبل نمیدهد بنابر این نتیجه همچنان یک توده با اندازه
32x32x12 خواهد بود .
لایه Pooling عملیات downsampling را در امتداد ابعاد مکانی (عرض و ارتفاع) انجام میدهد که نتیجه این کار یک توده با اندازه
16x16x12 خواهد بود . همانطور که دقت کردید در لایه pooling ما ابعاد توده ورودی (تصویر) را کاهش میدهیم.و در اصل از طریق عملیات این لایه است که در انتهای شبکه کانولوشن ما به یک بردار امتیاز دست پیدا میکنیم .
لایه FC یا تماما مرتبط وظیفه محاسبه امتیاز دسته ها (class) را دارد. نتیجه کار این لایه یک توده با اندازه
1x1x10 است که هر کدام از این ۱۰ عدد نمایانگر یک امتیاز برای یک دسته بخصوص (مثل یکی از ۱۰ دسته تصویر موجود در دیتاست CIFAR-10 ) است. مثل شبکه های عصبی معمولی و همانطور که از اسم این لایه بر می آید هر نورون در این شبکه با تمام نورون ها در توده قبل از خود ارتباط دارد.
با این روش, شبکه کانولوشن مقادیر پیکسل های خام تصویر اصلی را لایه به لایه به امتیاز دسته ها در انتهای شبکه تبدیل میکند.. دقت کنید که بعضی از لایه ها پارامتر داشته و بعضی دیگر فاقد پارامتر اند. بطور خاص لایه های Conv/FC لایه هایی هستند که تبدیلاتی را انجام میدهند که نه تنها تابعی از فعال سازی ها(مقادیر موجود) در توده ورودی اند بلکه تابع پارامترهایی نظیر وزن و بایاس نورون ها هم هستند .از طرف دیگر لایه های RELU/POOL تنها یک تابع ثابت را پیاده سازی میکنند. پارامترهای موجود در لایه های Conv/FC توسط روش gradient descent آموزش میبینند تا امتیازات دسته ها (class)یی که شبکه کانولوشن حساب میکند با برچسب های هر تصویر در مجموعه آموزشی سازگار باشد.(همخوانی داشته باشد).
بطور خلاصه :
• یک معماری شبکه کانولوشن لیستی از لایه هاست که توده متشکل از تصویر ورودی را به یک توده خروجی ( مثل توده ای که امتیازات دسته ها را در خود دارد) تبدیل میکند.
• تعداد کمی از انواع لایه ها برای شبکه کانولوشن وجود دارد( بعنوان مثال CONV/FC/RELU/POOL متداول ترین لایه ها در شبکه کانولوشن هستند)
• هر لایه یک ورودی سه بعدی را دریافت کرده و انرا از طریق یک تابع مشتق پذیر به یک توده سه بعدی خروجی تبدیل میکند .
• هر لایه ممکن است دارا یا فاقد پارامتر باشد (بعنوان مثال لایه های CONV/FC دارای پارامتر و لایه های RELU/POOL فاقد پارامتر هستند)
• هر لایه ممکن است دارا یا فاقد فرا پارامتر(hyperparameter) اضافی باشد. (مثلا لایه های CONV/FC/POOL دارای این نوع پارامترها هستند در حالی که لایه RELU فاقد این نوع پارامتر است)

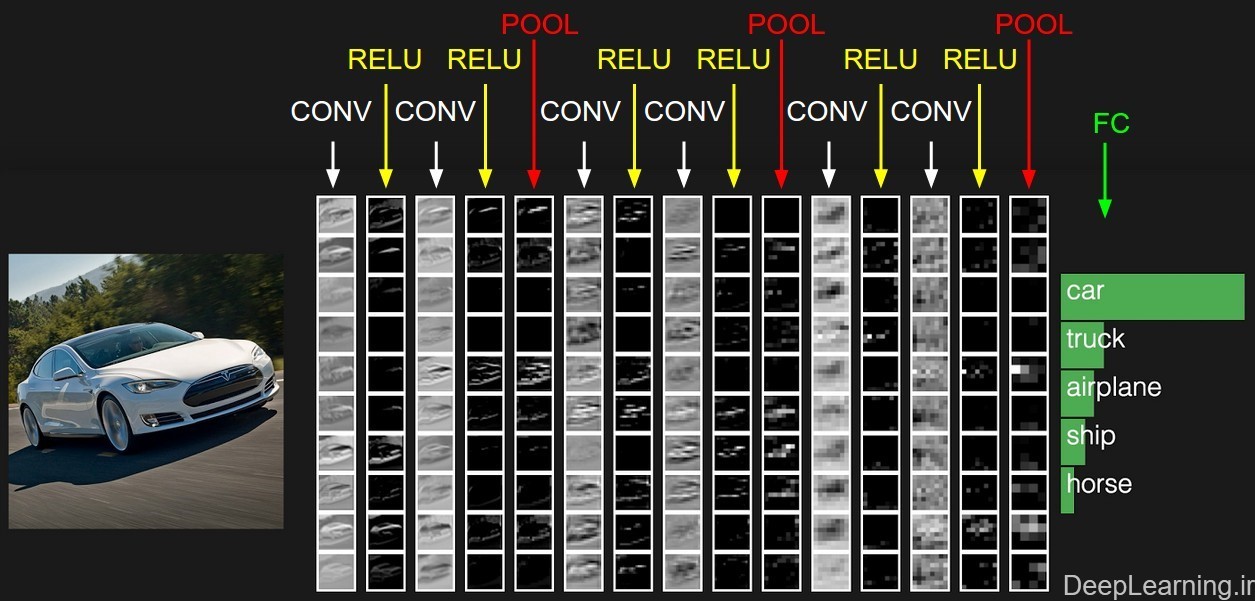
نمونه ای فعال سازیهای در یک نمونه از معماری شبکه کانولوشن .
توده ابتدایی پیکسل های خام تصویر را در خود ذخیره میکند(تصویر اتومبیل در سمت چپ) و آخرین توده امتیاز دسته ها را در خود جای میدهد(لایه تماما متصل یا به اختصار FC). هر توده فعال سازی در طی مسیر پردازش در قالب یک ستون نمایش داده شده است. از آنجایی که نمایش توده های ۳بعدی مشکل است ما برشهای (قاچهای) هر توده را بصورت سطری مرتب کردیم. توده مربوط به آخرین لایه حاوی امتیازات مربوط به هر دسته (class) است. اما در اینجا ما تنها ۵ امتیاز بالاتر را نمایش دادیم . معماری نمایش داده شده در اینجا یک شبکه VGGNet کوچک است که جلوتر در مورد آن توضیح داده ایم .
ما حالا میتوانیم بعد از این آشنایی اولیه , به جزییات بیشتر در رابطه با این لایه ها بپردازیم . در بخش بعد لایه های مختلف و جزییات مربوط به فراپارامترها و اتصالات آنها شرح داده میشوند.
اتمام بخش اول
سید حسین حسن پور
بهار ۹۵
سلام.
بابت مطالب مفیدتون واقعا ممنون.
سلام .
خواهش میکنم .
با سلام و احترام
خیلی ممنون از مطالب خوب سایتون.امکانش هست که پیاده سازی این شبکه رو هم تو سایت بزارین.و یه خواهش دیگه و آنم اینکه در مورد شبکه کانولوشن عمیق هم مطلب دارین آن رو هم در سایت قرار بدین.با سپاس
سلام.
خواهش ميكنم خدا رو شكر مفيد واقع شد.
تو بخش منابع يادگيري اگه دقت كنيد چند نمونه پياده سازي لينكش قرار داده شه (با جاوا اسكريپت با پايتون و با سي++) كه ميتونيد نگاه كنيد.
سورس كد فريم وركهايي مثل Caffe هم هست كه ميتونيد نگاه بهشون بندازيد . براي دانلود بخش ابزارها رو ببينيد لطفا.
شبكه كانولوشن عميق همين شبكه كانوشن هست هيچ فرقي با اين نداره جز اينكه كه تعداد لايه هاش بيشتره.(مثلا LeNet فككنم دو لايه داشت . كه يه شبكه كانولوشن ساده (كم عمق) بود. بعد از اون هرجا اسم شبكه كانولوشن رو ديديد منظور ورژن عميق اون هست (مثل الكس نت با فك كنم ۸ لايه يا vggnet با ۱۶ تا ۱۹ لايه يا گوگل نت با ۲۲ لايه و يا اخيرا ResNet با ۱۵۲ لايه) امروزه هرجا اسمي از شبكه كانولوشن ميشنويد منظور شبكه عصبي كانولوشن عميق هست كه چون همه ميدونن ديگه كمتر اون بخش عميق رو ذكر ميكنن.
سلام.
مطالب سایتتون برای من تا این مرحله بسیار مفید بوده است . خوشحالم که هنوز افرادی هستند که
بدون هیچ توقعی برای مردمشون خدمت می کنند.
واقعا ممنونم.
یک سوال داشتم: من یه سری تصویر دارم که میخوام از طریق cnn کلاس بندی انجام دهم.
داده های من دو کلاسه هستند و سطح روشنایی خاکستری دارند(رنگی نیست). و همچنین ابعاد داده من ۵۰ در ۵۰ هستش. از چه کد آماده ای برای انکار میتونم
استفاده کنم؟؟
خوشحال میشم راهنماییم کنید.
m.norizadeh1369@gmail.com
سلام .
خب خدا رو شکر . پس برای ما یه دعا کنید آخر عاقبت بخیر بشیم و خدا هم قبول کنه 🙂
شما میتونی براحتی از هر فریم ورکی استفاده کنی . چه Caffe چه Torch و چه نمونه های دیگه .
تو Caffe هم نمونه Classification داریم هم به سی++ هم پایتون و هم متلب یعنی با هر کدوم اینا میتونید با تغییرا جزئی کارتون رو انجام بدید. آموزش شبکه هم براحتی با خود Caffe قابل انجامه .
آموزش های اولیه رو دادم تو همین سایت . یه نگاه بندازید خوبه .
باز اگه سوالی بود میتونید تو همین کامنت یا بهتر تو گروه یادگیری عمیق که لینکش تو سایت دادم بپرسید و انشاالله بلد بودیم کمکتون کنیم .
در پناه حق انشالله همیشه موفق و سربلند باشید
التماس دعا
سلام.
ممنون بابت پاسختون.
من برای کلاس بندی دو تا داده دارم که مربوط به تصویر هواپیما و صندلی است. از هر کلاس ۲۰ تصویر برای آموزش استفاده می کنم که مجموعا ۴۰ تصویر برای آموزش و ۴۰ تصویر برای تست استفاده کردم. متاسفانه خوب کار نمیکنه!!! همه کلاسارو ۲ تشخیص میده!!!
جزئیات کار: تصویر ۹۶*۹۶
دو لایه کانولوشن و دو لایه pooling
اندازه کرنل ۵*۵
stride=1 در نظر گرفته در این کد. و پدینگ هم نداره.
برای داده minst که باهمین مشخصات ولی سایز تصویر ۲۸*۲۸ هست خوب کار میکنه.
از این تولباکس استفاده کرده ام: rasmusbergpalm-DeepLearnToolbox-5df2801
لطفا راهنماییم کنید که باید چیکار کنم؟؟
سلام.
تعداد تصاویر شما خیلی کمه . MNIST رو که میبینید خوب جواب میده ۶۰ هزارتا عکس داره . ۵۰ هزارتاش فقط برای اموزش هست و ۱۰ هزارتاش برای تست.
بعد الزاما یک پیکربندی و معماری که برای یه دیتاست خوب کار میکنه برای دیتاست دیگه خوب کار نمیکنه و باید خوب تستش کنید و حتما زمان تست سعی کنید نمودار Loss/accuracy رو رسم کنید و بصورت عینی ببینید اموزش چطور داره پیش میره .
شما قبل از اینکه پیکربندی رو دست بزنی اول باید تعداد تصاویرت رو زیاد کنی .
برای این کار دو کار میتونی انجام بدی .
۱٫ اول یه دیتاست از تصاویر که مثل تصاویر شماست گیر بیار و شروع کن رو اون دیتاست اموزش دادن شبکه ات و بعد که به دقت خوبی رسیدی مدل رو سیو میکنی و میای روی تصویر خودت شروع میکنی به تنظیم دقیق (به این کار میگن transfer learning و اموزش انجامش تو Caffe تو سایت هست)
معمولا هم وقتی تعداد تصاویر کم باشه از این روش استفاده میکنن. یا اگه مدل از پیش اموزش داده شده روی تصاویر شبیه تصاویر شما وجود داره از اون هم استفاده میکنن .
۲٫ شما بصورت مصنوعی (اگه نمیتونی داده بیشتری جمع کنی ) بر اساس تصاویری که داری تصاویر جدید ایجاد کنی . یعنی با rotate کردن crop کردن اضافه کردن نویز و… تغییراتی که تاثیر سوئی درنتیجه شما نمیزاره ولی اندازه دیتاستت رو میتونه افزایش بده سعی کنی دیتاستت رو بزرگتر کنی
ضمنا سوالتون رو تو گروه بپرسید بهتره چون علاوه بر من افراد دیگه هم ممکنه کمکهای بهتری بشما بکنن. و مهمتر از اون اگر کسی مشکل شما رو داشته باشه میتونه استفاده کنه.
سلام
کدی که بتونم باهاش تصویر خاکستری با سایز دلخواه به شبکه بدم و بتونم کلاس بندی رو انجام دهم رو
میشه معرفی کنین؟؟
کدهای زیادی هست که همشون یه تصویر با سایز یکسان میگیرن! من الان تصویرم سایزش فرق میکنه و وقتی به شبکه میدم
خطا میده!
لطفا راهنماییم کنید
من نمیدونم شما با چه زبان و یا فریم ورکی کار میکنی اما هم متلب هم سی++ (opencv ) این اجازه رو بشما میدن که تصاویرتون رو resize کنید.
سلام
و با عرض تشكر از شما به خاطر مطالب مفيدتون .
متاسفانه من اين قسمت رو متوجه نمي شم ممنون مي شم اگه امكانش هست يكم بيشتر توضيح بديد
“”شامل نورونهایی است که در سه بعد عرض, ارتفاع و عمق قرار گرفته اند(مرتب شده اند).(دقت کنید که کلمه عمق در اینجا اشاره به بُعد سوم یک توده فعال سازی (activation volume)[3] دارد و به معنای عمق یک شبکه عصبی کامل که به معنای تعداد لایه های موجود در آن است نمیباشد.””
يكم بيشتر شكل شبكه عصبي كانولوشن رو توضيح بديد ممنون مي شم
سلام .
تو شبکه کانولوشن ما با توده های سه بعدی سرو کار داریم . در شبکه های عصبی معمولی (mlp) ما تو هر لایه فقط یکسری نورون داشتیم . مثلا میگفتیم لایه اول ۱۰ تا نورون داره یا ۵ تا نورن داره . لایه دوم مثلا ۲۰ تا نورون داره و الی اخر . و این نورون ها هم همه بهم متصل بودن
یعنی مثلا نورون شماره ۱ به همه نورونها از مرحله قبل وصل بود .
در شبکه کانولوشن (لایه کانولوشن) اینطور نیست یکم ماجرا فرق میکنه. اینجا ما نورونهایی در سه بعد داریم . یعنی یه اندازه مکانی داریم که اشاره به ابعاد توده داره مثلا ۳*۳ و یک عمق داریم که اشاره به عمق این توده داره مثلا ۱۲ که میشه ۳x3x12 . اون ۱۲ یا عمق در اصل تعداد فیچرمپهای خروجی لایه کانولوشن هست (به عبارت دیگه میشه گفت تعداد نورون هایی که در آن واحد به یک ناحیه خاص از ورودی نگاه میکنن هست)
بعد این نورون ها هم با یک مکانیزم محلی روی ورودی اعمال میشن و خروجیشون هم تشکیل یک توده سه بعدی دیگه رو میده .
ادامه آموزش رو بخونید همه اینها مشخص میشه. خصوصا وقتی به بخش دوم برسید یک مثال عملی هم هست که میتونید ببینید عینا چه اتفاقی داره میوفته تقریبا.
سلام
وقتتون بخیر
در این قسمت از متن بالایی که لطف کردین گذاشتین نوشتین که:
“علاوه بر این ما قطعا خواهان تعداد بیشتری از این نورون ها خواهیم بود , پس تعداد پارامترها بسرعت افزایش پیدا میکند . مشخص است این اتصال کامل (Full connectivity) باعث اتلاف (wasteful) بوده و تعداد بسیار زیاد پارامترها هم بسرعت باعث overfitting خواهد شد.”
من احساس میکنم یه تناقضی وجود داره، ما میخواهیم تعداد نورون ها زیاد باشه ولی از طرفی هم تعداد زیاد نورون ها منجر به افزایش تعداد پارامتر ها و اورفیتینگ میشه…پس چرا میخوایم تعداد نورون ها زیاد باشه؟؟ لطفا توضیح میدین…شاید اشتباه متوجه شدم
اینجا اشاره به نقطه ضعف شبکه های عصبی معمولی داره و اینکه چرا اونها برای کار با تصاویر مناسب نیستن .و برای معرفی شبکه کانولوشن و اینکه چه فرقی ایجاد میکنه داده شده.
دو نکته اینجا باید بهش توجه بشه .
نکته اول اینه که بار پردازش رو دوش نورون ها هست یعنی نورون ها واحدهای پردازشی در یک شبکه عصبی هستند.
از طرف دیگه شما هرچقدر واحد پردازشی بیشتری داشته باشید و بصورت درست از اونها استفاده کنید میتونید مساءل غیرخطی پیچیده تری رو تخمین بزنید یا مدل کنید .
اگر بخواییم از شبکه های عصبی معمولی استفاده کنیم با توجه به مسایل بالا با مشکل مواجه هستیم . نمیتونیم از یک اندازه تصویر خاص بالاتر بریم وگرنه مجبور میشیم بخاطر سربار تحمیلی از نورون ها یا واحدهای پردازشی کمتری استفاده کنیم که این خودش به معنای ضعیف کردن قدرت شبکه است و نهایتا بدست نیاوردن یا حتی شکست خوردن در رسیدن به کارایی یا نتیجه مورد نظر رو باعث میشه.
نکته دوم بحث عمیق کردن هست یا بهره برداری از فلسفه معماری های عمیق. برای استفاده از مزایای یک معماری عمیق! باید معماری عمق زیادی داشته باشه و افزایش این عمق هم به افزایش تعداد نورون ها می انجامه که باز باعث ایجاد مشکل در سناریوی اول ما میشه .
در شبکه های کانولوشن با ایجاد اشتراک پارامتر تا حد خیلی زیادی این مساله برطرف شده . البته دقت کنید که لایه هایی مثل fully connected یا locally connected نمونه هایی هستن که در اونها هر نورون دارای وزن برای خودش هست . فرق بین fully connectedبا locally connected هم در این هست که دومی بر خلاف اولی لوکالیتی تصویر رو در نظر میگیره .
ببخشید یه سوال دیگه هم دارم
منظورتون از این جمله شبکه های عصبی مصنوعین یا کانولوشنی؟
“نورونهای هر لایه بصورت مستقل عمل کرده و هیچ ارتباطی با یکدیگر ندارند.”
شبکه عصبی معمولی یا همون multi layer preceptron منظور هست.
از مطالب بسیار مفید شما و زحمتی که برای تهیه آنها کشیده اید بینهایت سپاسگزاریم.
سلام .
خواهش میکنم انشاالله مفید فایده واقع بشن.
در پناه حق موفق و سربلند باشید
سلام و سپاس از توضیحات عالی شما.
سلام ممنون از مطلب عالی شما یه سوال داشتم:
چرا خروجی لایه کانولوشن عمقش ۱۲ می شود؟
لایه کانولوشن (CONV layer) این لایه خروجی نورونهایی که به نواحی محلی در ورودی متصل هستند را محاسبه میکند. عمل محاسبه هم از طریق ضرب نقطه ای بین وزن های هر نورون و ناحیه ای که آنها به آن(توده فعال سازی ورودی) متصل هستند صورت میگیرد. نتیجه این عمل یک توده با اندازه ۳۲x32x12 میشود.
سلام .
خواهش میکنم .
اون یک فراپارامتر هست که دست خود شماست. این عدد مشخص کننده تعداد فیلترهای شماست و هر فیلتر هم یه فیچرمپ تولید میکنه.
(اصلش رو اگه بخوایید در اصل اون تعداد نورونهایی هست که در یک لحظه به یک ناحیه از ورودی نگاه میکنن. ولی شما مثل بقیه این رو بعنوان تعداد فیلتر/فیچرمپ در نظر بگیرید که درکش براتون راحت تر باشه)
ما خودمون هم بخواییم حرف بزنیم و توضیح بدیم ازش بعنوان تعداد فیلتر یاد میکنیم. دیگه نمیگیم این همون تعداد نورون و…. هست.
اگه شبکه عصبی کار کردین این دقیقا معادل مشخص کردن تعداد نورون در هر لایه شبکه عصبی معمولی هست.)
[…] قبلی : آموزش شبکه کانولوشن بخش اول […]
سلام آقای حسن پور،
من یه سوالی داشتم راجع به استفاده از شبکه های کانولوشن برای تخمین توابع (function approximation or function fitting) . آیا برای تخمین توابع می شه از این نوع شبکه ها استفاده کرد. به عنوان مثال من یه تابع دارم که معادله اش نا مشخص هست و می خوایم توی یه بازه خیلی وسیع اونو شناسایی کنیم و تنها به یه سری داده رندم از اون تابع دسترسی داریم. آیا امکان استفاده از شبکه های کانولوشن برای این کار هست. یا استفاده از این شبکه ها فقط و فقط محدود به پردازش تصویر و خوشه بندی میشه؟
سوال دوم اینکه معادل nftool در نرم افزار متلب آیا جعبه ابزاری برای تخمین توابع توسط شبکه های کانولوشن وجود داره؟
ممنون میشم اگه راهنمایی بفرمایید
سلام .
از شبکه های کانولوشن شما میتونید در موقعیت هایی استفاده کنید که یک ارتباط بین ترتیب و جایگاه قرارگیری داده ها نسبت به هم وجود داشته . مثلا اگه شما داده ای داشته باشید که ارتباط معناداری در ترتیب قرارگیری اونها وجود نداره
به احتمال بسیار زیاد شبکه کانولوشن کارایی نخواهد داشت. الزامی وجود نداره که ورودی حتما تصویر باشه میتونه متن و همینطور سیگنال هم باشه. منتها چیزی که هر سه اینها اشتراک دارن اون بحث همسایگی اونهاست . تو تصاویر اگر شما ترتیب پیکسلها رو بهم بریزید دیگه ماهیت تصویر کلا از دست میره
این قضیه در مورد متون هم صادقه . در مورد سیگنالها هم صادقه .
حالا شما اگه داده ای دارید مثلا میگم شاید مثال دقیق و صحیحی هم نباشه ، فرض کنید چند ستون داده دارید اگه بتونید این ستونها رو جابجا کنید اما باز مفهوم تغییری نکنه این گزینه خوبی برای کانولوشن نیست چون ترتیب بین داده ها وجود نداشته.
ولی باز من پیشنهاد میکنم این سوال رو در Quora بپرسید اونجا افراد خبره ای این حوزه هستن که میتونن خیلی کمکتون کنن مثل یان لیکون مثل جفری هینتون و….
در مورد سوال دومتون هم متاسفانه من اطلاعی ندارم چون اصلا با متلب کار نمیکنم .
بینهایت از راهنمایی هاتون سپاسگزارم آقای حسن پور. در آستانه سال نو براتون ایام خوشی آرزومندم.
سلام
زنده باشید انشاالله در پناه خدا شما هم تحویل سال و همچنین سال نوی فوق العاده ای در پیش داشته باشید
در پناه خداوند انشاالله همیشه موفق و سربلند باشید
با سلام و خسته نباشید و آرزوی سال پر از توفیق برای شما
یه سوال داشتم، من یه دیتا بیس دارم که درباره activity Health میباشه، به این صورت که یه سری فعالیت مثل دراز کشیدن، دویدن، نشستن، کامپیوتر کار کردن و… رو داخلش برای آدمهای مختلف قرار دادن. می خواستم بدونم می تونم با شبکه CNN هر کدوم از این فعالیتهای موجود رو کلاسبندی کنم. مثلا با ورود دیتای یه قسمت از دیتابیس سیستم اتوماتیک بگه این مربوط به فعالیت خوابیدن بوده یا پیاده روی بوده. امکان این کار اصلا وجود داره یا نه
ممنون از راهنماییتون میشم
سلام
بله شدن میشه اما الان شیوه های ترکیبی CNN+LSTM بهترین نتایج رو ارائه میکنن (بر اساس اخرین اطلاعاتی که من دارم )
یه سرچ ساده کنید با activity recognition in deeplearning اطلاعات خیلی خوبی بدست میارید
اینم ببینید خوبه
با سلام مجدد و خسته نباشین و تشکر ویژه بابت اینکه اینقدر خوب پاسخگو هستین خدا بهتون خیر بده
سوالی که داشتم در باره این بود که وقتی مراحل کانولوشن و pooling انجام میشه و داده ها تبدیل به یه سری اجزای کوچک می شن به یه شبکه فول کانکت متصل میشن که پیرو فرمایشات جنابعالی این فول کانکتت یه شبکه عصبی مثل mlp میباشه. حالا مشکل بنده اینجاست که نمی دونم چطوری شبکه تست میشه. برای مثال اگه یه سری تصویر ۳۲*۳۲ به شبکه اعمال کنیم کانلولوشن و پولینگ انجام بشه و اجزا به ۱۲۰ نرون کوچک تبدیل بشن و سپس آموزش ببینه، چطوری تصویر جدید ۳۲*۳۲ رو باید به شبکه اعمال کنیم تا طبقه بندی رو برای ما انجام بده؟ آیا بایستی که تصویر رو به اندازه تعداد نرونهای شبکه فول کانکتت در بیاریم و به net شبکه آموزش داده شده اعمال کنیم یا نه؟
خیلییی ممنون میشم درباره این موضوع راهنماییم کنید
بازم تشکر
سلام .خواهش میکنم
من دقیق متوجه نشدم چی شد اما چیزی که برداشت کردم رو یه توضیحی میدم اگر اشتباه متوجه شدم یا جایی گنگ هست بفرمایید تا بیشتر باز بشه.
اول اینکه تصاویر به ۱۲۰ نورون و… تبدیل نمیشن. ما طی لایه های مختلف نگاشت های مختلفی از داده ورودی بدست میاریم . و در همین حین هم معمولا کاهش ابعاد داریم. نهایتا یکسری داده داریم که به نورونهای مختلف تغذیه میشن و وزنهای اونها تنظیم میشه . حالا بعد از اینکه این وزنها بطور مناسب تنظیم شدن فاز اموزش ما تموم میشه . نوبت تست هست . در تست هم خیلی ساده یک تصویر جدید به شبکه تغذیه میکنیم و همه کارهایی که در فاز اموزش انجام میشه اینجا هم تقریبا انجام میشه فقط فرقش در اینه که ما دیگه فاز پس انتشار خطا نداریم. صرفا ورودی ما در مقادیر وزنها که از مرحله اموزش تنظیم شدن ضرب میشن تا نهایتا بعد انجام همه محاسبات به یک عدد در انتهای شبکه برسه . انتهای شبکه ما نورون های مختلفی رو بعنوان معرف هر کلاس مشخص کردیم که بطور خودکار طوری وزنهاشون تنظیم شده اس که هر وقت یک کلاس خاص وارد بشه اون نورون مربوطه بالاترین خروجی رو ارائه بده .
سلام . ممنون از مطالبتون
من میخواهم از مطالب شما در پایان نامه ام استفتده کنم . لطف میکنید به من بگید رفرنسی خودتون که برای پایان نامه یا مقاله شما باید بذارم رو ؟
سلام
مطالب من به دو صورت هست. اگه از مطالب سایت استفاده کردید میتونید همین سایت رو ارجاع بدید اگر نه عنوان پایان نامه من (که مطالب سایت از اون گرفته شده) این بود : دسته بندی اشیاء با استفاده از شبکه عصبی کانولوشن عمیق (اگر پایان نامه رو نیاز دارید که بخونید میتونید ایمیل بزنید تا من یه نسخه ای که دستم مربوط به مراحل اخر نگارش رو براتون ارسال کنم )
اگر از شبکه SimpleNet استفاده کردید یا میخوایید بکنید یا بحثهایی که در مقاله (ماحصل پایان نامه) شده رو میخوایید رفرنس بدید میتونید این مقاله رو رفرنس بدید فعلا (https://arxiv.org/abs/1608.06037 )
اطلاعات در مورد ساختار شبکه و… در داخل پایان نامه زیاد بحث نشد و عوضش در مقاله من اون رو اوردم برای همین این گزینه ها پیش روی شماست
سلام. خییییییییییییییییییلی ممنون.
اگر لطف کنید پایان نامه رو برام ارسال کنید ممنون میشم چون زمان خیلی کمی برام باقی مونده و تا تیر باید به استادم متن پایان نامه ام رو تحویل بدم میخوام به خود پایان نامه شما رفرنس بزنم چون مطالب شما فارسی هست برام قابل فهم هست و از مطالب مفیدتون استفاده کنم.
خیییییییلیکمک بزرگی بهم میکنید با ارسال پایان نامه. خدا خیرتون بده .
من ایمیل شمارو ندارم اگر لطف کنید به ایمیل من پایان نامه رو بفرسید ممنون میشم
تشکر و سپاس
zahra.torabi.1367@gmail.com
سلام .
اطلاعات تماس مثل ادرس ایمیل و … از بخش درباره ما قابل دریافت هست.
براتون ارسال شد.
سلام
ببخشید من از شبکه کانولوشن برای پیش بینی نوسان قیمت میخوام استفاده کنم. سوالم این هست که شما از تولباکس متلب برای کد نویسی استفاده کرده اید یاخودتون کد نوشته اید ؟ و اینکه مدل های مثل ALEXNET فقط در زمینه تصویر هستند و در زمینه پیش بینی با شبکه کانولوشن از این مدل ها هم میشه استفاده کرد ؟ یا اینکه براساس چیدمان ورودی ها و با دو لایه که لایه اول ۶ تا ساب سمپل داره و لایه دوم ۱۲ به یک پیش بینی با دقت خوبی برسم راه صحیحی است ؟
سلام
لطفا این سوال رو در بخش پرسش و پاسخ بپرسید.
با عرض سلام وادب واحترام خدمت شما.
از مطالب بسیار مفیدی که بر روی سایت قرار دادید بسیار سپاسگزارم.
من در مورد این مبحث خیلی مبتدی هستم. سوالاتی که دارم شاید با اندک دانش من اشتباه باشه عذر میخوام.
۱ منظور از فیلتر همون نورون ها هستند؟
۲ اندازه فیلتر ها با لایه کانولوشن و وسعت ناحیه ادراکی چه ارتباطی دارند؟
۳ من مفهوم این جمله را متوجه نمیشم؟
With smaller kernels we can stack more convolutional layers, while having the same receptive field of
bigger kernels
سلام
۱٫نه فیلتر همون ماتریس وزن ما هست
۲٫اندازه فیلتر تاثیر مستقیم روی جمع آوری اطلاعات ویا هدردهی اون و همینطور اندازه توده خروجی داره . اندازه فیلتر مساوی receptive field هست در سطح یک لایه. اما وقتی چند لایه باشه بطور غیرمستقیم لایه های بعدی وسعت بیشتری از ووردی رو در بر خواهند گرفت. بخش دوم آموزش شبکه کانولوشن رو بخونید به همه این سوالاتتون پاسخ داده میشه اگر با خوندن اون بخش باز هم متوجه نشدید بپرسید تا توضیح بیشتری بدم.
۳٫معنای اون جمله اینه که با قرار دادن چند لایه کانولوشن با اندازه کرنل(فیلتر ) کوچکتر ، میشه به همون اندازه receptive field یک کرنل بزرگتر رسید (با این تفاوت که در این حالت (کرنل کوچک+تعداد بیشتر لایه کانلووشن) ما غیرخطی بیشتری لحاظ کردیم و به مراتب دقت بهتری میگیریم.)
این هم در همون بخش دو باید بتونید بخونید اگر متوجه نشدید بفرمایید (چون این سوال مرتبط با سوال قبلی شما در مورد مفهوم receptive field هست. )
با سلام.
سپاسگزارم از توجه و پاسخ شما.
بله حتما قسمت ها ی بعدی را هم مطالعه میکنم و اگر باز هم سوالاتی پیش آمد مزاحم وقت جنابعالی میشوم.
از لطف شما ممنونم
با سلام
در cnn گفته میشه که مانند شبکه عصبی سنتی تمام نورون های یک لایه به تمام نورون های لایه ی بعدی متصل نیستند. با توجه با اینکه در cnn ما فیلترهایی داریم که با تصاویر ورودی کانوالو می شوند. و هم چنین لایه های به نام pooling داریم و ساختار با نورون های شبکه عصبی سنتی متفاوت است برای من دو سوال پیش میاد.
۱٫ در cnn به چه چیزی نورون گفته میشه؟(ایا هر فیلتر یک نورون هست؟)
۲٫ چه چیزی باعث میشه تا cnn ها fully connected نباشند؟(وجود لایه pooling؟ یا چیز دیگه ای…)
ممنون میشم اگه در درک این مفهوم به من کمک کنید.
سلام
۱٫در هر لایه کانولوشن اون num_outputیی که مشخص میکنید در اصل تعداد نورون ها هست. ما به ازای هر نورون یک فیلتر داریم و به ازای هر فیلتر یک فیچرمپ ایجاد میشه. اگه بحث سه بعدی لایه شبکه کانولوشن شما رو سردرگم کرده پیشنهاد میکنم بخش پرسش و پاسخ رو حتما مطالعه کنید قبلا سوالهای مختلفی پرسیده شده و اونجا من جواب دادم .
۲٫فولی کانکتد یا تماما متصل اشاره به وجود یک یال منحصر بفرد از هر ورودی به هر نورون هست. چون ما در لایه کانولوشن اشتراک پارامتر داریم دیگه قضیه صادق نیست. لایه پولینگ هیچ ارتباطی با این قضیه نداره . لایه پولینگ یک لایه جداگانه اس مثل لایه نرمالیزیشن مثل لایه رلو مثل لایه فولی کانکتدو…
این سوال هم در بخش پرسش و پاسخ قبلا پرسیده شده پیشنهاد میکنم ابتدا سایت پرسش و پاسخ رو حتما ببینید اگر جوابتون رو نگرفتید (حتی اگر سوالی بود جوابی هم داشت منتها هنوز سردرگم بودید ) اونوقت دوباره بپرسید . ولی حتما سعی کنید ابتدا سوالهای قبلی رو ببینید چون خیلی از سوالات قبلا پاسخ داده شدند و در وقتتون صرفه جویی میشه.
با سلام
مطلبی که میگم خیلی ربطی به این پست اطلاعاتی نداره
سوالم اینه که:معیار انتخاب تعداد نرون ها در شبکه عصبی MLP با تعداد نرون های مثلا ۸۰ مقدار ویژگی و ۵ لایه نهان و ۱ لایه خروجی چیه؟
با تشکر
سلام
در شبکه عصبی mlp معمولی تا جایی که یادم میاد زیر ۳ لایه عموما استفاده میشه و بندرت حتی به ۳ یا بیشتر لایه میرسید. من نمیدونم این سوال شما در مورد معماری های عمیقه یا معماری سنتی منظور شماست .
در موردمعماری های عمیق که یک حکم کلی وجود نداره اصل تا به امروز این بوده شبکه بزرگ و پیچیده ایجاد بشه بعد با رگیولایریزیشن جلوی اورفیت گرفته بشه . البته اصل توسعه تدریجی هم مطرح شده که اشاره به ایجاد یک شبکه بصورت گام بگام و از ساده به سمت پیچیده است
تا با کمترین میزان اورفیت و همینطور سربار پردازشی مواجه باشن و همینطور تعمیم رو بهتر کرده باشن .
در مورد شبکه های سنتی من خاطرم هست یکسری روابط معرفی میکردن برای استارت اولیه و کلا نکات کار با شبکه های عصبی .اسم یکی از معروف ترین کتابها تو این زمینه هم Neural Networks: Tricks of the Trade بود که البته من خودم الان حضور ذهن ندارم . بنظرم اگر بحثتون شبکه های عصبی سنتی هست این کتاب رو حتما یک مطالعه ای کنید .
یه سوال
مفهوم کانولوشن به زبون ساده چیه؟!
سلام. کانولوشن اسم یک عملیات هست که من در انتهای آموزش شبیکه کانولوشن بخش دوم یا سوم در موردش توضیح دادم به زبان ساده . چک کنید باز اگر سوالی بود بفرمایید.
با سلام من یه سوال کلی داشتم که البته الان تو زمینه ی اموزش سبکه های کانولوشن دهنمو مشغول کرده. اینکه validation accuracyاز مقدارtest accuracy بیشتر باشه آیا به معنی اورفیت شدن شبکه هستش. بعترین حالت ممکن برا این دو تا چی هستش؟ کدوم اصولا بیشتر از اون یکی میتونه باشه. و یه سوال کلی اینکه اکیورسی ست رو بعد اینکه شبکه لا ترین ست ترین شد میدیم که تست بشه؟ یا یه مجموعه ای رو از داخل تست ست بعنوان اکسورسی میکشیم بیرون و اونو تست میکنیم؟ اگه همون سمپلهای ترین نباشه که با تست ست هیچ فرقی نداره اکیورسی ست !!!!
سلام .
اگه دیتای شما سه بخش باشه . ترین ولیدیشن و تست ، این امکان وجود داره که شما ولدیشن خیلی خوب بگیرید اما روی تست دقت خوب نگیرید و این نشونه اورفیت کردنه
بهترین حالت بالا بودن تست ست هست. چیزی که مهمه تست ست هست چون قراره مدل شما با اون کار کنه . ولیدیشن ست صرفا برای تنظیم مدل هست تا نهایتا روی تست ست تعمیم خوبی ارائه کنه و همینطور مشخص باشه که اورفیت نکنید روی ترینینگ ست .
شما باید طوری مدل رو ترین کنید که بالاترین دقت رو روی تست ست بگیرید.
accuracy set? من تا بحال نشنیدم همچین عبارتی رو . اگه منظورتون ملاک ارزیابی روی دیتاست هست معمولا مشخص میکنن در هر کاری که ملاک دقت روی تست ست هست یا ولیدیشن ست (اگه بطور جداگانه باشن) مثلا در دیتاست سیفار۱۰/۱۰۰، mnist و امثالهم یک ترینینگ ست هست و یک تست ست و ملاک ارزیابی دقت بدست اومده روی تست ست هست . در ایمیج نت یا رقابت های کاگل مثلا ترینینگ ست و ولیدیشن ست هست و نهایت یک تست ست که دقت نهایی اون ملاک بدست اومده با تست ست هست . (البته ایمیج نت الان اکثرا دقتهای ولیدیشن رو گزارش میکنن چون تست ست عمومی نیست )
بله متوجه شدم. در واقع ولیدیشن اکیورسی یه جورایی داره کیفیت ترینینگ رو نشون میده و ملاک اصلیمون همون اکیورسی تست ست هستش. خیلی ممنون از راهنمایی دقیقتون
با سلام
من میخواستم برای classification یک شبکهCNN ساده بزنم برای لایه آخر بعد از Fc به جای SVM که تشخیص بدیم از چه کلاسی از چی میشه استفاده کرد
من از صفحه زیر برای قسمت کد زنی استفاده میکنم که باید خودم کامل کنم ایا چیزی وجود دارد که بهتر و راحتتر باشه
http://ufldl.stanford.edu/tutorial/supervised/ExerciseConvolutionalNeuralNetwork/
برای تشخیص اعداد دست نویس؟
سلام برای کارکردن که از تنسورفلو یا کراس یا pytorch استفاده کنید (دوتای اول راحت ترن خصوصا کراس )
آموزش اونها در سایت هست
اگر منظور پیاده سازی کل مراحل ترینینگ و… هست توسط خودتون و برای دلایل اموزشی میخوایید خودتون همه چیز رو بنویسید این اموزش خوبه علاوه بر اون آموزش یادگیری عمیق اندرو ان جی هم خوبه در coursera.
ممنون
من همین لینکی که بتون نشون دادم
http://ufldl.stanford.edu/tutorial/supervised/ExerciseConvolutionalNeuralNetwork/
یک قسمتش گیر کردم ارور مرحله اخر که از لایه softmax میاد به سمت لایه pooling
و دوباره از لایه pooling میاد به سمت کانولوشن .
اینجا نوشته باید هم مرتبه با pooling باشه
For example, suppose the pooling region was 2×2 on a 4×4 image. This means that the incoming error to the
pooling layer will be of dimension 2×2 (assuming non-overlapping and contiguous pooling regions
الان من درست متوجه شدم یعنی وقتی بخواهم قسمت backpropagation انجام بدم ارور لایه اخر که softmaxlayer هست باید هم مرتبه با pooling باشه
یعنی الان ارور مرحله اخر برابر با اندازه pooling برابر با hiddensize*numimage
یه مثالی که backpropagation روی CNN زده باشه به چشمتون نخورده من بهتر بتونم درک کنم
ممنونم از راهنمایی تون
سلام
اگه درست یادم مونده باشه شما باید اندیس اون نواحی رو که در مکس پولینگ انتخاب شدن ذخیره کنید و موقع بک پراپ صرفا همون خونه ها رو اپدیت کنید
پیشنهاد میکنم آموزش شبکه های کانولوشن اندرو ان جی رو ببینید اونجا کامل توضیح داده میشه و میتونید استفاده کنید.
میتونیدهم نگاهی به اینجا بندازید و پیاده سازی ها رو ببینید (پیاده سازی کانولوشن رو ببیند)
(پیشنهاد میکنم اموزش اندرو ان جی رو ببینید چون خیلی خوب و کامل توضیح دادن)
با سلام و خسته نباشید
در خصوص عملیات پولینگ یه سوالی داشتم. فرض کنیم تصویر ورودی ما تو مقادیر پیکسلش نویزداره و مثلا این نویز مقدار عددی پیکسلش زیاده حالا اگه ما از ماکس پولینگ استفاده کنیم در واقع به اشتباه داریم نویز رو بعنوان فیچر برمیداریم یا بالعکسش نویز یه مقدار عددی کوچیک داره و ما داریم از مین پولینگ استفاده میکنیم. وقتی ما از کل عکسای دیتا ستمون مطلع نیستیم چطور میشه این حالت برداشتن نویز رو بعنوان فیچر در پولینگ کنترل کرد. یعنی آیا بالاخره توی لیرهای بعدی در حال بهبود میشه؟؟
سلام
عملیات پولینگ اگر روی تصویر مستقیما لحاظ بشه بله فرمایش شما صحیحه اما در حالت عادی ما پولینگ رو بعد از اعمال چندین لایه استفاده میکنیم و شاید بهتر باشه در ادامه به ورودی ها به عنوان تصویر صرف نگاه نکنید
با توجه به ماهیت distributed representation که در شبکه های عصبی داریم میتونیم به ورودی های پولینگ به عنوان ویژگی نگاه کنیم یعنی در مرحله قبل یکسری فیچردیتکتور یکسری پردازش هایی داشتن و یک سری خروجی ارائه دادند حاصلش رو ما داریم میبینیم.
حالا یک ویژگی یا مناسبه یا نیست. اگر مناسب نباشه در زمان بک پراپ به همون میزانی که در ورودی تاثیر گذاشته تاثیر میپذیره و مقدار وزن متناظر با اون تصحیح میشه و طی چند گام دیگه تاثیرش رو از دست میده .
اگه دقت کنید میبینید با استفاده از لایه دراپ اوت اتفاقا ما بصورت تعمدی نویز ایجاد میکنیم و با اینکار هر بار یک یا چند ویژگی مخفی میشن یا در نظر گرفته نمیشن انگار که وجود ندارن بنابر این شبکه از طریق باقی ویژگی ها مجبور میشه کارش رو پیش ببره
بله فرمایشتون درسته و ممنونم متوجه شدم
سلام ممنون از مطالب مفید و خوبی که در سایت قرار داده اید.
من یک سری داده هایی مروبط به تصاویر سه بعدی دارم که شامل XYZ RGB یعنی مکان و رنگ هر نقطه است. اگر بخوام در نرم افزار پایتون این تصاویر رو
با استفاده از شبکه عصبی کانولوشن طبقهبندی کنم چه مراحلی رو باید انجام بدم و چه لایبرری باید استفاده کنم. ممنون میشوم راهنمایی بفرمایید.
با تشکر فراوان
سلام
میخوایید دیتکشن انجام بدید ؟ یا اینکه اون سه عدد داده تکمیلی هستن ؟ (مختصات مکانی نیستن؟)
با سلام و تشکر
در معماری الکس نت ظاهرا ۲۲۴*۲۲۴سایز ورودی هستش ولی در محاسباتش درست درنمیاد. من کد دیجیتس رو نگا کردم داخلش خودش ورودی رو ۲۲۷گرفته. تو آموزش استنفورد نوشته سه تا پیکسل زیرو پدینگ داده تا ۲۲۷بشه. من هر کاری میکنم با سه تا زیرو پد نمیتونم ۲۲۷ رو دربیارم. میشه در این مورد یه توضیحی بفرمایید؟ چطور ۲۲۴ رو۲۲۷کرده؟
با سلام و تشکر
x ,y , z مختصات مکانی نقاط هستند. و قصد من در نهایت تشخیص یک شی از میان سایر اشیاء است.
سلام. تشکر از اطلاعات مفید شما. اگر بخواهیم در متن پایان نامه به این نوشته ها ارجاع دهیم ، چه منبعی را ذکر کنیم؟
سلام
میتونید به پایان نامه بنده “دسته بندی اشیاء با استفاده از شبکه عصبی کانولوشن عمیق” سید حسین حسن پور متی کلایی ارجاع بدید.
سلام بسیار ممنون از توضیحات خوبی که گذاشتید خدا خیرتون بده کلی از مشکلات من رو حل کردید من که خیلی دعاتون میکنم.ببخشید من تازه شروع به آموزش یادگیری عمیق کردم میخواستم بدونم تعداد نورون ها در هر لایه چگونه انتخاب میشه؟
تعداد لایه convوpooling بر چه اساسی تعیین میشه؟
اندازه fold ها برای دیتاست (test,train)برچه اساسی تنظیم میشه؟
همچنین نوع تابع هزینه برچه اساسی انتخاب میشه؟
خیلی ممنون از لطف شما
سلام
خیلی از این موارد رو در کارگاهی که برگزار کردیم من توضیح دادم .
اما علاوه بر اون پیشنهاد میکنم
۱٫حتما سری به سایت پرسش و پاسخ بزنید چون سوالات مشابه شما قبلا پرسیده شده و جواب گرفتن
۲٫آموزش یادگیری عمیق دانشگاه استنفورد و یا اقای اندرو ان جی رو هم میتونید تماشا کنید و خیلی از این دست مشکلاتتون برطرف بشه
۳٫تعداد نورونها در هر لایه یک فرا پارامتر هست که معمولا بصورت هرمی افزایش پیدا میکنه . یعنی از کم شروع میشه با افزایش لایه ها این تعداد هم افزایش پیدا میکنه (مثلا ۵ لایه باشه شبکه شما
لایه اول اگه از ۳۲ شروع کرده باشید لایه بعدی میتونه ۴۸ بعدی ۶۴ بعدی ۱۲۸ بعدی ۲۵۶ و اخر هم یه دسته بند داشته باشید . حالا چرا مبنای ۲؟ میشه غیر اون هم استفاده کرد . بله میشه . ولی مبنای ۲ باشه باعث میشه بشه از بهینه سازی های سخت افزاری استفاده کرد و سرعت ترینینگ و… افزایش پیدا کنه.
چندتا پولینگ باید باشه ؟ به اندازه کافی. چطور بفهمیم ؟ اول اینکه پولینگ زیاد نباید استفاده بشه. کم استفاده کنید. دوما سعی کنید پولینگ رو در لایه های اول شبکه نزنید . سوم با قرار دادن پولینگ در بین لایه های مختلف دقت شبکه رو چک کنید هر کدوم بهتر کرد از همون استفاده کنید.
چندتا کانولوشن باید باشه؟ بسته به مساله داره اما یک شبکه که لایه های کانولوشن بیشتری داره میتونه بشما دقت بهتری ارائه بده نسبت به اونی که لایه کمتری داره .
در دیپ لرنینگ چون اندازه دیتاست ها معمولا بزرگه (چند صد هزار تا میلیونها )معمولا بالای ۹۷ ۹۸ یا حتی ۹۹ درصد به ترینینگ اختصاص پیدا میکنه و مابقی برای تست . اگه دیتای شما چند ده هزارتاست شما با همون نسبت های سابق کار کنید بهتره (یعنی ۸۰ ۲۰ یا حتی ۷۰ ۳۰ البته اینها خیلی وابسته به دیتا ست هست ولی فک کنم ایده رو گرفته باشید )
تابع هزینه بر اساس ماهیت کار شما انتخاب میشه.
یک دنیا ممنون توضیحاتتون عالی بود.تشکر
[…] آموزش شبکه کانولوشن یادگیری عمیق Deep learning […]
سلام وقتتون بخیر .قربان فرمودید سوالمون رو تو گروه مطرح کنیم.میشه ادرس گروه رو بفرمایید. تشکر
سلام . در بخش منابع یادگیری لینک گروه و کانال قرار داده شده.
با سلام و تشکر از سایت بسیار خوبتان
ورودی شبکه کانولوشن فقط میتونه تصویر باشه؟
از داده هایی در قالب یک جدول اکسل نمی توان برای آموزش از CNN استفاده کرد؟
با تشکر
سلام
منحصر به تصویر نیست و میشه از انواع دیگه هم استفاده کرد مثل سیگنال (صدا) و یا متن و…
سلام ،
ممنون از مطالب مفیدتون
می خواستم بدونم منابعی در مورد “Face recognition based on Convolution Deep Neural Network” و همینطور ورژن انگلیسی شبکه های کانولوشن که زحمت کشیدید به فارسی قرار دادید دارید ؟
پیشاپیش از توجهتون ممنونم
سلام
برای مقالات میتونید از بخش منابع یادگیری استفاده کنید. لینکها و سایتهای مختلفی معرفی شدن
آموزش شبکه های کانولوشن هم برگرفته از کورس نوتهای دانشگاه استنفورده که اون هم لینکش در بخش منابع یادگیری اومده
با سلام
من یک سوالی کلی دارم در مورد شبکه های کانولوشن. در همه معماریها به فولی کانکتد که میرسه مثلا در معماری الکس نت ورودی فولی کانکتد رو ۱۰۲۴ زده یا در زد اف تعدادشو ۴۰۹۶ نوشته. آیا فرمولی هست که بتئنیم وقتی برای معماری خودمون میرسیم به این نقطه تعداد ورودیهای فولی کانکتد رو حساب کنیم؟ روشش چطوره. مثلا میبینم تئ بعضی معماریها که افراد خودشون کار کردن دو تا فولی کانکتد داره که اصلا رقمهای بزرگی نیس مثلا بیست و سی گذاشته.
ممنون میشم راهنمایی بفرمایید
سلام.
اون اعداد با سعی و خطا انتخاب شدن و وحی منزل نیستن. البته نیازی هم به فولی کانکتد ندارید اصلا. خوندن این مقاله پیشنهاد میشه.
در این مورد سوالهای مختلفی هم در کامنتهای اینجا مطرح شده هم در پرسش و پاسخ که جواب دادم .اونها رو چک کنید خوبه.
همینطور میتونید ارائه من در مورد شبکه ها مختلف کانولوشنی رو ببینید که این معماری ها توضیح داده شدند. (باید تو آپارات پیدا کنید)
متشکرم. امکانش هست بفرمایید با چ عنوانی سرچ کنم ارایتون رو؟ من آپاراتو سرچ کردم موفق به پیدا کردنش نشدم. خیلی خوب میشه هر گونه ارایه ای در این مورد دارید رو ببینم. یوتیوب یا هر جای دیگه. من واقعا خیلی از مطالبو از شما یاد گرفتم. واقعا متشکرم
سلام.
این کانال حمیم هست ویدئوها رو اینجا زحمت کشیدند و اپلود کردن همینجا باید باشه .
البته کلاس خیلی طولانی تر بود و بخش بحثهای تکمیلی و سوال جوابها حذف شده از این ویدئوها :
کانال https://www.aparat.com/partdpai
سلام خیلی ممنون از سایت مفیدتون.
من در رابطه با شبکه عصبی CNN داخل سایتی باید کدی را اجرا کنم ولی ارور داد و نمی دونم به چه صورته.اگه میشه زودتر جوابم رو بدید چون برای ارائم باید آمادش کنم.خیلی ممنون
این آدرس لینک کده…
https://github.com/llSourcell/math_of_machine_learning
سلام. فایل ipynb رو میخوایید اجرا کنید؟ اگر بله باید از طریق jupyter notebook اجراش کنید. آناکوندا رو نصب کنید. این هم همراهش نصب میشه . بعد هم میتونید در ترمینال یا cmd بنویسید jupyter notebook و اجراش کنید و هم از منو استارت اگر در ویندوز هستید اجراش کنید.
سلام
میشه لوضیح لطف بفرمایید یه توضیحی در مورد Wavelet + CNN بدهید؟
این شبکه ها چه تفاوتی با CNN ها دارند؟
سلام.
من متاسفانه مطالعه ای در مورداین شبکه نداشتم. اما بنظر میاد این مقاله بدرتون بخوره
با عرض سلام خدمت شما.و تشکر بابت مطالب مفیدتون.
نحوه ی انتخاب تعداد لایه های مختلف
مثلاسایز فیلترها و تعداد فیلترها و انتخاب فراپارامترها و تعداد نورونهای در لایهfully connectedو نوع تابع فعالسازی relu نوع پولینگی که استفاده میشود به چه صورت است ؟؟اگر مقاله ایی دارید لطفا بذارید
خیلی سپاسگذارم از زحماتتون تشکر
سلام .وقتتون به خیر .از مطالب بسیار مفیدتون که زحمت کشید و برای ما توصیح دادید بسیار ممنونم .یه سوال داشتم اینکه :من دانشجوی سال دوم ارشد هوش مصنوعی هستم و اcnn در پایان نامه باید استفاده و پیاده سازی کنم .تا الان توسط مطالب شما و توضیحات چند سایت دیگر تا حد زیادی متوجه شدمکه تا حدی cnn چیه اما فکر می کنم هنوز باید طلاعاتم بیشتری در این زمینه (هم تئوری و مخصوصا پیاده سازی)جمع اوری کنم .به زبان مطلب اشنایی و تا حدی بهش تسلط دارم اما با توجه به کارکرد پایتون در این زمینه شروع به یادگیری زبان پایتون کردم اما نمیدونم الان( با توجه به وقت محدودم (حدود یک ای دو هفته)و منابع بسیار)باید دقیقا چکار کنم و از کجا شروع کنم ؟ مثلا ویدیو های یادگیری عمیق اندرو ان جی را ایا لازمه تمام ویدیو ها را مشاهده کنم یا تنها مشاهده فیلم های شبکه کانولوشن کافیه؟من یادگیری ماشینرا در ترم اول یاد گرفتم اما با متلب، ایا نیازی هست که فیلم های یادگیری ماشین اندرو ام جی را کامل گوش کنم (زیرا نگرانم به موقع به پیاده سازی مقاله اصلی پایلن نامه ام نرسم )؟
خیلی ممنون از وقت و حوصله که می گذارید و بسیار خوب و با حوصله جواب می دهید .
اجرتون با خدا .ان شالله همیشه موفق و سربلند باشید
سلام
مطالب در مورد شبکه های عصبی کانولوشن بسیار زیاد هست. مواردی که من اینجا توضیح دادم ابتدایی و مبانیی هستند اما برای شروع کار ضروری.
کار درستی میکنید که با پایتون شروع میکنید متلب بشدت در این حوزه ضعیف هست و تقریبا هرکسی که تو این زمینه با متلب شروع بکار کرد با مشکلات اساسی مواجه شد.
آموزش اندرو ان جی (آموزش کامل یادگیری عمیق – ۵ بخشی) یک آموزش ابتدایی به بالا هست که موارد مختلف و نسبتا خوبی رو پوشش میده. اگر ببینید خوبه براتون و ضرر نمیکنید .
میتونید تمریناتش رو انجام ندید و صرفا از مفاهیمی که بیان میشه استفاده کنید تا ببینید چه چیزهایی وجود داره و به چه صورتی کار میکنن و بعدا هر کدوم رو که نیاز به تعمیق مطالب داشتید بصورت جزیی دنبال کنید.
آموزش یادگیری عمیق یک بخشه (منظور مفاهیم) و آموزش کار با فریم ورکها یک چیز دیگه.
شما میتونید یک آموزش یادگیری عمیق با تنسورفلو/کراس یا پای تورچ رو دانلود کنید (معمولا Udacity یا سایتهایی مثل Udemy آموزش های خوبی دارن. که با نگاه به لیست سرفصل ها و امتیازات و میزان دانلودشون میتونید به میزان خوب بودنشون پی ببرید و بعد در سایتهای فارسی دانلودشون کنید)
خوبی این آموزش ها اینه که ابتدا یک مقدمه ای معمولا از زبان پایتون گفته میشه و بعد مفاهیم مختلف یادگیری عمیق در یک فریم ورک خاص مثل تنسورفلو /کراس یا پای تورچ یا …. آموزش داده میشه.
بنظر من اول سعی کنید یک آموزش ساده مثل اندرو ان جی رو ببینید یکسری مفاهیم ابتدایی رو آشنا بشید
بعد یک آموزش یادگیری عمیق با تنسورفلو (یا کراس) یا پای تورچ دانلود کنید و شیوه کار رو در اون فریم ورکها ببینید .
ضمنا لازم نیست الزاما تمامی بخشهای یک اموزش رو ببینید اما پیشنهاد میشه ببینید چون ممکنه ایده خوبی بهتون بده برای انجام کاری که مد نظرتون هست. اما اگه شیوه کار شما مشخصه و فقط باید یادبگیرید چطور باید این کار خاص رو انجام بدید خب نیازی به بخشهای دیگه نیست.
یه سوال دیگه هم داشتم اینکه سیستم من قدیمی هست ایا می توان از این سیستم برای cnnاستفاده کرد؟
مشخصات سیستم:
NVIDIA GeForce 8400M GS
Processor:Intel(R) Core(TM)2 Duo CPU T5800@2.GHz 2.000GHz
Ram:2 GB
System 64 bit operating process
مرجع یادگیری عمیقی هم که میگم اینه:
https://howsam.org/1397/08/14/دوره-یادگیری-عمیق-andrew-ng/
خیلی ممنون مبشم زودتر جواب بدید
در مورد سیستم کار با یادگیری عمیق من پست های مختلفی قرار دادم . شما مطلب مربوط به کارت های گرافیک برای یادگیری عمیق رو مطالعه کنید
اطلاعات کامل اونجا داده شده .
بله اون پنج بخش آموزش اندرو ان جی خوبه برای شروع. اما یادتون باشه اینها خیلی ابتدایی هستند (ولی ضروری)
و نیاز شما به خوندن مقالات و…رو برطرف نمیکنه. این رو ببینید بعد برای بخشهای بعدی برگردید سوال کنید تا مستاصل نشید خدای نکرده.
سلام
یه سؤال داشتم
function approximation چیه؟
سلام اینجا رو مطالعه کنید . البته هر کتاب در حوزه شبکه عصبی مصنوعی رو بخونید اینو توضیح میده
سلام. می شه لطفا در مورد کاربرد های wavelet cnn توضوح دهید؟
لطفا ایراد این چند خط را هم بهم بگید خط زیر اجرا می شود ولی
“data_set_path = “C\\Users\\baran\\Desktop\\wanenet\\sara\\cat-and-dog
دستوررات زیر را که اجرا می کنم خطا می دهد
import os
os.listdir(data_set_path)
خطا:
FileNotFoundError Traceback (most recent call last)
in ()
۱ import os
—-> 2 os.listdir(data_set_path)
FileNotFoundError: [Errno 2] No such file or directory: ‘C\\Users\\baran\\Desktop\\wanenet\\sara\\cat-and-dog\\test_set’
مورد دوم:
train_img_dir = ‘C\\Users\\baran\\Desktop\\wanenet\\sara\\cat-and-dog\\training_set’
train_generator = train_data_gen.flow_from_directory(train_img_dir,
target_size=(224, 224),
batch_size=32,
class_mode=’categorical’)
خطا:
/usr/local/lib/python3.6/dist-packages/keras_preprocessing/image/directory_iterator.py in __init__(self, directory, image_data_generator, target_size, color_mode, classes, class_mode, batch_size, shuffle, seed, data_format, save_to_dir, save_prefix, save_format, follow_links, subset, interpolation, dtype)
۱۰۴ if not classes:
۱۰۵ classes = []
–> 106 for subdir in sorted(os.listdir(directory)):
۱۰۷ if os.path.isdir(os.path.join(directory, subdir)):
۱۰۸ classes.append(subdir)
FileNotFoundError: [Errno 2] No such file or directory: ‘C\\Users\\baran\\Desktop\\wanenet\\sara\\cat-and-dog\\training_set’
با تشکر
سلام
مسیر دیتاستتون رو تصحیح کنید مسیرتون اشتباهه و به همین خاطر دارید خطا میگیرید
سلام . وقت بخیر
“شبکه های عصبی کانولوشن تا حد بسیار زیادی شبیه شبکه های عصبی مصنوعی هستند که در بخش قبلی در مورد آنها توضیح داده شد.” این قسمت از متن بالا که نوشتید “بخش قبلی” ، میشه لینکشو به ایمیل rajabihr7@gmail.com بفرستید؟
سلام .
این بخش مربوط به پایان نامه من بود که اینجا اضافه نکردم چون منابعش همون موقع هم زیاد بود و الان هم هست. چون اون زمان شبکه عصبی کانولوشن منبعی نداشت من فقط همون رو اینجا منتشر کردم .
سلام من معنی cross validation و نیاز به داده های اعتبار سنجی رو نمی فهمم وقتی میتونیم فقط از داده های تست و ترین استفاده کنیم چه نیازی به داده های اعتبار سنجی هست ممنون میشم در این مورد هم راهنماییم کنید
سلام.
وقتی داده شما به اندازه کافی نباشه corss-validation یکی از راه هایی هست که استفاده میشه.
سلام و عرض خسته نباشید به شما به خاطر سایت پربارتون که تو زمینه DL که منابع فارسی فقیرند فوق العادست.
من دانشجوی سنجش از دور دانشگاه تهران هستم و پایان نامم شناسایی تخریب ساختمان ها در اثر زلزله با تصاویر ماهواره ای و الگوریتم های dl است. از اونجایی که کلا مباحث هوش مصنوعی مثل ML یا DL را در رشته مان زیاد استفاده میکنیم اما به دلیل عدم گذراندن درسهای مربوطه، هوش مصنوعی را به طور درست و اصولی بلد نیستیم و ما فقط معمولا از ماژول های آماده استفاده میکنیم حالا برای این پایان نامه من نیاز به یک شبکه DL دارم که مهم نیست چی باشه (CNN یا UNet ترجیحا) به نظرتون من با این سطح از چه شبکه ای استفاده کنم و کدوم سری از مطالب شمارو مطالعه کنم که کارم راه بیوفته . هدف فقط جواب دادن شبکه در کاربرد مدنظرم است و کاری به اصولش ندارم یعنی اگر یک شبکه آماده پیدا کنم و بتونم فقط با تغییر پارامتر ها شبکه رو بهینه کنم تا بهترین نتیجه رو بگیرم.
اگر امکانش هست بتونم با ایمیل باشما در ارتباط باشم یک دنیا ممنون میشوم.
سلام وقتتون بخیر یه سوال در مورد کد نویسی داشتم ,من میخام تو برنامم zero padding انجام بدم و نمیدونم چه دستوری براش بنویسم و برنامه من تو محیط اسپایدر از پایتون هستش,ممنون میشم اگه کمکم کنید
سلام اگه از فریم ورک خاصی استفاده میکنید مثل تنسورفلو کراس یا پای تورچ زیرو پدینگ رو دارن کافیه تو مستنداتشون چک کنید
اگر هم نیست زیرو پدینگ یعنی حاشیه گذاری با صفر . میتونید pad numpy چک کنید : https://docs.scipy.org/doc/numpy/reference/generated/numpy.pad.html
یا این لینک رو ببینید : https://stackoverflow.com/questions/35751306/python-how-to-pad-numpy-array-with-zeros
تو سایت پرسش و پاسخ هم فکر کنم قبلا جواب اینو داده باشم اونم بررسی کنید خوبه
سلام… امکان داره درباره ConvLstm هم توضیحاتی بدین؟ متشکر
سلام وقت بخیر خیلی خیلی ممنون از مطالبتون من رشته نرم افزار هستم و برای پایان نامه باید روی این حوزه کار کنم اما متاسفانه درس زیاد مرتبطی به جز پردازش تصویر پاس نکردم میشه راهنماییم کنید از کجا شروع کنم چند مقاله را استارت زدم اما خیلی موارد بود که من اطلاع نداشتم (مثلا spike یا robustness در شبکه ) واسه همین نتونستم ادامه بدم. پیشاپیش ممنونم
سلام. این حوزه خیلی گسترده اس اول باید زمینه مورد علاقتون رو مشخص کنید بعد نوبت به بحثای دیگه برسه
سلام
وقتتون بخیر
آیا الگوریتم GBC در یادگیری عمیق استفاده می شود؟
سلام . منظور شما Genetic Bee Colony هست؟ من شخصا پیگیر این موضوع نبودم اما بنظر میاد یک کارهایی داره صورت میگیره . متاسفانه چون اشراف ندارم نمیتونم راهنماییتون کنم
سلام…امکانش هست منابعی رو که استفاده کردی معرفی کنید؟
برای این گفتم چون میخام توی پایان نامم رفرنس بدم
سلام.
منبع اصلی پایان نامه منه! اما اگه منظور شما اینه که این مطالب خودشون منبعشون کجاست کورس نوت های دانشگاه استنفورد که تو بخش منابع یادگیری عنوان شده
سلام وقتتون بخیر واقعا ممنون از شما خدا خیرتان بده واقعا من پروژه طبقه بندی تصاویر سرطان سینه با متلب هست و نزدیک ۷۰۰۰ نمونه عکس دارم میخوام به ۲ کلاس تقسیم کنم و از متلب استفاده کنم کجا میتونم نمونه های پیاده سازی شده ببینم که کد زدنش بتونم انجام بدم
تو caffe با پایتون بود ولی متلب نه
سلام. من با متلب کار نمیکنم و متاسفانه کمکی نمیتونم بکنم . باید مستندات خود متلب رو ببینید. (هرچند پیشنهاد میکنم متلب رو بزارید کنار و از پایتون و یکی از فریم ورکهاش مثل پایتورچ یا تنسورفلو/کراس استفاده کنید
با سلام خدمت دکتر حسن پور
می خواستم از حضرتعالی بپرسم که اگر یک فیلتر کانولوشن ۳*۳ را بر روی یک ماتریس سه بعدی۳*۹۰*۹۰ اعمال کنیم نتیجه نهایی بعد از انجام عمل کانولوشن، یک ماتریس دو بعدی می شود یا یک ماتریس سه بعدی؟ ممنون
سلام
بخش دوم آموزش رو ببینید این بخش کاملا توضیح داده شده.
خیلی خلاصه به ازای هر فیلتر شما یک فیچرمپ در خروجی دارید
با سلام خدمت دکتر حسن پور
می خواستم از حضرتعالی بپرسم که اگر یک فیلتر کانولوشن ۳*۳ را بر روی یک ماتریس سه بعدی۳*۹۰*۹۰ اعمال کنیم نتیجه نهایی بعد از انجام عمل کانولوشن، یک ماتریس دو بعدی می شود یا یک ماتریس سه بعدی؟ ممنون
با سلام و خسته نباشید، ببخشید یک سوال داشتم. بنده قصد دارم شبکه عصبی CNN را برای تشخیص یک جسم آموزش بدم. فرض کنیم تصاویر برای آموزش ۵۱۲*۵۱۲ است. این جسم مد نظر بنده باید حداقل چند پیکسل را در تصاویر اشغال کرده باشد تا الگوریتم بتواند هم آموزش ببیند و هم بتواند در فاز آزمایش تشخیص دهد؟
سلام .
بستگی به ماهیت کار شما داره و شیوه پیاده سازی و همینطور اندازه دیتاست شما.
ملاک قابل تشخیص بودن چیزی از نظر دید انسان نیست. بصورت کلی شبکه های سی ان ان با فرض انتخاب معماری مناسب و وجود دیتای کافی قابلیت یادگیری و جنرالیزیشن بسیار خوبی دارن
بقیه موارد خیلی مرتبط میشه با ماهیت کار.
سلام آقای حسن پور
متشکرم از وقتی که برای پاسخگویی به سوالات میگذارید. خدا خیرتون بده.
میخواستم اگه میشه یک کتاب معرفی کنید که بطور پایه ای انواع شبکه عصبی و یادگیری عمیق رو آموزش بده. من برای انتخاب موضوع تز به خواسته ی استاد راهنمام باید موضوعی در این راستا انتخاب کنم ولی متاسفانه پایه و آشنایی چندانی با این زمینه ندارم. میخواستم کتابی باشه که مثال های حل شده داشته باشه تا بصورت کاربردی و عملی نحوه ی کار کردن با شبکه های عصبی رو آموزش بده و فقط به اطلاعات پایه ای و تئوری بسنده نکرده باشه.
متشکرم
سلام کتاب(dive into deep learning ) https://d2l.ai/ رو بخونید خوبه. همون چیزیه که در نظر دارید. (هم میتونید برای فریم ورک پیشفرضش استفاده کنید و هم پایتورچ و تنسورفلو)
سلام وقت بخیر ، من میتوانم پایان نامه شما رو داشته باشم؟
سلام من الان دسترسی به پایان نامه ندارم اما محتویات پایان نامه در سایت قرار گرفته در قالب پست های مختلف.
در مورد بحث شبکه و… این مقاله همون نتیجه پایان نامه منه https://arxiv.org/abs/1608.06037
سلام مهندس جان. خسته نباشید. ممنون از مطالب خوبتون. ببخشید موضوعی را بنده متوجه نشدم و آن اینکه اگر توده ورودی ما، به ترتیب، طول، عرض و عمقی برابر ۱۰۰۰*۱۰۰۰*۷ داشته باشد و بخواهیم یک کانولوشن ۳d روی آن اعمال کنیم با فرض اینکه ابعاد کرنل ما ۵ باشد یعنی اینکار را باید با فیلتری به ابعاد ۵*۵*۷ انجام دهیم که فقط در راستای طول و عرض ورودی بلغزد یا با فیلتری به ابعاد ۵*۵*۳ که روی توده ورودی در راستای طول و عرض و عمق بلغزد؟ و یا با یک فیلتر ۵*۵ که روی هر یک از ۷ برش یا هفت بعد از ورودی، این فیلتر را بلغزانیم و سپس نتایج همه ابعاد را با هم جمع کنیم و یک فیچر مپ دو بعدی به دست آوریم؟ به عبارت دیگر تعداد وزنهایی که باید در نظر گرفته شوند چندتا خواهد بود؟ ۱۷۵ یا ۷۵ یا ۲۵؟
سلام
سلامت باشید. بخش دوم آموزش رو بخونید این مساله کاملا توضیح داده شده.(خصوصا بخش انتهایی که با تصویر یک مثال ساده عنوان شده)
بعد از مطالعه اون اگر باز براتون جای سوال بود بفرمایید .
ممنون مهندس جان. بنده یک سری زمانی تصاویر با تعداد باند ۳۶ دارم. یعنی عمق ورودی من ۳۶ است. حال برای تولید فیچرمپ و انجام عمل کانولوشن سه بعدی، میخواستم از حضرتعالی بپرسم عمق فیلتر من باید ۳ باشد یا ۳۶٫ ممنون
سلام.
فیلتر کانولوشن شما میتونه هر عددی بین ۲ الی ۳۶ باشه. (۱ یعنی ارتباط زمانی رو ندید بگیر)
دقت کنید که کرنل شما هم در راستای طول و عرض و هم عمق حرکت میکنه و این عمق هم مثل اندازه ای که برای طول و عرض در نظر میگیرید یک پارامتر قابل تنظیم از طرف شماست).
نکته دیگه اینه که لایه کانولوشن سه بعدی از شما تعداد فیچرمپ(کانال) ورودی یا in_channels و تعداد فیچرمپ خروجی یا out_channels رو میخواد. in_channels همون تعداد کانالهای ورودی شماست و depth تعداد فریم ها در دنباله شماست. (اینجا depth ورودی شما ۳۶ هست- اینکه هر باند/فریم شما چند کاناله هست (۱ کاناله گری اسکیل یا ۳ کاناله ار جی بی و….) مشخص کننده in_channels شما میشه.
ممنون دکتر جان که وقت میگذارین. بسی جای تشکر داره. ببینید دکتر عزیز،
در معماری Krizhevsky که برنده رقابت ImageNet در سال ۲۰۱۲ شد، برای محاسبه خروجی لایه اول کانولوشن، در حقیقت تعداد ۹۶ کرنل با ابعاد ۱۱x11x3،روی تصاویر ورودی با ابعاد ۲۲۷x227x3 ، اعمال میشد و در نتیجه تعداد ۹۶ فیچرمپ با ابعاد ۵۵×۵۵ (با توجه به اندازه Stride) بعنوان خروجی تولید می شد. حال فرض کنید تصاویر ورودی بصورت فریم های گری اسکیل ماهواره ای از یک منطقه در ۳۶ زمان مختلف می بودند. در این حالت برای تولید فیچر مپ هایی که تغییرات زمانی منطقه را بهتر بازنمایی کند آیا (۱) باید مانند Krizhevsky عمق کرنل را برابر عمق ورودی یعنی ۳۶ بگیریم و مثلا ۹۶ کرنل مختلف را اعمال کنیم تا فیچرمپی با عمق ۹۶ داشته باشیم یا (۲) می توانیم عمق کرنل را هر عددی بین ۱ تا ۳۶ در نظر بگیریم و با توجه به اندازه Stride، آنرا در سه بعد روی ورودی بلغزانیم؟ (فرض کنید عمق فیچرمپ خروجی، از قبل تعیین شده نیست). اگر عمق کرنل، کمتر از عمق ورودی باشد(حالت ۲) مسلما تعداد پارامترهای آموزشی بسیار کمتر خواهد بود. البته متوجه شدم که حضرتعالی فرمودید عمق کرنل یک پارامتر قابل تنظیمه. خواستم از تجربه و دانش شما بیشتر استفاده کنم که کدوم حالت بهتر تغییرات را بازنمایی می کند. خیلی ممنون.
سلام.
همونطور که عرض کردم اون یک پارامتر هست و بسته به ماهیت کار/مدل مقادیر مختلفی میتونه بگیره. شما بیس لاین گیری باید بکنید.
یعنی یک مجموعه پارامتر رو ثابت در نظر میگیرید و بعد با تغییر پارامتر عمق خروجی رو ثبت و ارزیابی میکنید بعد این فرایند رو با تغییرات در سایر پارامترها ادامه میدید تا نهایتا به مجموعه پارامتر بهینه برسید.
ارتباط زمانی فقط قرار نیست در لایه اول بدست بیادو یکسری ارتباطات در ادامه شبکه توسعه پیدا میکنند (در این بخش ضروریه که شبکه شما حداقل تا چندین لایه کانو۳بعدی باشه نه اینکه صرفا شما بر روی ورودی یه کانولوشن سه بعدی بزنید و بعد در ادامه
کانولوشن دو بعدی. این شاید در برخی کارها جواب بده اما الزاما تنها گزینه و بهترین گزینه شما نیست. )
دقت کنید در مساله الکس نت شما با کانولوشن ۲بعدی مواجه هستید و بحث وابستگی زمانی بین ورودی مطرح نیست. این دو رو با هم قاطی نکنید. داده ورودی شما اگر دارای ارتباطات و وابستگی های زمانی مشخص باشه در ترین با لحاظ کردن عمق نتایج بهتری باید بگیرید نسبت به حالت عملگر دو بعدی کانولوشن که تنها تغییرات مکانی رو لحاظ میکنه. من خاطرم هست که سال ۲۰۱۵ یا ۲۰۱۷ اندره کارپاسی یک پیپری کار کرده بود در همین خصوص (تاثیرات early fusion/late fusion و… در بحث ویدئو کلسیفیکیشن) اون رو مطالعه کنید خوبه تا شهود بهتری بدست بیارید.
(ضمنا لطفا به من دکتر نگید من دکتر نیستم)
با سلام و احترام
تشکر از مطالب علمی و آموزنده خیلی خوب شما
سوال بنده در مورد بدست آوردن یک روش وزندهی جدید، برای مثال اگر داده های نامتوازن چند کلاسه داشته باشیم و بخواهیم برای طبقه بندی این دادها ازوزندهی سمپل ها استفاده کنیم بدنبال یک روش وزندهی خوب و جدید هستم لطفا ممکن راهنمایی بفرمایید.
ممنون وسپاسگزارم