

بسم الله الرحمن الرحیم
درون سازی یا تعبیه کلمه یا اصطلاحا word embedding نامی تجمعی است که به مجموعه ای از تکنیک های یادگیری ویژگی و مدلسازی زبان در پردازش زبان طبیعی اطلاق میشود. در این تکنیک ها، کلمات و عبارات از یک لغت نامه به بردارهای عددی نگاشت میشوند. بطور مفهومی این تکنیک، مستلزم تعبیه سازی ریاضی (mathematical embedding) از فضایی با ابعاد زیاد به ازای هر کلمه به فضای برداری پیوسته با ابعاد بسیار کمتر است. روشهایی که جهت تولید این نگاشت مورد استفاده قرار میگیرند شامل شبکه های عصبی، کاهش ابعاد بر روی ماتریس هم رخداد کلمه،مدل های احتمالاتی، روش پایه دانش قابل توضیح، و باز نمایی صریح تحت عنوان محتوایی که کلمات در آن ظاهر میشوند، میشود. زمانی که تعبیه کلمه و عبارت، بعنوان بازنمایی ورودی زیرین مورد استفاده قرار گیرد، نشان داده است که سبب افزایش کارایی در کاربردهای مبتنی بر پردازش زبان طبیعی همانند syntactic parsing و sentiment analysis میگردد.
word embedding یک بازنمایی متراکم از کلمات در قالب بردارهای عددی است که میتوان آن را توسط مدلهای زبانی مختلفی، فراگرفت. بازنمایی word embedding قادر است روابط مخفی بسیاری را بین کلمات مختلف آشکار کند. بعنوان مثال، در بازنمایی مبتنی بر word embedding ، نسبت بردار (گربه) به (پیشی) همانند نسبت بردار (سگ) به (هاپو) است! در این نوشتار ما مدلهای مختلفی برای یادگیری word embedding معرفی و سعی میکنیم نشان دهیم چگونه توابع خطای این مدلها برای این هدف خاص طراحی شده اند.
لغت نامه های انسانی بصورت متن ساده هستند اما برای اینکه یک مدل یادگیری ماشینی قادر به فهم و پردازش زبان طبیعی باشد، ما نیازمند تبدیل کلمات از متن ساده به مقادیر عددی هستیم. یکی از ساده ترین روش های تبدیل سازی، انجام فرایند کد گذاری one-hot encoding است که در آن هر کلمه دارای یک جایگاه خاص در یک بردار حاصل است و مقادیر دودویی صفر و یک نشانگر عدم وجود یا وجود یک کلمه در یک بردار میباشند.(برای اطلاعات بیشتر اینجا را ببینید)
اما، کدگذاری one-hot در زمانی که با تمام یک لغت نامه مواجه باشیم از نظر محاسباتی سربار بسیار زیادی بر ما تحمیل خواهد کرد و در نتیجه فرایندی غیرعملی خواهد بود چرا که بازنمایی حاصل در اینجا نیازمند صدها هزار بُعد خواهد بود. word embedding کلمات و عبارات را در قالب بردارهایی عددی (غیر دودویی برخلاف انچه در one-hot encoding مشاهده میکنیم) با ابعادی به مراتب کوچکتر و متراکمتر ارائه میکند. یک فرض شهودی در رابطه با تعبیه سازی کلمه مناسب (word embedding مناسب) این است که آنها باید قادر به تقریب شباهت بین دو کلمه (یعنی کلمات “گربه” و “پیشی” کلماتی شبیه به هم و در نتیجه انتظار آن میرود که در فضای برداری نیز بازنمایی های این دو کلمه نزدیک به یکدیگر باشند.) یا آشکار سازی روابط معنایی مخفی بین آنها باشد(یعنی، رابطه بین “گربه” و “پیشی” مشابه رابطه بین “سگ” و “هاپو” است). اطلاعات محتوایی (Contextual information) برای یادگیری معنای کلمات و روابط آنها بسیار حائز اهمیت است چرا که اغلب اوقات کلمات مشابه ممکن است در محتواهای مشابهی ظاهر شوند.
- Count-Based Vector Space Model
- Context-Based: Skip-Gram Model
- Context-Based: Continuous Bag-of-Words (CBOW)
- توابع خطا
- چند نکته مفید برای یادگیری تعبیه کلمه
- بردارهای سراسری (GloVe)
- نمونه مثالی از word2vec بر روی سریال بازی تاج و تخت!
- منابع
دو روش اصلی در رابطه با یادگیری word embedding وجود دارد که هر دوی آنها وابسته به دانش محتوایی اند:
- مبتنی بر شمارش(Count-based) : این روش بدون ناظر (unsupervised) بوده و مبتنی برتجزیه ماتریس یک ماتریس هم رخدادی کلمه سراسری(matrix factorization of a global word co-occurrence matrix) است. شمارش هم رخدادی خام(raw co-occurrence counts) به تنهایی بخوبی عمل نمیکند و به همین دلیل نیازمند انجام روشهای هوشمند دیگر بر روی نتایج آن است.
- مبتنی بر محتوا (Context-based): این یک روش با ناظر(supervised) است. در این روش به ازای یک محتوای محلی(local context) داده شده، مدلی جهت پیش بینی کلمات هدف طراحی شده و در همین حین، این مدل بازنمایی word embedding بهینه را فرا میگیرد.
مدل فضای برداری مبتنی بر شمارش (Count based Vector Space Model):
مدلهای فضای برداری مبتنی بر شمارش با فرض اینکه کلمات در یک محتوای یکسان از مفاد معنایی(semantic meanings) مرتبط یا مشابه بهره میبرند، بطور شدیدی وابسته به نرخ رخداد کلمات (فرکانس کلمات) و ماتریس هم رخدادی (co-occurrence matrix) اند. این مدل ها آمارهای مبتنی بر شمارش همانند هم رخدادی بین کلمات همسایه را به یک بردار کلمه کوچک و متراکم نگاشت میکنند. PCA، مدلهای موضوعی (topic models)، و مدلهای زبانی احتمالاتی عصبی (neural probabilistic language models) همگی نمونه های خوبی از این دسته اند.
روش های مبتنی بر محتوا متفاوت از روش های مبتنی بر شمارش، عمل کرده و اقدام به ساخت مدلهای پیش بینی میکنند که بصورت مستقیم پیش بینی یک کلمه را به ازای همسایه های داده شده آن هدف میگیرند. بردارهای کلمه متراکم بخشی از پارامترهای این گونه مدلها هستند. بهترین بازنمایی برداری از هر کلمه در زمان آموزش مدل فراگرفته میشود.
مبتنی بر محتوا : مدل Skip-Gram :
فرض کنید شما یک پنجره متحرک با اندازه ثابت دارید و آن را در امتداد یک جمله حرکت میدهید: کلمه ای که در وسط قرار میگیرد “هدف” و کلماتی که در سمت چپ و راست در داخل این پنجره متحرک(لغزان) قرار میگیرند همان کلمات محتوایی خواهند بود. مدل skip-gram (میکولوف و همکاران ۲۰۱۳)، مدلی است که در آن، به منظور پیش بینی احتمال اینکه آیا کلمه داده شده به ازای یک “هدف” یک کلمه محتوایی است یا خیر، آموزش میبیند.
نمونه مثالی که در ادامه آمده است چند جفت هدف و کلمات محتوایی مرتبط را بعنوان نمونه های آموزشی نشان میدهد، این کلمات توسط یک پنجره لغزان بطول ۵ کلمه که در امتداد یک جمله حرکت داده شده است بدست آمده اند.
ﺧﺪﺍﻭﻧﺪ ﺑﻪ ﻫﺮ ﭘﺮﻧﺪﻩﺍﯼ ﺩﺍﻧﻪﺍﯼ میدهد، ﺍﻣﺎ ﺁﻥ ﺭﺍ ﺩﺭ ﺩﺍﺧﻞ ﻻﻧﻪﺍﺵ نمیﺍﻧﺪﺍﺯﺩ.
| پنجره لغزان (اندازه = ۵) | کلمه هدف | محتوا |
|---|---|---|
| [خداوند به هر] | خداوند | به ، هر |
| [خداوند به هر پرنده ای] | به | خداوند, هر، پرنده ای |
| [خداوند به هر پرنده ای دانه ای] | هر | خداوند، به، پرنده ای، دانه ای |
| [به هر پرنده ای دانه ای میدهد] | پرنده ای | به، هر، دانه ای ، میدهد |
| … | … | … |
| [را در داخل لانه اش نمی اندازد] | داخل | را،در،لا نه اش، نمی اندازد |
| [در داخل لانه اش نمی اندازد] | لانه اش | در، داخل، نمی اندازد |
| [داخل لانه اش نمی اندازد] | نمی اندازد. | داخل، لانه اش |
با هر جفت “محتوا-هدف” بعنوان یک مشاهده جدید در داده برخورد میشود. بعنوان مثال، کلمه هدف”داخل” در مثال بالا، ۴ نمونه آموزشی تولید میکند که عبارتند از : (داخل، را)، (داخل، در)، (داخل، لانه اش) و (داخل، نمی اندازد)
معادل انگلیسی :
“The man who passes the sentence should swing the sword.” – Ned Stark
| Sliding window (size = 5) | Target word | Context |
|---|---|---|
| [The man who] | the | man, who |
| [The man who passes] | man | the, who, passes |
| [The man who passes the] | who | the, man, passes, the |
| [man who passes the sentence] | passes | man, who, the, sentence |
| … | … | … |
| [sentence should swing the sword] | swing | sentence, should, the, sword |
| [should swing the sword] | the | should, swing, sword |
| [swing the sword] | sword | swing, the |
 شکل ۱٫ مدل skip-gram. هم بردار ورودی x و هم بردار خروجی y از باز نمایی کلمه بصورت one hot رمز شده استفاده میکنند. لایه مخفی نیز word embedding ایی با اندازه N است.
شکل ۱٫ مدل skip-gram. هم بردار ورودی x و هم بردار خروجی y از باز نمایی کلمه بصورت one hot رمز شده استفاده میکنند. لایه مخفی نیز word embedding ایی با اندازه N است.
اگر اندازه لغتنامه V و اندازه بردارهای تعبیه کلمه برابر با N در نظربگیریم آنگاه مدل بصورت زیر فرا میگیرد تا هربار یک کلمه محتوایی (خروجی) را با استفاده از یک کلمه هدف(ورودی) پیش بینی کند. با توجه به شکل ۱ شاهد خواهیم بود که :
- هم کلمه ورودی
 و هم کلمه خروجی
و هم کلمه خروجی  که در قالب بردارهای x و y نمایش داده شده اند بصورت بردارهای one-hot رمز شده اند.
که در قالب بردارهای x و y نمایش داده شده اند بصورت بردارهای one-hot رمز شده اند. - ابتدا ضرب بردار x و ماتریس تعبیه کلمه
 با اندازه
با اندازه  بما بردار تعبیه کلمه ورودی را میدهد (iامین سطر از ماتریس W )
بما بردار تعبیه کلمه ورودی را میدهد (iامین سطر از ماتریس W ) - بردار تعبیه جدیدا بدست آمده که دارای N بعد است، لایه مخفی را تشکیل میدهد.
- ضرب لایه مخفی و ماتریس کلمه محتوایی
 با اندازه بردار one-hot شده خروجی y را تولید میکند
با اندازه بردار one-hot شده خروجی y را تولید میکند - ماتریس محتوایی خروجی معانی کلمات را در قالب محتوا، رمزگذاری (encode) میکند که متفاوت از ماتریس تعبیه است.
 بما بردار تعبیه کلمه ورودی
بما بردار تعبیه کلمه ورودی  بردار one-hot شده خروجی y را تولید میکند
بردار one-hot شده خروجی y را تولید میکنددقت کنید برخلاف نام مشابه بین ماتریس محتوا
 وماتریس تعبیه
وماتریس تعبیه  ، مستقل از بوده و هیچ ارتباطی به آن ندارد (یعنی معکوس یا تراناده و… ماتریس نیست!)
، مستقل از بوده و هیچ ارتباطی به آن ندارد (یعنی معکوس یا تراناده و… ماتریس نیست!)مبتنی بر محتوا : Continuous Bag of Words (CBOW)
مدل CBOW مدل دیگری است که برای یادگیری بردارهای کلمات مورد استفاده قرار میگیرد. این مدل کلمه هدف (مثلا “داخل”) را از بین کلمات محتوایی منبع (مثلا “را در داخل لانه اش نمی اندازد” ) پیش بینی میکند.
 شکل ۲ مدل CBOW. بردار های کلمات مربوط به چندین کلمه محتوایی میانگین گیری شده تا برداری با طول ثابت بعنوان لایه مخفی حاصل شود. سایر نماد ها دارای همان معنای خود در شکل ۱ هستند.
شکل ۲ مدل CBOW. بردار های کلمات مربوط به چندین کلمه محتوایی میانگین گیری شده تا برداری با طول ثابت بعنوان لایه مخفی حاصل شود. سایر نماد ها دارای همان معنای خود در شکل ۱ هستند.
از آنجایی که چند کلمه محتوایی وجود دارد، ما بردارهای کلمه متناظر با هر یک را که از طریق ضرب بردار ورودی با ماتریس حاصل شده اند، میانگین میگیریم. از اینجایی که مرحله میانگین گیری بخش زیادی از اطلاعات توزیعی را مسطح میکند، بعضی افراد اعتقاد دارند مدل CBOW برای دیتاست های کوچک مناسب تر است.
توابع خطا
هم مدل skip-gram و هم مدل CBOW باید جهت کمینه سازی یک تابع هدف/خطای بخوبی طراحی شده آموزش ببینند. چند تابع خطا وجود دارد که میتوانیم از آنها در فرایند آموزش این مدلهای زبانی استفاده کنیم. در ادامه، ما مدل skip-gram را بعنوان نمونه برای توصیف چگونگی محاسبه این خطا مورد استفاده قرار میدهیم .
Full Softmax
مدل skip-gram بردار تعبیه مربوط به هر کلمه را از طریق ماتریس و بردار محتوا را از طریق ماتریس خروجی مشخص میکند(تعریف میکند). به ازای کلمه ورودی  سطر متناظر از ماتریس را بعنوان بردار
سطر متناظر از ماتریس را بعنوان بردار  (بردار تعبیه) و ستون متناظر با آن در ماتریس را بعنوان بردار
(بردار تعبیه) و ستون متناظر با آن در ماتریس را بعنوان بردار  (بردار محتوا) برچسب گذاری میکنیم. لایه خروجی نهایی نیز تابع سافتمکس را برای محاسبه احتمال پیش بینی کلمه خروجی
(بردار محتوا) برچسب گذاری میکنیم. لایه خروجی نهایی نیز تابع سافتمکس را برای محاسبه احتمال پیش بینی کلمه خروجی  به ازای کلمه ورودی اعمال میکند و در نتیجه :
به ازای کلمه ورودی اعمال میکند و در نتیجه :

این رابطه همانطور که در شکل ۱ نمایش داده شده است دقیق است اما زمانی که  خیلی بزرگ باشد، محاسبه مخرج از طریق استفاده از تمامی کلمات برای هر نمونه از نظر محاسباتی غیرعملی است. نیاز برای تقریب احتمال شرطی بهینه تر (conditional probability estimation) سبب بوجود آمدن روشهای جدیدی مثل سافتمکس سلسله مراتبی یا همان hierarchical softamx شده است.
خیلی بزرگ باشد، محاسبه مخرج از طریق استفاده از تمامی کلمات برای هر نمونه از نظر محاسباتی غیرعملی است. نیاز برای تقریب احتمال شرطی بهینه تر (conditional probability estimation) سبب بوجود آمدن روشهای جدیدی مثل سافتمکس سلسله مراتبی یا همان hierarchical softamx شده است.
Hierarchical Softmax
اولین بار مورین و بنجیو (۲۰۰۵) سافتمکس سلسله مراتبی را برای تسریع عملیات جمع با استفاده از ساختار درخت دودویی پیشنهاد کردند. سافتمکس سلسله مراتبی لایه سافتمکس خروجی مدل زبانی را در قالب یک سلسله مراتب درختی کدگذاری میکند که در آن هر برگ یک کلمه و هر گره داخلی نمایانگر احتمال نسبی گره های فرزند میباشد.
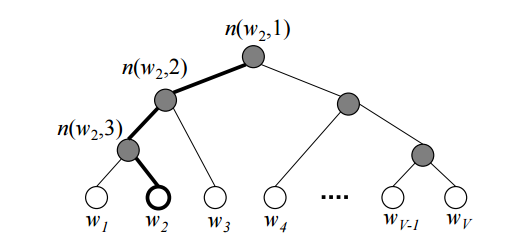
شکل ۳٫ شمایلی از یک درخت دودویی سافتمکس سلسله مراتبی. برگهای(گره های) سفید رنگ همان کلمات در لغتنامه اند. گره های داخلی خاکستری حامل اطلاعات در رابطه با احتمالات تا گره های فرزند میباشند. یک مسیر که از ریشه اغاز و به برگ  ختم میگردد.
ختم میگردد.  نشانگر
نشانگر  امین گره در این مسیر است.(منبع)
امین گره در این مسیر است.(منبع)
هر کلمه دارای یک مسیر یکتا از ریشه به سمت پایین و بطرف برگ مورد نظر است. احتمال انتخاب این کلمه برابر است با احتمال انتخاب این مسیر از ریشه بسمت پایین و درون شاخه های درخت. از انجایی که ما بردار تعبیه  مربوط به گره داخلی n را میدانیم ،لذا احتمال رسیدن به کلمه را میتوان از طریق ضرب انتخاب گردش به چپ یا راست در زمان مواجهه با هر گره داخلی انجام داد.
مربوط به گره داخلی n را میدانیم ،لذا احتمال رسیدن به کلمه را میتوان از طریق ضرب انتخاب گردش به چپ یا راست در زمان مواجهه با هر گره داخلی انجام داد.
بر اساس شکل ۳ احتمال یک گره برابر است با ( تابع سیگموید است) :
تابع سیگموید است) :
(۱) 
احتمال نهایی رسیدن به یک کلمه محتوایی به ازای کلمه ورودی برابر است با :

که در آن  عمق مسیری است که به کلمه میرسد و
عمق مسیری است که به کلمه میرسد و  نیز تابع نشانگر خاصی است که درصورتی که
نیز تابع نشانگر خاصی است که درصورتی که  فرزند چپ
فرزند چپ  باشد ۱ برمیگرداند و در غیر اینصور -۱ برمیگرداند. بردار های تعبیه گره های داخلی در حین آموزش مدل فراگرفته میشوند. ساختار درختی در جهت کاهش پیچیدگی تقریب مخرج از
باشد ۱ برمیگرداند و در غیر اینصور -۱ برمیگرداند. بردار های تعبیه گره های داخلی در حین آموزش مدل فراگرفته میشوند. ساختار درختی در جهت کاهش پیچیدگی تقریب مخرج از  (اندازه لغت نامه) به
(اندازه لغت نامه) به  (عمق درخت) کمک خیلی بزرگی در زمان آموزش میکند. اما در زمان پیش بینی، ما هنوز نیازمند محاسبه هر کلمه و انتخاب بهترین هستیم چرا که از ابتدا نمیدانیم به کدام برگ بایستی برسیم.
(عمق درخت) کمک خیلی بزرگی در زمان آموزش میکند. اما در زمان پیش بینی، ما هنوز نیازمند محاسبه هر کلمه و انتخاب بهترین هستیم چرا که از ابتدا نمیدانیم به کدام برگ بایستی برسیم.
انتخاب یک ساختار درختی مناسب برای کارایی مناسب مدل امری حیاتی است. چندین اصل سودمند برای نیل به این مهم وجود دارد از عبارتند از:
- کلمات را بر اساس نرخ رخداد آنها دسته بندی کنید همانند آنچیزی که توسط درخت هافمن برای افزایش سرعت ساده پیاده سازی شده است
- کلمات مشابه را در شاخه های یکسان یا نزدیک به هم دسته بندی کنید (یعنی از کلاسترهای کلمه ای از پیش تعریف شده استفاده کنید ، wordnet )
Cross Entropy
Cross Entropy روش دیگری است که کاملا متفاوت از چارچوب سافتمکس است. در اینجا تابع خطا Cross entropy بین احتمال پیش بینی شده  و برچسب های دودویی صحیح
و برچسب های دودویی صحیح  را اندازه میگیرد.
را اندازه میگیرد.
ابتدا اجازه دهید بیادبیاوریم که Cross entropy بین دو توزیع  و
و  بصورت
بصورت  محاسبه میشود. در مورد ما، برچسب صحیح
محاسبه میشود. در مورد ما، برچسب صحیح  تنها زمانی که کلمه خروجی باشد برابر با ۱ است و در غیر اینصورت برابر با ۰ خواهد بود. تابع خطا
تنها زمانی که کلمه خروجی باشد برابر با ۱ است و در غیر اینصورت برابر با ۰ خواهد بود. تابع خطا  مدل با پارامتر
مدل با پارامتر  بدنبال کمینه سازی Cross entropy بین پیش بینی و برچسب صحیح است چرا که Cross entropy کمتر نشانگر شباهت بیشتر بین دو توزیع است.
بدنبال کمینه سازی Cross entropy بین پیش بینی و برچسب صحیح است چرا که Cross entropy کمتر نشانگر شباهت بیشتر بین دو توزیع است.

در نتیجه:

 باشد.
باشد. (۲) 
که  توزیع نمونه های نویزی است.
توزیع نمونه های نویزی است.
بر اساس فرمول بالا، با توجه به عبارت اول ( هرچقدر مقدار  بزرگتر باشد loss بهتر خواهد بود) کلمه خروجی صحیح دارای یک افزایش مثبت(positive reinforcement) است، در حالی که سایر کلمات همانطور که توسط عبارت دوم مشخص شده است دارای اثر منفی خواهند بود.
بزرگتر باشد loss بهتر خواهد بود) کلمه خروجی صحیح دارای یک افزایش مثبت(positive reinforcement) است، در حالی که سایر کلمات همانطور که توسط عبارت دوم مشخص شده است دارای اثر منفی خواهند بود.
چگونگی تقریب  با نمونه مجموعه ای (sample set) از کلمات نویزی بجای آنکه تمامی لغت نامه را جستجو کنیم همان نکته کلیدی اصلی در استفاده از روش نمونه گیری مبتنی بر کراس انتروپی است
با نمونه مجموعه ای (sample set) از کلمات نویزی بجای آنکه تمامی لغت نامه را جستجو کنیم همان نکته کلیدی اصلی در استفاده از روش نمونه گیری مبتنی بر کراس انتروپی است
Noise Contrastive Estimation (NCE)
معیار Noise Contrastive Estimation (تقریب قیاسی نویز ) یا به اختصار NCE، به دنبال تفاوت قائل شدن بین کلمه هدف از نمونه های نویزی با استفاده از یک دسته بند logistic regression است (Gutmann and Hyvärinen, 2010).
به ازای کلمه ورودی کلمه خروجی صحیح تحت عنوان  شناخته میشود. در همین حین، ما اقدام به نمونه برداری از
شناخته میشود. در همین حین، ما اقدام به نمونه برداری از  کلمه دیگر از توزیع نمونه نویز
کلمه دیگر از توزیع نمونه نویز  میکنیم که بصورت
میکنیم که بصورت  مشخص شده است. اجازه دهید تصمیم دسته بندی دودویی را
مشخص شده است. اجازه دهید تصمیم دسته بندی دودویی را  در نظر بگیریم و نیز تنها قادر به دریافت یک مقدار دودویی است.
در نظر بگیریم و نیز تنها قادر به دریافت یک مقدار دودویی است.
![\mathcal{L}_\theta = - [ \log p(d=1 \vert w, w_I) + \sum_{\substack{i=1 \\ \tilde{w}_i \sim Q}}^N \log p(d=0|\tilde{w}_i, w_I) ]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-24010401e4d5e1aa5a9ecfa7966a8bdb_l3.png "Rendered by QuickLaTeX.com")
زمانی که به اندازه کافی بزرگ باشد، براساس قانون اعداد بزرگ :
![\mathcal{L}_\theta = - [ \log p(d=1 \vert w, w_I) + N\mathbb{E}_{\tilde{w}_i \sim Q} \log p(d=0|\tilde{w}_i, w_I)]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-56de27d6455e55d763f84e0290c88d18_l3.png "Rendered by QuickLaTeX.com")
به منظور محاسبه احتمال  ما میتوانیم با احتمال مشترک
ما میتوانیم با احتمال مشترک  شروع کنیم. در بین
شروع کنیم. در بین  ، ما در انتخاب کلمه صحیح ، که ازتوزیع احتمالاتی
، ما در انتخاب کلمه صحیح ، که ازتوزیع احتمالاتی  نمونه برداری شده، شانسی برابر با ۱ از
نمونه برداری شده، شانسی برابر با ۱ از  داریم، در همین حین، شانس انتخاب یک کلمه نویز که از
داریم، در همین حین، شانس انتخاب یک کلمه نویز که از  نمونه برداری شده است برابر از است. بنابراین :
نمونه برداری شده است برابر از است. بنابراین :

پس ما میتوانیم  و
و  را بدست بیاریم :
را بدست بیاریم :
(۳) 
(۴) 
سرانجام تابع خطای دسته بند دودویی NCE بصورت زیر خواهد بود :
(۵) ![\begin{align*} \mathcal{L}_\theta & = - [ \log p(d=1 \vert w, w_I) + \sum_{\substack{i=1 \\ \tilde{w}_i \sim Q}}^N \log p(d=0|\tilde{w}_i, w_I)] \\ & = - [ \log \frac{p(w \vert w_I)}{p(w \vert w_I) + Nq(\tilde{w})} + \sum_{\substack{i=1 \\ \tilde{w}_i \sim Q}}^N \log \frac{Nq(\tilde{w}_i)}{p(w \vert w_I) + Nq(\tilde{w}_i)}] \end{align*}](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-67a989a519304497865efe2d8ac5db6f_l3.png "Rendered by QuickLaTeX.com")
با این وجود  هنوز نیازمند جمع کردن تمامی (لغات موجود در) لغت نامه در مخرج است. اجازه دهید مخرج را بعنوان یک تابع جداساز کلمه ورودی،
هنوز نیازمند جمع کردن تمامی (لغات موجود در) لغت نامه در مخرج است. اجازه دهید مخرج را بعنوان یک تابع جداساز کلمه ورودی،  تعریف کنیم. یک فرض رایج این است که
تعریف کنیم. یک فرض رایج این است که  البته به شرطی که لایه خروجی سافتمکس نرمالیزه شده باشد(Minh and Teh, 2012). سپس تابع خطا بصورت زیر ساده میشود :
البته به شرطی که لایه خروجی سافتمکس نرمالیزه شده باشد(Minh and Teh, 2012). سپس تابع خطا بصورت زیر ساده میشود :
![\mathcal{L}_\theta = - [ \log \frac{\exp({v'_w}^{\top}{v_{w_I}})}{\exp({v'_w}^{\top}{v_{w_I}}) + Nq(\tilde{w})} + \sum_{\substack{i=1 \\ \tilde{w}_i \sim Q}}^N \log \frac{Nq(\tilde{w}_i)}{\exp({v'_w}^{\top}{v_{w_I}}) + Nq(\tilde{w}_i)}]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-03f4aa9694a67d45c7b9e09a5416eb61_l3.png "Rendered by QuickLaTeX.com")
توزیع نویز Q یک پارامتر قابل تنظیم است و خوب است آن را به شکلی طراحی کنیم که :
- بصورت شهودی، شبیه توزیع داده اصلی باشد و
- همچنین باید نمونه برداری از آن ساده باشد.
بعنوان مثال، پیاده سازی نمونه برداری مربوط به خطای NCE در تنسورفلو(log_uniform_candidate_sampler) اینطور فرض میکند که چنین نمونه های نویزی از یک توزیع log-uniform تبعیت میکنند که البته به قانون زیپ فیان (Zipfian’s law) نیز معروف است. چیزی که از احتمال لگاریتمی یک کلمه داده شده انتظار میرود این است که بصورت معکوس متناسب با درجه آن باشد، درحالی که کلمات با نرخ رخداد بالا درجه های پایین به آنها منتسب شوند. در این حالت  که در آن
که در آن ![r_{\tilde{w}} \in [1, V]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-d8cad168c9d37f441f00d25d3b762aff_l3.png "Rendered by QuickLaTeX.com") درجه کلمه ای بر اساس نرخ رخداد با ترتیب نزولی است.
درجه کلمه ای بر اساس نرخ رخداد با ترتیب نزولی است.
نمونه برداری منفی – Negative Sampling (NEG)
روش نمونه برداری منفی (Negative Sampling) یا به اختصار NEG توسط میکولوف و همکاران در سال (۲۰۱۳ارائه شد. این روش نمونه ساده شده ای از خطای NCE است. این روش بطور خاص بواسطه استفاده در فرآیند آموزش پروژه Word2Vec شرکت گوگل معروف است. این روش با خطای NCE متفاوت است از این جهت که بدنبال بیشینه سازی(تقریبی) احتمال لگاریتمی خروجی سافتمکس است، نمونه برداری منفی این فرایند را بیش از این ساده کرد چرا که بجای آنکه بدنبال مدلسازی توزیع کلمه در زبان طبیعی باشد بر روی یادگیری تعبیه سازی کلمه باکیفیت تمرکز میکند.
NEG خروجی دسته بندی دودویی را با توابع سیگمویید بصورت زیر تقریب میزند :
(۶) 
تابع خطای NCE نهایی بشکل زیر خواهد بود :
![\mathcal{L}_\theta = - [ \log \sigma({v'_{w}}^\top v_{w_I}) + \sum_{\substack{i=1 \\ \tilde{w}_i \sim Q}}^N \log \sigma(-{v'_{\tilde{w}_i}}^\top v_{w_I})]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-d04b2eab332b43880cfa0063bf9384c3_l3.png "Rendered by QuickLaTeX.com")
نکات دیگر جهت فراگرفتن تعبیه سازی کلمه (word embedding):
میکولوف و همکاران ۲۰۱۳ چند فعالیت کارآمد را پیشنهاد کردند که میتواند باعث نتایج تعبیه سازی لغت (word embedding) خوب شود :
- پنجره لغزان نرم (Soft sliding window):
زمانی که لغات را در یک پنجره لغزان با هم جفت میکنید، میتوانید وزن کمتری را به کلمات دورتر نسبت داد. یک روش ابتکاری – با فرض اینکه بیشترین اندازه پنجره بصورت پارامتری از قبل تعریف شده باشد، اندازه پنجره واقعی برای هر نمونه آموزشی بصورت تصادفی بین ۱ و انتخاب شود بنابراین، هر کلمه محتوایی با احتمالی برابر با ۱/ (فاصله آن تا کلمه هدف) مشاهده خواهد شد در حالی که کلمات نزدیک تر همیشه مشاهده میشوند.
از قبل تعریف شده باشد، اندازه پنجره واقعی برای هر نمونه آموزشی بصورت تصادفی بین ۱ و انتخاب شود بنابراین، هر کلمه محتوایی با احتمالی برابر با ۱/ (فاصله آن تا کلمه هدف) مشاهده خواهد شد در حالی که کلمات نزدیک تر همیشه مشاهده میشوند. - زیرنمونه گیری کلمات متداول (subsampling frequent words):
کلمات بشدت رایج ممکن است بیش از حد برای تفاوت قائل شدن در محتوا، کلی باشند، (مثلا کلمات پایانی در جملات(stopwords) را در نظر بگیرید). در حالی که از طرف دیگر، کلمات نادر بسیار محتمل ترند که معنای خاصی را منتقل کنند. برای ایجاد توازن بین کلمات نادر و کلمات رایج، میکولوف و همکاران پیشنهاد کردند کلمات با احتمال
با احتمال  در حین نمونه گیری حذف شوند. در اینجا
در حین نمونه گیری حذف شوند. در اینجا  نرخ رخداد کلمه و
نرخ رخداد کلمه و  آستانه قابل تنظیم است.
آستانه قابل تنظیم است. - فراگیری عبارات ابتدا انجام شود(Learning phrases first):
یک عبارت اغلب بجای آنکه ترکیبی ساده از چند لغت درنظر گرفته شود بعنوان یک واحد مفهومی در نظر گرفته میشود. بعنوان مثال ما واقعا نمیتوانیم تشخیص دهیم که آیا “New York” نام یک شهر است یا خیر حتی اگر معنای “new” و “york” را به تنهایی بدانیم. فراگیری چنین عباراتی در ابتدا و برخورد کردن با آنها بعنوان واحدهای لغتی قبل از آموزش مدل word embedding باعث بهبود کیفیت خروجی میشود. یک روش ساده مبتنی بر داده مبتنی بر شمارش unigram و bigram است : که
که  تعداد ساده unigram یا bigram
تعداد ساده unigram یا bigram  و
و  هم یک استانه تخفیف دهی برای پرهیز از کلمات و عبارات بیش از حد نادر است. امتیاز بالاتر نشانگر شانس بیشتر برای تشخیص عبارت است. برای ایجاد عبارات طولانی تر از ۲ کلمه، ما میتوانیم لغتنامه را چند بار با مقادیر کاهشی امتیاز مرور کنیم.
هم یک استانه تخفیف دهی برای پرهیز از کلمات و عبارات بیش از حد نادر است. امتیاز بالاتر نشانگر شانس بیشتر برای تشخیص عبارت است. برای ایجاد عبارات طولانی تر از ۲ کلمه، ما میتوانیم لغتنامه را چند بار با مقادیر کاهشی امتیاز مرور کنیم.
 از قبل تعریف شده باشد، اندازه پنجره واقعی برای هر نمونه آموزشی بصورت تصادفی بین ۱ و
از قبل تعریف شده باشد، اندازه پنجره واقعی برای هر نمونه آموزشی بصورت تصادفی بین ۱ و  در حین نمونه گیری حذف شوند. در اینجا
در حین نمونه گیری حذف شوند. در اینجا  نرخ رخداد کلمه و
نرخ رخداد کلمه و  آستانه قابل تنظیم است.
آستانه قابل تنظیم است. که
که  تعداد ساده unigram
تعداد ساده unigram  و
و  هم یک استانه تخفیف دهی برای پرهیز از کلمات و عبارات بیش از حد نادر است. امتیاز بالاتر نشانگر شانس بیشتر برای تشخیص عبارت است. برای ایجاد عبارات طولانی تر از ۲ کلمه، ما میتوانیم لغتنامه را چند بار با مقادیر کاهشی امتیاز مرور کنیم.
هم یک استانه تخفیف دهی برای پرهیز از کلمات و عبارات بیش از حد نادر است. امتیاز بالاتر نشانگر شانس بیشتر برای تشخیص عبارت است. برای ایجاد عبارات طولانی تر از ۲ کلمه، ما میتوانیم لغتنامه را چند بار با مقادیر کاهشی امتیاز مرور کنیم.GloVe: Global Vectors
مدل بردار سراسری یا به اختصار GloVe توسط پنینگتون و همکاران در سال ۲۰۱۴ به منظور ترکیب مدل تجزیه ماتریس مبتنی بر شمارش (count-based matrix factorization) و مدل skip-gram مبتنی بر محتوا (context-based skip gram) ارائه گردید.
ما میدانیم که شمارش ها و هم رخداد ها (counts and co-occurrences) میتوانند معنای کلمات را مشخص کنند. به منظور تمایز بین  در محتوای یک کلمه word embedding ، ما دوست داریم تا احتمال هم رخدادی (co-ocurrence probability) را بصورت زیر تعریف کنیم:
در محتوای یک کلمه word embedding ، ما دوست داریم تا احتمال هم رخدادی (co-ocurrence probability) را بصورت زیر تعریف کنیم:

 تعداد هم رخدادی بین کلمات و
تعداد هم رخدادی بین کلمات و  را شمارش میکند.
را شمارش میکند.
فرض کنید، ما دو کلمه =”ice” و  = “steam “داشته باشیم. کلمه سوم
= “steam “داشته باشیم. کلمه سوم  =”solid” به “ice” مربوط است و نه “steam” و بنابر این ما انتظار داریم
=”solid” به “ice” مربوط است و نه “steam” و بنابر این ما انتظار داریم  بسیار بزرگتر از
بسیار بزرگتر از  باشد و بنابر این
باشد و بنابر این  خیلی بزرگ باشد. اگر کلمه سوم = “water” به هر دو وابسته باشد و یا = “fashion” به هیچکدام ربطی نداشته باشد، انتظار میرود که به یک نزدیک باشد.
خیلی بزرگ باشد. اگر کلمه سوم = “water” به هر دو وابسته باشد و یا = “fashion” به هیچکدام ربطی نداشته باشد، انتظار میرود که به یک نزدیک باشد.
شهود در اینجا به این صورت است که بجای اینکه معنای کلمات با خود احتمالات بدست بیاید از طریق نسبت احتمالات هم رخدادی بدست آید. بردار سراسری روابط بین دو لغت را با توجه به کلمه محتوایی سوم بصورت زیر مدل میکند :

علاوه بر آن، از آنجایی که هدف در اینجا یادگیری بردارهای کلمه ای با معنی است،  بگونه ای طراحی شده است تا تابعی از تفاوت خطی بین دو کلمه و باشد:
بگونه ای طراحی شده است تا تابعی از تفاوت خطی بین دو کلمه و باشد:

با در نظر گرفتن متفارن بودن بین کلمات محتوایی و هدف، راه حل نهایی مدل کردن بعنوان یک تابع نمایی است. لطفا مقاله اصلی را برای اطلاعات بیشتر در مورد روابط مطرحی مطالعه کنید.
(۷) 
سرانجام،

ازآنجایی که عبارت دوم  مستقل از
مستقل از  است، میتوان عبارت بایاس
است، میتوان عبارت بایاس  را برای برای دریافت اضافه کرد. به منظور حفظ شکل تقارن، ما همچنین یک بایاس
را برای برای دریافت اضافه کرد. به منظور حفظ شکل تقارن، ما همچنین یک بایاس  برای اضافه میکنیم.
برای اضافه میکنیم.

تابع خطا برای مدل GloVe بطوری طراحی شده است تا فرمول بالا را با کمینه سازی جمع مربع خطاها حفظ کند :

طرح وزن دهی  تابعی از هم رخدادی و بوده و یکی از گزینه های قابل تنظیم مدل است.خروجی این تابع با میل
تابعی از هم رخدادی و بوده و یکی از گزینه های قابل تنظیم مدل است.خروجی این تابع با میل  باید نزدیک به صفر باشد، همینطور باید غیر نزولی بوده تا هم رخدادی بالاتر تاثیر گذاری بیشتری داشته باشد در زمانی که
باید نزدیک به صفر باشد، همینطور باید غیر نزولی بوده تا هم رخدادی بالاتر تاثیر گذاری بیشتری داشته باشد در زمانی که  خیلی بزرگ باشد نیز باید اشباع گردد. مقاله اصلی تابع وزن دهی زیر را پیشنهاد میدهد:
خیلی بزرگ باشد نیز باید اشباع گردد. مقاله اصلی تابع وزن دهی زیر را پیشنهاد میدهد:

مثال: word2vec بر روی سریال بازی تاج و تخت
بعد از بازنگری تمام مفاهیم نظری بالا، بیایید یک مثال کوچک در زمینه word embedding را که از سریال بازی تاج و تخت گرفته شده است با هم انجام دهیم. با استفاده از gensim این کار بسیار ساده ای است .
گام اول : استخراج کلمات :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# cmnt import sys from nltk.corpus import stopwords from nltk.tokenize import sent_tokenize STOP_WORDS = set(stopwords.words('english')) def get_words(txt): return filter( lambda x: x not in STOP_WORDS, re.findall(r'\b(\w+)\b', txt) ) def parse_sentence_words(input_file_names): """Returns a list of a list of words. Each sublist is a sentence.""" sentence_words = [] for file_name in input_file_names: for line in open(file_name): line = line.strip().lower() line = line.decode('unicode_escape').encode('ascii','ignore') sent_words = map(get_words, sent_tokenize(line)) sent_words = filter(lambda sw: len(sw) > 1, sent_words) if len(sent_words) > 1: sentence_words += sent_words return sentence_words # You would see five .txt files after unzip 'a_song_of_ice_and_fire.zip' input_file_names = ["001ssb.txt", "002ssb.txt", "003ssb.txt", "004ssb.txt", "005ssb.txt"] GOT_SENTENCE_WORDS= parse_sentence_words(input_file_names) |
گام دوم: تغذیه یک مدل word2vec
|
1 2 3 4 5 6 7 8 9 |
#cmnt from gensim.models import Word2Vec # size: the dimensionality of the embedding vectors. # window: the maximum distance between the current and predicted word within a sentence. model = Word2Vec(GOT_SENTENCE_WORDS, size=128, window=3, min_count=5, workers=4) model.wv.save_word2vec_format("got_word2vec.txt", binary=False) |
گام سوم: بررسی نتایج
در فضای تعبیه کلمه بازی تاج و تخت، شبیه ترین کلمات به پادشاه و ملکه (King و Queen) بصورت زیر است :
model.most_similar('king', topn=10)(word, similarity with ‘king’) |
model.most_similar('queen', topn=10)(word, similarity with ‘queen’) |
|---|---|
| (‘kings’, ۰٫۸۹۷۲۴۵) | (‘cersei’, ۰٫۹۴۲۶۱۸) |
| (‘baratheon’, ۰٫۸۰۹۶۷۵) | (‘joffrey’, ۰٫۹۳۳۷۵۶) |
| (‘son’, ۰٫۷۶۳۶۱۴) | (‘margaery’, ۰٫۹۳۱۰۹۹) |
| (‘robert’, ۰٫۷۰۸۵۲۲) | (‘sister’, ۰٫۹۲۸۹۰۲) |
| (‘lords’, ۰٫۶۹۸۶۸۴) | (‘prince’, ۰٫۹۲۷۳۶۴) |
| (‘joffrey’, ۰٫۶۹۶۴۵۵) | (‘uncle’, ۰٫۹۲۲۵۰۷) |
| (‘prince’, ۰٫۶۹۵۶۹۹) | (‘varys’, ۰٫۹۱۸۴۲۱) |
| (‘brother’, ۰٫۶۸۵۲۳۹) | (‘ned’, ۰٫۹۱۷۴۹۲) |
| (‘aerys’, ۰٫۶۸۴۵۲۷) | (‘melisandre’, ۰٫۹۱۵۴۰۳) |
| (‘stannis’, ۰٫۶۸۲۹۳۲) | (‘robb’, ۰٫۹۱۵۲۷۲) |
منابع
[۱] Tensorflow Tutorial Vector Representations of Words.
[۲] “Word2Vec Tutorial – The Skip-Gram Model” by Chris McCormick.
[۳] “On word embeddings – Part 2: Approximating the Softmax” by Sebastian Ruder.
[۴] Xin Rong. word2vec Parameter Learning Explained
[۵] Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[۶] Frederic Morin and Yoshua Bengio. “Hierarchical Probabilistic Neural Network Language Model.” Aistats. Vol. 5. 2005.
[۷] Michael Gutmann and Aapo Hyvärinen. “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models.” Proc. Intl. Conf. on Artificial Intelligence and Statistics. 2010.
[۸] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.
[۹] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[۱۰] Marco Baroni, Georgiana Dinu, and Germán Kruszewski. “Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors.” ACL (1). 2014.
[۱۱] Jeffrey Pennington, Richard Socher, and Christopher Manning. “Glove: Global vectors for word representation.” Proc. Conf. on empirical methods in natural language processing (EMNLP). 2014.
این مطلب ترجمه ای از نوشتار زیر است :
https://lilianweng.github.io/lil-log/2017/10/15/learning-word-embedding.html
در بخش های بعدی ما مفاهیم مطرح شده را بیشتر باز خواهیم کرد تا به درک کامل و دقیقی از مفاهیم عنوان شده در بالا برسیم.
خداییش خودت فهمیدی که چی نوشتی؟!
فقط صرفاً ترجمه کردی.
اصلاً مفهوم نیست.
سلام.
اگر مطالب این بخش برای شما سنگینه و احساس میکنید نیاز به توضیحات سطح بالاتر و کاملتری دارید لطفا بخش دوم رو که در ابتدای نوشتار لینکش داده شده مطالعه کنید.
هرکدوم از مطالبی که قرار داده میشه در سایت مخاطب و دلیل خاص خودشو رو داره.
سلام
زحمت زیاد کشیدین ولی لازم هست یک اصلاح کلی انجام بدین برای راحتی فهم مطالب .
من word embedding را بهتر متوجه شدم از مطالب این بخش که بعنوان پیش درامد آورده بودین.
متشکرم
ممنون از زحماتتون. بخش های بعدی کجاست؟ لطفا لینکش رو اینجا بذاربد
سلام وقت شما بخیر
بخشهای بعدی بعلت مشغله شدید کاری و… هنوز تو سایت قرار نگرفته .شما میتونید بخشی از این اموزشها رو در گیتهاب من ببینید(البته به انگلیسی هستند)
انشاءالله در فرصتهای اینده اموزشها رو به سایت منتقل میکنم