

بسم الله الرحمن الرحیم
در پست قبلی ما معرفی خیلی کوتاهی از word embedding یا همان “تعبیه سازی کلمات” و روشهای تولید آن داشتیم. در این نوشتار سعی میکنیم یکبار دیگر به این موضوع پرداخته و با زبان ساده تری با مفاهیم مطرح شده در قبل مثل تعبیه کلمه، شیوه کار word2vec و…بهتر آشنا شویم.
سرفصل ها در این نوشتار بصورت زیر است:
- تعریف
- Word embedding چیست؟
- بردار کلمات یا اصطلاحا Word Vector چیست؟
- یک مثال ابتدایی از Word embedding – معرفی One-hot encoding
- پیاده سازی یک طرح word embedding پیچیده تر
- خصائص word embedding
- خصائص و ویژگی های زبان شناختی word embedding (استدلال با بردار کلمات )
- فراگیری بردار کلمات
- مدل Continuous Bag of Words
- مدل Continuous Skip-gram
- بهینه سازی
- Softmax سلسله مراتبی
- نمونه برداری منفی
- الگوریتم های رایج word embedding مثل Word2vec,GloVe,Fasttext
- کتابخانه های مطرح جهت استفاده از word embedding در پایتون
- کاربردهای word embedding
تعریف
Word embedding ها بردار های عددی هستند که نمایانگر کلمات یک لغت نامه اند و کاربردهای گسترده ای هم در حوزه پردازش زبان طبیعی دارند (البته محدود به این حوزه نیستند!). اگر تا بحال از word embedding در کارهای مرتبط با دسته بندی متن یا احساس و یا سایر وظایف مرتبط با پردازش زبان طبیعی، استفاده نکرده باشید، به احتمال بسیار زیاد با بهره گیری از آن خواهید توانست بطور قابل توجهی دقت مدل خود را افزایش دهید. Word embedding بشما اجازه میدهد تا بطور غیرصریح اطلاعاتی را از دنیای بیرونی به مدل های زبانی خود اضافه کنید.
از سال ۱۹۹۰ ، مدلهای مبتنی بر فضای بردار در زمینه word embedding مورد استفاده محققان بوده اند. در طول این زمان، مدلهای بسیاری برای تقریب بازنمایی پیوسته کلمات(Continuous representations of words) توسعه داده شده اند که از Latent Semantic Analysis(LSA) و Latent Dirichlet Allocation(LDA) میتوان به عنوان دو نمونه نام برد. در اینجا تاریخچه مفصلی در این باره آمده که مطالعه آن خالی از لطف نیست. بنجیو و همکارانش در سال ۲۰۰۳ عبارت word embedding را ابداع کردند. اولین کسانی سودمندی word embedding های از پیش آموزش دیده را نشان دادند Collobert و Weston در سال ۲۰۰۸ بودند. مقاله معروف آنها ” A unified architecture for natural language processing ” نه تنها word embedding را بعنوان یکی از ابزارهای سودمند برای وظایف پایین دستی حوزه پردازش زبان طبیعی، تثیبیت کرد، بلکه معماری شبکه عصبی ای معرفی کرد که اساس بسیاری از روشهای امروزی است. اما همه گیری تدریجی word embedding را میتوان به کار میکولوف و همکارانش در سال ۲۰۱۳ که Word2vec را ارائه کردند منتسب کرد. در سال ۲۰۱۴، پنینتگون و همکرانش GloVe را که مجموعه ای قدرتمند از Word embedding های از پیش آماده را ارائه کردند و با این کار نشان دادند Word embedding وارد استفاده روزمره شده است.(منبع)
بطور ساده word embeddings و word vectors یعنی چه؟
مفهوم اصلی word embedding این است که تمامی لغات استفاده شده در یک زبان را میتوان توسط مجموعه ای از اعداد اعشاری (در قالب یک بردار) بیان کرد. Word embedding ها بردارهای n-بعدی ای هستند که تلاش میکنند معنای لغات و محتوای آنها را با مقادیر عددی خود ثبت و ضبط کنند. هر مجموعه ای از اعداد یک “بردار کلمه” معتبر بحساب می آید که الزاما برای ما سودمند نیست، آن مجموعه ای از بردار کلمات برای کاربردهای مورد نظر ما سودمندند که معنای کلمات ، ارتباط بین آنها و محتوای کلمات مختلف را همانطور که بصورت طبیعی [توسط ما] مورد استفاده قرار گرفته اند، بدست آورده باشند.
پس word embedding های سودمند چند مشخصه کلیدی دارند :
- هر کلمه دارای یک word embedding (یا بردار) یکتاست که تنها شامل لیستی ساده از اعداد به ازای هر کلمه است.
- word embedding ها چند بعدی اند و عموما یک مدل خوب، embedding هایی با طولی بین ۵۰ الی ۵۰۰ بعد دارد.
- به ازای هر کلمه، embedding معنای آن کلمه را بدست می آورد.
- کلمات مشابه در نهایت به مقادیر embedding مشابه میرسند.
اما بردار کلمه یعنی چه؟
در یک سطح، بردار کلمه خیلی ساده اشاره به برداری دارد که حاوی یکسری وزن(یا همان مقادیر عددی) است. مثلا اگر طرح کدگذاری one-hot را در نظر بگیریم، در این طرح ساده، هر المان در بردار به یک کلمه در لغت نامه اختصاص داده میشود یعنی هر درایه این بردار معرف یک کلمه از لغت نامه خواهد بود. برای هر کلمه نیز تنها درایه متناظر برابر با ۱ بوده و مابقی درایه ها با صفر مقداردهی خواهند شد. مثلا فرض کنید لغت نامه ما فقط حاوی ۵ کلمه “پادشاه”، “ملکه”، “مرد”، “زن” و “بچه” باشد. اگر از شیوه ای که تازه مطرح کردیم استفاده کنیم کلمه “ملکه” بصورت زیر بازنمایی خواهد شد :
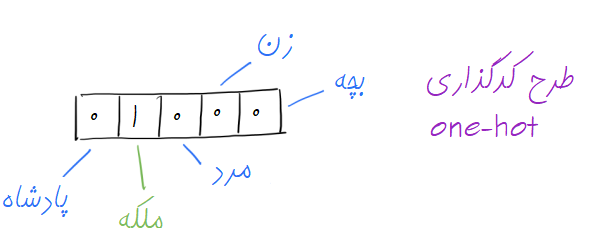
با استفاده از این شیوه، ما نمیتوانیم هیچ قیاس معناداری بین دو بردار داشته باشیم و تنها میتوانیم مساوی بودن بردارها را بررسی کنیم!
در الگوریتم word2vec (نکته انتهایی را ببینید) اما از بازنمایی توزیع شده برای هر کلمه استفاده میشود. بعنوان مثال برداری با چند بُعد را در نظر بگیرید. هر کلمه توسط توزیعی از مقادیر عددی (وزنها) بر روی درایه های مختلف بردار بازنمایی میشود. بنابر این بجای نگاشت یک به یک بین یک درایه در بردار و یک کلمه در لغت نامه، بازنمایی یک کلمه در تمامی درایه های یک بردار پخش میشود، و هر درایه بردار در مشخص شدن معنای تعداد زیادی از کلمات نقش ایفا میکند. برای درک بهتر این قضیه به مثال زیر توجه کنید. در مثال زیر کلمات مختلف توسط مقادیر مختلف هر درایه توصیف شده اند و تمامی درایه ها در ثبت و ضبط معنای کلمات مختلف نفش ایفا میکنند.(در اینجا ما خصائص ویژه ای را به هر درایه اختصاص داده ایم مثلا درایه اول مشخص کننده “صفت” حکمرانی، درایه دوم بردار مشخص کننده صفت “مردانگی” و الی اخر است. در بردار کلمه پادشاه میبینیم که درایه های مختلف به ترتیب بر اساس میزان سنخیت با صفت با کلمه مورد بحث، دارای مقادیر(وزن های) مختلفی اند. بعنوان مثال صفت مردانگی برای پادشاه بسیار بالا بوده اما صفت زنانگی مقدار پایینی دارد این مساله برای ملکه و زن برعکس است.)

چنین برداری بوسیله روشی انتزاعی، معنای یک کلمه را ارئه میکند. همانطور که در ادامه خواهیم دید، صرفا با استفاده از یک مجموعه متنی بزرگ ، میتوان بردار کلماتی را فرا گرفت که قادر به ثبت و ضبط روابط بین کلمات باشند. ما همچنین میتوانیم از این بردارها بعنوان ورودی به یک شبکه عصبی استفاده کنیم.
تمامی این نکات در ادامه با نمونه مثالهایی که جلوتر خواهیم دید روشن میشوند.
یک مثال ساده از Word Embedding
رمزگذاری One-hot
ساده ترین شکل یک طرح word embedding همانطور که تازه دیدیم کد گذاری one-hot است. دیدیم که در طرح کد گذاری one-hot یا کدگذاری ۱-of-N فضای embedding دارای ابعاد مشابهی با کلمات موجود در لغت نامه است و هر word embedding متشکل از برداری عموما ۰ است که تنها بُعد(درایه) متناظر با کلمه مورد انتظار مقداری برابر با ۱ دارد.
یک word embedding مبتنی بر روش کذگذاری one-hot برای لغت نامه کوچکی که حاوی ۹ کلمه است در شکل زیر نمایش داده شده است:

چند مشکل در رابطه با این شیوه کدگذاری وجود دارد :
- تعداد ابعاد (در اینجا ستون ها) با افزایش تعداد کلمات در لغت نامه بصورت خطی افزایش میابد. یعنی برای لغت نامه ای با ۵۰ هزار کلمه، هر کلمه بایستی توسط ۴۹,۹۹۹ صفر و تنها یک مقدار ۱ در مکان صحیح نمایش داده شود. به همین دلیل، مصرف حافظه بشدت افزایش پیدا میکند.
- ماتریس embedding نهایی خیلی تنک خواهد بود چرا که اکثرا از صفر تشکیل شده است.
- هیچ اشتراک اطلاعاتی بین کلمات و هیچ وجه مشترکی بین کلمات مشابه وجود ندارد. تمامی کلمات در فضای برداری با یک “فاصله یکسان” از یکدگیر قرار دارند (در مثال بالا هر word embedding ما یک بردار [۱×۹] است.)
کدگذاری سفارشی!
حالا اگر بخواهیم ابعاد این شیوه کدگذاری را کاهش دهیم یعنی از تعداد عدد کمتری برای نمایش /معرفی هر کلمه استفاده کنیم چه باید کرد؟ یک راه حل این است که این کار را از طریق انتخاب دستی ابعاد لغت نامه انجام دهیم. یعنی چه؟ اجازه دهید این مساله را با یک مثال بیشتر باز کنیم. فرض کنید ما سه بُعد بنام مردانگی، جوانی و حکومت را انتخاب کنیم و مقادیری که این سه بُعد قبول میکنند مقادیر اعشاری بین ۰ و ۱ باشد. سعی کنید لیست زیر را با مقادیری که بنظر شما منطقی است پر کنید.
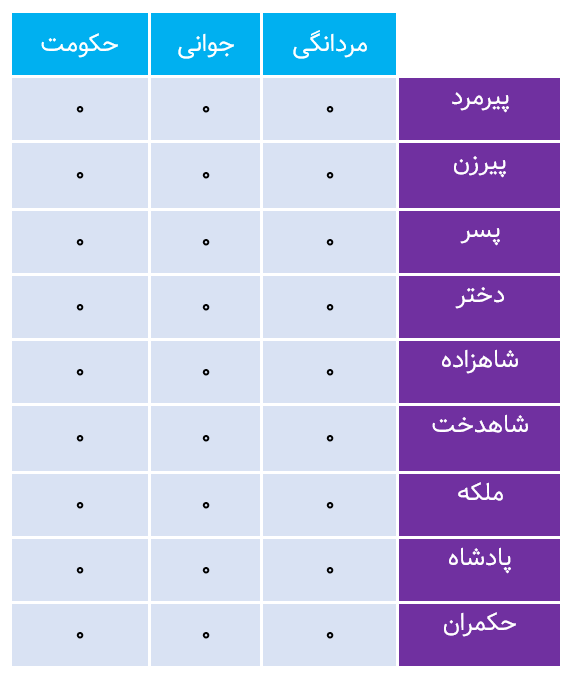
تنها با کمی فکر کردن احتمالا شما هم به چیزی شبیه آنچه در زیر آمده است رسیده اید:

- این مجموعه embedding ها بهینه تر از embedding هایی است که در ابتدا با کمک روش رمزگذاری one-hot بدست آورده بودیم. در اینجا هر کلمه توسط یک بردار ۳ بعدی ارائه شده است در حالی که روش قبلی هر کلمه توسط یک بردار ۹ بعدی ارائه میشد!
- کلمات مشابه دارای بردارهای مشابهی هستند بعبارت دیگر ، embedding های تولید شده برای کلمات “دختر” و “شاهدخت” فاصله کمتری نسبت به “دختر” به “شاهزاده” دارد. در اینجا فاصله ای که از آن صحبت میکنیم همان فاصله اقلیدسی (Euclidean distance) است.
- ماتریس embedding جدید خیلی متراکم تر از نمونه قبلی است (فضای خالی کمتری دارد،) و ما میتوانستیم بدون آنکه مجبور به افزایش ابعاد باشیم لغات بیشتری به لغت نامه اضافه کنیم. بعنوان مثال ما میتوانستیم کلمه “بچه” را با [۰٫۵ ,۱ , ۰] نمایش دهیم! بدون اینکه نیازی به افزایش بُعد جدیدی باشد!
- روابط بین کلمات ثبت و ضبط شده اند مثلا حرکت از سمت پادشاه به ملکه، مثل حرکت از طرف پسر به دختر است و میتوان آنرا بصورت [-۱, ۰, ۰] نمایش داد.
تعمیم به لغت نامه های بزرگتر
گام بعدی گسترش مثال ساده ۹ کلمه ای ما به یک لغت نامه کامل یا حداقل لغت نامه ای که شامل رایج ترین کلمات است میباشد. تشکیل بردار های n بعدی که بتوانند معنی را به همان صورتی که در مثال ساده خود دیدیم بدست آورند،و کلمات مشابه دارای embedding های مشابه بوده و روابط بین کلمات حفظ شود کار ساده ای نیست.
انتساب دستی بردارها در عمل غیرممکن است، چرا که مدل های word embedding معمولی صدها بُعد دارند و برخلاف مثال ساده ای که ما زدیم، در عمل هر بُعد به تنهایی قابل تفسیر نیست. به همین دلیل، الگوریتم های مختلفی توسعه داده شده اند، برخی از آنها قادرند مجموعه های عظیم متنی را دریافت کرده و مدلهای بامعنایی تولید کنند. الگوریتم Word2vec شرکت گوگل، الگوریتم GloVe دانشگاه استنفورد و الگوریتم fasttext شرکت فیس بوک از معروف ترین و رایح ترین این الگوریتم ها هستند.
قبل از آنکه به توضیح این روشها بپردازیم، ابتدا به بیان خصائص embedding هایی که بخوبی آموزش دیده اند میپردازیم و در ادامه هر روش را بصورت خلاصه بیان میکنیم.
خصائص Word Embedding
یک مجموعه کامل word embedding خصائص سودمند و فوق العاده ای از خود بروز میدهد، کلمات مشابه را تشخیص داده و بصورت طبیعی روابط بین کلمات را همانگونه که ما آنها را مورد استفاده قرار میدهیم ثبت و ضبط میکند.
شباهت کلمات /مترادف ها
در فضای word embedding کلمات مشابه به مکان های مشابهی در فضای  بعدی همگرا میشوند. در مثال بالا، کلمه “خودرو”، “وسیله نقلیه” و “وانت” هر سه در مکان مشابهی در فضای embedding قرار میگیرند ، بسیار دورتر از مکان کلمات بی ربطی مثل “ماه”، “فضا” ، “درخت” و…
بعدی همگرا میشوند. در مثال بالا، کلمه “خودرو”، “وسیله نقلیه” و “وانت” هر سه در مکان مشابهی در فضای embedding قرار میگیرند ، بسیار دورتر از مکان کلمات بی ربطی مثل “ماه”، “فضا” ، “درخت” و…
شباهتی که در اینجا از آن صحبت میکنیم را را میتوان توسط فاصله اقلیدسی (فاصله واقعی بین نقاط در فضای بُعدی) و یا شباهت کسینوسی یا اصطلاحا Cosine Similarity (زاویه بین دو بردار در فضای برداری) تعریف نمود.

در تحقیقات دانشگاه استنفورد، نزدیک ترین همسایه ها، برای کلمه قورباغه، کلمات آشنا و غیرآشنای بدست آمده توسط word embedding را نمایش میدهد.منبع
این خصیصه را میتوان با استفاده از کتابخانه Gensim در زبان پایتون مشاهده کرد که در آن، نزدیک ترین کلمات به یک کلمه هدف در فضای برداری را میتوان با استفاده مجموعه ای از Word embedding ها براحتی استخراج نمود.

در کاربردهای مبتنی بر یادگیری ماشین، خصیصه شباهت Word embedding ها برنامه ها را قادر میسازد تا با کلماتی که تا بحال در فاز آموزش با آنها مواجه نشده اند بخوبی کار کنند.
بجای اینکه تنها با استفاده از کلمات به مدلسازی پرداخته شود، مدلهای مبتنی بر یادگیری ماشین از بردار کلمات برای اهداف پیش گویانه استفاده میکنند. اگر کلماتی که تا بحال در زمان آموزش مشاهده نشده اند، اما در فضای Word embedding شناخته شده هستند، به مدل عرضه شوند، بردار کلمات بخوبی با این مدل به فعالیت خود ادامه خواهد داد . بعبارت دیگر اگر مدلی آموزش دیده تا بردارهای “گربه”، “وانت”، “جیپ” و “خودرو” را تشخیص دهد این مدل در مواجه با بردار “کامیون” بواسطه وجود شباهت در بین بردارها، همچنان بخوبی بکار خود ادامه خواهد داد.
به این شکل، استفاده از Word embedding بصورت ضمنی، اطلاعات اضافی را از مجموعه آموزشی Word embedding به برنامه کاربردی مورد نظر تزریق میکند. توانایی مدیریت عبارات دیده نشده (شامل املاهای غلط) برتری بسیار بزرگی برای روش های مبتنی بر Word embedding نسبت به روش های رایج قدیمی مثل TF-IDF ، Bag-of-words است.

روابط زبان شناختی
یکی از خصوصیت های جذاب word embedding های آموزش دیده این است که روابط بین کلمات در شیوه سخن گفتن معمولی نیز از طریق روابط خطی بین بردارها ثبت و ضبط میشود!
استدلال با استفاده از بردار کلمات
“…ما دریافتیم ک بازنمایی کلمات فراگرفته شده در حقیقت قواعد نحوی و معنایی را بشیوه ساده ای ثبت و ضبط میکنند. بطور ویژه، قواعد مورد بحث در قالب آفست های برداری ثابت (constant vector offsets) بین جفت کلماتی که رابطه خاصی با یکدیگر دارند مشاهده شده است. بعنوان مثال، اگر ما بردار مربوط به کلمه i را بصورت
در نظر بگیریم، و تمرکزمان را معطوف به رابطه بین صیغه مفرد/جمع کلمات نماییم، انوقت مشاهده میکنیم که
و الی آخر میباشد. شاید شگفت انگیز تر این باشد که ما دریافتیم که این حالت برای روابط معنایی متنوعی نیز صادق است! … “
 در نظر بگیریم، و تمرکزمان را معطوف به رابطه بین صیغه مفرد/جمع کلمات نماییم، انوقت مشاهده میکنیم که
در نظر بگیریم، و تمرکزمان را معطوف به رابطه بین صیغه مفرد/جمع کلمات نماییم، انوقت مشاهده میکنیم که  و الی آخر میباشد. شاید شگفت انگیز تر این باشد که ما دریافتیم که این حالت برای روابط معنایی متنوعی نیز صادق است! … “
و الی آخر میباشد. شاید شگفت انگیز تر این باشد که ما دریافتیم که این حالت برای روابط معنایی متنوعی نیز صادق است! … “این بردارها در پاسخ دادن به سوالات قیاسی به فرم “الف نسبت به ب همانند ج است نسبت به … ” بسیار خوب عمل میکنند. بعنوان مثال، سوال ” نسبت مرد به زن همانند نسبت عمو است به …. ” در اینجا توسط یک روش مبتنی بر آفست بردار ساده براحتی با استفاده از محاسبه فاصله کسینوسی بسادگی کلمه “زن عمو”، بدست می آید.
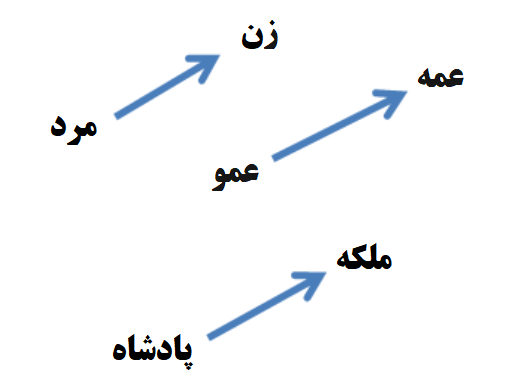
بعنوان مثالی دیگر، در اینجا آفست های برداری مربوط به سه جفت کلمه که نمایانگر رابطه “جنسیت” هستند را مشاهده میکنیم :
 در اینجا هم رابطه مفرد/جمع را مشاهده میکنیم:
در اینجا هم رابطه مفرد/جمع را مشاهده میکنیم:

این نوع از ترکیب بردار ها با یکدیگر، به ما اجازه میدهد تا بتوانیم به سوالاتی مثل ” پادشاه – مرد + زن = ؟” پاسخ داده و بعنوان مثال به جواب “ملکه” برای این سوال برسیم. چنین نتایجی واقعا شگفت انگیزند خصوصا زمانی که بیاد می آوریم تمام دانشی که در اینجا با آن مواجه هستیم صرفا با نگاه به تعداد زیادی از کلمات در زمینه محتوایی خاص خود بدست آمده است بدون آنکه هیچ اطلاعات دیگری مبنی بر معنای این کلمات به مدل ارائه شود!
مساله ای که تا حدودی شگفت آور است این است که ما دریافتیم شباهت بین بازنمایی های کلمات فراتر از قواعد نحوی است. با استفاده از یک تکنیک آفست کلمه، که در آن عملیات جبری ساده ای بر روی بردار کلمات اعمال گردید، مشاهده گردید که بعنوان مثال، بردار(پادشاه) – بردار(“مرد”) + بردار(“زن”) برداری را نتیجه میدهد که بسیار به بازنمایی بردار کلمه “ملکه” نزدیک است!
بردارهای مربوط به پادشاه، مرد ، ملکه و زن :

نتیجه ترکیب بردارهای پادشاه – مرد + زن = ؟
 در اینجا نتایج بیشتری که توسط همین روش بدست آمده است را مشاهده میکنید:
در اینجا نتایج بیشتری که توسط همین روش بدست آمده است را مشاهده میکنید:
 همچنین ما میتوانیم از عملیات جمع درایه به درایه بر روی بردارها استفاده کنیم و اینگونه به سوالاتی نظیر چک + واحد پولی و… تنها از طریق مشاهده نزدیک ترین بردار به بردار نتیجه شده خود پاسخ دهیم!:
همچنین ما میتوانیم از عملیات جمع درایه به درایه بر روی بردارها استفاده کنیم و اینگونه به سوالاتی نظیر چک + واحد پولی و… تنها از طریق مشاهده نزدیک ترین بردار به بردار نتیجه شده خود پاسخ دهیم!:

بردار کلمات با چنین روابط معنایی میتوانند جهت بهبو بسیاری از کاربردهای حوزه پردازش زبان طبیعی، نظیر ترجمه ماشینی، بازیابی اطلاعات و سامانه های پرسش و پاسخ مورد استفاده قرار گیرند و ممکن است کاربردهایی که هنوز اختراع نشده اند را در آینده موجب گردند.
در مقاله اصلی word embedding ، مثالهای جالبی از روابط موجود برای مواردی مثل “پایتخت کشورِ “، “رودخانه اصلی در” ، زمان فعل، و… سایر الگوهای جالب آورده شده است. درک و توجه به این موضوع که این روابط بطور صریح در حین فرایند آموزش به مدل ارائه نشده بلکه از طریق استفاده از زبان در دیتاست آموزشی “کشف” شده اند بسیار مهم است

در زیر مثال دیگری از رابطه میان کلمات را مشاهده میکنید که روابطی مربوط به جنسیت (حرکت از سمت جنسیت نر به ماده) و یا زمان فعل ( حال به گذشته) را نشان میدهد :

روابط خطی بین کلمات در فضای embedding موجب ظهور جبر کلمه ای غیرمعمولی میشود که به کلمات اجازه جمع و تفریق داده و نتایج منطقی نیز بدنبال دارد! بعنوان مثال، در یک مدل word embedding بخوبی تعریف شده، محاسباتی همانند آنچه در ادامه میبینید واقعا کار میکنند و نتایج صحیح و منطقی ارائه میدهند (در مثال زیر [x] به معنای بردار کلمه x است. پس [man] یعنی بردار embedding مربوط به کلمه man میباشد)
[[king]] – [[man]] + [[woman]] = [[queen]] [[Paris]] – [[France]] + [[Germany]] = [[Berlin]]
مثال دوم :

مبنای الگوریتم های آموزش Word embedding
محتوای کلمه
در زمان آموزش word embedding برای یک لغت نامه بزرگ، تمرکز بر روی بهینه سازی embedding هاست بگونه ای که معنای اصلی و روابط بین کلمات حفظ شود. این ایده اولین بار توسط جان روپرت فرث که بعنوان زبان شناس بر روی الگوهای زبانی در دهه ۱۹۵۰ کار میکرد ارائه شد.
شما باید یک کلمه را از اطرافیانش بشناسید!
فرث به اصلی اشاره دارد که در آن معنای یک کلمه آن چیزی است که توسط استفاده آن به همراه سایر کلمات بدست می آید چرا که کلمات دربرگیرنده، برای هر کلمه ای برای دریافت معنای آن کلمه مفیدند!


فرض کنید ما کلمه ای را بعنوان کلمه “وسطی” انتخاب کنیم سپس به کلمات “معمولی” که ممکن است این کلمه را در یک استفاده زبانی رایج احاطه کنند نگاه کنیم. دیاگرام زیر کلمات محتوایی محتمل برای کلمات “وسطی” مورد نظر را نشان میدهد. در این مثال، کلمات محتوایی برای “وانت” معمولا ” تایر،”جاده”،”مسافرت” و… هستند. کلمات محتوایی برای یک کلمه شبیه به “وانت” مثل “خودرو” نیز مشابه هستند! . به همین شکل، کلمات محتوایی برای کلمه نامشابه ای مثل “ماه”، نتایج کاملا متفاوتی خواهد داشت.
 کلمات محتوایی “وسیله نقلیه”، انتظار میرود که این کلمات مشابه کلمات محتوایی برای “وانت” و “خودرو” باشند.
کلمات محتوایی “وسیله نقلیه”، انتظار میرود که این کلمات مشابه کلمات محتوایی برای “وانت” و “خودرو” باشند.

 کلمات محتوایی برای خودرو ممکن است شامل”جاده”،”فرمان گیری” و… باشد و نه ماه و یا برج!
کلمات محتوایی برای خودرو ممکن است شامل”جاده”،”فرمان گیری” و… باشد و نه ماه و یا برج!
 کلمات محتوایی برای “ماه” در یک متن ساده بطور اساسی با کلماتی که برای “خودرو”، وسیله نقلیه و “وانت” ارائه میشوند متفاوت است.
کلمات محتوایی برای “ماه” در یک متن ساده بطور اساسی با کلماتی که برای “خودرو”، وسیله نقلیه و “وانت” ارائه میشوند متفاوت است.
فراگیری بردار کلمات
میکولوف و همکارانش اولین کسانی نبودند که از بازنمایی های برداری پیوسته کلمات استفاده کردند، او و همکارانش اما اولین کسانی بودند که چگونگی کاهش پیچیدگی محاسبات مربوط به یادگیری چنین بازنمایی ها را نشان دادند. فعالیت ایشان موجب شد تا بتوان بردار کلمات با ابعاد بالایی را با استفاده از حجم عظیمی از داده ها فرا گرفت چیزی که سابقا ممکن نبود. بعنوان مثال، همانطور که در مقاله اشاره شده است:
“…ما از مجموعه متن اخبار گوگل برای آموزش بردار کلمات بهره بردیم. این مجموعه متن شامل بیش از ۶ میلیارد توکن است که البته ما اندازه لغت نامه خود را به ۱ میلیون کلمه پرکاربرد محدود نمودیم…”
دو روش اصلی برای آموزش مدلهای word embedding وجود دارد:
- مدل های معنایی توزیع شده (Distributed Semantic Models) :این مدلها مبتنی بر هم رخداد/نزدیکی کلمات به یکدگیر در یک مجموعه متنی بزرگ میباشند. یک ماتریس هم رخداد (co-occurrence matrix) برای مجموعه متنی بزرگی تشکیل میشود ( یک ماتریس
 با مقادیری که هر کدام نمایانگر احتمال رخ دادن کلمات در کنار همدیگر است)، و این ماتریس تجزیه شده (توسط SVD/PCA و یا روشهای مشابه) تا یک ماتریس بردار کلمه را تشکیل دهد. تکنیک های مدلسازی word embedding به این شیوه به روشهای مبتنی بر شمارش یا همان Count approaches یا Count based معروف اند.
با مقادیری که هر کدام نمایانگر احتمال رخ دادن کلمات در کنار همدیگر است)، و این ماتریس تجزیه شده (توسط SVD/PCA و یا روشهای مشابه) تا یک ماتریس بردار کلمه را تشکیل دهد. تکنیک های مدلسازی word embedding به این شیوه به روشهای مبتنی بر شمارش یا همان Count approaches یا Count based معروف اند. - مدلهای شبکه عصبی (Neural Network Models) : روشهای مبتنی بر شبکه های عصبی عموما “روش های مبتنی بر پیش بینی” یا بهتر بگوییم “پیش بینی محور” هستند که در آنها مدلها برای پیش بینی کلمات محتوایی با استفاده از کلمات وسطی، یا برعکس (پیش بینی کلمه وسط با استفاده ازمجموعه ای از کلمات محتوایی) ساخته میشوند.
 با مقادیری که هر کدام نمایانگر احتمال رخ دادن کلمات در کنار همدیگر است)، و این ماتریس تجزیه شده (توسط SVD/PCA و یا روشهای مشابه) تا یک ماتریس بردار کلمه را تشکیل دهد. تکنیک های مدلسازی word embedding به این شیوه به روشهای مبتنی بر شمارش یا همان Count approaches یا Count based معروف اند.
با مقادیری که هر کدام نمایانگر احتمال رخ دادن کلمات در کنار همدیگر است)، و این ماتریس تجزیه شده (توسط SVD/PCA و یا روشهای مشابه) تا یک ماتریس بردار کلمه را تشکیل دهد. تکنیک های مدلسازی word embedding به این شیوه به روشهای مبتنی بر شمارش یا همان Count approaches یا Count based معروف اند.مساله ای که در رابطه با مدل های مبتنی بر شبکه عصبی وجود دارد بحث پیچیدگی زیاد این نوع شبکه هاست. این پیچیدگی در مدلهای شبکه عصبی، (چه پیش خور و چه مدلهای بازگشتی ) از لایه های مخفی غیرخطی نشات میگیرد:
…هرچند این همان خصیصه ای است که شبکه های عصبی را بسیار جذاب میکند، اما ما تصمیم گرفتیم مدلهای ساده تری که قادر به بازنمایی داده ها با همان دقت شبکه های عصبی نیستند، اما در عین حال اجازه آموزش بهینه بر روی انبوهی ازداده ها را فراهم میکنند، مورد بررسی و کنکاش قرار دهیم.
به همین جهت دو معماری جدید ارائه شد: مدل Continuous Bag of words و مدل Continuous Skip-gram.
نکته:
روشهای پیش بینی محور، عموما از نقطه نظر کارایی روش های مبتنی بر شمارش را پشت سر میگذارند و بهتر از آنها عمل میکنند. بعضی از رایج ترین الگوریتم های word embedding ، مثل Skip-Gram ، Continuous Bag of Words (CBOW) و Word2Vec همگی روشهای پیش بینی محور هستند.
مدل Continuous Bag of Words
اجازه دهید با مدل CBOW شروع کنیم. متنی مثل “من هر هفته با وسیله نقلیه عمومی به دانشگاه میروم.” را در نظر بگیرید. فرض کنید یک پنجره لغزان بر روی این متن وجود دارد و کلمه ای که روی آن تمرکز شده، همان کلمه وسطی باشد که ۴ کلمه قبل و بعد از آن وجود دارد. :
کلمات محتوایی لایه ورودی را تشکیل میدهند و هر کلمه نیز، در قالب یک بردار one-hot ارائه میشود، اندازه لغت نامه را  در نظر میگیریم. بنابر این، این بردارها در نتیجه بُعدی خواهند بود و تنها یک درایه آنها مقداری برابر با ۱ خواهد داشت و مابقی درایه ها صفر خواهند بود. در اینجا تنها یک لایه مخفی و یک لایه خروجی وجود دارد.
در نظر میگیریم. بنابر این، این بردارها در نتیجه بُعدی خواهند بود و تنها یک درایه آنها مقداری برابر با ۱ خواهد داشت و مابقی درایه ها صفر خواهند بود. در اینجا تنها یک لایه مخفی و یک لایه خروجی وجود دارد.

هدف آموزش، بیشینه سازی احتمال شرطی مشاهده کلمه خروجی واقعی (کلمه وسطی ) به ازای کلمات محتوایی ورودی، با توجه به وزن انهاست. در مثال ما، به ازای دریافت ورودی (” من”،”هر”، هفته”، “با”، “عمومی”، “به”، “دانشگاه”، “میروم”) ما میخواهیم احتمال دریافت “وسیله نقلیه” را بعنوان خروجی بیشینه کنیم.
از آنجایی که بردارهای ورودی ما بصورت one-hot هستند، ضرب یک بردار ورودی در ماتریس وزن  به مثابه انتخاب سطری از خواهد بود:
به مثابه انتخاب سطری از خواهد بود:

به ازای C بردار کلمه ورودی، تابع فعالسازی لایه مخفی  خیلی ساده اقدام به جمع “سطر های فعال” در ماتریس وزن میکند (سطرهایی که در ضرب با ورودی انتخاب شدند) و سپس نتیجه را بر
خیلی ساده اقدام به جمع “سطر های فعال” در ماتریس وزن میکند (سطرهایی که در ضرب با ورودی انتخاب شدند) و سپس نتیجه را بر  تقسیم کرده تا میانگین آنها را بدست آید.
تقسیم کرده تا میانگین آنها را بدست آید.
این به این معناست که تابع (فعالسازی) پیوند واحدهای لایه مخفی ،خطی هستند! (یعنی، بصورت مستقیم جمع وزن دار ورودی را به لایه بعدی ارسال میکنند!)
ببین لایه مخفی و لایه خروجی، ماتریس وزن دومی بنام  وجود دارد که از آن برای محاسبه امتیازی برای تمامی کلمات موجود در لغت نامه استفاده میشود و بعد از آن میتوان از سافتمکس برای کسب توزیع خلفی(posterior distribution) کلمات بهره برد.
وجود دارد که از آن برای محاسبه امتیازی برای تمامی کلمات موجود در لغت نامه استفاده میشود و بعد از آن میتوان از سافتمکس برای کسب توزیع خلفی(posterior distribution) کلمات بهره برد.
مدل Skip-gram
مدل skip-gram برعکس مدل CBOW است. این مدل بگونه ای ساخته شده است تا کلمه وسطی را بعنوان یک بردار ورودی دریافت کرده و کلمات محتوایی هدف را در لایه خروجی تولید کند.
 تابع فعالسازی لایه مخفی تنها در کپی کردن سطرهای متناظر از ماتریس وزن ۱ (خطی) خلاصه میشود. در لایه خروجی، ما بجای اینکه یک توزیع چند جمله ای داشته باشیم! C توزیع چندجمله ای خواهیم داشت. هدف آموزش کمینه سازی مجموع خطای پیش بینی همه کلمات محتوایی در لایه خروجی است. در مثال ما ورودی “وسیله نقلیه” بوده و ما امیدواریم (” من”،”هر”، هفته”، “با”، “عمومی”، “به”، “دانشگاه”، “میروم”) را در خروجی ببینیم!
تابع فعالسازی لایه مخفی تنها در کپی کردن سطرهای متناظر از ماتریس وزن ۱ (خطی) خلاصه میشود. در لایه خروجی، ما بجای اینکه یک توزیع چند جمله ای داشته باشیم! C توزیع چندجمله ای خواهیم داشت. هدف آموزش کمینه سازی مجموع خطای پیش بینی همه کلمات محتوایی در لایه خروجی است. در مثال ما ورودی “وسیله نقلیه” بوده و ما امیدواریم (” من”،”هر”، هفته”، “با”، “عمومی”، “به”، “دانشگاه”، “میروم”) را در خروجی ببینیم!
بهینه سازی
بروز کردن تمامی بردار کلمات خروجی به ازای تمامی کلمات در یک فرایند آموزش عملیاتی بشدت هزینه بر است :
به منظور حل این مساله، یک راه حل شهودی محدود سازی تعداد بردارهای خروجی است که ممکن است در هر فرایند آموزش بروزشوند. یک روش زیبا برای دست یابی به این مساله، استفاده از سافتمکس سلسله مراتبی است. روش دیگر از طریق نمونه برداری محقق میشود.
Softmax سلسله مراتبی
سافتمکس سلسله مراتبی، از یک درخت دودویی برای بازنمایی تمامی کلمات یک لغت نامه بهره میبرد. کلمات خود، برگهای درخت هستند و برای هر برگ ، مسیری یکتا از ریشه به آن برگ وجود دارد. این مسیر همان چیزی است که برای تقریب احتمال کلمه ای که آن برگ معرف آن است استفاده میشود. ما احتمال را بصورت احتمال پیاده روی تصادفی با شروع از ریشه و رسیدن به برگ مورد نظر تعریف میکنیم.
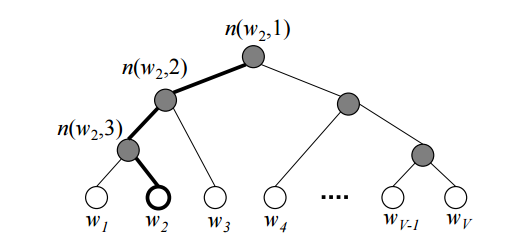 شمایلی از یک درخت دودویی سافتمکس سلسله مراتبی. برگهای(گره های) سفید رنگ همان کلمات در لغتنامه اند. گره های داخلی خاکستری حامل اطلاعات در رابطه با احتمالات تا گره های فرزند میباشند. یک مسیر که از ریشه اغاز و به برگ
شمایلی از یک درخت دودویی سافتمکس سلسله مراتبی. برگهای(گره های) سفید رنگ همان کلمات در لغتنامه اند. گره های داخلی خاکستری حامل اطلاعات در رابطه با احتمالات تا گره های فرزند میباشند. یک مسیر که از ریشه اغاز و به برگ  ختم میگردد.
ختم میگردد.  نشانگر
نشانگر  امین گره در این مسیر است.
امین گره در این مسیر است.
مزیت اصلی در اینجا، این است که بجای ارزیابی
گره خروجی در شبکه عصبی به منظور دست یافتن به توزیع احتمالاتی، تنها نیاز به ارزیابی حدودا
کلمه است… برای کار خود، ما از یک درخت هافمن دودویی، که کدهای کوتاهی به کلمات مکرر منتسب میکند و در نتیجه موجب تسریع فرآیند آموزش میشود، استفاده میکنیم.
 کلمه است… برای کار خود، ما از یک درخت هافمن دودویی، که کدهای کوتاهی به کلمات مکرر منتسب میکند و در نتیجه موجب تسریع فرآیند آموزش میشود، استفاده میکنیم.
کلمه است… برای کار خود، ما از یک درخت هافمن دودویی، که کدهای کوتاهی به کلمات مکرر منتسب میکند و در نتیجه موجب تسریع فرآیند آموزش میشود، استفاده میکنیم.نمونه برداری منفی (NEG)
نمونه برداری منفی به بیان ساده، همان بروز رسانی “نمونه ای” از کلمات خروجی در هر تکرار است. کلمه خروجی هدف در اینجا باید در نمونه برداری مورد نظر، حفظ شده و بروز رسانی گردد. در این نمونه برداری علاوه بر کلمه مورد نظر، چند کلمه (غیر-هدف) نیز بعنوان نمونه های منفی قرار داده میشود و به همین دلیل به این شیوه، روش نمونه برداری منفی گفته میشود. “یک توزیع احتمالاتی برای این فرآیند نمونه برداری مورد نیاز بوده که میتوان بصورت دلخواه آنرا انتخاب کرد… فرد میتواند یک توزیع خوب را بصورت تجربی انتخاب کند.”
میکولوف و همکارانش همچنین از یک روش زیرنمونه برداری ساده جهت مقابله با عدم توازن موجود بین کلمات متداول و نادر در مجموعه آموزشی استفاده کردند.(بعنوان مثال در، و، را و… ارزش اطلاعاتی کمتری نسبت به کلمات نادر فراهم میکنند). در طرح پیشنهادی آنها، هر کلمه در مجموعه آموزشی، با توزیع  حذف میشود :
حذف میشود :
![\[ P(w_i) = 1 - \sqrt{\frac{t}{f(w_i)}} \]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-0989d33e210424c0ecddf326ff7a6236_l3.png "Rendered by QuickLaTeX.com")
در اینجا  نرخ تکرار کلمه است.
نرخ تکرار کلمه است.  نیز در اینجا مقدار آستانه انتخاب شده است که عموما دارای مقداری برابر با
نیز در اینجا مقدار آستانه انتخاب شده است که عموما دارای مقداری برابر با  است.
است.
ایده word2vec بیشینه سازی شباهت (یا در اصل همان نتیجه ضرب نقطه ای ) بین بردارهایی که در متن نزدیک بهمبنظر میرسند (درمحتوای مربوط به یکدیگر ) و کمینه سازی شباهت کلماتی که اینگونه نیستند است. در معادله شماره ۳ مقاله اصلی(شماره ۴ در منابع)  ، برای لحظه ایی توجهی به توان نمایی نکنید. با انجام این کار با عبارت زیر مواجه خواهیم شد :
، برای لحظه ایی توجهی به توان نمایی نکنید. با انجام این کار با عبارت زیر مواجه خواهیم شد :
![\[ \frac{v_c \cdot v_w}{\sum(v_{c1} \cdot v_w)} \]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-919dc4a1d52c7e6b07739fdaf3462a71_l3.png "Rendered by QuickLaTeX.com")
صورت کسر بطور ساده همان میزان شباهت بین c (کلمه محتوایی) و w (کلمه هدف) است. مخرج کسر نیز محاسبه شباهت تمامی کلمات محتوایی با کلمه هدف w را بر عهده دارد. بیشینه سازی این نسبت اطمینان حاصل میکند که کلماتی که در متن بهم نزدیک تر هستند بردارهای مشابه تری نسبت به آنهایی که نیستند ایجاد کند. اما، محاسبه به این صورت سربار خیلی زیاده تحمیل کرده و زمان زیادی برای محاسبه طلب میکند چرا که کلمات محتوایی (c1) زیادی وجود دارد. نمونه گیری منفی یکی از راه های مقابله با این مشکل است. در این روش چند کلمه محتوایی بصورت تصادفی انتخاب میشوند. نتیجه نهایی اینگونه است که مثلا اگر گربه در محتوای “غذا” ظاهر شود، بنابر این بردار “غذا” بیشتر به “گربه” شبیه است(چنانکه ازنتیجه ضرب نقطه ای بین آنها بدست می آید) تا کلمات دیگری که بصورت تصادفی انتخاب شدند(مثلا حرص، دموکراسی، بنزین و…) (و نه تمامی کلمات موجود در لغت نامه!) و این باعث میشود بتوان خیلی سریعتر word2vec را آموزش داد.(منبع)
الگوریتم های رایج Word embedding
یکی از رایج ترین روش های آموزش Word2vec است که توسط تیمی به سرپرستی میکولوف در گوگل توسعه پیدا کرد. این روش در زمان آموزش در اصل از تکنیک های Skip-gram و CBOW بطور همزمان با هم استفاده میکند. روش های آموزش دیگری نیز وجود دارند که از آنها میتوان به بردارهای سراسری برای بازنمایی کلمات یا همان GloVe و یا الگوریتم fasttext اشاره کرد که الگوریتم اول توسط تیم پردازش زبان طبیعی دانشگاه استنفورد و الگوریتم دوم توسعه فیس بوک توسعه داده شده است.

کیفیت مدلهای word embedding مختلف را میتوان از طریق سنجش روابط بین یک مجموعه کلمات شناخته شده مورد ارزیابی قرار داد. میکولوف و همکاران روشی را توسعه دادند که از طریق آن میتوان مجموعه ای از بردار ها را ارزیابی کرد. دقت مدل و سودمنی وابسته به داده آموزشی مورد استفاده ، انتخاب فراپارامترهای مرتبط با الگوریتم آموزش، الگوریتم مورد استفاده، و ابعاد مدل است.
استفاده از Word embedding در پایتون
گزینه های مختلفی برای استفاده از word embedding در پروژه شما در پایتون وجود دارد. دو کتابخانه اصلی که عموما از آن استفاده میشود،Spacy -که یک کتابخانه پردازش زبان طبیعی سرعت بالاست- و Gensim که کتابخانه ای متمرکز بر روی کاربردهای مدلسازی مبتنی بر موضوع است میباشند.
مجموعه های از پیش آموزش دیده word embedding ، که با استفاده از تمامی محتویات ویکی پیدیا، یا تاریخچه اخبار گوگل ایجاد شده اند را میتوان بصورت مستقیم دانلود کرده و با مدلها و سامانه های خود ادغام کنید. علاوه بر این، شما میتوانید مدلهای خود را با استفاده از زبان پایتون و کتابخانه Genesis اموزش دهید. یک مدل سفارشی میتواند مدلهای استاندارد را در دامنه ها و لغت نامه های خاص پشت سر بگذارد.
کاربردهای word embedding :
word embedding ها در گستره زیادی از عملیات های مرتبط با پردازش زبان طبیعی مورد استفاده قرار میگیرند
- علاوه بر تکنیک های مدلسازی نظیر شبکه های عصبی مصنوعی، word embeddings بطرز شگفت آوری دقت دسته بندی متن را در بسیاری ازدامنه های نظری، سرویس مشتری، تشخیص هرزنامه، دسته بندی اسناد و… را بهبود داده است.
- word embedding برای بهبود کیفیت ترجمه زبانهای مختلف از طریق aligning single-language word embedding با استفاده از یک ماتریس تبدیل مورد استفاده قرار گرفته است. برای اطلاعات بیشتر میتوانید به اینجا نگاهی بیندازید.
- بردار کلمات همچنین جهت بهبود دقت در کاربردهای مبتنی بر جستجوی اسناد و بازیابی اطلاعات، که در آن تنظیمات جستجو نیازمند جستجوی کلید واژه های دقیق نیست و نسبت به املا نیز حساسیت ندارد استفاده شده اند.
لازم به ذکر است کاربردهای مبتنی بر بردار کلمات و بطور خاص Word2vec محدود به تجزیه جملات نبوده و چیزی فراتر از آن است. از آن میتوان بر روی گستره زیادی از داده ها همانند، ژن، سورس کد، پسندها در یک شبکه اجتماعی، playlist ها، گراف های شبکه های اجتماعی و سری های سمبولیک و… که میتوانند حاوی الگوهایی باشد، استفاده کرد.
این داده ها همانند متن دارای ماهیت یا عبارت بهتر حالات گسسته اند، و از این جهت ما میتوانیم همانند آنچه با متن انجام دادیم با آنها نیز انجام دهیم. بعنوان مثال ما میتوانیم به گذار احتمالات بین دو حالت دقت کنیم و ببینیم احتمال رخ دادن هریک به چه صورت است. بنابر این gene2vec، like2vec ،follower2vec و… مواردی از این دست همه قابل انجام هستند. این دید، بشما کمک خواهد کرد تا چگونگی ایجاد embedding های عصبی برای انواع مختلف داده را بخوبی درک کنید.
نکته :
بعضی ها قائل به این هستند که Word2Vec بعنوان یک الگوریتم معرفی نشه و برعکس بعنوان یک نرم افزار به اون نگاه بشه چرا که در درون خودش از دو الگوریتم مختلف (که بحثش رو بالا کردیم ) بهره میبره. اگر در متونی با لفظ برنامه word2vec یا نرم افزار word2vec مواجه شدید به این علت هست.
مطالعه بیشتر(منابع و مآخذ) :
شما میتوانید از پیوند های زیر برای تثبیت آنچه در اینجا یادگرفتید استفاده کنید :
- Coursera Deep Learning course video on Word Embeddings.
- Google Tensorflow Tutorial on Word Embeddings.
- Excellent break down for Skip-Gram algorithm.
- Chris McCormick – The Skip-Gram Model
- “The amazing power of word vectors” – Adrian Colye
- Get Busy with Word Embeddings – An Introduction
- (مجموعه ۵ بخشی)On word embeddings – Part 1 (خیلی خوبه)
مقالات :
The papers are:
- Efficient Estimation of Word Representations in Vector Space – Mikolov et al. 2013
- Distributed Representations of Words and Phrases and their Compositionality – Mikolov et al. 2013
- Linguistic Regularities in Continuous Space Word Representations – Mikolov et al. 2013
- word2vec Parameter Learning Explained – Rong 2014
- word2vec Explained: Deriving Mikolov et al’s Negative Sampling Word-Embedding Method – Goldberg and Levy 2014
در بخش بعد اگر فرصت شد انشاءالله شیوه کار با word2vec و embedding ها توسط چند کتابخونه معتبر انجام میشه.
جالب بود
مرسی
بسیار عالی و شفاف توضیح دادید. من مقالات انگلیسی زیادی در مورد word embedding خوندم و به اندازه ۷۰ درصد درکی که الان کسب کردم، رسیده بودم. واقعا خیلی شفاف و سلیس به زبان ساده توضیح دادید. بخصوص مثالهایی که بیان کرده بودید.
واقعا خدا قوت میگم.
امیدوارم کارهای بیشتری به این گونه از شما ببینیم.
فقط ترجمه بود هيچ مفهوم خاصي را در بر نداشت.شما که اين سايت را راه اندازي کرديد بايد جنبه آموزش تفهيمي را دنبال کند نه فقط يک سري مقاله را ترجمه کنيد بزاريد.به نظر من که هيچ ارزشي نداشت حداقل واسه من.
عالی بود با قدرت ادامه دهید
خیلی عالی بود من هر چی انگلیسی میخوندم نمیفهمیدم دستتون درد نکنه واقعا
آقای شهرام متاسفانه ما ایرانیا که هیچکدوم عرضه نداریم یک علم یا شاخه علمی یا حداقل یک صنعت جدید یا … را درست کنیم ، پس مجبوریم هر چی که دیگران میسازن را ترجمه کنیم و یاد بگیریم برای مثال از برق تا کامپیوتر و اتومبیل تا موبایل و همه چیزهای دیگه را غیر ایرانیها اختراع و ابداع کردن اما این دلیل نمیشه که حداقل کار با محصولات اونها را هم با استفاده از مقاله های خودشون یاد نگیریم ، پس مطالب آموزشی در هر کجای ایران و توسط هر کسی که نوشته بشه ترجمه + تجربه مترجم است و این یکی از بهترین ترجمه های ایرانیست که من تا حالا دیدم ، پس بهتره از همین ترجمه عالی هم متشکر باشیم تا عقب موندگیمون بیشتر از این نشه.
————————————————
من که خیلی از این سایت استفاده کردم دستتون درد نکنه ، عالیه
خیلی خیلی ممنون. منابع فارسی در این زمینه نداریم و این سایت کمک بسیار خوب و بزرگی می کند.
ازشما بسیار متشکرم.
واقعا عالی، خسته نباشید.
عالی بود بسیار ممنونم
با سلام خدمت مهندس حسن پور
مطالبی که توضیح دادید بسیار روان و عالی بود و بنده هیچ سایت فارسی رو ندیدم که به این شکل کار کرده باشند.
ان شاءالله که به کارتون ادامه بدید.
عالی و قابل فهم بود . ممنون که اطلاعات ارزشمندتون رو ب اشتراک میگذارید. سپاس فراوان
خیلی عالی بود
ممنون از اینکه واضح و کامل توضیح داده بودین، مخصوصا با مثال های خوب و ساده.
امیدوارم اینگونه مطالب باز هم منتشر بشن.
تشکر
کاربردش با پایتون رو مثال نیوردبد؟
سلام در سوال قبلیتون جواب دادم. انشاءالله در اولین فرصت قرار میگیرن.
ممنون از تنها منبع رسمی فارسی
مطالب شما برای من بسیار مفید بود. خداقوت و پرانرژی باشید برای تلاش های بیشتر.
بسیار عالی بیان کردید.
خصوصا مثالهای خوبی که آوردید به فهم مطالب کمک می کرد.بنده مقاله انگلیسی را خوانده بودم ولی درست متوجه نشده بودم.
انتهای متن هنوز یکم کار دارد تا واضحتر بیان شود.
متشکرم
بسیار عالی بود .
عالی و مفید بود. ممنون
اولین باره که تونستم تا حدودی مفهوم عبارت word embedding رو بفهمم. هرچی مقاله انگلیسی تا الان دیده بودم تا این حد نتونسته بود برای من قابل فهم باشه. خیلی ممنونم بسیار عالی بود