

بسم الله الرحمن الرحیم
بخش دوم آموزش در مورد Solver و پارامترهای مختلف اون هست.
توضیحات در مورد Solver
در Caffe ما با استفاده از solver ها, تنظیمات مختلف مربوط اجرای آموزش و آزمایش شبکه را مشخص میکنیم. تنظیماتی نظیر روش بهینه سازی (otpimization), نرخ یادگیری, momentum , تعداد تکرار آزمایشها (test iterations) و… در solver مشخص میشوند.وظایف یادگیری بین solver و شبکه تقسیم شده است به این صورت که کارهایی نظیر نظارت بر بهینه سازی و بروز آوری پارامترها مربوط به solver بوده و محاسبه خطا و مقادیر گرادیانت به عهده شبکه (مدل شبکه) میباشد. .
روش های بهینه سازی که قابل استفاده در Solver هستند را در زیر مشاهده میکنید:
|
1 2 3 4 5 6 7 8 |
Stochastic Gradient Descent (type: "SGD") AdaDelta (type: "AdaDelta") Adaptive Gradient (type: "AdaGrad") Adam (type: "Adam") Nesterov’s Accelerated Gradient (type: "Nesterov") RMSprop (type: "RMSProp") |
بطور کلی وظایف یک solver را میتوان در موارد زیر خلاصه کرد :
- . ساماندهی بهینه سازی و ایجاد شبکه آموزشی(training network) جهت یادگیری و همینطور ایجاد شبکه (های) آزمایشی(testing network(s)) جهت ارزیابی خروجی شبکه.
- انجام بهینه سازی با فراخوانی های پی در پی فازهای forward و backward و بروزآوری پارامترهای شبکه.
- ارزیابی (دوره ای ) شبکه .
- گرفتن snapshot از مدل شبکه و وضعیت solver در طی بهینه سازی.
در هر تکرار از عمل بهینه سازی, مراحل زیر اتفاق می افتند :
- فاز forward شبکه برای محاسبه خروجی و خطای شبکه فراخوانی میشود.
- فاز backward شبکه برای محاسبه گرادیانت ها فراخوانی میشود.
- گرادیانت ها در بروزآوری پارامترها با توجه به روش مشخص شده در solver اعمال میشوند.
- وضعیت solver با توجه به نرخ یادگیری , تاریخچه و روش مشخص شده بروز آوری میشود تا وزنها را از مقداردهی اولیه به مدل یاد گرفته شده منتقل کند.
Solver ها را نیز همانند مدلها با استفاده از CPU و یا GPU اجرا کرد.
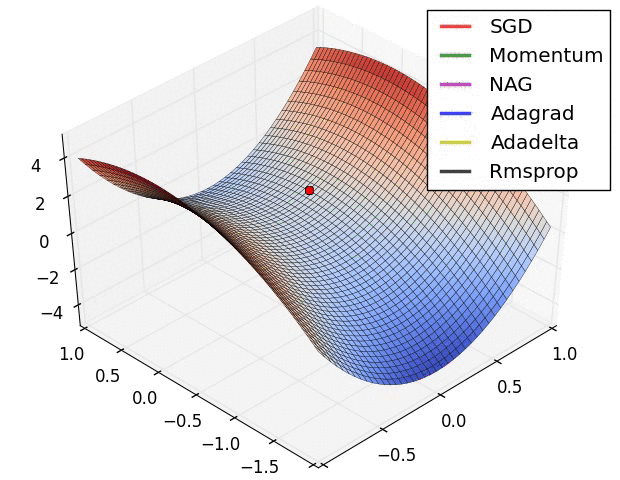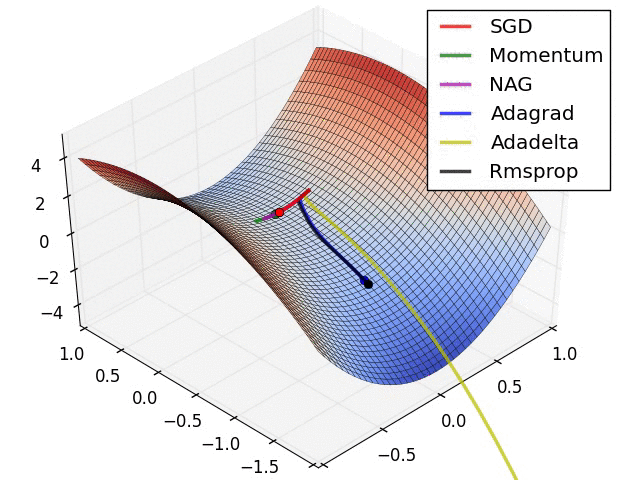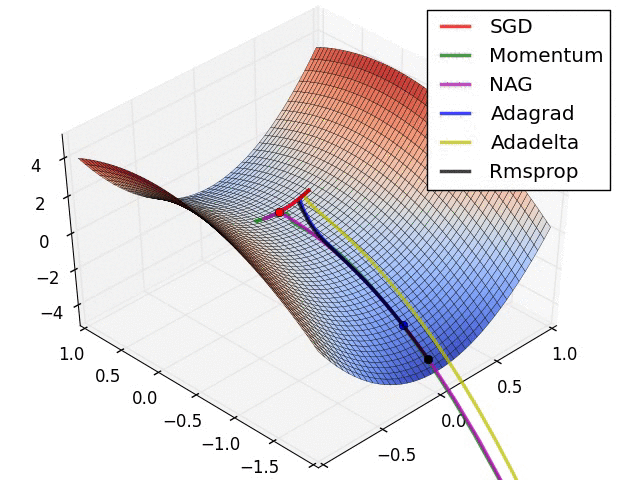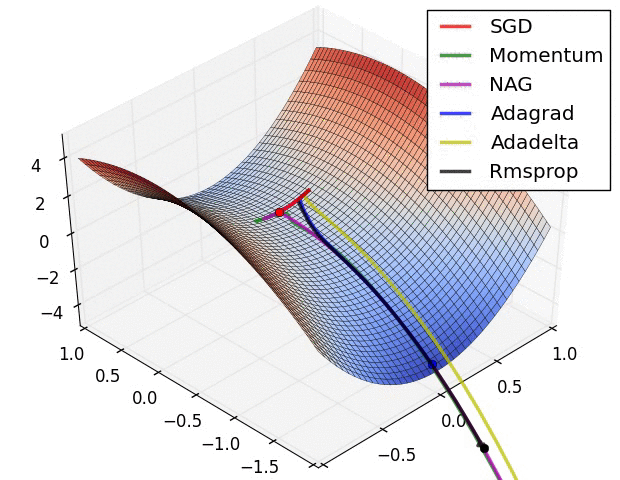
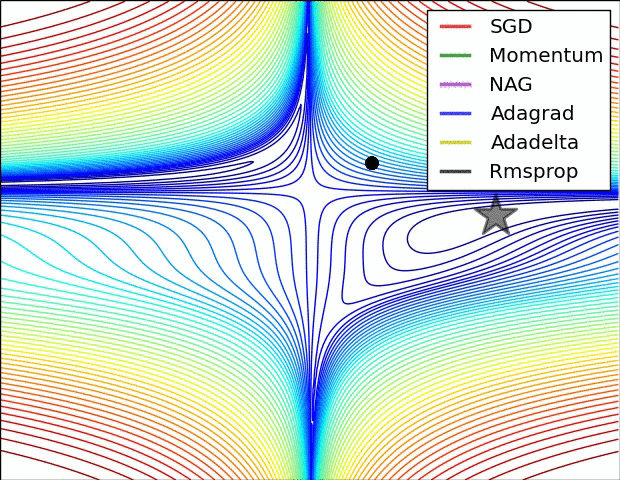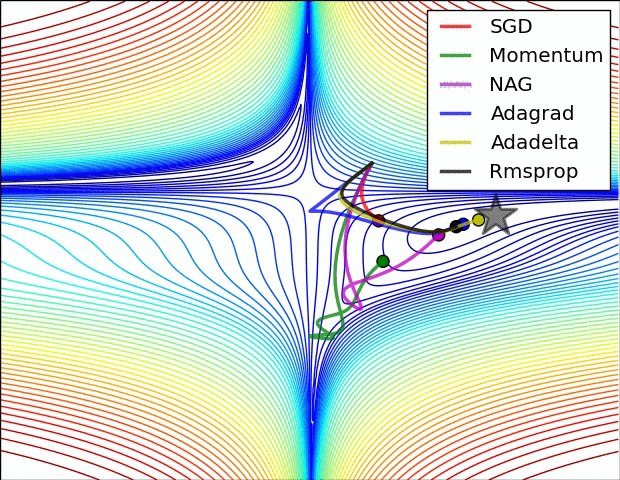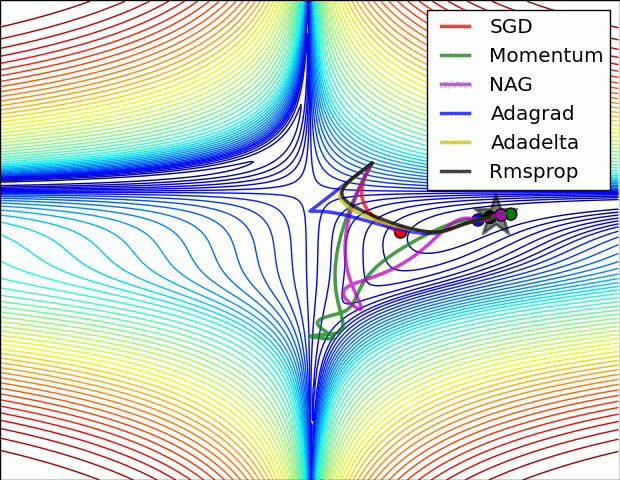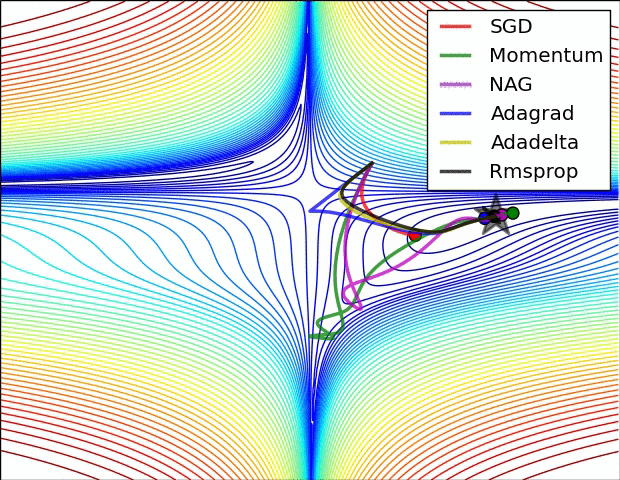
روشهای بهینه سازی
روشهای بهینه سازی که در Solver مشخص میشوند به مسائل بهینه سازی کلی کاهش خطا میپردازند. بعنوان مثال اگر فرض کنیم ما دارای دیتاست D باشیم ,هدف بهینه سازی میانگین گیری خطا از تمام |D|نمونه داده در این دیتاست است
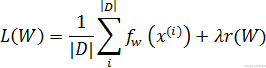
عبارتی که در بالا مشاهده میکنید همان عبارت محاسبه میانگین خطا است که در آن ![]() خطای نمونه داده
خطای نمونه داده ![]() بوده و
بوده و ![]() عبارت regularization است که دارای وزن
عبارت regularization است که دارای وزن ![]() میباشد. از آنجایی که |D| میتواند خیلی بزرگ باشد, در عمل, در هر تکرار solver , ما از تقریب تصادفی (stochastic approximation) این خطا استفاده میکنیم. برای اینکار بجای استفاده از تمام نمونه های دیتاست (|D|) ما از یک دسته کوچک(mini-batch) که تعداد نمونه هایی برابر با |N<<|D دارد (یعنی تعداد آن بمراتب بسیار کمتر از تعداد نمونه های موجود در دیتاست D است) را بصورت زیر استفاده میکنیم :
میباشد. از آنجایی که |D| میتواند خیلی بزرگ باشد, در عمل, در هر تکرار solver , ما از تقریب تصادفی (stochastic approximation) این خطا استفاده میکنیم. برای اینکار بجای استفاده از تمام نمونه های دیتاست (|D|) ما از یک دسته کوچک(mini-batch) که تعداد نمونه هایی برابر با |N<<|D دارد (یعنی تعداد آن بمراتب بسیار کمتر از تعداد نمونه های موجود در دیتاست D است) را بصورت زیر استفاده میکنیم :
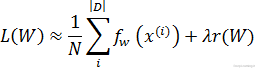
در اینجا مدل, ![]() را در forward pass محاسبه کرده و گرادیانت
را در forward pass محاسبه کرده و گرادیانت ![]() ∇ را نیز در backward pass محاسبه میکند. مقدار w∆ (آپدیت وزن) بوسیله solver از طریق گرادیانت خطای
∇ را نیز در backward pass محاسبه میکند. مقدار w∆ (آپدیت وزن) بوسیله solver از طریق گرادیانت خطای ![]() ∇ , گرادیانت regularization
∇ , گرادیانت regularization ![]() و سایر پارامترهای اختصاصی مربوط به روش مشخص شده در آن بدست می آید.
و سایر پارامترهای اختصاصی مربوط به روش مشخص شده در آن بدست می آید.
روش SGD
Stochastic gradient descent که با نوع”SGD” در solver قابل استفاده است ((type: “SGD”)) ) ماتریس وزن W را توسط ترکیب خطی منفی گرادیانت (L(W∇ و مقدار تغییرات وزن قبلی Vt بروز آوری میکند..مقدار نرخ یادگیری α برابر با وزن منفی گرادیانت و مقدار momentum μ برابر با وزن آپدیت قبلی است.
بطور کلی ما برای محاسبه مقدار جدید Vt+1 و وزنهای آپدیت شده ماتریس Wt+1 در تکرار t+1 با داشتن مقدار آپدیت قبلی Vt و ماتریس وزن فعلی Wt از عبارت زیر استفاده میکنیم :
![]()
![]()
احتمالا برای بدست آوردن بهترین نتایج ,فراپارامترهای α و μ نیازمند کمی تغییر هستند. اگر مطمئن نیستید که از چه مقداری شروع کنید, میتوانید به بخش قواعد کلی که در ادامه آمده است نگاهی بندازید. همچنین برای اطلاعات بیشتر در این زمینه میتوان به مقاله جامع Leon Bottou در این باره با نام [۱]Stochastic Gradient Descent Tricks مراجعه کرد.
قواعد کلی در باره تنظیم نرخ یادگیری (α) و momentum (μ)
یک روش خوب برای گرفتن نتایج بهتر با استفاده از روش SGD مقدار دهی نرخ یادگیری α حول مقدار α≈۰٫۰۱ =۱۰-۲ است و در صورتی که خطا شروع به افزایش کرد, کاهش مقدار آن در فاز آموزش با یک ضریب ثابت مثل ۱۰ و تکرار این روش برای چندین مرتبه است. بطور کلی , سعی کنید از momentum با مقدار μ=۰٫۹ یا مقداری مشابه آن استفاده کنید. با (هموار تر شدن)بهتر شدن آپدیت وزنها در طی تکرار های مختلف, momentum باعث سریعتر و پایدار تر شدن یادگیری عمیق با SGD شود.
روشی که تازه توضیح دادیم , روشی است که توسط Krizhevsky et al در مقاله معروف آنها در سال ۲۰۱۲ که مقام اول رقابت ILSVRC-2012 را با استفاده از شبکه های کانولوشنی برایشان به ارمغان آورد ارائه شده است.
اعمال تنظیمات فوق در Caffe با استفاده از solver ها بسیار راحت بوده و در ادامه ما با نحوه انجام این کار آشنا میشویم . برای استفاده از روشی که در بالا توضیح داده شد و تنظیم نرخ یادگیری خطوط زیر را بایستی به solver خود اضافه کنید.
|
1 2 3 4 5 6 7 8 |
base_lr: 0.01 lr_policy: "step" gamma: 0.1 stepsize: 100000 max_iter: 350000 momentum: 0.9 |
در خط اول مشخص میکنیم که آموزش با نرخ یادگیری ۰٫۰۱ شروع شود
در خط دوم سیاست نرخ یادگیری را مشخص میکنیم, در این قسمت ما مشخص کردیم که نرخ یادگیری طی گام هایی (steps)کاهش یابد. در ادامه بیشتر درمورد این گزینه صحبت میکنیم.
خط سوم , همان ضریب کاهش نرخ یادگیری است که در هر گام انجام میشود. در این قسمت است که مشخص میکنیم نرخ یادگیری با چه ضریبی کاهش پیدا کند. در اینجا ما مشخص کردیم که نرخ یادگیری با ضریب ۱۰ کاهش پیدا کند ( یعنی نرخ یادگیری در مقدار gama که مساوی ۰٫۱ است ضرب شود)
خط چهارم همان تعداد گام هایی است که نرخ یادگیری در آنها باید کاهش یابد. دراینجا این مقدار برابر با ۱۰۰هزار است. یعنی هر ۱۰۰ هزار تکرار, نرخ یادگیری را کاهش بده.
خط پنجم هم تعداد تکرار مراحل آموزش را مشخص میکند. در اینجا یعنی ۳۵۰ هزار بار آموزش را تکرار کن .
خط آخر نیز مقدار momentum را مشخص کرده است.
تحت تنظیمات بالا, ما همیشه از momentum با مقدار =۰٫۹ μ استفاده میکنیم. ما آموزش را با نرخ یادگیری پایه (base_lrا) α=۰٫۰۱=۱۰-۲ برای ۱۰۰ هزار تکرار اول شروع میکنیم و سپس نرخ یادگیری را با مقدار (gama (γ ضرب کرده و آموزش را با نرخ یادگیری ![]() برای ۱۰۰ هزار تکرار بعدی (۱۰۰-۲۰۰) ادامه میدهیم . به همین صورت برای تکرار های ۲۰۰ هزار تا ۳۰۰ هزار از نرخ یادگیری
برای ۱۰۰ هزار تکرار بعدی (۱۰۰-۲۰۰) ادامه میدهیم . به همین صورت برای تکرار های ۲۰۰ هزار تا ۳۰۰ هزار از نرخ یادگیری ![]() استفاده کرده و نهایتا از نرخ یادگیری
استفاده کرده و نهایتا از نرخ یادگیری ![]() برای تکرار های باقی مانده (۳۰۰ تا ۳۵۰ هزار) استفاده میکنیم .
برای تکرار های باقی مانده (۳۰۰ تا ۳۵۰ هزار) استفاده میکنیم .
لطفا دقت کنید که مقدار momentum یی که تنظیم میکنید اندازه اپدیت شما را بعد از تعداد زیادی تکرار آموزش با ضریب ![]() ضرب میکند. بنابر این اگر مقدار μ را افزایش دادید بهتر است مقدار α را نیز به همان نسبت کاهش دهید.
ضرب میکند. بنابر این اگر مقدار μ را افزایش دادید بهتر است مقدار α را نیز به همان نسبت کاهش دهید.
بعنوان مثال, فرض کنید مقدار momentum ما =۰٫۹ μ باشد. در اینصورت ما ضریبی آپدیتی برابر با ![]() داریم .یعنی مقدار آپدیت ما هرچه باشد در این ضریب ضرب خواهد شد. حال اگر مقدار momentum را به μ=۰٫۹۹ افزایش دهیم, ما با اینکار ضریب اندازه آپدیت را ۱۰۰ برابر افزایش داده ایم و باید α (اbase_lr) را با ضریب ۱۰ کاهش دهیم.
داریم .یعنی مقدار آپدیت ما هرچه باشد در این ضریب ضرب خواهد شد. حال اگر مقدار momentum را به μ=۰٫۹۹ افزایش دهیم, ما با اینکار ضریب اندازه آپدیت را ۱۰۰ برابر افزایش داده ایم و باید α (اbase_lr) را با ضریب ۱۰ کاهش دهیم.
همچنین دقت کنید که تنظیمات بالا تنها حکم راهنما را داشته و اینطور نیست که بهترین تنظیمات تحت هر شرایط و برای هر کاری باشند. اگر متوجه شدید که یادگیری شروع به بد شدن ( diverge) کرده است (بعنوان مثال مشاهده میکنید که مقادیر خطای شبکه و یا خروجی همگی Nan و یا inf میشوند و این مسئله هم بسیار زیاد دارد تکرار میشود) سعی کنید مقدار base_lr را کاهش دهید (مثلا مقداری برابر با base_lr: 0.001 ) و عمل آموزش را تکرار کنید. انقدر این عمل را تکرار کنید تا به base_lr برسید که عملا برایتان کار کند.
سیاست های نرخ یادگیری
در Caffe میتوان سیاست های مختلفی برای کاهش نرخ یادگیری لحاظ کرد. شما میتوانید در زیر لیستی از این سیاست ها و نحوه عملکرد آنها را مشاهده کنید.
- fixed : همیشه از base_lr استفاده میکند.(مقدار نرخ یادگیری ثابت است)
- : step نرخ یادگیری از رابطه ((base_lr * gamma ^ (floor(iter / step بدست می آید
- : exp نرخ یادگیری از رابطه base_lr * gamma ^ iter بدست می آید
- inv : نرخ یادگیری از رابطه (base_lr * (1 + gamma * iter) ^ (- power بدست می آید
- multistep : مثل step عمل کرده با این تفاوت که اجازه تعریف گامهای غیریکسان در stepvalue میدهد
- poly: در این روش ,نرخ یادگیری از یک کاهش چند جمله ای تبعیت کرده و با رسیدن به max_iter صفر میشود, نرخ یادگیری در این روش از رابطه (base_lr * (1 - iter/max_iter) ^ (power بدست می آید.
- sigmoid: در این روش ,نرخ یادگیری از یک کاهش سیگمویدی تبعیت کرده از رابطه ((((base_lr * ( 1/(1 + exp(-gamma * (iter - stepsizeبدست می آید
لطفا دقت کنید که در صورت انتخاب هر کدام از موارد فوق بعنوان lr_policy در solver , اطمینان حاصل کنید تمامی پارامترهای مورد نیاز آنها (مواردی که در رابطه آورده شده اند) را فراهم کنید. بعنوان مثال اگر قصد استفاده از poly را دارید باید پارامترهای base_lr , iter , max_iter و power را نیز فراهم کنید.
این سیاستها به همراه توضیحات هریک در فایل Caffe.proto که پیشتر توضیح دادیم قرار دارد و برای فهمیدن اینکه آیا سیاست جدیدی اضافه شده است یا خیر و یا مشاهده اینکه یک سیاست به چه صورت در caffe عمل میکند میتوان به این فایل مراجعه کرد.
روش AdaDelta
روش AdaDelta که با نوع”AdaDelta” در solver قابل استفاده است (type: “AdaDelta”) . یک روش مشخص سازی نرخ یادگیری قدرتمند است که توسط M.Zeiler ارائه شد. این روش هم همانند SGD یک روش بهینه سازی مبتنی بر گرادیانت بوده و فرمول بروز آوری آن بصورت زیر است :
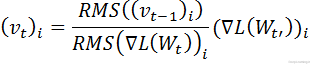
![]()
![]() و
و
![]()
AdaGrad
روش adaptive gradient که با نوع AdaGrad در solver قابل استفاده است (type: “AdaGrad”) یک روش بهینه سازی مبتنی بر گرادیانت است که توسط Duchi et al ارائه شد. این روش بقول Duchi سعی میکند سوزن را در انبار کاه پیدا کند! و این کار را با استفاده از ویژگی های بسیار قابل پیش بینی اما بندرت دیده شده انجام میدهد.
با داشتن اطلاعات بروز آوری از تمام تکرار های قبلی ![]() که در آن
که در آن ![]() ∋ t’ , فرمولی که توسط Duchi برای هر مولفه i از ماتریس وزن W ارائه شده است بصورت زیر میباشد
∋ t’ , فرمولی که توسط Duchi برای هر مولفه i از ماتریس وزن W ارائه شده است بصورت زیر میباشد
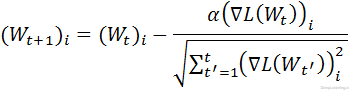
توجه کنید که در عمل, برای وزن های ![]() , روش AdaGrad بصورتی پیاده سازی میشود (خصوصا پیاده سازی که در Caffe وجود دارد) تا بجای اینکه از (O(dt فضای اضافی که برای ذخیره تک تک گرادیانتهای قبلی لازم است استفاده کند تنها به اندازه (O(d فضای اضافی برای اطاعات مربوط به گرادیانت های قبلی استفاده کند.
, روش AdaGrad بصورتی پیاده سازی میشود (خصوصا پیاده سازی که در Caffe وجود دارد) تا بجای اینکه از (O(dt فضای اضافی که برای ذخیره تک تک گرادیانتهای قبلی لازم است استفاده کند تنها به اندازه (O(d فضای اضافی برای اطاعات مربوط به گرادیانت های قبلی استفاده کند.
Adam
روش Adam که با نوع “Adam” در solver قابل استفاده است (type: “Adam”) یک روش بهینه سازی مبتنی بر گرادیانت است که توسط D.Kingma ارائه شد.این روش را میتوان تعمیمی از روش AdaGrad دانست که فرمول محاسبه آن در زیر آمده است :
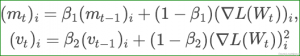 و
و
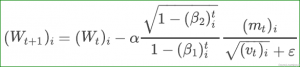
Kingma et al پیشنهاد کرد برای مقادیر ![]() ,
, ![]() و ε به ترتیب از مقادیر ۰٫۹ , ۰٫۹۹۹ و
و ε به ترتیب از مقادیر ۰٫۹ , ۰٫۹۹۹ و ![]() بعنوان مقادیر پیشفرض استفاده شود.در Caffe مقادیر momentum , momentum2 و delta به ترتیب معادل
بعنوان مقادیر پیشفرض استفاده شود.در Caffe مقادیر momentum , momentum2 و delta به ترتیب معادل ![]() ,
, ![]() و ε هستند.
و ε هستند.
NAG
روش Nesterov’s accelerated gradient که که با نوع “Nesterov” در solver قابل استفاده است (type: “Nesterov”) توسط Netsrov بعنوان یک روش مطلوب بهینه سازی convex ارائه شد. این روش قادر است بجای (O(1/t به نرخ همگرایی (![]() /O(1 دست پیدا کند. هرچند که فرضیات مورد نیاز برای دستیابی به (
/O(1 دست پیدا کند. هرچند که فرضیات مورد نیاز برای دستیابی به (![]() /O(1 معمولا در شبکه های عمیق آموزش داده شده توسط Caffe برقرار نمیشوند( بعنوان مثال بخاطر non-smothness و non-convexity ) اما در عمل روش NAG میتواند روش بسیار موثری برای بهینه سازی گونه های خاصی از معماری های deep learning همانند آنچه در deep MNIST autoencoders توسط Sutskever et al انجام شد, باشد.
/O(1 معمولا در شبکه های عمیق آموزش داده شده توسط Caffe برقرار نمیشوند( بعنوان مثال بخاطر non-smothness و non-convexity ) اما در عمل روش NAG میتواند روش بسیار موثری برای بهینه سازی گونه های خاصی از معماری های deep learning همانند آنچه در deep MNIST autoencoders توسط Sutskever et al انجام شد, باشد.
فرمولهای بروز آوری وزن بسیار شبیه آنچیزی است که در روش SGD ارائه شد. این فرمولها را در زیر مشاهده میکنید :
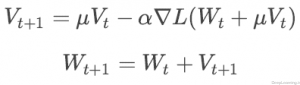
آنچیزی که باعث تمایز این روش با روش SGD میشود نحوه تنظیم ماتریس وزن W است که ما خطای گرادیانت (W)∇L را بر اساس آن محاسبه میکنیم. در روش NAG ما گرادیانت را از وزنهای جمع شده با momentum بدست می آوریم (![]() در حالی که در روش SGD ما خیلی ساده گرادیانت
در حالی که در روش SGD ما خیلی ساده گرادیانت ![]() را از روی خود وزنها بدست می آوریم.
را از روی خود وزنها بدست می آوریم.
RMSprop
روش RMSprop که با نوع “RMSProp” در Solver قابل استفاده است یک روش بهینه سازی مبتنی بر گرادیانت همانند SGD است توسط Tieleman در یکی از کلاسهای Coursera ارائه شد . فرمول محاسبه بروز آوری پارامترها را در زیر مشاهده میکنید:
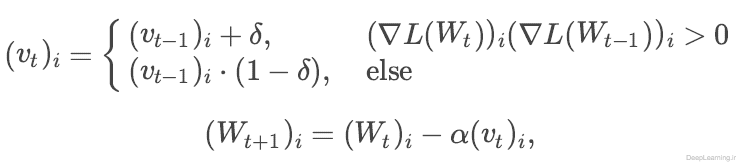
درصورتی که نتایج بروز آوری ها دارای نوسان باشد, گرادیانت با ضریب ۱-δ کاهش پیدا میکند. در غیر اینصورت به اندازه δ افزایش پیدا میکند. مقدار پیشفرض δ (اrms_decay) نیز برابر با δ=۰٫۰۲ میباشد.
Scaffolding یا قالب بندی
قالب بندی Solver روش بهینه سازی را آماده کرده و مدل را جهت شروع یادگیری مقدار دهی اولیه میکند. (با استفاده از Solver::Presolve() )
در زیر یک نمونه solver که در حال اجرا توسط Caffe است را مشاهده میکنید:
مرحله بهینه سازی : مقداردهی پارامترهای Solver :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
> caffe train ‐solver examples/mnist/lenet_solver.prototxt I0902 13:35:56.474978 16020 caffe.cpp:90] Starting Optimization I0902 13:35:56.475190 16020 solver.cpp:32] Initializing solver from parameters: test_iter: 100 test_interval: 500 base_lr: 0.01 display: 100 max_iter: 10000 lr_policy: "inv" gamma: 0.0001 power: 0.75 momentum: 0.9 weight_decay: 0.0005 snapshot: 5000 snapshot_prefix: "examples/mnist/lenet" solver_mode: GPU net: "examples/mnist/lenet_train_test.prototxt" |
در اینجا نیز شبکه در حال راه اندازی را مشاهده میکنید :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
I0902 13:35:56.655681 16020 solver.cpp:72] Creating training net from net file: examples/mnist/lenet_train_test.prototxt [...] I0902 13:35:56.656740 16020 net.cpp:56] Memory required for data: 0 I0902 13:35:56.656791 16020 net.cpp:67] Creating Layer mnist I0902 13:35:56.656811 16020 net.cpp:356] mnist ‐> data I0902 13:35:56.656846 16020 net.cpp:356] mnist ‐> label I0902 13:35:56.656874 16020 net.cpp:96] Setting up mnist I0902 13:35:56.694052 16020 data_layer.cpp:135] Opening lmdb examples/mnist/mnist_train_lmdb I0902 13:35:56.701062 16020 data_layer.cpp:195] output data size: 64,1,28,28 I0902 13:35:56.701146 16020 data_layer.cpp:236] Initializing prefetch I0902 13:35:56.701196 16020 data_layer.cpp:238] Prefetch initialized. I0902 13:35:56.701212 16020 net.cpp:103] Top shape: 64 1 28 28 (50176) I0902 13:35:56.701230 16020 net.cpp:103] Top shape: 64 1 1 1 (64) [...] I0902 13:35:56.703737 16020 net.cpp:67] Creating Layer ip1 I0902 13:35:56.703753 16020 net.cpp:394] ip1 <‐ pool2 I0902 13:35:56.703778 16020 net.cpp:356] ip1 ‐> ip1 I0902 13:35:56.703797 16020 net.cpp:96] Setting up ip1 I0902 13:35:56.728127 16020 net.cpp:103] Top shape: 64 500 1 1 (32000) I0902 13:35:56.728142 16020 net.cpp:113] Memory required for data: 5039360 I0902 13:35:56.728175 16020 net.cpp:67] Creating Layer relu1 I0902 13:35:56.728194 16020 net.cpp:394] relu1 <‐ ip1 I0902 13:35:56.728219 16020 net.cpp:345] relu1 ‐> ip1 (in‐place) I0902 13:35:56.728240 16020 net.cpp:96] Setting up relu1 I0902 13:35:56.728256 16020 net.cpp:103] Top shape: 64 500 1 1 (32000) I0902 13:35:56.728270 16020 net.cpp:113] Memory required for data: 5167360 I0902 13:35:56.728287 16020 net.cpp:67] Creating Layer ip2 I0902 13:35:56.728304 16020 net.cpp:394] ip2 <‐ ip1 I0902 13:35:56.728333 16020 net.cpp:356] ip2 ‐> ip2 I0902 13:35:56.728356 16020 net.cpp:96] Setting up ip2 I0902 13:35:56.728690 16020 net.cpp:103] Top shape: 64 10 1 1 (640) I0902 13:35:56.728705 16020 net.cpp:113] Memory required for data: 5169920 I0902 13:35:56.728734 16020 net.cpp:67] Creating Layer loss I0902 13:35:56.728747 16020 net.cpp:394] loss <‐ ip2 I0902 13:35:56.728767 16020 net.cpp:394] loss <‐ label I0902 13:35:56.728786 16020 net.cpp:356] loss ‐> loss I0902 13:35:56.728811 16020 net.cpp:96] Setting up loss I0902 13:35:56.728837 16020 net.cpp:103] Top shape: 1 1 1 1 (1) I0902 13:35:56.728849 16020 net.cpp:109] with loss weight 1 I0902 13:35:56.728878 16020 net.cpp:113] Memory required for data: 5169924 |
بخش خطا و اتمام آماده سازی شبکه:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
I0902 13:35:56.728893 16020 net.cpp:170] loss needs backward computation. I0902 13:35:56.728909 16020 net.cpp:170] ip2 needs backward computation. I0902 13:35:56.728924 16020 net.cpp:170] relu1 needs backward computation. I0902 13:35:56.728938 16020 net.cpp:170] ip1 needs backward computation. I0902 13:35:56.728953 16020 net.cpp:170] pool2 needs backward computation. I0902 13:35:56.728970 16020 net.cpp:170] conv2 needs backward computation. I0902 13:35:56.728984 16020 net.cpp:170] pool1 needs backward computation. I0902 13:35:56.728998 16020 net.cpp:170] conv1 needs backward computation. I0902 13:35:56.729014 16020 net.cpp:172] mnist does not need backward computation. I0902 13:35:56.729027 16020 net.cpp:208] This network produces output loss I0902 13:35:56.729053 16020 net.cpp:467] Collecting Learning Rate and Weight Decay. I0902 13:35:56.729071 16020 net.cpp:219] Network initialization done. I0902 13:35:56.729085 16020 net.cpp:220] Memory required for data: 5169924 I0902 13:35:56.729277 16020 solver.cpp:156] Creating test net (#0) specified by net file: examples/mnist/lenet_train_test.prototxt |
پایان قالب بندی solver یا (solver scaffolding)
|
1 2 3 4 |
I0902 13:35:56.806970 16020 solver.cpp:46] Solver scaffolding done. I0902 13:35:56.806984 16020 solver.cpp:165] Solving LeNet |
اطلاعات بسیار خوبی رو میتونید در مورد روشهای مختلفی که بالا مطرح شد (و نشد!) و کارایی هر کدوم نسبت به بقیه ببینید : An overview of gradient descent optimization algorithms (با تشکر از آقای درخشانی عزیز)
بخش بعدی اینترنفیس های Caffe و نحوه اجرای اون
[۱] [۱] L. Bottou. Stochastic Gradient Descent Tricks. Neural Networks: Tricks of
the Trade: Springer, 2012.
[…] بخش بعدی : fine-tuning بخش قبلی : تنظیمات Solver […]
سلام و خسته نباشید 🙂
اول خیلی خیلی ممنون از شما بابت تمام مطالبی که نوشتین، ی سوال داشتم از خدمتتون :
در رابطه با روش بهینه سازی منظورم L(w) هست، امکانش هست بیشتر توضیح بفرمایید؟ درست متوجه نشدم
باتشکر فراوان
سلام
خواهش میکنم . منظورتون کدوم بخشش هست ؟
همون بخش اول جایی که L(w) رو فرمولش رو نوشتین
سلام
خلاصه داره میگه فرض کنید شما یه دیتاست دارید با اندازه D یعنی تعداد نمونه های شما D تاس. قصد شما هم اینه که میانگین loss رو بدست بیارید برای کل دیتاست (یعنی تمام D نمونه). فرمولش میشه فرمول اول. تو فرمول اول هم یه loss از مرحله forward propagation داریم (یعنی همون مرحله اول) و یکی هم مربوط به مقدار regularization هست.
حالا در عمل اتفاقی که می افته اینه که اندازه دیتاست ها خیلی بزرگه و اینطور عمل کردن اصلا بهینه نیست بجای اینکه بیاییم میانگین رو روی کل اقلام بگیریم میاییم تقریبی از اون رو استفاده میکنیم . یعنی میاییم از mini-batch ها که اندازه اشون خیلی کمتر از اندازه کل دیتاست هست استفاده میکنیم .
(برای همین در عمل هرچقدر اندازه بچ شما بزرگتر باشه در اصل تقریب بهتری بدست میارید و گرادیانت استیبل تری بدست میاد.)
خیلی خیلی ممنون
سلام
خیلی خوب بود ممنون از لطفتون
ببخشید ی جاهایی خوب جا نیفتاد برام دوباره مزاحمتون شدم
۱-ببخشید در فرمول دوم که نوشته به جای |D| از N نمونه استفاده میکنیم بالای سیگما نباید N باشه؟
۲-ببخشید من این iteration رو تو حتی الگوریتمهای بهینه سازی(مثل ژنتیک) هم متوجه نمیشم اینجا منظرتون اینه که یه دیتاست داریم میاد ۳۵۰هزارتا ۳۵۰هزار (max_iter) تقسیم میکنه بعد هر ۱۰۰ هزار تا با یه نرخ یادگیری آموزش میده دوباره ۳۰۵هزارتای بعدی از اول ؟
۳-ممکنه momentum μ رو یکم بیشتر درموردش توضیح بدید که چیه و چه کارایی داره؟(یه جا نوشته شده فراپارامتره بعد تو اون اشکال سه بعدی که بهینه سازها هستن اینم هست)
۴- weight decay یا تنزل وزن چیه ؟ و چه کارایی داره؟
۵- تو تعریف solver یکی دوتا متوجه شدم (فکر کنم test_iter تعداد تکرار تسته و test_interval هم یعنی بعد از این تعداد train تست رو انجام بده) ولی دوتاشو هم نفهمیدم مثل display و power اگر ممکنه بگید چیه (snapshot هم فکر کنم تو بخش بعد توضیح دادید)
۶-آخرین و مهمترین سوالم
تو متن روش های بهینه سازی گفته شده و گفته تو solver تعین میکنیم که از کدوم روش استفاه میکنیم سوالم اینه کجای solver روش بهینه سازی تعیین میشه ؟ (تو مثالی که از solver آوردید نوع بهینه سازی گفته نشده)
ببخشید سوالهام طولانی بود
آقای حسن پور عزیز ممنون از لطفتون که اینقدر با صبر و حوصله جواب میدید خودم میدونم سوالهام یکم طولانیه هروقت که وقتش رو داشتید جواب بدید
ممنونم
سلام
۱٫بله
۲٫در شبکه عصبی ما مفهوم ایپاک رو داریم که اشاره به مرور یکباره کل داده های اموزشی هست. این مرور ممکنه چندین تکرار رو شامل بشه.
در کفی بعنوان مثال ما با مفهوم ایپاک کار نمیکنیم این مفهوم مستتر هست. ما با ایتر یا تعداد تکرار سرو کار داریم . که توضیحش رو فکر میکنم در اموزش کفی دادم . اون بخشها رو بخونید متوجه میشید . (خلاصه این هست چون دیتا زیاده ما خورد خورد داده ها رو پردازش میکنیم . مثلا ۱۰ تا عکس داریم. هر بار دوتا عکس با هم پردازش میشه . ۵ بار تکرار باید بشه تا تمام عکسا پردازش بشن . این ۵ میشه تعداد ایتر. حالا اگه شما ۲۰ تکرار مشخص کنید یعنی ۴ بار تمام دیتا رو مرور کردید (به شبکه ارایه کردید) . یعنی ۵ ایپاک اموزش انجام دادید. باز دوباره این یعنی هر ایپاک برابر با ۵ تکرار هست)
۳.لطفا یه کتاب شبکه عصبی رو بگیرید بخونید. این چیزا جزو مبانی این کار هست .مومنتوم رو بصورت خیلی خلاصه و خیلی ساده یه ضریب در نظر بگیرید که هرجهتی انتخاب شد در اون ضرب میشه. اگه نتیجه خوب باشه همگرایی شما و رسیدن به جواب سریعتر و اگر بد باشه برعکس دنده عقب میرید به طرف بدتر شدن. مومنتوم خصوصا برای زمانهایی که در سطوح مسطح گرفتار میشید خیلی خوبه چون باعث میشه سریعتر این نقاط پشت سر گذاشته بشن. این دیگه خیلی خیلی ساده و مختصر بود.
۴.یکی از روشهای اصطلاحات regularization هست که برای جلوگیری از اورفیتینگ ازش استفاده میشه
۵.اینا تو اموزش توضیحشون داده شده . اون بخشها رو ملاحظه کنید متوجه میشید
۶.lr_policy که مخفف همون learningrate-policy هست. مشخص میکنه که نرخ یادگیری شما چطور کاهش/تغییر پیدا بکنه . انواع مختلفی هم داره.که در بخش سالور توضیحات کاملش داده شده.
۷٫ type مشخص کننده نوع بهینه سازی هست .جلوی این هرچی بنویسید به معنای انتخاب سیاست یادگیری شماست.مقادیری مثل SGD یا AdaDelta یا AdaGrad یا inv و… اینم در بخش سالور اومده اگر خوب بخونید
سلام
بی نهایت ممنونم
ببخشید ببینید ایتر رو درست متوجه شدم
مثلا ۱۰۰۰ نا عکس داریم و base_lr: 0.01 ، lr_policy: “step” ، gamma: 0.1 ، stepsize: 100000 ، max_iter: 350000 (همین مثال خودتون)
فرض کنید هر ۱۰۰ تا عکس با هم پردازش میشن پس ده تا دسته عکس داده میشه به شبکه
پس ۱۰ تا ایتر طول میکشه تا کل دیتاست پردازش بشه و با توجه به تعداد گام ۱۰۰۰ دفه هر عکس با یک ضریب یادگیری ثابت تکرار میشه بعد میره سراغ ضریب یادگیری بعدی و باز این کار تکرار میشه تا ۳۵۰هزار تکرار
درست متوجه شدم ؟ حالا فرق iter و max_iter چیه ؟
ببخشیددرمورد سوال ۶ در پیام قبل مگه lr_policy سیاست تغییرات نرخ یادگیری رو تعیین نمیکنه ؟ (مثلا inv ) سیاست بهینه سازی مثلا (SGD) کجا تعین میشه ؟
نمیدونم شایدم من اشتباه برداشت کردم
لطفا این سوالها رو در بخش پرسش و پاسخ بپرسید
۱۰ ایتر باید طی بشه که به یک ایپاک برسید.
تعداد گام شما ۳۵۰ هزار تاست که با max_iter مشخص کردید. یعنی ۳۵ هزار ایپاک . stepsize مشخص کننده زمان تغییر نرخ یادگیری هست.
شما دارید میگید هر ۱۰۰ هزار تکرار مقدار گاما رو در base_lr ضرب کن و از نتیجه حاصل بعنوان نرخ یادگیری جدید استفاده کن. به عبارت بهتر تا ۱۰۰ هزار تکرار اول نرخ یادگیری شما ۰.۱ هست. از ۱۰۰ هزار تا ۲۰۰ هزار نرخ یادگیری شما میشه ۰٫۰۰۱ از ۲۰۰ هزار تا ۳۰۰ هزار میشه ۰٫۰۰۰۱ و از ۳۰۰ هزار تا ۳۵۰ هزار هم میشه ۰٫۰۰۰۰۱ .
iter جدا نداری. test_iter داریم و interval_iter که بالا توضیحاتشون داده شده.
سیاست بهینه سازی به کل پارامترها اطلاق میشه .
من یه اشتباهی کردم و تازه یادم اومد.اصلا حواسم نبود. lr_policy سیاست تعیین نرخ یادگیری هست که مشخص میکنه نرخ یادگیری چطوری کاهش یا تغییر پیدا کنه . برای مشخص کردن سیاست بهینه سازی هم از type میتونید استفاده کنید. که بالا در بخش سالور توضیحات هر دوی اینا کامل اومده.
شما بجای inv میتونید از SGD و بقیه موارد هم استفاده کنید. اگه چیزی برای type مشخص نکنید پیشفرض SGD در نظرگرفته میشه)
ممنون
ببخشید من الآن دیدم که گفتید سوالامها رو دربخش پرسش و پاسخ بپرسم چشم
ممنون
سلام و وقت بخیر
لطفا جمله زیر را که در متن به صورت ناقص آمده تصحیح نمایید .
“بعنوان مثال, فرض کنید مقدار momentum ما =۰٫۹ μ باشد. در اینصورت ما ضریبی آپدیتی برابر با داریم .”
برابر با چی؟؟؟؟؟؟؟؟؟؟؟؟؟
متشکرم
سلام
برابر ۱۰ هست.
چون فرمولها به تصویر تبدیل شده بودند این یکی جا موند.
خیلی ممنون که اطلاع دادید
سلام
من توضیحاتی در مورد “اهمیت مقدار دهی اولیه و ممنتوم در یادگیری عمیق” میخوام
سلام .
اهمیت مقداردهی اولیه قبلا خیلی زیاد بود قبل از معرفی بچ نرمالیزیشن اما الان به همین خاطر به اندازه و شدت قبل نیست
مومنتوم هم داستانش مثل همون شبکه عصبی متداول و سنتی هست و همگرایی رو تسریع میکنه خصوصا در مواجهه با saddle point ها .
اگه اطلاعات بیشتر و عینی تر میخوایید علاوه بر اینکه میتونید سرچ کنید و مطالب زیادی بدست بیارید میتونید آموزش ویدئویی دانشگاه استنفورد رو ببینید فکر میکنم جلسه ۴ یا پنجمش که در مورد relu ها صحبت میکنه
در مورد مقداردهی اولیه و اهمیت اون هم توضیحاتی میده و اینکه چرا مهم بوده.
با سلام
میشه لطف کنید مفهوم test interval و test_iter رو توضیح بدیم من هیج جا تو آموزش هاتون اینا رو ندیدم
سلام .
من اونو تو بخش پنجم آموزش اوردم و توضیح دادم : بخش پنجم آموزش عملی
در بخش پرسش و پاسخ هم سوالات مختلف شده و جواب دادم یه سرچ کنید مشخص هست
فکر کنم test_iter تعداد تکرار تسته و test_interval هم یعنی بعد از این تعداد train تست رو انجام بده درست میگم یا نه ؟
سلام
در فرمول Adam بتا به توان t رسیده این t چی هست؟؟؟؟؟