
بسم الله الرحمن الرحیم
بعد از مدتها خدا رو شکر فرصتش پیش اومد تا بتونم مطالبی که در مورد RNN ها (و همینطور موارد دیگه) قبلا نوشته بودم ویرایش کنم و در سایت منتشر کنم. چند پست مختلف به این کار اختصاص پیدا میکنه که انشاءالله خواهید دید. در این بخش ایده معرفی شبکه های عصبی بازگشتی و یکسری موارد مرتبط با اونها مثل مفاهیم پردازش زبان طبیعی (متن و…) هست که تا بحال در سایت قرار نگرفته بودن و وجودشون احساس میشد. شیوه بیان مطالب به این صورته که در این بخش من یکسری کلیات رو بیان میکنم و در هر پست(بعدی) موارد و جزییات رو بیشتر بیان میکنم تا اینطور همه مطالب تحت یک پست بزرگ و طویل نباشه مثل مطالب سابق. بگذریم این آموزش طی چند بخش ارائه خواهد شد و موارد زیر را در بر خواهد گرفت :
- معرفی و پیاده سازی کامل شبکه عصبی بازگشتی RNN (سنتی، GRU و LSTM )
- Embedding
- attention models
- شیوه کار با پای تورچ /تنسورفلو کراس
- اگر فرصت کنم : پردازش صوت/تصویر
نکته:
قبل از شروع به بحث ذکر این نکته ضروریست که فقط مورد استفاده ما زبان و پردازش زبان و مشتقات آن نیست. در RNN ما با انواع مختلف داده ها میتوانیم کار کنیم . تصویر ،متن ،صوت و …. نمونه هایی از این دست هستند . در ادامه ما آموزش اولیه در حوزه پردازش زبان طبیعی را خواهیم داشت و به بیان مبانی شبکه های عصبی در این حوزه میپردازیم و سپس شیوه کار با سایر داده ها را مورد بررسی قرار میدهیم. مفاهیمی که در این آموزش بیان میشود برای سایر کاربردها هم قابل استفاده است.
نکته دوم :
نگران ارائه برخی مباحث ریاضی در این آموزش نباشید. اگر بحثی را متوجه نشدید ادامه بدهید در بخشهای بعدی ما با زبان ساده همه موارد رو مرور میکنیم.
مقدمه :
بخش عظیمی از داده ها همانند گفتار (speech), داده های مبتنی بر زمان یا اصطلحا سری های زمانی ( time series) (مثل داده های پیش بینی هوا داده های مالی و …) داده های دریافتی از سنسورها, ویدئوها, متن ها و… ماهیتا بصورت سریال/سری( sequential) اند. شبکه های عصبی بازگشتی (یا به اختصارRNN) خانواده ای از شبکه های عصبی اند که بطور ویژه جهت پردازش داده های سری(یا دنباله ها) طراحی شده اند. در این نوشتار ما به بحث در مورد RNNها خواهیم پرداخت و از طریق بررسی نقاط منحصر به فرد در فهم متن, بازنمایی و تولید آن با RNNها اشنا خواهیم شد.
برای شروع اجازه دهید کارمان را با یک سوال آغاز کنیم, ما میدانیم درصورتی که بتوانیم به شیوه ای کامپیوترها را قادر به درک زبان طبیعی کنیم به چه فواید بی شماری دست خواهیم یافت. اما واقعا اینکه یک ماشین قادر به فهم زبان طبیعی باشد به چه معناست؟
روشهای مختلفی برای جواب دادن به این سوال وجود دارد اما شاید یکی از این پاسخ ها را بتوان با نگاه به یکی از خواسته های اصلی ما از این ویژگی اینطور بیان کرد که یکی از توانایی هایی که ما از چنین ماشینی انتظار داریم این است که بتواند بما بگوید چقدر یک جمله داده شده محتمل است. در این روش ما فرض میکنیم که رخداد یک جمله را میتوان از طریق استفاده از زبان روزمره مشخص کرد. پس بعبارت دیگر:
مدلهای زبان طبیعی (یا اصطلاحا Natural Language Models) تلاش دارند تا مشکل مشخص کردن احتمال یک جمله در دنیای واقعی را حل کنند.
گرچه ممکن است این مساله چندان با اهمیت جلوه نکند اما این نوع مدلسازی یکی از زیربناهای اساسی جهت درک زبان طبیعی و وظیفه ای حیاتی در پردازش زبان طبیعی است. زمانی که ما چنین سامانه ای را در اختیار داشته باشیم میتوانیم از آن جهت تولید متن جدید با نتایج شگفت انگیزی استفاده کنیم. زمانی که ما به این مدل مجهز باشیم میتوانیم دیدهای مهمی نسبت به سایر وظایفی همچون ترجمه ماشینی و تولید محاوره بدست آوریم.
واحدهای زبانی :
احتمالا همه ما بر روی این اصل که یک جمله را میتوان بصورت یک دنباله درنظر گرفت اتفاق نظر داریم. اما دنباله ای از چه چیز؟ دنباله ای از حروف یا کلمات ؟ یا شاید هم چیزی مابین این دو؟ پاسخ به این سوال هنوز بعنوان یک موضوع تحت تحقیق مستمر شناخته میشود و اجماعی بر روی اینکه چه چیزی واحد پایه در یک زبان نگارشی را تشکیل میدهد وجود ندارد. به همین دلیل در این نوشتار فعلا ما از کلمات بعنوان واحد زبانی خود استفاده میکنیم.(در بخش بعد ما از حروف بعنوان واحد زبان نیز استفاده خواهیم کرد تا با هر دو حالت کار کرده باشیم.)
در این بخش ما ابتدا سعی خواهیم کرد تا اصول اولیه مدلهای زبانی را فرا گرفته و بدانیم شبکه های عصبی بازگشتی چیستند و چگونه میتوانیم از آنها جهت حل مساله مدلسازی زبان استفاده کنیم. سپس تلاش خواهیم کرد تا دلیل کار کردن این روش و همچنین چگونگی عمل کردن و تعمیم آن را درک کنیم. سرانجام نیز به ارائه توضیحی در مورد چگونگی درکنار هم قرار دادن تمامی این ابزارها جهت تولید متن بصورت خودکار اقدام خواهیم کرد.
از آنجایی که این نوشتار قرار است مقدمه ای بر فهم زبان طبیعی و تولید متن باشد, اکثر جزییات پیاده سازی و عملی را در نوشتارهای بعدی خواهیم دید که بیشتر ماهیت عملی در تولید متن به روشهای گوناگون دارد.
مدلهای زبانی در سطح کلمه (Word Level Language Models) :
اکنون ما میتوانیم ایده های خود را فرموله کنیم .اگر یک جمله  را که از
را که از  کلمه تشکیل شده است بصورت زیر در نظر بگیریم
کلمه تشکیل شده است بصورت زیر در نظر بگیریم

هر  بخشی از یک لغت نامه ( یا اصطلاحا vocabulary)
بخشی از یک لغت نامه ( یا اصطلاحا vocabulary)  خواهد بود که این لغت نامه شامل تمامی کلمات ممکن میباشد :
خواهد بود که این لغت نامه شامل تمامی کلمات ممکن میباشد :

و  نیز در اینجا نمایانگر اندازه لغت نامه است.
نیز در اینجا نمایانگر اندازه لغت نامه است.
اگر م بخواهیم احتمال یک جمله را محاسبه کنیم میتوانیم از قانون زنجیره حسابان برای بدست اوردن احتمال بصورت زیر:
![\[p(S) = p(x_1 , x _2 , ... , x _T) = p(x _1) \cdot p(x _2 | x _1) \cdot p(x _3 | x _2, x _1) \cdot \cdot \cdot p(x _T | x _{T-1}, x _{T-2}, ..., x _1 )\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-0946cd55664f89e22d64b5c3f58a5722_l3.png "Rendered by QuickLaTeX.com")
یا فرم مختصر تر آن
![\[p(S) = \prod_{t=1}^T p(x _t | x _{< t})\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-9d8a1b10529fe16b8ad3461f638a5d34_l3.png "Rendered by QuickLaTeX.com")
بهره ببریم. که در آن  اشاره به تمامی کلمات قبل از زمان
اشاره به تمامی کلمات قبل از زمان  دارد.
دارد.
احتمال یک کلمه در زمان وابسته به کلمات قبلی آن جمله است. به منظور محاسبه احتمال یک جمله ما تنها نیاز داریم تا تک تک عبارات  را محاسبه نموده و آنها را در هم ضرب کنیم .
را محاسبه نموده و آنها را در هم ضرب کنیم .
یک مدل زبانی , بطور کل, تلاش میکند تا کلمه بعدی  را با توجه به کلمات قبلی ارایه شده در هر گام زمانی پیش بینی کند.
را با توجه به کلمات قبلی ارایه شده در هر گام زمانی پیش بینی کند.
شبکه های عصبی بازگشتی (RNNs) چیستند؟:
شبکه های عصبی بازگشتی در سال ۱۹۸۰ ایجاد شدند اما تنها در چند سال اخیر بوده است که این گونه از شبکه ها بطور گسترده مورد استفاده قرار گرفته اند. از دلایل عمده وقوع چنین رخدادی میتوان به پیشرفت های صورت گرفته در طراحی شبکه های عصبی بطور عام و بهبود چشمگیر قدرت محاسباتی و بطور ویژه بهره وری از قدرت واحدهای پردازش موازی کارتهای گرافیک اشاره نمود. این گونه از شبکه های عصبی بطور خاص برای پردازش داده های سری یا دنباله دار مفید هستند و در آن ها هر نورون یا واحد پردازشی قادر به حفظ حالت داخلی یا یا همان حافظه به منظور حفظ اطلاعات مرتبط با ورودی قبلی میباشد. این ویژگی بطور ویژه در کاربردهای مختلف مرتبط با داده های سری اهمیت اساسی پیدا میکند. بطور مثال در پردازش زبان طبیعی, جمله ای همانند “I had washed my car” معنای متفاوتی از جمله I had my car washed دارد. در این دو جمله همه کلمات یکسان هستند اما معنای مترتب با هرکدام کاملا متفاوت است. در جمله اول ما میگوییم “من خودروی سواری خود را شسته ام” در حالی که در جمله دوم ما با جمله “دستور دادم تا خودروی سواری ام شسته شود(فرد یا گروه دیگری با دستور من خودرو سواری را شستند (استخدام شدند یا من به آنها دستور دادم در هر حالت “دیگرانی” خودروی مرا شسته اند”.
این ویژگی حفظ حالت درونی یا همان قابلیت حافظه به شبکه کمک میکند تا قادر به فهم و کشف ارتباط بین لغات مختلف در دنباله های طولانی تر باشد. لازم به ذکر است که ما انسان ها نیز زمانی که یک جمله را میخوانیم با توجه به زمینه محتوایی که هر کلمه در آن قرار گرفته است معنای آن را استنباط میکنیم . به عبارت بهتر با توجه به کلمات قبلی و (در بعضی موارد حتی بعدی) زمینه محتوایی را استباط کرده و با توجه به آن معنای یک کلمه را درک میکنیم .
ایده اصلی پشت این نوع از معماری بهره برداری از این ساختار سری داده است. نام این شبکه عصبی از این واقعیت بدست می آید که این نوع از شبکه ها بصورت بازگشتی عمل میکنند. یعنی یک عملیات برای تک تک المانهای یک دنباله (کلمه،جمله،…) انجام میگیرید و خروجی آن وابسته به ورودی فعلی و عملیاتهای قبلی است. این مهم از طریق تکرار یک خروجی از شبکه در زمان با ورودی شبکه در زمان  انجام میشود.(یعنی خروجی از مرحله قبل با ورودی تازه در مرحله جدید ترکیب میشوند.) این چرخه ها اجازه وجود اطلاعات از یک گام زمانی به گام زمانی بعدی را موجب میشوند. بعبارت بهتر این نوع شبکه ها دارای حلقه ای در درون خود اند که بوسیله آن میتوانند اطلاعات را در حین خواندن ورودی از نورونها عبور دهند.
انجام میشود.(یعنی خروجی از مرحله قبل با ورودی تازه در مرحله جدید ترکیب میشوند.) این چرخه ها اجازه وجود اطلاعات از یک گام زمانی به گام زمانی بعدی را موجب میشوند. بعبارت بهتر این نوع شبکه ها دارای حلقه ای در درون خود اند که بوسیله آن میتوانند اطلاعات را در حین خواندن ورودی از نورونها عبور دهند.
عموما در رابطه با این نوع شبکه ها با نمادها و اشکالی همانند زیر مواجه میشوید :
 که با باز کردن آن به ماهیت حلقه موجود در این نوع شبکه ها بهتر پی میبرید :
که با باز کردن آن به ماهیت حلقه موجود در این نوع شبکه ها بهتر پی میبرید :
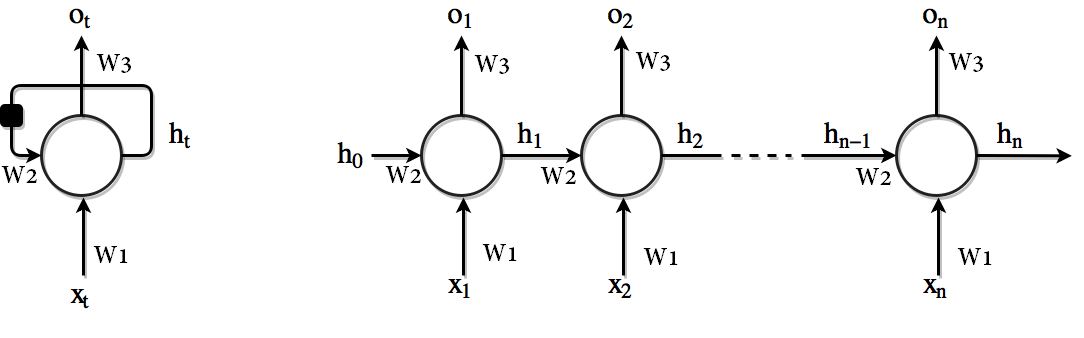
شکل ۱. سمت چپ . دیاگرام مدار . مربع سیاه رنگ نمایانگر تاخیر زمانی یک گام زمانی است. سمت راست:همان شبکه که بصورت یک گراف محاسباتی باز شده نمایش داده شده است. هر نود مرتبط با یک زمان خاص است. (اشاره به یک گام زمانی دارد)
این ساختار با چرخه ها ممکن است کمی گیج کننده باشد. اما زمانی که ما به زنجیره شکل گرفته بعد از باز کردن این گراف محاسباتی نگاه بیاندازیم این مساله کاملا قابل فهم میشود. اکنون ما معماری ای داریم که میتواند ورودی های مختلفی را در هر گام زمانی  دریافت نموده و قابلیت تولید خروجی هایی
دریافت نموده و قابلیت تولید خروجی هایی  در هر گام زمانی را داشته و همینطور یک حالت حافظه
در هر گام زمانی را داشته و همینطور یک حالت حافظه  را که حاوی اطلاعاتی در مورد انچه که در شبکه تا زمان رخ داده است در خود حفظ کند.
را که حاوی اطلاعاتی در مورد انچه که در شبکه تا زمان رخ داده است در خود حفظ کند.
در این تصاویر یک ورودی,  (
( ) الی ) حالت داخلی(بعضا به حالت مخفی هم شهره است) یا همان حافظه و نیز خروجی است. t یا n در اینجا اشاره به طول گام های زمانی دارد. شما میتوانید لغات را از دنباله هایی همانند جملات و یا عبارات و… و یا حتی حروف را از یک رشته در قالب یک دنباله بصورت x_t به شبکه ارایه کرده و از طریق RNN خروجی o_t را دریافت نمایید. بعنوان مثال در یک جمله “من حسین هستم” شما با یک دنباله شامل ۳ کلمه مواجه هستید. و x_t شما حاوی ۳ عنصر خواهد بود. بصورت زیر :
) الی ) حالت داخلی(بعضا به حالت مخفی هم شهره است) یا همان حافظه و نیز خروجی است. t یا n در اینجا اشاره به طول گام های زمانی دارد. شما میتوانید لغات را از دنباله هایی همانند جملات و یا عبارات و… و یا حتی حروف را از یک رشته در قالب یک دنباله بصورت x_t به شبکه ارایه کرده و از طریق RNN خروجی o_t را دریافت نمایید. بعنوان مثال در یک جمله “من حسین هستم” شما با یک دنباله شامل ۳ کلمه مواجه هستید. و x_t شما حاوی ۳ عنصر خواهد بود. بصورت زیر :
|
1 2 3 4 5 6 7 |
x_1 = من x_2 = حسین x_3 = هستم |
به همین شکل اگر دنباله خود را یک رشته فرض کنیم بعنوان مثال “ایران” شما دنباله ای از ۵ حرف خواهید داشت و در نتیجه x_t شما حاوی ۵ عنصر خواهد بود:
|
1 2 3 4 5 6 7 8 9 10 11 |
x_1 = ا x_2 = ی x_3 = ر x_4 = ا x_5 = ن |
اگر به مثالهای بالا خوب نگاه کنیم متوجه میشویم که دو دید کلی در رابطه با کار در حوزه دنباله ها (در حوزه پردازش زبان طبیعی) وجود دارد. دید کلمه ای(که پیشتر توضیح مختصری دادیم) و دید حرفی که در ادامه سعی میکنیم در این رابطه بیشتر توضیح دهیم. (اما آیا تنها ورودی های ما به حروف و کلمات محدود است؟ خیر. ما میتوانیم از هرچیزی که ماهیت دنباله ای داشته باشد استفاده کنیم . از فریم های یک ویدئوکلیپ گرفته تا اعداد و ارقام مرتبط با بازار بورس و سهام و … در ادامه در باره این موارد انشاءالله بیشتر یاد خواهیم گرفت.)
برای درک بهتر این ساختار بهتر است یک حلقه for را در نظر بگیرید. شما در این حلقه در هر بار دو ورودی دریافت میکنید و دو خروجی میتوانید تولید کنید. در ابتدای حلقه متغیر h شما برابر با صفر خواهد بود. و متغییر x از ورودی مقدار دریافت میکنید. یک محاسبه انجام شده و خروجی h1 تولید میشود. محاسبه دیگری صورت گرفته و خروجی o1 بدست می آید. قبل از اینکه به گام دوم بپردازیم متغیرh0 برابر با متفییر h1 خواهد بود. چرا که در گام بعدی خروجی حالت فعلی بعنوان حالت قبلی باید در دسترس باشد. پس از این کار حالا اندیس حلقه یکی افزایش یافته نوبت دور دوم محاسبات است. ورودی دوم وارد متغییر x میشود. اینجا مقدار h0 ما دارای مقدار مناسب است چرا که از گام قبلی مقدار آنرا برابر با مقدار h_1 کردیم. حالا باید h1 جدید برای گام دوم محاسبه شود. اینکار انجام میشود و دوباره محاسبه دیگری انجام شده و خروجی تازه ای بدست می اید و این فرایند تا زمان تعداد گام های زمانی مورد نیاز ادامه میباد. نمونه کد زیر این مساله را بهتر نشان میدهد :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
h_0 = 0 T = Number_of_steps for t in range(T): x = input[t] h_1 = compute(h_0, x) o_result = compute(h_1) # save output at each time step outputs.append(o_result) # the new h will be the previous h for the next time step h_0 = h_1 |
نکته :
ما انشاءالله بطور مفصل در بخش بعد این آموزش به این مساله خواهیم پرداخت. فعلا تنها سعی کنید مطالب کلی و ایده های کلی مطرح شده در اینجا را به ذهن بسپارید. اگر نکته ای مبهم است در بخش های آتی که دقیق تر شده و بطور مفصل سلول RNN را واکاوی میکنیم این موارد برطرف خواهند شد.
از نظر تئوری RNN ها بایستی قادر به مدیریت و استفاده بهینه از محتوای موجود در یک جمله باشند. در عمل اما اینگونه نیست و RNN های معمولی با کاستی مواجه هستند. به همین دلیل نیز استفاده از RNN ها تا مدتی متوقف گردید تا اینکه نتایج بسیار خوبی با استفاده از واحد حافظه بلندمدت و کوتاه مدت یا به اختصار LSTM (مخفف Long Short Term Memory ) در شبکه عصبی بدست آمد. برخلاف RNN سنتی LSTM ها در مواجهه با دنباله های طولانی مشکلی نداشته و با مکانیزم طراحی شده در آنها بخوبی اجازه کار با دنباله های طولانی تر را میدهند. ما درادامه بصورت مبسوط به توضیح این مورد و همچنین GRU که نوع دیگری از این نوع شبکه ها هستند خواهیم پرداخت.
توجه به این نکته حایز اهمیت است که ما میتوانیم این شبکه را به هر تعداد کلمه ای که در جمله ورودی وجود دارد باز کنیم. علاوه بر آن پارامترهای هر کدام از سلولهای RNN یکی خواهند بود (حلقه for بالا و پارامترهای W1 الی W3 در شکل ۱ را در نظر بگیرید) که باعث میشود تعداد پارامترهای مدل مستقل از طول جمله باشد.
شبکه های عصبی بازگشتی را میتوان با توجه به اینکه ورودی ها چگونه به شبکه تغذیه شده و خروجی های چگونه تفسیر میشوند در سناریوهای گوناگونی مورد استفاده قرار داد.
این سناریوها میتوانند به سه کلاس اصلی مختلف تقسیم شوند :
- ورودی سری و خروجی سری : ترجمه ماشینی، تولید متن جدید(مثل video captioning و…) ،
- ورودی سری و خروجی یکتا : یکی از وظایف با این خصیصه تحلیل احساس یا sentiment analysis است. که در آن ما جمله ای را به شبکه تغذیه کرده و سپس میخواهیم آنرا بصورت مثبت ,منفی و یا بی طرف(neutral) طبقه بندی کنیم.
- ورودی یکتا و خروجی سری : بعنوان مثال حالت شرح نویسی تصاویر (Image Captioning) که در آن ما یک تصویر را به RNNتغذیه کرده و میخواهیم توضیح یا تفسیری از آن را ایجاد کنیم.
مدلهای زبانی بازگشتی
در این بخش ما نگاهی به چگونگی استفاده از این معماری برای وظیفه مدلسازی زبان بگونه ای که بحثش رفت میپردازیم. تصور کنید که میخواهیم احتمال وجود جمله ؛ و صاحبخانه یک پیرمرد بنام باباعلی است؛ را محاسبه کنیم. به همین منظور ما نیازمند تقریب زدن احتمالات زیر هستیم :
![\[p(\text{And}), p(\text{the}| \text{And}), p(\text{landlord}| \text{And the}) ..., p(\text{babaali}|\text{And the landlord is an old man named})\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-50f82edb192277cbc58429d36183b34c_l3.png "Rendered by QuickLaTeX.com")
تعبیه سازی کلمه : word embedding
اولین چیزی که ما باید به آن توجه کنیم چگونگی تعریف ورودی برای تابع مدلسازی زبان مان است. واضح است که ورودی یک دنباله از  کلمه است اما چطور باید هرکدام از این کلمات معرفی شوند؟ دراکثر سامانه های یادگیری عمیق ما دوست داریم تا مدل را با دانش قبلی تا جایی که ممکن است محدود کنیم. یک طرح رمزگذاری(یا اصطلاحا encoding) که این معیار را ارائه میکند رمزگذاری ۱-of-k یا ۱-از-چند (one-hot encoding یا اصطلاحا در زبان فارسی رمزگذاری ۱ داغ!) است.
کلمه است اما چطور باید هرکدام از این کلمات معرفی شوند؟ دراکثر سامانه های یادگیری عمیق ما دوست داریم تا مدل را با دانش قبلی تا جایی که ممکن است محدود کنیم. یک طرح رمزگذاری(یا اصطلاحا encoding) که این معیار را ارائه میکند رمزگذاری ۱-of-k یا ۱-از-چند (one-hot encoding یا اصطلاحا در زبان فارسی رمزگذاری ۱ داغ!) است.
در این طرح هر کلمه  ام در لغت نامه بصورت یک بردار دودویی(متشکل از ۰ و ۱)
ام در لغت نامه بصورت یک بردار دودویی(متشکل از ۰ و ۱)  ارایه میشود. برای مشخص کردن مین کلمه در بردار ما مین المان این بردار را برابر ۱ قرار داده و مابقی المان ها را برابر ۰ قرار میدهیم.
ارایه میشود. برای مشخص کردن مین کلمه در بردار ما مین المان این بردار را برابر ۱ قرار داده و مابقی المان ها را برابر ۰ قرار میدهیم.
![\[x _i = [0,0,...,1 (\i\text{-th element}), 0,...,0]^T in { 0, 1}^{|V|}\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-c9be4e69134625a34f45a923929a430d_l3.png "Rendered by QuickLaTeX.com")
عبارت بالا به معنای این است که ما دارای برداری با اندازه هستیم که تمام درایه های آن صفر است به جز درایه iام این بردار که ما برابر با ۱ قرار داده ایم.
دانش قبلی (prior knowledge) تعبیه شده در این طرح کدگذاری کمینه بوده از این جهت که اگر دو کلمه متفاوت بوده فاصله بین هر دو بردار لغت مساوی ۱ و اگر دو کلمه یکسان باشنداین فاصله برابر با ۰ خواهد بود.
حالا ورودی به مدل ما یک دنباله از  بردار one-hot
بردار one-hot  ))شده است . هرکدام از این بردارها سپس توسط یک ماتریس وزن
))شده است . هرکدام از این بردارها سپس توسط یک ماتریس وزن  ضرب شده تا دنباله ی پیوسته از بردارها بدست آید بطوری که :
ضرب شده تا دنباله ی پیوسته از بردارها بدست آید بطوری که :
![\[\mathbf{x} _j = \mathbf{W}^T \mathbf{x} _j\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-5317e90571df7b82aea7683fd0ba2db1_l3.png "Rendered by QuickLaTeX.com")
نکته :
درواقع این ضرب بردار در ماتریس انجام نمیشود. از آنجایی که بردار  تنها یک المان برابر با ۱ (مین المان) دارد و مابقی صفر هستند ضرب مساوی با گرفتن مین سطر از ماتریس میباشد. چرا که برش یک ماتریس سریعتر از انجام ضرب است . این در اصل عملیاتی است که در عمل انجام میگیرد.
تنها یک المان برابر با ۱ (مین المان) دارد و مابقی صفر هستند ضرب مساوی با گرفتن مین سطر از ماتریس میباشد. چرا که برش یک ماتریس سریعتر از انجام ضرب است . این در اصل عملیاتی است که در عمل انجام میگیرد.
شیوه انجام فاز Forward pass :
شکل ۲ چگونگی پرداختن به این مساله را نشان میدهد.
ابتدا ما بردار حافظه  را برابر صفر قرار میدهیم.
را برابر صفر قرار میدهیم.
در این گام زمانی (که با صفر مشخص شده است) اولین ورودی ما به واحد RNN یک توکن مخصوص <s> میباشد که شروع یک جمله را مشخص میکند(نمادی از شروع یک جمله).
در خروجی نیز ما احتمال وقوع هر کلمه ممکن در لغت نامه را به ازای دریافت توکن شروع جمله بدست می اوریم.
بردار حافظه در این عملیات بروز شده و به گام زمانی بعدی ارسال میشود.
حالا ما رویه انجام شده را برای گام زمانی ۱ تکرار میکنیم که در آن And ورودی سلول بوده و  حالت حافظه ای است که شامل اطلاعاتی در باره گذشته بوده و احتمال وقوع کلمه
حالت حافظه ای است که شامل اطلاعاتی در باره گذشته بوده و احتمال وقوع کلمه  به ازای <s> And (یعنی
به ازای <s> And (یعنی  ) نیز خروجی میباشد.
) نیز خروجی میباشد.
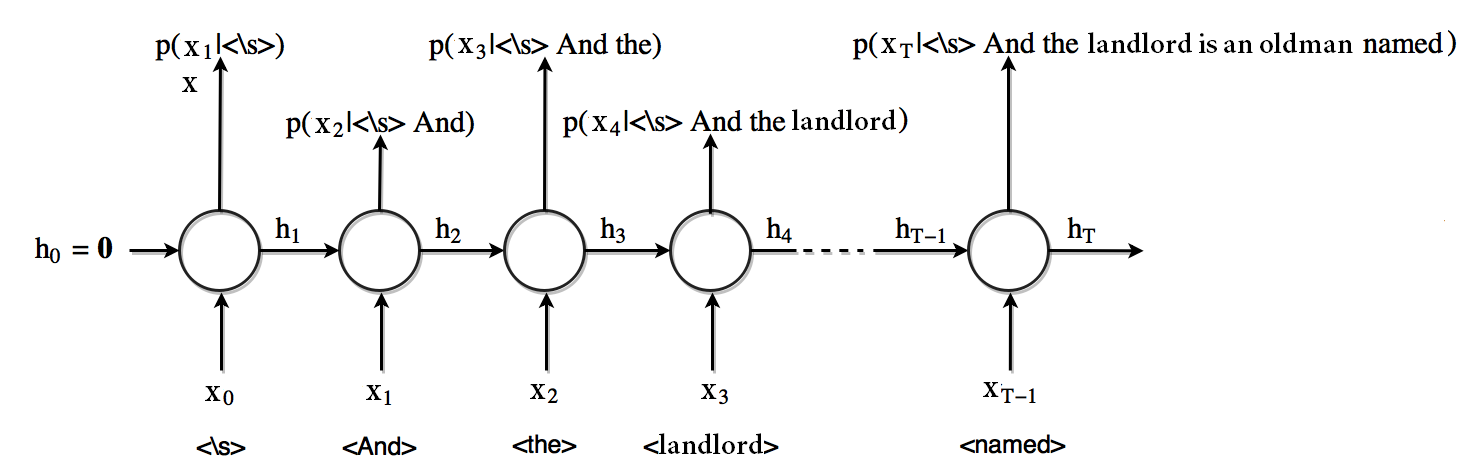
شکل۲. RNNبرای مدلسازی زبان
در کل در هر گام زمانی ما بدنبال تقریب زدن یک توزیع احتمالاتی بر روی تمامی لغات بعدی ممکن در لغت نامه به ازای کلمات داده شده قبلی هستیم. لایه خروجی یک RNN نیز یک لایه Softmax است که برداری با اندازه ارایه میکند که المان م آن اشاره کننده به احتمال لغت  م مبنی بر کلمه بعدی جهت ظاهر شدن در جمله میباشد.
م مبنی بر کلمه بعدی جهت ظاهر شدن در جمله میباشد.
برای حالتی که در آن خروجی در زمان یک تبدیل affine از حالت حافظه محاسبه شده است ما داریم :
![\[p(x_t = k | x_{< t}) = \frac {\exp(\mathbf{W_3} _k^T h _t + b _k)}{\sum _{k'} \exp(\mathbf{W_3} _{k'}^T h _t + b _{k'})}\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-948c08bf89f51a966be92442c3ba7aea_l3.png "Rendered by QuickLaTeX.com")
شیوه انجام فاز backward pass :
ما تا به اینجا معماری ای داریم که میتواند با جملات کنش داشته و برای این منظور از شبکه های عصبی بازگشتی استفاده کردیم. تنها بخش باقی مانده تعریف تابع اتلاف مناسب برای شبکه است تا بتواند بطور واقعی چیزی که ما از آن انتظار داریم را یادبگیرد.
loss یا خطا برای یک دنباله داده شده برابر است با منفی احتمال لگاریتمی که مدل به خروجی صحیح منتسب میکند. یعنی  با استفاده از قاعده زنجیره حسابان و این اصل که لگاریتم یک ضرب برابر است با جمع لگاریتمها. ما برای یک دنباله
با استفاده از قاعده زنجیره حسابان و این اصل که لگاریتم یک ضرب برابر است با جمع لگاریتمها. ما برای یک دنباله  خواهیم داشت :
خواهیم داشت :
![\[L(\mathbf{x}) = - \sum _t \log p _{model} (x _t = x _{t + 1}) = - \sum _t \log \mathbf{o} _t [x _{t+1}]\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-175f11a0b3366be239f390c9cf147133_l3.png "Rendered by QuickLaTeX.com")
بطوریکه![\mathbf{o} _t [x _{t+1}]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-ce1a802846b6d99c0af2f5322d3671e7_l3.png "Rendered by QuickLaTeX.com") المانی از خروجی softmax متناظر با لغت
المانی از خروجی softmax متناظر با لغت  واقعی است .
واقعی است .
با تعریف این لاس و دانستن این مساله که تمامی سیستم مشتق پذیر است ما میتوانیم loss را از درون تمامی واحدهای RNN قبلی و ماتریس های تعبیه شده backpropagate کنیم و وزنها را به همان نسبت بروز رسانی نماییم .
تعمیم به n-gram دیده نشده :
حالا که مدل زبانی خود را تعریف کردیم اجازه بدهید تا با هم نگاهی به آنچه که در درون اتفاق می افتد بیاندازیم تا بهتر متوجه شویم چرا این روش انقدر قدرتمند است. بطور خاص ما بر روی چگونگی تعمیم این مدل بر روی n-gram های دیده نشده (دنباله ای از n لغت پشت سر هم) تمرکز میکنیم که یکی از مهمترین فایده های مدل های زبانی عصبی در قیاس با روشهای پردازش زبان طبیعی سنتی همانند مدل زبانی n-gram است.
مدل ما را میتوان بعنوان ترکیبی از دو تابع ( ) در نظر گرفت. تابع اول
) در نظر گرفت. تابع اول  لغات قبلی دنباله (
لغات قبلی دنباله (  لغت قبلی) را به یک فضای برداری پیوسته نگاشت میکند. بردار
لغت قبلی) را به یک فضای برداری پیوسته نگاشت میکند. بردار  نهایی یک حالت حافظه یا بردار محتوا خواهد بود. بعبارت دیگر :
نهایی یک حالت حافظه یا بردار محتوا خواهد بود. بعبارت دیگر :
![\[f: {0,1}^{|V| \times (n-1)} \rightarrow \mathbb R^d\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-d636033701d5aa25fbd4f72e3a44e716_l3.png "Rendered by QuickLaTeX.com")
مرحله دوم, که با  توصیف شده است نگاشت بردار پیوسته به احتمال لغت مورد نظر, از طریق اعمال یک تبدیل affine (ضرب در یک ماتریس و جمع آن با یک بردار بایاس) قبل از نرمالسازی softmax (به منظور تبدیل خروجی به یک توزیع احتمال معتبر) را انجام میدهد.
توصیف شده است نگاشت بردار پیوسته به احتمال لغت مورد نظر, از طریق اعمال یک تبدیل affine (ضرب در یک ماتریس و جمع آن با یک بردار بایاس) قبل از نرمالسازی softmax (به منظور تبدیل خروجی به یک توزیع احتمال معتبر) را انجام میدهد.
![\[g(\mathbf{h}) = softmax(\mathbf{W_3}^T \mathbf{h} + \mathbf{c})\]](https://deeplearning.ir/wp-content/ql-cache/quicklatex.com-5bbe51d23c1aedb64a48d0daa6c4ed1d_l3.png "Rendered by QuickLaTeX.com")
اجازه دهید کمی دقیقتر به عملیات انجام شده توسط نگاهی بیاندازیم. ما میتوانیم به اثر بایاس در اینجا توجهی نکنیم .بنابر این میتوانیم ضرب بردار-ماتریس را بصورت زیر بنویسیم :
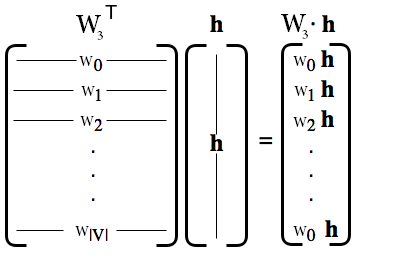
که در این حالت هر المان بردار خروجی ضرب برداری با سطر متناظر از  میباشد. برای شهود بهتر میتوان از این بصری سازی برای قانع کردن خود استفاده کنید.
میباشد. برای شهود بهتر میتوان از این بصری سازی برای قانع کردن خود استفاده کنید.
این به این معناست احتمال پیش بینی شده مدل برای مین لغت لغت نامه تا چه حد متناسب با چگونگی تراز بودن ستون م با محتوای بردار است.
حالا اگر ما دو دنباله از لغات محتوایی داشته باشیم که معمولا توسط مجموعه مشابه ای از لغات دنبال میشوند, پس بردارهای محتوایی  و
و  بایستی شبیه هم باشند. چرا؟ زیرا زمانی که ما آنها را با ضرب میکنیم نیاز داریم که یک مجموعه لغات یکسان دارای بیشترین احتمال باشند.
بایستی شبیه هم باشند. چرا؟ زیرا زمانی که ما آنها را با ضرب میکنیم نیاز داریم که یک مجموعه لغات یکسان دارای بیشترین احتمال باشند.
به عبارت دیگر در انتها مدل زبانی عصبی باید n-gramهایی را ارایه کند که بدنبال آن همان لغتی انتخاب شود که در جوار نقاط نزدیک در فضای برداری محتوا است. اگر این خصوصیت براورده نشود و دو n-gram به بردارهای کاملا متفاوت نگاشت شوند بنابر این ضرب هر کدام از انها در احتمالات بسیار متفاوتی را برای لغت بعدی بدست خواهند داد که در نتیجه باعث نتیجه شدن یک مدل زبانی بد خواهد شد.
اجازه دهید این مساله را با یک مثال بدون آنکه کلیت را از دست دهیم روشن کنیم. ما فرض میکنیم که هر لغت تنها به لغت قبلی که در جمله امده است وابسته است. بعبارت بهتر ما یک مدل زبانی bigram را فرض میکنیم که طول محتوای آن ۱ است. مجموعه آموزشی ما (training corpus) متشکل از سه جمله زیر است :
There are three teams left for the qualification.
four teams have passed the first round.
four groups are playing in the field
ما بر روی عباراتی که تو پر شده اند تمرکز میکنیم . اولین کلمه هر کدام از این bigram ها یک لغت محتوایی است و یک مدل زبانی باید احتمال لغت بعدی را پیش بینی کند.
با توجه به تحلیل قبلی ما, متوجه میشویم که مدل باید لغت three و four را در فضای محتوایی بر روی نقاط نزدیک بهم نگاشت کند. زیرا ما نیاز داریم که آنها احتمالات یکسانی برای لغت teams (جملات اول و دوم موجود در مجموعه اموزشی (training set)) ارایه دهند.
بردارهای لغت هدف  و
و  هم الزاما باید نزدیک به هم باشند چرا که در غیر اینصورت احتمال teams به ازای four (
هم الزاما باید نزدیک به هم باشند چرا که در غیر اینصورت احتمال teams به ازای four ( ) و احتمال groupsبه ازای four (
) و احتمال groupsبه ازای four ( ) برخلاف این حقیقت که انها بصورت مساوی در مجموعه اموزشی محتمل هستند متفاوت خواهد بود.
) برخلاف این حقیقت که انها بصورت مساوی در مجموعه اموزشی محتمل هستند متفاوت خواهد بود.
حالا فرض کنید که ما میخواهیم مدل زبانی را با این مجموعه کوچک اموزش دهیم . ما میتوانستیم احتمال three groups را درخواست کنیم که مدل هرگز ندیده است . مدل زبانی ما لغت محتوایی three را نزدیک نقطه ای به four در فضای محتوایی نمایش میدهد. از این بردار محتوایی مدل خواهد تنوانست احتمال بالایی را به لغت groupاختصاص دهد چرا که بردار محتوایی  و بردار لغت هدف
و بردار لغت هدف  بخوبی هم تراز شده اند. بنابر این حتی بدون حتی یکبار دیدن bigram three groups این روش میتواند احتمال منطقی ای را منتسب کند.
بخوبی هم تراز شده اند. بنابر این حتی بدون حتی یکبار دیدن bigram three groups این روش میتواند احتمال منطقی ای را منتسب کند.
در این خصیصه است که بیشتر قدرت این روش به آن وابسته است . این خصیصه کلیدی اینجا استفاده از بازنمایی توزیع شده لغتها و محتوا است یعنی این حقیقت که ما از بازنمایی های برداری پیوسته برای لغات و محتوا استفاده میکنیم . این روش مبتنی بر نظریه توزیعی زبان است :
؛نظریه توزیعی به این معناست که لغاتی که در یک زمینه یکسان رخ میدهند متمایل به معانی مشابه هستند. اصل زیرین به این معناست که ؛ یک لغت از طریق اطرافیانش شناخته میشود ؛
این روش نه تنها از طبیعت احتمالاتی زبان از دو جهت مهم بهره برداری میکند بلکه از طرف دیگر احتمال یک لغت را در ازای محتوای ارایه شده فرا میگیرد و از طرف دیگر محتوای مشابه را با بردارهای مشابه در فضای محتوای و لغات مشابه در فضای لغت ارایه میکند. برگرفنه از ACLWeb
تولید متن :
چگونه میتوانیم از این مدل زبانی برای تولید قطعات جدید متن استفاده کنیم ؟تقریبا این مساله سر راست است. اگر ما بخواهیم یک جمله جدید را ایجاد کنیم باید بردار محتوایی  را بصورت تصادفی مقداردهی اولیه کنیم سپس در هر گام زمانی اقدام به نمونه گیری یک لغت از توزیع احتمال لغت خروجی کرده و بعد این لغت را دوباره به ورودی,واحد RNN در گام زمانی بعدی تغذیه کنیم.
را بصورت تصادفی مقداردهی اولیه کنیم سپس در هر گام زمانی اقدام به نمونه گیری یک لغت از توزیع احتمال لغت خروجی کرده و بعد این لغت را دوباره به ورودی,واحد RNN در گام زمانی بعدی تغذیه کنیم.
اجازه دهید با یک مثال ساده این مساله را بیشتر روشن کنیم . فرض کنید ما نمیخواهیم صرفا یک متن معمولی ایجاد کنیم بلکه دنبال یک سری کاراکتر خاص هستیم. بعنوان مثال ما میخواهیم جمله هایی تولید کنیم مثل اینکه شلدون کوپر(بازیگر سریال بیگ بنگ تئوری) در حال نوشتن آنهاست. یک روش میتواند این باشد که همه نمایش نامه های Big Bang theoryرا گرفته و اسکریپت های مختص به کوپر را جدا کرده و مدل زبانی رو بر روی این داده ها اموزش دهیم .
مشکل این روش این است که تعداد مشاهدات ممکن است به اندازه کافی زیاد نباشد که بتوان با آن سیستم خود را اموزش دهیم. راه دیگری که ما پیش رو خواهیم داشت استفاده از پیش اموزش است. یعنی ما ابتدا مدل زبانی خود را بر روی یک متن معمولی اموزش دهیم (مثلا میتوانیم از مجموعه گوتنبرگ استفاده کنیم). سپس زمانی که مدل ما به سطح خاصی از درک از لغات محتوا و ساختار متن رسید ما میتوانیم رویه اموزش را تنها با خطوط مربوط به شلدون ادامه دهیم و مدل شیوه خاص صحبت کردن او را یاد بگیرد.
گام های بعدی :
در پست بعدی(بخش دوم) ما بیشتر در جزییات پیاده سازی این نوع مدلها غرق خواهیم شد به معرفی شبکه RNN با جزییات بیشتر پرداخته و انواع مختلف آن مثل GRU و LSTM را معرفی میکنیم. سپس مثالهایی را با هم پیاده سازی میکنیم و و بعضی از مشکلات متداول و چگونگی مرتفع سازی آنها در عمل خواهیم پرداخت.
برای مطالعه بیشتر مطالب زیر را نیز ببینید :
Written Memories: Understanding, Deriving and Extending the LSTM . Link
Recurrent Neural Networks introduction part 1. Link
\experimenting with text generation. Deep writing blog
Natural Language Understanding with Distributed Representation. Kyunghyun Cho. New York University, 2015. Lecture Note for DS-GA 3001
The Unreasonable Effectiveness of Recurrent Neural Networks. Link
Understanding LSTM Networks. Link
۱: Example borrowed from Prof. Kyunghyun Cho lecture notes on on Natural Language Understanding with Distributed Representations. New York University, 2015. Link.
سلام
ممنون از توضیحات خوبتون، منتها قسمت n-gram را گنگ بیان کردید بهتره یکم واضح تر بیان کنید. – سپاس
[…] آموزش شبکه های عصبی بازگشتی (Recurrent Neural Networks) بخش اول […]
سلام. لطفا رفرنس مطالب بیان شده و نام مقاله را بفرمایید.
سلام. همه رفرنسها در انتها قرار داده شده .لطفا لینکها رو چک کنید
سلام.
فوق العاده متن خوبی نوشتید. انصافا خسته نباشید. به من که خیلی کمک کرد.
البته یک نکته برای من گنگ موند که کلا نفهمیدم ماتریس W چی هست و به چه علت وارد مباحث شد.
سلام.
ممنون از مطالب خیلی خوبتون.
کار یادگیری یک زبان خاص یا همون مدل زبانی با شبکه عصبی یک task بانظارت است یا بدون نظارت؟
مثلا در تشخیص تصاویر ما برچسب تصاویر رو به عنوان Label به شبکه می دهیم و با کمک اونها خطای شبکه رو محاسبه می کنیم. اما در اینجا برنامه برای محاسبه ی خطای شبکه در تشخیص کاراکتر بعدی از کجا می فهمه کاراکتر واقعی بعدی چی بوده؟
امکانش هست همین کار یادگیری مدل زبانی و تولید عبارت رو با لایه های آماده ی کراس، یعنی GRU توضیح بدید؟
سلام مثالی که زده شده اینجا همونطور که میبینید با نظارت هست.
مبنای کار هم اگر بخش های بعدی آموزش رو ببینید متوجه میشید که مبتنی بر احتمال هست مثل همون چیزی که در کار با تصاویر میبنید حالا کمی متفاوت تر
متاسفانه من بشدت سرم شلوغ هست و فرصت نمیکنم
برای لایه های کراس یه سرچ ساده کنید کلی مطلب پیدا میکنید.
سلام وقتتون بخیر
ممنون بابت مطالب خوبتون
آیا میتونیم از این شبکه ها برای حذف نویز تصاویر هم استفاده کرد؟
سلام. از این شبکه های برای اینکار استفاده نمیشه.
میتونید از اتوانکودرها برای این قبیل موارد استفاده کنید.
مساله پیچیده تر باشه شبکه های GAN میتونید استفاده کنید
سپاسگزارم. خیلی عالی بود. مفاهیمی که بارها خوانده بودم ولی به درک کافی نرسیده بودم را با زبانی بسیار شیوا بیان کردید.
سپاس بیکران
واقعا خیلی خوب بود مفاهیم در عین سادگی به طور کامل بیان شده بود
فقط یکم از نظر نوشتار به دستورات نگارشی توجه شود دیگه عالی می شود.