
بسم الله الرحمن الرحیم
کمک معلم یا اصطلاحا Teacher Forcing روش سریع و کارآمدی است که برای آموزش مدلهای مبتنی بر شبکه های عصبی بازگشتی که از خروجی یک گام قبل بعنوان ورودی بهره میبرند مورد استفاده قرار میگیرد. این متد یک روش آموزش شبکه است که در توسعه مدلهای زبانی مبتنی بر یادگیری عمیق که در حوزه های گوناگون من جمله ترجمه ماشینی، خلاصه سازی متن و شرح نویسی تصویر مورد استفاده قرار میگیرند نقش حیاتی دارد.
استفاده از خروجی بعنوان ورودی در پیش بینی دنباله :
مدلهای پیش بینی دنباله ای وجود دارند که در آنها از خروجی تولید شده در اخرین گام زمانی  بعنوان ورودی برای مدل در گام زمانی فعلی (
بعنوان ورودی برای مدل در گام زمانی فعلی ( )بهره برده میشود. این گونه مدلها در مدلهای زبانی که خروجی هر گام، یک کلمه بوده و سپس این خروجی بعنوان ورودی گام زمانی بعدی مورد استفاده قرار میگیرد تا کلمه بعدی در دنباله ایجاد شود رایج است. بعنوان مثال این گونه مدل های زبانی در معماری های شبکه عصبی بازگشتی Encoder-Decoder برای مسائل تولید دنباله به دنباله (Sequence to sequence) ای همانند :
)بهره برده میشود. این گونه مدلها در مدلهای زبانی که خروجی هر گام، یک کلمه بوده و سپس این خروجی بعنوان ورودی گام زمانی بعدی مورد استفاده قرار میگیرد تا کلمه بعدی در دنباله ایجاد شود رایج است. بعنوان مثال این گونه مدل های زبانی در معماری های شبکه عصبی بازگشتی Encoder-Decoder برای مسائل تولید دنباله به دنباله (Sequence to sequence) ای همانند :
- ترجمه ماشینی (Machine Translation)
- تولید عنوان (Caption Generation)
- خلاصه سازی متن (Text Summarization)
مورد استفاده قرار میگیرند.
بعد از آنکه مدل اموزش دید. میتوان از توکن (نشانه) “شروع دنباله” برای آغاز فرآیند استفاده کرد و یک کلمه را درگام زمانی اول تولید کرد حالا از این خروجی (کلمه تازه) بعنوان ورودی برای گام زمانی دوم استفاده میشود و خروجی آن بعنوان ورودی برای گام زمانی بعدی و همینطور الی اخر استفاده میشود. این فرآیند بازگشتی را میتوان در زمان اموزش مدل نیز مورداستفاده قرار داد اما این کار میتواند باعث مشکلاتی نظیر زیر شود :
- همگرایی آهسته
- ناپایداری مدل
- مهارت (یا تعمیم) ضعیف مدل
کمک معلم یا همان teacher forcing روشی است که جهت بهبود مهارت مدل و پایداری آن در زمان آموزش این گونه مدلها مورد استفاده قرار میگیرد.
کمک معلم چیست؟
کمک معلم استراتژی ای برای آموزش شبکه های عصبی بازگشتی است که در آنها از خروجی مدل از گام زمانی قبل بعنوان ورودی در گام زمانی بعد مورد استفاده قرار میگیرد. مدل هایی که دارای اتصالات بازگشتی از خروجی های خود هستند را میتوان با این شیوه آموزش داد.
این شیوه در ابتدا بعنوان شیوه جایگزینی برای الگوریتم پس انتشار خطا در زمان برای آموزش شبکه های عصبی بازگشتی توسعه داده شده و سپس ارائه گردید. این تکنیک با استفاده از برچسب مورد انتظار(و نه خروجی تولید شده توسط شبکه در گام زمانی قبلی) در گام زمانی قبلی و استفاده ازآن بعنوان ورودی در گام زمانی بعدی عمل میکند.
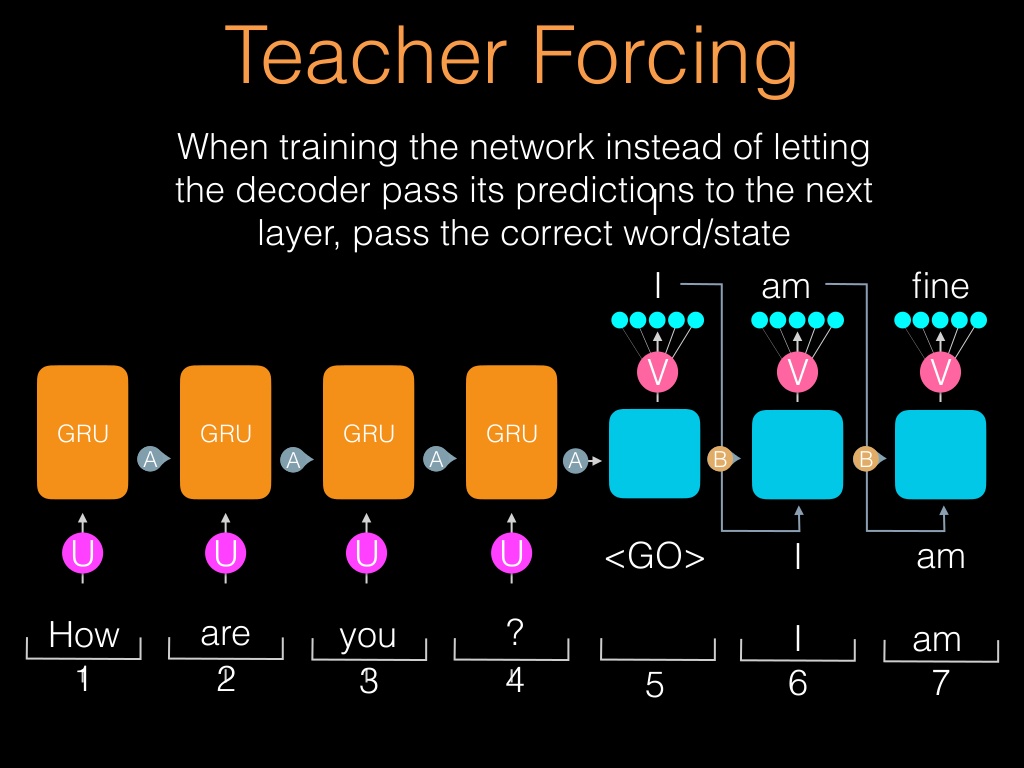
کمک معلم رویه ای است که در آن در حین آموزش مدل برچسب های صحیح را بعنوان ورودی در گام زمانی بعدی مورد استفاده قرار میدهد!
درک شهودی :
اجازه دهید جهت درک بهتر این مساله مثالی را با هم مرور کنیم .
فرض کنید ما یک دنباله بصورت زیر داشته باشیم :
|
1 2 3 |
Mary had a little cat whose fur was white as snow |
حالا فرض کنید ما قصد داریم مدلی را آموزش دهیم تا با دریافت کلمه قبلی، کلمه بعدی در دنباله بالا را تولید کند.
قائدتا اولین کاری که میکنیم مشخص سازی ابتدا و انتهای دنباله خود با نمادهای شروع و پایان است. مثلا مثل زیر :
|
1 2 3 |
[START] Mary had a little cat whose fur was white as snow [END] |
در گام بعد در حین آموزش ما نماد شروع را بعنوان اولین ورودی به شبکه تغذیه میکنیم. حالا انتظار داریم شبکه کلمه اولی که مد نظر ماست را تولید کند. شبکه نیز اولین خروجی خود را تولید میکند. مثلا فرض کنید اولین خروجی که ما دریافت کردیم کلمه a بوده باشد. خب مشخص است که این آن کلمه مورد انتظار ما یعنی ماری نیست.
|
1 2 3 4 |
input(X) output(o) [START], a |
حالا ما میتوانیم مثل روش معمول خروجی تازه تولید شده را بعنوان ورودی گام زمانی بعد به شبکه تغذیه کنیم.
|
1 2 3 4 |
input(X) output(o) [START], a, ? |
تا اینجای کار مشخص است که شبکه در مسیر اشتباه قرار گرفته است. به همین دلیل اگر این کار را انجام دهیم قائدتا شبکه مابقی کلمات را نیز اشتباه پیش بینی خواهد کرد و در نتیجه بخاطر خطاهایی که صورت داده قائدتا مجازات میشود. تا اینجا نکته خاصی نیست جز اینکه میدانیم این مساله همانطور که میبینید همگرایی را کند میکند چرا که شبکه بخاطر خطاهای مختلفی که کرده باید مجازات شده و پارامترها همگی دوباره تنظیم شوند تا نهایتا به خروجی مناسب متمایل شود و این مسلتزم تکرار های مختلفی است. ممکن است بگویید خب این کاری است که همیشه انجام میدهیم! نکته خاصی اینجاست که باید به آن توجه کنیم؟
بحث ما اینجاست که چطور بتوانیم همگرایی یک شبکه را تسریع کنیم و مانع ایجاد خطاهای بیشتر شبکه شویم تا اینگونه تعداد خطاهای صورت گرفته کمینه شده و همگرایی شبکه افزایش یابد. دیدیم که در حالت پیشفرض با سناریو بالا مواجه هستیم. اما آیا راهی هست که بتوان بهبودی در شیوه آموزش فوق داد؟ جواب بله است!
روش دومی که میتواتیم از آن استفاده کنیم همان “راهنمای معلم یا اصطلاحا Teacher Forcing است. در این روش بعد از اینکه اولین خروجی ما بدست آمد ما این خروجی را ندید گرفته و بجای اینکه از این خروجی بعنوان ورودی برای گام زمانی بعد استفاده کنیم، بعد از اینکه خطای این گام را محاسبه کردیم، مستقیما از برچسب اصلی که مورد انتظار ماست استفاده میکنیم (یعنی ماری).
|
1 2 3 4 |
input(X) output(o) [START], Mary, ? |
و این عمل را برای تمامی گام های زمانی بعدی تکرار میکنیم. اینطور مدل میتواند خیلی سریع دنباله مورد نظر و یا ویژگی های آماری آن را یادگرفته و سریعتر همگرا شود.
|
1 2 3 4 5 6 7 8 |
input(X) output(o) [START], ? [START], Mary, ? [START], Mary, had, ? [START], Mary, had, a, ? ... |
مشکل!
حالا ممکن است بپرسید خب اگر این روش انقدر خوب است پس چرا همیشه از این روش استفاده نمیشود؟ دلیل این امر این است که این روش ممکن است باعث ایجاد مدلهایی شود که در عمل زمانی که دنباله های تولید شده با آنچه که شبکه در زمان آموزش با آن مواجه بوده است متفاوت باشد بسیار ضعیف و محدود عمل کند. این مساله در اکثر کاربردهایی از این دست که خروجی ها ماهیت احتمالاتی دارند متداول است. این نوع از کاربرد مدلها معمولا به چرخه باز(open loop) معروف هستند.
متاسفانه این رویه میتواند موجب مشکلاتی در تولید دنباله شود چرا که خطای پیش بینی کوچک در محتوای شرطی ساز(conditioning context) ترکیب میشود. این مساله متعاقبا موجب کیفیت پایین پیش بینی میشود چرا که محتوای شرطی ساز RNN (دنباله ای از نمونه های تولیدی قبلی) از دنباله هایی که در حین آموزش مشاهده شده است فاصله میگیرد(واگرا میشود).(منبع)
برای مقابله با این مشکل روشهای مختلفی پیشنهاد شده است از آن جمله میتوان به جستجو برای دنباله های خروجی کاندید اشاره کرد.
دنباله های خروجی کاندید
یک روش رایج که در مدلهایی که مقادیر گسسته مثل کلمه را بعنوان خروجی تولید میکنند(پیش بینی میکنند) استفاده از جستجو در بین احتمالات پیش بینی شده برای هر کلمه است تا تعدادی کاندید محتمل اینگونه تولید گردد. از این روش در مسائلی مثل ترجمه ماشینی جهت بهبود دنباله تولیدی ترجمه شده استفاده میگردد. رویه جستجوی متداولی که برای این عملیات استفاده شده است جستجو پرتو (beam search) است.
یادگیری برنامه آموزشی (Curriculum Learning)
روش جستجوی پرتو (beam search) تنها برای مسائل پیش بینی ای مناسب است که دارای مقادیر خروجی گسسته باشند و از آن نمیتوان برای خروجی های حقیقی (real-valued) استفاده کرد.
گونه ای از یادگیری کمکی (Forced learning) این است که خروجی های تولید شده از گام های زمانی قبلی در حین آموزش به شبکه معرفی شود تا اینطور شبکه تشویق شده تا چگونگی تصحیح خطاهای خود را فرا بگیرد.
در مقاله ای تحت عنوان Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks اینطور آمده است :
“ما یک تغییر در فرایند آموزش را پییشنهاد میدهیم تا بصورت تدریجی مدل را مجبور کنیم تا با خطاهای خود مقابله کند همانطور که در زمان تست مجبور است این کار را صورت دهد.”
به این روش “یادگیری برنامه آموزشی” یا اصطلاحا Curriculum Learning میگویند و شامل انتخاب تصادفی استفاده از لیبل خروجی و یا خروجی تولید شده از گام زمانی قبلی بعنوان ورودی برای گام زمانی فعلی است. “برنامه آموزشی” در طی زمان تحت چیزی که به آن نمونه برداری زمانبندی شده (scheduled sampling) اطلاق میشود تغییر کرده که در آن رویه با یادگیری کمکی شروع شده و سپس بصورت آهسته احتمال ورودی کمکی (تحمیل شده) را در طی دوره های اموزشی کاهش میدهد.
مطالعات بیشتر :
- A Learning Algorithm for Continually Running Fully Recurrent Neural Networks, 1989.
- Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks, 2015.
- Professor Forcing: A New Algorithm for Training Recurrent Networks, 2016.
- What is Teacher Forcing for Recurrent Neural Networks
- Sam Witteveen: Neural-machine-translation-seq2seq
نکته :
در ترجمه forced میتوان از تحمیلی یا تحمیل شده نیز بهره برد اما بنظر می اید لفظ کمک یا راهنمایی دید بهتری نسبت به فعالیت الگوریتم ارائه میدهد. اگر ترجمه رسمی و معادل صحیحی میشناسید لطفا در بخش نظرات بفرمایید.
[…] روش Teacher Forcing چیست؟ […]
خیلی خوب و روان توضیح میدید
لذت بردم