
بسم الله الرحمن الرحیم
در بخش قبل با شبکه عصبی بازگشتی GRU آشنا شدیم و در این بخش به معرفی شبکه عصبی بازگشتی LSTM میپردازیم.
پیشتر(۱و۲و۳) دیدیم که یک شبکه عصبی بازگشتی سنتی (اگر به اندازه کافی بزرگ باشد) از نظر تئوری باید قادر به تولید دنباله هایی با هر پیچیدگی ای باشد اما در عمل مشاهده میکنیم که این شبکه در ذخیره سازی اطلاعات مرتبط با ورودی های گذشته به مدت طولانی ناتوان است.(منبع) علاوه بر اینکه این خصصیه توانایی این شبکه در مدل سازی ساختارهای بلند مدت را تضعیف میکند، این “فراموشی” باعث میشود تا این نوع از شبکه ها در زمان تولید دنباله در معرض ناپایداری قرار گیرند. مشکلی که وجود دارد(که البته در تمامی مدلهای تولیدی شرطی نیز متداول است) این است که اگر پیش بینی های شبکه تنها وابسته به چند ورودی اخیر باشد و این ورودی ها خود نیز توسط شبکه تولید شده باشند، شانس بسیار کمی برای تصحیح و جبران اشتباهات گذشته توسط شبکه وجود دارد.
داشتن یک حافظه بلند مدت تر دارای اثر تثبیت کننده است چرا که حتی اگر شبکه نتواند از تاریخچه اخیر خود درک صحیحی پیدا کند، باز با این وجود قادر است با نگاه در گذشته پیش بینی خود را کامل کند. مشکل ناپایداری بطور ویژه در زمان مواجه با داده اعشاری وخیم میشود چرا که پیش بینی ها میتوانند از مانیفولدی که داده های آموزشی بر روی آن قرار گرفته اند فاصله بگیرند. یک راه حل که برای مدلهای شرطی مطرح شده است تزریق نویز به پیش بینی های صورت گرفته توسط شبکه قبل از تغذیه آنها به گام زمانی بعدی است.(منبع) این کار باعث تقویت شبکه در قبال ورودی های غیرمنتظره میشود. با این وجود اما یک حافظه بهتر، راه حل به مراتب بهتر و تاثیرگذار تری است. حافظه طولانی کوتاه مدت یا به اختصار LSTM یک معماری شبکه عصبی بازگشتی است که برای ذخیره سازی و دسترسی بهتر به اطلاعات نسبت به نسخه سنتی آن طراحی شده است.
برخلاف شبکه عصبی بازگشتی سنتی که در آن محتوا در هر گام زمانی از نو بازنویسی میشود در یک شبکه عصبی بازگشتی LSTM شبکه قادر است نسبت به حفظ حافظه فعلی از طریق دروازه های معرفی شده تصمیم گیری کند. بطور شهودی اگر واحد LSTM ویژگی مهمی در دنباله ورودی در گام های ابتدایی را تشخیص دهد بسادگی میتواند این اطلاعات را طی مسیر طولانی منتقل کند بنابر این اینگونه وابستگی های بلندمدت احتمالی را دریافت و حفظ دارد.
همانطور که قبلا بطور مختصر اشاره کرده بودیم واحد حافظه طولانی کوتاه مدت (Long Short-Term Memory) ابتدا توسط هوخرایتر و اشمیت هوبر در سال ۱۹۹۷ معرفی شد. از آن زمان به بعد تغییرات جزئی در LSTM ایجاد شده است. مبانی که از آن در رابطه با آموزش و پیاده سازی این نوع شبکه ها مطرح میشود برگرفته از مقاله ای تحت عنوان Generating Sequences WithRecurrent Neural Networks در سال ۲۰۱۳ است.
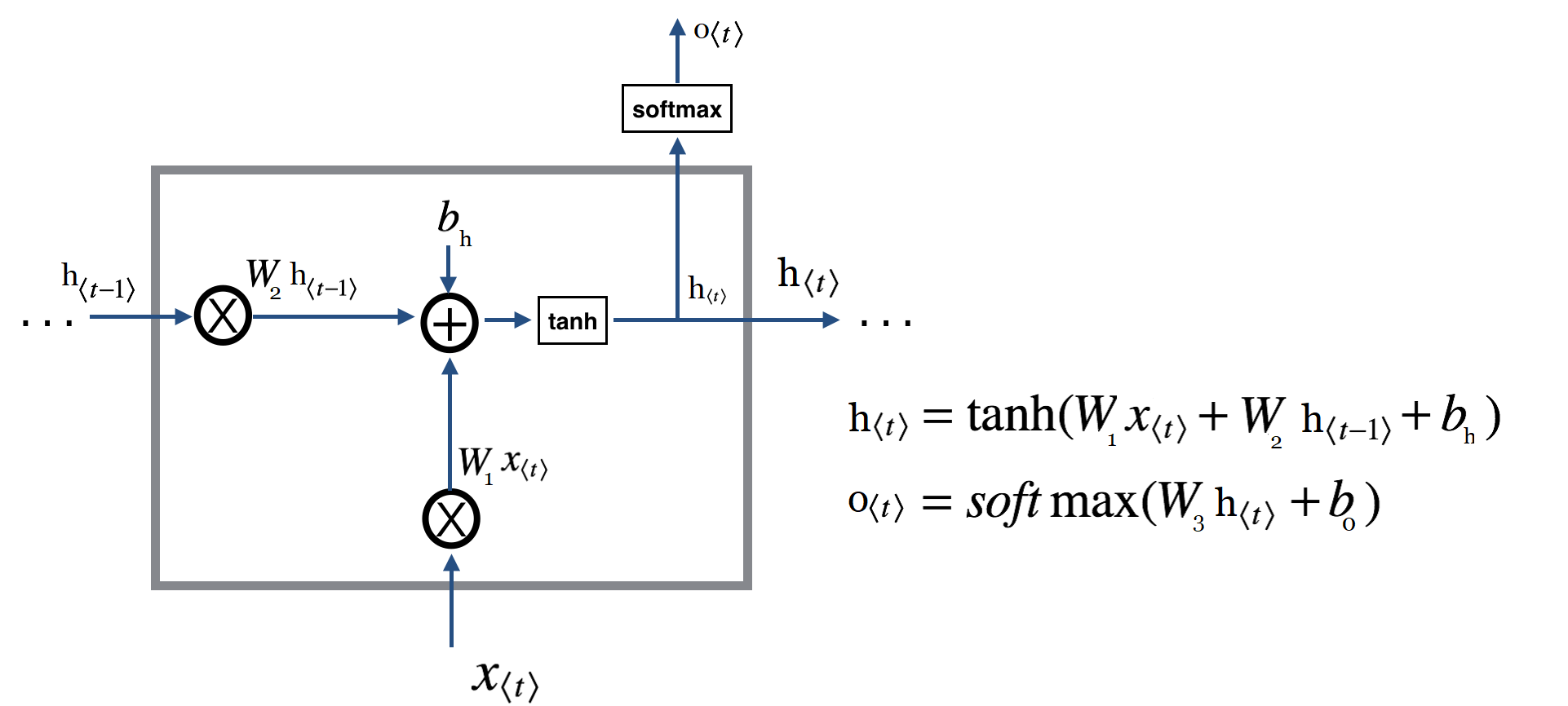
برخلاف شبکه عصبی بازگشتی سنتی که صرفا جمع متوازن سیگنالهای ورودی را محاسبه کرده و سپس از یک تابع فعالسازی عبور میدهد هر واحد LSTM از یک حافظهدر زمان
بهره میبرد. خروجی
و یا فعالسازی واحد LSTM بصورت
است که در آن
دروازه خروجی است که کنترل کننده میزان محتوایی است که از طریق حافظه ارائه میشود. دروازه خروجی از طریق عبارت
محاسبه میشود که در آن
تابع فعالسازی سیگموید است.
نیز یک ماتریس اوریب است. سلول حافظه
نیز با فراموشی نسبی حافظه فعلی و اضافه کردن محتوای حافظه جدید بصورت
بصورت
بروز رسانی میشود که در آن محتوای حافظه جدید از طریق عبارت
بدست می آید. آن میزان از حافظه فعلی که باید فراموش شود توسط دروازه فراموشی
کنترل میشود و آن میزانی از محتوای حافظه جدید که باید به سلول حافظه اضافه شود توسط دروازه بروزرسانی (یا بعضا به دروازه ورودی معروف است) انجام میگیرد. این عمل با محاسبات زیر صورت میگیرد :
اما همه این مفاهیم به چه معناست؟ اجازه دهید بصورت دقیق همه موارد را با هم مرور کنیم تا به درک بهتری برسیم.
توضیح مفاهیم
چرا این حرف را میزنیم؟ از کجا متوجه شدیم ؟

![\Gamma_f = \sigma(W_f . [ h_{t-1}, X_{t} ] + b_f)](http://deeplearning.ir/wp-content/ql-cache/quicklatex.com-f71a7e1f817bba5cf23c6ddf24bdf6a8_l3.png "Rendered by QuickLaTeX.com")
![\Gamma_u = \sigma(W_u . [ h_{t-1}, X_{t} ] + b_u)](http://deeplearning.ir/wp-content/ql-cache/quicklatex.com-2b27de563df7e132feeef0f6aeda71e5_l3.png "Rendered by QuickLaTeX.com")
اما این روابط به چه معنا هستند و چگونه به رفع محدودیتی که از آن صحبت کردیم کمک میکنند؟
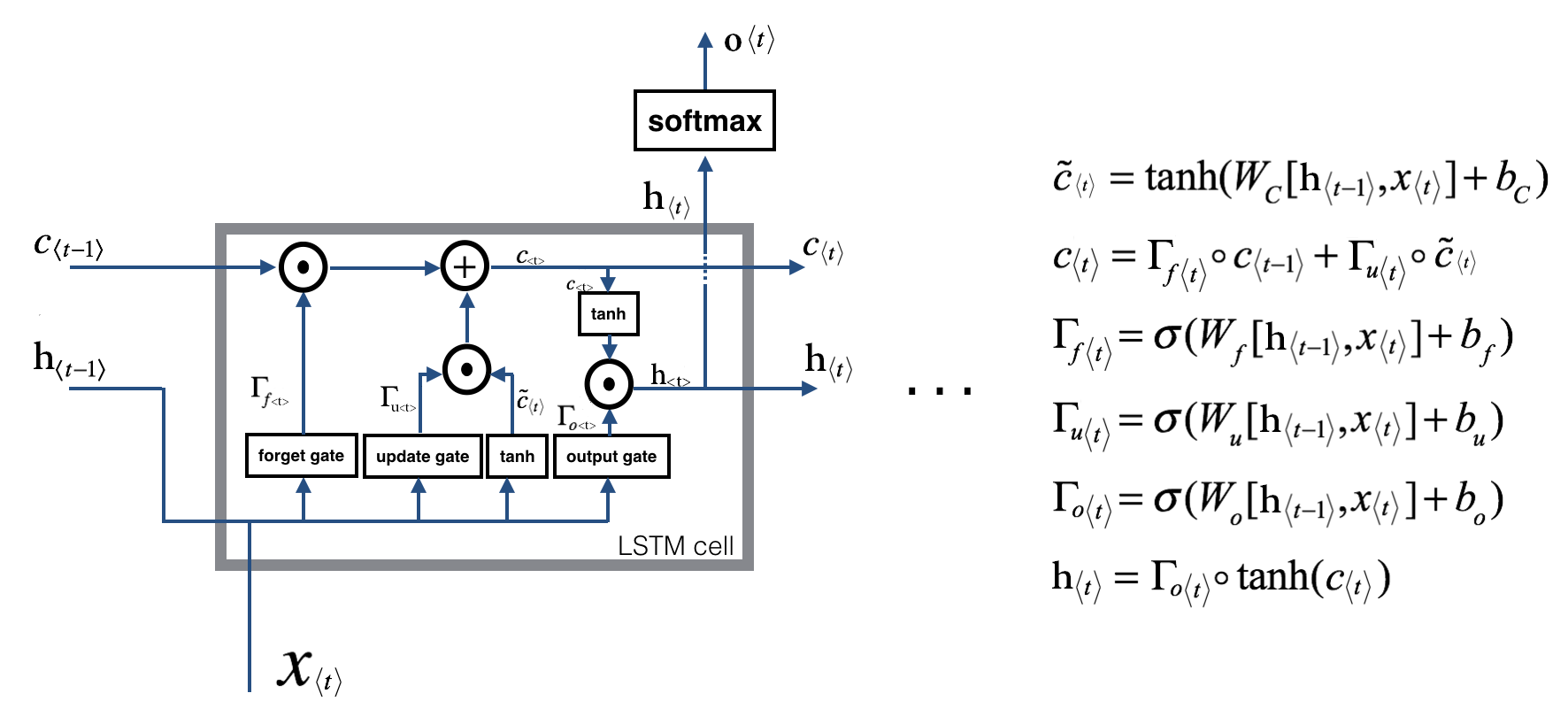
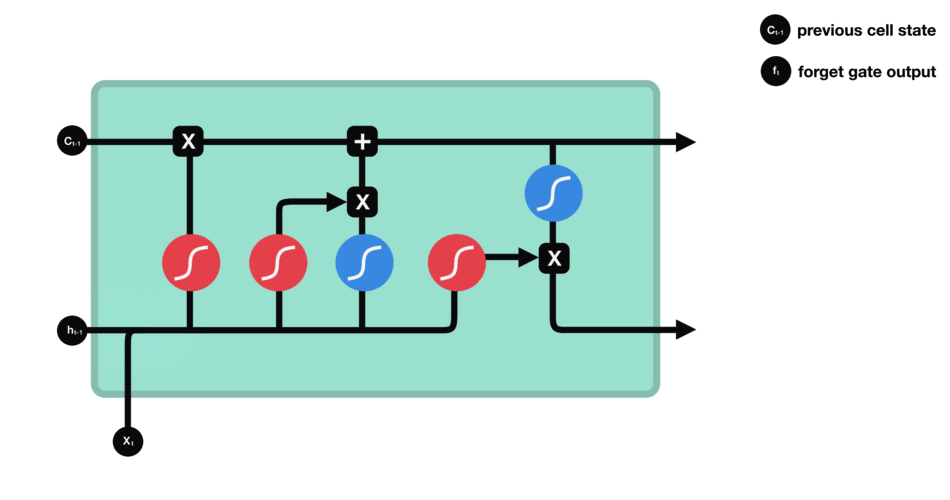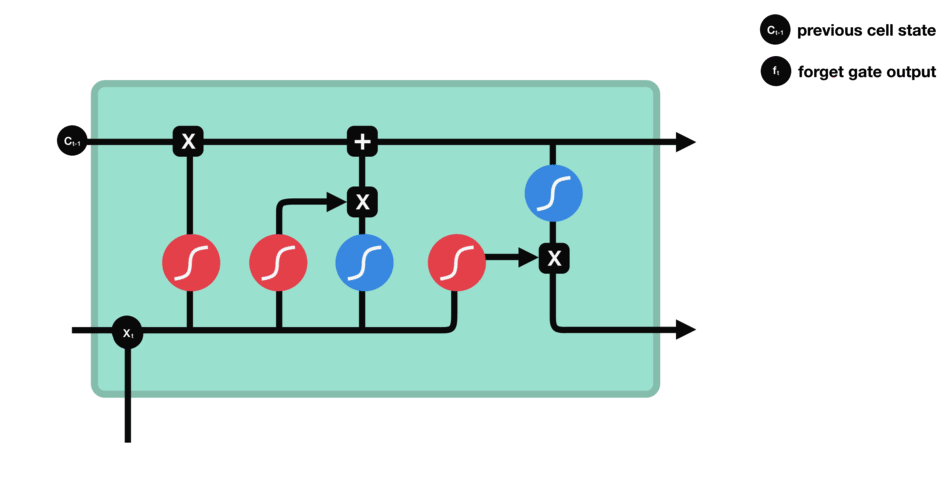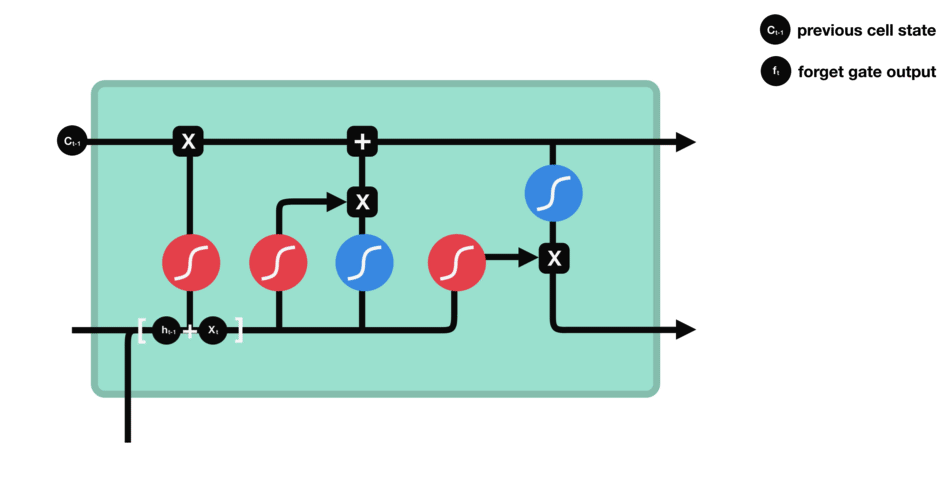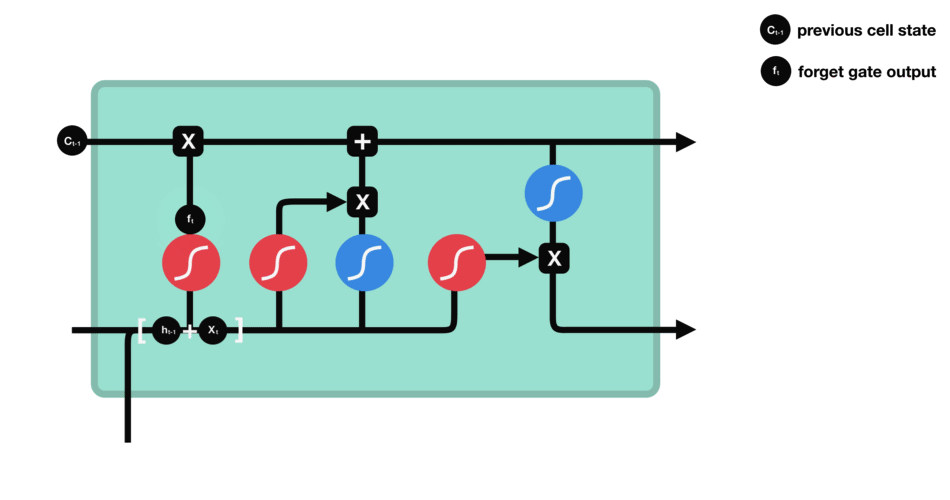
- دروازه نسیان یا فراموشی (Forget gate)
- دروازه بروزرسانی (Update gate) (به دروازه ورودی یا Input gate هم معروف است)
- و دروازه خروجی (Output gate)
و خروجی دیگر است که خود به دو بخش تقسیم میشود بخشی به گام زمانی بعد منتقل شده و بخشی نیز در صورت نیاز به تولید خروجی در گام زمانی فعلی مورد استفاده قرار میگیرد.) با بردار حافظه
با بردار حافظه  یکسان نیست! و این دو کارکردهای متفاوتی دارند.
یکسان نیست! و این دو کارکردهای متفاوتی دارند.خب حالا چطور این دروازه ها محدودیتهایی که صحبتش را کردیم مرتفع میسازند؟
نمایش داده شده است، وظیفه کنترل جریان اطلاعات از گام زمانی قبلی را دارد. این دروازه مشخص میکندآیا اطلاعات حافظه از گام زمانی قبل مورد استفاده قرار گیرد یا خیر و اگر بایداز گام زمانی قبل چیزی وارد شود به چه میزان باشد. نمایش داده شده است، وظیفه کنترل جریان اطلاعات جدید را بر عهده دارد. این دروازه مشخص میکند آیا در گام زمانی فعلی باید از اطلاعات جدید مورد استفاده قرار گیرد یا خیر و اگر بلی به چه میزان. از این دروازه عموما به دروازه ورودی نیز یاد میشود. نمایش داده شده است، نیز مشخص میکند چه میزان از اطلاعات گام زمانی قبل با اطلاعات گام زمانی فعلی به گام زمانی بعد منتقل شود.
نمایش داده شده است، وظیفه کنترل جریان اطلاعات جدید را بر عهده دارد. این دروازه مشخص میکند آیا در گام زمانی فعلی باید از اطلاعات جدید مورد استفاده قرار گیرد یا خیر و اگر بلی به چه میزان. از این دروازه عموما به دروازه ورودی نیز یاد میشود. نمایش داده شده است، نیز مشخص میکند چه میزان از اطلاعات گام زمانی قبل با اطلاعات گام زمانی فعلی به گام زمانی بعد منتقل شود.دروازه فراموشی :
 ماتریس وزنی است که رفتار دروازه فراموشی را کنترل میکند. در بخش قبل دیدیم که برای سادگی کار چطور بردارهای
ماتریس وزنی است که رفتار دروازه فراموشی را کنترل میکند. در بخش قبل دیدیم که برای سادگی کار چطور بردارهای  و
و  را با هم ترکیب میکنیم و در یک عملیات آنها را شرکت میدهیم. (برای مرور اینجا را ببینید). اگر ما عملیات فوق را انجام دهیم چون از تابع فعالسازی سیگموید استفاده میکنیم نتیجه برداری بنام خواهد بود که مقادیری بین ۰ و ۱ خواهد داشت. این بردار سپس در عبارت بعدی در
را با هم ترکیب میکنیم و در یک عملیات آنها را شرکت میدهیم. (برای مرور اینجا را ببینید). اگر ما عملیات فوق را انجام دهیم چون از تابع فعالسازی سیگموید استفاده میکنیم نتیجه برداری بنام خواهد بود که مقادیری بین ۰ و ۱ خواهد داشت. این بردار سپس در عبارت بعدی در  ضرب خواهد شد. بنابر این اگر مقادیر بردار دروازه فراموشی صفر باشد(یا به سمت صفر میل کند) عملا به معنای در نظر نگرفتن محتوای است. به عبارت ساده تر یعنی شبکه اطلاعات ارائه شده توسط را دور انداخته و هیچ توجهی به آن نمیکند. به همین صورت اگر مقادیر بردار ۱ باشد این اطلاعات توسط شبکه حفظ میشود.مقادیر مابینی نیز موجب میشود شبکه به همان میزان از محتوای ارائه شده از گام زمانی قبل استفاده کند(یعنی بخشی را دور ریخته و از بخش دیگر استفاده کند).
ضرب خواهد شد. بنابر این اگر مقادیر بردار دروازه فراموشی صفر باشد(یا به سمت صفر میل کند) عملا به معنای در نظر نگرفتن محتوای است. به عبارت ساده تر یعنی شبکه اطلاعات ارائه شده توسط را دور انداخته و هیچ توجهی به آن نمیکند. به همین صورت اگر مقادیر بردار ۱ باشد این اطلاعات توسط شبکه حفظ میشود.مقادیر مابینی نیز موجب میشود شبکه به همان میزان از محتوای ارائه شده از گام زمانی قبل استفاده کند(یعنی بخشی را دور ریخته و از بخش دیگر استفاده کند).دروازه بروزرسانی:
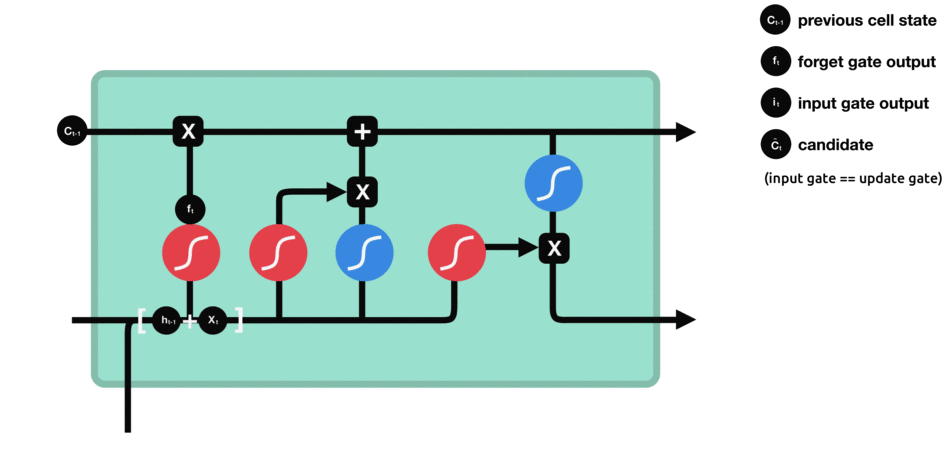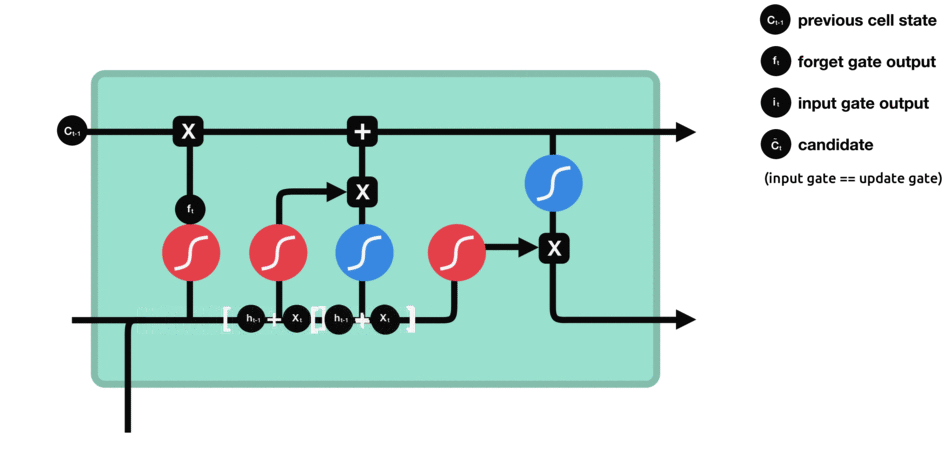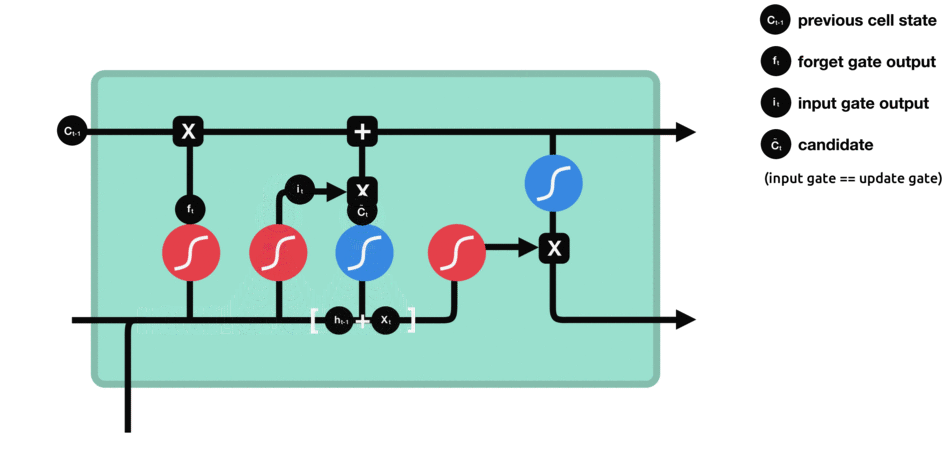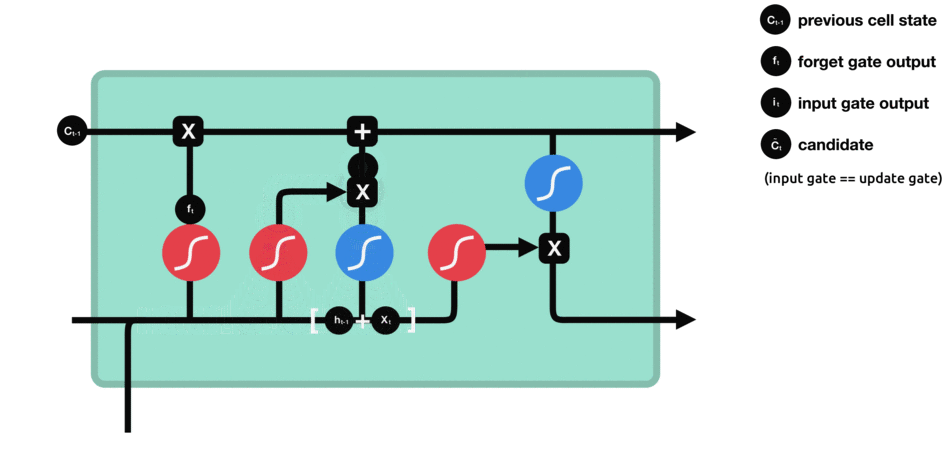
و در آخر هم حافظه را بروز رسانی میکنیم :
در عبارت فوق بخش ابتدایی مشخص کننده این است که چه میزان اطلاعات از بخش قبل(حافظه از گام زمانی قبل) استفاده شود و بخش دوم حاوی اطلاعات جدید است که مورد استفاده قرار میگیرد.
دروازه خروجی :
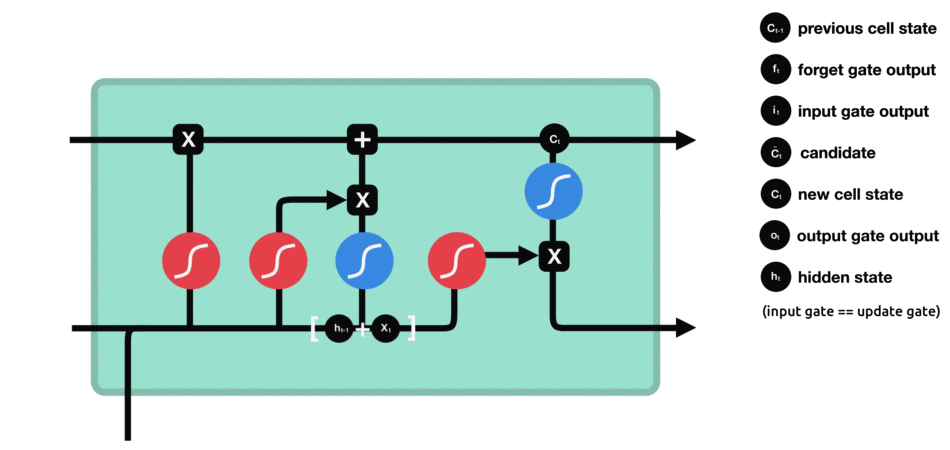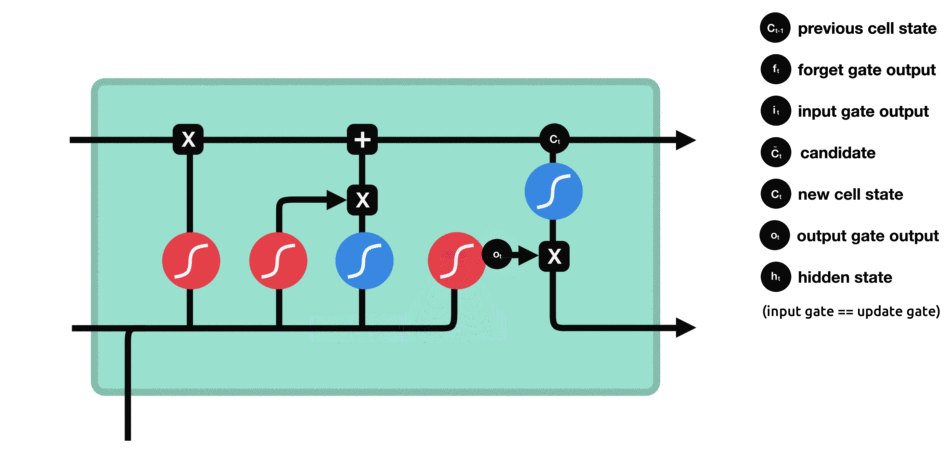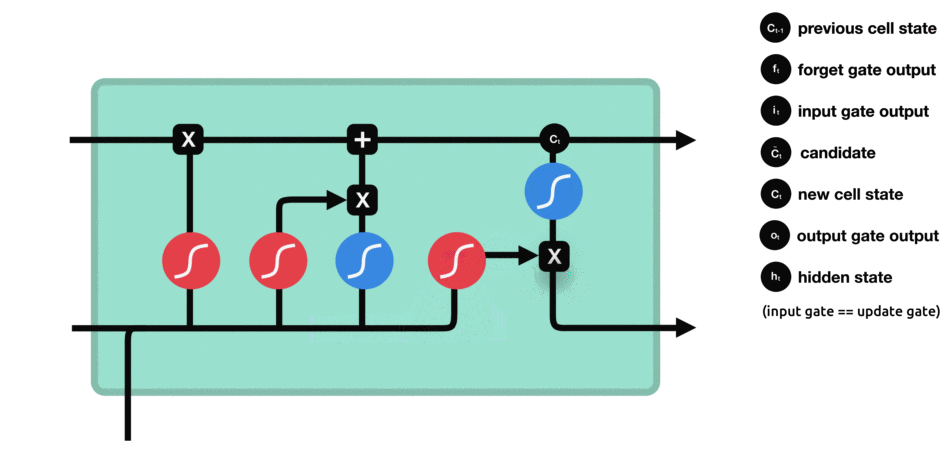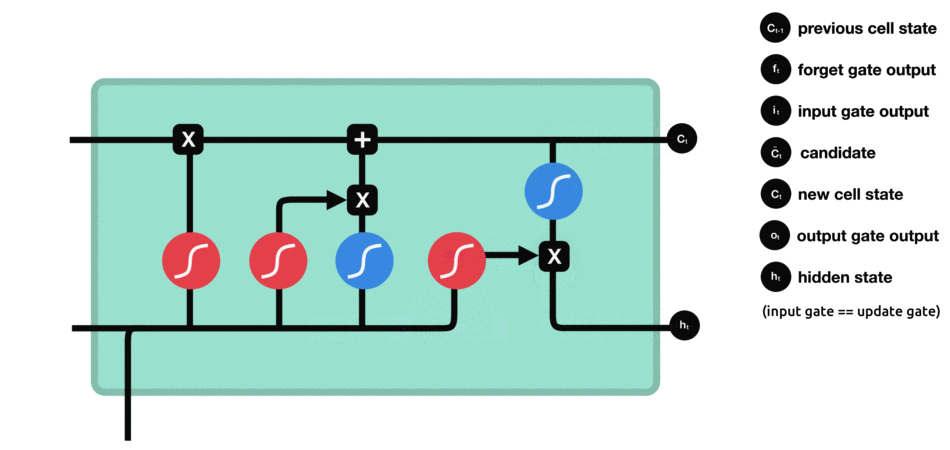
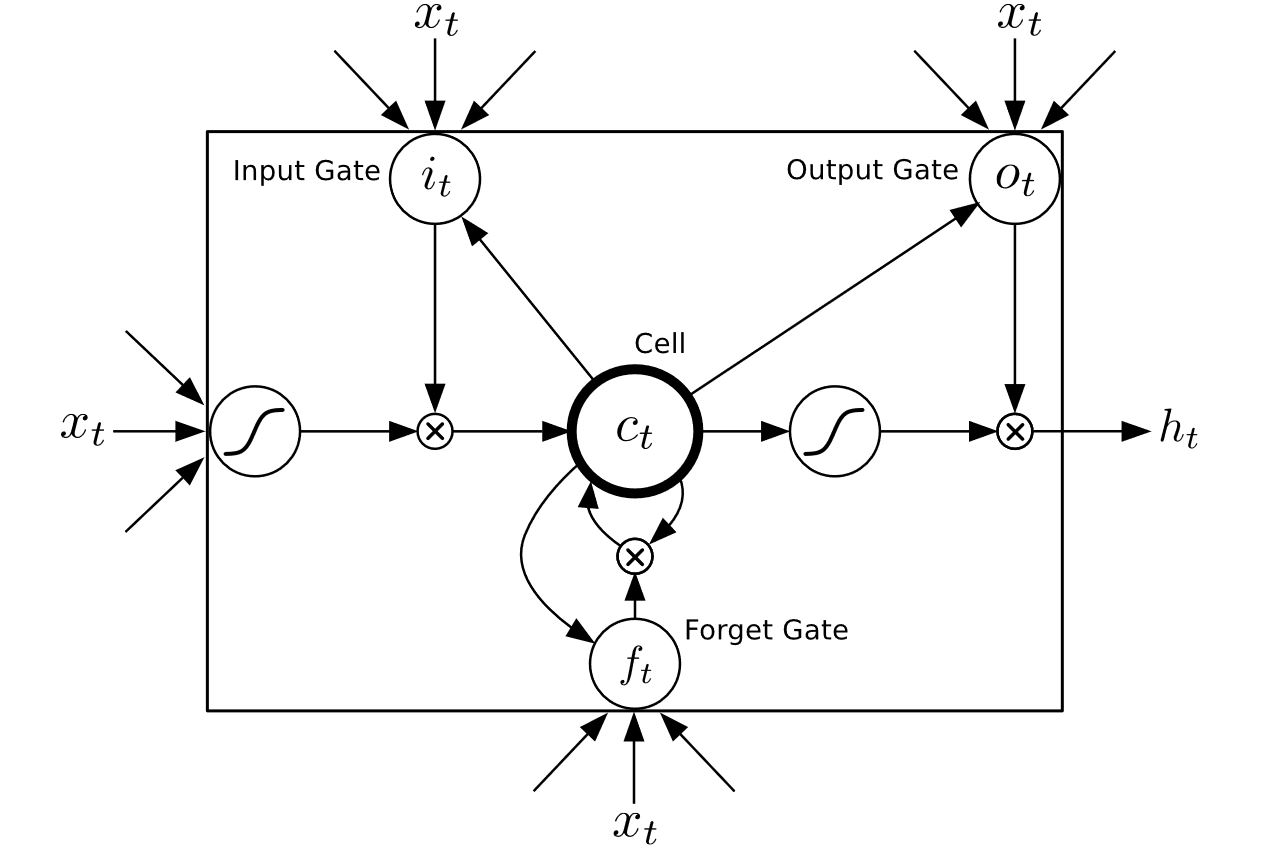
تصویر و عملیات اصلی LSTM برابر آنچه در مقاله اصلی آمده است بصورت زیر است.
همانطور که مشاهده میکنید تصویر ارائه شده ما پیچیدگی کمتری دارد و اکنون شما باید براحتی بتوانید نمادها و عملیاتهای رخ داده در زیر را درک کنید.




روابط فوق بصورت زیر نیز ارائه میشوند :




همانطور که از شیوه نامگذاری در عبارات فوق بر می آید تابع سیگموید بوده و 

 و
و  به ترتیب بردارهای مربوط به دروازه ورودی(یا همان دروازه بروزرسانی)، دروازه فراموشی، دروازه خروجی و سلول حافظه میباشند که همگی آنها دارای اندازه یکسان و برابر با اندازه بردار حالت مخفی h هستند. اندیس ماتریسهای وزن نیز به آنچه که از نام آنها بر می آید اشاره میکنند بعنوان مثال
به ترتیب بردارهای مربوط به دروازه ورودی(یا همان دروازه بروزرسانی)، دروازه فراموشی، دروازه خروجی و سلول حافظه میباشند که همگی آنها دارای اندازه یکسان و برابر با اندازه بردار حالت مخفی h هستند. اندیس ماتریسهای وزن نیز به آنچه که از نام آنها بر می آید اشاره میکنند بعنوان مثال  به معنای ماتریس وزن مربوط به ضرب حالت پنهان با بردار دروازه ورودی است، به همین شکل
به معنای ماتریس وزن مربوط به ضرب حالت پنهان با بردار دروازه ورودی است، به همین شکل  نیز به معنای ماتریس وزن مربوط به ضرب بردار دروازه ورودی با بردار دروازه خروجی است و همینطور الی آخر. ماتریس های وزن مربوط به سلول حافظه و بردار دروازه (مثل
نیز به معنای ماتریس وزن مربوط به ضرب بردار دروازه ورودی با بردار دروازه خروجی است و همینطور الی آخر. ماتریس های وزن مربوط به سلول حافظه و بردار دروازه (مثل  بصورت مورب (diagonal) هستند بنابر این درایه m ام در هر بردار دروازه فقط ورودی از درایه m ام بردار سلول حافظه را دریافت میکند. عبارات بایاس (که با i,f,c و o به ترتیب مشخص شده اند) برای وضوح بیشتر حذف شده اند. الگوریتم LSTM اصلی از یک روش خاص برای محاسبه گرادیان استفاده میکرد که به آن اجازه میداد وزنها بعد از هر گام زمانی بروزرسانی شوند. اما در اینجا گرادیان ها از طریق “الگوریتم پس انتشار خطا در زمان” محاسبه میشوند. یک مشکل که در زمان آموزش LSTM خود را نمایش میدهد این است که مقادیر گرادیان ها بشدت بزرگ میشوند که در نتیجه این مساله باعث رخداد خطا میشود(سر ریز و..) برای جلوگیری از این مشکل از روش gradient clipping بهره برده میشود تا اینطور مقادیر آن در گستره از پیش مشخص شده قرار گیرند.
بصورت مورب (diagonal) هستند بنابر این درایه m ام در هر بردار دروازه فقط ورودی از درایه m ام بردار سلول حافظه را دریافت میکند. عبارات بایاس (که با i,f,c و o به ترتیب مشخص شده اند) برای وضوح بیشتر حذف شده اند. الگوریتم LSTM اصلی از یک روش خاص برای محاسبه گرادیان استفاده میکرد که به آن اجازه میداد وزنها بعد از هر گام زمانی بروزرسانی شوند. اما در اینجا گرادیان ها از طریق “الگوریتم پس انتشار خطا در زمان” محاسبه میشوند. یک مشکل که در زمان آموزش LSTM خود را نمایش میدهد این است که مقادیر گرادیان ها بشدت بزرگ میشوند که در نتیجه این مساله باعث رخداد خطا میشود(سر ریز و..) برای جلوگیری از این مشکل از روش gradient clipping بهره برده میشود تا اینطور مقادیر آن در گستره از پیش مشخص شده قرار گیرند.
- اول اینکه هر واحد براحتی قادر است یک ویژگی خاص در جریان ورودی را در صورت مهم تلقی شدن برای گام های زمانی طولانی بعدی بیاد داشته باشد. هر ویژگی ای که توسط دروازه بروزرسانی GRU یا دروازه فراموشی LSTM مهم تشخیص داده شود بدون اینکه رونویسی شود به همان حالت باقی مانده و منتقل میشود.
- نکته دوم و شاید مهمتر اینکه این مکانیزم های جدید در عمل مسیرهای میانبری ایجاد میکنند که چندین گام زمانی را ندید گرفته و پشت سر میگذارند (از روی چندین گام زمانی میپرند) این میانبرها به همین صورت به خطای تولیدی اجازه میدهد تا بدون آنکه خیلی سریع محو شود براحتی در فاز پس انتشار منتقل گردد و اینطور معضلات مرتبط با گرادیان های محو شونده کاهش میابد.
با سلام و تشکر از زحماتی با ارزشی که می کشید
پیشنهادی داشتم اینکه فونت مطالب رو تغییر دهید مثل Samim که توی سایت dotnettips.ir هستش یا فونت ایران سنس
اینجوری خوندنش آسونتر میشه
بازم ممنونم از تمامی زحماتی که بابت آموزش این مطالب کمیاب توی زبان فارسی
سلام
خیلی ممنونم هم از نظر لطفتون و هم از پیشنهادت خوبتون. حتما در نظر میگیرم.
قالب سایت قراره تغییر بکنه و حتما فونت پیشنهادی شما رو هم تست میکنم ببینم اگر در قالب جدید خوب نمایش داده میشه انشاءالله استفاده میکنیم.
سلام
خیلی خوب شد خدا قوت
سلام.
خیلی ممنون از پیشنهاد خوب شما که من رو با این فونت آشنا کردید!
سلام
از مطالب مفید سایتتون بسیار تشکر میکنم. توضیح مطالب و نحوه بیان مسئله و پاسخ دهی به آن بسیار شیوا و تا حد امکان ساده و قابل فهم بیان شده.
واقعا خدا قوت.
اگر ممکنه یک مثال در مورد نحوه استفاده lstm در مورد مدل کردن ساختار یک جمله بیان کنید. در توضیحاتتون کمی درمورد نوع فاعل توضیح دادید که البته به فهم ساختار کمک کرد. ولی من دنبال یک مثال کامل و هدفمند هستم.
سلام.
انشاءالله فرصت بکنم این کارو انجام میدم. (در برنامه اولیه ام برای این مجموعه آموزش این رو در نظر داشتم منتها باید وقت آزاد پیدا کنم تا مفصل بشه نوشت و توضیح داد)
خیلی ممنون بابت تمام آموزش هاتون
بسیار عالی و مفید هستkد
خداقوت
فقط اگر لطف بفرمایید طبق نظر دوستان یک مثال هم از شبکه lstm قرار دهید
سلام
انشاءالله در اولین فرصت این کار رو انجام میدم. در حال حاضر سرم خیلی شلوغ هست.
سلام ممنون از این مطالب آموزشی عالی آموزش شما درمورد rnn ها خیلی به من کمک کرد.
ابهامی برای من ایجاد شده در مورد شبکه بازگشتی چند لایه… وقتی ما دیتایی با timestep=10 به لایه ورودی یک شبکه LSTM که تعداد ۱۰ بلوک LSTM در لایه اول داره وارد میکنیم هر دیتای ورودی به یک بلوک LSTM وارد میشه در لایه بعد ما مثلا ۱۰۰ بلوک LSTM داریم ۱۰ خروجی لایه اول به چه صورت به ۱۰۰ ورودی لایه دوم اعمال میشه؟
ابهام بعدی این که آیا خروجی Ctو ht از لایه اول به لایه دوم منتقل میشه؟ یا Ctو ht هر لایه به همان لایه اعمال میشه؟ اطلاعات حافظه به چه صورت از یه لایه به لایه بعد منتقل میشه؟
سلام بخش اول رو دقیق متوجه نشدم میشه واضح تر توضیح بدید؟
برای بخش دوم این میتونه به صورت های مختلفی پیاده سازی بشه اما چیزی که شاید نرمال تر باشه این هست که هر لایه ct, ht مستقل داره .
سلام ممنون که جواب دادید… درمورد قسمت اول سوال توی لایه اول به ازای هر دیتای ورودی timestep یک بلوک LSTM داریم مثلا timestep=10 و ۱۰ بلوک LSTM داریم
هر بلوک لایه اول یک خروجی داره که به لایه دوم میره اگه در لایه دوم هم ۱۰ بلوک داشته باشیم هر خروجی لایه اول به یک بلوک وارد میشه ولی اگه تعداد بلوک های لایه دوم بیشتر یا کمتر از خروجی لایه اول باشه اتصالات بین لایه اول و دوم به چه صورت وصل میشه؟
درمورد قسمت دوم سوال اگه Ct , Ht هر لایه مستقل باشه دراین صورت اطلاعات حافظه از لایه اول چجوری به لایه های بعد منتقل میشه؟
سلام.
این بحث بلوک LSTM رو متوجه نمیشم! ما یه سلول lstm داریم که روی یک ورودی کار میکنه هر گام یک بخش از داده به اون ارائه میشه محاسبات انجام میشه اطلاعات مربوط به حالت نهان و حافظه در بین گام های زمانی مشترک هست (اینطور هم میشه گفت که هر داده ورودی(مربوط به یک گام زمانی) به یک سلول اختصاص پیدا میکنه یا باز به عبارت بهتر یک لوپ داریم و…) اینکه میگید هر بلوک لایه اول یک خروجی داره که به لایه دوم ! میره اینجا خبری ازلایه دوم نیست! منظورتون به سلول lstm بعدی هست؟ (بهتره بگیم یک سری اطلاعات از گام زمانی فعلی به گام زمانی بعدی منتقل میشه منظورتون اینه؟ یا اینکه نه یک لایه LSTM داریم و بعد از اون یک لایه LSTM دومی داریم (اشاره به Stacked LSTM دارید؟)
اگه بحثتون Stacked LSTM باشه باید دقت کنید که ورودی و خروجی شما باید متناسب با کارتون باشه. لایه اول که ارتباط با داده شما بصورت مستقیم داره عموما اینطور هست که به ازای هر گام زمانی یک خروجی تولید میکنه و این خروجی به مثابه ورودی برای لایه LSTM دوم هست (میتونید فکر کنید یک رپرزنتیشن جدید از داده ورودی هست که به لایه دوم داره ارائه میشه) و پردازش لایه دوم هم بصورت معمول طی میشه. البته این یک سناریو (معمول) هست و میشه طرح های مختلفی رو پیاده کرد.
در مورد بخش دوم باید بدونیم که حافظه نهان (ht) بعنوان خروجی منتقل میشه و میشه بعنوان ورودی لایه دیگه از اون بهره گرفت (معمولا از خروجی ازش یاد میشه و دیگه بهش حافظه نهان نمیگن ولی از نظر عملی چیزی جلوی شما رو نمیگیره ازش استفاده نکنید). همونطور که بالا گفتم یکی از سناریوها این هست و در این سناریو حافظه نهان و حافظه سلولی (بلند مدت) برای بدست دادن یک رپرزنتیشن جدید در لایه فعلی استفاده میشن و بعد این رپرزنتیشن به لایه بعدی داده میشه و اونجا با استفاده از ht و ct سعی میشه ساختارهای جدید بصورت جداگانه بدست بیاد. همینطور که میبینید هر لایه بصورت مستقل داره عملیاتی رو انجام میده که الزاما نیازی به حافظه از مرحله قبل میتونه نداشته باشه. میتونید هم اونو لحاظ کنید. در برخی از کاربردهایی که داده های ورودی بهم وابستگی دارن شاید این کار نتایج بهتری ارائه کنه.
ممنون ازجواب تفصیلی که داداید… بله منظور از بلوک همون سلول هست …بحث Stacked LSTM هست … از جواب شما برداشت من اینه که در حالت معمول Ot از لایه اول به عنوان رپرزنتشن به ورودی لایه دوم میره و همچنین میتونیم از Ct , Ht لایه اول هم برای رپرزنتیشن به لایه دوم استفاده کنیم که این باعث میشه حافظه سلولی و نهان به لایه بعد منتقل بشه… توی حالت معمول که Ot لایه اول به لایه دوم اعمال میشه ما برای لایه دوم میتونیم هرتعدادی از سلول LSTM درنظر بگیریم (مستقل از تعداد سلول های لایه اول و به تبع اون تعداد Ot های لایه اول) در صورتی که در لایه اول این امکان وجود نداره چون ما در لایه اول باید به تعداد timestep سلول درنظر بگیریم «اینطور هم میشه گفت که هر داده ورودی(مربوط به یک گام زمانی) به یک سلول اختصاص پیدا میکنه» . سوال این بود که ما N سلول در لایه اول داریم و M سلول در لایه دوم. این N عدد Ot لایه اول به چه صورت به M عدد سلول لایه دوم اعمال میشه؟
باز هم ممنون بخاطر وقتی که برای جواب دادن میذاری
بله دیفالت اکثر فریم ورکها در Stacked LSTM این هست من جمله پای تورچ .
خروجی های لایه اول شما بعنوان ورودی به N سلول LSTM لایه دوم اعمال میشه مابقی هم از خروجی گام زمانی قبلش میتونه تغذیه بشه مگر اینکه شما خودتون طرح خاصی مد نظرتون باشه.
یک نکته فقط اینکه شما دنبال افزایش قدرت lstm هستید؟ برای این دارید این سوال رو میپرسید؟ اگر آره
ملاک افزایش قدرت لایه lstm اندازه لایه نهان و تعداد لایه هاست. stacked lstm چیز جز اعمال چند لایه lstm پشت سر هم نیست! دیگه خودتون در نظر بگیرید.
در کراس یه لایه ای به نام timedisterbution وجود داره اگر ممکنه در مورد این لایه و کاربرد اون توضیحی بفرمایید
سلام. مستندات کراس رو مطالعه کردید؟ اینجا توضیحات کامل رو داده .بطور خلاصه این لایه بشما اجازه میده تا یک لایه رو بر روی تک تک دنباله ها بصورت مستقل از هم اعمال کنید
منظور از تک تک دنباله ها چیه ؟ مگه ما یک دنباله ورودی بیشتر داریم؟
منظور ایتم های هر دنباله اس.
سلام آقای حسن پور
سوالی خدمتتون داشتم
اگه داده های کافی برای آموزش نداشته باشیم و یا اینکه داده ها به تعداد کم در هر فاصله زمانی به ما برسه (مثل یاددادن یک مبحث خاص توسط مدرس به دانش آموزان، که دانش آموز به مرور یادمیگیره) باید چطوری به مدلمون اینو یادبدیم تا بازدهیش هم کاهش پیدا نکنه
آیا فقط با Reinforcement Learning (یادگیری تقویتی) میشه اینو حل کرد؟
برای یادگیری تقویتی، گوگل dopamin رو داده آیا بهتر از این هم وجود داره فعلا؟
و آیا همه مسائلی که تا الان توی هوش مصنوعی مطرح شدن (مثل پردازش صوت متن تصویر و ..) رو میشه با دوپامین حل کرد یا اینکه هنوز کار خاصی نمیشه باهاش انجام داد (نمونه زیادی ازش توی اینترنت ندیدم)؟
سلام.
من متاسفانه وارد حوزه RL نشدم و اطلاعاتم سطحیه برای همین نمیتونم اظهار نظری در این مورد داشته باشم.
اگر بحث رو جدای RL در نظر بگیریم در مورد کمبود داده اموزشی باید همون مسیر دیتا اگمنتیشن و یا ترنسفر لرنینگ طی بشه
اگر به هر دلیلی ممکن نباشه باید سویچ بشه به روش های دیگه ( سیستم های خبره و…)
با سلام
بنده مدتی است دارم تلاش میکنم این ساختار lstm را برای دستهبندی چندین گونه از داده متنی بکار ببرم اما مشکلات بسیاری دارم با اجازه برخی از آنها را میپرسم و در صورتی که لازم بود ممنون میشم بتوانم با ایمیل سوالاتم را کامل بپرسم چرا که واقعا کسی نیست مطالب را بهم یاد بده.
اول از همه نمیدونم فرمت داده که قرار است دستهبندی شود به چه صورتی باشد تا بتوانم به lstm بگویم به پنج دسته تقسیم کن
دوم بنده با استفاده از word2vec بردارهای واژگانی دارم اما باز هم نمیدانم چگونه آن را با برنامه پایتون نمایش دهم که بتواند برای هر سند دستهبندی را انجام دهد. بیشتر سوالاتم مربوط به برنامه نویسی های آن است که نمیدانم در کل چطور داده هایم را که ۵ دسته گوناگون را شامل میشود با برنامه دستهبندی کنم
سلام.
داده شما لیبل داره یا نه؟ به چه فرمی هست دیتاست شما؟
سلام و عرض ادب
ممنون از مطالب ارزشمندتون ….. من یک مجموعه ای از داده ها دارم شامل ۱۰۰۰ گام زمانی و در هر گام زمانی، ۹ پارامتر رو دارم که فقط ۶ تا از اون ۹ پارامتر تغییر میکنه. میخواستم با جعبه ابزار متلب، شبکه م رو طراحی کنم ولی نمیدونستم که چه تعداد سلول lstm لازم دارم یا سلول fully connected . بر اساس هلپ نرم افزار ، اشاره کرده که یک لایه ورودی، یه لایه مموری، یک لایه اتصال کامل و یک لایه هم خروجی رگرسیون ولی نمیدونم که برای مثال من هم همین کاربرد داره یا نه؟ ضمن اینکه اگر بخوام دیتاست رو وارد سیستم کنم باید یکپارچه باشه و برای هر گام زمانی لیبل داشته باشه؟ آیا امکان ش هست که نمونه ای از یک شبکه رو اینجا هم قرار بدید ببینیم چطور میشه طراحی کرد؟ ممنون
سلام
من متاسفانه متلب کار نمیکنم و در این زمینه نمیتونم کمکی خدمتتون بکنم
بسیار عالی
از زحمات شما متشکرم
سلام.
با تشکر از مطالب خیلی مفیدتان.
در کامنت های بالا ذکر کردید که منظور از stacked lstm چند لایه lstm پشت سر هم هست. تکنیکی که من باید پیاده سازی کنم stack-GRU هست و مقاله در این رابطه به آدرسی که در پایین قرار دادم ارجاع داده و من مقاله ارجاع داده شده رو مطالعه کردم. از لیست و اپراتورهای pushوpop استفاده کرده. حالا سوالم اینه که باید از صفر پیاده سازی بشه (که این طور فکر می کردم) یا اینکه به سادگی چند لایه GRU از کراس قرار بدم و تمام؟!(آیا push و pop رو در پشت صحنه دارن؟!)
سوال دیگری هم داشتم، پیاده سازی گرادیان ها در GRU به نظر خیلی پیچیده میاد آیا ابزاری هست که بشه همه کار محاسبه گرادیان ها رو با اون انجام داد و فاز backpropagation راحتتر پیاده سازی بشه؟
http://arxiv.org/abs/1503.01007
با سلام و عرض تشکر از شما
میخواستم بپرسم که آیا تعداد lstm باید با تعداد سلول های ورودی یکی باشه؟ و این که آیا تعداد نرون میانی همان تعداد lstm هست؟
ممنون از شما…
سلام.
به چه صورت LSTM میتونه ویژگی های مهم را شناسایی کند؟
سلام
به چه صورت LSTM میتونه ویژگی های مهم را شناسایی کند؟