
بسم الله الرحمن الرحیم
هفته گذشته کارگاه چند روزه ای داشتیم و موارد مختلفی پوشش داده شد. من سعی میکنم بعضی از مطالبی که در کارگاه بیان شد رو اینجا هم عنوان کنم و یکسری توضیحات که اونجا وقت نشد بیشتر توضیح داده بشن اینجا عنوان کنم.(البته سر فرصت)
در این پست میخوایم بطور مختصر در مورد معماری ResNet صحبت کنیم و ببینیم ایده اصلی چه چیزی بوده و داستان residual block از چه چیزی نشات گرفته.
معرفی کوتاه معماری ResNet :
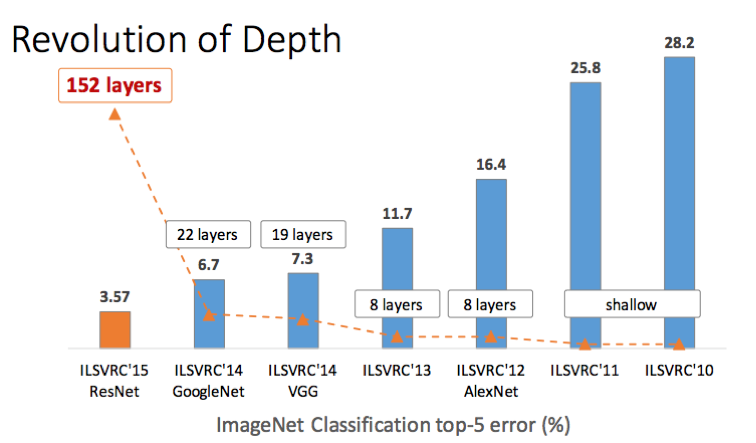
معماری ResNet ، در سال ۲۰۱۵ معرفی شد و تونست رقابتهای زیادی رو برنده بشه. این معماری با عمق ۱۵۲ لایه ، عمیق ترین معماری تا اون سال شناخته میشه و بعد از اون هم کماکان یکی از عمیق ترین هاست. البته نسخه های مختلفی ازاون معماری وجود داره که بسته به نیاز مورد استفاده قرار میگیرن.
دقت کنید بحث دو بخشیه . در بخش اول ما یک توضیح میدیم مشکل اصلی چیه و در ادامه بحث باز میشه. در بخش دوم هم یک سری نکات و توضیحات مطرح میشه تا یکسری نکات مبهم مشخص تر بشه. اگر هم نکته ای مبهم باقی موند در کامنت بپرسید تا توضیح داده بشه.
اصل داستان در باره چیه؟
اصل داستان بر میگرده به مساله degradation یا کاهش. کاهش چی؟ کاهش دقت آموزش (training accuracy degradation). دوباره یعنی چی ؟ تا قبل از معرفی ResNet ما از خیلی سالهای پیش (دهه نود میلادی بعنوان مثال) فهمیده بودیم که با افزایش عمق (و عرض) شبکه میشه به کارایی بهتری دست پیدا کرد. این موارد بطور خاص طی سالهای قبل با معماری هایی مثل AlexNet, VGGNet, GoogleNet هم بطور مکرر تایید شد. اما یک مشکل بزرگ وجود داشت. همه این معماری ها هرچند عنوان میکردند که عمق بیشتر بهتره اما در عمل از یک حد خاصی نمیتونستن بیشتر پیش برن. مشکل اون زمان عموما vanishing gradient بود. با گذشت زمان و معرفی الگوریتم های مقداردهی بهتر و همینطور معرفی الگوریتم BatchNormalization این بحث به حاشیه رفت. حالا میشد از نظر تئوری معماری های بسیار بسیار عمیقتری رو بدون نگرانی از مواجهه با vanishing gradient توسعه داد و ترین کرد. بنابر این فرض منطقی این بود حالا که این مشکل بغرنج از سر راه برداشته شده باید بشه معماری های عمیقتری رو ترین کرد و به دقت های بهتری رسید. اما!
زمانی که شروع به افزایش تعداد لایه ها در معماری میکنیم میبینیم که دقت بهتر که نشده بدتر میشه و با افزایش تعداد لایه ها این قضیه بغرنج تر میشه. این بخاطر اورفیت کردن نیست. پس چی میتونه باشه؟ آیا این یکی از مهمترین دلایلش سیگنال ضعیف بک پراپگیشن به ورودی نیست؟ (خیلی خلاصه نه!)
قبل از جواب دادن به این سوال بزارید یک بحثی رو پیش بکشیم. برگردیم سر موضوع اصلی. بحث ما دیگردیشن هست و این نشون میده که همه سیستم ها رو به یک شکل و به اسانی نمیشه ترین (بهینه) کرد.
درمقاله اینطور شروع به معرفی مشکل شده ، بزارید اینطور به قضیه نگاه کنیم:
اگه ما یک مدل کم عمق رو در نظر بگیریم میدونیم که میتونیم یک معادل عمیق تر از اون رو با اضافه کردن یکسری لایه جدید بدست بیاریم. از نظر ساختاری یک راه حل برای مدل عمیق تر وجود داره که به همون عملکرد معمار ی کم عمق(تر) برسه. یعنی چی ؟ یعنی تمام اون لایه های اضافه شده نگاشت همانی رو انجام بدن (Identity mapping) و بقیه لایه های قدیمی هم از معماری کم عمق(تر) به این معماری منتقل شده باشن(وزنهاشون رو بیاریم اینور ). یعنی معماری عمیق ما میشه همون معماری کم عمق(تر) + لایه های همانی در ادامه اش. وجود یک همچین راه حلی نشون میده که یک مدل عمیقتر باید بتونه همون کاری که معماری کم عمق تر میکنه انجام بده ولی در عمل میبینیم این اتفاق نمی افته و solver های فعلی ما نمیتونن این راه حل رو پیدا کنن. باز یعنی وقتی ما این فرض رو انجام میدیم یعنی یک سالور هم باید بتونه با توجه به خطای شبکه تشخیص بده این لایه های اضافی جدید تابع سودمندی که باعث کاهش خطای شبکه بشه ایجاد نمیکنن پس بهتره از خروجی تابع قبلی که مقدار مناسبی داشته استفاده بشه (تابع جدید بشه همانی).
همه اینها یعنی چی ؟ یعنی مشکل معماری های عمیقتر اینه که بصورت دیفالت نمیشه یکسری لایه Identity mapping رو پیاده سازی کنن (فرابگیرن). ایده این مقاله پس چیه؟ ایده این مقاله اینه که ما کاری کنیم که این اتفاق در معماری رخ بده.
حالا در مقاله چی میگن ؟ میگن ما این مشکل رو میاییم با معرفی یک چارچوب یادگیری رزیجوآل عمیق (deep residual learning framework) حل میکنیم . میاییم بجای اینکه امیدوار باشیم چندتا لایه پشت سر هم به یک نگاشت زیرین دلخواه برسن، ما بطور صریح کاری میکنیم که این لایه ها یک نگاشت رزیجوآل رو انجام بدن. اگه نگاشت دلخواه رو H(x) در نظر بگیریم ما اجازه میدیم که چندتا لایه پشت سر هم یک نگاشت F(x) = H(x) - x رو انجام بده. بعد نگاشت اصلی رو (یعنی همینی که تازه دیدیم) میاییم تغییر کوچیکی توش میدیم و بصورت F(x) + x مینویسیمش. هرچند هر دو فرم باید بتونن هر تابعی رو تقریب بزنن اما سادگی یادگیری این دوتا میتونه کاملا با هم فرق کنه یعنی یکی ساده باشه یکی نباشه. فرض ما اینه که برای بهینه ساز انجام نگاشت ریزجول به این شکل خیلی ساده تر از رابطه اصلی باشه. بعد هم عنوان میشه که در نهایت اگه یک نگاشت همانی ، نگاشت بهینه مورد نظر باشه، نزدیک کردن مقدار رزیجوآل به صفر خیلی ساده تر از بدست اوردن نگاشت همانی توسط چند لایه کانولوشن پشت سر هم با توابع غیرخطی هست. و این شکل رو هم نشون میدن !
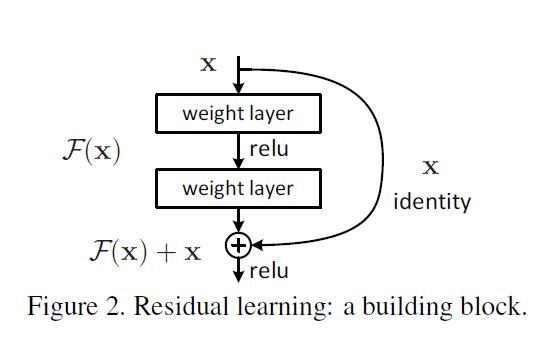
حالا همه اینها یعنی چی؟
قبل از اینکه شروع کنیم و ادامه بدیم بزارید معنی Residual رو بدونیم . این معنیش میشه باقی مونده یا خطای بین دوتا data point یا متغییر. الزاما این خطا به معنای اینکه واقعا خطایی رخ داده باشه نیست یک ملاکی هست برای اینکه ببینیم چقدر تغییر بین این دوتا دیتاپوینت یا متغییر یا دو حالت وجود داره.
اینجا ما دنبال بدست اوردن تابع همانی هستیم . درسته؟ یعنی هرچی ورودی باشه در خروجی هم قرار بگیره .
حالا شکل زیر رو در نظر بگیرید. شکل زیر ورودی ، دو لایه پشت سر هم و یک خروجی رو نشون میده

اون t1 و t2 هم یعنی مرحله ۱ و مرحله بعدش (t اصطلاحا اشاره به زمان داره . و معمولا وقتی بخواییم برای نشون دادن ترتیب استفاده کنیم از این فرمت هم استفاده میکنیم. حالت قبل و حالت بعد)
حالا برای اینکه ما identity داشته باشیم باید h(x)_t2 مساوی h(x)_t1 باشه یعنی خطای اونها صفر باشه باز یعنی
|
1 2 3 |
h(x)_t2 - h(x)_t1=0 |
h(x)_t1 رو اگر همون x خودمون بگیریم میشه h(x)_t2 - xمیشه نوشت
حالا اینو یک معادله در نظر بگیریم میشه f(x) = h(x) - x
به این میگن رزیجوال یعنی h(x) باید خودش دقیقا x رو بدست بیاره تا خطا صفر بشه و چون این کار سختیه (اگه اسون بود همون اول در اموزش انجام میشد) ما اینو به فرم زیر نوشتیم
|
1 2 3 |
h(x) = f(x)+x |
که در اینجا گفتیم تابع h(x) بطور صریح بیاد و یک رابطه ریجول رو یاد بگیره . با اینکار سالور خیلی راحت میتونه f(x) رو برابر صفر قرار بده تا h(x) = x بشه یعنی همون چیزی که ما میخوایم . یعنی تابع همانی
و این f(x)+x هم در شبکه عصبی براحتی پیاده سازی میشه با یک اسکیپ کانکشن و جمع کردن اون با خروجی (همین چیزی که داریم). این داستان ریجوال هست .
خب حالا همه این حرفها در مورد زمانی بود که ما نیاز به تابع همانی داریم برای وقتی که افزایش لایه چیزی به قدرت بازنمایی شبکه اضافه نمیکنه . خب برای لایه هایی که تاثیر مثبت دارن چی ؟ برای اون لایه ها میشه گفت ما داریم با اسکیپ کانکشن ها و ارائه خروجی از لایه های قبلی به بعدی داریم information pool بهتری ارائه میکنیم و در نتیجه فیچرهای بهتری بدست میاریم از طرفی حالا وقتی ما این مطلب رو در قالب کل ببینیم و طی چند مرحله انجام بدیم چه اتفاقی می افته؟ قدم به قدم خطا کاهش پیدا میکنه. یا میشه اینطور گفت قدم به قدم بهبود داریم یا باز دوباره اینطور میشه گفت قدم به قدم داریم چیزی رو یاد میگیریم(تا نهایتا به تابع بهینه موردنظر برسیم در هر سطح ) به همین دلیل بهش گفتن رزیجوآل لرنینگ که میشه بهش بنوعی گفت یادگیری افزایشی (در ارائه هم فکر کنم یکی از بچه ها منظورشون این مطلب بود که فرصت نشد بعد از اتمام بخش اول دراین مورد صحبت بشه و این قضیه باز بشه (البته ما در ادامه و همینطور بخش مربوط به Maximum information utilization به این مطلب تحت مثالهایی برای ایجاد information pool های بهتر اشاره کردیم اما نیاز به توضیح بیشتر بود که اینجا داریم همین کارو میکنیم) اگه به چیز دیگه ای اشاره داشتن که در کامنت عنوان بشه خیلی خوبه) دقت کنید که در زمانی که ما نیاز به تابع همانی نداریم قرار نیست f(x)=0 بشه. اینجا f(x) خیلی ساده یک تبدیل غیرخطی از ورودی خواهد بود همون چیزی که همیشه داشتیم. و علاوه بر اون چیزی که همیشه داشتیم الان در هر سطح ما یک ورودی از مرحله قبل هم داریم که باعث میشه لایه بعدی هم به داده اصلی و هم دید بلاک قبلی از این داده برسه و اینطور بتونه سطح بالاتری از ویژگی ها رو بدست بده. باز عرض میکنم دقت کنید که بحث ما این بوده که سالور نمیتونسته برای لایه های جدیدی که چیزی به شبکه اضافه نمیکنن تابع ایدنتتی رو ارائه کنه یا تقریب بزنه . و کاری که ما کردیم این بوده که کاری کردیم بطور صریح هر وقت سالور نیاز به این کار داشت براحتی این کار قابل انجام باشه (با صفر کردن f(x) یا نزدیک کردن اون به صفر تا تابع همانی یا تقریب خوبی از اون رو بدست بده) و در زمانهایی که نیازی نیست اون f(x) کماکان توابع غیرخطی مورد نیاز رو مثل معمول تقریب میزنه.
پس بطور خلاصه قرار نیست همه جا همیشه ایدنتی داشته باشیم. ما اینطور فرموله کردیم که هر زمان نیاز به تابع ایدنتتی بود سالور بتونه با قرار دادن f(x) برابر صفر یا مقداری نزدیک به اون تابع همانی رو بدست بده یا تا حد خوبی تقریب بزنه. در لایه هایی که ایدنتی مورد نیاز نیست ما خیلی معمولی همون روال سابق طی میشه با این نکته که برخلاف معماری های ساده ما الان در هر سطح اطلاعات بیشتری داریم و این باعث بهبود کارایی میشه چون هر سطح اطلاعات بیشتری داره و میتونه ازش استفاده کنه و همونطور که بالاتر اشاره کردیم در هر سطح علاوه بر دیدی که از لایه قبلی بدست میاد خود داده هم فراهم میشه تا لایه جدید بهتر بتونه ویژگی های بهتری رو توسعه بده. (نکته دوم (بخش دوم شهود ما که مبتنی بر همین توضیحاتی که اینجا دادیم رو حتما در پایین بخونید)
بخش کامنت رو برای اطلاعات بیشتر مطالعه کنید
چند نکته :
نکته اول : شهودهای دیگه:
تا اینجا صحبتهایی که کردیم و اطلاعاتی که ارائه دادیم همه اش مبتنی بر مقاله اصلی رزنت بوده. از بحث نیاز به توابع همانی گرفته تا بحث مشکل سالورها و اینکه چطور مشکل رو برطرف کنیم در مقاله اصلی وارد شد.
از طرفی یکسری صحبت در داخل کارگاه توسط یکی از عزیزان مطرح شد که من چندان موافق نبودم به چند دلیل که در ادامه البته توضیحاتی در این رابطه دادم. و مضافا اینکه در مقاله اصلی مطرح نشده چنین بحثایی. بنظرم میاد این بحثا نشات گرفته از مقاله ای بنام Deep Networks with Stochastic Depth باشه. یعنی اونجا بحثایی در این حوزه مطرح شد. حالا میخواییم با هم یک نگاهی به بحثی که این مقاله مطرح کرده بندازیم و بعد در انتها با ترکیب این دو مبحث به یک نتیجه گیری برسیم ببینیم کدوم اینتویشن شاید دید بهتری بما بده و برای ما سودمند تر باشه یا مهمتر از اون اصلا ایا اینتویشنی که ما پیدا کردیم صحیح بوده یا ناقص هست؟
قبلش من یک خلاصه ای از مقاله Stochastic depth ارائه کنم. این مقاله بعد از رزنت ارائه شد در سال ۲۰۱۶ و ایده اش بطور خلاصه این بود که دارپ اوت رو روی عمق (لایه ها) اعمال کنه.(بجای اینکه روی نورونها اعمال بشه) یعنی در زمان ترینینگ یکسری لایه ها رندوم در نظر گرفته نشن(نادیده گرفته بشن) تا اینطور بطور ضمنی یک انسمبلی از چند شبکه تشکیل بشه بنوعی و از طرفی یکسری ویژگی از لایه هایی پایینی به لایه های بالایی ارائه بشه و اون لایه ها خودشون تشکیل یکسری رپرزنتیشن های جدید رو بدن . در اینجا هم از اسکیپ کانکشن ها برای ارائه خروجی یکسری لایه پایینی بطور مستقیم به لایه های بالایی استفاده میشد (بطور صریح ایدنتتی رو لحاظ کردن اینجا) واین باعث شد دقتش نسبت به حالت رزنت معمولی بهتر بشه. در این مقاله بود که عنوان کردن هدف مولفان رزنت از ایجاد resblock ها یا همون بلوکهای رزنت این بوده که ویژگی ها از لایه های پایینی به لایه های بالایی برن و لایه های بالایی خودشون یک انتزاع جدید رو یاد بگیرن و اینکه f(x) به سمت صفر میل کنه تا باعث بشه ایدنتتی رخ بده برای این کار صرفا هست نه چیز دیگه! این صحبتایی که اینا کردن یکسری نکات قابل بحث داره.(اولا بعضی موارد مطرحی با مقاله اصلی همخونی نداره بعضی موارد هم عنوان شده که در مقاله اصلی اشاره ای بهش نشده (برداشت خودشون هست) حالا سعی میکنیم باز کنیم اینارو) این بحث در مقاله خودشون رو میشه اینطور بهش نگاه کرد و گفت بله در مقاله شما اینطوره اما در مقاله اصلی رزنت حداقل من با توجه به صحبتها و دلایل ارائه شده در مقاله اصلی و بحثایی که در ادامه میکنم متقاعد به همچین بحثی نشدم. اولین بحث اینجا اینه که stochastic depth که ایده فوق الذکر رو مطرح کرده قائدتا با تغییراتی که بطور صریح در معماری لحاظ کرد باید خیلی بهتر بتونه از معماری های ساده با عمق خیلی کمتر کار بکنه (ایده این بوده نکات مثبت معماری با عمق کم با نکات مثبت معماری با عمق زیاد بدست داده بشه) در حالی که باز ما میبینیم معماری های مثل Wide residual netو SimpleNet یا SimpNetv2 با فاصله زیادی هم معماری رزنت و هم معماری stochastic depth رو پشت سر گذاشتن. ما یک بحثی رو مطرح کردیم گفتیم که اون اسکیپ کانکشن ها در لایه هایی که کانتربیوشن مثبت به شبکه دارن حکم information pool های بهتر رو ایفا میکنن یعنی همون انتقال ویژگی از لایه پایینی به بالایی تا لایه بالایی هم یک ترنسفورمیشن از لایه قبل خودش و هم داده اصلی رو با هم داشته باشه و اینطور بتونه ویژگی های بهتری رو بدست بده.(البته باز اینجا اگه جمع نشن بهترن یعنی بصورت کانکت ارائه بشن ویژگی ها خیلی بهترن اما به هر صورت به این شکلش هم تاثیر مثبت داره) تا اینجا تقریبا بحث استوکستیک دپس و ما در اینجا یکیه هر دو اعتقاد داریم که اسکیپ کانکشنها اطلاعات بهتری ارائه میکنن در هر سطح و این خوبه. بحث ما از جایی شروع میشه که عنوان میشه یک لایه چیزی یاد نمیگیره بعد تبدیل به ایدنتتی میشه تا اسکیپ کانکشن داده از مرحله قبل رو ببره به لایه بعد تا اون خودش یک رپرزنتیشن جدید و مفید رو ارائه بده. (علاوه بر بحث ونیشینگ گریدینت که گفتن اینها بخاطر اون ارائه شده در حالی که در مقاله اصلی رزنت (صفحه ۵ ام فکرکنم) صریحا قید شده که این مشکل دیگردیشن ربطی به ونشینیگ گریدینت نداره و چون از بچ نرمالییشن استفاده شده ما چک کردیم و همه چیز رو براه هست) اولا اینجا هیچ چیزی وجود نداره که اینو انفورس کنه. خب اگر شبکه دید یک لایه تابعی ارائه کرده که خوب نیست بعد بیاد اون لایه رو ندید بگیره و در لایه بعد یک تابع رو تقریب بزنه که بهتر کار کنه. آیا راحت تر نبود که در همون سطح اون تابع رو در همین لایه پایینی تقریب بزنه؟ ایا امکانش نبود؟ یا سخت بود؟ چون با توجه به دقت بهبود یافته در WRN که یک معماری رزنتی هست با عمق کمتر و عرض بیشتر و همینطور معماری های بسیار ساده simplenet و SimpNetv2شبکه قادر بوده در تعداد لایه های کم خیلی عالی کار بکنه بحدی که هم رزنت معمولی و هم نسخه مبتنی بر استوکستیک دپس رو پشت سر بزارن.(بحث در این مورد در پایین رو ببینید) این یک نکته. حالا نکته دوم اگر فرض بگیریم که این بحث ادعایی صحیح باشه دوباره اینکه یک سری لایه ایدنتتی شده باشن تا ورودی به لایه بعدی بره اثر موثرش باید قائدتا مثل معماری stochastic depth باشه که چندتا لایه کلا کنار گذاشته میشن و خروجی از لایه های پایینی به لایه های بالایی ارائه میشن و اونها ویژگی های جدید یا مناسبی رو توسعه میدن. اما در عمل میبینیم اینطور نیست و در stochastic depth هم بصورت صریح این کار صورت میگیره. پس میشه نتیجه گرفت اتفاقی که در رزنت معمولی می افته کمی متفاوت تر از اون چیزی هست که در استوکستیک دپس داره رخ میده. باز یعنی در رزنت با در نظر گرفتن فرض تازه ما بطور موثر یکسری لایه نداریم (میتونه در هر جایی از شبکه باشه) و لایه های بعدی یک بحثی رو فرا میگیرن از لایه های زیرین و این فیچرها از مرحله قبل به لایه های بالایی ارائه شده و اونها بازنمودها یا رپرزنتیشنهای بهتری رو نسبت به حالت معمولی توسعه میدن که نهایتا دقت رو بهبود میده نسبت به معماری های کم عمق تر. ولی در عمل میبینیم نسبت به همونها اتفاقا شکست میخوره. در استوکستیک دپس اما این مساله بصورت رندوم رخ میده و چیزی که باعث بهبود میشه بنوعی اون اثر انسمبل هست که باعث بهبود کار میشه (و اینجا هم البته باعث فراگیری ویژگی های تکراری خواهیم بود یعنی یکسری لایه کار تکراری انجام میدن.) به این خاطر من شخصا این بحثی که صحبتش رفت رو به اینصورت کاملا صحیح نمیبینم و ترجیح میدم با توجه به اینتویشنی که در مقاله اصلی ارائه شده پیش برم.(ممکنه برداشت من ناقص بوده باشه ولی با بحثایی که دیدیم هنوز بنظرم بحثی که در بالا کردم صحیح تر میاد تا این بحث جدید) در بحث فیچر ریوز هم ما در ادامه معماری دنز نت رو داشتیم که اونجا عنوان میکنه ما بطور خاص از بحثی که در رزنت مطرح شد پرهیز میکنیم چون این کار (جمع) باعث خراب کردن ویژگی ها میشه. پس اگر ایده اصلی چیزی غیر از بحثی که در مقاله اصلی رزنت ارائه کردن بود قائدتا کانکت و ارائه به لایه بعد گزینه بهتر و معقول تری بنظر میاد تا اینکه ما بخواییم به شبکه بار اضافی تحمیل کنیم که اول یک تابع همانی یاد بگیره تا بعد ویژگی از لایه قبل به لایه بعد منقل بشه و اینطور لایه بعد علاوه بر داده پردازش شده به داده خام مرحله قبلش هم دسترسی پیدا کنه (البته اینجا باز یک نکته هست وقتی لایه زیرین ایدنتتی بشه دیگه خبری از ترنسفورمیشن روی داده قبلی نیست صرفا داده از مرحله قبل ارائه میشه و باز بحث بالا رو داریم) و بحث ادعا شده در استوکستیک دپس صدق کنه. مضافا اینکه در مقاله اصلی بنیان بحث روی بحث فیچر ریوز بنا نشده و بحثش چگونگی ارائه راه حلی برای بدست اوردن راحت تر تابع همانی توسط سالور بوده و با مثالی که در ابتدای مقاله زده اشاره کرده که شهود اونها در چه راستایی بوده. درنهایتا ارائه ای که خود kaiming he بعد از انتشار مقاله ارائه داد این مطلب بهش اشاره شده بود که میشه از اینجا اون ارائه رو دید. در ادامه هم توضیحات Andrew Ng در رابطه با این بحث هم میتونه خیلی خوب باشه و برای ما روشن کنه که واقعا چه اتفاقی داره میوفته.
نکته دوم – بخش دوم شهود ما:
یکسری بحثا مطرح میشه که به بخشی بالا هم اشاره کردیم(بعضی دیگه رو در ادامه انتهای بحث من انشاءالله مینویسم) مبنی بر یادگیری افزایشی یا بطور کلی به بهبود رسیدن در این بلاکها هست. یک بحثی در مقاله اصلی مطرح شده که میشه با توجه به اون به ایده ای در راستای بهبود احتمالی که حاصل میشه دست پیدا کرد. (علاوه بر بحث بالایی که بدون توجه به شهود اول ما بود مبنی بر بهبود کارایی اینجا میخواییم با توجه به شهود اولی که مطرح کردیم ببینیم چطور میشه بهبود احتمالی رو هم اثبات کرد و فهمید شهود اول ما صحیح هست) حالا اون چی هست؟ در مقاله تو صفحه سوم یک بخشی هست تحت این عنوان که اگر یک تابع بهینه ای به نگاشت ایدنتتی نزدیک تر باشه تا نگاشت صفر برای اپتمایزر خیلی راحت باید باشه تا با انجام یکسری تغییرات به اون تابع دست پیدا کنه. این همون بخش مهم هست بنظر من که میتونم ازش یکسری شهود تازه بدست بیاریم. یعنی چی؟ بزارید بازش کنم. اینجا داره اینو میگه اگه ما یک تابع ایدنتتی داشته باشیم اپتمایزر با اعمال تغییرات در اون باید راحت تر بتونه یک تابع دلخواه شبکه رو تقریب بزنه تا اینکه بخواد از صفر یک تابع دلخواه شبکه رو یاد بگیره . (فکر کنید یک سیاهه ای از قبل باشه و شما شروع به کار رو اون کنید و یک شکل تازه بدست بیارید تا اینکه بخوایید از صفر یک شکل رو خودتون طراحی کنید یک همچین چیزی رو در نظر بگیرید ). حالا چه اتفاقی می افته؟ ما گفتیم تا یک لایه ای همه چیز خوب هست و توابع مناسب تقریب زده میشن. از یک لایه ای به بعد گفتیم که شبکه میره و تمام لایه های بعدی که کمکی به شبکه نمیکنن رو همانی میکنه که خروجی اخرین لایه بره انتهای شبکه. تا اینجا درست. حالا اگر این فرض رو در نظر بگیریم سالور میتونه همین توابع همانی که شبکه رفته بدست اورده رو شروع میکنه کمی تغییر دادن (اگر بتونه) و اینطور تابعی که قبلا همانی صرف بوده یا نزدیک به اون میتونه تبدیل به یک نگاشت جدید و مفید برای شبکه بشه. و اگر این مسیر ادامه پیدا کنه ما میتونیم بگیم بصورت افزایشی هر بخش داره یک چیز جدید یاد میگیره (اگر بتونه وگرنه همون همانی باقی میمونه) .وقتی نتایج تو مقاله رو میخونیم و همینطور لایه ها رو ویژوالایز میکنیم میبینیم که کانتربیوشن خیلی از این لایه ها خیلی کمه و میشه این رو به این قضیه ربطش داد. و این شهود جدید ما با شهود قبلی ما هم منافاتی نداره و در اصل تکمیل کننده اونه . یعنی ابتدا شبکه توابع همانی رو تقریب میزنه و در اینجا باعث میشه یک شبکه عمیقتر از یک شبکه کم عمق تر خطای بیشتری ایجاد نکنه. حالا اگر شانس بیاریم و سالور تغییراتی در بعضی از این توابع همانی یا نزدیک به همانی جدید ایجاد کنه که یک تابع بهینه دلخواه ازش در بیاد باعث میشه بهبود هم داشته باشیم. با توجه به این بحثی که الان شد میشه دلیل عدم بهبود که در بخش قبل صحبت کردیم رو فهمید و اینکه شهود اولیه ما صحیح بوده .
نکته بعدی:
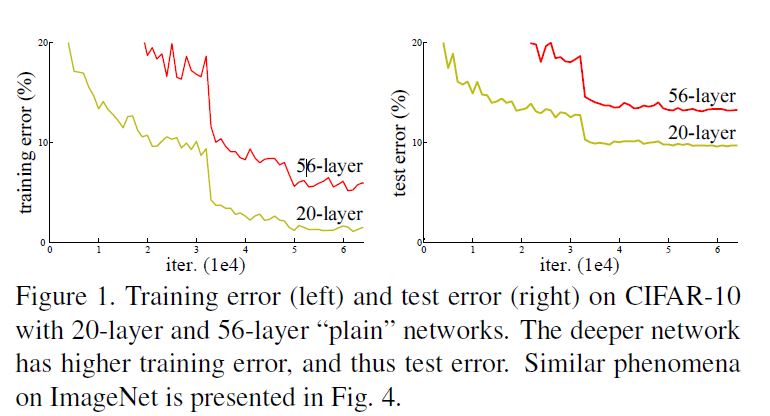
این تغییر فرمولی که دادیم بخاطر رخ دادن مشکل دیگردیشن هست (شکل ۱ سمت چپ) . همونطوری که در بحث مقدمه مطرح کردیم اگه لایه های اضافه شده نگاشت همانی انجام بدن یک مدل عمیق تر باید مثل یک مدل کم عمق تر کار کنه و خطای بیشتری نداشته باشه . مشکل دیگردیشن دلالت بر این داره که سالورهای فعلی ما در تقریب نگاشت همانی توسط چند لایه غیرخطی پشت سر هم مشکل دارن (حداقل برای عمق های خیلی زیاد. چون برای لایه هایی مثل ۱۸ یا حتی شاید ۳۴ لایه هنوز همه چیز خوب کار میکنه تقریبا خصوصا تا ۱۸ لایه چون ۱۸ لایه ساده از معادل رزنتیش بهتر عمل میکنه. با این تغییر فرمول نگاشت همانی بهینه اس و سالورها باید بتونن خیلی ساده وزنهای چند لایه غیرخطی رو ببرن به سمت صفر تا به نگاشت همانی نزدیک بشن.
در بلاکهای رزنت ما دو فرم داریم که بصورت زیر هست :
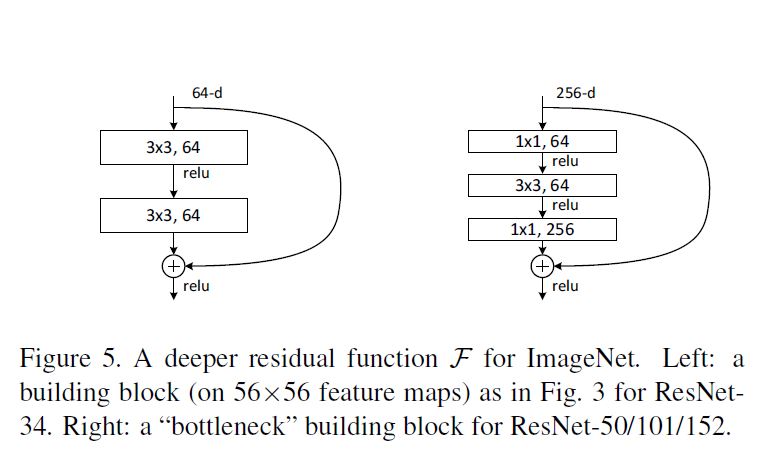
تفاوت اونها در استفاده از bottleneck هست که در بلاک سمت راستی استفاده شده برای کاهش سربار پردازشی و در بلاک سمت چپی استفاده نشده . در معماری های خیلی عمیق برای کاهش سربار پردازشی از این شیوه استفاده میشه .
برای اینکه نسبت به این معماری و بحثهای انجام شده اطلاعات بیشتری بدست بیارید پیشنهاد میکنم مقاله Identity Mappings in Deep Residual Networks رو مطالعه کنید که توسط همین نویسندگان چند ماه بعد ارائه شد و سناریوهای مختلف مرور شد و پیرامون چگونگی بهبود توضیحات خوبی داده شده . بعد از اون مقاله خوندن Stochastic depth و همینطور Wide residual network هم توصیه میشه.
با خوندن مطالب بالا حالا باید بتونید براحتی مقاله ResNet رو بخونید و انشاءالله بطور کامل متوجه بشید که داستان از چه قرار بوده.
البته من این رو عنوان کنم که من صحبتهای متفاوت از بحثایی که بالا شد رو هم دیدم یعنی افراد مختلف اینویشن های مختلفی داشتن و هرکسی به نحوی توضیح خودش رو ارائه کرده من انشاءالله این بحثا رو سعی میکنم باز کنم اینجا (یعنی نظرات دیگران رو بنویسم و توضیح بدم از نظر اینها داستان چی هست و اگر نکته ای از دید من مخفی مونده یا من بحثی رو کامل بیان نکرده باشم اینجا مشخص و تکمیل بشه و در انتها هم ببینیم این بحث ها ایا متضاد هم هستن یا مکمل هم و ایا تایید یکی نفی دیگری هست یا نه.
در این بین اگر نکته ای هست که نیاز به توضیح یا تصحیح داره لطفا بفرمایید.
با سلام
ممنون از توضیحات بسیار خوبتون.
در مورد مواقعی که عمیق تر کردن و افزایش تعداد لایه ها باعث بهبود شبکه میشه، بازهم شبکه F رو مساوی صفر قرار میده و باز هم لایه های مفید در حکم یک تابع همانی رفتار می کنند؟ فرمودید information pool بهتری انجام میشه. من این قضیه رو اینطوری درک میکنم که در مواردی که افزایش لایه ها به نفع بهبود شبکه است، مثل یک تابع همانی رفتار کردن لایه های آخر جلوی بهبود شبکه رو در اون حالت میگیره و نباید اینجا F=0 بشه و مثل همانی رفتار کنن، در واقع در این حالت لایه های کانولوشنی بعدی با دریافت خروجی لایه قبل به عنوان ورودی ، قابلیت استخراج ویژگی های با سطح انتزاع بالاتر را دارند و همین کار رو انجام میدن و عملکرد شبکه به این ترتیب افزایش پیدا میکنه.
اگه لطف کنید و توضیح مختصری در این مورد بفرمایید که شبکه بین دو حالت بهبود و عدم بهبود تمییز قائل میشه و F در دو حالت به چه نحوی هست و اگر تفاوت قائل میشه چطور این تفاوت رو قائل میشه ممنون میشم.
سلام
نه f(x) = 0 نمیشه و قرار هم نبوده که بشه. اگه خاطرتون باشه بحث ما این بوده که چند لایه پشت سر هم یک تابع پیچیده مثل H(x) رو تقریب میزنن (در اصل باید بتونن هرچیزی رو تقریب بزنن ولی بطور ویژه سر ایدنتتی مشکل داشتن. و ایدنتتی کجا برای ما مهم بود لایه های جدیدی که چیزی به شبکه اضافه نمیکردن. ما میدونستیم که اگه تا یک لایه ای شبکه خوب کار میکنه و یکسری لایه جدید هم اضافه کردیم اگه اون لایه ها همانی بشن مشکلی نداریم. اما شبکه نمیتونست برای لایه های جدید تابع همانی رو بدست بده. برای همین ما این داستان رز نت رو اوردیم که اونها ،”هر زمانی که “نیاز” به ایدنتتی باشه سالور “براحتی” بتونه اونو ارائه کنه” و در حالت عادی کماکان مثل سابق توابع مورد نیاز تقریب زده بشن.)
در حالت عادی اون f(x) یک تابع غیرخطی خواهد بود که خیلی معمولی در جهت افزایش سطح انتزاع عمل میکنه. یعنی همون چیزی که در معماری های معمولی داریم. اون کانکشنی که از مرحله قبل میره به مرحله بعد هم در اصل اینطوره که میگه من یک ورودی به این بلاک دادم (بلاک ما مثلا دو لایه داره مثل همین شکلی که نشون دادیم . اسمشو میزاریم b ) این بلاک خودش یکسری محاسبات انجام داده روی (ورودیش) و به یک سطح انتزاعی رسیده. لایه بعدی یا بلاک بعدی علاوه بر این دیدی که لایه قبلی بهت میده نسبت به من بیا خودت به اصل داده هم نگاه کن (البته این در معماری دنز نت خیلی مشهود تره نسبت اینجا ) . یعنی چی؟ شما هم به سطح انتزاع قبلی و هم سطح انتزاع حاصل از اون در یک آن نگاه میکنید و بهتر میتونید فیچرهای مورد نیاز رو استفاده کنید و دوباره سطوح انتزاع بالاتری رو بدست بدید.
حالا یک سوال، این بحث فیچر رو مطرح کردیم که خب بیا علاوه بر دید لایه قبل(نگاشت لایه قبل) روی ورودیش بیا ورودیش رو هم بگیر، یک مساله ای هست ایا اینکه جمع میکنیم این فیچرمپ ها رو مشکلی ایجاد نمیکنه ؟ بنظر میاداگه ویژگی ها بصورت جدا ارائه بشن شاید بهتر باشن و اینطوری شاید کارایی رو بد کنه نسبت به حالت مورد نظر ما. درسته؟
بله این جمع کردن ها در اصل باعث بدتر کردن حالت نسبت به بحث کانکت کردن معمولی میشه. و این ایده در دنز نت مطرح شد و برای همین هم اونجا دیگه خبری از جمع کردن و… نیست .
نکته دیگه اینه که در بحث ایجاد اینفورمیشن پول شما میتونید ترکیب اینها و ترکیب های متنوع تر دیگه ای رو ارائه بدید در هر سطح تا بسته به میزان اثربخشی هرکدوم کارایی شبکه افزایش پیدا کنه . در این بین میتونید با تست بیشتر به یک حد معقول برسید .
پس بطور خلاصه قرار نیست همه جا همیشه ایدنتی داشته باشیم. ما اینطور فرموله کردیم که هر زمان نیاز به تابع ایدنتتی بود سالور بتونه با قرار دادن f(x) برابر صفر یا مقداری نزدیک به اون تابع همانی رو بدست بده یا تا حد خوبی تقریب بزنه. در لایه هایی که ایدنتی مورد نیاز نیست ما خیلی معمولی همون روال سابق طی میشه با این نکته که برخلاف معماری های ساده ما الان در هر سطح اطلاعات بیشتری داریم و این باعث بهبود کارایی میشه چون هر سطح اطلاعات بیشتری داره و میتونه ازش استفاده کنه.
ممنون از توضیحاتتون
آقای حسن پور شما فرمودید با این فرموله کردن کماکان شبکه قادر است f رو و در نهایت H رو یک تابع غیرخطی خوب در جهت رسیدن به انتزاع بیشتر تقریب بزنه و علاوه بر اون این نوع فرموله کردن به سالور این امکان رو میده که در مواقع نیاز f رو صفر قرار بده و H رو یک تابع همانی تقریب بزنه تا همونجا که عمکرد بهینه هست stop کنه انگار. حالا من میخوام بدونم چور میفهمه که کجا باید سطح انتزاع رو افزایش بده و اجازه بده مثل قبل یک تابع غیر خطی برای مدل کردن و استخراج ویژگی های جدید از فیچرمپ های قبلی تقریب بزنه و کجا باید f رو مساوی ۰ قرار بده؟
ببخشید اگه سوالم خیلی ابتدایی هست و متوجه این قسمت نمیشم که چطور میفهمه، در واقع میخوام بدونم شبکه یکبار f رو براش تقریب میزنه بعد که متوجه شد عملکرد بهتره، تو بک پراب با گرادیان ها، اون موقع دفعه بعد برای بروز رسانیش میاد همون جا f رو مساوی ۰ میذاره؟
ببخشید تو خط آخر اشتباه نوشتم عملکرد بدتره منظورم بود نه بهتره!
ممنون
در مقاله بطورجزئی به این مطلب اشاره ای نشده که چطور این گام بگام انجام میشه . یک شهود سطح بالاس و پیاده سازی شده و جواب داده و منطقی که در نظر گرفته شده اینه. بصورت دیفالت در همه لایه ها یک تابعی تقریب زده میشه . حالا چیزی که بعنوان مثال در مقاله اومده اینه اگه فرض بکنیم که یک تابع بهینه دلخواه وجود داشته باشه که به نگاشت همانی نزدیک تر باشه نسبت به یک نگاشت صفر ، برای سالور خیلی راحتتره که بتونه با اعمال تغییراتی با توجه به نگاشت همانی به تابع بهینه دست پیدا کنه تا اینکه بخواد از صفر اون به اون تابع برسه.
و اینطور میگن که این بحث رزیجوال در همه جای شبکه اینطور میتونه مفید باشه، اخر شبکه همانی میشه و در جاهای دیگه سالور میتونه با تغییراتی به تابع بهینه مورد نظر برسه یا اونو بهتر تقریب بزنه.
از طرفی میشه طور دیگه ای هم به این قضیه نگاه کرد اگه بخواییم ریز بشیم یعنی یکسری وزن در اون لایه ها حاوی مقادیری میشن و هرکدوم به میزانی تاثیر در خروجی میزارن. حالا در هر سطح ما یکسری ویژگی بدست میاریم. در سطوح پایینی ویژگی ها وقتی صحیح و کاربردی و دقیق باشن باعث بهبود کارکرد شبکه میشن. از طرفی در سطوحی (لایه هایی) که چیزی به قدرت بازنمایی شبکه اضافه نمیکنن یعنی ویژگی های نادقیق و احتمالا رندوم بدست داده شدن یا در بهترین حالت تکراری) اون فیچرها در لایه های جدید که کمکی به افزایش سطح انتزاع شبکه نمیکنن اغلب حتمالا رندوم هستن به همین دلیل برخلاف ویژگی های سطوح قبل که ویژگی های قابل قبولی دارن ، موقع تصحیح وزنها سالور در اصل وزنها و تاثیر اونها رو کاهش میده و رفته رفته میبینید که وزنها بیشتر صفر یا نزدیک به صفر هستن و از طرفی اون اسکیپ کانکشنها کماکان هستن و این رفته رفته اون بحث ایدنتتی رو رقم میزنه. وزنهای بیشتری برابر با صفر یا متمایل به اون میشن و ترکیب اون با ورودی از مرحله قبل ترتیب یک ایدنتتی یا تقریب نزدیکی از اون رو میده. در لایه های قبل این مساله خیلی کمتر هست و در نتیجه مقادیر مثل لایه های بعدی صفر یا متمایل به صفر نیستن و اون بحث ایدنتتی رخ نمیده.
یک نکته ای که باید توجه کنید اینه که اینها توصیفات دقیق نیستن ما فعلا فکر میکنیم اینطور اتفاق داره میوفته و ممکنه واقعا بحث اصلی یک چیز دیگه باشه کما اینکه دیدم یکسری فرضیات ارائه شده در رزنت بعدا نقض شدن یا زیرسوال رفتن و نه تنها رزنت بلکه خیلی از موارد قبلی در مقالات. راهش هم انجام تستهای مختلف و بازبینی دقیق اتفاقات رخ داده در معماری هست چیزی که باعث شد مثلا Wide residual nework ارائه بشه و یا چیزی که باعث شد stochastic depth در مورد رزنتها بوجود بیاد و همینطور مقالات مختلف دیگه در مورد رزنت که تعدادشون هم کم نیست (خود من هم خیلی ها رو مطالعه نکردم اما شما یا کسایی که علاقه دارید میتونید و باید ببینید اونها چه چیزی برای گفتن دارن و چه بحثهایی رو مطر کردن. مثلا رزنت بصورت معمولی redundancy زیادی داره یا اینکه خیلی از لایه ها ممکنه اصلا چیزی یاد نگیرن یا یادگیری خیلی ناچیز صورت بگیرده در سطح اون لایه ها و به این ترتیب مثلا استوکستیک دپس مقاله اش رو ارائه داد که کارایی رزنت رو خیلی بهبود داد . به همین شکل wrn اومد و رو همین مباحث عنوان کرد عوض عمیق تر کردن عریض بکنیم شبکه رو که این مباحث رو نداشته باشیم یا خیلی کمتر بشه بعنوان مثال.
عرضم اینه که همه مقالات یکسری ایده ارائه میکنن اما عموما شیوه رسیدن به این بحث ها اینطور نیست که خیلی متقن و رو اصول بوده باشه از ابتدا. نه خیلی ها بصورت تصادفی و رندوم بدست میان یعنی اول یکسری بحث و ایده رو انجام میدن بعد که نتیجه گرفتن شروع میکنن داستان سرایی کردن برای همین ممکنه ببینید این داستانه (همه جا) صادق نیست.
ممنون از اینکه با حوصله به سوال هامون جواب میدید آقای مهندس.
سپاسگزارم.
خواهش میکنم
در پناه خداوند موفق و سربلند باشید
سلام و عرض ادب
تا اونحایی که لایه های معماری رز نت رو نگاه کردم لایه دراپ اوت نداشت. ولی به هنکام تست باید سالور رو برای اون تظیم کرد. ایا عرضم درسته؟
ممنون
سلام.
یعنی چی ؟ منظور شما اینه چون از دراپ اوت استفاده نشده برای مقابله با اورفیتینگ از مقدار مناسب ویت دیکی استفاده کنید ؟اگه اره بله همینطوره باید مقدار ویت دیکی رو متناسب با کارتون تنظیم کنید
البته بهتره از دراپ اوت استفاده کنید چون کنترل بهتری بشما میده تا ویت دیکی (دراپ اوت استفاده کنید ولی مقدار ویت دیکی رو کمتر کنید اینطور خیلی بهتر هست)
سلام سپاس از مقاله خوبتون
اکlانش هست اموزش فاین تیون کردن هم بزارید؟
بخصوص فاین تیون ResNet و InceptionResNetV2 با کراس .
ممنون میشم
سلام .
اگه سرچ کنید نمونه های مختلفی در اینترنت باید باشه خصوصا مثالهای کراس رو چک کردید ؟
خود فاین توننینگ بحثش در بخش پرسش و پاسخ بارها شده اونجا رو چک کردید ؟
سلام و عرض ادب
به منظور wide کردن یک کرنل چه تغییری در ابعاد باید صورت بگیرد؟ به طور مثال ابعاد کرنل[۳,۳,۵۱۲,۵۱۲] تبدیل به
[۵,۵,۵۱۲,۵۱۲] میشه؟ با توجه به افزایش بار پردازش چه زمانی کمک کننده است؟
ممنون
سلام
واید کردن معمولا به عرض لایه ها اطلاق میشه یعنی منظور همون افزایش تعداد کرنلها در یک لایه است (قبلا ۶۴ کرنل بود الان اونو برابر مقدار بیشتری مثل ۷۰ یا ۱۰۰ یا ۱۲۸ قرار بدید )
خود کرنل بزرگتر بشه دقت بدتر میشه حداقل در کاربردهایی مثل کلسیفیکیشن . کرنلهای بزرگتر رو با کرنلهای کوچکتر جایگزین کنید اینطور هم دقت بهتری میگیرید و هم سرعتتون خیلی افزایش پیدا میکنه
این موارد(قیاس اندازه کرنلهای مختلف و تاثیر اونها در کسب دقت و زمان اجرا….) در اسلایدها هست
منون.اگر دست فهمیده باشم اگر بعد چهارم یک کرنل ۴*۱ رو بیشتر کنم میشه واید کردن. این کار وری بعدهای دیگه یک کرنل اثر نمیذاره؟
و در مورد دوم که فرمودید کرنل رو کوچک کنم متلا به چای ۵*۵ بذارم ۱*۱ درست متوجه شدم؟
سلام
اندازه کرنل رو ترجیحا ۳در۳ قرار بدید تا بهترین دقت و پرفورمنس رو در اغلب کارها بدست بیارید
میتونید از ۱در۱ هم استفاده کنید ولی باید به نکات مهم در این رابطه توجه کنید. مثلا در ابتدای شبکه اینکارو نکنید یا میزان اینکار باید کم باشه. اسلایدها رو ببینید توضیح دادم در این رابطه
بسیار ممنون
سلام ممنون از توضیحات خوبتون.میشه درمورد معماری resnet34هم کمی توضیح بدبد؟و توضیحاتی درمورد لایه های آن
سلام
همون رزنت معمولیه حالا ۳۴ لایه اش! نکته خاصی نداره. اگه سوالتون حول موضوع خاصیه اون رو بفرمایید
من درمورد اعدادی که در شکل آخر استفاده شده سوال دارم .ای اعداد در هر لایه نشان دهنده چی هست وچرا این مقدار انتخاب شده , در هر لایه تغییر میکنه؟
۲۵۶d
۱*۱*۶۴
۳*۳*۶۴
۱*۱*۲۵۹
استفاده از هر مدل در چه مواردی هست؟
۶۴d
۳*۳*۶۴
۳*۳*۶۴
من در یک مقاله دیدم در جدول برای ۳۴ لایه این اعداد را برای هر لایه نوشته
CONV1
۳*[۳*۳*۶۴] CONV2.X
۴*[۳*۳*۱۲۸] CONV3.X
۶*[۳*۳*۲۵۶] CONV4.X
۳*[۳*۳*۵۱۲] CONV5.X
و اینکه FLOPS چی هست؟برای ۳۴ لایه مقدارش برابر ۹^۱۰*۳٫۶ هست
سلام
دلیل تغییر اونها بخاطر کاربرد متفاوت هرکدوم هست . ما اینجا یک لایه نداریم . اصطلاحا یک بلاک داریم که حاوی چند لایه هست.
برای اینکه سربار پردازشی کاهش پیدا کنه بعنوان مثال از تکنیکی بنام bottleneck استفاده میکنن. یعنی تعداد فیچرمپ رو کاهش میدن و بعد افزایش میدن .(دقت کنید اول ۲۵۶ فیچر مپ داشتید بعد شد ۶۴ که از یک فیلتر ۱در۱ و بعدش ۳در۳ استفاده شد ( کاهش بعد) و بعد دوبار افزایش ابعاد رو دارید (باتل نک. یک ساعت شنی رو در نظر بگیرید که دو طرفش بزرگ ولی وسطش تنگه.) در مورد این بحث در کارگاه به تفصیل صحبت کردیم البته .
استفاده از هر مدل بسته به دیتاست و کار شماست که چقدر نیاز به پیچیدگی داره .
اون ضرب در ۳ یا ضرب در ۴ و الی اخر به معنای تکرار هست.
FLOPS یعنی Floating poin operation per second و اشاره به سربار محاسباتی داره . منظور اینه در این معماری بعنوان مثال چه میزان عمل ضرب و …. انجام میشه . بشما ایده میده این معماری مثلا سربار کمتری داره یا یک معماری ایکس دیگه
هرچقدر FLOPS کمتر باشه نشون میده سربار محاسباتی کمتر هست و منابع محاسباتی سیستم کمتری درگیر میشه.
ببخشید یه سوال دیگه هم داشتم در کد نویسی در paytorchچطوری تعداد داده test , train را مشخص میکنیم؟
تعداد تصاویر من ۳۵۰۰۰ هست چند تا برای test مناسب هست چند تا با train?
پای تورچ و غیرپارتورچ فرقی نداره در دیپ لرنینگ بیشترین تعداد داده رو به ترینینگ اختصاص میدیم . البته شما اینجا داده اتون زیاد نیست . میتونید ۸۵ ۸۶ درصد رو به ترینینگ اختصاص بدید و بقیه رو به تست.
ایده اینه هرچقدر داده بیشتر به ترینینگ اختصاص پیدا کنه بهتره ولی اینجا چون دیتای زیادی هم ندارید نمیشه خیلی زیاد همه رو به ترینینگ داد چون اینطور برای تست ملاک مناسبی ندارید که شبکه چطور داره کار میکنه(تعداد نمونه ها خیلی کم نباید باشه)
خیلی لطف کردید ممنون از توضیحات خوبی که دادید خداروشکر که هنوز انسانهای شریفی مثل شما وجود داره که دانش خودش رو در اختیار دیگران قرار بده.تشکر فراوان
خواهش میکنم
بهتر از من در گروه ما الحمدالله خیلی زیاده . کافیه یه سری به سایت پرسش و پاسخ ما بزنید:) بچه های واقعا خوب و خیلی عزیزی صادقانه و بی منت مدتهاست سعی میکنن به بقیه کمک کنن. امیدوارم شما هم بزودی به جرگه ما بپیوندید 🙂
در پناه خدا موفق و سربلند باشید
سلام
ممنونم بایت توضیحات خوبتون
می خواستم جایی هست که شبکه ی زرنت آموزش داده شده روی imagenet رو برای کفی بتونم دانلود کنم؟
سلام
بله : https://github.com/KaimingHe/deep-residual-networks
البته معماری های بهتر از رزنت هم اومده که میتونید از اونها هم استفاده کنید (مثل موبایل نت دنزنت wide residual newtork , …
سلام
فرق resnet50,resnet101,resnet152 با resnet34 چیه؟ تو مقالش از اصطلاح bottleneck برای resnet50/101/152 استفاده کرده. منظورش چیه؟
سلام
عمق اونهاست. رزنت یکسری پارامتر داره که بر اساس اون معماری رو ایجاد میکنن در همه پیاده سازی ها ببینید مشخصه.
در مورد باتل نک در بخش پرسش و پاسخ قبلا بحث شده لطفا اونجا رو سرچ کنید
سلام آقای دکتر خوبین؟ امیدوارم که همیشه موفق و سربلند باشید. ببخشین که مزاحم اوقات شریف شما می شوم. راستش در مورد برنامم از شما یک راهنمایی می خواستم ممنون می شم قبول زحمت کنید و به سوالم جواب بدین. من یک شبکه کانولوشن کلاسیک رو که سه لایه کانولوشن و دو لایه فولی کانکتید با تقسیم هر ایپک به ۱۰۰۰۰ هزار قسمت و تکرار ایپک ها به تعداد ۲۵ دفعه رو برای دو کلاس کاری از تصاویرم امتحان کردم به طوریکه هر کلاس کاری ۲۰ هزار تصویر داشت و ۲۰۰۰ تصویر تست برای هر کلاس در نظر گرفتم. نتیجه خوبی برای این آزمایش گرفتم. تقریبا اکورسی نزدیک ۹۴ در صد و ولیدیشن اکورسی نزدیک ۹۰ درصد گرفتم. در مرحله بعد کل کلاس کاری خودم رو که شامل ۹ کلاس کاری هر کدام با ۲۰ هزار تصویر ترین و هر کدام با ۲۰۰۰ تصویر تست جمعا ۱۸۰ هزار تصویر ترین با ۱۸ هزار تصویر تست به شبکه دادم. الان که نتایج در هر ایپک را نگاه می کنم(تا مرحله ۱۲ در طی ۳۰ ساعت جلو رفته) تقریبا در هر مرحله اکورسی ۰٫۱۱ و ولیدیشن اکورسی هم در همین رنج هستش. احساس می کنم نتیجه نهایی مطلوب نخواهد بود. به نظر شما چیکار می تونم بکنم. تعداد تصاویر ترین رو کم کنم و یا تعداد گامها در هر ایپک را زیاد کنم و یا تعداد ایپک ها را زیاد کنم و یا…. ممنون می شم در این خصوص منو راهنمایی بفرمائید. با تشکر
البته سایز تصاویر را هم ۱۲۸*۱۲۸ انتخاب کردم.
سلام
پیشنهاد میشه همیشه از فاین تونینگ استفاده کنید تا همگرایی سریعتر داشته باشیذ و دقت بالاتری بگیرید ویا از معماری های معروف. طراحی معماری نکات ریز خیلی زیادی داره و همیشه ضروری نیست. اول سعی کنید از چیزی که موجود هست بهره ببرید.
همیشه در این مواقع نرخ ویت دیکی و یا دراپ اوت اگر استفاده کردید رو چک کنید و خیلی پیش اومده مقدار بالایی ست کنید و شبکه اندرفیت کنه.
مقادیر اولیه نامناسب هم از این موارد رو باعث میشن سعی کنید از بچ نرم استفاده کنید یا نرخ یادگیری رو کاهش بدید یا از الگوریتم های مناسب تر مثل ژاویر بهره ببرید
لیبل ها رو هم چک کنید تا اشتباه نباشن این هم یکی دیگه از موارد رایج هست/
سعی کنید سوالتون رو در بخش پرسش و پاسخ بپرسید تا عزیزان سریعتر جواب بدن
ضمنا من دکتر نیستم
در پناه حق موفق و سربلند باشید
جناب دکتر سلام یه سوال داشتم درباره اجرای رزنت در تنسورفلو.برای اجرا باید خودمون شبکه های کانولوشن پولینگ رو مثلا ۷۰ بار بزاریم تو برنامه یا اینکه تابعی برای حل موجود هست.البته در مورد شبکه های دیگه مثل google net یا vggnet هم همینطوریه شرایط نوشتن کد.
سلام عموما کلاسهایی که برای این معماری ها طراحی شده در constructorش یکسری پارامتر برای عمق شبکه و… دریافت میشه.
نیازی نیست N لایه رو پشت سر هم بنویسید خیلی راحت از یک لوپ میتونید استفاده کنید.
یه دنیا ممنون لطف کردین