

در این پست مفاهیم اولیه تنسورفلو مورد بررسی قرار خواهد گرفت و در پایان شما موارد زیر را فرا خواهید گرفت:
تنسورفلو چگونه کار میکند؟
اعلان متغیر ها و تنسور ها
استفاده از Placeholder ها و متغیر ها
اعلان عملیات
پیاده سازی توابع فعال ساز
کار کردن با پایگاههای دانش
سخن پایانی
مطالب امروز و مطالبی که در هفته های آتی منتشر خواد شد از کتاب Tensorflow machine learning cookbook آقای Nick McClure استخراج شده و با کسب اجازه از ایشان آنها را در اختیار کاربران فارسی زبان قرار خواهیم داد. این کتاب برای افرادی است که با زبان برنامه نویسی پایتون و یادگیری ماشینی آشنایی دارند. در اکثر موارد توضیحاتی که توسط نویسنده در کتاب آورده شده خیلی سطحی هستند، به همین دلیل بنا به ضرورت در بسیاری از موارد سعی میکنیم مطالبی فراتر از موارد مطرح شده در کتاب را در اختیارتان بگذاریم.
مقدمه
فریم ورک تنسور فلو گوگل یک روش منحصر به فرد برای حل مسائل مختلف دارد. این روش منحصر به فرد به ما این امکان را میدهد که مسائل یادگیری ماشینی را به شکل موثر حل کنیم. یادگیری ماشینی تقریبا در تمامی سطوح زندگی و کار ما استفاده میشود، اما کاربرد مهمتر آن در بینایی ماشین،بازتشخیص صدا،ترجمه زبان، و مراقبت سلامت است. در این فصل، مفاهیم اولیه این فریم ورک بررسی و در بخش های دیگر به تدریج تکنیک های رایج یادگیری ماشینی در محیط این فریم ورک پیاده سازی خواهند شد. دانستن این اصول برای درک دستورالعمل هایی که در ادامه ذکر خواهد شد ، ضروری است.
تنسورفلو چگونه کار میکند؟
در نگاه اول ممکن است محاسباتی که در تنسورفلو انجام میشود پیچیده به نظر برسد، اما این پیچیدگی امکان پیاده سازی الگوریتم های پیچیده را به شکلی ساده تر ممکن میسازد. در حال حاضر این فریم ورک توسط سه سیستم عامل ویندوز،لینوکس و مک پشتیبانی میشود. کدهایی که در ادامه استفاده خواهند شد در سیتم عامل لینوکس بدون هیچ مشکلی آزمایش شده است، اما مطمینا در دو سیستم عامل دیگر نیز قابل اجزا هستند. تمامی این کد ها در این مخزن قرار گرفته است، این کدها در ابتدا توسط پایتون پایتون ۳٫۴ و تنسورفلو (نسخه ۰٫۱۲ ) نوشته شد اما برای نسخه های بالاتر مانند ۱٫۰٫۱ نیز بروز رسانی شده اند. تنسورفلو قابلیت اجزا در دو حالت CPU و GPU را دارد، اما بیشتر الگویتم هایی که در ادامه مورد بررسی قرار خواهند گرفت، نیاز است که بر روی کارت گرافیک اجرا گردند (به علت سرعت بالای کارت گرافیک ها در پردازش های موازی). تمامی کارت گرافیک های انویدیا که در این لیست قرار گرفته اند توسط این فریم ورک پشتیبانی میشوند. کارت گرافیک های محبوب برای تنسورفلو عبارتند از :کارت گرافیک های انویدیا با معماری Tesla و Pascal با حداقل ۴ گیگابایت حافظه داخلی. برای اجرای کد ها بر روی کارت گرافیک ابتدا نیاز است که Nvidia Cuda Toolkit از طریق این لینک دانلود و نصب کنید.برخی از کد های این مجموعه برای اجرا شدن نیاز به پکیج های رایج پایتون مثل Scipy،Numpy و Scikit-Learn دارند، تمامی این پکیج های به صورت یکجا در Anaconda قرار گرفته اند که میتوانید آن را از طریق این لینک دانلود کنید.
تمامی دستورالعمل های موجود در این مجموعه از ۱۱ طرح کلی زیر پیروی میکنند:
۱- وارد کردن یا تولید پایگاه های دانش : تمامی الگوریتم های یادگیری ماشینی به پایگاه دانش وابسته هستند. در این مجموعه، ما یا از پایگاه های دانش رایج استفاده خواهیم کرد، یا آنها را تولید میکنیم. در برخی مواقع بهتر است که به داده های تولید شده تکیه کنیم زیرا نیاز است فقط خروجی مورد انتظار را بدانیم. در بیشتر موارد از پایگاه های دانش رایج استفاده خواهیم کرد که در بخش های بعدی طریقه دسترسی به این پایگاه های دانش به صورت کامل توضیح داده خواهد شد.
۲- انتقال و نرمال سازی داده ها : معمولا داده های ورودی به شکلی که مورد انتظار تنسورفلو هست ، نیستند و نیاز است این داده ها به شکل قابل قبول تنسورفلو تبدیل شوند، در نتیجه برای استفاده از آنها نیاز است که این داده ها تغییر شکل داده شوند. همچنین در بیشتر الگوریتم ها داده های ورودی نیز باید نرمال سازی شوند، بدین منظور تنسورفلو دارای توابع تعبیه شده ای است که این کار را برای ما انجام میدهد، به عنوان مثال:
|
1 2 3 |
data = tf.nn.batch_norm_with_global_normalization(...) |
۳-تقسیم داده های پایگاه دانش به سه دسته داده آموزش، داده اعتبارسنجی و داده آزمایش: معمولا نیاز است که الگوریتم های ما توسط داده هایی غیر از داده های آموزش، آزمایش شوند، همچنین در بسیاری از الگوریتم ها نیاز به یک مجموعه داده است که توسط آنها مقدار ابر پارامتر ها را تنظیم کنیم، بدین منظور از دو مجموعه داده آزمایش و اعتبار سنجی استفاده میشود.
۴-تنظیم پارامتر های الگوریتم (هایپر پارمتر ها): الگوریتم های ما عموما دارای یک مجموعه از پارامتر ها هستند که در طول اجرای الگوریتم به صورت ثابت باقی میمانند. به عنوان مثال این مقدار میتواند تعداد تکرارها ، نرخ یادگیری یا اندازه دسته داده ما باشد. این مجموعه پارامتر ها عموما در ابتدای الگوریتم به شکل زیر مقدار دهی اولیه میشوند:
|
1 2 3 4 5 |
learning_rate = 0.01 batch_size = 100 iterations = 1000 |
۵- مقدار دهی اولیه متغیر ها و placeholder ها : تنسورفلو مقادیر متغیر ها و وزن ها/بایاس ها را در طول فرآیند بهینه سازی برای کمینه کردن تابع هزینه تنظیم میکند، برای این امر تنسورفلو باید بداند که کدام مقادیر قابل تغییر و کدامیک ثابت هستند. ابتدا داده ها توسط placeholder ها به الگوریتم مورد نظر داده میشوند، نوع این داده ها بایستی مشخص شوند . در اکثر الگوریتم هایی که در ادامه بحث خواهند شد ما از نوع داده float32 استفاده خواهیم کرد. تنسورفلو همچنین دو نوع داده float64 و float16 را پشتیبانی میکند. توجه کنید هر چه از نوع داده با بایت بیشتر استفاده کنید (به عنوان مثال float64) الگوریتم شما کند تر عمل خواهد شد، همچنین در صورتی که از نوع داده با بایت کمتر استفاده شود (به عنوان مثال float16) به نتایج با دقت کمتری دست پیدا خواهید کرد. نمونه ای از مقدار دهی اولیه placeholderها:
|
1 2 3 4 5 6 7 |
a_var = tf.constant(42) x_input = tf.placeholder(tf.float32, [None, input_size]) y_input = tf.placeholder(tf.float32, [None, num_classes]) |
۶-تعریف ساختار مدل :بعد از انجام عملیات ذکر شده بر روی داده ها و مقدار دهی کردن متغیر ها و placeholder ها، نوبت به تعریف مدل میرسد، این امر با ایجاد کردن یک گراف محاسباتی انجام میشود. این موارد به صورت جزیی در بخش های بعدی مورد بررسی قرار خواهد گرفت . مثال زیر یک مدل خطی ساده است:
|
1 2 3 |
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix) |
۷- اعلان تابع هزینه: بعد از تعریف مدل، نوبت به ارزیابی خروجی میرسد. اینجا جایی است که ما تابع هزینه را اعلان میکنیم. نقش تابع هزینه در گفتن میزان تفاوت خروجی پیش بینی شده مدل ما از مقادیر واقعی خیلی مهم است. توابع هزینه متفاوتی وجود دارد که در ادامه به صورت جزیی به آنها خواهیم پرداخت، به عنوان مثال:
|
1 2 3 |
loss = tf.reduce_mean(tf.square(y_actual – y_pred)) |
۸- مقدار دهی اولیه و آموزش مدل: بعد انجام مراحل بالا، نوبت به ایجاد یک نمونه از گراف میرسد، سپس داده ها توسط placeholder ها به مدل داده میشوند، و اجازه میدهیم که تنسورفلو مقادیر متغیر ها را برای پیش بینی هر چه بهتر داده های آموزش تغییر دهد. یک راه برای مقدار دهی اولیه گراف محاسباتی به شکل زیر است:
|
1 2 3 4 5 6 |
with tf.Session(graph=graph) as session: ... session.run(...) ... |
راه دیگر برای مقدار دهی اولیه گراف استفاده از کد زیر است:
|
1 2 3 4 |
session = tf.Session(graph=graph) session.run(…) |
۹- ارزیابی مدل: هنگامی که مدل ایجاد و آموزش داده شد نوبت به ارزیابی آن میرسد، بدین منظور نیاز است مدل توسط داده های جدید مورد ارزیابی قرار گیرد و بررسی شود مدل در مواجه شدن با داده هایی جدید چگونه عمل میکند.این ارزیابی به ما این اجازه را میدهد تا ببینیم آیا مدل ما بیش برارزش یا underfit شده است. این موارد نیز به صورت جزیی در بخش های بعدی شرح داده خواهد شد.
۱۰- تنظیم ابرپارامتر ها: در بیشتر مواقع نیاز است که به گام های قبلی بازگردیم و مقدار تعدادی از ابرپارامترها را با توجه به کارایی مدل، اصلاح کنیم. در نتیجه گام قبلی مجددا با ابرپارامتر های جدید اجرا میگردد و مدل توسط مجموعه داده اعتبارسنجی مورد ارزیابی قرار میگیرد.
۱۱- پیش بینی خروجی های جدید: در گام آخر، بعد از نهایی شدن فرآیند آموزش نوبت به پیش بینی داده های دیده نشده توسط مدل میرسد.
عملیات بهینه سازی مقادیر مدل در یک گراف محاسباتی انجام میشود. این گرافهای محاسباتی، گراف هایی جهت دار غیر بازگشتی هستند. با توجه به ساختار گراف محاسباتی و قابلیت های منحصر به فرد آن، عملیات مشتقگیری میتواند برای هر کدام از متغیر ها به صورت جداگانه محاسبه و مقادیر متغیرها بروز رسانی شوند.
اعلان تنسورها (tensors)
تنسور، ساختار داده اولیه ای است که تنسورفلو از آن برای انجام عملیات بر روی گراف محاسباتی استفاده میکند. این تنسورها میتوانند به عنوان متغیر اعلان یا به عنوان placeholder به مدل تغذیه شوند. به عبارت ساده در تنسورفلو، تنسور را میتوان به عنوان یک آرایه چند بعدی در نظر گرفت. به عنوان مثال، میتوان یک دسته کوچک از عکس ها را به عنوان یک آرایه چهاربعدی از اعداد ممیز شناور به شکل زیر نمایش داد :
|
1 2 3 |
[batch, height, width, channels] |
هنگامی که ما یک تنسور را ایجاد و به عنوان یک متغیر اعلان میکنیم تنسورفلو چندین ساختار گراف را در گراف محاسباتی ما ایجاد میکند.
راههای مختلف ایجاد تنسور در تنسورفلو به شکل زیر است :
۱- ایجاد تنسور ثابت :
یک تنسور پرشده با عنصرهای صفر:
|
1 2 3 |
zero_tsr = tf.zeros([row_dim, col_dim]) |
یک تنسور پرشده با عنصرهای یک :
|
1 2 3 |
ones_tsr = tf.ones([row_dim, col_dim]) |
یک تنسور پرشده با مقدار ثابت :
|
1 2 3 |
filled_tsr = tf.fill([row_dim, col_dim], 42) |
ایجاد یک تنسور از اعداد ثابت :
|
1 2 3 |
constant_tsr = tf.constant([1,2,3]) |
۲- ایجاد تنسور با شکل مشابه:
همچنین میتوان متغیر هایی بر اساس شکل دیگر تنسورها به صورت زیر ایجاد کرد: (در این موارد تنسوری که شما از آن برای ایجاد یک تنسور مشابه استفاده میکنیم بایستی از قبل مقدار دهی شده باشد، در صورتی که بخواهیم تمامی این تنسورها را به صورت یکجا مقدار دهی کنیم با خطا روبرو خواهید شد.)
|
1 2 3 4 5 |
zeros_similar = tf.zeros_like(constant_tsr) ones_similar = tf.ones_like(constant_tsr) |
۳- تنسور های ترتیبی:
تنسورفلو این اجازه را به ما میدهد تنسورهایی را ایجاد کنیم که دارای یک بازه تعرف شده هستند. تابع زیر مشابه تابع ()range موجود در پایتون و ()linspace در Numpy کار میکند. به عنوان مثال، خروجی تابع زیر یک دنباله تنسور [۰٫۰, ۰٫۵, ۱٫۰] است. خروجی تولید شده در این تابع شامل عدد پایانی(num) نیز میشود.
|
1 2 3 |
linear_tsr = tf.linspace(start=0, stop=1, num=3) |
در تابع زیر خروجی یک دنباله از [۶, ۹, ۱۲] است. در این تابع خروجی شامل مقدار limit نمیشود.
|
1 2 3 |
integer_seq_tsr = tf.range(start=6, limit=15, delta=3) |
۴-تانسورهای تصادفی:
کد زیر باعث ایجاد اعداد تصادفی میشود که از یک توزیع یکنواخت هستند:
|
1 2 3 |
randunif_tsr = tf.random_uniform([row_dim, col_dim], minval=0, maxval=1) |
اعدادی که در این بازه انتخاب میشوند در بازه minval و maxval هستند که خود maxval شامل آن نمیشود، به عبارتی x در بازه زیر خواهد بود:
|
1 2 3 |
minval <= x < maxval |
برای ایجاد یک مجموعه اعداد تصادفی از یک توزیع نرمال، تابع زیر استفاده میشود:
|
1 2 3 |
randnorm_tsr = tf.random_normal([row_dim, col_dim], mean=0.0, stddev=1.0) |
در این تابع mean میانگین و stddev انحراف از معیار است.
در تنسورفلو برای ایجاد یک توزیع نرمال بریده شده از تابع ()truncated_normal استفاده میشود. توزیع نرمال دارای بسیاری خواص مطلوب است و یکی از توزیع هایی است که کاربردهای زیادی دارد. دامنه این توزیع از منفی بی نهایت تا مثبت بی نهایت است، اما در بسیاری از موارد در عمل مشاهدات ثبت شده از راست یا از چپ یا از دو طرف محدود شده هستند. در این حالت با یک توزیع روبرو هستیم که به آن توزیع نرمال بریده شده گفته می شود.
|
1 2 3 |
runcnorm_tsr = tf.truncated_normal([row_dim, col_dim], mean=0.0, stddev=1.0) |
در مواقعی نیاز به تصادفی کردن عناصر یک آرایه است، بدین منظور تنسورفلو دارای دو تابع ()random_shuffle و ()random_crop است:
|
1 2 3 4 |
shuffled_output = tf.random_shuffle(input_tensor) cropped_output = tf.random_crop(input_tensor, crop_size) |
در بخش های بعدی خواهید دید مواردی پیش میآید که نیاز به برش تصادفی یک عکس با اندازه (height, width, 3) است (در اینجا عدد سه به تعداد کانال های عکس اشاره دارد). در این موارد میتوان از این تابع به شکل زیر استفاده کرد:
|
1 2 3 |
cropped_image = tf.random_crop(my_image, [height/2, width/2, 3]) |
بعد از ایجاد تنسور مورد نظر اکنون نوبت ایجاد متغیر متناظر آن میرسد، که این کار از طریق قرار دادن تنسور در داخل تابع ()Variable به شکل زیر امکان پذیر است:
|
1 2 3 |
my_var = tf.Variable(tf.zeros([row_dim, col_dim])) |
در بخش بعدی جزییات تعریف متفیر ها شرح داده خواهد شد. اما در تنسورفلو ما فقط به توابع تعبیه شده ای که در بالا توضیح داده شد، محدود نمیشویم بلکه میتوان با استفاده از تابع ()convert_to_tensor هر آرایه numpy را به یک لیست، یا مقادیر ثابت را به یک تنسور تبدیل کرد.
استفاده از متغیر ها و placeholder ها
Placeholder ها و متغیرها ابزارهای کلیدی برای استفاده از گرافهای محاسباتی در تنسورفلو هستند. شاید این سوال برای خیلی از افرادی که تازه با این فریم ورک شروع به کار میکنند به وجود آید، لذا لازم میدونم قبل از پرداختن به موارد بعدی تفاوت variable و placeholder رو به صورت خلاصه برایتان ذکر کنم :
در تنسورفلو از tf.Variable برای داده های قابل آموزش مثل وزن ها و بایاس ها استفاده میشود به عبارتی شامل پارامتر هایی است که الگوریتم در طول فرآیند آموزش مقادیر آنها را برای بهینه کردن الگوریتم تغییر میدهد، اما tf.placeholder محلی برای قرار گیری نمونه های آموزش با نوع و شکل مشخص است ، در واقع مدل شما توسط این داده ها تغذیه میشود. به عنوان مثال :
|
1 2 3 |
x = tf.placeholder(tf.float32, [None, 784]) |
در مثال بالا x یک placeholder است ، مقداری که به عنوان ورودی به مدل داده میشود .
ایجاد یک متغیر از طریق تابع ()Variable امکان پذیر است، که یک تانسور را به عنوان ورودی دریافت کرده و یک خروجی متغیر تولید میکند. در این مرحله ما فقط متغییر را اعلان کردیم سپس نوبت به مقدار دهی اولیه متفییر میرسد. با مقداردهی کردن کردن، تنسورفلو متغیر را با متد متاظر آن، در گراف محاسباتی قرار میدهد. یک مثال از ایجاد و مقداردهی اولیه کردن یک متغیر در زیر آورده شده است:
|
1 2 3 4 5 6 |
my_var = tf.Variable(tf.zeros([2,3])) sess = tf.Session() initialize_op = tf.global_variables_initializer () sess.run(initialize_op) |
همانگونه که در بالا توضیح داده شد Placeholder ها محلی برای نگهداری نمونه های آموزشی هستند که قرار است به مدل تغدیه شوند. Placeholder ها، داده خود را توسط آرگومان feed_dict در هنگام فراخوانی Session دریافت میکند. قبل از قرار دادن Placeholder در گراف نیاز است که حداقل یک عملیات بر روی آن انجام شود، در مثال زیر ابتدا عملیات identity بر روی x انجام شده است که خروجی آن مشابه ورودی آن یعنی x است.
|
1 2 3 4 5 6 7 |
sess = tf.Session() x = tf.placeholder(tf.float32, shape=[2,2]) y = tf.identity(x) x_vals = np.random.rand(2,2) sess.run(y, feed_dict={x: x_vals}) |
نکته: در صورتی که در هنگام فراخوانی آرگومان feed_dict ازPlaceholder خود ارجاع استفاده شود، با خطا روبرو خواهید شد. به عنوان مثال کد زیر باعت تولید خطا خواهد شد:
|
1 2 3 |
sess.run(x, feed_dict={x: x_vals}) |
در شکل زیر گراف محاسباتی مقدار دهی شده یک متغیر تشکیل شده از تنسور با عناصر صفر نمایش داده شده است:
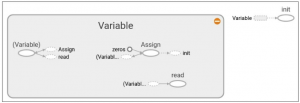
ناحیه خاکستری رنگ، یک نمایش دقیق از عملیات اعمال شده است . در شکل سمت راست گراف محاسباتی اصلی با جزییات کمتر نمایش داده شده است.
شکل گراف محاسباتی برای مثال بالا در Tensorboard به شکل زیر خواهد بود:
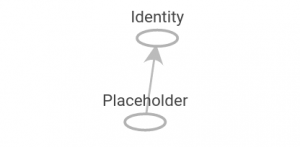
در طول اجرای گراف محاسباتی، نیاز است به تنسورفلو بگوییم متغیر هایی که توسط ما ایجاد شده اند را مقداردهی اولیه کند. تنسورفلو تابعی به نام ()global_variables_initializer دارد، این تابع تمامی متغیرهایی که توسط ما ایجاد شده اند را مقدار دهی اولیه میکند:
|
1 2 3 |
initializer_op = tf.global_variables_initializer () |
در صورتی که بخواهیم یک متغیر را با توجه به یک متغیر دیگر (که قبلا مقدار مقدار دهی شده است) مقدار دهی کنیم، نیاز است این عملیات به ترتیبی که مد نظر ما است انجام گردد، همانند مثال زیر:
|
1 2 3 4 5 6 7 8 |
sess = tf.Session() first_var = tf.Variable(tf.zeros([2,3])) sess.run(first_var.initializer) second_var = tf.Variable(tf.zeros_like(first_var)) # به متغیر اول وابسته است sess.run(second_var.initializer) |
کار با ماتریس ها
دانستن چگونگی کارکرد تنسورفلو با ماتریس ها برای درک جریان داده در طول گراف محاسباتی ضروری است. بسیاری از الگوریتم ها به عملیات ماتریسی وابسته هستند. تنسورفلو بدین منظور امکاناتی را در اختیار کاربر قرار میدهد که استفاده از آنها ساده است . برای تمامی مثال های بعدی، شما میتوانید با اجرای کد زیر یک session را ایجاد کنید:
|
1 2 3 4 |
import tensorflow as tf sess = tf.Session() |
ایجاد ماتریس
در بخش تنسور، شیوه ایجاد ماتریس ها با عناصر پرشده صفر و یک شرح داده شد. در کد زیر نمونه ای از این ماترسی ها نمایش داده شده است. به عنوان مثال در تنسورفلو با استفاده از تابع ()diag میتوان یک ماتریس قطری از یک آرایه یک بعدی ایجاد کرد (یک ماتریس قطری ماتریسی است که تمام درایههای خارج از قطر اصلی آن، همه صفر باشد)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
identity_matrix = tf.diag([1.0, 1.0, 1.0]) A = tf.truncated_normal([2, 3]) B = tf.fill([2,3], 5.0) C = tf.random_uniform([3,2]) D = tf.convert_to_tensor(np.array([[1., 2., 3.],[-3., -7., -1.],[0., 5., -2.]])) print(sess.run(identity_matrix)) [[ 1. 0. 0.] [ 0. 1. 0.] [ 0. 0. 1.]] print(sess.run(A)) [[ 0.96751703 0.11397751 -0.3438891 ] [-0.10132604 -0.8432678 0.29810596]] print(sess.run(B)) [[ 5. 5. 5.] [ 5. 5. 5.]] print(sess.run(C)) [[ 0.33184157 0.08907614] [ 0.53189191 0.67605299] [ 0.95889051 0.67061249]] print(sess.run(D)) [[ 1. 2. 3.] [-3. -7. -1.] [ 0. 5. -2.]] |
نکته: در صورتی که تابع (sess.run(C مجددا اجرا شود، ماتریس C دوباره با مقادیر جدید تصادفی مقدار دهی خواهد شد.
برای انجام عملیات جمع و تفریق میتوان به شکل زیر عمل کرد:
|
1 2 3 4 5 6 7 8 |
print(sess.run(A+B)) [[ 4.61596632 5.39771316 4.4325695 ] [ 3.26702736 5.14477345 4.98265553]] print(sess.run(B-B)) [[ 0. 0. 0.] [ 0. 0. 0.]] |
و برای انجام عملیات ضرب از تابع ()matmul استفاده میشود:
|
1 2 3 4 5 |
print(sess.run(tf.matmul(B, identity_matrix))) [[ 5. 5. 5.] [ 5. 5. 5.]] |
این تابع همچنین دارای آرگومان هایی است که میتوان قبل از اعمال عملیات ضرب، ترانهاده ماتریس را محاسبه کرد:
|
1 2 3 4 5 |
print(sess.run(tf.transpose(C))) [[ 0.67124544 0.26766731 0.99068872] [ 0.25006068 0.86560275 0.58411312]] |
برای محاسبه دترمینان یک ماتریس در تنسورفلو از تابع matrix_determinant استفاده میشود:
|
1 2 3 4 |
print(sess.run(tf.matrix_determinant(D))) -38.0 |
برای محاسبه معکوس یک ماتریس از تابع زیر استفاده میشود:
|
1 2 3 4 5 6 |
print(sess.run(tf.matrix_inverse(D))) [[-0.5 -0.5 -0.5 ] [ 0.15789474 0.05263158 0.21052632] [ 0.39473684 0.13157895 0.02631579]] |
برای محاسبه تجزیه چولسکی یک ماتریس از تابع cholesky استفاده میشود:
|
1 2 3 4 5 6 |
print(sess.run(tf.cholesky(identity_matrix))) [[ 1. 0. 1.] [ 0. 1. 0.] [ 0. 0. 1.]] |
برای محاسبه مقدارویژه و بردارویژه از تابع self_adjoint_eig استفاده میشود:
|
1 2 3 4 5 6 7 |
print(sess.run(tf.self_adjoint_eig(D)) [[-10.65907521 -0.22750691 2.88658212] [ 0.21749542 0.63250104 -0.74339638] [ 0.84526515 0.2587998 0.46749277] [ -0.4880805 0.73004459 0.47834331]] |
اعلان عملیات
در کنار عملیات استاندارد ریاضی، تنسورفلو عملیات دیگری را برای کاربران فراهم میکند که شما به عنوان یک برنامه نویس باید از آنها آگاه باشید. همانند بخش قبلی، قبل از هر کار باید یک session برای گراف ایجاد کنیم که این کار با اجرای کد زیر امکان پذیر است:
|
1 2 3 4 |
import tensorflow as tf sess = tf.Session() |
تنسورفلو دارای عملیات استاندارد ریاضی برای کار کردن بر روی تنسورها است، این عملیات عبارتند از: ()add(), sub(), mulو ()div. توجه کنید، تمام این عملیات به صورت عنصر به عنصر بر روی ورودی انجام میشوند. در تابع ()div، در صورتیکه یکی از خروجی ها از نوع float باشد خروجی تابع نیز float خواهد بود اما در غیر این صورت خروجی به صورت یک عدد از نوع integer برگردانده خواهد شد. برای برگرداندن خروجی با نوع float از تابع ()truediv استفاده میشود. این تابع ابتدا ورودی ها را به float تبدیل میکند سپس عملیات تقسیم را اجرا میکند. در صورتی که اعدادی از نوع float داشته باشیم و بخواهیم یک عدد رند شده float را برگردانیم از تابع ()floordiv استفاده میشود:
|
1 2 3 4 5 6 7 8 |
print(sess.run(tf.div(3,4))) 0 print(sess.run(tf.truediv(3,4))) 0.75 print(sess.run(tf.floordiv(3.0,4.0))) 0.0 |
تابع بعدی، تابع ()mod است. این تابع باقیمانده عملیات تقسیم را برمیگرداند:
|
1 2 3 4 |
print(sess.run(tf.mod(22.0, 5.0))) 2.0 |
ضرب خارجی بین دو ماتریس توسط تابع ()cross انجام میشود. ورودی های این تابع بایستی دو بردار سه بعدی باشند:
|
1 2 3 4 |
print(sess.run(tf.cross([1., 0., 0.], [0., 1., 0.]))) [ 0. 0. 1.0] |
در مواردی نیاز است عملیاتی بر روی ورودی انجام شود و این توابع در تنسورفلو تعبیه نشده است، در این موارد شما میتوانید یک تابع شخصی برای انجام عملیات مورد نظر ایجاد کنید. فرض کنید که قصد دارید تابع چند جمله ۳x^2-x+10 را به گراف محاسباتی خود اضافه کنید این کار را میتوان به شکل زیر انجام داد:
|
1 2 3 4 5 6 |
def custom_polynomial(value): return(tf.sub(3 * tf.square(value), value) + 10) print(sess.run(custom_polynomial(11))) 362 |
در زیر تعدادی از توابع رایج برای انجام عمیلات ریاضی بر روی ورودیها آورده شده است. تمام این توابع عمیلات مورد نظر را به صورت عنصر به عنصر انجام میدهند.
|
1 2 3 |
Abs(),Cell(),Cos(),Exp(),Floor(),Inv(),Log(),Maximum(),Minimum(),Neg(),Pow(),Round(),Rsqrt(),Sign(),Sin(),Sqrt(),Square() |
پیاده سازی توابع فعال ساز
توابع فعال ساز بخشی جدانشدنی از شبکه های عصبی هستند. در تنسورفلو توابع فعال ساز عملیات غیر خطی را بر روی تانسورها انجام میدهند. طریقه کارکرد آنها همانند عملیات ریاضی که قبلا انجام دادیم است، یکی از مفاهیم اساسی این توابع معرفی عملیات غیر خطی در گراف محاسباتی ماست. همانگونه که در بخش قبلی ذکر شد ابتدا نیاز است یک گراف ایجاد کنیم، این عملیات از طریق دستورات زیر امکان پذیر است:
|
1 2 3 4 |
import tensorflow as tf sess = tf.Session() |
توابع فعال ساز در کتابخانه شبکه عصبی تنسورفلو (tensorflow.nn) قرار گرفته اند، علاوه بر استفاده از توابع تعبیه شده در تنسورفلو، ما میتوانیم توابع فعال ساز خود را نیز ایجاد کنیم.برای وارد کردن این ماژول از کد زیر استفاده میکنیم:
|
1 2 3 |
import tensorflow.nn as nn |
تابع یکسوساز خطی یا ReLU، رایج ترین تابع برای معرفی عملیات غیر خطی در شبکه های عصبی است. این تابع ساده به شکل (max(0,x است، این تابع همچنین پیوسته اما نرم (Smooth) نیست. به عنوان مثال:
|
1 2 3 4 |
print(sess.run(tf.nn.relu([-3., 3., 10.]))) [ 0. 3. 10.] |
البته انواع متفاوتی از این تابع وجود دارد، به عنوان مثال ReLU6. این تابع به شکل (min(max(features, 0), 6 است که برای اولین بار توسط Alex Krizhevsky در مقاله Convolutional Deep Belief Networks on CIFAR-10 معرفی شد. (برای جزئیات بیشتر بخش ۴٫۱ مقاله را بخوانید) این تابع یک نسخه از تابع سیگموید سخت (hard-sigmoid) است، به لحاظ محاسباتی سریعتر و پدیده ناپدید شدن گرادیان مخصوصا در نواحی نزدیک به صفر در آن وجود ندارد. تابع سیگموید استاندارد به شکل
|
1 2 3 |
1/(1+e^(-x)) |
است، این تابع به علت محاسبه عملیات نمایی ()exp آهسته عمل میکند، ذکر این نکته ضروری به نظر میرسد که کامپیوترها در واقع عملیات نمایی به شکلی که در تصور خیلی از افراد است را انجام نمیدهد، نتایجی که شما می بینید اینطور به نظر میرسد، اما در واقع کاری که کامپوتر ها انجام میدهند یک تقریب از یک چند جمله ای با دقت بالا است پرداختن به جزییات بیشتر خارج از بحث ما است اما در صورتی که علاقه مند هستید میتوانید جزییات بیشتر را در این مقاله ببینید. در بسیاری از موارد، ما به یک عملیات نمایی با دقت بالا نیاز نداریم، و یک تقریب برای گرفتن جواب صحیح کافی به نظر میرسد. به عنوان مثال در شبکه های عصبی مقادیر دقیق به اندازه مقادیر تقریبی مهم نیستند، چون نتایج خروجی همیشه با درصدی از خطا همراه هستند. در شکل زیر سه نوع مختلف از تابع سیگموید نمایش داده شده است :
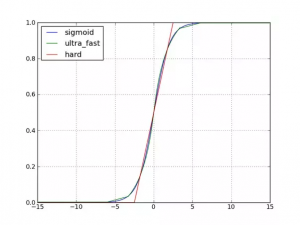
همانگونه که در شکل بالا نمایش داده شده است تابع سیگموید (آبی رنگ) نرم است در حالیکه دو تابع دیگر (سبز رنگ و قرمز رنگ) به شکل خطی تکه به تکه هستند. در تابع سیگموید از ()exp استفاده شده است اما در دو شکل دیگر به عنوان مثال سیگموید سخت این تابع به شکل (max(0, min(1, (x + 1)/2) است.دو شکل دوم نسب به سیگموید سریعتر عمل میکنند اما با تقریب کمتر. این خطا اینقدر کم است که بسیاری از شبکه های عصبی میتوان، این میزان خطا را نادیده گرفت. البته جزییات دیگری نیز وجود دارد، اما راه نسبتا درازی را در پیش داریم و پرداختن به جزییات به این شکل، باعث کند شدن فرآیند ارایه مطالب میشود به همین دلیل در مواردی که نیاز به دانستن جزییات بیشتر باشد لینک را در میان مطالب قرار خواهم داد و خواننده بنا به نیاز میتواند آنها را مطالعه کند. از تابع ReLU6 در پست های بعدی، وقتی وارد پیاده سازی شبکه های کانولوشنال و شبکه ای عصبی بازگشتی شدیم استفاده خواهیم کرد. مثال:
|
1 2 3 4 |
print(sess.run(tf.nn.relu6([-3., 3., 10.]))) [ 0. 3. 6.] |
تابع بعدی، تابع سیگموید است که رایجترین تابع فعالساز نرم و پیوسته است. این تابع همچنین تابع لجستیک نامیده میشود . امروزه اغلب از این تابع به علت رخ دادن پدیده ناپدید شدن گرادیان در شبکه های عصبی عمیق استفاده نمیشود. مثال:
|
1 2 3 4 |
print(sess.run(tf.nn.sigmoid([-1., 0., 1.]))) [ 0.26894143 0.5 0.7310586 ] |
توجه کنید برخی از توابع، مثل تابع سیگموید “صفر مرکز” نیستند، به همین علت نیاز است که قبل از استفاده از گراف محاسباتی داده ها zero-mean شوند.
تابع نرم بعدی تانژانت هایپربولیک است. این تابع خیلی شبیه به تابع سیگموید است اما محدوده آن برخلاف تابع سیگمید (که بین صفر و یک است)، بین ۱ و -۱ است. این تابع به شکل tanh(x)=2⋅σ(۲x)−۱ است (()σ تابع سیگموید است).مثال:
|
1 2 3 4 |
print(sess.run(tf.nn.tanh([-1., 0., 1.]))) [-0.76159418 0. 0.76159418 ] |
از تابع softsign همچنین به عنوان یک تابع فعال ساز استفاده میشود که به شکل
|
1 2 3 |
x/(abs(x) + 1) |
است. این تابع یک تقریب پیوسته از تابع sign (بیشتر بخوانید) است. مثال:
|
1 2 3 4 |
print(sess.run(tf.nn.softsign([-1., 0., -1.]))) [-0.5 0. 0.5] |
همچنین تابع softplus یک نسخه نرم شده از تابع ReLU که به شکل
|
1 2 3 |
log(exp(x) + 1) |
است.مثال:
|
1 2 3 4 |
print(sess.run(tf.nn.softplus([-1., 0., -1.]))) [ 0.31326166 0.69314718 1.31326163] |
توجه کنید تابع softplus با افزایش مقدار ورودی به سمت بینهایت، اما تابع softsign به سمت ۱ میل میکند. در صورت کاهش ورودی softplus به صفر و softsign به -۱ نزدیک میشود.
تابع ELU بسیار مشابه تابع softplus میباشد اما خط مجانب پایین آن به جای ۰ عدد -۱ است. این تابع به شکل زیر است:
|
1 2 3 |
(exp(x)+1) اگر x < 0 در غیر اینصورت x |
جزییات زیادی در مورد نحوه انتخاب تابع فعال ساز با توجه به معماری وجود دارد که در پست های بعدی بنا به ضرورت وارد جزییات خواهیم شد. به عنوان مثال تابع سیگموید بازه ای بین ۰ و ۱ دارد در نتیجه گراف محاسباتی ما فقط میتواند خروجی در این بازه تولید کند یا در صورتی که داده های ما zero-mean باشند در این صورت باید از توابع فعال سازی مثل tanh و softsign استفاده کنیم که واریانس زیادی در نواحی اطراف صفر را حفظ میکنند. در صورتی که مقادیر تانسور های ما مثبت هستند انتخاب ایده آل، توابعی هستند که واریانس را در دامنه مثبت نگه میدارند.
در شکل زیر چهار تابع Softplus،ReLU،ReLU6 وELU نمایش داده شده است. تمامی این توابع در ناحیه سمت چپ صفر و دارای یک خط مجانب تخت هستند، و در سمت راست صفر و به صورت خطی افزایش پیدا میکنند (به جزء ReLU6 که ماکسیمم آن ۶ است)
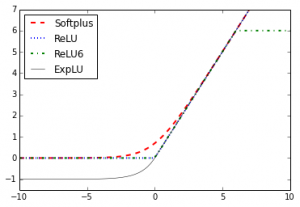
همانگونه که در شکل زیر پیداست، توابع Sigmoid،Tanh و Softsign نرم و دارای شکل S مانندی هستند. در این توابع دو خط مجانب افقی وجود دارد.
کار کردن با پایگاه های دانش
در پست های بعدی ما از پایگاه های دانش رایج به صورت فراوان استفاده میکنیم، به همین دلیل در این بخش طریقه کارکردن با انواع مختلف پایگاه های دانش به وسیله تنسورفلو و پایتون شرح داده خواهد شد. برخی از این پایگاه های دانش در کتابخانه های پایتون تعبیه شده اند اما برای استفاده از سایر پایگاه های دانش نیاز است آنها بوسیله اسکریپت های پایتون دانلود شوند.
این پایگاه دانش مسلما کلاسیک ترین پایگاه دانش در یادگیری ماشینی یا شاید در علم آمار باشد. در این پایگاه داده ویژگی های سه نوع گل زنبق از جمله طول وعرض کاسبرگ، طول و عرض گلبرگ قرار گرفته است. برای بارگزاری این پایگاه دانش از ماژول datasets موجود در کتابخانه Scikit Learn به صورت زیر استفاده میشود:
|
1 2 3 4 5 6 7 8 |
from sklearn.datasets import load_iris iris = load_iris() print(len(iris.data)) print(len(iris.target)) print(iris.data[0]) print(set(iris.target)) |
این پایگاه دانش یکی از پایگاه های دانش دانشگاه ماساچوست در امهرست است که شامل اطلاعات مربوط به وزن کودکان در ابتدای تولد آنها و… است. برای دسترسی به این داده ها در پایتون به شکل زیر عمل میکنیم:
|
1 2 3 4 5 6 7 8 9 10 |
import requests birthdata_url = 'https://github.com/nfmcclure/tensorflow_cookbook/raw/master/01_Introduction/07_Working_with_Data_Sources/birthweight_data/birthweight.dat' birth_file = requests.get(birthdata_url) birth_data = birth_file.text.split('rn') birth_header = birth_data[0].split('t') birth_data = [[float(x) for x in y.split('t') if len(x)>=1] for y in birth_data[1:] if len(y)>=1] print(len(birth_data)) print(len(birth_data[0])) |
این پایگاه دانش شامل اطلاعات مربوط به مسکن است. برای دسترسی به این داده ها در پایتون به شکل زیر عمیل میکنیم:
|
1 2 3 4 5 6 7 8 9 |
import requests housing_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' housing_header = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] housing_file = requests.get(housing_url) housing_data = [[float(x) for x in y.split(' ') if len(x)>=1] for y in housing_file.text.split('n') if len(y)>=1] print(len(housing_data)) print(len(housing_data[0])) |
پایگاه دانش ارقام دست نویس MNIST:
این پایگاه دانش شامل ۷۰۰۰۰ عکس از اعداد دستنویس ۰ تا ۹ است که ۶۰۰۰۰ تای آنها آنها مربوط به دسته آموزش و مابقی آنها برای آزمایش استفاده میشود. از این پاپگاه دانش به صورت فراروان در بازشناسی عکس استفاده میشود، به همین علت، تنسورفلو این پایگاه دانش را به صورت یک تابع تعبیه شده در درون خود قرار داده است. برای دسترسی به این پایگاه دانش از کد زیر میتوان استفاده کرد:
|
1 2 3 4 5 6 7 8 |
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) print(len(mnist.train.images)) print(len(mnist.test.images)) print(len(mnist.validation.images)) print(mnist.train.labels[1,:]) |
کتابخانه یادگیری ماشینی دانشگاه کالیفرنیا پایگاه دانشی به نام spam-ham text دارد. برای دسترسی به این پایگاه دانش میتوان از کد زیر استفاده کرد:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import requests import io from zipfile import ZipFile # Get/read zip file zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip' r = requests.get(zip_url) z = ZipFile(io.BytesIO(r.content)) file = z.read('SMSSpamCollection') # Format Data text_data = file.decode() text_data = text_data.encode('ascii',errors='ignore') text_data = text_data.decode().split('n') text_data = [x.split('t') for x in text_data if len(x)>=1] [text_data_target, text_data_train] = [list(x) for x in zip(*text_data)] print(len(text_data_train)) print(set(text_data_target)) print(text_data_train[1]) |
در این پایگاه دانش، اطلاعات مربوط به بررسی فیلم ها قرار گرفته است که به دو کلاس خوب و بد تقسیم میشوند.برای دسترسی به این پایگاه داده از کد زیر میتوان استفاده کرد:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import requests import io import tarfile movie_data_url = 'http://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz' r = requests.get(movie_data_url) # Stream data into temp object stream_data = io.BytesIO(r.content) tmp = io.BytesIO() while True: s = stream_data.read(16384) if not s: break tmp.write(s) stream_data.close() tmp.seek(0) # Extract tar file tar_file = tarfile.open(fileobj=tmp, mode="r:gz") pos = tar_file.extractfile('rt-polaritydata/rt-polarity.pos') neg = tar_file.extractfile('rt-polaritydata/rt-polarity.neg') # Save pos/neg reviews pos_data = [] for line in pos: pos_data.append(line.decode('ISO-8859-1').encode('ascii',errors='ignore').decode()) neg_data = [] for line in neg: neg_data.append(line.decode('ISO-8859-1').encode('ascii',errors='ignore').decode()) tar_file.close() print(len(pos_data)) print(len(neg_data)) print(neg_data[0]) |
CIFAR-10 :
این پایگاه دانش حاوی ۶۰۰۰۰ عکس (۳۲×۳۲) است که در ۱۰ کلاس طبقه بندی شده اند و از این تعداد ۵۰۰۰۰ مربوط به مجموعه آموزش و ۱۰۰۰۰ آن برای مجموعه آزمایش است. با توجه به اینکه حجم این پایگاه دانش نسبتا زیاد است و ما به صورت فراوان از آن استفاده خواهیم کرد شما میتوانید این پایگاه داده را از طریق این لینک دانلود کنید. طریقه استفاده از این دیتا بیس در پست های بعدی شرح داده خواهد شد.
The works of Shakespeare text data:
این پایگاه دانش نسخه الکترونیکی کارهای ویلیام شکسپیر است. برای استفاده از این پایگاه دانش میتوان از کد زیر استفاده کرد:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# The Works of Shakespeare Data import requests shakespeare_url = 'http://www.gutenberg.org/cache/epub/100/pg100.txt' # Get Shakespeare text response = requests.get(shakespeare_url) shakespeare_file = response.content # Decode binary into string shakespeare_text = shakespeare_file.decode('utf-8') # Drop first few descriptive paragraphs. shakespeare_text = shakespeare_text[7675:] print(len(shakespeare_text)) |
English-German sentence translation data :
وب سایت tatoeba ترجمه جملات به زبان های مختلف را جمع آوری میکند.این اطلاعات تحت مجوز کرییتیو کامنز منتشر شده اند. همچنین وب سایت ManyThings ترجمه جمله به جمله در قالب فایل متنی برای زبان های مختلف را منتشر کرده است. این داده ها در دسترس عموم قرار گرفته اند و شما میتوانید به راحتی آنها را دانلود کنید. در مثال زیر از پایگاه دانش آلمانی –انگلیسی استفاده شده است، اما شما بنا به نیاز میتوانید URL را عوض کنید:) برای زبان فارسی-انگلیسی میتوانید از این آدرس استفاده کنید)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# English-German Sentence Translation Data import requests import io from zipfile import ZipFile sentence_url = 'http://www.manythings.org/anki/deu-eng.zip' r = requests.get(sentence_url) z = ZipFile(io.BytesIO(r.content)) file = z.read('deu.txt') # Format Data eng_ger_data = file.decode() eng_ger_data = eng_ger_data.encode('ascii',errors='ignore') eng_ger_data = eng_ger_data.decode().split('n') eng_ger_data = [x.split('t') for x in eng_ger_data if len(x)>=1] [english_sentence, german_sentence] = [list(x) for x in zip(*eng_ger_data)] print(len(english_sentence)) print(len(german_sentence)) print(eng_ger_data[10]) |
سخن پایانی :
تمامی کد های استفاده شده در این پست در این لینک قرار گرفته شده، همچنین مستندات رسمی تنسورفلو در این لینک قرار گرفته است که در صورت نیاز میتوانید از آن استفاده کنید.
نسخه های جدیدتر، تنسورفلو تغییرات جزیی داشته است. همچنین در وبسایت تنسورفلو آموزش های متععدی وجود دارد که در صورت تمایل میتوانید آنها را در این لینک دنبال کنید.
تنسورفلو همچنین محلی برای کار با شبکه های عصبی دارد که شما میتوانید به صورت بصری یک شبکه عصبی با تغییر دادن پارامتر ها آموزش دهید. این لینک را دنبال کنید.
سوالات فراوانی نیز در وب سایتstackoverflow (برچسب Tensorflow)پرسیده شده است که محلی عالی برای جستجوی سوالات مشابه است.
هرچند تنسورفلو خیلی انعطاف پذیر است و شما میتوانید کارهای بسیار زیادی با آن انجام دهید، اما استفاده رایج آن در یادگیری عمیق است.
تنسورفلو همچنین دارای یک داکر عمومی است که جدید ترین نسخه تنسورفلو در آن قرار گرفته است. این لینک را دنبال کنید.
همچنین یک نسخه ماشین مجازی تنسورفلو که بر روی سیتم عامل لینوکس Ubuntu 15.04 نصب شده است را میتوانید از این لینک دانلود کنید. حجم این فایل دو گیگا بایت است که برای اجرای آن نیاز به نرم افزار VMware Player دارید.
سلام
میخواستم یکم بیشتر درباره ی سخت افزار مورد نیاز تنسورفلو برام توضیح بدید، مثلا اگر ما یه سیستم داشته باشیم با کانفیگ خیلی عالی و تنسورفلو رو روی اون ترین کنیم، بعد اینو ببریم روی یه سیستم با کانفیگ متوسط آیا میشه از اون شبکه ای که ترین کردیم استفاده کنیم؟
مثلا یه سیستم با یه گرافیک GTX 1080 برای ترین کردن و یه سیستم با یه گرافیک GTX 1050 یا GTX 1060 برای اجرا و پردیکت.
با تشکر
سلام
برای تست نیازی به سیستم قوی نیست میتونید با سی پی یو هم مدل رو ران کنید. یا با کارت گرافیک های ضعیف تر .
سلام و خسته نباشید جناب حسن پور.
ممنون از توضیحات و آموزش که بصورت رایگان در اختیار ما قرار دادید.
ببخشید در پست های مختلف من چندین بار مزاحم وقتتان شدم امیدوارم منو ببخشید.
سوالی داشتم من دیتاست خودم که متعلق به شرکت اینترنتی هست را با حدود ۸ ویژگی بوجود آوردم و بحث بر پیش بینی ریزش است که با دو لیبل که ۰ ریزش می کند و ۱ ریزش نمی کند مشخص شده است که دیتاست آموزش من را تشکیل می دهد .
از آنجایی که تمام مثال ها توضیحات و … برروی تصاویر زده شده همین امر باعث شده سوالاتی برایم بوجود بیاید.
اول که قطعا من به مسائلی مثل reshape کردن و نرمالسازی تصاویر نیاز ندارم درسته ؟ من تمام رکوردهام دستی بررسی کردم و داده های پرت هم دستی حذف کردم .
سوال دوم این که توابعی که استفاده کردید ، من برای آموزش دادن دیتاست خودم که تصویر نیست از چه توابعی استفاده کنم که نتیجه بهتری دریافت کنم .
ببخشید ممکن سوالات من عجیب یا شاید اشتباه باشه که بخاطر ورود به این موضوع و تازه کار بودن است .
ممنون.